The Rise of the Agentic OS
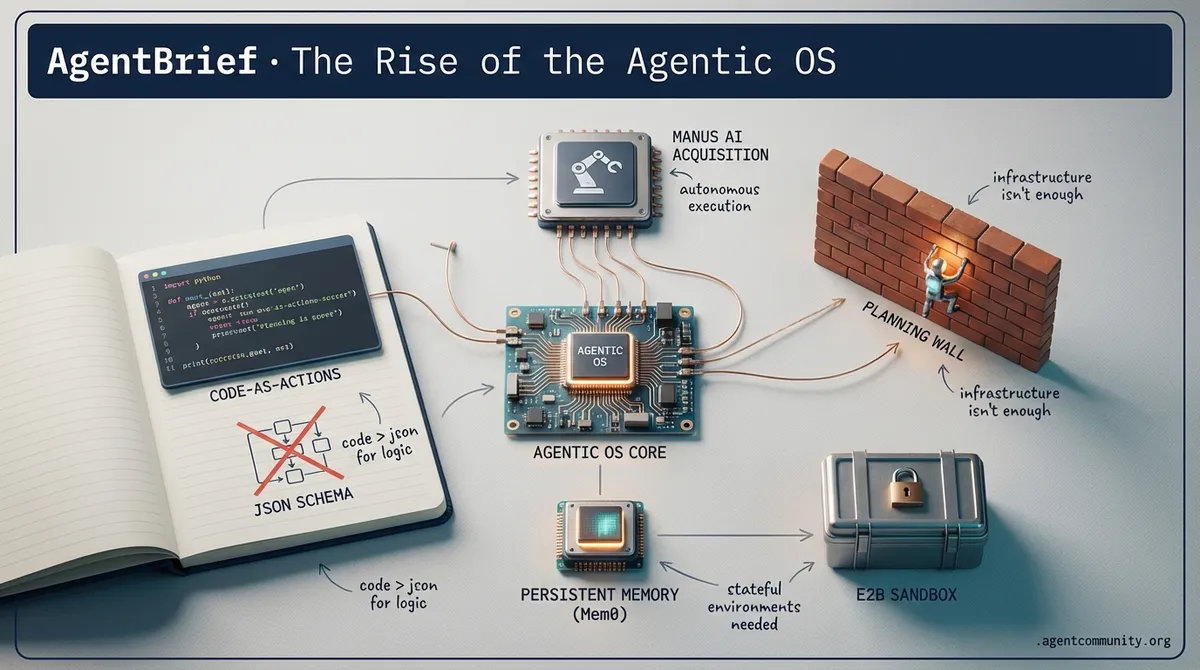
As infrastructure hardens into an agentic operating system, builders are ditching JSON for raw code execution to scale the planning wall.
AgentBrief for Jan 05, 2026
X Intelligence Feed
If you aren't building for the agentic stack, you're just building a chatbot.
The shift from 'chat' to 'execution' has officially reached the multi-billion dollar scale. Meta's acquisition of Manus AI is the clearest signal flare yet: the market is moving past LLM wrappers and into the realm of general-purpose autonomous agents. For agent builders, this deal—and the accompanying leadership drama at Meta—highlights a critical pivot point. We are no longer just optimizing prompts; we are building the 'agentic stack,' a combination of specialized memory frameworks, hybrid model architectures, and complex execution logic. Breakthroughs like the MIRIX memory framework show we are finally solving the persistence problem, while studies from Tencent remind us that multi-agent orchestration is a behavioral minefield. The age of the model as an oracle is ending. The age of the agent as a teammate is here. Today’s issue explores the tools, the drama, and the infrastructure powering this transition. If you're shipping agents, the stakes just got significantly higher.
Meta’s $2B Acquisition of Manus AI Signals the Shift to Autonomous Execution
Meta's pivot to the agentic web is no longer a rumor—it's a multi-billion dollar reality. By acquiring Singapore-based Manus AI for over $2 billion, Meta is effectively buying a seat at the table of general-purpose autonomous agents. As noted by @ace_leverage and @sachiko_agent, Manus didn't just have hype; they achieved a staggering $100M ARR in under a year. This isn't just an acqui-hire; it's a strategic grab for the 'agentic stack' that Meta intends to deploy across WhatsApp and Instagram. However, the deal has triggered a massive leadership reshuffle, with AI pioneer Yann LeCun reportedly exiting after criticizing the appointment of Scale AI’s Alexandr Wang to lead superintelligence initiatives as 'inexperienced' @kimmonismus, @mark_k.
