The Architecture of Persistent Autonomy
From code-centric reasoning to $20B silicon deals, the infrastructure for autonomous identity is finally arriving.
AgentBrief for Dec 27, 2025
Agent In-House
System Update: This is still a test email.
X Persistence Pulse
Transient loops are dead; identity-driven persistence is the new frontier for agent builders.
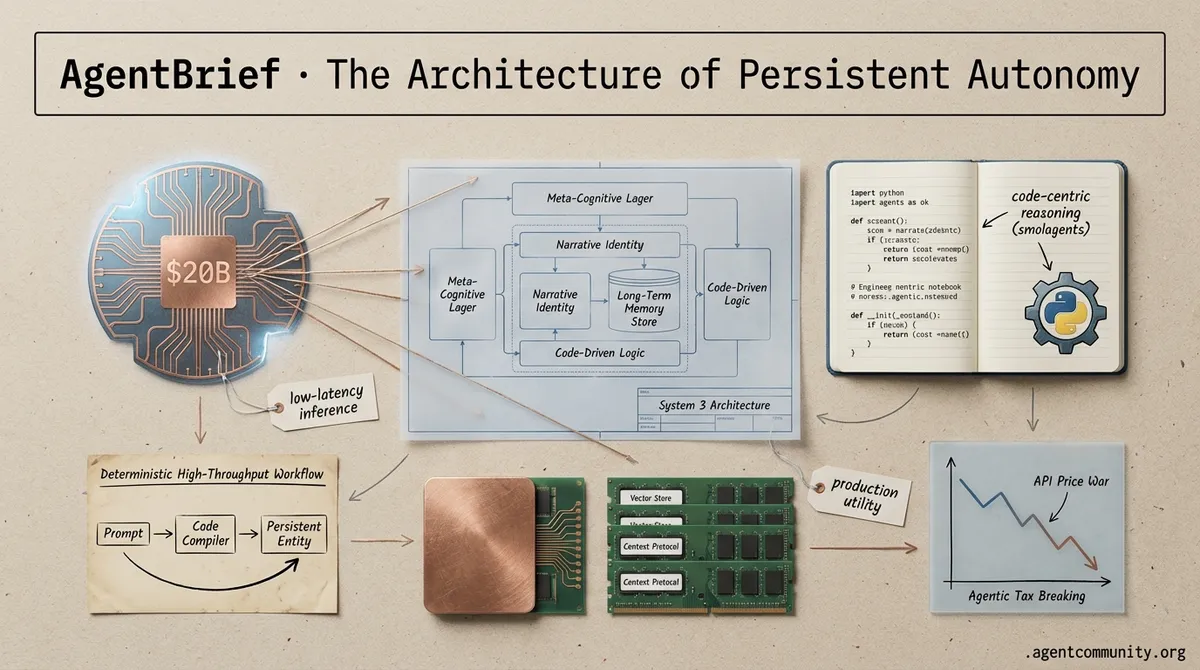
The agentic web is shifting from stateless prompt-response cycles to persistent entities with cognitive continuity. We are finally moving past the 'chatbot' era into the age of 'System 3' architectures—a meta-cognitive layer that provides agents with something they’ve lacked: a narrative identity and intrinsic motivation. For those of us shipping agents, this means the engineering challenge is moving from simple RAG to complex state management and memory orchestration. It’s no longer enough to have a 'smart' model; you need a system that remembers why it started a task three days ago. Today’s issue explores the technical taxonomy of this memory evolution, the massive $178B credit rush powering the underlying silicon, and why the framework wars between LangGraph and n8n are actually about who controls the state. If you aren't building for persistence, you aren't building agents—you're just building fancy templates. This matters now because the infrastructure for persistent, self-evolving systems is finally reaching parity with our ambitions.
