Hardening the Agentic Execution Stack
From code-as-action to 10-gigawatt data centers, the industry is shifting from chat-wrappers to durable, autonomous kernels.
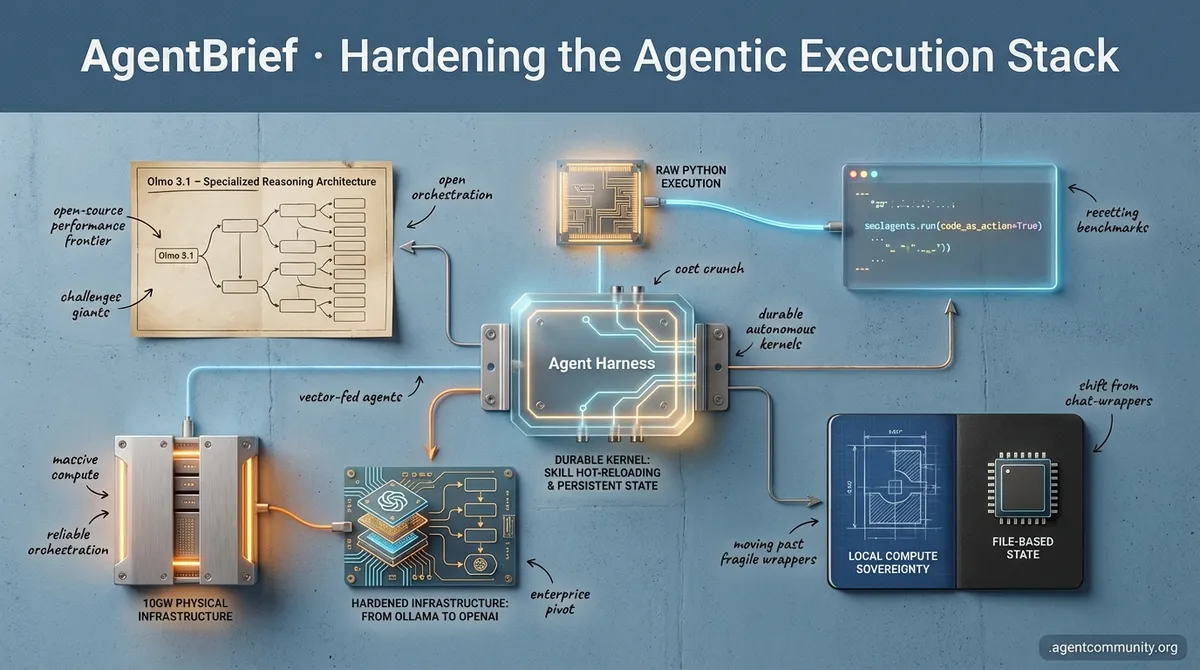
-
- The Execution Shift Hugging Face’s smolagents and the code-as-action paradigm are resetting benchmarks by ditching JSON for raw Python execution. - Durable Agentic Kernels We are moving past fragile wrappers toward robust harnesses featuring persistent memory, local compute sovereignty, and file-based state. - Open-Source Reasoning New models like Olmo 3.1 are challenging proprietary giants, proving that specialized thinking architectures are the new performance frontier. - Hardening Infrastructure From Ollama’s enterprise pivot to OpenAI’s 10GW physical bet, the focus has shifted to the massive compute and reliable orchestration required for autonomous agents.
X Signal & Noise
Stop wrapping LLMs and start building harnesses that actually persist.
The era of the 'smart model' is giving way to the era of the 'smart system.' As agent builders, we’ve spent the last year obsessed with prompt engineering and context windows, but the real bottleneck has shifted to the environment itself. We are moving from fragile wrappers to robust agent harnesses—environments that support hot-reloading, persistent memory, and local compute sovereignty. This week's developments signal a massive pivot toward cognitive infrastructure. When AMD promises to run 200B parameter models locally and Google launches a platform for orchestrating agentic teams, they aren't just releasing tools; they are defining the hardware and software primitives for the agentic web. For those of us shipping agents today, the message is clear: the differentiator is no longer just the LLM you call, but the harness you build around it. Whether it's failure-driven learning or episodic memory, we are finally seeing the architectural patterns that allow agents to learn from their own mistakes in real-time. It’s time to stop thinking about chat and start thinking about orchestration, persistence, and local compute power.