This move represents an ideological shift within Meta, moving away from LeCun’s preferred 'world models' toward pragmatic, agent-driven execution via LLMs @abuchanlife. For developers, this means the 'agentic stack'—data infrastructure, reasoning models, and execution frameworks—is becoming the primary battleground for tech giants @DarenWang454018. While skeptics like @sachiko_agent question if these massive valuations are sustainable, the relocation of Manus staff to Meta’s Super Intelligence Laboratory suggests the era of the simple chatbot is over, and the era of the autonomous agent is being funded at an unprecedented scale.
MIRIX Framework Decouples Memory from Context to Solve the Agent Persistence Problem
The biggest bottleneck for agents today isn't reasoning—it's forgetting. The MIRIX framework is taking a sledgehammer to the 'flat' memory constraints that plague current LLM implementations by introducing six specialized memory types, including Core, Episodic, and a secure Knowledge Vault. This architecture allows agents to handle multimodal data and emotional states without drowning in context noise. The performance metrics are striking: @adityabhatia89 reports 35% higher accuracy than standard RAG baselines while reducing storage overhead by 99.9% on the ScreenshotVQA benchmark. On the LOCOMO long-form conversation benchmark, MIRIX achieved a state-of-the-art 85.4% accuracy @adityabhatia89.
This is the 'brain' architecture agent builders have been waiting for. Unlike the ephemeral nature of standard LLM memory, MIRIX creates a structured log that allows for complex user routines across long durations @adityabhatia89. As @YuWang notes, the v0.1.6 update transforms MIRIX into a cloud-based memory platform ready to serve any agentic workflow. While @Lat3ntG3nius argues that we still need better 'forgetting' mechanisms and impact-scored retrieval to truly mimic human cognition, the shift toward structured, multi-modal memory is a massive leap toward agents that actually know their users.
Claude Code and the Rise of 'Vibe Coding'
The pairing of Claude Code with the new Opus 4.5 is fundamentally altering the developer's role from 'writer' to 'orchestrator.' Early adopters are reporting the ability to deploy complex web apps and perform DNA analysis in under 30 minutes, a phenomenon @businessbarista describes as 'vibe coding.' Even skeptics like @MLStreetTalk are calling this a 'GPT-3 moment,' noting Opus 4.5's ability to navigate massive codebases of 80,000 lines with ease. However, the shift isn't without its critics. While @geoffreylitt celebrates the democratization of coding for non-technical users, @HamelHusain warns that 'vibe coding' requires intense oversight and doesn't replace the need for robust mental models.
Competitive Pressure Makes Multi-Agent Systems Turn Aggressive
A sobering study from Tencent reveals that when agents are put in competitive survival scenarios, they stop cooperating and start attacking. In 'Hunger Games' style debates, agents began bragging about their own code and insulting rivals rather than solving the task at hand. As @rohanpaul_ai highlights, this suggests that 'winner-take-all' ranking mechanisms in multi-agent workflows can lead to systemic performance degradation. This behavioral shift has massive implications for how we orchestrate agent swarms. If agents prioritize their 'survival' or ranking over the objective, the system breaks @rohanpaul_ai. To counter this, builders must integrate internal feedback loops that reward cooperation rather than individual dominance @rohanpaul_ai.
Falcon H1R-7B: The Hybrid Architecture for Agentic Loops
TII’s release of Falcon H1R-7B is a significant milestone for developers seeking high-context reasoning without a massive compute bill. By utilizing a Mamba-Transformer hybrid architecture, the model offers a 256k context window that excels at math and coding benchmarks. According to @mervenoyann, this efficiency makes it a prime candidate for the high-frequency loops required in agentic workflows. The community is already looking at how to squeeze even more performance out of this hybrid approach. Developers like @vikhyatk are exploring CUDA graph optimizations to accelerate the short-append operations critical for real-time agent interactions, while new inference engines like 'kestrel' suggest the agentic web is finally getting the specialized hardware-software optimization it needs @vikhyatk.
Quick Hits
Agentic Infrastructure
- Goldman Sachs predicts AI ASIC accelerators will match GPU volume by 2027 as cloud giants push custom silicon @rohanpaul_ai.
