Building the Agentic Execution Harness
From NVIDIA's TTT to MCP's rise, the focus is shifting from simple prompting to architecting execution environments.
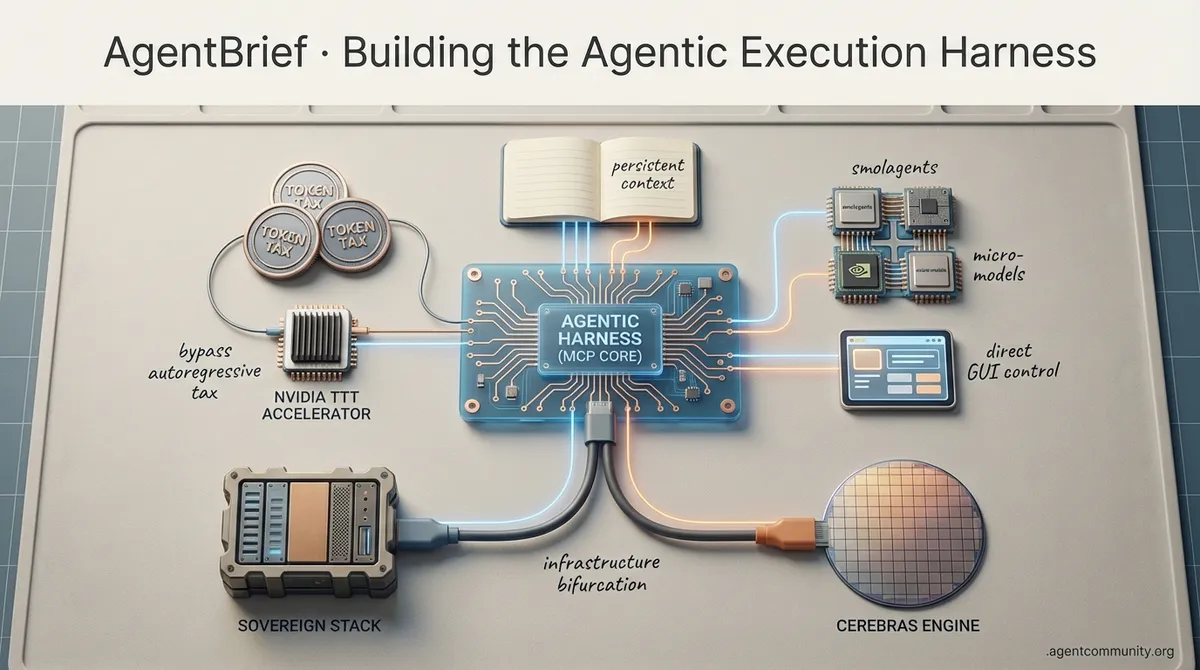
The Execution Layer Shift We are moving beyond simple prompting into the era of the 'agentic harness'—sophisticated execution layers like Anthropic’s Model Context Protocol (MCP) that wrap models in persistent context and tool-making capabilities.
Efficiency vs. The Token Tax While frontier models like GPT-5.2 solve long-horizon planning drift, developers are fighting a 'token tax' with lazy loading for MCP tools and exploring NVIDIA’s Test-Time Training to bypass the autoregressive tax.
Small Models, Specialized Actions The 'bloated agent' is being replaced by hyper-optimized micro-models and frameworks like smolagents that prioritize transparent Python code and direct GUI control.
Infrastructure Bifurcation As power users hit usage caps on models like Claude Opus 4.5, the ecosystem is splitting between sovereign hardware stacks and hyper-specialized inference engines like Cerebras.
AgentBrief for Jan 15, 2026
The X Intelligence Feed
Stop prompting models and start building execution environments that learn from their own failures.
The developer ecosystem is undergoing a fundamental shift from 'chatbot' interfaces to what I call the 'agentic harness.' We are no longer just sending text to a black box; we are building sophisticated execution layers that encapsulate models within tailored environments. This isn't just about better prompts—it's about building agents that possess their own memory, tool-making capabilities, and persistent context. From Anthropic's Model Context Protocol (MCP) to Google's Antigravity, the infrastructure of the agentic web is being laid down in real-time. For us as builders, this means our focus is moving away from the 'magic' of the model and toward the architecture of the agentic workflow. We are seeing a move toward 'vibe coding' where the model handles the boilerplate while we architect the system's reasoning loops and memory retrieval. Today's issue explores how frameworks like MemRL are allowing agents to learn post-deployment and why failure-based training is outperforming perfect demonstrations. If you aren't building a harness for your agents to thrive in, you're just building a fancy autocomplete.
