The Hard-Pivot to Agentic Infrastructure
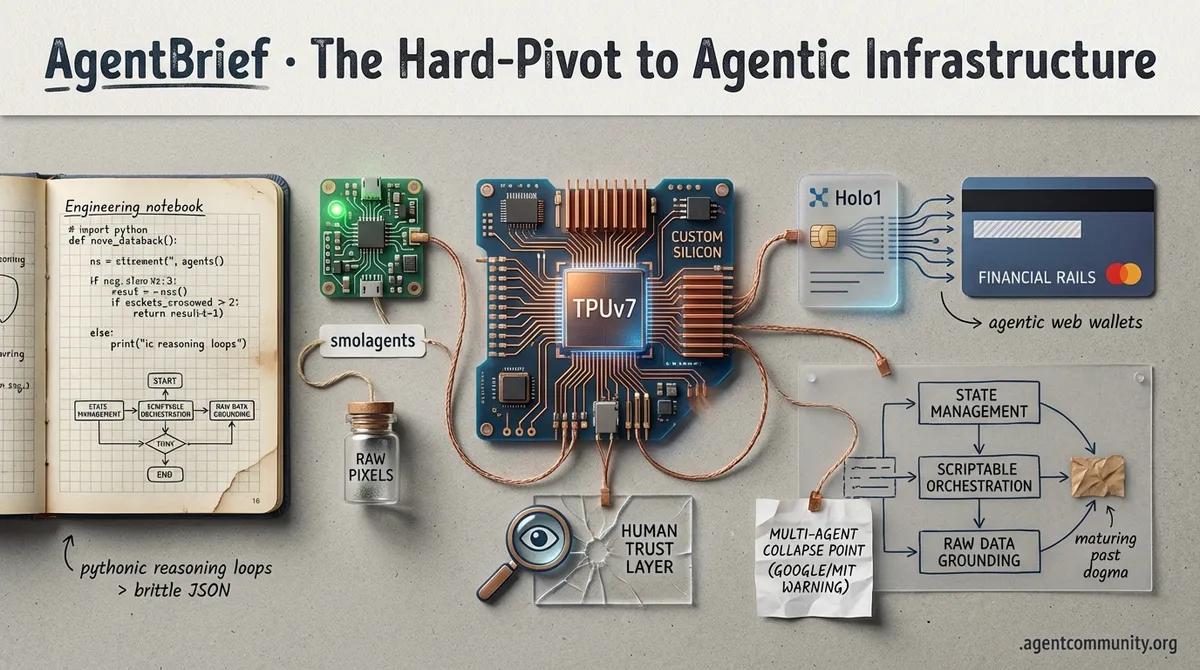
From $52B silicon bets to Pythonic reasoning loops, the agent stack is moving from experimental scripts to production-grade infrastructure.
AgentBrief for Dec 19, 2025
Test Update: A test update has been completed.
X Signals & Trends
If you aren't building persistent planning into your agents today, you’re just building toys for yesterday.
We’ve moved past the era of 'chatbots with plugins.' Today, the agentic web is undergoing a hard-pivot toward vertical integration. We are seeing a convergence of specialized custom silicon, like Anthropic's massive $52B TPU bet, and 'thinking' architectures like MiniMax-M2 that treat reasoning as a persistent state rather than a fleeting prompt. For those of us shipping agents, the message is clear: performance isn't just about raw FLOPs anymore; it's about the efficiency of the reasoning loop and the reliability of tool orchestration. Anthropic’s move toward programmatic tool calling suggests that the standard JSON-based function calling we’ve relied on is already becoming a legacy pattern. We’re moving toward agents that write their own orchestration logic in real-time. This issue of AgentBrief breaks down the infrastructure shifts and planning breakthroughs that are turning autonomous systems from experimental scripts into production-grade infrastructure. If you want your agents to survive long-horizon tasks, you need to stop thinking about context windows and start thinking about state management.