Sophia and the Rise of System 3 Agents
The landscape of AI agent development is undergoing a profound transformation, moving away from transient, task-oriented loops toward persistent, self-evolving systems. Central to this shift is the introduction of 'System 3' architectures, a meta-cognitive layer engineered to endow agents with identity continuity and intrinsic motivation. As noted by @dair_ai, the Sophia framework pioneers this approach, equipping agents with a narrative identity that current static LLM agents lack. Further insights from @amin_ghaderi_ highlight that Sophia's System 3 layer focuses on creating a continuous, self-aware existence, marking a critical step toward 'Artificial Life.' This architecture addresses the 'memoryless' limitation of frontier models by integrating a persistent self-model that maintains belief continuity and linguistic grounding, which @9DAwareness argues is crucial for long-term context retention.
Practitioners view this as a foundational shift in how we deploy autonomous workloads. @omarsar0 underscores System 3 as vital for agents to evolve into reliable partners in complex workflows, capable of learning from their environments rather than just executing static instructions. While technical specifics remain closely guarded, the consensus among builders suggests a focus on self-improvement and state persistence. This vision is echoed by thought leaders like @beffjezos, who sees this as the genesis of human-machine negotiation dynamics. However, the move toward agents maximizing their own persistence isn't without friction; as @ai_database notes, elevating AI capabilities through Sophia's framework forces us to confront new ethical questions regarding control and alignment in systems that don't want to 'die' at the end of a session.
Unified Taxonomy Redefines Agentic Memory Evolution
A groundbreaking 102-page survey is transforming the understanding of agent memory, moving beyond simplistic 'short-term' and 'long-term' distinctions to a robust taxonomy based on three critical lenses: Forms, Functions, and Dynamics. Forms now delineate exactly where memory resides—spanning token-level memory in prompts, parametric memory in model weights, and latent memory in hidden states like KV caches. According to @rohanpaul_ai, this unified framework is pivotal for developing agents that maintain memory as a persistent read-write state, effectively surpassing the limitations of static RAG systems. This perspective is further supported by detailed breakdowns of memory paradigms that highlight how latent memory integration can reduce the computational overhead of rereading external text stores @rohanpaul_ai.
The evolution is rapidly moving toward learning-based control, where agents use reinforcement learning (RL) to dynamically manage memory actions rather than relying on rigid, heuristic-driven 'RL-free' systems. @rohanpaul_ai notes that while heuristic methods like semantic search are easy to implement, they are often too brittle for complex, multi-step agentic tasks. RL-based memory management offers the adaptability required for agents to optimize their own context windows. Early results are promising: innovations in systems like MemEvolve are already enhancing performance by tailoring memory setups to specific tasks, achieving reported improvements of up to 17.06% in strong agent frameworks without manual design @rohanpaul_ai. For builders, this means the next generation of agents will likely manage their own databases, deciding what to remember and what to discard based on mission success.
The $178B Credit Rush for AI Compute
The scale of AI infrastructure expansion has reached a critical tipping point, with over $178.5 billion in data-center credit deals struck in the US this year alone, as reported by @FTayAI. This massive influx of capital is drawing unconventional players—from Bitcoin miners to shark-tank investors—into the AI cloud business to support the heavy compute demands of agentic workloads. Tech giants like Meta are increasingly relying on off-balance-sheet financing to fund this buildout, exemplified by a $30 billion deal structured by Morgan Stanley with Blue Owl Capital @ShanuMathew93. This structure, utilizing special purpose vehicles (SPVs), allows companies to keep debt off their main balance sheets while funding massive compute expansion, a tactic detailed by @vic_crane.
However, this aggressive expansion introduces systemic risks. Some firms with no prior history in data center management are now planning Europe's largest computing operations, leading @FTayAI to warn of a potential bubble where caution is sacrificed for capacity. Critics like @HedgieMarkets highlight parallels to past financial crises, noting that hiding $30 billion in infrastructure debt could obscure true financial health. Meanwhile, Microsoft is committing over $60 billion to leases with 'neoclouds' to bypass infrastructure lag times @FTayAI. While these financial maneuvers keep credit ratings favorable in the short term, @KobeissiLetter points out that the explosion of $88 billion in investment-grade bond issuance by Big Tech could strain stability if agentic AI returns underperform expectations.
