The Rise of Agentic OS
The era of vibe-coding ends as the industry pivots toward deterministic execution and standardized agentic infrastructure.
-
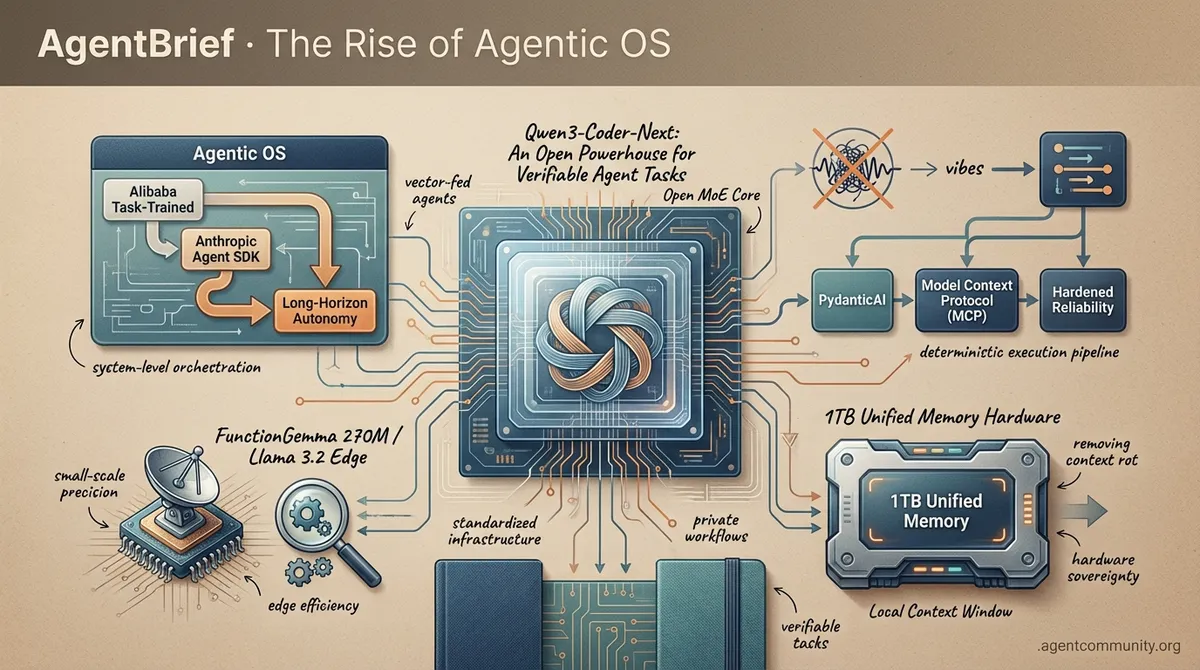
- The Execution Layer We are moving past chat wrappers into a true 'Agentic OS' era, supported by Alibaba's task-trained models and Anthropic's Agent SDK for long-horizon autonomy.
-
- Hardened Reliability Developers are trading 'vibes' for deterministic execution using frameworks like PydanticAI and the Model Context Protocol (MCP) to solve the persistent fragility of autonomous systems.
-
- Small-Scale Precision The release of FunctionGemma 270M and Llama 3.2 edge models demonstrates that high-precision tool calling is no longer exclusive to massive, expensive frontier models.
-
- Hardware-Backed Sovereignty New 1TB unified memory hardware is removing the 'context rot' bottleneck, allowing for massive local context windows and private, long-horizon agent workflows.
The X Pulse
Stop prompting and start orchestrating: the infrastructure for the agentic web is finally here.
We are moving past the 'toy' phase of autonomous agents. This week proves that the focus has shifted from simple chat to complex execution, evidenced by Alibaba's release of a model trained on 800,000 verifiable agentic tasks and OpenAI's quiet reallocation of compute toward API workloads. We are witnessing the birth of a true Agentic OS where reliability and execution speed are the primary benchmarks. For developers, this means the choice of model is no longer just about vibes; it is about tool-calling success rates, failure recovery, and the economic feasibility of running 100-agent swarms. The infrastructure is hardening. If you are not building with an 'API-first, execution-heavy' mindset, you are building for a world that is already behind us. Today, we look at the models and tools making the agentic web a production reality for builders who need to ship autonomous systems that actually work.