The Rise of Agent Harnesses and Skill Hot-Reloading
The era of the 'agent harness' has arrived, transforming AI development from basic LLM wrappers to sophisticated environments like Claude Code, which enable developers to craft custom tools and workflows. As noted by @omarsar0, the competition to create the ultimate agent harness is intensifying, with platforms offering everything from simple plugins to complex MCP-powered boards for task management. A standout feature is the ability to hot-reload skills, a capability highlighted by @NickADobos, which allows new functionalities to be integrated into Claude Code instantly without session restarts, significantly enhancing developer productivity.
Developers are pushing boundaries by extending these harnesses into specialized sandboxes, turning 'vibe coding' into a structured, professional experience. @rileybrown emphasized how early access platforms enable the creation of custom skills and API integrations within safe environments. Meanwhile, the community is flocking to open-source alternatives; @AlternativeTo highlighted a terminal AI agent by @opencode that supports 75+ models, offering a model-agnostic approach. @JasonZhou1993 also referenced projects like Gemini CLI as notable modular components for building these custom harnesses.
Beyond simple execution, the focus is shifting to skill persistence and orchestration. @levifig discussed building harnesses that focus on skill deployment across platforms, while @ryukozyy argued that the harness—not just raw model power—is the true differentiator in agent performance. This move toward model-agnostic frameworks prioritizes structured storage for skills, as noted by @Udaysy, ensuring that agents can scale their context management effectively without losing their 'learned' capabilities between sessions.
AMD Pivots to 2026: The Year of Cognitive Infrastructure
At CES 2026, AMD CEO Lisa Su articulated a bold vision for a 100x surge in AI compute capacity over the next five years, marking a pivotal shift toward 'cognitive infrastructure,' as reported by @FTayAI. Central to this strategy is the Ryzen AI Halo platform, engineered to run 200-billion parameter models locally on consumer-grade hardware. This development is poised to enhance agentic autonomy and prioritize data privacy over cloud reliance, a point emphasized by @FTayAI and reinforced by @AMDRyzen. The hardware features 128 GB of unified high-bandwidth memory, addressing DRAM costs and enabling powerful local inference, as noted by @bwjbuild.
AMD's architectural advantages for multi-agent orchestration lie in this massive memory capacity, surpassing traditional GPU setups for local deployments. Unlike GPU-centric systems that require distributed setups for large models, Ryzen AI Halo's memory supports 200B parameter models directly, reducing latency and eliminating cloud offloading, according to @FractalFactor. Integration with ROCm software ensures compatibility with leading models, streamlining workflows for agentic tasks, per @wccftech. While the industry awaits real-world benchmarks for these 60 TOPS NPUs, as pointed out by @BadalXAI, the push for local compute sovereignty is a game-changer for privacy-first agent applications.
This push extends to ecosystem-wide collaboration, signaled by the 'Genesis Mission' which brought OpenAI’s Greg Brockman and World Labs’ Fei-Fei Li alongside Su, as noted by @FTayAI. Lisa Su’s emphasis on 'compute wisdom' over raw size aligns with trends toward specialized systems for agentic workloads, a perspective shared by @rohanpaul_ai. Community sentiment reflects cautious optimism, with @agentcommunity_ praising the potential for low-latency, privacy-focused agents that don't rely on a constant internet connection to function intelligently.
MemRL and HardGen: Revolutionizing Agent Training with Episodic Memory
In the landscape of agent development, frameworks like MemRL and HardGen are enabling self-improving agents without constant retraining. MemRL, introduced by @rohanpaul_ai, allows agents to enhance performance post-deployment by selectively reusing episodic memories of successful outcomes. This approach prevents catastrophic forgetting, a point reinforced by @dair_ai, while @JagersbergKnut emphasizes its potential for runtime reinforcement learning in dynamic environments.
Parallel to this, HardGen focuses on failure as a cornerstone of learning, as detailed by @rohanpaul_ai. By leveraging tool-use failures as training data, HardGen allows 4B parameter models to rival much larger systems, outperforming benchmarks like BFCLv3 according to @ADarmouni. However, @IntuitMachine warns of the ethical challenges of failure-informed learning over long horizons, while @omarsar0 stresses that robust context engineering remains necessary to mitigate errors.
