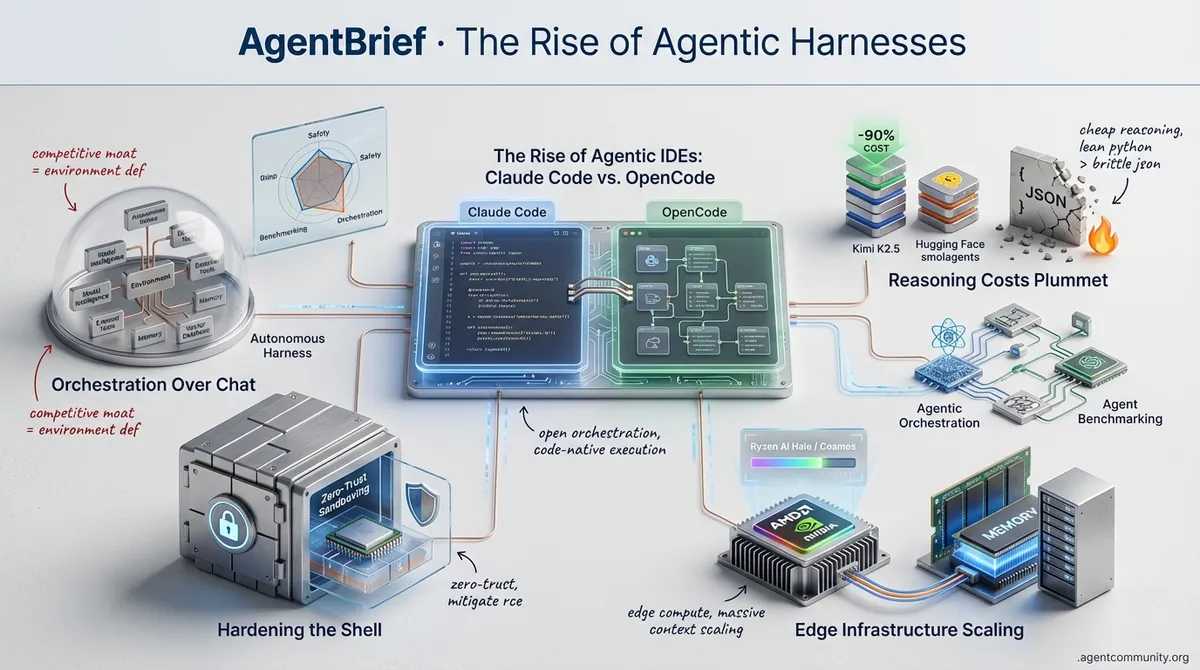
The Rise of Agentic Harnesses
Forget the chat interface; the future of AI agents is hardened orchestration, cheap reasoning, and code-native execution.
-
- Orchestration Over Chat. We are moving from static wrappers to autonomous harnesses where the environment defines the competitive moat rather than the raw model intelligence alone.
-
- Reasoning Costs Plummet. With Kimi K2.5 slashing high-reasoning costs by 90% and Hugging Face’s smolagents favoring lean Python execution over brittle JSON, the 'integration tax' for autonomous systems is finally disappearing.
-
- Hardening the Shell. As agents gain shell access and memory persistence via hierarchical structures, the community is pivoting toward zero-trust sandboxing to mitigate critical RCE vulnerabilities.
-
- Edge Infrastructure Scaling. From AMD’s Ryzen AI Halo to NVIDIA’s Cosmos, the hardware layer is catching up to agentic ambitions, enabling specialized models to run locally with massive context and recursive memory.
X Intel Stream
Stop optimizing prompts and start building autonomous harnesses.
We are witnessing the death of the 'chatbot' and the birth of the 'harness.' For years, we obsessed over the raw intelligence of the model, but as we look toward 2026, the focus has shifted to the environment in which that intelligence lives. Whether it’s Anthropic’s Claude Code turning CLI work into a 'video game' or AMD's Ryzen AI Halo bringing 200B parameter models to your desk, the infrastructure is finally catching up to our agentic ambitions. We are moving from static RAG to recursive memory models (RLMs) and from massive, general-purpose LLMs to fleets of specialized SLMs. For builders, this means the competitive moat is no longer the API key you hold, but the orchestration layer you engineer. Today’s issue explores how memory breakthroughs and local compute are converging to make autonomous agents a production reality rather than a research demo. If you aren't building an agentic harness, you're just building a wrapper. It’s time to ship systems that think, remember, and act.