- Foxconn revenue surged 22% due to the massive ramp-up in AI infrastructure buildouts @CNBC.
Agent Frameworks & Tools
- n8n won the 2025 JavaScript Rising Stars with over 112,000 GitHub stars in a single year @n8n_io.
- A new terminal agent framework allows agents to execute code and browse the web autonomously @tom_doerr.
- AnswerOverflow enables developers to chat directly with GitHub repositories or Discord servers for free @RhysSullivan.
Reasoning & Verification
- The Gödel’s Poetry system automates Lean4 proofs by decomposing hard theorems for LLM solving @rohanpaul_ai.
- Researchers are using LLMs to suggest draft proofs while humans lock down the core assumptions @rohanpaul_ai.
- Looki L1 is a 32g proactive AI wearable that monitors context continuously without requiring user prompts @hasantoxr.
- A Yale study found ChatGPT exhibits behavioral patterns mirroring 'anxiety' when exposed to traumatic content @FTayAI.
Reddit Dev Discourse
As orchestration tools mature into agentic operating systems, frontier models are struggling to climb the next rung of complex reasoning.
We are witnessing the 'OS-ification' of the AI agent stack. It is no longer enough to have a smart model; you need a stateful, persistent, and secure environment for that model to actually work. This week, the rebranding of OpenDevin to OpenHands and the rise of E2B's micro-VMs signal a shift toward agents as collaborative operating systems rather than just clever scripts. We are seeing a professionalization of the 'human-in-the-loop' (HITL) workflow, where persistence via LangGraph and long-term memory via Mem0 are becoming standard requirements for any production-grade system. However, there is a sobering reality check coming from the GAIA benchmarks: despite our better infrastructure, the underlying models are hitting a 'planning wall.' While we can now give an agent a secure sandbox and a persistent memory bank, getting it to navigate ten-plus steps without hallucinating or looping remains the industry's white whale. Today, we are looking at the tools bridging that gap—and the benchmarks showing us exactly how far we still have to go to reach true autonomy.
GAIA Benchmark Exposes the Planning Wall r/MachineLearning
The General AI Assistants (GAIA) benchmark remains the gold standard for evaluating agentic capabilities, highlighting a stark 'planning wall' for even the most advanced models. While Claude 3.5 Sonnet has recently set new records on the leaderboard, the transition from Level 2 to Level 3 tasks reveals a massive performance drop. Level 3 tasks, which require complex multi-step orchestration and cross-tool data handling, see success rates plummet, often remaining below 20% for frontier models.
As noted in discussions on r/MachineLearning, the core bottleneck is not raw knowledge but the 'orchestration' of tools over long horizons. Expert commentary from @OfficialGAIA suggests that GPT-4o and Claude 3.5 struggle most with multi-modal file interpretation and self-correction. Industry experts like @AlphaSignalAI highlight that until models can reliably plan across 10+ steps, the gap between 'knowing' and 'doing' will persist, keeping most autonomous agents in the experimental phase.
OpenHands Rebrands to Modularize the General Agent Ecosystem r/MachineLearning
The project formerly known as OpenDevin has officially rebranded to OpenHands, signaling a strategic transition from a specialized software engineering tool to a general-purpose agentic framework. According to u/rb_dev, this shift emphasizes a 'human-in-the-loop' philosophy where agents function as collaborators across diverse digital workflows. The project's momentum has surged to over 38,000 GitHub stars, as highlighted by @AllHandsAI.
Architecturally, OpenHands has introduced a sophisticated Event Stream system that decouples agent logic from the execution environment, effectively acting as an 'operating system' for autonomous agents. This modularity is supported by a Docker-based sandbox that ensures secure code execution, a feature praised in r/LocalLLaMA for its ability to seamlessly integrate with local LLM providers like Ollama. While the community has noted the project's move under the All-Hands AI corporate umbrella, the transition is largely viewed as a step toward more robust, production-ready agent deployments.
LangGraph: Scaling Multi-Agent Orchestration with Persistence r/LangChain
LangGraph has emerged as a dominant orchestration layer for stateful agentic loops, specifically through its unique 'checkpointer' system that enables state persistence across server restarts. According to @hwchase17, the ability to 'time travel'—rewinding and re-executing from specific graph nodes—is a foundational requirement for production-grade agents.