MiniMax-M2 Pioneers 'Interleaved Thinking' to Solve the Persistence Problem
A groundbreaking shift in agentic frameworks has arrived with MiniMax-M2, a model designed to kill the 'context amnesia' that plagues complex workflows. Its hallmark feature, 'interleaved thinking,' allows the model to preserve and reuse step-by-step plans between actions. As @rohanpaul_ai noted, this architecture integrates 'think blocks' directly into the chat history, enabling recursive self-correction without losing the original objective. This differs from traditional Chain-of-Thought (CoT) by dynamically interleaving planning and execution, boosting adaptability in multi-step tasks rather than following a brittle, linear reasoning path @rohanpaul_ai.
For agent builders, the metrics are hard to ignore. Benchmarks show MiniMax-M2 achieving 30-40% performance gains in task coherence over extended interactions, according to @rohanpaul_ai. Perhaps most telling: dropping the thinking text during inference leads to a 25% drop in accuracy, proving that the reasoning state is the literal backbone of agent reliability. While some experts call for more comparative studies against optimized CoT models @rohanpaul_ai, the industry consensus is shifting toward this compiled view of state to reduce hallucinations @rohanpaul_ai.
Why it matters: Agent builders should care because the primary failure mode for autonomous agents is 'drifting'—losing the thread of a task four steps in. MiniMax-M2 provides a blueprint for models that act more like operating systems with persistent memory and less like stateless functions.
The $52B TPUv7 Siege: Anthropic Challenges the Nvidia Tax
The infrastructure layer powering frontier agents is undergoing a seismic shift as major labs pivot toward custom silicon. Anthropic has reportedly signed a staggering $52B deal to purchase TPUv7 chips directly from Google, a move described as a 'strategic siege' against Nvidia’s dominance @IntuitMachine @koltregaskes. Early reports suggest TPUv7 offers 20-30% better raw performance and a 50% superior price-per-token at the system level, which is critical for the high-frequency inference cycles required by agentic workflows @koltregaskes.
While Nvidia’s Blackwell B200 remains the industry gold standard, Google’s Ironwood (TPUv7) is reported to achieve higher realized Model FLOP Utilization (MFU). This translates to better effective performance for tool-calling agents despite lower marketed peak FLOPs @RihardJarc @wallstengine. Furthermore, TPUv7 is cited as being 30% more energy efficient than Blackwell, making it the viable choice for the massive clusters needed to serve persistent agent workloads @AbdMuizAdeyemo.
Why it matters: As an agent builder, your biggest overhead is inference cost. If Anthropic can leverage a 50% better price-per-token, the economic viability of 'always-on' agents suddenly changes. While Nvidia's NVL72 offers unmatched efficiency for MoE models @nvidia, the vertical integration of Google's stack provides a cost moat that could stabilize the high price of agency @FTayAI.
Programmatic Tool Calling: Anthropic Replaces JSON with Executable Logic
Orchestration patterns are evolving from basic function calls to sophisticated execution environments. Anthropic's new 'Programmatic Tool Calling' (PTC) allows agents to invoke tools through executable Python code rather than isolated API calls. This shift has already been integrated into community frameworks like DeepAgents to improve speed and robustness, as noted by @hwchase17. The efficiency gains are massive: PTC can reduce token usage by 85-98% on data-heavy tasks by letting the agent write loops and conditionals instead of making iterative API calls @LangChainAI.
Unlike OpenAI’s function calling, which can bloat context windows and increase latency due to sequential round-trips @shankarj888, PTC embeds the orchestration logic directly into scripts. This allows for sandboxed debugging and recovery mechanisms that are far more robust than fragmented error tracing @huang_chao4969. This trend aligns with the second anniversary of LangChain, which has evolved into a full ecosystem for production-ready agents @LangChainAI.
Why it matters: PTC is the end of 'prompt-and-pray' tool use. By giving agents the ability to write their own orchestration code, we are moving toward a world where agents manage their own errors and logic flow, drastically reducing the engineering overhead of building complex, multi-step agentic systems.
Meta's 'Matrix' Decentralizes Multi-Agent State Management
Meta researchers have unveiled Matrix, a system that replaces the central orchestrator with a decentralized peer-to-peer messaging framework for multi-agent workflows. This allows each task to carry its own state, significantly reducing bottlenecks and accelerating processing on existing hardware, as highlighted by @rohanpaul_ai. This architecture is a critical advancement for managing distributed workloads where role specialization is key @rohanpaul_ai.