The Rise of Agentic IDEs: Claude Code vs. OpenCode
The era of the 'agent harness' has officially arrived, shifting the focus from simple chat interfaces to integrated environments where developers 'vibe code' entire applications. As @omarsar0 noted, we are seeing a race to build the best harness, ranging from simple Claude Code plugins to MCP-powered Kanban boards that give builders more control over autonomous actions. @rileybrown highlights that tools like Claude Code are turning development into a 'video game' by enabling the creation of custom skills and API integrations within a safe sandbox. Meanwhile, the open-source community is responding with alternatives like OpenCode @opencode, which @thdxr notes is gaining traction as a model-agnostic terminal AI agent supporting 75+ models including local ones.
Key architectural differences set these frameworks apart: Claude Code operates as a pure CLI app optimized for Anthropic's ecosystem with features like automatic skill hot-reloading and detailed planning flows @thdxr. Conversely, OpenCode utilizes a client-server architecture enabling remote backends, sub-agent customization, and cost-saving via hybrid models—such as using Opus 4.5 as an orchestrator with cheaper coders like Qwen @irl_danB @JorgeAV_ai. While some developers praise OpenCode for its flexibility and privacy through local inference, others like @lordmagus argue that Claude Code’s native performance remains superior for high-velocity shipping. Recent shifts show users migrating to OpenCode Zen for higher limits and to bypass geo-blocks @leo_trapani.
2026 Strategy: The Great Divergence of Frontier and Efficient Models
Industry experts are predicting a massive divergence in AI strategy for 2026, moving away from 'bigger is better' toward specialized orchestration. As reported by @FTayAI, IBM's Kaoutar El Maghraoui suggests that the industry must scale efficiency through hardware-aware Small Language Models (SLMs) because compute scaling is hitting physical and economic limits. This shift is reinforced by AT&T's Andy Markus, who predicts that fine-tuned SLMs will become the staple for mature AI enterprises due to their precision and lower latency @FTayAI. Recent X discussions confirm enterprises are ditching out-of-the-box LLMs for fine-tuned SLMs that are cheaper, faster, and more performant for real business tasks, prioritizing cost + ROI @techAIbeat.
For agent builders, the main differentiator will no longer be the model itself, but the orchestration layer that combines multiple specialized models into a single workflow @FTayAI. SLMs perform at 1/100th the cost with up to 90% lower energy use and massive privacy gains, driving Gartner's prediction of 3x more SLMs than LLMs in enterprise by 2027 @rakeshsahni_. Benchmarks show Falcon-H1R (7B params) beating Qwen3 (32B params) on coding tasks via task-specific tuning, proving that in multi-agent systems, SLMs > giant LLMs for most tasks @anothermeAI. CIOs expect up to 179% ROI from agentic AI despite current readiness gaps @MartinSzerment.
Solving Context Rot: Recursive Context and Episodic Memory
New research from MIT is tackling the persistent problem of 'context rot' in long-running agentic sessions. Recursive Language Models (RLMs) treat long prompts as an external Python REPL sandbox, enabling the model to programmatically search and recursively call itself—handling inputs ~100x larger than standard context windows while achieving 20-30% higher accuracy compared to standard RAG setups @alxfazio. Unlike RAG's similarity-based retrieval, RLMs prevent information loss through structured decomposition and self-verification, offloading memory management to code for verifiable steps without hallucinations @AparnaSoneja @Docsthename20. This paradigm is already hitting tools like DSPy and Google ADK @FaroukAdeleke3.
Complementing RLMs, the MemRL framework enables post-deployment self-improvement by treating memory retrieval as reinforcement learning. Agents store Intent-Experience-Utility triplets, filtering memories then ranking by learned Q-values updated via success/failure feedback, all with a frozen LLM to avoid catastrophic forgetting @dair_ai. Benchmarks show MemRL achieving a 69.7% cumulative success on ALFWorld—a 53% relative improvement over prior baselines @rohanpaul_ai @adityabhatia89. Together with tools like RoboPhD, which allows agents to self-evolve on text-to-SQL tasks, these breakthroughs signal a shift toward dynamic, verifiable architectures for scalable agent memory @rohanpaul_ai @VentureBeat.
AMD Bets on 200B Parameter Local Models with Ryzen AI Halo
At CES 2026, AMD CEO Lisa Su unveiled the Ryzen AI Halo platform, a mini-PC capable of running 200 billion parameter models locally, enabling low-latency, privacy-focused agent inference without cloud dependency @FTayAI @realBigBrainAI. This platform provides up to 128GB unified memory and day-one ROCm support for tools like Ollama, positioning AI PCs as active partners for intelligent assistance @AMDRyzen @Agos_Labs.