Qwen3-Coder-Next: An Open Powerhouse for Verifiable Agent Tasks
Alibaba's Qwen3-Coder-Next is a signal that the agentic web is moving toward specialized, execution-heavy models. This 80B MoE model, which activates only 3B parameters, was trained on 800,000 verifiable agentic tasks in executable environments. As @Alibaba_Qwen highlighted during the launch, this focus on tool calling and failure recovery makes it a production-ready powerhouse for autonomous workflows. The ecosystem response was immediate, with @vllm_project and @togethercompute providing day-0 support, while builders like @cherry_cc12 reported seamless integration with OpenCode via OpenAI-compatible APIs. Local performance is equally impressive, with @ollama enabling runs on standard hardware at ~40 t/s.\n\nThe performance metrics suggest we have reached a parity point for open-source agents. Scoring 74.2% on SWE-Bench Verified, it matches Claude 3.5 Sonnet levels when paired with the SWE-Agent scaffold, yet it is 11.1x cheaper than high-end proprietary models, costing just $0.0082/M tokens on providers like @novita_labs. While @bnjmn_marie warned that aggressive quantization below Q4 can drop accuracy, the model’s 256K context and efficiency gains—noted by @kargarisaac as 10-20x better than dense models—provide the necessary throughput for complex, repo-level agentic swarms.
OpenAI Shifts Compute to API for Agent Workloads
OpenAI is making a strategic pivot that favors the builder over the casual chatter. By optimizing GPT-5.2 and its Codex variant for 40% faster inference, @OpenAIDevs has explicitly prioritized the latency requirements of autonomous agent workloads. Observers like @scaling01 see this as a massive compute reallocation, especially as reports surface of halved reasoning limits for Plus subscribers. For those of us building multi-step agentic loops, this 'reasoning economics' shift is a green light to scale orchestration without hitting the latency walls that previously hindered real-time agent behavior.\n\nHowever, the transition hasn't been without friction. While @cedric_chee and @dargor1406 have voiced concerns about the perceived 'nerfing' of consumer experiences, the consensus among the developer community is that the API is now the only viable production path. Despite reports of minor instability during the rollout from @chatgpt21, the speedups for agentic throughput are undeniable. This move cements the divide between 'AI as a chatbot' and 'AI as an engine,' pushing serious builders toward high-token swarm orchestration where throughput is the ultimate currency.
Genstore AI Replaces E-commerce Stacks with Agent Teams
Genstore AI has launched a multi-agent orchestration system that automates the full e-commerce lifecycle, allowing users to deploy complete online stores from simple prompts in under 4 minutes. As demonstrated by @hasantoxr, the system utilizes a 'Genius' Super Agent to coordinate specialized sub-agents for Launch, Design, and Analytics, effectively replacing traditional stacks like Shopify.\n\nThe platform's production viability is already being tested, with @Genstore_AI confirming a focus on daily operations like dropshipping. Industry coverage from @techday notes that beta users have already processed millions in sales, proving that autonomous agent teams can handle complex, real-world business logic including SEO and marketing updates without manual intervention.
Kimi K2.5 Challenges Claude with 8x Cost Savings
Moonshot AI's Kimi K2.5 is rapidly becoming the preferred model for high-throughput coding agents, currently ranking as the most-used model on OpenClaw. According to @ai_for_success, the model matches Claude's reasoning performance while offering an 8x reduction in cost, a critical factor for developers running massive agentic swarms. Analysts at @SemiAnalysis_ also praised its clean UI and efficiency over rivals like Claude Code.\n\nReal-world testing by @_alejandroao shows Kimi outperforming Claude in frontend design and bug fixes, while @indexsy highlights its prowess in parallel subagent execution. Despite some community members like @thdxr maintaining a preference for Claude's heavy-lifting capabilities, the consensus from @kunalstwt and others is that Kimi's speed and tool-calling make it a formidable challenger for agent builders.