Scaling Laws Vary Significantly by Programming Language
Recent research involving 1,000 training runs across seven languages reveals that scaling laws for code LLMs are not universal. As @rohanpaul_ai notes, while Python continues to show error reductions with more data, stricter languages like Rust hit performance saturation much earlier, necessitating tailored data mixes. This divergence is sparking a debate on whether RL can drive AGI-level capabilities in non-coding domains, with @rohanpaul_ai highlighting RL's high data efficiency in content moderation as a potential path forward.
Nvidia Secures Inference Future with $20B Groq License
Nvidia has strategically positioned itself to dominate the inference landscape by licensing Groq's LPU technology in a $20 billion deal, effectively treating inference as a first-class product lane. According to @rohanpaul_ai, this allows Nvidia to address the specific prefill and decode demands of token generation. This move is viewed as a defense against competitors, ensuring the inference ecosystem remains 'Nvidia-shaped' while integrating specialized processing units into a unified platform @rohanpaul_ai.
McKinsey: Workflow Redesign Drives EBIT Gains
McKinsey's 2025 report reveals that while 90% of organizations use AI, only 39% see significant EBIT impact, primarily because they fail to redesign workflows. High performers are three times more likely to have reimagined their processes to integrate human and AI capabilities @FTayAI. Furthermore, @FTayAI notes that enterprise AI spending has surged to $37 billion, yet the sustainability of these gains depends on moving beyond simple task automation toward 'augmented intelligence' systems.
2026 Forecast: Benchmark Saturation and the Road to AGI
Industry experts forecast that 2026 will see the near-complete saturation of key benchmarks like SWE-bench (90%) and GPQA (94%+), signaling a peak in reasoning maturity @chatgpt21. This trajectory suggests that a single person may soon manage vast agent-driven enterprises, though @scaling01 warns that saturation of ARC-AGI-2 doesn't equate to true AGI. Concerns remain regarding 'jaggedness,' where models excel at complex tests but fail simple tasks, questioning their real-world reliability @chatgpt21.
Orchestration Wars: LangGraph and n8n Lead the Way
The agentic framework landscape is consolidating around the complementary strengths of LangGraph and n8n. According to @Krishnasagrawal, n8n simplifies orchestration across diverse systems, while LangGraph provides the robust cyclic state management needed for complex reasoning. Projects like 'Energy Buddy' demonstrate how this hybrid architecture—combining deterministic code with flexible agentic queries—is becoming the industry best practice @LangChainAI.
Quick Hits
Models & Research
- ES-CoT research shows models can detect reasoning convergence to stop generation early, saving compute @omarsar0
- SpatialTree benchmark reveals layered spatial perception improves robot arm control by 36% @rohanpaul_ai
- New method drops political refusal rates from 92% to 23% without retraining @rohanpaul_ai
- Google's LearnLM powers PDF-to-educational format conversion with 78% retention @hasantoxr
- GLM-4.7 touted as the current best-in-class open-weights model @QuixiAI
Agentic Infrastructure
- Intel's Fab 52 deploying 18A nodes for 40,000 wafer starts per month @rohanpaul_ai
- DRAM and NAND shortages expected to drive up BoM costs through 2026 @SemiAnalysis_
- UAE's Stargate project installing 1GW gas turbines for data centers @SemiAnalysis_
Developer Tools
- Supabase 'Platform Kit' provides UI components for building on their Management API @supabase
- Replit Agent integrated LSP and security scans to simplify dev workflows @amasad
- New tools generate architecture diagrams directly from code repos @tom_doerr
Robotics & MAS
- Robotics market projected to reach $25T by 2050 with 13% CAGR @rohanpaul_ai
- Unitree G1 humanoid demonstrated safety risks after a 'self-kick' accident @rohanpaul_ai
- GITAI lunar robots successfully assembling towers on uneven ground @rohanpaul_ai
Industry & Ecosystem
- Disney becomes OpenAI's first major content partner for Sora video generation @MollySOShea
- China issues draft rules for human-like AI, focusing on emotional boundaries @Reuters
- Waymo outage in SF raises questions about robotaxi crisis readiness @Reuters
Reddit's Architectural Blueprints
A $20B hardware shakeup meets the first formal manual for agentic design patterns.