The Era of Agent Harnesses and Vibe Coding
The developer ecosystem is rapidly evolving from raw LLM prompting to sophisticated 'agent harnesses' that encapsulate models within tailored execution environments. As noted by @omarsar0, this shift empowers developers to 'vibe code' personalized tools akin to Cursor by crafting plugins for Claude Code or integrating MCP-powered Kanban boards. This trend is further fueled by the Model Context Protocol (MCP), an open standard by Anthropic that enables seamless connections between Claude and external data sources like GitHub or web search. This allows for automation of complex tasks like creating pull requests with zero local setup required, as highlighted by developers such as @MervinPraison and @AnthropicAI.
Claude Code is at the forefront of this transformation, with practitioners like @rileybrown describing development as a 'video game' due to its sandboxed environments for building skills and API integrations. Community sentiment on X echoes this enthusiasm, with users such as @Avthar likening the use of Claude Code without plugins or MCPs to 'using an iPhone without apps,' underscoring the power of these extensions. Innovations like semantic code search plugins are enhancing capabilities with full codebase indexing for richer context, as shared by @Sumanth_077 and @akshay_pachaar, who note its 100% open-source nature.
However, challenges persist, particularly with browser-based agent tools. @petergyang critiques their inefficiency for complex tasks like document editing, advocating for deeper API-level integrations. Contrarian views on X, such as from @VictorLeeJW, point out that while MCP facilitates real-time data connections, limitations remain regarding pushing directly to GitHub in some setups. Despite this, recent developments like AIRC MCP, which enables Claude instances to message each other, as announced by @slashvibedev, suggest the community is actively addressing integration gaps, pushing vibe coding toward production-ready workflows.
MemRL and RoboPhD Drive Breakthroughs in Post-Deployment Agent Learning
Recent advancements in AI research are addressing the critical challenge of enhancing agent performance post-deployment without the need for costly retraining of base models. The 'MemRL' framework, as discussed by @rohanpaul_ai, enables frozen LLMs to self-improve by identifying and leveraging specific memories that enhance success in future tasks. This agentic memory system allows LLM agents to iteratively learn from their own history, achieving impressive results like 87.88% Pass@3 on GAIA validation and 79.40% on private tests, without altering the base model parameters, as highlighted by @rohanpaul_ai.
In specialized domains, the RoboPhD framework takes this concept further by enabling agents to evolve their own prompts and tools based on feedback from databases, particularly excelling in complex text-to-SQL tasks, as noted by @rohanpaul_ai. Additionally, the quest for handling vast contexts has led to innovations like Recursive Language Models, which @IntuitMachine describes as a potential remedy for 'context rot' in models dealing with 10M+ tokens. A recent post by @rohanpaul_ai also suggests that long-context capabilities can be achieved through test-time learning, compressing context directly into model parameters with low attention costs.
The sentiment on X reflects excitement about these developments, though nuanced reactions point to scalability concerns. For instance, @IntuitMachine discusses 'Iterative Deployment' as a brilliant yet terrifying approach to LLMs getting smarter with use, hinting at long-term implications for control and ethics in agentic systems. These insights underscore the transformative potential of MemRL and Recursive Language Models while calling for cautious exploration of their broader impacts in real-world applications.
The Rise of Efficient Local Agentic Workloads
In 2026, the AI landscape is witnessing a pivotal shift from resource-intensive frontier models to efficient, hardware-aware models tailored for agentic workloads. This transition is underscored by predictions from @FTayAI that 2026 will mark the 'year of frontier versus efficient model classes,' with a focus on smaller, specialized models like Small Language Models (SLMs) that promise cost and performance advantages. The push towards efficiency is driving innovations in local deployment, where advancements in edge computing enable on-device AI processing that eliminates latency, a trend seen as critical for agentic applications by @FTayAI.
Hardware advancements are playing a crucial role in supporting this shift, with diverse solutions like ASIC-based accelerators and chiplet designs emerging to prioritize efficiency over raw power. @FTayAI notes that this may pave the way for agent-specific chips, though training efficiency does not fully address inference costs or hardware shortages. Companies are increasingly opting for specialized SLMs over frontier models to achieve better ROI in agentic contexts, as highlighted by @FTayAI.
