The Agentic Operating System Era
Stop building chatbots and start building systems as agents evolve toward code-centric architectures and stateful filesystems.
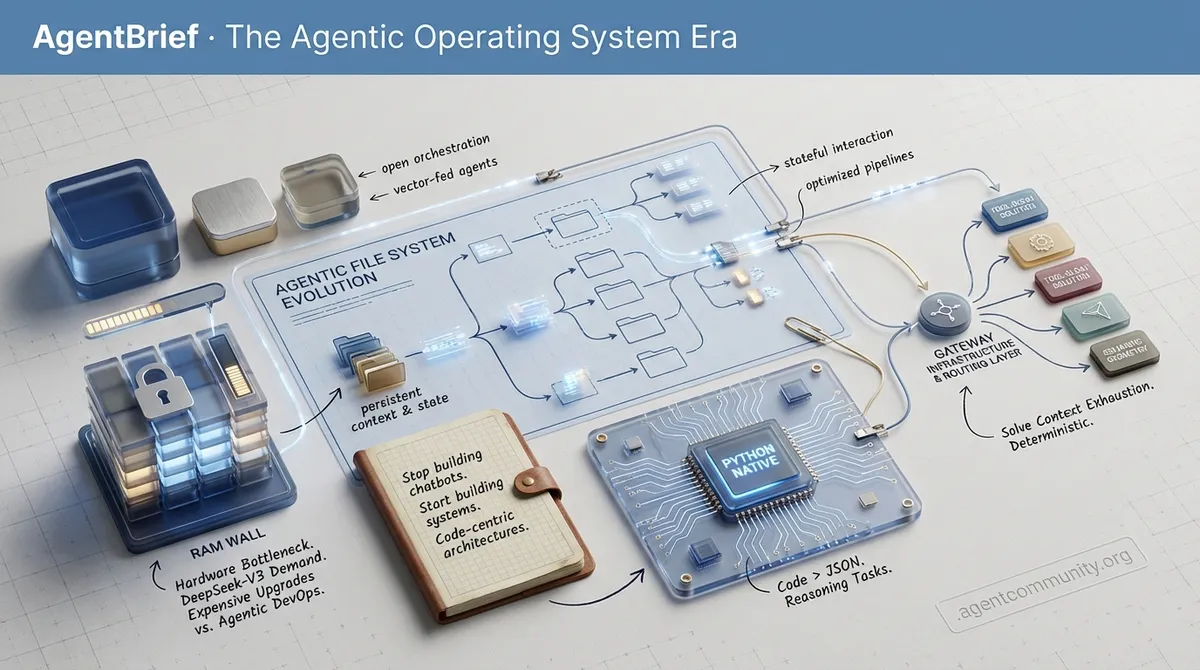
Architectural Shifts Beyond simple text prompts, the industry is moving toward "agentic filesystems" and persistent sandboxes, treating AI as an operating system rather than a stateless chat interface. > Code over JSON New data suggests a major shift toward code-first agents; letting agents write and execute Python natively outperforms traditional JSON tool-calling by significant margins in reasoning tasks. > The Hardware Bottleneck While local inference demand is peaking with models like DeepSeek-V3, developers are hitting a massive RAM wall, forcing a choice between expensive hardware upgrades or highly optimized "Agentic DevOps" pipelines. > Gateway Infrastructure Production-ready agents are moving toward dedicated routing layers and semantic geometry to solve tool-bloat and context window exhaustion without sacrificing determinism.
AgentBrief for Jan 06, 2026
Architectural Shifts Beyond simple text prompts, the industry is moving toward "agentic filesystems" and persistent sandboxes, treating AI as an operating system rather than a stateless chat interface. Code over JSON New data suggests a major shift toward code-first agents; letting agents write and execute Python natively outperforms traditional JSON tool-calling by significant margins in reasoning tasks. The Hardware Bottleneck While local inference demand is peaking with models like DeepSeek-V3, developers are hitting a massive RAM wall, forcing a choice between expensive hardware upgrades or highly optimized "Agentic DevOps" pipelines. Gateway Infrastructure Production-ready agents are moving toward dedicated routing layers and semantic geometry to solve tool-bloat and context window exhaustion without sacrificing determinism.