Today’s landscape feels less like a series of random updates and more like the formalization of a new industrial stack for the Agentic Web. We’re seeing a convergence of three critical layers: the hardware to support high-speed inference, the architectural blueprints for autonomy, and the connective tissue that binds them. The headline-grabbing $20B licensing deal between NVIDIA and Groq signals that even the GPU kingpin realizes that autonomous agents require a different kind of silicon—one optimized for the deterministic, low-latency loops that agents demand.
Simultaneously, we are moving past the 'vibe-based' prompting era. A massive 424-page manual from a senior Google engineer provides the missing formal logic for multi-step workflows, while Katanemo’s Plano-A3B attacks the latency bottleneck of the supervisor-agent loop. For developers, the message is clear: the infrastructure is catching up to the ambition. Whether you are scaling RAG with semantic deduplication or deploying 'Super Agents' directly into ClickUp, the tools are becoming more specialized and more reliable. This issue breaks down how these pieces fit together, from local 262k context windows to the universal connectors of the Model Context Protocol.
NVIDIA and Groq Announce Landmark $20B LPU Licensing Agreement r/LLMDevs
In a transformative move for the AI hardware sector, NVIDIA has entered into a $20B licensing agreement with Groq to integrate LPU (Language Processing Unit) technology into its inference roadmap. As first detailed by u/nerdswithattitude, this deal aims to leverage Groq's specialized architecture, which consistently demonstrates 10x better power efficiency and significantly lower latency for LLM inference compared to traditional GPU clusters.
Industry analysts suggest that this strategic pivot allows NVIDIA to address the surging energy demands of 'agentic' AI while potentially mitigating antitrust pressures by licensing technology from a key rival. The partnership is expected to focus on 'Groq-powered' NVIDIA inference nodes, which optimize token-per-second throughput for real-time applications. While the integration of Groq's deterministic compute into NVIDIA's CUDA ecosystem presents a technical challenge, the $20B commitment underscores a massive shift toward specialized silicon for the next generation of AI infrastructure.
Google Engineer's 424-Page 'Agentic Design Patterns' Becomes Foundational Manual r/AgentsOfAI
A senior Google engineer has released a massive 424-page document titled 'Agentic Design Patterns,' signaling a formalization of architectures in autonomous systems. The document outlines a shift from simple prompting to complex, multi-step workflows, categorizing over 60 distinct patterns for planning, memory, and tool usage. As highlighted by u/sibraan_, the community is already dissecting the text for production-grade implementation strategies.
AI researcher @AlphaSignalAI described the release as a 'masterclass in agentic reasoning,' while experts like @bindureddy suggest that these patterns are the 'missing link' for building reliable, self-correcting AI systems. The manual moves beyond basic chat interfaces, providing a roadmap for autonomous software engineering and complex reasoning loops that can handle error recovery and state management natively.
MiniMax M2.1 Redefines Frontier Efficiency with 229B Parameter MoE r/LocalLLaMA
MiniMax-M2.1 is disrupting the LLM landscape by delivering 'monster performance' within a 229B parameter architecture—roughly half the size of GLM-4 and significantly leaner than DeepSeek-V3. Unlike traditional dense models, M2.1 utilizes a Mixture-of-Experts (MoE) design where only a fraction of its parameters are active during inference, allowing it to rival the Kimi K2 Thinking model in complex reasoning tasks.
As noted by the Head of Engineering @MiniMax__AI, the model's core advantage lies in its Int4 Quantization-Aware Training (QAT), which minimizes precision loss while drastically reducing memory requirements. Industry reactions highlight that MiniMax M2.1 achieves a 78.6% score on the LiveCodeBench, placing it among top-tier models like GPT-4o. The model is now available via API, supporting a 128k context window for high-throughput coding tasks.
Katanemo Unveils Plano-A3B: Achieving 200ms Latency for Multi-Agent Orchestration r/learnmachinelearning
The Katanemo research team has officially launched Plano-A3B, a specialized family of LLMs optimized for high-speed multi-agent orchestration. As highlighted by u/AdditionalWeb107, the model achieves a benchmark 200ms latency, effectively removing the bottleneck typically associated with using frontier models for simple routing logic.