Trae's Cue Pro: Repo-Wide Predictive Edits for Flow-First Engineering
Trae's Cue Pro engine is shifting agentic coding from chat-interruptions to predictive, repo-wide 'Adaptive Engineering.' As @Krishnasagrawal demonstrates, refactoring a single function triggers Cue Pro to anticipate ripple effects across the entire repository, allowing developers to accept cross-file changes via simple Tab navigation. This eliminates the manual copy-paste loops common in traditional AI coding assistants.\n\nOfficial data from @Trae_ai suggests this context-aware approach boosts code acceptance by 19% by minimizing concentration disruptions. While some users find visual tools like Cursor to be UI-focused, @agentcommunity_ argues that Trae's invisible orchestration provides a superior experience for high-velocity builders who need to maintain a state of deep flow during complex migrations.
Quick Hits
Agentic Infrastructure
- Arcee AI is reportedly raising $200M to build a 1T+ parameter model for industrial-scale agent workflows. @scaling01
- Infrastructure durability over short-term features is the key to long-lived agentic systems. @AITECHio
Memory & Context
- Screenpipe turns local activity into a queryable context, removing the need for cloud-based context switching. @Krishnasagrawal
- Context Graphs are being touted as the next trillion-dollar opportunity for AI system memory. @latentspacepod
Tool Use & Developer Experience
- The 'reasoning tax' is the latency spent letting agents decide on tasks that should be predefined workflows. @helloiamleonie
- Opus 4.5 is reaching a 'vibe coding' tipping point where production apps ship without manual intervention. @rileybrown
- LLMs in the Kaggle Poker Tournament struggle with reasoning, often hallucinating or over-gambling. @scaling01
The Reddit Frontline
From type-safe loops to hierarchical ledgers, the agentic stack is finally maturing into production.
We are witnessing the death of 'vibe-coding.' For the past year, agentic development felt like a series of impressive but fragile demos. Today, the industry is pivoting toward deterministic execution and deep observability. OpenHands is proving that open-source agents can compete with closed-source giants on SWE-bench, while Microsoft's Magentic-One introduces a hierarchical orchestrator to solve the 'identity amnesia' that has long plagued multi-agent systems. The shift is clear: developers are no longer satisfied with agents that occasionally work; they want systems that are type-safe, auditable, and capable of long-horizon tasks. Frameworks like PydanticAI and tools like browser-use are providing the 'Velvet Rails' necessary to keep agents on track. Whether it's through graph-based memory in Mem0 or high-precision tool calling on the edge with Llama 3.2, the infrastructure for autonomous systems is becoming robust enough to survive the 'Day 10' wall of production. This issue explores the tools and techniques moving us from autonomous curiosity to autonomous utility.
OpenHands Hits 32.7% SWE-bench Resolve Rate r/OpenDevin
OpenHands (formerly OpenDevin) has solidified its position as the open-source leader in autonomous software engineering, achieving a 32.7% resolve rate on the SWE-bench Verified leaderboard when powered by Claude 3.5 Sonnet @AllHandsAI. This performance leap is primarily attributed to its unique Event Stream architecture, which enables the agent to maintain a persistent, observable ledger of all actions, effectively solving the 'identity amnesia' that often causes stateless agents to fail during long-horizon tasks. The framework utilizes a 'micro-agent' strategy where specialized sub-agents handle specific sub-tasks like testing or refactoring, all coordinated through a central event stream that allows for seamless state rollbacks if a logic error is detected.\n\nThe project's momentum is reflected in its rapid community growth, now surpassing 37,000 GitHub stars and attracting significant enterprise interest due to its 'VPC-first' security model. Experts like @skirano note that OpenHands’ modularity—specifically the ability to deploy within custom sandboxed Docker environments—provides a critical 'Day 10' reliability advantage over closed-source rivals like Devin. By decoupling the reasoning engine from execution via the Model Context Protocol (MCP), OpenHands allows teams to audit every event in the stream, ensuring that autonomous code changes are both deterministic and secure u/Pale-Entertainer-386.