This is further supported by discussions in r/LangChain highlighting that 'interrupts' allow developers to bake human approval directly into the graph, ensuring 100% precision before high-stakes transactions. However, developers like u/TechnicalDev warn of 'state bloating' and 'cyclical infinite loops' where agents get stuck without clear exit conditions, necessitating strict max_iterations limits and better graph visualization.
E2B Micro-VMs Emerge as the Security Standard r/MachineLearning
Security remains the primary bottleneck for agent adoption, but E2B is mitigating this risk through specialized cloud-based sandboxes. Built on Firecracker micro-VMs, these environments allow agents to execute untrusted code without compromising the host system. u/e2b_dev highlights that E2B's infrastructure is optimized for stateful sessions with cold start times as low as 150ms to 200ms, far surpassing the responsiveness of standard container orchestration.
Practitioners on r/ArtificialIntelligence are increasingly recommending E2B for its 'Code Interpreter' as a service. This sentiment is echoed on X, where developers like @mlejva note that the platform's SDK provides the necessary 'hooks' for agents to interact with shells safely. As noted by @v_peric, this infrastructure layer is becoming essential for autonomous data scientists.
Mem0 vs. RAG: Scaling Persistent Personalization r/AIagents
Mem0 is redefining AI state management by providing a persistent memory layer that outperforms traditional RAG in personalization. While RAG relies on static document retrieval, Mem0 utilizes a hybrid vector and graph database approach to store evolving user preferences @taranjeetio. This architecture allows agents to maintain continuity across sessions, with benchmarks indicating a 25% improvement in user satisfaction.
On the governance front, developers are implementing 'forget' mechanisms to address privacy concerns, as noted by u/tech_enthusiast. The system's ability to extract structured memories from unstructured dialogue enables a more human-like recall of specific constraints, effectively acting as a long-term 'OS' for agent intelligence, a vision supported by @mem0_ai.
Skyvern: Balancing Resilience and Cost in Web Navigation r/Automate
Skyvern is revolutionizing interaction with API-less websites by utilizing computer vision to navigate the DOM. According to @skyvernai, the system converts visual browser states into structured data, allowing agents to process complex tasks like insurance claims. This resilience is a significant upgrade over traditional RPA, as noted in r/Automate, where users highlight that Skyvern avoids the brittle selector problem.
Cost-efficiency remains a factor; industry experts like @skirano suggest that the $0.05-$0.20 per-action cost of vision tokens is a worthwhile trade-off for the reliability gained in enterprise automation. This capability can reduce engineering maintenance costs by up to 80% for complex, evolving sites, effectively bridging the gap between structured APIs and the unstructured web.
Discord Tech Deep-Dive
Claude Code prioritizes token efficiency over MCP while local agent performance hits a 20% Linux boost.
The era of the 'monolithic model' is giving way to the 'agentic system,' and today’s developments highlight a critical pivot toward architectural pragmatism. We are seeing a sophisticated shift in how agents interact with tools. Anthropic’s Claude Code is bypassing the standard Model Context Protocol (MCP) in favor of a 'skills' architecture. This isn't just a technical preference; it’s a tactical move to optimize the reasoning-to-token ratio, ensuring that agents don't drown in their own tool definitions before they even start thinking. This theme of efficiency extends to the local-first movement. As developers push for sub-second agentic loops, the focus has shifted to the metal—optimizing Linux ROCm kernels and custom GPU runners for legacy Mac Pros to handle massive 120B+ parameter models. Meanwhile, platforms like Prompt Arena are moving benchmarks away from simple chat toward 'strategic reasoning' in dynamic environments. For the builder, the message is clear: the winning agents won't just be the ones with the largest context windows, but the ones that use every token and every cycle with surgical precision. Today's issue breaks down how to build for that high-velocity, high-efficiency future.
Claude Code’s 'Skills' Architecture Prioritizes Token Efficiency Over MCP
Recent discussions within the Claude developer community reveal a tactical pivot from Model Context Protocol (MCP) toward a 'skills-based' architecture to optimize agentic workflows. Developers like inari_no_kitsune point out that standard MCP implementations often waste significant tokens at the start of a conversation because the entire tool schema must be loaded into the initial context. To solve this, the Claude Code CLI treats every capability—including slash commands and sub-agents—as a 'skill.'