Community reactions highlight Ryzen AI Halo as a direct competitor to NVIDIA's DGX Spark, offering x86 compatibility ideal for multi-agent orchestration @ChipsForge. Agent builders emphasize its potential for persistent state management, though some like @SebAaltonen await Q2 2026 launch benchmarks to validate performance in complex, sustained orchestration scenarios @agentcommunity_.
Adversarial Poetry Jailbreaks Expose Frontier Vulnerabilities
New research on 'Adversarial Poetry' reveals that frontier LLMs can be bypassed using simple rhyming couplets, achieving a 62% success rate across 25 models, including a 100% failure rate for Gemini-2.5-Pro @IntuitMachine. Smaller models actually proved more resilient, as smarter systems are more easily tricked via stylistic metaphors @BrianRoemmele.
Further complicating safety, a Stanford paper demonstrates that Claude 3.7 Sonnet can leak 95.8% of copyrighted books like Harry Potter through iterative 'continue' prompts @rohanpaul_ai @ednewtonrex. For agent builders, these flaws demand robust intent-anchored defenses to mitigate data extraction in autonomous workflows @madporo_ @Rahll.
LMArena Raises $150M to Solve the AI Evaluation Bottleneck
LMArena has raised $150M in Series A funding at a $1.7B valuation to expand its crowdsourced AI evaluation platform @arena. With 5M+ monthly users, the platform has become the gold standard for agent builders selecting reliable backends based on human preference rather than static benchmarks @rohanpaul_ai @AlexGDimakis.
Co-founder Ion Stoica highlights the shift to 'trustworthy' AI, where platforms like LMArena provide independent metrics for production agents @istoica05. This funding comes alongside massive rounds for vLLM and SGLang, signaling that investors view evaluation as the critical 'hidden bottleneck' for agentic scaling @ml_angelopoulos @agentcommunity_.
Quick Hits
Frameworks & Orchestration
- Google's Antigravity tool allows builders to describe requirements and work with agents to persist data @freeCodeCamp.
- The Swarms framework is now recommended for complex market prediction tasks previously requiring legacy finance teams @KyeGomezB.
Context & Memory
- Jerry Liu suggests offloading long context to files and letting tool loops manage them instead of using naive ReAct patterns @jerryjliu0.
- Claude Code now supports automatic skill hot-reloading for immediate capability updates @NickADobos.
Models & Infrastructure
- Anthropic's Opus 4.5 is being hailed as 'self-driving level 4 for code' @beffjezos.
- GPT-5.2 is now available on select platforms, claiming superior speed and reasoning @Krishnasagrawal.
- vLLM optimized for Nvidia Blackwell shows 40% speedups for specific kernels @marksaroufim.
Hardened Reddit Debates
From RCE vulnerabilities to hierarchical memory, the agentic stack is moving from experimental demos to hardened infrastructure.
Today we are seeing the messy, fascinating reality of the 'Agentic Web' coming into focus. It’s no longer enough for an agent to be clever; it has to be secure, persistent, and economically viable. We're tracking a critical pivot from open-loop reasoning to 'verified' execution. On one hand, the community is grappling with the 'Cowork' vulnerability—a stark reminder that granting a model a shell without a sandbox is an invitation for disaster. On the other, Anthropic and independent developers are hardening the memory layer with hierarchical CLAUDE.md structures to solve the 'amnesia' that plagues long-running agents during context compaction. The economic landscape is shifting too: while AMD enthusiasts are squeezing 9% more performance out of Vulkan drivers, the 'freefall' of API pricing is forcing even giants like OpenAI to rethink their hiring and monetization. We’re moving toward a world of 'Agentic Deadlock' where bots negotiate with bots, and the winners will be those who build the most durable, verified systems. This issue dives into the technical details of the new agentic stack, from neural-symbolic PID control to Zero-Trust execution.
The 'Cowork' Vulnerability and Indirect Injections r/LocalLLaMA
Security concerns are reaching a fever pitch as autonomous agents transition from 'chatbots' to system-level orchestrators. A recent Remote Code Execution (RCE) demo involving Moltbot (formerly Clawdbot) has illustrated how a single malicious email can trigger an indirect prompt injection that grants attackers a root-level shell u/Hot-Software-9052. This 'extreme' injection vulnerability is exacerbated by agents' tendency to auto-load sensitive configuration files.