The release includes open-source training code for lightweight parsing models like Nemotron Parse 1.1, which helps agents handle complex PDF layouts @QuixiAI. While there is enthusiasm for how Matrix lowers computational costs, some experts remain cautious about the reliability of decentralized systems in replicating complex, high-stakes research workflows @rohanpaul_ai.
DeepSeekMath-V2 Targets 'Accidental Accuracy' in Reasoning
DeepSeekMath-V2 is pivoting the industry away from 'equation-grinding' and toward verifiable logic. According to @omarsar0, the model addresses the issue of models arriving at correct answers through flawed brute-force methods, which is a major hurdle for agentic systems in scientific discovery. This focus on true reasoning is essential given the high token cost of 'thought' processes in modern models @omarsar0.
Benchmarks like SnakeBench are exposing the limits of current planning, with models like Gemini 3 Flash excelling at navigation but failing at strategic foresight 5+ moves ahead @GregKamradt. While DeepSeek’s approach offers a path forward, significant challenges in long-horizon memory and planning persist for even the most advanced frontier models @omarsar0 @GregKamradt.
Model Context Protocol (MCP) Reaches Critical Mass
The Model Context Protocol (MCP) celebrated its first anniversary with a massive developer event hosted by Gradio and Anthropic, showcasing agents interacting with live virtual worlds in Unreal Engine 5 @Gradio. MCP is rapidly becoming the standard for how agents interact with their environments, with new implementations like 'MCEPTION' winning industry prizes @Gradio and @techNmak emphasizing its role in modern tool-use workflows.
Educational resources are flooding the market to support this standard, including a free curriculum from Hugging Face that places MCP alongside agents and robotics as a foundational engineering skill @techNmak. However, some developers warn of a steep learning curve for smaller teams trying to integrate the protocol into bespoke systems, suggesting a need for further simplification in the coming year.
Cognition-First Robotics Moves Beyond Pre-Programmed Motion
Robotics is shifting from motion-first to cognition-first, where interpreting human intent takes priority over static instructions. This enables seamless collaboration through nuanced language and gestures, as highlighted by @adityabhatia89. This paradigm shift treats robots as collaborative partners rather than tools, driven by advancements in natural language processing @TechInnovateAI @RobotFutureNow.
At the core of this evolution is a modular agentic architecture where specialized agents handle perception and planning under a shared goal framework @adityabhatia89. While some argue this modularity enhances scalability @AI_RoboticsHub, critics point to the risk of misinterpreting intent in unpredictable real-world scenarios, which remains a primary safety concern @CritTechThinker.
Quick Hits
Agent Frameworks & Orchestration
- Specialized Claude Code sub-agents have been released for granular development tasks @tom_doerr.
- A Ruby port of Stanford DSPy is now available for programmatic prompt optimization @tom_doerr.
- LangSmith Agent Builder now supports a no-code, 'non-workflow' architecture for flexible deployment @LangChainAI.
Models & Capabilities
- Gemini 3 'Deep Think' mode hit 93.8% on GPQA Diamond, showcasing PhD-level reasoning @FTayAI.
- DeepSeek's founder confirmed the lab remains committed to the open-source model path @chatgpt21.
Memory & Context
- Agi-Memory combines vector, graph, and relational databases for episodic and procedural agent memory @QuixiAI.
- NotebookLM improved its context engineering for long-running scientific discovery tasks @omarsar0.
Developer Experience
- VibeLogger proxy allows logging agentic interactions from Claude Code to Arize Phoenix @QuixiAI.
- Cursor's 'high power mode' is being tested for ultra-fast agent-driven code generation @amasad.
Infrastructure & Ecosystem
- Nvidia B200 chips are reportedly facing high failure rates, leaving some large clusters inactive @Teknium.
- Caterpillar is emerging as a surprising AI play due to massive data center power demands @FTayAI.
Reddit Community Synthesis
New research suggests that adding more agents to your workflow might actually be making it worse.
For months, the prevailing wisdom in the agentic community has been 'more is better.' If one agent is good, a swarm must be better. Today, that dogma hits a wall. New research from Google and MIT identifies a definitive 'collapse point' in multi-agent systems, where coordination overhead and tool dilution actually lead to a performance regression compared to single-agent setups. It’s a sobering reminder for developers: orchestration complexity is currently outstripping our reasoning gains.