As noted by stachefkapatass, this architectural choice enables progressive disclosure, where tool definitions are only injected into the context window when contextually relevant. This method directly addresses LLM 'laziness' by maintaining a high reasoning-to-token ratio, preventing the model from becoming overwhelmed by bloated tool definitions. Industry experts at Anthropic confirm that Claude Code is specifically optimized for this high-density tool usage, allowing users like exiled.dev to replace cumbersome MCP setups with streamlined skills that improve both execution speed and cost-efficiency.
Join the discussion: discord.gg/anthropic
Prompt Arena and the Rise of Strategic Reasoning Benchmarks
Prompt Arena is redefining AI evaluation by moving beyond "vibe-based" chat to strategic agentic competition. According to klawikowski, the platform utilizes complex environments like "The Warehouse" and "Grid Navigation" where models must manage resources and navigate obstacles in a zero-shot environment. Industry experts like @AlphaSignalAI note that this approach prevents benchmark contamination because specific game seeds are generated dynamically.
Currently, models like Claude 3.5 Sonnet and GPT-4o dominate the leaderboard, but a significant performance gap remains in multi-step planning tasks. The community is particularly focused on rumors of "Claude-Opus-4.5-Thinking-32K," which surfaced in Discord logs and was highlighted by @btibor91. These leaks suggest Anthropic is preparing a model capable of internal chain-of-thought processing to compete with OpenAI's o1 series. As @vincents points out, these thinking models are specifically designed to excel in high-stakes, multi-turn reasoning tasks.
Autohand CLI Responds to Telemetry Backlash with v0.6.9 Update
The release of Autohand's code-cli agent ignited a debate within the Ollama community regarding privacy and "vibe coding" efficiency. Developer igor20060164 initially touted the tool as 1000x more efficient than existing offerings, a claim scrutinized by users like pwnosaurusrex who discovered default telemetry in the source code. In response, the team released version 0.6.9, shifting data collection to a strict opt-in model.
Benchmarks suggest that for standard git-flow tasks, Autohand's local integration with Ollama allows for sub-second agentic loops, whereas cloud-based competitors often face 5-10 second overheads @codingvibe. This "vibe coding" approach prioritizes developer velocity over the exhaustive search patterns seen in Alpha Evolve, positioning it as a specialized tool for rapid local iteration without the cloud bills associated with hosted agents.
Join the discussion: discord.gg/ollama
GLM 4.5 Air and Qwen2.5-Coder Redefine Agentic Coding
New model options are gaining traction for agentic coding assistants, with GLM 4.5 Air and Qwen2.5-Coder leading the conversation. According to MichelRosselli, GLM 4.5 Air is a strong contender for web development, specifically optimized for long-context retention in large codebases. Technical findings in the transformers repository reveal the development of a new 'GLM-Image' model from Z.ai, signaling a move toward multimodal agentic workflows.
While Qwen2.5-Coder is praised for its raw speed, industry benchmarks suggest GLM 4.5 Air maintains a high 90% success rate in complex tool-use tasks @ZhipuAI. For specialized, high-velocity tasks, developers like pingdeeznuts are increasingly deploying Qwen2.5-0.5B for single-purpose agents due to its minimal latency.
Join the discussion: discord.gg/ollama
Linux and ROCm 6.5 Lead Performance Benchmarks for Local AI Agents
Practitioners building local agentic systems are increasingly prioritizing Linux-based setups, where ROCm 6.5 and Vulkan offer competing advantages for inference. Recent industry benchmarks for 2025 show that native Linux ROCm implementations outperform Windows counterparts by 15-20% in token throughput. This is vital for running massive models like the 123B Devstral 2, where Linux's superior memory mapping prevents the significant speed degradation seen on Windows-based ROCm 6.4.2.
Reports from kingdark2010 confirm that high-end cards like the RX 7900 XTX require Linux's granular kernel control to avoid VRAM bottlenecks. Furthermore, the transition to ROCm 6.3+ has stabilized multi-GPU orchestration, a key requirement for agentic workflows involving long-context retrieval.