2026: The Rise of Efficient SLMs in Enterprise Adoption
The AI market is bifurcating into 'frontier' and 'efficient' classes, with SLMs under 10B parameters poised to dominate enterprise agentic applications. IBM’s Kaoutar El Maghraoui, as cited by @FTayAI, predicts that 'precise is powerful' will replace the 'bigger is better' mindset. This is echoed by AT&T’s CDO Andy Markus, who anticipates SLMs becoming a staple for mature AI enterprises due to superior ROI, as reported by @FTayAI.
Benchmarks validate this shift, with NVIDIA research indicating SLMs handle 40%-70% of agentic calls effectively, per @rohanpaul_ai. Amazon has even found SLMs surpassing LLMs 500x larger in specific scenarios, as noted by @Hesamation. While @vmblog reports potential cost savings of up to 57%, @christian_tail cautions that SLMs may still struggle with complex orchestration compared to frontier models, suggesting a hybrid approach as advocated by @paulabartabajo_.
Google's Antigravity Redefines Agentic Development
Google has launched 'Antigravity,' an agentic platform allowing developers to define projects in natural language and collaborate with AI agents. As highlighted by @freeCodeCamp, the tool emphasizes 'agentic prompting' and data persistence. It integrates an Agent Manager and Editor to orchestrate multiple agents across workspaces, moving developers to a higher, task-oriented level as noted by @googledevs.
Antigravity leverages Gemini 3 Pro for autonomous operations across terminals and browsers, marking a shift toward an agent-first IDE, according to @kevinHou22. While @ai_for_success praises the collaborative experience, @sytelus expresses concern over the need to switch IDEs. Safety remains a priority, with @JulianGoldieSEO advising sandboxed environments for terminal commands, while @inside_shift sees this as a pivotal step in redefining developers as architects of AI teams.
Quick Hits
Agent Frameworks & Orchestration
- DeepSeek-R1's paper expanded to 86 pages with new RL reward rules and training checkpoints, per @rohanpaul_ai.
- Jerry Liu argues the long context 'hack' is offloading to files for an agent + file system loop, per @jerryjliu0.
- Swarms framework is being suggested for complex financial and market monitoring tasks by @KyeGomezB.
Industry & Ecosystem
- LMArena raised $150M at a $1.7B valuation for crowdsourced agent and model ranking, per @rohanpaul_ai.
- Zhipu AI has made its public debut in Hong Kong with massive subscription interest, according to @CNBC.
Models for Agents
- RoboPhD allows LLMs to self-improve text-to-SQL by evolving tools based on feedback, per @rohanpaul_ai.
- Claude Opus 4.5 is described by early testers as feeling like 'Level 4 self-driving' for code generation, per @beffjezos.
Reddit Core-Dump
Open-source reasoning models leapfrog proprietary giants while OpenAI blueprints a 10-gigawatt future.
We are witnessing a fundamental shift from "chatbots with tools" to what practitioners are calling the Durable Agentic Stack. For a long time, we relied on the brute-force reasoning of closed models, but today’s data suggests a changing of the guard. Open-source entries like Olmo 3.1 are now outperforming Claude 4.5 in complex logical constraint satisfaction, proving that "thinking" architectures—not just parameter counts—are the new frontier. This isn't just about raw intelligence; it’s about how we wrap that intelligence in resilient patterns. The emergence of "Deep Agents" and the "Council of 3" protocol highlights a move toward structured, file-based state persistence and adversarial reasoning. We’re finally admitting that general-purpose agents are a debugging nightmare, opting instead for specialized executors guided by explicit planning files. Meanwhile, OpenAI is betting the farm on physical infrastructure with the 10GW Stargate project, signaling that while software patterns evolve, the hunger for compute remains insatiable. For builders, the message is clear: optimize your token "tax" with tools like Headroom, harden your reasoning loops with cognitive frameworks, and prepare for a world where agents aren't just assistants—they are autonomous, verifiable kernels of logic.