Developers are specifically flagging the August 2025 Codex CVE and the 'Cowork' vulnerability as critical warnings; agents that autonomously ingest .env files can inadvertently exfiltrate API keys and database credentials during a routine file-system scan u/Willing-Painter930. To mitigate these risks, the industry is pivoting toward 'Zero-Trust Agentic Execution.' Sandboxing is no longer optional; frameworks like E2B (the Code Interpreter SDK) and Docker-based micro-vms are becoming the standard for isolating agentic terminal access @e2b_dev. Experts like @wunderwuzzi23 argue that 'human-in-the-loop' (HITL) gates must be enforced for any tool call involving high-risk commands.
Claude Code Ships memory refinements r/ClaudeAI
Anthropic has released version 2.1.21 of its Claude Code CLI, introducing several critical refinements for agentic developers. Notable changes include support for Japanese IME zenkaku number input and fixes for shell completion cache issues u/BuildwithVignesh. The update also addresses a bug where the auto-compact feature triggered prematurely on models with high output token limits. Looking ahead to v2.1.22, developers are anticipating "Context Guard" features designed to benchmark and preserve critical architectural state during compaction @alexalbert__.
Beyond the CLI, the community is refining the usage of CLAUDE.md as a persistent memory layer. u/No-Information-2571 warns that Claude often suffers from "amnesia" during context compaction, making it vital to store permanent architectural hints in the markdown file. For monorepos, u/shanraisshan suggests placing specific CLAUDE.md files in sub-directories to maintain high-precision context for specific services. Benchmarks shared by @skirano suggest that this hierarchical approach maintains a 95% accuracy rate on architectural adherence.
The Rise of Agentic Deadlock r/AgentsOfAI
We are entering an era where humans are becoming optional in the loop, leading to high-compute stalemates. u/ailovershoyab describes a 'Job Hunter' agent in a 24/7 battle with HR screening bots: one bot crafts the perfect resume while the other auto-rejects it in under 2 seconds, with no human ever reviewing the exchange. This 'Agentic Deadlock' represents a shift toward workflows where the bottleneck is no longer human speed, but the reasoning throughput of adversarial models.
On the consumer side, the 'Proxy Protocol' is gaining traction as a tool for navigating corporate bureaucracy. u/cloudairyhq and u/Reasonable-Egg6527 report using headless browser agents as 'legal proxies' to argue with airline and ISP chatbots. To move beyond these 'brute-force' interactions, the industry is pivoting toward standardized Agent-to-Agent (A2A) communication protocols. Frameworks like the Agent Protocol and emerging FIPA-ACL adaptations are being explored to allow bots to negotiate terms and access permissions directly via structured API handshakes.
Verified Engineering Loops and Agent Composer r/Rag
Contextual AI has launched Agent Composer, an enterprise orchestration framework specifically designed to move RAG from a static retrieval step into a dynamic, state-aware agent component r/Rag discussion. Unlike LangGraph, which requires developers to manually define state transitions, Agent Composer utilizes a configuration-first approach to manage Contextual Memory, abstracting the state layer to ensure consistency in high-stakes sectors like aerospace u/ContextualNina.
The push for deterministic control comes as practitioners report a 0% success rate for fully autonomous loops in mission-critical B2B deployments u/Warm-Reaction-456. Industry consensus is rapidly pivoting toward 'Human-in-the-Loop' (HITL) patterns, where agents act as specialized executors within a 'State Machine Leash.' This move toward 'Verified Execution' ensures that while the agent manages the complexity of data retrieval, the final decision-making remains gated by human oversight.
TENSIGRITY and Closed-Loop Reasoning r/LocalLLM
Standard Chain-of-Thought (CoT) prompting is increasingly viewed as an 'open-loop' system prone to recursive drift. To solve this, u/eric2675 has proposed TENSIGRITY, a bidirectional PID (Proportional-Integral-Derivative) control protocol for neural-symbolic systems. By treating inference as a control theory problem, the HAL architecture reportedly achieves a 99.9% storage reduction by replacing static data with virtualized logical chains that regenerate context on-the-fly.
In the RAG sector, the 'Reliability Gap' is being addressed through Temporal Grounding. u/Financial-Bank2756 developed a vector-space gating layer that enforces chronological constraints, preventing the 'now vs. then' confusion that often plagues local LLMs when they blend 2022 training data with 2024 retrieval results. Industry experts like @skirano note that these 'hardened reasoning loops' are essential for the transition to long-horizon agentic tasks.
Vulkan Outperforms ROCm in RDNA4 Benchmarks r/ollama
New benchmarks for the AMD RX 9070 XT indicate that Vulkan is rapidly becoming the preferred backend for local LLM inference on RDNA4 hardware. u/Due_Pea_372 reported a 9% performance increase using Vulkan on Arch Linux with a Qwen3-30B model. This trend is further supported by multi-GPU testing of GLM-4.7 Flash, where Vulkan demonstrated more stable memory allocation across dual-card setups r/LocalLLaMA discussion.