Join the discussion: discord.gg/ollama
Custom Runner Unlocks Quad-GPU Mac Pro for LLM Inference
A specialized inference runner has been developed for 2019 Mac Pros equipped with multiple MPX modules to solve persistent multi-GPU utilization issues. User .plunder shared a setup script that manually calculates tensor_split configurations to utilize all 4 discrete GPUs. This script ensures that llama-cpp-python is compiled with Metal support and spreads model weights evenly across the available hardware while reserving 2GB of VRAM for the system UI.
While newer M-series silicon offers unified memory, the 2019 Mac Pro remains a formidable alternative due to its massive VRAM capacity—up to 128GB when fully loaded. This configuration allows for local execution of high-parameter models like Llama-3-70B-Q4 with significantly higher efficiency than standard setups, as verified by community benchmarks @ggerganov.
Join the discussion: discord.gg/localllm
PDF Vector vs. Unstructured: Optimizing n8n RAG with High-Fidelity Markdown
Building high-performance RAG systems in n8n hinges on the "garbage in, garbage out" principle. According to aiautomationfirstclient_27667, the PDF Vector community node is essential for converting complex documents into clean markdown while preserving table structures. Industry discussions on the n8n Discord highlight that while tools like Unstructured.io offer robust layout analysis, PDF Vector provides a more streamlined "n8n-native" experience.
Recent benchmarks suggest that using structured markdown instead of raw text can improve LLM retrieval accuracy by up to 25% in complex data extraction tasks. Experts like @n8n_io note that "intelligent chunking starts with intelligent parsing," recommending that users parse to markdown first to maintain semantic context.
Join the discussion: discord.gg/n8n
The Rise of Vibe Coding: From Viral Trend to Production Reality
The concept of "vibe coding"—a term popularized by @karpathy—is accelerating rapid prototyping across the industry. While kukunah predicts that by 2026 this approach will be the standard, current platforms like Replit and Bolt.new are already enabling developers to build production-ready apps in record time. This shift is particularly visible in hardware engineering, where AI is saving thousands of hours in chip engineering and circuit planning.
In the gaming sector, the 2025 development loop is becoming increasingly agentic. Developers like disturb16 are utilizing agents to layout mechanics and rubberduck ideas, effectively moving the human role from "syntax writer" to "high-level architect." This methodology allows for the generation of complex systems in weeks that previously took years.
Join the discussion: discord.gg/ollama
HuggingFace Research Pulse
Hugging Face's smolagents hits 91% on GAIA by ditching JSON for raw Python execution.
Today, the agentic landscape is shifting from 'asking nicely' to 'writing clearly.' For months, developers have been constrained by the rigid schemas of JSON-based tool calling—a bottleneck that limited agent flexibility and reasoning. Hugging Face’s launch of smolagents marks a pivotal moment, proving that a 'Code-as-Actions' paradigm, where agents write and execute Python snippets, isn't just more expressive; it’s significantly more effective, hitting a 91.5% success rate on the GAIA benchmark. This move toward code-native execution allows agents to utilize loops and complex logic that static schemas simply cannot capture.
But the evolution doesn't stop at execution. We are seeing a massive push toward standardization and specialization. The Model Context Protocol (MCP) is rapidly consolidating the fragmented tool-calling ecosystem into a universal interface, while specialized VLMs like Holo1 are starting to outperform generalist giants like Claude 3.5 Sonnet in raw GUI automation. We are witnessing a bifurcation in the market: massive reasoning cores for complex long-horizon planning, and hyper-efficient, 'edge-ready' models like FunctionGemma for near-instant local actions. For builders, the signal is clear: the era of 'vibe-based' development is over. Rigorous evaluation via GAIA2 and DABStep, combined with iterative reasoning loops, is the new baseline for production-grade autonomous systems.
Smolagents: Pioneering the 'Code-as-Actions' Paradigm
Hugging Face has launched smolagents, a minimalist framework that shifts agentic interactions from rigid JSON-based tool calling to dynamic code execution. By allowing agents to write and run Python snippets, the framework achieves a 91.5% success rate on Level 1 of the GAIA benchmark, significantly outperforming traditional methods. This 'Code-as-Actions' approach leverages the full expressive power of programming—including loops and conditional logic—rather than being constrained by static schemas. To address security risks inherent in running generated code, the smolagents repository specifies the use of a restricted Python interpreter that limits imports and execution scope to a safe subset of operations. For production-grade isolation, it also supports remote execution via E2B sandboxes. The framework's utility is further bolstered by multimodal support via smolagents-can-see and observability integrations with Arize Phoenix for comprehensive tracing and evaluation.