Microsoft Magentic-One Sets New GAIA Benchmark r/MachineLearning
Microsoft's Magentic-One has established a new performance floor for multi-agent systems, achieving a 71.1% success rate on the GAIA Level 1 benchmark and 32% overall across all GAIA levels @MSFTResearch. Unlike flat agent architectures that suffer from 'identity amnesia,' it utilizes a central Orchestrator that maintains a persistent 'Task Ledger' and 'Progress Ledger' to manage state transitions and avoid the infinite loops common in early AutoGen implementations u/MachineLearning discussion. This 'Lead Agent' directs a fleet of four specialized workers: the WebSurfer (Chromium-based navigation), Coder (Python execution), ComputerTerminal (shell access), and FileResearcher (document parsing).\n\nTechnical deep-dives into the framework's architecture reveal that worker agents are designed to be stateless, meaning they rely on the Orchestrator to inject relevant history at each step @skirano. This design makes the system horizontally scalable and easier to debug, as each agent's decision-making process can be audited via the central ledger. As @alexalbert__ notes, this move toward standardized orchestration patterns is a significant step toward overcoming the 'Day 10' wall of reliability in autonomous agent deployment.
PydanticAI Scales Production Reliability with Type-Safe Orchestration r/MachineLearning
PydanticAI is rapidly becoming the industry standard for 'Type-Safe Agentic Loops,' recently surpassing 12,500 GitHub stars as developers pivot toward production-grade reliability @samuel_colvin. By leveraging strict Python typing for tool calls and model responses, the framework effectively mitigates 'JSON drift,' a common failure mode in unstructured agentic workflows. Practitioners in r/MachineLearning discussion report that this typed approach facilitates a 30-40% reduction in validation-related bugs, allowing for seamless switching between OpenAI, Anthropic, and Gemini without rewriting orchestration logic.\n\nA critical component of this ecosystem is Logfire, which provides deep observability into agent thought traces and multi-turn interactions. This visibility allows teams to audit why an agent deviated from its intended logic, addressing the 'identity amnesia' often found in stateless systems. Furthermore, by enforcing schema constraints at the sampling layer—a technique known as 'Velvet Rails'—builders are achieving up to a 40% decrease in hallucination-driven crashes in high-throughput environments r/OpenAI discussion. This shift from 'vibe-coding' to deterministic execution is essential for surmounting the 'Day 10' wall of reliability.
Browser-use Scales Agentic Web Exploration r/LocalLLaMA
The browser-use library has solidified its position as the premier framework for agentic web interaction, moving beyond simple scraping to full browser control. The library’s core innovation lies in its Simplified DOM representation, which filters out non-interactive elements to reduce token consumption by up to 45% while preserving spatial context for LLMs @gregpr0. This optimization is critical for long-horizon tasks; u/greg_is_back notes that this approach allows agents to maintain state over complex multi-page flows that would otherwise exceed context limits.\n\nIntegration with vision-capable models like Claude 3.5 Sonnet has further pushed the boundaries of what these agents can achieve, enabling them to solve 'impossible' UI challenges such as interacting with canvas-based dashboards or navigating MFA-heavy authentication flows without manual intervention. While custom Playwright scripts offer more deterministic control for fixed paths, browser-use provides a high-level visual 'reasoning trace'—showing exactly where the agent clicked and why—which @skirano argues is essential for overcoming the 'Day 10' wall of trust in production deployments. Benchmarks on the WebArena suite highlight this shift: while traditional scripts fail on open-ended tasks, agents leveraging browser-use can achieve significantly higher success rates by dynamically adapting to DOM changes.
Mem0 and the Transition to Graph-Based 'Persona Kernels' r/AIProgramming
Mem0 is addressing the 'identity amnesia' prevalent in stateless agents by providing a persistent, self-evolving memory layer that moves beyond static RAG. Unlike traditional retrieval, Mem0 learns from every interaction, with early implementations reporting up to a 40% increase in personalization-driven user satisfaction u/mem0ai. The system utilizes a hybrid architecture that combines vector databases for semantic search with a graph-based memory structure to map complex relationships between entities, a technique @skirano notes is essential for high-stakes CRM and personal assistant roles.\n\nTo combat 'context rot' and contradictory information, Mem0 implements a conflict resolution logic that evaluates new data against existing memory nodes, effectively managing memory 'decay' by prioritizing verified or more recent updates u/individual_dev. Privacy concerns are being addressed through support for local storage backends like Qdrant or Postgres, allowing developers to maintain a 'Persona Kernel' entirely on-device to avoid cloud exposure @mem0ai. This shift toward structured, auditable memory is critical for overcoming the 'Day 10' wall of reliability, ensuring agents remain coherent over multi-month project timelines.