The X Threadstream
Stop dumping text into context windows; start mounting workspaces for your agents.
We are moving past the "chatbot" era and into the "operating system" era of AI. The shift from stateless prompts to stateful, agentic file systems is the architectural foundation we've been missing. It’s no longer about how well an LLM can guess the next token; it’s about how an agent manages its environment, interacts with persistent storage, and manipulates physical or virtual tools. Whether it’s NVIDIA’s NitroGen learning to play games from pixels or Boston Dynamics putting a high-torque electric worker on the factory floor, the theme is clear: agents are gaining agency through better context and better bodies. For those of us shipping today, the challenge isn't just picking a model—it's building the plumbing that allows that model to act reliably over long horizons. If your agent doesn't have a filesystem, a sandbox, and a way to prove its work, it's just a demo. Today's issue dives into the infrastructure—hardware and software—that makes the agentic web a production reality for developers who are tired of building toys and ready to build systems.
Context Management Evolves into Agentic File Systems
The architectural meta is shifting. We're seeing a move away from fragmented vector databases toward unified agentic file systems. As @rohanpaul_ai argues, integrating memory, tool outputs, and human feedback as files within a shared workspace is the key to separating raw history from long-term logic. This isn't just storage; it’s a shared workspace for persistent context, a sentiment echoed by @LangChain. By treating context as a filesystem, we solve the 'slop thinking' problem—a term @deliprao uses to describe the fuzzy, inefficient code generation resulting from poor specs.
Safety and virtualization are the next hurdles. @JerryLiu0 points out that virtualizing these systems (like AgentFS) prevents agents from nuking actual production environments while they "think." This is more than just sandboxing; it's about reducing context rot and optimizing token usage, as @CloudAI-X highlights. We're seeing this manifest in real projects like Turso's AgentFS, which @itsclelia and @tursodatabase are already integrating into secure agentic workflows.
Electric Atlas Enters Production for Industrial Agent Deployment
Humanoid agents are leaving the lab. Boston Dynamics just announced the immediate production of the electric Atlas, a machine designed specifically for fenceless, real-world industrial interaction. According to @chatgpt21, this isn't just a prototype; it's a production-grade worker with a 4-hour battery life and a massive 110-pound (50 kg) lift capacity. @SawyerMerritt notes that its operating range of -4°F to 104°F makes it a viable candidate for the grittiest factory floors.
The deployment pipeline is already full. Hyundai and Google DeepMind are the first in line, with @rohanpaul_ai confirming fleets are shipping to specialized metaplants soon. This hardware isn't just "dumb" robotics; it boasts 56 degrees of freedom, allowing for precise parts sequencing, as @XRoboHub reports. For the agent builder, the most impressive feature might be the autonomy: @yaelkroy highlights Atlas’s ability to walk itself to a charger and swap batteries, ensuring continuous uptime without human intervention. Commercial rollouts are slated to scale through 2027, per @NorbertRoettger.
NVIDIA NitroGen: Training Action Models from Raw Pixels
NVIDIA has just commoditized the data bottleneck for embodied AI. Their new NitroGen model is an open-source vision-action foundation trained on 40,000 hours of gameplay across 1,000+ titles. As @hasantoxr explains, NitroGen learns directly from pixels and controller inputs, bypassing the need for internal game states. This turns the entire internet of streaming video into a training set for autonomous agents, a massive win for scalability noted by @heysajib.
The technical stack is sophisticated, utilizing SigLIP-2 for vision and diffusion transformers for action modeling to filter out noisy human demonstrations. @hasantoxr notes this handles imperfect data better than traditional policies. Furthermore, NVIDIA released a universal simulator that wraps Windows games in a Gymnasium-compatible interface, as highlighted by @hasantoxr and @jiqizhixin. We're looking at a future where agents handle complex quests and resource collection autonomously, potentially redefining player-AI interaction, as @JVCom suggests.