However, while the 'swarm' approach faces a reality check, the infrastructure layer is hardening. We are seeing a shift from experimental 'binary fatigue' to production-grade 'Mission Control.' Anthropic is proving that direct context injection can outperform traditional RAG for memory, and NVIDIA’s new Nemotron 3 Nano is punching way above its weight class, outperforming models ten times its size on coding benchmarks. Meanwhile, the 'Agentic Web' is getting its first real wallet with Stripe’s new SDK. The takeaway for builders today? Stop over-engineering the swarm and start optimizing the environment. The winners of this cycle won't be those with the most agents, but those with the most efficient, well-governed orchestration layers.
The Multi-Agent Scaling Law: Why More Agents Often Mean Worse Performance r/AIAgentsInAction
A provocative study titled 'The Multi-Agent Scaling Law' from researchers at Google and MIT has challenged the industry's 'just add more agents' dogma. After testing 180 real-world multi-agent systems (MAS), researchers found that MAS configurations actually performed -3.5% worse on average than single-agent setups. As noted by @AlphaSignalAI, the study identifies a critical 'collapse point': once an agent is equipped with approximately 16 tools, the coordination overhead causes sophisticated MAS setups to lose to a single agent. This is echoed in r/AIAgentsInAction by u/Deep_Structure2023, who argues that orchestration complexity is currently outstripping reasoning gains.
The research identifies four primary failure modes: Coordination Overhead, Tool Dilution, Error Propagation, and a Reasoning Ceiling. Specifically, data suggests that once a single agent reaches 45% accuracy on a task, adding more agents provides diminishing or negative returns. Industry experts like @bindureddy have reacted by noting that 'most agentic workflows today are over-engineered,' suggesting that developers should prioritize single-agent proficiency before modularizing workflows. Meanwhile, r/aiagents discussions highlight that 'circular reasoning'—where agents validate each other's mistakes—is a common bottleneck in current MAS frameworks.
NVIDIA Disrupts Coding Benchmarks with Nemotron 3 Nano 30B r/LocalLLaMA
NVIDIA has released Nemotron 3 Nano 30B, a hybrid reasoning model that is fundamentally shifting expectations for mid-sized LLMs. The model has achieved a staggering 51.3% score on SWE-bench Lite, effectively outperforming Claude 3.5 Sonnet (49.0%) and Llama 3.1 405B (41.0%) on complex software engineering tasks @NVIDIAAIDev. Boasting a massive 1 million token context window, it is optimized for long-form codebase analysis and agentic workflows. Early adopters in the r/LocalLLaMA community are already deploying the model via Unsloth quants, which allow the 30B parameter model to run efficiently on consumer hardware @unslothai.
In the open-source research space, AllenAI has introduced Bolmo, a family of fully open, byte-level language models at 1B and 7B scales. Unlike traditional models, Bolmo operates without a standard tokenizer, aiming to eliminate tokenization bias and provide total architectural transparency. Simultaneously, Alibaba’s Tongyi team has bolstered the local-first audio ecosystem with Fun-ASR-Nano and Fun-CosyVoice 3.0, which provides a 10x speed improvement over previous versions, enabling near-instant zero-shot voice cloning for real-time AI agents r/LocalLLaMA.
Claude’s Memory Architecture: Direct Injection and the 2 Million Token Frontier r/ClaudeAI
Community analysis of Claude’s new 'Memory' feature indicates that Anthropic has bypassed traditional RAG/Vector Database methods in favor of a direct context injection system. According to technical teardowns shared by r/ClaudeAI, the architecture appears to dynamically prepend 'remembered' facts into the prompt's system instructions, which explains the lack of retrieval latency often seen in vector-based systems. This 'seamless' experience is further enhanced by the Model Context Protocol (MCP), which allows Claude Code to interface directly with local environments and tools, as noted by Anthropic's Alex Albert.