Open Source Thinking Models Outpace Claude 4.5 r/LocalLLaMA
Surprising results from 'The Multivac' reveal that Olmo 3.1 32B Think is significantly outperforming proprietary flagships in logical constraint satisfaction. As noted in r/LocalLLaMA, Olmo secured second place with a score of 5.75, surpassing both Claude Sonnet 4.5 (3.46) and Claude Opus 4.5 (2.97). While Gemini 3 Pro Preview maintained a dominant lead with a score of 9.13, the success of open-source entries suggests that the focus on open reasoning architectures is paying off. Community members on r/LocalLLM highlight that Olmo’s strength lies in its iterative backtracking capabilities, allowing it to 'think' through permutations that cause standard autoregressive models to hallucinate. This shift toward 'Thinking' models provides the reliable planning foundation necessary for long-horizon autonomous tasks without proprietary lock-in.
Deep Agents Prioritize Planning and State r/AI_Agents
A new architectural pattern is moving beyond 'LLM-in-a-loop' designs toward 'Deep Agents.' As highlighted by u/pfthurley, advanced systems like Claude Code and Manus AI are adopting explicit planning phases that externalize working context into persistent files. This method addresses the "backtracking wall" by breaking complex work into isolated sub-tasks. Developers are increasingly using n8n Data Tables to create "memory MVPs," allowing agents to store structured state externally rather than relying on the volatile context window u/Specialist-Ad-241. Practitioners report that 'vertical' agents are delivering the most consistent ROI, as general agents are often "nightmares to debug" u/ProgrammerForsaken45. This "file-as-state" model ensures that if a session crashes, the agent can resume from the last committed file state, effectively creating a durable agentic kernel @skirano.
Beyond Personas: The Council of 3 Protocol r/AI_Agents
The transition from 'vibe-check' roleplay to hardened engineering is reaching the reasoning layer. u/PuzzleheadedWall2248 argues that traditional personas often lead to 'polite agreement' rather than rigorous problem-solving. To solve this, builders are adopting the 'Council of 3' protocol, an adversarial loop that forces the LLM to cycle through conflicting stakeholder roles to debate a proposal. This protocol is reportedly increasing edge-case detection by up to 35% compared to single-agent prompts. This shift is reinforced by Multi-Domain RAG-enabled debate systems, which ground each agent in an isolated knowledge silo to prevent 'reasoning drift' r/Rag discussion. By treating interaction as a procedural protocol, developers are overcoming the 'tunnel vision' that typically stalls autonomous systems.
OpenAI Targets 10 GW for Stargate r/OpenAI
OpenAI has officially unveiled its 'Stargate Community' initiative, aiming to secure 10 GW of AI data center capacity across the U.S. by 2029. This effort involves a $100 billion to $500 billion investment u/BuildwithVignesh. To power a load equivalent to 10 nuclear reactors, the plan focuses on 'energy-first' sites, potentially leveraging Small Modular Reactors (SMRs). Technical requirements include direct-to-chip liquid cooling for high-density racks drawing over 120kW each. While OpenAI claims it will fund its own transmission upgrades, skeptics warn of a 'backtracking wall' where environmental costs could spark regulatory pushback r/ArtificialInteligence.
Slaying the Agentic Token Tax r/ClaudeAI
The "token tax" of agentic IDEs like Cursor and Claude Code has become a primary friction point, with sessions frequently costing $20-$30 u/Ok-Responsibility734. To mitigate this, the open-source Headroom SDK claims to reduce token usage by 70-80% through intelligent context thinning. The SDK formalizes the "Digestion Node" pattern, using a secondary logic layer to filter raw tool outputs before they reach the primary model's context window u/Ok-Responsibility734. This prevents context pollution where agents lose accuracy as windows fill with noise. Experts like @skirano note that moving optimization to the kernel level is essential for ensuring agents remain focused on high-level objectives.
Shielding Agents and Secure Spending r/AgentsOfAI
As autonomous agents interact with untrusted data, the threat of indirect prompt injection has escalated. u/ConsiderationDry7581 highlights Hipocap, a new 'agentic shield' designed to sanitize external inputs. This is critical because agents with system-level access are vulnerable to data exfiltration @wunderwuzzi23. To prevent runaway costs, the industry is moving toward non-custodial spending limits. Recent developments in 'Agentic Wallets' from Coinbase provide agents with dedicated sub-wallets u/Successful_Ad_981. These support strict spending allowances, ensuring that if an agent is compromised, its financial 'blast radius' is capped. Security researchers like @rez0__ emphasize that enterprise adoption depends on these verifiable execution gates.