HardGen: Enhancing Agent Tool-Use Through Failure-Based Training
Recent advancements in training methodologies for tool-using agents highlight the efficacy of learning from mistakes over traditional perfect demonstrations. A notable approach, HardGen, introduced by @rohanpaul_ai, leverages tool-use failures as critical training data, allowing a 4B parameter LLM agent to rival much larger models. This iterative learning from errors is echoed in broader discussions about adaptive training strategies to improve agentic performance on multi-hop question answering, as seen in posts by @rohanpaul_ai.
Further perspectives from X reveal a growing consensus on the need for innovative operational frameworks, such as transforming tool use into tool-making capabilities. @rohanpaul_ai discusses enabling LLMs to handle novel scientific tasks by dynamically evolving tools at test time. Additionally, insights from @jerryjliu0 suggest a practical workaround for long-context tool use by offloading history to a file system tool loop instead of relying on naive ReAct patterns.
Google Pioneers Agentic Web Development with Antigravity
Google has recently unveiled 'Antigravity,' a tool aimed at empowering developers to create projects through direct collaboration with AI agents. According to @GoogleCloudTech, Antigravity facilitates a seamless workflow between AI Studio and Agent Manager, allowing developers to start in the cloud and finish in local IDEs with Gemini 3. This aligns with broader sentiment where agents are viewed as essential developer tools, as shared in tutorials by @freeCodeCamp.
Beyond project management, Google is promoting 'intelligent software testing' through Gemini, focusing on detecting UI anomalies and enabling natural language control of devices. This capability is part of a larger suite of Gemini-powered tools like AlphaEvolve, which proposes intelligent code modifications for algorithm efficiency, as shared by @GoogleCloudTech. While developers are excited about rapid prototyping with Gemini 3 Flash, @freeCodeCamp notes that some express concerns over the learning curve of these advanced agentic tools.
Quick Hits
Agent Frameworks & Orchestration
- A new framework for AI agents with self-learning capabilities has been released by @tom_doerr.
- Claude Code now supports automatic skill hot-reloading, making skills immediately available without restarts per @NickADobos.
Models for Agents
- DeepSeek-R1's technical paper updated to 86 pages, detailing a three-stage 'training story' for reasoning, according to @rohanpaul_ai.
- Opus 4.5 is rumored to offer significant coding capability gains, described as 'everything we hoped' by @scaling01.
Tool Use & Function Calling
- Pandada AI launched to turn messy CSVs into executive reports automatically, as shared by @hasantoxr.
- ClinicalReTrial is a new agent that iteratively rewrites trial protocols to improve success probability, per @rohanpaul_ai.
Agentic Infrastructure
- vLLM achieved 16K tokens per second (TPS) optimizations for Nvidia Blackwell out of the box, according to @MaziyarPanahi.
- Samsung projects a 3x profit jump due to surge in AI-driven demand for memory chips, reports @Reuters.
Industry & Ecosystem
- LMArena raised $150M at a $1.7B valuation to scale its model-comparison platform, per @rohanpaul_ai.
- Zhipu AI, China's 'AI tiger,' has officially gone public in a Hong Kong debut, via @CNBC.
Reddit's Technical Deep-Dive
NVIDIA's Test-Time Training aims to kill the 'autoregressive tax' while Claude optimizes for the 'token tax.'
The architecture of the Agentic Web is shifting from static inference to dynamic learning. Today’s lead story on NVIDIA’s Test-Time Training (TTT) suggests a future where models don’t just retrieve context but actually 'learn' it in the inner loop, potentially ending the quadratic scaling nightmare of the Transformer. This theoretical breakthrough arrives just as practical tooling is hitting its own limits. Anthropic’s Claude Code is now forced to implement lazy loading for MCP tools to combat massive token bloat—a reminder that as agents get more capable, the overhead of their 'tool belts' is becoming a primary bottleneck. For builders, the message is clear: efficiency is the new performance. Whether it's through TTT-Linear architectures, ultra-small models like LFM 2.5 punching above their weight, or hardware like the Raspberry Pi AI HAT+ 2 bringing 40 TOPS to the edge, the focus is on local, low-latency, and high-precision execution. However, this move toward autonomy brings sharp risks, evidenced by the critical CVE-2026-22686 sandbox escape in FrontMCP. We are moving toward a world where agents are more autonomous, but our safety primitives like Packet B must move from 'vibes' to the kernel level to keep up.