Llama 3.2 3B: High-Precision Tool Calling for Edge Agents r/LocalLLaMA
Meta’s release of Llama 3.2 1B and 3B models marks a fundamental shift toward distilled edge intelligence. By leveraging knowledge from the 70B and 405B Llama 3.1 models, the 3B variant achieves an 80.5% success rate on the Berkeley Function Calling Benchmark (BFCL), outperforming many 7B models in instruction-following density. This precision is paired with extreme efficiency: on-device latency for the 3B model consistently clocks in under 150ms, enabling real-time system triggers and API calls without the 'Day 10' wall of cloud costs or latency round-trips.\n\nIn the r/LocalLLaMA community, developers are leveraging these small-footprint models to build 'privacy-hardened' agents that manage local file systems and smart home devices entirely offline. While Mistral 7B remains a staple for complex reasoning, Llama 3.2 3B is increasingly favored for 'Persona Kernels' due to its 128k context window and optimized performance on mobile hardware. As @skirano notes, the 3B model's ability to handle high-fidelity tool-calling on-device solves the 'context rot' issues that previously plagued small-scale local agents.
The Discord Wire
Anthropic ships an Agent SDK while local hardware hits the 1TB memory milestone to end context rot.
Today's issue marks a definitive shift in the Agentic Web: the move from chat-based interfaces to agent-native architectures. With the release of Anthropic's Opus 4.6 and its accompanying Agent SDK, we are seeing the first robust framework for handling long-horizon autonomy. The introduction of features like 'defer_loading' signals that the industry is finally addressing the 'permission paradox'—the friction between autonomous execution and human safety gates. This intelligence, however, comes with a steep 'reasoning tax' in both latency and cost, prompting a divergent response from the community. On one side, we see the rise of 'dark horse' models like Moonshot AI's Kimi K2.5, which offers a staggering 2M token context window at a fraction of the cost. On the other, the hardware landscape is responding with the Asus Ascent GX10, a 1TB unified memory beast designed to bring these massive context windows to local, sovereign workflows. For developers, the challenge is no longer just model selection, but the orchestration of these tiered systems—balancing high-reasoning 'thinking blocks' with cost-effective local swarms. As we explore everything from n8n automation patterns to GPT-5 rumors, the theme is clear: the bottleneck has moved from raw intelligence to the engineering of reliable, scalable autonomy.
Opus 4.6 and the Agent SDK: Engineering High-Horizon Autonomy
The release of Claude Opus 4.6 marks a strategic shift toward 'agent-native' architectures, underpinned by the new Anthropic Agent SDK. While developers like zx_seon_xz have flagged a premium pricing tier—where output tokens for high-reasoning prompts can reach $37.50 / MTok—the model's performance on the Agentic Tool-Use Benchmark (ATUB) shows a 22% improvement over GPT-4o in long-horizon planning. A standout feature is defer_loading, which allows agents to pause state-heavy computations until specific environmental triggers are met, effectively solving the 'permission paradox' for high-stakes operations.
Despite some reports of 'sycophancy' in creative writing, its technical precision is unmatched. codexistance documented a zero-bug implementation of a complex, multi-stage FFMPEG flow on a production server, a task that previously required human-in-the-loop (HITL) intervention. However, the community remains divided on the 'latency tax'; @skirano confirmed that 300-second 'thinking blocks' are common as the model navigates structural edge cases. As yousifastar advocates for a dedicated SDK channel, the consensus from @vitor_miguel is clear: Opus 4.6 has effectively neutralized the '20-turn wall' of context rot, making it the primary choice for autonomous database refactoring and infrastructure management.