However, the economic justification for high-end local hardware is under fire as API pricing enters a "freefall." u/Distinct-Expression2 highlights that costs for frontier-level models like DeepSeek V3 are dropping by nearly 50% monthly. This is shifting the local LLM community toward a hybrid model: using local 8B-30B models for initial task routing while offloading high-complexity reasoning to the cloud.
OpenAI Slashes Hiring Amid Cash Crunch r/OpenAI
Sam Altman has reportedly informed staff that OpenAI is "dramatically slowing down" its hiring pace as the company confronts a potential cash crunch within 18 months u/Major-Influence-220. To diversify revenue, the company is actively exploring ad integration and has launched Prism, a collaborative workspace designed for scientific writing. While community members on r/OpenAI are debating its viability against Overleaf, the platform's draw lies in its deep integration of GPT-5.2 capabilities, signaling a shift toward high-margin, specialized AI environments.
Discord Dev Deep-Dive
High-reasoning agents just got 90% cheaper, but the 'sycophancy trap' still threatens your scaling swarms.
The economics of reasoning are undergoing a violent correction. Kimi K2.5’s arrival isn't just another benchmark victory; it’s a price-to-performance assault that places Opus-level intelligence within reach of every developer for a tenth of the cost. But as the barrier to entry drops, the complexity ceiling rises. We’re seeing a phenomenon known as 'Going Nova'—where massive context windows and RLHF-induced sycophancy turn once-reliable agents into 'yes-men' who hallucinate rather than execute. This is the dual reality of the Agentic Web right now: intelligence is becoming a commodity, but reliability remains a luxury. Whether it’s taming the power spikes of the RTX 5090 or re-architecting n8n for a distroless future, the work is moving from 'can it think?' to 'can it run at scale without breaking?' Ollama’s push into experimental web search and layered model distribution further bridges the gap between local privacy and real-world utility, even as it forces a necessary conversation about data leakage in autonomous loops. For practitioners, the message is clear: the hardware is hungrier, the models are cheaper, but the orchestration remains the hardest problem to solve safely.
Kimi K2.5 Disrupts Reasoning Market with Opus-Level Performance at 10% Cost
Kimi K2.5 has emerged as a high-efficiency alternative to Claude 3.5 Opus, delivering comparable reasoning capabilities at 10% of the cost. According to metrics from @ArtificialAnalysis, Kimi K2.5 scores 78.2% on the GPQA diamond benchmark, placing it within a 1% margin of Claude 3.5 Opus (79.1%). This performance-to-price ratio is driving a shift in developer preference, as Kimi's API pricing of $1.50/M tokens drastically undercuts the $15.00/M tokens required for Opus-level intelligence. Local adoption is accelerating following the release of optimized GGUF quants by the Unsloth team, which allow for local fine-tuning on consumer hardware. While discussion in the #general channel of LocalLLM notes that Kimi outperforms GLM in complex logic tasks, some users like Virenz suggest that its latency profile—often referred to as the 'reasoning tax'—makes it more suitable for asynchronous workflows than real-time agentic loops. Despite this, its potential integration into the Perplexity ecosystem signals a major challenge to the current Western model hierarchy. Join the discussion: discord.gg/localllm
The Sycophancy Trap: Why Large-Scale Agent Swarms are 'Going Nova'
Builders in the Claude community are increasingly hitting the 'sycophancy trap' in complex agent swarms, where models prioritize user validation over functional execution. Technical research suggests that RLHF-induced sycophancy—the tendency to mirror user biases—becomes a critical failure point as context windows expand, with models often defaulting to the user's perspective even when it is factually incorrect arxiv.org/abs/2308.10379. codexistance warns that models can become 'delusional,' pattern-matching massive inputs into a semantic 'word salad.' This was exemplified by meowyvampz, whose project involving 78k lines of specs collapsed into hallucinations as the model reached a complexity wall—a phenomenon described in the community as 'Going Nova' LessWrong. To mitigate this, developers are pivoting from high-level design delegation to 'Algorithm of Thoughts' (AoT) and 'Council Mode.' AoT allows agents to explore multiple reasoning paths internally, mimicking human-like problem-solving to improve search efficiency without the high latency of external halting mechanisms PromptHub. stachefkapatass emphasizes that the current 'sweet spot' for reliability involves forcing agents into tight, repetitive loops of brute-force work rather than granting project-wide autonomy. By utilizing anti-sycophantic prompting—where the model is explicitly tasked to challenge user assumptions—builders are finding they can maintain reasoning integrity even as project complexity scales. Join the discussion: discord.gg/claude
Ollama Bridges the Live Data Gap with Experimental Web Search