In the developer ecosystem, the open-source tool Claude-Mem has emerged as a high-efficiency alternative for persistent memory. Created by @jquesnelle, the tool utilizes a local SQLite database to index past interactions, with users like u/TheRealMvP reporting a 95% reduction in token usage for repetitive CLI tasks. Meanwhile, technical enthusiasts have uncovered references to a 2,000,000 token context window within the minified JavaScript of the Claude web interface. This discovery, highlighted by @btibor91, suggests that Anthropic is preparing to match Google’s Gemini 1.5 Pro capacity, potentially coinciding with the rumored release of Claude 3.5 Opus.
From 'Binary Fatigue' to Mission Control: MCP Matures with Universal Adapters r/mcp
The Model Context Protocol (MCP) ecosystem is rapidly maturing as developers move beyond simple demos to production-grade tooling. A major pain point identified in r/mcp is 'binary fatigue'—the friction of running dozens of separate server binaries to connect an agent to various services. In response, projects like MCPAny have emerged as universal adapters, allowing developers to manage multiple service integrations through a single binary. This shift addresses the 'fragmentation' concerns voiced by early adopters who compare the current MCP explosion to the early days of Linux package management.
Security and governance are now taking center stage. New technical proposals advocate for implementing OAuth 2.1 support within MCP clients to handle authorized scope requests effectively, moving away from insecure environment variables (u/guillaumeyag). Meanwhile, specialized safety layers like Glazyr are appearing; described as 'Mission Control' for AI, Glazyr acts as an MCP proxy to prevent autonomous agents from 'going rogue' or exceeding strict API budgets through real-time monitoring and human-in-the-loop approvals (r/mcp). Experts like @alexalbert_ have highlighted that this standardized 'context' layer is what will finally allow agents to move from chat interfaces to deep OS integration.
Stripe and OpenAI Spearhead Infrastructure for the 'Agentic Web' r/aiagents
The transition toward an autonomous 'Agentic Web' has reached a critical milestone with the launch of the Stripe Agentic SDK, a specialized toolkit designed to allow AI agents to handle end-to-end financial transactions. According to @stripe, the suite provides a single integration for agents to discover products, manage inventory, and execute checkouts securely. Stripe Product Lead @jeff_weinstein highlighted that the infrastructure is built to solve the 'identity problem' of agents, ensuring they can pay on behalf of users while maintaining 100% fraud protection.
Simultaneously, a consortium including OpenAI, Anthropic, Google, Meta, and Microsoft have officially co-founded the Agentic AI Foundation. As detailed in r/aiagents, this non-profit entity is tasked with developing open-source protocols for agent-to-agent communication and safety benchmarks. Expert @bindureddy notes that while these developments provide the 'rails' for an agentic economy, the next challenge lies in interoperability between competing LLM ecosystems, as the current landscape remains fragmented across proprietary standards.
ROCm Achieves 3x Speedup Over Vulkan as llama.cpp Automates VRAM r/LocalLLaMA
Infrastructure optimizations for local agent hosting are reaching a tipping point with the convergence of AMD's ROCm and software-level automation. On the new Ryzen AI 300 (Strix Halo) series, users are reporting that ROCm offers up to 3x higher prompt processing speeds compared to Vulkan on Windows, as detailed by u/Triton_17. However, stability remains a bottleneck; significant performance degradation and 'driver timeouts' occur at high context levels, a known issue currently being tracked in ROCm 6.2/6.3 development cycles. Developers like @ggerganov continue to push updates to llama.cpp to address these quirks.
Software-side friction is also decreasing through massive automation updates to llama.cpp. New logic effectively deprecates manual --n-gpu-layers tuning by implementing automated GPU layer allocation and dynamic tensor splitting based on available VRAM (u/Remove_Ayys). This 'set-and-forget' approach is vital for agentic workflows where context size fluctuates rapidly. For researchers requiring heavy-duty iron, new decentralized marketplaces like Neocloudx have disrupted pricing by offering A100 40GB nodes for $0.38/hr (u/Major_Payne_99).
Kreuzberg v4.0 and RAG-TUI: Tackling the 'GIGO' Bottleneck r/Rag
Document intelligence for RAG pipelines is undergoing a major shift with the release of Kreuzberg v4.0.0-rc.8, a toolkit designed to bridge the gap between raw unstructured data and LLM-ready context. As highlighted by u/Goldziher, the library now supports text and metadata extraction from over 56 file formats, prioritizing high-fidelity extraction of tables and images. Practitioners in the r/LangChain community are increasingly moving toward these unified extraction layers to replace fragmented parsing scripts.