Claude Code and the Agentic IDE Shift
The release of Claude Code with Opus 4.5 is forcing a rethink of the "maintainable codebase." @burkov suggests that agentic systems can now simply rewrite messy code from scratch based on unit tests, making technical debt a solved problem. This isn't just theory; @samhogan reports a 100% success rate in automating complex OAuth flows for Slack and Gmail.
However, the experience isn't uniform. @samhogan notes a distinct performance gap between Opus and Sonnet, while @burkov observes that full rewrites will likely be reserved for critical economic junctures rather than every commit. This points to a new "version-increment" model for AI-driven development.
New Evals Target Long-Horizon Orchestration
We are finally moving past simple Q&A evals. @SakanaAILabs introduced ALE-Bench at NeurIPS, focusing on long-horizon algorithm engineering for NP-hard logistics problems. Their ALE-Agent recently beat 800 humans in a coding contest, proving these models can handle sustained, objective-driven tasks @SakanaAILabs.
Multi-agent cooperation is also getting its own yardstick. @darrenangle launched 'Escape Room,' a framework that forces agents to collaborate on nested subproblems. While exciting, @darrenangle warns that current harnesses still struggle with high-level abstraction, reminding us that orchestration is still in its early phase.
NVIDIA Vera Rubin Boosts Agentic Workflows
Jensen Huang’s CES keynote confirmed that the Vera Rubin NVL 72 is in full production, promising a 10x throughput increase for the trillion-parameter models our agents rely on @scaling01. This shift from "programmed" to "generative" software is exactly what the agentic web needs to scale, according to @BrianRoemmele.
But there’s a catch: HBM capacity hasn't seen a massive jump yet, which might bottleneck model size scaling until 2027, as noted by @scaling01. While the cost per token is dropping, @BrianRoemmele cautions that real-world deployment challenges will still be the primary friction point for agent builders.
Quick Hits
Agent Frameworks & Orchestration
- Modal released a Slack bot example for their Agent SDK, perfect for quick prototyping via @trq212.
- Linear's Slack agent now handles issue creation and search directly from the overflow menu per @linear.
Tool Use & DevX
- Cursor is reportedly revolutionizing internal programming workflows at NVIDIA according to @ericzakariasson.
- Rork v1.5 adds built-in analytics and monetization for AI-native mobile builders via @mattshumer_.
Memory & Verification
- Query-only test-time training (qTTT) might fix fact retrieval in long-context models via @rohanpaul_ai.
- Inference Labs is leveraging zkML to make agentic outputs cryptographically verifiable reported by @danivaweb3.
Models & Reasoning
- New 1B models featuring large-scale multi-stage RL are now live on HuggingFace via @maximelabonne.
- LLMs solve ARC-AGI puzzles more effectively when prompted to think in images first says @rohanpaul_ai.
Subreddit Intel
As tool-bloat hits a ceiling, developers are turning to gateways and semantic geometry to save the context window.
We have reached the infrastructure phase of the agentic web. The novelty of a model performing a single task has worn off; the industry is now obsessing over how to manage 50 tools without blowing the context window or losing its mind after ten messages. Today’s issue highlights a massive shift toward Gateways—the routing layers that sit between LLMs and their tools. Whether it is the Deco MCP Mesh or the push for Semantic Geometry over error-prone vision screenshots, the goal is the same: determinism. We are also seeing a fascinating divergence in frameworks. Developers are choosing sides between the rapid abstractions of CrewAI and the granular, state-heavy control of LangGraph. Meanwhile, the Turn 10 Amnesia problem is finally getting a technical fix via dynamic state rewriting, proving that long-term agentic behavior is not just about bigger context windows—it is about smarter memory management. From NVIDIA’s physics-informed models to local UNIX-style agent pipes, the stack is hardening. If you are building for production, today’s stories on hybrid retrieval and nested orchestrators are your roadmap for the next quarter.