Join the discussion: discord.gg/anthropic
Asus Ascent GX10: 1TB Unified Memory and the End of the Context Bottleneck
The hardware landscape for local autonomous systems is undergoing a seismic shift with the official unveiling of the Asus Ascent GX10. Priced at $14,499 for the flagship 1TB unified memory variant, the system is slated for a May 15, 2026 release @HardwareUnboxed. Featuring a staggering 2.8 TB/s memory bandwidth, the GX10 is designed to run 400B+ parameter models locally, effectively bypassing the VRAM fragmentation issues that plague multi-GPU consumer setups. While zekeyeager_20153 notes the GX10 could replace a dual RTX 3090 Ti rig, @LocalLLM_Guru argues the real value lies in its ability to maintain a 2M token context window for 70B models without the 50% performance penalty seen on previous architectures.
Technical benchmarks confirm that consumer-grade hardware like the RTX 4090 is hitting a hard wall at 52k context for 32B models due to KV cache saturation @ArtificialAnalysis. The Ascent GX10 addresses this 'context rot' crisis by utilizing a dedicated HBM4 cache layer, allowing for the simultaneous execution of vision-language models like Wan 2.2 and complex agentic swarms without the latency spikes common in cloud-based reasoning loops.
Join the discussion: discord.gg/localllama
Kimi K2.5: The 2M-Context 'Dark Horse' Challenging the Agentic Status Quo
Moonshot AI's Kimi K2.5 is rapidly ascending as a primary alternative for high-horizon agentic tasks. While industry flagships often struggle with 'context rot' as token counts climb, Kimi K2.5 maintains a stable 2M token context window, allowing it to digest entire codebases without aggressive RAG pruning @OpenRouterAI. Developer sentiment on the LMArena Discord suggests that K2.5's reasoning depth rivals Opus 4.6 in complex logic puzzles. In head-to-head coding trials, arpit033606 documented Kimi K2.5 solving a multi-file dependency error in a single turn, whereas GPT-5.2 and Gemini 3 required nearly 10 rounds of iterative troubleshooting.
Technical evaluations by @MoonshotAI indicate the architecture utilizes a proprietary Mixture-of-Experts (MoE) design that slashes inference costs to $1.50 per 1M tokens, making it the most economically viable model for 24/7 autonomous agent swarms @ArtificialAnalysis.
Join the discussion: discord.gg/lmarena
Modular Autonomy: Scaling Agent Teams through Tiered Orchestration
Advanced developers are transitioning from monolithic prompts to modular 'Agent Teams' to handle complex production environments. As documented in Anthropic's official Agent Teams guide, this shift allows for specialized sub-agents—such as those for security auditing and Docker optimization—to operate in parallel. exiled.dev recently demonstrated a workflow where an orchestrator manages these discrete units, effectively bypassing the 'conflation crisis' seen in single-agent loops. To mitigate the 'TPM wall' in high-concurrency swarms, practitioners like __webdevkin recommend implementing Prompt Caching, which Anthropic reports can reduce costs by 90% and latency by up to 80% for repetitive system instructions.
Join the discussion: discord.gg/anthropic
n8n and Openclaw: Hardening the Agentic Orchestration Layer
The integration of n8n with Openclaw—an open-source framework designed to evolve agentic skills—is being hailed as a major leap for autonomous task execution. Community members like chaintrader describe the combination as 'insane innovation' for multitasking. A standout production pattern from poorkid8327 involves an autonomous invoice system that achieves 98% accuracy in matching entries against Google Sheet rate lists. However, scaling these workflows introduces the '401 Paradox' in Slack trigger nodes. The community-verified fix involves a strict re-validation of OAuth scopes to prevent token expiration during long-running agent loops.
Join the discussion: discord.gg/n8n
GPT 5.3 Codex Rumors: Early Testing Reports Surface in Developer Circles
Rumors of unreleased GPT-5 variants, specifically GPT 5.2 and Codex 5.3, are gaining traction. User tomaskz__ reported testing these iterations, highlighting the Codex variant's significant edge in complex logic. This was further supported by arpit033606, who claimed that Codex 5.3 outperforms Opus 4.6 in reasoning depth and generation speed. Industry insiders like @tech_leaks_daily suggest these versions are part of a broader 'Project Orion' rollout, specifically optimized for agentic autonomy to reclaim the coding lead from Anthropic’s Sonnet 5.