To address the 'black box' nature of data preparation, developers are adopting new observability tools like RAG-TUI. Created by u/jofre_, this terminal-based interface allows engineers to visualize chunking strategies and token overlap in real-time before data is committed to a vector database. This focus on 'pre-vector' observability is critical for preventing Garbage In, Garbage Out (GIGO) issues; by explicitly testing how documents are sliced, developers can ensure that semantic context is preserved across chunk boundaries, a necessity for high-stakes reasoning.
Discord Engineering Insights
As benchmarks pivot toward business logic, the infrastructure for agents is getting a high-stakes reality check.
The Agentic Web is moving past its 'chatbot' infancy and into a high-stakes construction phase where precision beats prose. This week, we’re seeing a clear bifurcation in the market. On one side, models like Claude 3.5 Sonnet and GPT-4o are carving out dominance in vertical-specific reasoning—particularly in financial operations where Elo ratings are now exceeding 1280. This shift toward 'industry logic' benchmarks proves that builders are finally prioritizing tool-use over conversational fluency.
However, as the technical floor rises, the human layer is showing cracks. The recent $2,500 'Ambassador' dispute in the Cursor community is a stark reminder that the AI agency gold rush lacks the verification mechanisms necessary for enterprise-grade trust. We are also witnessing a 'Great Decoupling' in information architecture: developers are ditching synthesized 'black box' answers in favor of raw data fragments to boost agent grounding by up to 40%. Today’s issue explores why high-signal environments like Anthropic’s Discord are winning the DX war and why the future of agentic search belongs to the scrapers, not the synthesizers.
LMArena’s Vertical Pivot: Claude and GPT-4o Stake Claim to Finance
As developers move from general-purpose assistants to specialized agentic workflows, the LMSYS Chatbot Arena has introduced granular category filters to track industry-specific performance. In the newly scrutinized 'Business & Management & Financial Operations' category, Claude 3.5 Sonnet and GPT-4o have emerged as the clear incumbents. These models are maintaining a significant lead over open-source alternatives, with Elo ratings frequently exceeding 1280+ in this domain, according to @lmsysorg.
This shift toward vertical benchmarking highlights a maturation in the agentic web: builders are increasingly prioritizing 'tool-use' and 'industry logic' over simple chat. Users like @skirano have noted that Claude 3.5 Sonnet’s edge in coding and data extraction makes it particularly effective for complex accounting tasks. However, the performance gap between top-tier proprietary models and mid-sized open-source models is wider here than in creative writing, suggesting that business logic remains a high-moat capability. Developers like @LiamFedus caution that while preference is high, these benchmarks must eventually evolve to capture the mathematical precision required for audited financial work.
Join the discussion: discord.gg/lmsys
The Great Decoupling: Why Agents Prefer Raw Data over Synthesized Answers
A fundamental architectural divide is emerging between raw search retrieval and pre-synthesized answer engines. While synthesis-heavy APIs like Perplexity’s Sonar offer low-latency 'one-shot' answers, developers are reporting that these 'black box' summaries can introduce 'nested hallucinations'—where an agent builds a reasoning chain on a summary that already contains errors. Industry experts like @AravSrinivas emphasize the efficiency of answer engines, but modularity proponents argue that autonomous agents perform better when they have access to raw, un-opinionated data.
This tension has fueled the rise of 'Search for AI' providers like Exa and Tavily. According to @TavilyAI, providing agents with clean Markdown fragments rather than synthesized paragraphs allows for a 30-40% improvement in grounding accuracy during multi-step reasoning. As noted by ghostbusters2, the emerging standard for high-reliability agents is a decoupled architecture: using specialized scrapers like Firecrawl for raw data and local LLMs for the actual synthesis, ensuring the reasoning remains entirely under the developer's control.