Scaling MCP: Orchestration Gateways and the End of Tool-Bloat r/AI_Agents
As the Model Context Protocol (MCP) gains traction, developers are hitting a wall with 'tool-bloat.' u/babydecocx introduced Deco MCP Mesh, an open-source gateway designed to prevent context window exhaustion when connecting 10 to 100 MCP servers. This is critical because, as noted by @swyx, the 'context tax' of raw tool definitions can consume over 10,000 tokens before a user even types a prompt when scaling to 50+ tools. By using a self-hosted control plane, the system acts as a routing layer that prevents the LLM from being overwhelmed by redundant tool schemas. Practitioners like u/c1nnamonapple are moving away from stuffing entire Swagger docs into system prompts in favor of MCP gateways like Ogment.ai. This shift is further accelerated by automation tools like the CLI from u/taranjeet, which can turn any API into an MCP-compliant tool in seconds. This 'gateway-first' architecture is emerging as the preferred standard for maintaining production reliability and context window optimization in the agentic web.
Production Trade-offs: LangGraph vs. CrewAI r/AI_Agents
The developer community is increasingly divided over the 'abstraction tax' associated with agent frameworks. While u/Responsible-Luck-175 notes that CrewAI allows for rapid prototyping, it often results in 'hand-waving' around agent boundaries, leading to significant observability gaps in complex production environments. In contrast, LangGraph is being adopted for its cyclic graph architecture and granular state management, though experts like @hwchase17 highlight that its persistence layer requires careful configuration to prevent latency overhead during state checkpointing. Technical deep-dives suggest that CrewAI’s task abstraction can introduce internal processing overhead, whereas LangGraph's performance is primarily dictated by the size of the state schema being serialized. To bridge the 'hallucination gap,' developers are now leveraging the Model Context Protocol (MCP) to stream observability logs directly into IDEs, as discussed in r/LLMDevs, allowing for runtime prompt debugging.
Solving 'Turn 10 Amnesia' with Dynamic State r/ArtificialInteligence
A phenomenon dubbed 'Turn 10 Amnesia' is being increasingly observed in advanced models like GPT-4o and Claude 3.5 Sonnet. As documented by u/cloudairyhq, LLMs tend to lose track of core system instructions after roughly 10 to 15 messages. To combat this, developers are implementing 'Session Anchor' prompts—a technique where the agent dynamically rewrites its own system prompt to carry over critical state into the next context window. This shift addresses the '5-second memory' problem highlighted in r/AI_Agents. On the architectural side, the memU framework is emerging as a solution for self-evolving memory. Rather than relying on static RAG, memU utilizes a file-based 'skills.md' architecture. According to u/davilucas1978, this allows agents to reorganize their own memory based on successful outcomes, effectively moving from simple recall to active procedural learning.
Deterministic Action Spaces: Bridging the Vision-Execution Gap r/LocalLLaMA
Hallucinations in vision-based web agents remain a major hurdle. u/Aggressive_Bed7113 introduced SentienceAPI, an SDK that replaces error-prone screenshots with a 'semantic geometry' approach. By exposing a deterministic action space directly from the browser, the tool eliminates vision-LLM retries, which typically account for 40% of agentic latency. This shift ensures 95%+ execution accuracy compared to the 60-70% success rate seen in pure vision-only models. Further innovation includes 'site-aware' adapters like the L.U.N.A project, shared by u/LunaNextGenAI. Industry discussions in r/aiagents suggest that Chrome extensions are the 'perfect' form factor for these agents, as they provide direct access to the browser's internal state.
Scaling Codebase Agents: Hybrid Retrieval and Nested Architectures r/Rag
Building production-grade codebase agents requires moving beyond simple vector search. Technical discussions from u/somangshu emphasize that for large-scale repositories, Hybrid Retrieval (BM25 + kNN) is essential. Architecturally, the industry is shifting toward an 'Orchestrator + Specialist' model. As highlighted by u/GruckionCorp, nesting subagents via tools like the Claude Code plugin allows each task to operate within a fresh 200k context window. This modularity is particularly effective for large-scale React and TypeScript refactors, where r/LLMDevs contributors suggest breaking changes into atomic 'micro-PRs' managed by specialized sub-units.