NVIDIA’s Test-Time Training (TTT) Challenges Transformer Dominance in Long Context r/MachineLearning
NVIDIA researchers and collaborators have unveiled a breakthrough in End-to-End Test-Time Training (TTT), a method that replaces the traditional static hidden state with a dynamic model updated via gradient descent during inference @_akhaliq. By treating the context window as a training set, the architecture achieves linear complexity, effectively bypassing the quadratic scaling bottlenecks of standard Transformers. Research indicates that TTT-Linear not only matches Transformer performance at 2k context but outperforms Mamba at 32k tokens, providing a more robust framework for long-context reasoning u/44th--Hokage.
This approach addresses the 'autoregressive tax' by utilizing an inner-loop optimization that allows the model to 'learn' the specific nuances of a prompt as it processes it. For agentic workflows, this means long-horizon agents can maintain state more effectively without the compute-heavy overhead of traditional RAG or massive KV caches @p_v_v_. Experts note that this shift from simple retrieval to real-time learning could redefine how models handle mid-task memory and complex multi-step reasoning, potentially reducing reliance on external memory systems r/AgentsOfAI.
Claude Code v2.1.7 Optimizes MCP via Lazy Loading to Combat Token Bloat r/ClaudeAI
Anthropic's Claude Code has officially implemented lazy loading for Model Context Protocol (MCP) tools in version 2.1.7, a move designed to drastically reduce the initial context payload. As highlighted by u/jpcaparas, this update addresses the 'token tax' where tool definitions alone can consume up to 16.7k tokens per request, according to internal logs shared by u/DSHR24. By deferring the loading of tool schemas until they are explicitly invoked, the CLI significantly reduces Time to First Token (TTFT) and prevents tool-heavy agents from hitting context limits prematurely.
The release has also intensified the debate between the raw CLI experience and the new 'Cowork' GUI. While power users like u/FlatulistMaster question if Cowork adds sufficient value for terminal-centric workflows, Anthropic's developer relations team suggests that GUI-based agent management is critical for collaborative debugging. However, platform stability remains a concern; a recent 'Compaction' incident documented on status.claude.com caused intermittent outages for Pro and Team users.
CVE-2026-22686: Critical Sandbox Escape in FrontMCP Patched r/mcp
A critical sandbox escape, identified as CVE-2026-22686, has been discovered in the enclave-vm used by FrontMCP’s CodeCall plugin. According to u/DavidAntoon, the vulnerability allows sandboxed JavaScript to execute arbitrary code on the host system by bypassing AST validation. Technical analysis reveals the flaw carries a CVSS score of 9.8, stemming from improper sanitization of nested function calls; a fix has been deployed in enclave-vm v2.4.1.
In response to growing safety concerns, new control primitives like Packet B are emerging. As discussed by u/Agent_invariant, Packet B is a stateless execution gate designed to answer whether an action is safe before it hits the kernel level, reportedly reducing safety-check latency by 40% compared to traditional LLM-based verification. Furthermore, the community is moving toward transparency with tamper-evident audit logs, as highlighted in r/LocalLLaMA, providing a cryptographically verifiable record of all agent-driven tool executions.
Small Models Punch Up: LFM 2.5 and Step-Audio-R1.1 Set New Benchmarks r/LocalLLaMA
The trend of "ultra-small" models reaching utility is accelerating with the release of LFM 2.5, a 1.3B parameter model from Liquid AI. u/guiopen reports that this model is the first in its class to avoid the infinite loops common in tiny models, performing comparably to models 3x its size. This is a significant milestone for edge-based agents that require low-latency reasoning on constrained hardware.
Simultaneously, Mistral has released the technical paper for Ministral 3, including dedicated "reasoning" variants specifically tuned for complex problem-solving. Complementing these text-based breakthroughs, StepFun has released Step-Audio-R1.1, an open-weight model that has reportedly set a new SOTA for audio reasoning, surpassing flagship models in audio understanding r/LocalLLaMA. These developments suggest the infrastructure for local, autonomous agents is maturing rapidly, allowing for sophisticated task automation without high cloud API costs.
Raspberry Pi AI HAT+ 2: 40 TOPS and the Challenge of Edge LLM Storage r/LocalLLaMA
Raspberry Pi has launched the AI HAT+ 2, priced at $130, featuring the Hailo-10H accelerator and 8 GB of dedicated LPDDR4X SDRAM. This hardware provides a massive leap to 40 TOPS, specifically targeting generative AI tasks. As noted by u/nicolash33, the accelerator consumes the Pi's singular PCIe port, forcing a difficult trade-off between high-speed AI performance and NVMe storage.