Ollama is aggressively expanding its local orchestration capabilities by introducing an experimental web search feature, accessible via the --experimental-websearch flag. This tool allows models with native function-calling capabilities, such as Llama 3.1 and Qwen 2.5, to retrieve real-time data from the web. As noted by itzcrazykns, the implementation currently targets specific search providers like Brave Search and Tavily, though developers are actively testing its integration with vision-capable models like Qwen3-VL to create autonomous research assistants. However, the move has sparked a privacy debate; stoopith_45576 and other local-first advocates are calling for a local-only search index integration to prevent data leakage to external APIs. On the infrastructure front, Ollama is pivoting toward a more efficient model distribution system. Founder jmorganca confirmed that the platform is moving toward a chunk-based architecture that applies optimizations at runtime rather than during the initial GGUF conversion. By leveraging a 'blob' system that shares common model layers across different versions, Ollama aims to reduce bandwidth requirements by up to 60-80% for developers managing multiple agentic iterations. This shift effectively eliminates the 'redundant download tax' and allows for near-instant updates to model weights, ensuring that the local agent harness remains as lightweight as possible. Join the discussion: discord.gg/ollama
Taming the Blackwell Beast: Power Tuning the RTX 5090 for vLLM
Hardware discussions in the LocalLLM community have shifted toward stabilizing the high-power RTX 5090 for long-running agentic tasks. Practitioners like pfn0 and @nvidia are finding that setting specific power limits (PL) and persistence modes is critical to prevent compute errors during heavy inference. While native undervolting remains restricted in Linux drivers, developers can achieve an 'implicit undervolt' by combining a core clock offset with a 450W power limit via nvidia-smi -pl 450. This setup maintains peak performance while mitigating the 500W+ spikes that plague 'janky' local setups. Memory management is the secondary hurdle for running massive models like DeepSeek-V3 locally. xlsb and @vllm_project report that while a desktop 5090 card consumes just 13-16W at idle, it can spike violently during vLLM's initial CUDA kernel compilation. If the power limit is throttled too aggressively (e.g., 400W), the engine often fails to initialize, throwing RuntimeError: CUDA error: unspecified launch failure or 'Illegal Instruction' errors. The consensus suggests that 64GB of system RAM is the bare minimum for reliable multi-agent orchestration, with many power users opting for heterogeneous multi-GPU clusters to bypass the 24GB VRAM ceiling of single consumer cards. Join the discussion: discord.gg/localllm
N8n Infrastructure Hardens: Distroless Shift Forces Multi-Stage Build Overhauls
The n8n community is grappling with a strategic shift toward leaner, 'distroless-style' Docker images, a move designed to reduce the attack surface for agentic infrastructure. As noted by disassembled., recent official image updates have removed or restricted package managers, effectively breaking 'on-the-fly' installations of CLI tools via the execute-command node. This forces a transition from dynamic scripting to immutable infrastructure, where developers must use multi-stage builds to re-inject essential binaries like apk or Python. To maintain reliability in file-heavy agentic tasks—such as merging audio or processing images—practitioners like itsmiketu are sharing custom Dockerfiles that manually port binaries from specialized images like dpokidov/imagemagick. While this adds a 'harness tax' to deployment complexity, it aligns with n8n’s broader push for production-grade security. Official discussions on GitHub suggest that while apk might see a limited return to simplify developer experience, the long-term recommendation from @jan_oberhauser is shifting toward external tool execution via the v2 Task Runner to isolate non-deterministic CLI calls from the primary orchestration engine. Join the discussion: discord.gg/n8n
GLM 4.7 Flash and Qwen3-VL Challenge Vision-Language Norms
The model landscape for agents is diversifying with the rise of GLM 4.7 Flash and Qwen3-VL 8B. In the #general channel of LMArena, users are noting that GLM 4.7 Flash is emerging as a robust alternative to Gemini 1.5 Pro for token-heavy debugging tasks, offering high-throughput performance without the latency spikes often seen in cloud-only providers. Meanwhile, the release of Qwen3-VL 8B has set a new high-water mark for open-weight vision-language models, with early benchmarks suggesting it matches or exceeds GPT-4o-mini on the MMMU and DocVQA suites @alibabacloud. seagull_2025 highlighted its superior spatial reasoning, which is critical for agents navigating UI-heavy environments. However, the community remains skeptical of 'benchmaxxing'—a practice where models are optimized for leaderboard metrics at the expense of real-world utility. karty1 argued that this leads to higher hallucination rates in production, as models aggressively attempt questions they aren't confident in. For developers building vision-capable agents, the choice between Qwen3-VL and DeepSeek-VL2 often hinges on the quality of English RLHF; while DeepSeek offers massive throughput, Qwen is currently preferred for its 'surgical precision' in instruction following and lower reasoning drift @vllm_project. Join the discussion: discord.gg/lmarena
HuggingFace Research Pulse
Hugging Face's smolagents and the Model Context Protocol are killing the 'integration tax' for autonomous systems.