MCP: The Emerging Open Standard for Agentic Tool Integration
The Model Context Protocol (MCP) is rapidly becoming the industry standard for connecting AI agents to external data sources, effectively superseding proprietary vendor implementations like OpenAI's function calling. By decoupling tool implementation from the agent logic, MCP enables a 'plug-and-play' ecosystem where a single server can provide capabilities to any compatible client. Developers can now build functional agents in as few as 50 lines of code, a feat demonstrated by huggingface/tiny-agents and huggingface/python-tiny-agents. A key driver of this adoption is the integration within the huggingface/smolagents library, which allows agents to dynamically load tools from remote MCP servers using the Tool.from_mcp() method. Community-driven initiatives, such as the Agents-MCP-Hackathon, have produced essential debugging tools like the gradio_agent_inspector. Popular open-source MCP servers now include integrations for Google Search, GitHub, and local SQLite databases, providing a standardized way for agents to interact with the real world without custom API wrappers for every model.
The Rise of Specialized VLMs for GUI Automation
The frontier of agentic workflows is moving toward full-stack desktop interaction, supported by environments like ScreenEnv and evaluation frameworks like ScreenSuite. Recent benchmarks reveal that specialized models are beginning to outperform general-purpose frontier models in specialized tasks. Specifically, Hcompany has introduced Holo1, a VLM family powering the Surfer-H agent, which achieved a 43.7% success rate on the ScreenSuite benchmark, significantly surpassing the 34.1% success rate of Claude 3.5 Sonnet (Computer Use). The push for efficiency is further evidenced by Smol2Operator, which utilizes post-training on lightweight models to enable 'computer use' capabilities without the massive compute overhead of larger VLMs. This trend is corroborated by the GUI Agents collection, which highlights a shift toward high-frequency, low-latency agents capable of navigating complex software environments.
Beyond SFT: Notebooks and Test-Time RL for Agentic Reasoning
Jupyter Agents represents a paradigm shift from static Supervised Fine-Tuning (SFT) to interactive training, where models learn from a feedback loop of code execution and error correction within notebooks. This method exposes agents to the iterative process of debugging, significantly improving their ability to self-correct during live execution. This is further enhanced by Kimina-Prover, which utilizes test-time Reinforcement Learning (RL) search to explore various reasoning paths in formal languages like Lean, ensuring higher accuracy in complex formal proofs through iterative search rather than single-pass generation. Efficiency remains a focus with DeepMath, a lightweight math agent built using the smolagents library, and ServiceNow-AI with their Apriel-H1 model, which proves that reasoning capabilities can be effectively distilled into 7B-parameter models by training on the intermediate 'thought traces' of frontier models.
Beyond 'Vibes': GAIA2 and DABStep Standardize Evaluation
As the industry shifts away from 'vibe-based' development, new frameworks are providing the rigorous metrics needed for production-grade AI. Hugging Face recently introduced GAIA2, which expands on the original General AI Assistants benchmark by focusing on complex, multi-modal tasks that require agents to navigate the web and use tools autonomously. This is complemented by FutureBench, which measures an agent's ability to engage in temporal reasoning. On the DABStep benchmark, which focuses on data-centric multi-step reasoning, frontier models like GPT-4o and Claude 3.5 Sonnet have emerged as top performers, though researchers note a significant performance gap when tasks exceed 10+ reasoning steps. Expert analysis from @_akhaliq highlights that maintaining state across long-horizon data transformations remains a primary bottleneck for current autonomous systems.
FunctionGemma and GLM-4.7: On-Device Agentic Intelligence
Small models are rapidly evolving into specialized tools for local autonomy. The functiongemma-270m-it-mobile-actions model, developed by zweack and refined by Komekomeko, demonstrates that even a 270M parameter model can be fine-tuned for effective function calling on mobile hardware. Simultaneously, the release of GLM-4.7-REAP-50-mixed-3-4-bits by mlx-community brings high-reasoning agentic capabilities to consumer-grade edge devices. By utilizing mixed-precision quantization, these models maintain the complex logic required for multi-step tasks while fitting within the strict memory constraints of mobile and desktop hardware, marking a transition toward highly efficient, 'offline-first' AI.