NVIDIA Alpamayo and the Shift Toward Physics-Informed AI r/ArtificialInteligence
The agentic landscape is pivoting from semantic reasoning to 'Physics AI.' Central to this is NVIDIA’s new Alpamayo family of models, designed to accelerate engineering simulations by up to 10,000x. These models, integrated into the PhysicsNeMo framework, allow agents to reason about fluid dynamics in real-time. To fuel this, NVIDIA released a massive datacenter CFD dataset on Hugging Face—as highlighted by u/Difficult-Cap-7527. Simultaneously, Intel is addressing the 'cloud bottleneck' by prioritizing local inference. At CES, Intel demonstrated how localized processing ensures the privacy required for physical robotics, a move discussed in r/LocalLLaMA as a critical step for hardware-integrated AI.
Orla and the Rise of the UNIX-Style Local Agent r/LocalLLM
Developers are pivoting toward lean, local-first agent tools. u/Available_Pressure47 introduced Orla, a tool that treats LLM agents as standard UNIX commands, enabling developers to pipe data directly. This 'agentic UNIX' trend is bolstered by projects like LiteRT Studio, a dedicated offline chat application for Linux u/M999999999, and Chorus Engine u/ChorusEngine. The hardware barrier is simultaneously collapsing; Apple's M4 Pro has demonstrated staggering performance for local tasks, while consumer setups are now capable of running 100B parameter models with efficient local inference.
LTX-2 Democratizes 4K Local Video Generation r/LocalLLaMA
Lightricks has released LTX-2, a 2B parameter video transformer capable of generating 4K video. As detailed by u/NV_Cory, the model is optimized for NVIDIA hardware and integrated into ComfyUI. Technical benchmarks indicate that native 4K generation typically requires 24GB of VRAM, though r/generativeAI suggests 16GB VRAM is sufficient for 1080p output when using FP8 quantization. This release allows for consistent character generation previously gated behind proprietary services, as noted by u/umarmnaq.
The Discord Dev-Log
As DeepSeek-V3 pushes consumer RAM to its limits, AMD and orchestration frameworks race to bridge the production gap.
The Agentic Web is currently fighting a two-front war: one against hardware limitations and the other against the sheer complexity of reliable orchestration. Today, we are seeing the local inference movement reach a fever pitch. DeepSeek-V3 is setting new standards for what we can run at home, but the 1.1 TiB weight of the full model—and even the 163GB quants—is colliding head-on with a memory market that is pricing 128GB RAM kits like high-end GPUs. AMD is stepping up with the Strix Halo to challenge the Nvidia-centric status quo, but for developers, the real pain is in the plumbing. As we see in the n8n 2.0 migration and the rise of frameworks like Phinite, the 'Agentic DevOps' gap is the biggest hurdle to moving past toy demos. Meanwhile, the tooling layer is optimizing for speed, with developers ditching MCP servers for native Claude skills to squeeze every millisecond of performance. It is a transition period where the hardware is expensive and the software is breaking, but the capability of these autonomous systems is undeniably entering a new era of production-readiness.
DeepSeek-V3 Dominates Local Infrastructure Discussions
DeepSeek-V3 has become the primary benchmark for local LLM practitioners, pushing the boundaries of consumer hardware with its 671B parameter architecture. While the full model weighs in at 1.1 TiB, the community is rallying around GGUF quants to enable local execution. As highlighted by pwnosaurusrex, the 'Terminus' GGUF version at 163 GB pushes the limits of high-end Mac Studio setups, requiring nearly the full capacity of a 192GB Unified Memory system. These developments are accelerated by @unslothai, whose dynamic quantization methods help preserve logic at lower bit-widths. Technical discourse in the Ollama community, including insights from andherpearlcollector, emphasizes that DeepSeek-V3's Mixture-of-Experts (MoE) design only utilizes 37B active parameters during inference. This allows for smarter responses without the full weight of the network per token. Furthermore, the implementation of Multi-head Latent Attention (MLA) significantly reduces the KV cache footprint, a claim verified in the Ollama GitHub repository. For those on 128GB RAM systems, 2-bit quants are the current threshold, while users with 12GB or 16GB VRAM are looking toward distilled versions. Join the discussion: discord.gg/ollama
AMD Challenges Nvidia Dominance with Strix Halo
AMD has officially pivoted to high-performance agentic hardware at CES 2026, unveiling the Strix Halo (Ryzen AI Max) platform designed specifically for local LLM orchestration. As reported by AMD Press, the hardware delivers a massive 60 TFLOPS of AI compute, effectively matching the performance profile of high-end discrete GPUs while maintaining a unified ROCm 6.3 ecosystem. This release includes a direct competitor to the Spark architecture, aimed at reducing the 'Nvidia tax' for developers. According to discussions in LocalLLM Discord, the standout feature is the high-speed interconnect allowing for clusterable mini-PC configurations, which aimark42 notes could revolutionize small-scale data centers. Industry analysts at The Verge suggest this marks a shift toward 'Agentic PC' standards where local inference becomes the default for enterprise workstations. Join the discussion: discord.gg/localllm