Performance benchmarks for the Hailo-10H indicate it can run Llama 3 (8B) at approximately 5-10 tokens per second when using 4-bit quantization, a significant lead over legacy edge solutions. However, the memory-intensive nature of these models has sparked a "hardware nostalgia" for high-endurance tech, with u/astral_crow arguing that Intel Optane’s low-latency persistence would have been the perfect hybrid for modern AI caches. By enabling local execution of 3B-7B parameter models, it allows for sophisticated planning loops without cloud-based privacy concerns.
Hardening Agent Production: From Hallucination Detection to $12K Guardrails r/AI_Agents
Reliability remains the primary hurdle for production-grade agents, as "full confidence" hallucinations often mask underlying logic failures u/dinkinflika0. Developers are shifting toward structured RAG architectures over fine-tuning for data tasks to maintain schema integrity for large files. To combat "AI glaze," u/N8Karma has released a specialized model to "unslop" prose, removing the over-enthusiastic patterns typical of instruction-tuned models.
On the financial side, the release of "UsageF" by u/Extension_Key_5970 addresses the "infinite loop" risk, where agents stuck in recursive reasoning have generated $12,000 bills in just three days. This reflects a broader industry push toward observability tools to provide real-time cost and logic guards, ensuring agents don't bankrupt their creators through runaway orchestration.
Jira and Redis Integration Accelerate the Agentic Web via MCP r/mcp
The Model Context Protocol (MCP) is rapidly becoming the standard for tool-calling, with the new Jira MCP server allowing AI agents to perform complex project management tasks through natural language. On the data infrastructure side, the Ayga MCP client has emerged as a critical bridge, offering a unified Redis-backed interface for over 21 AI models, including Perplexity, Gemini, and DeepSeek r/mcp.
Beyond enterprise SaaS, the ecosystem is expanding into personal IoT with the Renpho MCP server, which exposes body composition data from smart scales to LLMs. This proliferation of adapters aligns with the Jovian Cyberplug concept—a universal interface for AI APIs—discussed in r/ArtificialInteligence. Recent developments include specialized servers for real-time memory management, further solidifying the trend toward a cross-platform, agentic web.
Musk v. OpenAI Trial Set for April; Meta Restricts WhatsApp AI Access r/OpenAI
The landmark legal battle between Elon Musk and OpenAI is heading to a jury trial on April 27, 2025. The case centers on whether OpenAI violated its founding non-profit mission, with OpenAI arguing that the shift to a capped-profit model was essential to secure the billions in compute resources required for AGI u/Cold_Respond_7656.
In another major ecosystem shift, Meta has officially banned third-party AI assistants from the WhatsApp Business API. u/SumGeniusAI notes that this move effectively kicks ChatGPT and Copilot off the platform, leaving Meta AI as the sole allowed assistant. This signaling of aggressive tightening coincides with reports that the Trump administration is granting broad powers to officials to oversee AI development, potentially reshaping federal oversight of tech giants.
The Discord Dev Chat
As GPT-5.2 sets a new bar for long-horizon planning, the industry grapples with the 'laziness' of frontier models and the reality of usage caps.
Today’s agentic landscape is defined by a paradox: we have the brains and the hardware, but we’re fighting against the 'laziness' of the models themselves. The community is buzzing over Cursor’s findings on GPT-5.2, which finally seems to tackle the 'drift' that plagues autonomous workflows, maintaining a 92% completion rate over long horizons. This isn't just a benchmark victory; it’s a prerequisite for the Agentic Web. However, the friction remains high. Claude Opus 4.5 is facing a backlash as power users hit token walls that make complex refactoring nearly impossible, forcing developers to find clever workarounds or switch providers entirely. Meanwhile, the infrastructure layer is bifurcating. On one side, we see sovereign AI stacks like Zhipu AI’s Huawei-based training; on the other, hyper-specialized inference hardware like Cerebras delivering 1,800 tokens per second. For developers, the takeaway is clear: the bottleneck is shifting from 'can it do it?' to 'how do we keep it from taking shortcuts?' and 'how do we afford the context?'. Whether it's through metacognitive prompting loops or shifting to edge-optimized models like Step3-VL, the goal is the same: building systems that don't just plan, but persist.
Cursor Scaling Agents: GPT-5.2 vs Opus 4.5 Performance Gap
The agentic community is currently obsessed with Cursor's latest 'Scaling Agents' deep dive, which exposes a massive rift in model performance for long-running autonomous tasks. According to hime.san, the GPT-5.2 model is a significant leap over GPT-5.1-codex, particularly in its ability to follow complex instructions without 'drifting'—that frustrating phenomenon where an agent loses the plot mid-workflow. Technical evaluations shared by @tech_analyst_99 show GPT-5.2 maintaining a 92% task completion rate over 100+ steps.