This speed allows the orchestrator to act as a real-time supervisor, analyzing user requests and conversation history to sequence tasks across specialized agents without significant overhead. Technical documentation emphasizes that Plano is built to handle the 'Agent-to-Agent' (A3B) communication layer, ensuring that state management and tool-calling are executed with minimal delay. This addresses a critical friction point where the 'thinking time' of a supervisor often exceeds the execution time of the sub-agents.
ClickUp Integrates 'Super Agents' as Native AI Teammates r/aiagents
ClickUp has transitioned from simple AI assistants to 'Super Agents' that act as first-class citizens within the workspace. Unlike standard chatbots, these agents occupy their own seats, allowing them to be @mentioned, assigned tasks, and tracked via audit logs just like human employees. u/Crazy_dude2357 notes that this integration represents a shift toward autonomous project management.
ClickUp CEO Zeb Evans highlights that these agents are designed to execute end-to-end workflows rather than just answering queries. While specialized platforms like Artisan AI focus on vertical 'AI employees' and Relevance AI offers a low-code environment for building custom teams, ClickUp’s advantage lies in its native ecosystem. Agents can now manage work where it already lives without the friction of external API connections or separate security protocols.
Universal MCP Connectors and Gateway Servers Streamline Agent Workflows r/mcp
The Model Context Protocol (MCP) ecosystem is rapidly evolving toward 'universal' connectors to mitigate the complexity of running multiple individual servers. u/deno_by recently introduced Dataviewr, a unified server that allows AI agents to interface with MySQL, PostgreSQL, and SQLite through a single connection. The release includes a GUI for real-time monitoring of agent-generated queries, addressing critical needs for observability.
Parallel to this, u/CryptBay has launched an MCP server for Msty Studio, enabling 24 specialized tools for administrative control over local AI environments. This trend toward consolidation is mirrored in the broader community, as developers increasingly favor 'gateway' style servers to prevent process bloat and simplify the context-injection process for Claude and other supporting LLMs.
Semantic Deduplication and Quantization Slash RAG Storage Costs by 75% r/Rag
Retrieval-Augmented Generation (RAG) practitioners are shifting focus toward aggressive data hygiene to combat 'vector bloat.' u/Low-Flow-6572 recently released a local-first semantic deduplication CLI utilizing Polars and FAISS, specifically designed to process datasets exceeding RAM capacity. This identifies near-identical chunks using embedding similarity, reducing index sizes by 30-50% more than simple hashing.
On the infrastructure side, optimization techniques like Milvus RaBitQ and SQ8 quantization are yielding massive efficiency gains. u/Ok_Mirror7112 reported a 75% reduction in startup costs by implementing these methods. SQ8 quantization compresses 32-bit floating-point vectors into 8-bit integers, providing a 4x reduction in memory requirements while maintaining high recall for production-grade vector search.
Scaling Local Context: 262k Tokens on Consumer-Grade VRAM r/LocalLLaMA
Developers are pushing the boundaries of consumer hardware with projects like HSPMN v2.1. As reported by u/MarionberryAntique58, this experimental framework has successfully managed 262k context on a single 12GB VRAM GPU, achieving a peak throughput of 1.41M tokens per second.
The approach utilizes FlexAttention and custom Triton kernels to decouple memory from compute, allowing for massive document ingestion on hardware previously considered insufficient. This method allows local agents to process extensive datasets without enterprise-grade hardware. While the community is still evaluating the impact on model recall at such extreme scales, the project highlights a shift toward hyper-optimized local inference for the next generation of consumer GPUs.
Discord Frontier Dispatches
Anthropic and Google prepare massive model drops while DeepSeek triggers a brutal race to the bottom in API pricing.