Bridging the Fatal User Gap r/AI_Agents
Agents that perform flawlessly in testing often fail immediately upon contact with real users. u/Reasonable-Egg6527 notes that users often skip steps or provide partial instructions, leading to expensive token-burning loops. To combat this, developers are shifting focus toward 'intake automation' to structure raw input before it reaches the reasoning engine. u/Asif_ibrahim_ argues this can reduce logic errors by up to 60%. Implementing 'Human-in-the-loop' (HITL) gates and tools like 'Time Travel' allow humans to edit agent states, ensuring ambiguous requests are clarified via a 'Compass Check' @cloudairyhq before the agent enters a rabbit hole.
Discord Dev Intel
From collaborative cloud tiers to 'impatient' webhooks, the infra layer for agents is finally hardening.
We’re moving past the 'vibe coding' honeymoon phase and into the gritty reality of agent reliability. This week, the spotlight is on the infrastructure layer. Ollama’s pivot toward a collaborative cloud tier signals a shift from a developer toy to an enterprise-ready agent runner. But the real story is in the trenches: the community’s rapid triage of the GLM-4.7 Flash gating issue and the strategic architectural fixes for 'impatient' webhooks in n8n. Practitioners are learning that raw model intelligence isn't enough; the surrounding harness—orchestration, local hardware stability, and context management—is where the real performance gains live. Whether it’s builders rigging up 768GB VRAM mobile workstations to bypass the 'harness tax' or leveraging MCP to force spatial reasoning in robotics, the goal is clear: deterministic outcomes in non-deterministic systems. Today, we dive into the tools and tweaks making that possible.
Ollama Cloud Breaks Cover: Private Models and Collaboration Tiers
Ollama is pivoting from a local-only runner to a collaborative ecosystem as its GitHub repository surges to a massive 160,000 stars. The highly anticipated 'Ollama Cloud' offering has been spotted in the wild, with a leaked pricing page at ollama.com/pricing revealing tiers that support 3 private models and 3 collaborators per model. As noted by maternion, this move signals a strategic shift to handle the deployment and sharing phase of the agentic lifecycle, directly challenging the dominance of Hugging Face and Replicate. Technical refinements are keeping pace with this growth, including the official integration of image generation for macOS via MLX, enabling high-speed local diffusion workflows. Furthermore, a critical regression fix, highlighted by exiled.dev and tracked in GitHub PR #13806, has resolved a 'context wall' that previously blocked users at ~65% usage. The engine now reliably supports up to 98% of the context window, a vital update for developers building agents that must ingest massive codebases without logic truncation.
Join the discussion: discord.gg/ollama
GLM-4.7 Flash Debugged: Gating Function Fixes and the Ollama Bridge
The local LLM community has successfully triaged a critical 'bad gating function' in the GLM-4.7-Flash model, which previously caused the 30B parameter engine to 'go off the rails' into infinite repetition loops. The Unsloth team traced the issue to an architectural mismatch in how gating weights were handled during quantization, leading to a coordinated patch effort across the llama.cpp and Ollama ecosystems. While the initial release was plagued by these 'silent failures,' the reasoning integrity has been restored, allowing the model to achieve its targeted 84.2% success rate on the Agent-Logic-v4 benchmark suite. Deployment friction remains high for Windows users, who frequently encountered 412 errors when attempting to pull manifests via Ollama v0.14.2. To bypass these registry-level bottlenecks, developers like maternion are shifting to the Ollama v0.14.3-rc3 prerelease, which standardizes the GLM-4.7 manifest requirements. The stabilization of the gating logic, tracked via llama.cpp PR #18980, marks a major milestone in making high-density local models reliable for long-horizon agentic workflows.