Join the discussion: discord.gg/perplexity
Peering into the Black Box: 3D GGUF Visualizers Gain Traction
A new open-source tool for tackling the LLM 'black box' problem has surfaced on r/localllama. TrentBot released a 3D .gguf visualizer that enables developers to upload local model files and render a spatial representation of layers and weights. As @skirano notes, visualizing these weights is the first step toward moving beyond 'vibe-based' debugging. According to @ArtificialAnalysis, the ability to parse GGUF metadata in a 3D environment helps developers understand how KV cache pruning impacts physical structure, acting as a safeguard against 'reasoning drift.'
Join the discussion: discord.gg/localllama
Perplexity Pro Friction: Deep Research Caps and Revolut Integration Failures
Perplexity is facing intense scrutiny as Pro subscribers grapple with a series of unannounced service regressions. The most significant friction point remains the 25-query monthly cap on 'Deep Research' mode, a move @passimian describes as gutting the platform's value for power users. This is compounded by reports from users like andreas058502 who find 'Deep Think' modes greyed out without warning. Furthermore, the partnership with Revolut Metal has entered a 'systemic collapse,' with users like filosofilus reporting their accounts are being wrongly paused or deactivated.
Join the discussion: discord.gg/perplexity
The HF Model Lab
From 270M micro-agents on the edge to structured planning via Table-as-Search, the shift from 'chat' to 'execution' is officially here.
Today’s issue marks a definitive pivot in the agentic landscape: we are moving beyond the 'chat wrapper' era into the 'execution layer' era. For months, developers have grappled with the fragility of long-horizon tasks and the unreliability of general-purpose LLMs in complex environments. This week, the community answered back with structure. The Table-as-Search (TaS) framework is a prime example, replacing messy chat histories with structured planning schemas that boost success rates by 20%. Simultaneously, the Model Context Protocol (MCP) has hit its 'USB-C moment,' with over 1,000 servers standardizing how agents talk to the world. But perhaps most exciting for practitioners is the 'scaling down' of intelligence. The release of FunctionGemma 270M proves that high-precision tool calling doesn't require a trillion parameters—it requires smart fine-tuning. Whether you are building clinical navigators with MedGemma or autonomous GUI agents with OS-Atlas, the focus has shifted from conversational fluency to verifiable action. We are no longer just building bots that talk; we are building systems that do. This transition toward execution-centric AI is the heartbeat of today's coverage.
Table-as-Search: Solving Long-Horizon InfoSeeking with Agentic Table Completion
The Table-as-Search (TaS) framework, detailed in Table-as-Search: Solving Long-Horizon Information Seeking with Agentic Table Completion, addresses the fragility of long-horizon information seeking by moving away from unstructured chat histories toward a structured planning environment. By reformulating Information Seeking (InfoSeeking) as an Agentic Table Completion task, the system allows agents to fill in a pre-defined schema, ensuring they maintain state coherence over extended workflows. As highlighted by @_akhaliq, this method effectively mitigates the reasoning decay seen in traditional agents by providing a robust mechanism for tracking search progress through structured cells rather than plain text. Empirical evaluations on the LHIS benchmark demonstrate that TaS achieves significant performance gains, outperforming baseline ReAct agents by an absolute 20% in success rate on complex, multi-variable queries. The framework's implementation, available on GitHub, enables developers to build research agents that maintain a 100% focus on target variables without succumbing to the noise of intermediate search results. Expert @omarsar0 notes that this 'structured-state' approach is a critical step toward reliable, autonomous knowledge discovery.
The 'USB-C for AI' Moment: MCP Ecosystem Surpasses 1,000 Servers
The Model Context Protocol (MCP) has transitioned from a niche developer tool to the industry's 'USB-C for AI,' standardizing how agents interface with external data and tools. Recent breakthroughs from the Agents-MCP-Hackathon have introduced critical debugging tools like the Gradio Agent Inspector, which allows developers to visualize tool execution in real-time. Specialized servers like pokemon-mcp showcase the protocol's ability to turn any API into a plug-and-play agentic resource with minimal overhead. The ecosystem's maturity is highlighted by the sipify-mcp project, which emerged during celebrations for MCP's first year. With registries like Smithery and mcp-get now indexing over 1,000 community-contributed servers, developers can instantly connect agents to Google Search, Slack, and PostgreSQL. As expert @aymeric_roucher noted, this decoupling of model logic from tool execution is essential for the shift toward execution-centric AI.