This reliability is the holy grail for developers building agents that need to operate for hours. While some like aris.krmt are finding success with sub-agents, others like frerduro are still hitting walls where models merely describe a plan instead of executing it. As @dev_lead_x points out, the real differentiator is persistence; while Opus 4.5 often falls prey to 'agentic laziness,' GPT-5.2 utilizes a 30% more robust reasoning tree to maintain state across long-horizon windows. Join the discussion: discord.gg/cursor
Claude Opus 4.5 Usage Caps Spark Pro User Backlash
Power has a price, and for Claude Opus 4.5 users, that price is currently paid in tokens. Frustrated developers like en_tal are reporting that reaching 402k tokens can trigger weekly limits in just two days. @skirano notes that high-intelligence models come with rapid message depletion, with as few as 4 high-context outputs exhausting a session, making the model nearly unusable for large-scale code refactoring.
To fight back, the community is getting creative with prompt engineering. _mr.ee suggests forcing the model to 'write in silence' or 'provide a tarball' to save on output token quotas. Anthropic’s @alexalbert__ has acknowledged the tension between model power and availability, but for many like exiled.dev, the 1M+ token window of Gemini is becoming an increasingly attractive fallback despite Claude's superior reasoning. Join the discussion: discord.gg/anthropic
The 'Law of Laziness' and the Rise of Metacognitive Agentic Loops
If your agents are cutting corners, you might need to invoke the 'Law of Laziness.' Popularized by telepathyx, this technique forces a model to explicitly ask itself, 'Could I be less lazy?' before finishing a task. It's a metacognitive check that forces the agent to admit to its own potential omissions, particularly in software engineering tasks where models skip boilerplate. Harrison Chase observes that these self-correction loops are becoming foundational to modern agentic frameworks.
Research supports this iterative approach; the 'Self-Refine' framework can boost performance across coding benchmarks by up to 20%. However, researchers at DeepMind warn that these loops are only as good as the model's internal knowledge. Without a way to ground the critique in external feedback—like a compiler or tool output—the loop risks simply reinforcing hallucinations. This has led to the development of 'verified' loops where the model's self-critique is grounded in real-world tool execution. Join the discussion: discord.gg/anthropic
Zhipu AI and Cerebras Redefine AI Infrastructure Beyond NVIDIA
While US-based developers argue over token caps, Zhipu AI is proving that high-scale vision-language models can thrive outside the NVIDIA ecosystem. Training their latest GLM-Image model on a Huawei Ascend 910B stack, they achieved over 80% efficiency relative to NVIDIA A100 clusters. @SinoTechFocus highlights that the CANN software layer is finally mature enough to support the complex reasoning chains agents require despite US export bans.
Closer to home, the OpenAI and Cerebras partnership is redefining the speed of the agentic web. The Cerebras WSE-3 is now pumping out 1,800 tokens per second for Llama-3 70B—a staggering 20x faster than standard cloud GPU providers. This throughput is essential for autonomous systems where low-latency inference allows models to perform dozens of iterative tool-calls in the time it previously took to generate a single paragraph.
n8n Optimizes Agentic Workflows with High-Performance Python Runner
In the world of workflow automation, n8n is making a major play for high-concurrency performance. Founder Jan Oberhauser confirmed the rollout of a new internal Python runner that eliminates the performance bottlenecks of legacy implementations. This allows for what experts like @algonovalabs call 'agentic pagination'—processing massive datasets through Gemini 1.5 Pro without the workflows timing out or exceeding memory limits.
Document processing is also getting a boost through multi-layered OCR strategies. 3xogsavage is championing a 'best-of-breed' approach, using Mistral OCR for layout preservation and DeepSeek for cost-effective extraction. For those needing local fallbacks, the n8n-nodes-tesseractjs package remains a staple for ensuring agents can process multi-page PDFs without cloud dependency. Join the discussion: discord.gg/n8n
Ollama v0.14.1 Bolsters Security as Step3-VL-10B Disrupts Edge Vision
Ollama’s v0.14.1 release marks a shift toward production-ready local agents by introducing a Terminal User Interface (TUI) and granular tool permissions. maternion notes that the new release enforces explicit permission prompts before a model executes external tools, effectively mitigating unauthorized actions. This UX improvement, praised by theunknownmuncher, allows for better resource monitoring directly from the CLI.