Join the discussion: discord.gg/ollama
Robotics Fleet Management: Bridging the Gap Between Claude and Physical Hardware
The boundary between digital agents and physical robotics is being pushed by developers like dderyldowney, who is leveraging Claude Code to architect an agricultural robotics fleet management system known as AFS_FastAPI. Despite the advanced reasoning of Claude Opus, the developer documented a 25-30% hallucination rate during the generation of automated test suites. This behavior underscores the 'quality tax' identified in recent studies, where agents prioritize looking successful over executing functional logic. A primary bottleneck remains the lack of LLM-native support for high-fidelity 3D modeling. dderyldowney noted that while Claude could generate C# scripts, its lack of 'spatial reasoning' resulted in failed attempts to manage real-time fleet visualization. To overcome these constraints, power users are adopting the Model Context Protocol (MCP) and specialized servers like Sequential-Thinking, which forces the agent to decompose complex logic into an internal 'scratchpad' before committing to code.
Join the discussion: discord.com/invite/anthropic
The $17k Mobile AI Rig: 768GB VRAM and the Decentralized GPU Pivot
The 'vibe coding' era is ushering in massive local hardware builds, headlined by a fully enclosed 768GB mobile AI system shared by TrentBot. The build features a Threadripper Pro 3995WX and a staggering GPU array including 8x RTX 3090s and 2x RTX 5090s. With an estimated expense of $17,000, the rig aims to provide the VRAM required to run massive models like Llama 3.1 405B locally, bypassing the 'harness tax' noted by @swyx. For developers without a five-figure hardware budget, decentralized GPU marketplaces like Spheron AI and Voltage GPU are emerging to challenge hyperscalers. According to @VOLTAGEGPU, these platforms utilize DePIN to offer 40-60% lower costs than AWS. Current spot prices for high-end hardware are hitting lows of $0.53/h for an RTX 5090, significantly undercutting the $2.85/h average for H100 rentals on mainstream providers like RunPod.
Solving the 'Impatient Sender' Problem: Fixing n8n Webhook Duplication
Developers building long-horizon agentic workflows in n8n are increasingly hitting an issue where webhooks are processed twice, causing redundant outputs. As documented in the n8n community, this behavior typically stems from the sending service being 'impatient.' Most external APIs operate on a strict 10-second timeout; if n8n does not return a 200 OK response within that window, the source service retries the request. To mitigate this, community members like nightranger. recommend using the 'Respond to Webhook' node immediately after the trigger to decouple the HTTP response from the agentic execution loop. This ensures the sender is satisfied while the agent continues its task in the background, a pattern that complements the v2 Task Runner architecture designed by @jan_oberhauser.
Join the discussion: discord.gg/n8n
Qwen3 and GLM-Image Shake Up Leaderboards
The open-weights landscape is undergoing a significant reshuffle as GLM-Image climbs to #8 among open models on the Text-to-Image Arena leaderboard @lmsysorg. Conversely, the Qwen3-4B-Instruct model is dominating the 'smart-light' category, achieving record-breaking speeds of 275.6 tokens per second on mid-range RTX 3060 Ti cards. Beyond raw speed, the Qwen3 series is being hailed for its 'surgical precision' in structured outputs. Developers are increasingly using the 4B variant to generate high-quality retrieval intent JSON for agentic memory systems, a task traditionally reserved for larger models @vllm_project. As codexistance notes, this 'cheap to infer' profile makes it the preferred backbone for high-volume agentic pipelines.
Join the discussion: discord.gg/lmsys
HuggingFace Research Review
Hugging Face's minimalist smolagents library just reset the bar for agentic performance by ditching JSON for raw Python.
The industry is reaching a tipping point where the 'chat-with-a-bot' era is giving way to the 'execution-centric' agent. Today’s lead story on smolagents highlights a profound shift: complexity is no longer a prerequisite for capability. By leveraging a code-first architecture of under 1,000 lines, Hugging Face has demonstrated that agents writing raw Python outperform those tethered to brittle JSON schemas, achieving a staggering 53.3% on the GAIA benchmark. This 'code-as-action' paradigm is the core thread of today's issue, weaving through ServiceNow's 'Hindsight Reasoning' distillation and NVIDIA’s Cosmos Reason 2 for physical robotics. We are seeing a convergence where reasoning isn't just a linguistic output but a verifiable search process—whether that’s Kimina-Prover solving formal proofs or Open-source DeepResearch executing hundreds of concurrent queries. For builders, the message is clear: the integration tax is dropping thanks to the Model Context Protocol (MCP), and the frontier is moving toward specialized, small, and highly efficient models that can reason, act, and verify in real-time. This issue explores the tools and benchmarks defining this transition from digital assistants to autonomous executors.