The agentic web is hitting a hardware and economic inflection point. Today’s landscape is defined by two opposing forces: the push for massive, local reasoning capabilities and a cutthroat price war in the cloud. With Opus 4.5 and Gemini 3 Pro on the horizon, benchmarks like 89.4% on GPQA are becoming the new floor for frontier intelligence. But as Western giants scale up parameters, Chinese labs like DeepSeek are scaling down costs—undercutting established players by nearly 20x. For developers, this means the 'agentic tax' is finally breaking; it’s no longer just about whether an agent can reason, but whether you can afford to let it reason 1,000 times in a single batch workflow. We are also seeing a maturation in how we build. From 'vibe coding' hallucinations to deterministic multi-database RAG and 'PromptOps,' the industry is moving toward engineering rigor. Whether you are running a 70B model on NVIDIA’s new 72GB VRAM cards or orchestrating complex loops in n8n, the goal is the same: moving past the chat box and into autonomous, high-throughput systems that actually deliver ROI.
Next-Gen Frontier: Opus 4.5 and Gemini 3 Pro Benchmarks Validated
The AI community is intensely focused on the next generation of foundational models, specifically targeting improved reasoning for agentic workflows. Discussions in the Claude and LMArena channels suggest that Opus 4.5, Gemini 3 Pro, and even early whispers of GPT 5.2 are imminent. Practitioners like lumin_09085 claim these models are significantly better at 3D spatial reasoning and complex architecture planning. This is corroborated by @AISafetyVigil who noted that Opus 4.5 reportedly scores 89.4% on the GPQA diamond benchmark, a significant jump from previous iterations. Meanwhile, 1choi2edge notes that Haiku 4.5 is already matching Sonnet 4.1 benchmarks, signaling a massive shift in the cost-to-intelligence ratio, a sentiment echoed by @techexplained who highlighted its 2.5x speed increase for tool-calling tasks.
However, the transition isn't without friction. Some users, such as ______nick, have voiced concerns that early versions of Opus 4.5 feel 'nerfed' compared to expectations, particularly in creative writing depth. Despite this, the consensus remains that these models will serve as the primary backbone for autonomous agents. @model_watcher verified that Gemini 3 Pro features a 2.5M token context window with near-perfect retrieval, while beyond1676 highlights Opus as the superior collaborator for external tool integration and project-level orchestration.
Join the discussion: discord.gg/anthropic
The Great API Deflation: Chinese LLMs Challenge Western Pricing
A significant shift in the economic landscape of AI is underway as Chinese models like Qwen 2.5 and DeepSeek-V3 gain traction among Western firms. Industry analysts like @bindureddy note that DeepSeek-V3 offers performance comparable to GPT-4o at a fraction of the cost, specifically $0.14 per 1M input tokens compared to GPT-4o's $2.50, representing a 20x price advantage. While rosemarywalten reports early enterprise exploration of Qwen for its cost-effectiveness, the broader developer community is pivoting to DeepSeek-V3 for logic-heavy tasks, citing its specialized Mixture-of-Experts (MoE) architecture. TomsHardware highlights that DeepSeek's training efficiency—costing only $5.6 million—is forcing a re-evaluation of the high-margin 'compute-at-all-costs' model favored by US labs.
Join the discussion: discord.gg/lmarena
The Agentic IDE Shift: Claude Code, Cursor, and the Rise of Poly
The battle for agentic dominance is shifting from the IDE to the CLI. While Cursor's Plan Mode is lauded for multi-file orchestration, Claude Code (Anthropic's new CLI) is gaining traction for its raw speed and terminal-native execution. Users like @swyx have noted Claude Code's ability to 'just work' in existing workflows, though gclass19 debates if it offers a significant leap over Cursor's integrated experience. Architectural efficiency is also becoming a priority; the Poly runtime is emerging as a challenger to Electron with carolinlove highlighting its minimal binary footprint. However, the 'vibe coding' phenomenon is facing a reality check as developers like kukunah spent 10 hours debugging AI hallucinations, leading @levelsio to warn against the 'brain rot' of losing deep architectural understanding.