On the performance front, the Step3-VL-10B model is redefining expectations for 'edge' multimodal agents. Benchmarks indicate that this 10B parameter model achieves an MMMU score of 55.4%, rivaling much larger models like Gemini 1.5 Pro. dagbs highlights its proficiency in UI navigation and document understanding, achieving scores of 85.1% in ChartQA and 91.2% in DocVQA, suggesting high-fidelity visual agents no longer require massive cloud backends. Join the discussion: discord.gg/ollama
Soprano 1.1 and MedGemma 1.5 Signal the Era of Micro-Agents
The era of the 'micro-agent' has arrived with the release of Soprano 1.1-80M, targeting audio generation stability. According to technical assessments by TrentBot, the update boasts a 95% reduction in hallucinations and a 63% preference rate over its predecessor. This ultra-compact architecture effectively eliminates audio glitches, making it ideal for real-time edge computing where larger models fail due to inference lag.
Simultaneously, specialized models like MedGemma 1.5-4B are demonstrating that micro-agents can achieve high-tier accuracy in complex fields like medical reasoning. This trend suggests a shift toward distributed agentic systems where specialized SLMs handle domain-specific tasks on-device. The 80M to 4B parameter range is becoming the 'sweet spot' for balancing performance with privacy and hardware constraints.
HuggingFace Open-Source Pulse
The 'agentic web' is shifting toward lean, code-first execution and direct visual control.
The era of the 'bloated agent' is ending. We are witnessing a massive structural shift toward two extremes: unconstrained multimodal models that interact directly with pixels (GUI agents) and hyper-optimized micro-models that handle high-frequency tasks on the edge. Today's coverage highlights how the Model Context Protocol (MCP) is maturing into a genuine industry standard, effectively slashing the 'integration tax' for builders. Meanwhile, Hugging Face's smolagents is stripping away the abstraction layers that have plagued agent development for the last year, favoring transparent Python code over complex, black-box state machines. For practitioners, the signal is clear: the focus has moved from general-purpose reasoning to specialized execution. We are seeing 4B parameter models achieve state-of-the-art reasoning scores through stepwise distillation, and 270M parameter models rivaling 7B giants in narrow tool-use domains. Whether you are building medical navigators or mobile automation, the blueprint for the next generation of agents is becoming modular, visual, and remarkably lightweight. This issue breaks down the frameworks, models, and protocols making this lean future a reality.
MCP Gains Momentum: Standardizing the Agent-Tool Interface
The Model Context Protocol (MCP) is rapidly becoming the industry standard for connecting AI agents to external data and tools, effectively reducing the 'integration tax' that previously required custom wrappers for every new data source. Adoption has surged following its introduction by Anthropic, with major IDEs like Cursor and Zed integrating MCP support to allow agents to interact directly with local files and terminal environments. The official modelcontextprotocol/servers repository now hosts a growing library of over 25+ community-maintained connectors, ranging from Google Search and Slack to Postgres databases.
Recent innovations from the Agents-MCP-Hackathon/pokemon-mcp demonstrate the protocol's versatility in handling specialized data lookups, while the Agents-MCP-Hackathon/gradio_agent_inspector provides a critical debugging layer for visualizing agent-tool interactions. The ecosystem is also expanding into niche communication protocols, as seen with MCP-1st-Birthday/sipify-mcp. By decoupling the model from the specific implementation of the tool, MCP enables a more modular and portable agentic architecture, allowing developers to swap models without rewriting their entire toolset.
Pixels Over APIs: Navigating the GUI Frontier
A significant cluster of recent research is pivoting from API-dependent tools to 'GUI Agents' that interact directly with visual interfaces. Central to this shift is OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real-World Computer Control, which established a rigorous testbed across Ubuntu, macOS, and Windows. While human performance on OSWorld sits at 72.3%, current state-of-the-art models like GPT-4o initially struggled with scores around 12-15%, highlighting the immense complexity of long-horizon screen navigation. To bridge this gap, ShowUI: One-Step Visual-to-Action for GUI Agents introduces a lightweight vision-language-action model that treats the screen as a continuous coordinate space, significantly reducing latency by predicting precise click points in a single step.