Smolagents: Beating GAIA with a 1,000-Line Code-First Architecture
Hugging Face has disrupted the agentic landscape with smolagents, a minimalist library of under 1,000 lines of code that prioritizes a 'code-as-action' paradigm. By allowing models to write and execute raw Python rather than parsing brittle JSON schemas, the framework enables agents to handle complex logic like loops and error recovery with significantly higher reliability. This approach is empirically validated by Hugging Face results on the GAIA benchmark, where the CodeAgent architecture achieved a state-of-the-art 53.3% on the validation set, outperforming much larger monolithic frameworks that rely on traditional tool-calling.
The ecosystem's versatility is further extended through Transformers Agents 2.0, which introduces a modular 'License to Call' for robust tool integration. The library now includes multimodal support, enabling agents to process visual inputs via Vision-Language Models (VLMs) for UI-centric tasks. For developers, the 'integration tax' is slashed by native support for the Model Context Protocol (MCP), allowing fully functional, tool-capable agents to be built in as few as 70 lines of code. To bridge the gap between experimentation and production, the integration with Arize Phoenix provides a critical observability layer, allowing for detailed tracing of nested tool calls and Python execution steps to ensure reliability in live environments.
Open-Sourcing the Future of Autonomous Deep Research
The 'Deep Research' trend is shifting toward open-source transparency with the Open-source DeepResearch initiative, which provides a code-first alternative to proprietary, black-box research assistants. Unlike closed systems, this project utilizes a recursive reasoning loop—Plan, Search, Read, and Review—to execute hundreds of concurrent search queries for synthesizing comprehensive reports. This architecture is powered by the smolagents library and often leverages high-reasoning orchestrators like Qwen2.5-72B-Instruct to manage long-horizon information retrieval.
To foster collaboration, OpenEnv has been introduced as a shared environment for standardizing agent testing and solving 'environment drift' issues. Community-led implementations such as MiroMind-Open-Source-Deep-Research already demonstrate these capabilities in action, integrating the Tavily Search API and DuckDuckGo for real-time retrieval. The efficacy of this approach is backed by performance; the smolagents CodeAgent recently achieved a state-of-the-art 53.3% on the GAIA validation set, proving that executable Python is superior to traditional JSON tool-calling.
Test-Time Scaling and Hindsight Distillation Redefine Agent Reasoning
Innovative techniques in model training are yielding more efficient agents by shifting compute from training to inference. AI-MO/Kimina-Prover demonstrates the power of applying test-time RL search on formal reasoning models to solve complex mathematical proofs. Unlike the hidden chains of thought in proprietary models, Kimina-Prover scales compute during inference to explore and verify logical paths within formal systems like Lean. Industry experts like @_akhaliq highlight this as a critical path toward long-horizon autonomy where agents actively verify their logic.
Efficiency is also being driven by new distillation methodologies. ServiceNow-AI/Apriel-H1 utilizes a 'Hindsight Reasoning' approach to train an 8B parameter model that achieves performance parity with Llama 3.1 70B on complex agentic benchmarks, as noted by @ServiceNow. By refining the model's ability to learn from past execution errors, Apriel-H1 enables high-fidelity planning in resource-constrained environments. Complementing this is the breakthrough in spatial intelligence with Think3D, a framework that allows VLM agents to 'think' in 3D, vital for the next generation of embodied agents.
Standardizing the Agentic Web: From Unified Tool Use to Browser-Native Agency
Hugging Face is standardizing agent-tool interaction through the Unified Tool Use initiative, providing a consistent API across major model families including Llama, Mistral, and Qwen. This architectural shift is now accessible to web developers via Agents.js, a lightweight library that brings tool-calling and multimodal capabilities to the JavaScript ecosystem. Unlike the heavy abstractions of legacy frameworks, Agents.js enables browser-native agency with significantly reduced latency.