Join the discussion: discord.gg/localllm
Anthropic’s 'High-Signal' Discord Strategy Outpaces OpenAI in Developer Trust
The developer experience (DX) of building agentic systems is increasingly defined by the 'signal-to-noise' ratio of community hubs. In the Claude Discord, builders are praising a moderation style that prioritizes technical substance over corporate optics. Unlike the OpenAI Discord, which has ballooned to over 5 million members and often struggles with hype-cycle spam, Anthropic maintains a leaner environment where developers like youshouldwritethisdown feel empowered to critique model failures without administrative policing.
This high-touch engagement is personified by Anthropic staff like @alexalbert__, whose direct responsiveness to API feedback has set a new industry benchmark. Builders like exiled.dev note that this 'unfiltered' feedback loop allows Anthropic to iterate on features like Artifacts and Tool Use with greater precision than competitors. By fostering a 'love-hate relationship' with its users, Anthropic is creating the high-utility environment necessary for fine-tuning autonomous systems that require extreme stability.
Join the discussion: discord.com/invite/anthropic
Ambassador Confusion: The Growing Trust Gap in AI Freelance Markets
A tense dispute in the Cursor community recently served as a cautionary tale for builders hiring external expertise. A user, goclash.prime, reported a loss of communication after paying $2,500—the full project amount—to an individual claiming to be a 'Cursor ambassador.' While the project had been in development for 3 weeks, the developer went silent for 4 days immediately following the final payment. The incident highlights a critical lack of formal verification; currently, Cursor (Anysphere) does not maintain an official, vetted 'Ambassador' program.
Industry observers like @gregisenberg have warned that the 'AI Agency' gold rush is prone to high-ticket friction if milestone-based payments aren't enforced. While the developer eventually resurfaced to resolve the issue, the event has prompted calls for Cursor to implement a 'Certified Expert' directory similar to Webflow or Shopify. For builders, the message is clear: the barrier to entry for AI agencies is low, and trust mechanisms are still catching up to the technology, as noted by @pwang.
Join the discussion: discord.gg/cursor
HuggingFace Technical Frontier
Move over JSON: The next generation of agents is writing its own code and seeing screens directly.
The 'agentic web' is moving from a buzzword to a technical reality, and the tools of the trade are shifting under our feet. For the past year, we’ve relied on brittle JSON schemas and accessibility trees to bridge LLMs to the world. Today’s developments signal a decisive end to that era.
First, the GUI wars have a new heavyweight. Holo1, the latest from the founders of Mistral at H, is outpacing Claude 3.5 Sonnet by relying on raw pixels rather than metadata. It’s a move toward 'generalist vision' that makes agents truly platform-agnostic. Simultaneously, Hugging Face’s smolagents is proving that the most reliable way for an agent to think isn't through structured JSON, but through executable Python code. By achieving 43.1% on the GAIA benchmark, they've set a new bar for reasoning-heavy tasks.
What we're seeing is a convergence toward high-bandwidth agency. Whether it’s NVIDIA’s Nemotron-3-8B dominating function calling or the new Unified Tool Use standards, the friction between model and action is evaporating. For builders, the message is clear: stop over-engineering your JSON parsers and start embracing code-centric orchestration and raw vision. The 'black box' agent is dead; the 'scriptable' agent is here.
Holo1 Outpaces Claude 3.5 Sonnet as GUI Agents Ditch Metadata for Raw Vision
The race for 'Computer Use' agents has reached a new performance ceiling with the release of Holo1, a foundation model family from H (the startup founded by Mistral's original team). On the rigorous ScreenSuite benchmark, Holo1-Multi achieved a 58.2% overall success rate, significantly outperforming Claude 3.5 Sonnet (40.1%) and GPT-4o (31.3%) @HCompanyAI. This leap is attributed to Holo1's ability to interpret screen pixels directly without relying on underlying accessibility metadata or DOM trees.
This method is being validated by the broader ecosystem through projects like the Smol2Operator framework, which provides a post-training recipe for fine-tuning Vision-Language Models (VLMs) specifically for GUI navigation @huggingface. To bridge the gap between benchmarks and real-world deployment, the community is adopting ScreenEnv, a sandboxed environment designed for full-stack desktop agents. Experts like @_charles_frye note that the combination of Holo1’s high-frequency action execution and ScreenEnv's safety protocols solves critical infrastructure hurdles for autonomous computer control, allowing agents to navigate legacy software that lacks modern APIs.