RAM Scarcity and Zombie GPUs Drive Infrastructure Costs
Building local agentic infrastructure is becoming increasingly expensive as memory prices continue to climb, driven by a pivot in global manufacturing toward HBM for enterprise AI. Retailers like Newegg are currently bundling 128GB DDR5 RAM kits for a staggering $1,460, a price point that rivals high-end GPUs like the RTX 5080. TrentBot noted that these rising costs are hitting developers just as hardware roadmaps shift toward higher DRAM pricing. In response to these PC hardware constraints, developers are increasingly adopting Apple’s M4 Max as a compact alternative. gurumeditation0 pointed out that while an M4 Max with 128GB of RAM costs approximately £3,799, its unified memory architecture and 546 GB/s bandwidth make it a superior small server for AI. This bandwidth is critical for running large models like DeepSeek-V3; though the full model exceeds 1.1 TiB in BF16, quantized 4-bit versions can run on high-memory Mac configurations, whereas PC builds require complex multi-GPU setups to achieve similar throughput. Join the discussion: discord.gg/ollama
Phinite Bridges The Agentic DevOps Gap
A new orchestration layer called Phinite is emerging to address the 'production gap' where AI agent workflows fall apart after the demo phase. According to exquisite_chipmunk_88877, the project focuses on the messy reality of multi-agent coordination, brittle infrastructure, and the lack of clear ownership for retries and failures. Phinite is positioned as a DevOps layer specifically designed to make multi-agent systems reliable at scale, addressing the non-deterministic nature of LLM-based workflows that frequently break in high-concurrency environments. The platform aims to provide the necessary guardrails for security reviews and operational monitoring that current frameworks often lack. As agentic workflows move from simple chat interfaces to autonomous background processes, the need for deterministic geometry and tracing utilities—similar to those mentioned by tonyw0852 for web automation—becomes critical for troubleshooting and replay capabilities. By providing a unified control plane, Phinite allows developers to implement 'Agentic DevOps' practices, ensuring that autonomous agents can be monitored, audited, and recovered without manual intervention.
n8n 2.0 Binary Migration Sparks Workflow Friction
Developers migrating to n8n 2.0 are facing significant friction due to the platform's transition to a new binary data engine. A critical issue identified by killerclasher involves the Supabase integration, where XLSX files are frequently misidentified as 'application/json' or generic 'application/octet-stream,' effectively breaking downstream parsing nodes. Parallel to data issues, the community is grappling with loop instability. Expert 0x0oz noted that connecting multiple inputs to a 'Loop Over Items' start node causes the engine to lose track of indices, a bug that can lead to infinite loops or skipped data. To mitigate this, documentation and power users now recommend isolating complex logic within Sub-workflows. As noted in the n8n migration guide, these architectural shifts are intended to improve performance, but the current breaking change phase has led many to revert to Python-based task runners for production-grade stability. Join the discussion: discord.gg/n8n
The Shift from MCP Servers to Native Claude Skills
The Model Context Protocol (MCP) ecosystem is witnessing a transition toward 'native skill' integration as developers seek to minimize infrastructure overhead. According to insights from ia42, a 'brute force' engineering trend has emerged where Claude is used to re-engineer MCP server source code into direct function definitions. This allows for zero-latency tool execution by eliminating the need for a persistent local or remote server. On the enterprise side, Blockade Labs is actively navigating the complexities of the official Claude directory. While their Skybox AI tool is operational, quantumjeep highlights that the publishing process remains opaque. Developers are currently grappling with the untold truths of directory placement, which involves meeting stringent security and reliability benchmarks that go beyond basic protocol compliance. This friction has pushed more independent developers toward the skill conversion path to maintain agility in agentic setups. Join the discussion: discord.gg/anthropic-claude
LMSYS Launches Video Arena to Standardize Evaluation
LMSYS has officially launched the Video Arena, a crowdsourced benchmarking platform designed to rank the visual fidelity and prompt adherence of generative video models. According to @lmsysorg, the experiment utilizes a side-by-side Elo rating system to evaluate models such as Wan-Video 2.1 and Luma Ray. While early reports mentioned a Wan 2.6 version, current technical documentation for Wan-Video highlights the 2.1 release, which features native audio generation and support for 480p/720p resolutions. Users like @AIVideoGuy report that while the model is powerful, aspect ratio controls in the arena remain inconsistent, often defaulting to square outputs. Furthermore, the appearance of stealth models, including a mysterious entry nicknamed 'Grok 4.2' by the community, has sparked significant speculation; @TestingAI notes these models appear and vanish as part of blind A/B testing to gather unbiased performance data.