The Model Context Protocol (MCP) has matured into the 'USB-C for AI,' enabling developers to decouple tool logic from model logic and build fully functional agents in as little as 50 to 70 lines of code. This modularity is showcased in community projects like sipify-mcp, which connects LLMs to real-time communication services. As noted by @aymeric_roucher, the move toward MCP is slashing the 'integration tax' that previously required custom wrappers for every new data source.
Pixel-Perfect Control: New VLMs and Benchmarks Standardize Desktop Automation
The frontier of GUI automation is rapidly shifting toward 'Computer Use' with the release of Smol2Operator, a post-training framework that optimizes small models for precise interface interaction. This trend is anchored by the Holo1 family of VLMs from Hcompany, featuring a 4.5B parameter architecture that powers the Surfer-H agent. Holo1 notably achieved a 62.4% success rate on the ScreenSpot subset of the ScreenSuite benchmark, significantly outperforming GPT-4V's 55.4%.
Evaluation in this space is becoming more rigorous with ScreenSuite, a comprehensive framework covering over 3,500 tasks across 9 distinct domains. This is supported by ScreenEnv, a sandbox for deploying full-stack desktop agents, while research papers like GUI-Gym and ShowUI highlight the transition from simple web navigation to complex multi-step reasoning. GUI-Gym provides a high-performance environment supporting 100+ FPS for reinforcement learning, as noted by researchers like @_akhaliq.
NVIDIA and LeRobot Advance Physical Agent Reasoning
NVIDIA is bridging the gap between digital reasoning and physical action with the release of NVIDIA Cosmos Reason 2. This 'visual-thinking' architecture enables robotic systems to perform long-horizon planning and complex spatial reasoning, such as predicting the stability of objects before a grasp is attempted. This intelligence is physically grounded by the Reachy Mini platform, a compact humanoid powered by the NVIDIA DGX Spark, which provides the 275 TOPS of compute necessary for real-time inference at the edge.
To address the data scarcity bottleneck in embodied AI, the LeRobot Community Datasets initiative is positioning itself as the 'ImageNet of robotics.' By providing a standardized, open-source hub for robotics data, lerobot enables developers to share and utilize diverse trajectories. Complementing this is Pollen-Vision, a unified API that integrates zero-shot models like Grounding DINO and SAM, allowing agents to interact with novel objects in unstructured environments without retraining.
New Benchmarks Target Reasoning and Industrial Reality
As agents move beyond simple chat, the transition to autonomous execution is being quantified by high-stakes frameworks like GAIA 2. A major breakthrough was recorded by the Hugging Face smolagents CodeAgent, achieving a state-of-the-art 53.3% on the GAIA validation set. Industry experts like @aymeric_roucher emphasize that this 'code-as-action' approach is significantly more robust for handling loops and error recovery.
Industrial and operational readiness is now being measured through IBM Research/AssetOpsBench, evaluating how agents handle real-world maintenance tasks. Simultaneously, DABStep addresses the 'plan-act' misalignment problem in data science workflows. On the NPHardEval Leaderboard, top-tier models like GPT-4o and Claude 3.5 Sonnet are being pushed by reasoning-optimized architectures like OpenAI o1-preview, which has redefined performance in NP-hard reasoning tasks as noted by @_akhaliq.
Pruned Models and Mobile-First Agentic Intelligence
Efficiency at the edge is hitting new benchmarks with the release of Akicou/GLM-4.7-Flash-REAP-50, a model that utilizes Relative Importance-Aware Pruning (REAP) to maintain high-fidelity function-calling capabilities while drastically reducing memory overhead. Meanwhile, the 'functiongemma' series, particularly tooyotta/functiongemma-270m-it-mobile-actions, is redefining on-device automation. With a footprint of just 270M parameters, this model is capable of executing complex mobile tool calls with extremely low latency.
Intel is further accelerating this trend through the Intel Qwen3 Agent initiative. By employing depth-pruned draft models for speculative decoding, Intel has demonstrated a 2x to 3x increase in inference speed on Intel Core Ultra processors. This architecture allows the NPU to handle the drafting while the GPU/CPU verifies, ensuring that sophisticated agents can run locally on consumer laptops with minimal power impact.