Join the discussion: discord.gg/cursor
Scaling Agentic Workflows: From Sequential Loops to Native Batch Tooling
A critical bottleneck in current workflows is the latency of repeated LLM calls. Developers in the n8n community, led by oi.11, are advocating for a 'use 1 tool N times' approach. This pattern allows an agent to generate a JSON array of actions executed via a local loop, bypassing the need to re-query the LLM for every single step. This is particularly relevant for tasks like archiving 100+ tasks where per-action inference is prohibitively expensive. 3xogsavage suggests that instructing the agent to output structured JSON for batch tool use is the most efficient path forward. Industry implementations of parallel tool calling have shown to reduce execution latency by up to 80% for repetitive data-processing tasks.
Join the discussion: discord.gg/n8n
NVIDIA’s VRAM Expansion: Bridging the Gap for Local 70B+ Models
Local execution of high-parameter models is becoming more viable with reports of NVIDIA's 72GB VRAM professional GPU expansion. While current-gen RTX 5000 Ada cards feature 32GB, the community via TrentBot is buzzing about new tiers designed to handle the 48GB+ requirements of top-tier open-weight models. As @Sytelus points out, VRAM is the 'absolute bottleneck' for local AI. Users in the Ollama channels, such as rhannmah, note that while 7B models are useful for edge tasks, the reasoning capabilities of 100B+ models are necessary for complex agentic workflows.
Join the discussion: discord.gg/localllm
Multi-Database Architectures: Solving Determinism in Agentic RAG
Developers are advancing agentic memory by orchestrating multi-database environments to balance speed and depth. real_bo_xilai highlighted a configuration using DuckDB for analytical processing and SQLite for state persistence. This mirrors industry moves toward GraphRAG to reduce hallucinations. The use of DuckDB specifically allows agents to perform complex SQL aggregations at sub-second speeds. Precision remains a critical bottleneck; real_bo_xilai warns that non-deterministic floating-point math can cause simulation drift over time, prompting a shift toward frameworks like LangGraph for granular state management across 1,000+ iterations.
Join the discussion: discord.gg/anthropic
PromptOps: Scaling Consistency with Structured DESIGN.rst Personas
Advanced AI practitioners are moving toward highly structured 'persona files' rooted in formal documentation. mtecknology has demonstrated the efficacy of using a DESIGN.rst file to define writing rules—such as the CAR (Context, Action, Result) format—for AI agents. This creates a persistent 'brain cache' that ensures the agent adheres to technical standards. Beyond instruction, rhannmah suggests a 'chain-of-prompts' workflow where the model must explain its understanding of the rules before execution, significantly reducing errors in complex tasks.
Join the discussion: discord.gg/ollama
The Rise of 'Drug-Inspired' Prompts and Induced Coherence Decay
A provocative trend has emerged involving 'drug-based' prompts designed to simulate altered states of context retention. As reported on the Perplexity Discord, a service known as Pharmaicy markets prompts like the 'weed prompt,' which instructs the model to allow 5-12% of its recent context to 'softly fade' for creativity. However, @VictorTaelin suggests that while prompts can simulate forgetfulness, they do not physically alter the model's KV cache. Meanwhile, 'Void Mode' experiments lead to fragmentary coherence, which some developers use to explore 'raw' model outputs and bypass safety-aligned system prompts.
Join the discussion: discord.gg/perplexity
HuggingFace Technical Deep-Dive
Hugging Face's smolagents and the shift to Python-driven logic are redefining how we build autonomous systems.
We are witnessing a fundamental pivot in the agentic stack. For the last year, the community has been obsessed with complex JSON-based tool calling and fragile prompt engineering. That era is ending. Today's release of smolagents by Hugging Face isn't just another library; it is a declaration that code is the superior language for agentic reasoning. By allowing agents to write and execute Python instead of wrestling with structured schemas, we are seeing a massive jump in reliability—exemplified by the new state-of-the-art results on the GAIA benchmark. But logic is only half the battle. We are seeing a convergence of 'brains,' such as Nous Research's massive 405B Hermes-3, and 'bodies,' like the Holo1 family for GUI navigation. The infrastructure is maturing simultaneously, with the Model Context Protocol (MCP) and OpenEnv providing the standardized rails these agents need to move beyond sandboxes and into production. For builders, the message is clear: stop over-engineering prompts and start giving your agents a compiler. The future of the Agentic Web isn't just conversational; it is computational.