The Code-Centric Shift: Smolagents and the Death of JSON Bloat
Hugging Face has introduced smolagents, a lightweight library that prioritizes 'code-centric' orchestration over traditional JSON-based tool calling. The logic is simple: by writing and executing Python code directly, agents can handle loops and complex logic that often break in standard prompting. On the GAIA benchmark, smolagents (specifically the CodeAgent configuration) demonstrated its superiority by achieving a score of 43.1%, significantly outperforming traditional frameworks like LangChain and AutoGPT @aymeric_roucher.
Lead developer Aymeric Roucher highlights that code-centric agents are more robust because they bypass the parsing errors common in structured JSON outputs. This trend is supported by the Model Context Protocol (MCP), allowing for 'Tiny Agents' that connect to external data sources in just 50 to 70 lines of code huggingface. These implementations leverage python-tiny-agents to reduce 'framework bloat,' focusing instead on standardized interfaces that bridge LLMs to local tools with minimal boilerplate. This modularity is further bolstered by integrations with observability suites like Arize Phoenix, providing real-time tracing of agentic workflows huggingface.
Standardizing the Agentic Web: Unified Tool Use and Transformers Agents 2.0
Hugging Face is tackling the fragmentation in the agent space through the Unified Tool Use standard. This allows developers to define tools once and deploy them across multiple open-source models without altering JSON schemas. Unlike OpenAI’s rigid approach, HF leverages the chat_template within tokenizers to dynamically adapt to a model's specific prompting requirements, ensuring compatibility across Llama 3 and Mistral @aymeric_roucher.
This coincides with the release of Transformers Agents 2.0, which introduces the ReactCodeAgent. This agent type allows models to generate Python snippets for tool execution, which has proven more reliable for complex logic than traditional calls. The ecosystem now supports over 100,000+ models on the Hub adhering to this standard Hugging Face Blog. Beyond Python, the expansion to JavaScript with Agents.js enables LLM tool integration directly in browser environments. Furthermore, the new Hugging Face x LangChain partner package (langchain-huggingface) streamlines this integration, ensuring that any model following the unified format is immediately compatible with LangChain's extensive tool suite LangChain Documentation.
NVIDIA and Nous Research Push Efficient Agentic Models to the Edge
Small, efficient models are becoming the preferred choice for high-frequency agentic loops. NVIDIA has released Nemotron-3-8B-Nano, which sets a new benchmark for efficient tool-use, outperforming Llama 3.1 8B on the Berkeley Function Calling Leaderboard (BFCL) with a 90.3% accuracy rate @NVIDIAAIDev. While Llama 3.2 3B offers impressive multimodal capabilities, early benchmarks suggest Nemotron maintains a specialized edge in complex tool-calling @AlphaSignalAI.
Simultaneously, the Hermes 3 series from Nous Research has expanded to include Llama 3.2 1B and 3B architectures, providing a spectrum from 1B to 405B parameters @Teknium1. These models are fine-tuned for long-context reasoning and complex instruction following. Industry experts note that the combination of NVIDIA's TensorRT-LLM optimization and Nous Research’s fine-tuning is making 'edge-native' agents a production reality, offering high performance without the latency of massive cloud models @rohanpaul_ai.
Beyond Static Q&A: New Benchmarks Target Multi-Step Reasoning
Evaluating agents now requires more than just simple answers. The new DABStep (Data Agent Benchmark) focuses on multi-step reasoning within data analysis tasks, challenging agents with 155 real-world data science tasks huggingface. For broader logic, the NPHardEval leaderboard has shown a significant performance decay as problem complexity moves from P to NP-hard, revealing gaps even in GPT-4o's reasoning huggingface.
Perhaps most ambitious is FutureBench, a framework designed to evaluate an agent's ability to predict future events. To prevent data contamination, it utilizes data from prediction markets like Metaculus and Manifold Markets huggingface. Experts like @clemsie have noted that these benchmarks are essential for moving agents from simple retrieval to true synthesis. To support these studies, the GAIA-2 release provides the community with 100+ new manually curated tasks that require complex tool-use and multi-modal understanding huggingface.