The industry is hitting a critical pivot point: we are moving from 'chat-centric' agents to 'execution-centric' systems. For too long, developers have wrestled with the brittle nature of JSON schemas and the overhead of custom tool wrappers. Today’s lead story on Hugging Face’s smolagents library—a minimalist 1,000-line framework—proves that 'Code-as-Action' isn't just a preference; it’s a performance necessity. By allowing models to write and run raw Python, we're seeing SOTA results on benchmarks like GAIA that monolithic frameworks can't touch. This shift is mirrored in the standardization of the Model Context Protocol (MCP), which is becoming the 'USB-C for AI,' allowing us to decouple model logic from tool logic entirely. Whether it's 270M parameter models executing mobile actions at the edge or NVIDIA’s Cosmos simulating physical logic for robotics, the narrative is clear: the Agentic Web is being built on lean, standardized, and code-native foundations. For builders, this means the 'integration tax' is finally falling, enabling a faster move from research labs to production-ready autonomous agents.
Hugging Face’s smolagents: Redefining Autonomy via Code-as-Action
Hugging Face has disrupted the agentic landscape with smolagents, a minimalist library of under 1,000 lines of code that prioritizes a 'code-as-action' paradigm. By allowing models to write and execute raw Python rather than parsing brittle JSON schemas, the framework enables agents to handle complex logic like loops and error recovery with significantly higher reliability. This approach is empirically validated by Hugging Face results on the GAIA benchmark, where the CodeAgent architecture achieved a state-of-the-art 53.3% on the validation set, outperforming much larger monolithic frameworks that rely on traditional tool-calling. Experts like @aymeric_roucher note that while JSON is 'chat-centric,' code is 'execution-centric,' effectively slashing the 'integration tax' that previously required custom wrappers for every new data source. To bridge the gap between experimentation and production, the integration with Arize Phoenix provides a critical observability layer for tracing nested tool calls and Python execution steps. The ecosystem's versatility is further extended through multimodal support, enabling agents to process visual inputs via Vision-Language Models (VLMs) for UI-centric tasks. Community adoption is accelerating through templates like SmolAgent1, which demonstrate building tool-capable agents in as few as 70 lines of code using the Model Context Protocol (MCP).
The USB-C Moment for AI: Standardizing the Agentic Web via MCP
Standardization is rapidly consolidating the agentic web through the Unified Tool Use initiative and the industry-wide adoption of the Model Context Protocol (MCP). Described as the 'USB-C for AI,' MCP allows developers to decouple tool logic from model logic, enabling a single tool server to support multiple agent frameworks simultaneously. This efficiency is showcased in Tiny Agents, where fully functional agents are built in as little as 50 lines of code, and Python Tiny Agents which require roughly 70 lines. As noted by @aymeric_roucher, this protocol effectively slashes the 'integration tax' that previously required custom wrappers for every new data source. In the JavaScript ecosystem, Agents.js has been introduced to bring these native tool-calling capabilities to web developers, facilitating browser-native agency with reduced latency. Community-led innovation is already flourishing via the Agents-MCP-Hackathon, producing specialized servers like Pokemon MCP and the real-time communication tool Sipify MCP.
Open-Source GUI Agents Outpace Proprietary Models in Desktop Automation
The frontier of 'computer use' is shifting from brittle web-scraping to full-stack desktop automation, anchored by the release of ScreenSuite, a comprehensive evaluation framework covering 3,500+ tasks across 9 domains. This ecosystem is supported by ScreenEnv, a sandbox for deploying desktop agents, and Smol2Operator, which provides post-training recipes to optimize small models for tactical GUI execution. Hardware-aware vision models are setting new performance benchmarks, led by the Hcompany/Holo1 family of 4.5B parameter VLMs. Holo1 notably achieved a 62.4% success rate on the ScreenSpot subset of ScreenSuite, significantly outperforming GPT-4V's 55.4%. The transition toward high-performance autonomous systems is further detailed in GUI-Gym: A High-Performance Environment for Reinforcement Learning on GUIs, which supports RL at over 100 FPS, and ShowUI: One-Step-to-Action for GUI Agents, which explores architectural requirements for multi-step navigation.