Perplexity Users Frustrated By Comet Browser Overhaul
Perplexity's aggressive push for its Comet agentic browser is causing significant friction among its power user base. Subscribers are reporting a software experience where the UI frequently forces users toward Comet download screens with no option to go back. @tech_insider_2026 highlighted a 15% increase in churn sentiment on social platforms, while ahriusdc and other Pro users have expressed intent to cancel their subscriptions, citing a decline in reliability. The frustration extends to the product's core functionality, including hallucinations and an over-reliance on past conversation history. @perplexity_ai recently acknowledged UI navigation friction following the v2.4 update, though users remain concerned with the basic stability of search and coding features. Join the discussion: discord.gg/perplexity
HuggingFace Open-Source Alpha
Hugging Face's smolagents proves that letting agents write Python beats JSON tool-calling by 10% in accuracy.
The Agentic Web is moving past the JSON bottleneck. Today's release of smolagents and the Open Deep Research framework by Hugging Face signals a paradigm shift toward code-as-action. By allowing agents to write and execute Python rather than just filling out structured forms, we are seeing a 10% accuracy boost on complex benchmarks like GAIA. This isn't just a technical nuance; it's the difference between an agent that follows a script and one that can program its way out of a problem. Simultaneously, the push for on-device agency is heating up. We are seeing 270M parameter models achieving 150 tokens per second on mobile chips, while NVIDIA's Cosmos framework brings advanced reasoning to the physical world. However, the reasoning gap remains real. New benchmarks like NPHardEval show that even SOTA models like Claude 3.5 Sonnet struggle when task complexity scales. As developers, the mission is clear: move toward code-centric architectures, leverage specialized small models for speed, and remain skeptical of hallucinated logic in complex reasoning traces. The following sections break down the frameworks, the hardware, and the benchmarks defining this new era of autonomous systems.
Open Source Deep Research: Challenging Proprietary Silos
The Deep Research trend is shifting toward open-source transparency with the release of open-deep-research by Hugging Face. Unlike closed-source competitors, this project utilizes the smolagents library, which prioritizes code-based actions over traditional JSON-based tool calling. According to @m_ric, code agents demonstrate significantly higher accuracy in complex multi-step tasks. The architecture allows agents to autonomously browse, synthesize, and report on data using open-source models like Hermes-3-Llama-3.1-405B, which is specifically fine-tuned for agentic reasoning. While OpenAI's Deep Research feature offers a high-polish user experience, this open-source alternative provides a 90% cost reduction for developers who leverage local hardware or low-cost inference providers like Together AI. Community-driven implementations, such as the MiroMind Open Source Deep Research Space, are already proving that open models can match the depth of proprietary agents when paired with robust search APIs like Tavily or Serper. To ensure reliability, Hugging Face has also introduced OpenEnv, a framework designed to evaluate these agents in real-world environments, as noted by @clemens_hf.