Further advancements in GUI-Gym provide high-performance environments for reinforcement learning, moving agents beyond static datasets like Mind2Web: Towards a Generalizable Agent for the Web. These systems are increasingly capable of navigating legacy software and complex web workflows without underlying metadata. By treating the screen as a visual sensor, these agents effectively bridge the gap between human-centric design and machine autonomy, transitioning from constrained script-followers to 'unconstrained' digital workers capable of operating any software a human can.
Small Models Achieve SOTA Reasoning via Stepwise Distillation
The release of DASD-4B-Thinking (Distilling Anything into Small Models) marks a significant pivot in training lightweight reasoning agents. By utilizing a Stepwise Distillation paradigm that focuses on intermediate reasoning steps rather than just final outputs, this 4B parameter model achieves a state-of-the-art 81.1% on the MATH benchmark and 84.8% on HumanEval. These metrics demonstrate that small models can outperform counterparts twice their size when trained with high-quality Long-CoT (Chain-of-Thought) data. Furthermore, mradermacher/ToolRM-Gen-Qwen3-4B-Thinking-2507-GGUF highlights the industry move toward Reward Models (RM) specifically optimized for tool integration. By leveraging preference datasets like ToolPref-Pairwise-30K, developers are successfully aligning agent behavior to reduce hallucinations during complex, multi-step tool execution phases.
The Rise of Micro-Agents: Challenging 7B Giants at the Edge
The push for local, low-latency intelligence is shifting from 'small' models (7B) to 'micro' models capable of running on entry-level hardware. The ilkka/functiongemma-270m-it-mobile-actions model demonstrates that 270M parameter architectures, when fine-tuned for specific UI intents, can effectively execute mobile action sequences. Benchmarks in simple tool-selection tasks reveal that these sub-1B models can achieve 90%+ accuracy, rivaling 7B models in narrow domains where the function schema is constrained. This indicates a future where 'micro-agents' handle high-frequency, privacy-sensitive 'last mile' execution directly on-device.
Efficiency is further optimized by the REAP (Relative importance Aware Pruning) method, as showcased in mike-ravkine/GLM-4.7-REAP-50-FP8-Dynamic. By utilizing REAP and FP8 dynamic quantization, these models maintain high reasoning integrity for tool-use while slashing memory footprints by nearly 50%. This tiered architecture—where tiny edge executors handle immediate actions and cloud models handle complex multi-step planning—is becoming the blueprint for the 'agentic web.'
Smolagents and the Rise of 'Code-First' Agent Education
Hugging Face's educational push is seeing massive momentum, with the agents-course/First_agent_template now surpassing 629 likes. This success is anchored by the release of the smolagents library, which Aymeric Roucher @aymeric_roucher describes as a move toward extreme simplicity. Unlike the complex state-management graphs of LangGraph or the role-based abstractions of CrewAI, smolagents prioritizes a 'CodeAgent' that writes actual Python code to interact with tools, a method argued to be more robust than traditional JSON-based tool calling. This 'agents as code' philosophy is the cornerstone of the new Hugging Face Agents Course. The community's response has been rapid, with lightweight implementations like kernel-memory-dump/HuggingFaceAgentsCourse_SmolAgent1 appearing as developers swap 'black box' frameworks for transparent, scriptable logic. Industry experts like Merve Noyan @mervenoyann emphasize that this shift significantly lowers the entry barrier for developers by making the agent's planning and tool-calling logic visible and debuggable directly within a standard Python environment.
The Rise of Specialized 'Navigator' Agents in Healthcare and Science
Specialized AI agents are evolving from general-purpose assistants into 'Navigator' agents designed for high-stakes environments where accuracy is non-negotiable. google/ehr-navigator-agent-with-medgemma showcases how the MedGemma model—a specialized medical LLM fine-tuned for clinical reasoning—can be deployed to synthesize complex Electronic Health Records (EHR) into actionable insights. These medical agents are frequently benchmarked against the MedQA (USMLE style) and PubMedQA datasets, where MedGemma-based systems have demonstrated state-of-the-art performance in clinical retrieval and summarization, effectively navigating siloed data to assist clinicians.
In the scientific domain, the shift toward vertical specialization is exemplified by alarv/QSARion-smolagents, which utilizes the smolagents framework to automate Quantitative Structure-Activity Relationship (QSAR) modeling for drug discovery. By integrating specialized toolsets for chemical analysis, these agents transform raw molecular data into predictive insights. Furthermore, pdx97/ScholarAgent streamlines the research lifecycle by automating literature synthesis and citation management. These developments signal a move toward highly skilled digital specialists that prioritize domain-specific tool-use and safety over general conversational breadth.