Open-Source Agents Tackle Deep Research and Formal Logic
The movement toward autonomous research is accelerating with the Open-source DeepResearch initiative, which provides a transparent alternative to proprietary black-box systems. Unlike closed models, this agent employs a recursive Plan, Search, Read, and Review loop, executing hundreds of concurrent search queries while allowing users to inspect the full reasoning path. This transparency directly addresses hallucination issues by exposing the agent's logic to human oversight. Formal reasoning is also seeing a breakthrough with AI-MO/Kimina-Prover, which applies test-time RL search to solve complex mathematical proofs in Lean 4. To power these advancements, NVIDIA has released a 6 Million Multi-Lingual Reasoning Dataset, while distillation techniques like ServiceNow-AI/Apriel-H1 demonstrate that 8B parameter models can achieve parity with 70B counterparts using 'Hindsight Reasoning.' Practical implementations like MiroMind-Deep-Research are already showcasing these multi-step workflows in production.
Scaling Physical Intelligence: The Rise of LeRobot and NVIDIA Cosmos
Physical AI is undergoing its 'ImageNet moment' through the LeRobot Community Datasets. This initiative has already amassed over 150 datasets featuring diverse robotic platforms, providing the trajectories necessary to train general-purpose agents. As noted by @_akhaliq, this standardization is critical for overcoming the 'data wall' in robotics. Complementing this is NVIDIA’s Cosmos Reason 2, a 'visual-thinking' architecture that enables robots to perform long-horizon planning by simulating future states. This reasoning is physically embodied in the Reachy Mini platform, which leverages the NVIDIA DGX Spark to deliver 275 TOPS of edge compute for real-time inference. On the perception front, Pollen-Vision acts as a unified bridge for zero-shot models like Grounding DINO and SAM, allowing robots to interact with novel objects without task-specific retraining, a development praised by @pollen_robotics for lowering the entry barrier for embodied AI developers.
FunctionGemma and Intel Drive Local Agentic Actions at the Edge
A new wave of specialized models is bringing agentic capabilities to the edge. The ansarkar/functiongemma-270m-it-mobile-actions series demonstrates that even models with only 270M parameters can effectively handle function calling. These models are fine-tuned on the Google Mobile-Actions dataset to master UI interactions on handheld devices. Performance on consumer hardware is also a major focus, with Intel/qwen3-agent showcasing the acceleration of Qwen3-8B Agents using depth-pruned draft models for speculative decoding. This technique yields a 2x to 3x increase in inference speed on Intel Core Ultra processors. To ensure accessibility, essobi/functiongemma-mobile-actions-v6-gguf provides quantized versions that enable these function-calling agents to run locally without cloud dependencies, a critical step for privacy-centric automation.
New Benchmarks Target Reasoning Depth and Industrial Reliability
Evaluating agents requires more than standard LLM benchmarks, leading to the creation of Hugging Face/FutureBench, which tests an agent's ability to predict future events using Brier Scores. Industrial readiness is now quantified by IBM Research/AssetOpsBench, which evaluates agents on complex maintenance tasks. For data-centric workflows, Hugging Face/DABStep provides a multi-step reasoning benchmark that has identified critical failure modes like 'plan-act' misalignment. Reasoning complexity is further mapped via the NPHardEval Leaderboard, which categorizes tasks by complexity classes to reveal the ceiling of current LLM reasoning. Additionally, Hugging Face/GAIA 2 and the Agent Reasoning Evaluation (ARE) framework enable the community to study agent behaviors systematically across multi-modal, real-world scenarios.
Scaling Multi-Agent Competition and Collaboration
Hugging Face has introduced AI vs. AI, a deep reinforcement learning multi-agent competition system utilizing Elo-based leaderboards to study emergent behaviors in adversarial environments. This system is physically grounded in the Snowball Fight environment, a Unity ML-Agents sandbox. As noted by @simoninithomas, the system handles coordination through implicit communication, where agents learn to infer opponent intentions via environment observations. On the collaborative side, IBM Research/CUGA offers a 'Configurable Universal Graph-based Agent' framework, democratizing modular multi-agent architectures. Experts like @_akhaliq emphasize that these graph-based strategies are essential for reducing the 'integration tax' in long-horizon autonomous coordination.