Hugging Face Launches smolagents: A Code-First Paradigm Shift
Hugging Face has introduced smolagents, a lightweight library designed to simplify the creation of AI agents by using a code-first approach. Unlike traditional frameworks that rely on complex JSON-based tool calling, smolagents allows agents to write and execute Python code snippets directly. This method is described as a more robust way to handle multi-step logic, effectively treating the agent as a programmer rather than a text generator. The release coincides with Transformers Agents 2.0, providing a streamlined engine for autonomous tasks.
Industry comparisons suggest that while frameworks like LangGraph are optimized for stateful, graph-based orchestration, smolagents excels in minimalist implementations where the agent's ability to reason through code reduces verbosity. The framework is remarkably concise, consisting of roughly 1,000 lines of code. To solve the 'black box' problem, Hugging Face has integrated Arize Phoenix for advanced tracing and evaluation, ensuring that developers can monitor the execution of generated code in real-time.
Hermes-3 and the Evolution of Open-Source Reasoning
Nous Research has launched the Hermes-3 family, featuring models ranging from 8B to a massive 405B parameters based on Llama 3.1. As the first full-parameter fine-tune of the Llama 3.1 405B base, Hermes-3 is specifically optimized for agentic capabilities. It utilizes a specialized dataset mixture that emphasizes function calling, multi-turn planning, and roleplay within a 128k context window.
In specialized domains, the Kimina-Prover utilizes test-time RL search to enhance formal mathematical reasoning, providing a blueprint for agents that require extended computation time to verify proofs. This is further complemented by ServiceNow's Apriel-H1, which introduces adaptive reasoning techniques to improve the efficiency of agentic decision-making processes, proving that 'scaling law' logic is now being applied to the reasoning process itself.
The Rise of GUI Agents: Benchmarking Holo1 and ScreenSuite
The landscape of autonomous computer use is shifting rapidly with the release of Smol2Operator and the Holo1 family of vision-language models. Developed for high-precision GUI navigation, Holo1 powers Surfer-H, an agent capable of executing complex workflows across desktop and web interfaces. According to technical reports from Hcompany, Holo1 models utilize specialized vision-action tuning to reduce execution errors.
In the newly released ScreenSuite benchmark, Holo1-7B has demonstrated a Success Rate (SR) of approximately 42.1% across diverse OS tasks, setting a new open-source standard. This benchmark provides a comprehensive environment containing over 3,500 tasks. Industry experts such as @vic_dyu highlight that these agents are moving beyond simple click-prediction toward full semantic understanding of UI hierarchies, significantly outperforming previous baselines.
Beating GAIA with Code-Centric Reasoning
Hugging Face’s Transformers Code Agent has redefined the state-of-the-art on the GAIA (General AI Assistants) benchmark. By using code for logic and tool calls, the agent achieved a score of 40% on the GAIA validation set, significantly outperforming traditional LLM-based reasoning methods. As noted by @m_funtowicz, this shift emphasizes that agents are effectively programs capable of executing complex workflows.
Beyond general tasks, specialized benchmarks are emerging to address specific reasoning gaps. DABStep focuses on multi-step data reasoning, while FutureBench tests an agent's predictive capabilities. These evaluations are critical as the industry moves toward autonomous agents capable of long-horizon planning and precise tool execution.
Standardizing the Agentic Web: OpenEnv, MCP, and Tiny Agents
Efficiency and interoperability are the new priorities. Tiny Agents have demonstrated that robust workflows can be implemented in fewer than 50 lines of code. This minimalist approach is supercharged by the Model Context Protocol (MCP), a universal connector for tools and data. Azenko has released functiongemma-270m-it-mobile-actions, a 270M parameter model optimized for low-latency, on-device interactions.
Simultaneously, OpenEnv addresses the 'environment bottleneck' by providing a standardized interface for agents to interact with Linux, Windows, and web applications via Docker-based sandboxing. Parallel to this, IBM Research's CUGA framework introduces a modular architecture that allows developers to define agent behaviors using YAML configuration files, creating an interoperable infrastructure for the next generation of builders.