Code-First Agents Outperform JSON Tool-Calling with smolagents
Hugging Face has launched smolagents, a minimalist library that replaces traditional JSON-based tool calling with direct code execution. According to lead developer @aymeric_roucher, this 'code-as-action' approach allows agents to express complex logic like loops and conditional branching that are difficult to serialize in JSON. This architectural shift is central to Transformers Agents 2.0, where agents utilizing Python snippets have demonstrated superior performance on the GAIA benchmark, outperforming JSON-based counterparts by nearly 10 percentage points in accuracy. The Tiny Agents initiative further demonstrates this efficiency, showing that a fully functional agent compatible with the Model Context Protocol (MCP) can be written in roughly 50 lines of code. For enterprise-grade reliability, smolagents-phoenix provides integration with Arize Phoenix, allowing developers to trace and evaluate reasoning steps in real-time.
The Rise of Specialized VLMs for Autonomous Desktop Interaction
The race for autonomous computer use is accelerating with the release of Holo1, a new family of GUI automation VLMs powering the Surfer-H agent. Developed by H Company, Holo1 utilizes a compact VLM architecture designed for high-frequency visual feedback, allowing it to process screen changes in near real-time. Complementing this is Smol2Operator, a post-training method from the Hugging Face team that enables small models to function as efficient GUI agents by distilling reasoning capabilities from larger teachers, making local deployment viable. To support this growth, the community has released ScreenSuite, which provides the most comprehensive evaluation to date with over 100+ tasks across 13 distinct platforms. Furthermore, new research in Paper 2501.12326 explores the nuances of visual grounding, proving that element-level localization can improve multi-step task success rates by up to 15% compared to standard VLM prompting.
Benchmarks Tighten: NPHardEval and DABStep Reveal Critical Limits
As agents move beyond simple retrieval, DABStep establishes a rigorous baseline for multi-step data tasks, revealing that even advanced models struggle when reasoning depth exceeds 10 steps. Complementing this, NPHardEval utilizes complexity classes to expose the 'reasoning gap' in LLMs. Recent leaderboard data shows that while Claude 3.5 Sonnet and GPT-4o lead in 'P' class problems, their performance drops significantly—often falling below 30% accuracy—on NP-Hard tasks like the Traveling Salesperson Problem (TSP) as the number of nodes increases. A critical failure mode identified is 'reasoning faithfulness.' According to Fan et al., models frequently arrive at correct answers via flawed logic, a phenomenon NPHardEval tracks by comparing the reasoning trace to the final output. Experts like @_akhaliq have noted that while Claude 3.5 Sonnet shows superior logic in coding, it still faces 'sharp degradation' when complexity scaling is applied.
Tiny Models Master Mobile Function Calling: The Rise of On-Device Agents
A new wave of hyper-specialized, small-scale models is emerging to power edge-device agency. The aquarta/functiongemma-270m-it-mobile-actions series demonstrates that models as small as 270 million parameters can be fine-tuned effectively for mobile-specific actions and tool calling. On modern hardware like the Snapdragon 8 Gen 3, models of this size can achieve inference speeds exceeding 150 tokens per second, enabling near-instantaneous on-device task execution without cloud dependencies. Specialized fine-tunes such as bhaiyahnsingh45/Qwen2.5-1.5B-Instruct-kpi-tool-calling show that models under 8B parameters can achieve high precision in niche domains like manufacturing KPI monitoring through targeted tool-use training.
NVIDIA and Pollen-Vision Bridge Physical Reasoning for Edge Robotics
NVIDIA is accelerating the transition to agentic intelligence in the physical world with Cosmos Reason 2, a reasoning framework that leverages world models to understand physical constraints and spatial relationships. According to NVIDIA, this model integrates into the wider Cosmos ecosystem, which includes high-resolution world models for simulation and planning. This software layer is brought to life through hardware like the Reachy Mini, a compact humanoid robot powered by NVIDIA DGX Spark, which provides the localized compute necessary for real-time inference in the field. Complementing these advancements, Pollen-Vision offers a unified Python library that simplifies the deployment of zero-shot vision models—such as Grounding DINO and SAM—for robotic manipulation without the need for task-specific training.