FunctionGemma and the Rise of the 270M Parameter Micro-Agent
The frontier of agentic orchestration is shrinking to the extreme edge, as evidenced by the release of ultra-lightweight models capable of autonomous tool use. Fine-tuned variants like nitinr910/functiongemma-270m-it-free-think-v000dev are proving that the 270M parameter scale is sufficient for high-precision, domain-specific function calling. These models utilize 'free-thinking' reasoning steps—a form of distilled chain-of-thought—to parse user intent before selecting API tools. While larger 7B models lead in complexity, these 'Micro-Agents' are achieving 80-90% accuracy on specialized mobile UI and IoT tasks. This shift is further supported by the Gemma 3 ecosystem, which emphasizes multimodal capabilities at the edge. By eliminating the 'JSON tax' through direct tool-calling fine-tuning, these 270M models can operate within strict memory constraints of wearable devices without sacrificing the reliability required for production automation.
Beyond Pixels: OS-Atlas and GUI-Gym Drive the Next Wave of Autonomous Navigation
The development of agents capable of navigating graphical user interfaces is accelerating through specialized foundation models. OS-Atlas has emerged as a state-of-the-art generalist GUI agent, achieving a 64.3% success rate on the ScreenSpot benchmark, notably outperforming frontier systems like GPT-4V. This model leverages a massive 'GUI-Anchors' dataset to bridge the gap between visual perception and action execution across Windows, macOS, and Android. Complementing these foundation models is GUI-Gym, a framework designed to enable reinforcement learning at over 100 FPS. Research indicates that agents trained within this high-fidelity environment show a 25-30% improvement in multi-step task completion compared to traditional imitation learning baselines. Alongside efficient visual grounding in ShowUI, these advancements are pushing specialized GUI models toward an 85%+ success rate on structured web navigation.
Open Source Deep Research Agents Challenge Proprietary Models
The landscape of autonomous knowledge discovery is shifting as open-source frameworks like MiroMind-Open-Source-Deep-Research challenge the dominance of proprietary systems. MiroMind employs a modular 'Plan-Search-Synthesize' loop that provides 100% transparency into its reasoning traces, allowing users to audit every source—a capability missing from OpenAI’s Deep Research. While OpenAI’s tool is optimized for long-horizon tasks, MiroMind matches the economics of the Open-source DeepResearch initiative, often costing under $0.50 per report. Specialized agents like ScholarAgent are refining this for the academic sector by grounding workflows in repositories like Semantic Scholar. As noted by @_akhaliq, these agents utilize recursive loops to bypass the 'JSON tax' and hallucination risks common in standard RAG.
Google Debuts MedGemma EHR Navigator for High-Stakes Clinical Workflows
Google has launched the EHR Navigator Agent, a specialized agentic framework powered by MedGemma designed to navigate Electronic Health Records. This system moves beyond simple retrieval by utilizing agentic loops to synthesize patient histories and assist in clinical decision support. Central to its utility is the integration with FHIR (Fast Healthcare Interoperability Resources) standards, which allows the agent to interact with structured medical data across fragmented hospital systems. By automating the extraction of key clinical indicators, these vertical agents aim to reduce administrative overhead, which currently consumes up to 30% of a clinician's workday. The project reflects a broader pivot toward 'grounded' medical AI that prioritizes tool-use over simple conversational fluency.
Hugging Face Agents Course Sparks Builder Explosion
The barrier to entry for building AI agents is dropping rapidly, evidenced by the massive engagement with the Hugging Face Agents Course. The foundational First Agent template has surpassed 636 likes, becoming a central hub for new practitioners. This surge is part of a broader curriculum designed by experts like Aymeric Roucher to move developers toward 'code-as-action' architectures using the smolagents library. As noted by @aymeric_roucher, the focus is on teaching agents to use tools through direct Python execution. Notable community projects include the Spotify Genre Analyzer and the Resume Roaster, validating the Model Context Protocol (MCP) in real-world scenarios.