Sovereign Infrastructure and Code-as-Action
From self-modifying code to 1M token windows, the agentic stack is shifting from chat to persistent autonomy.
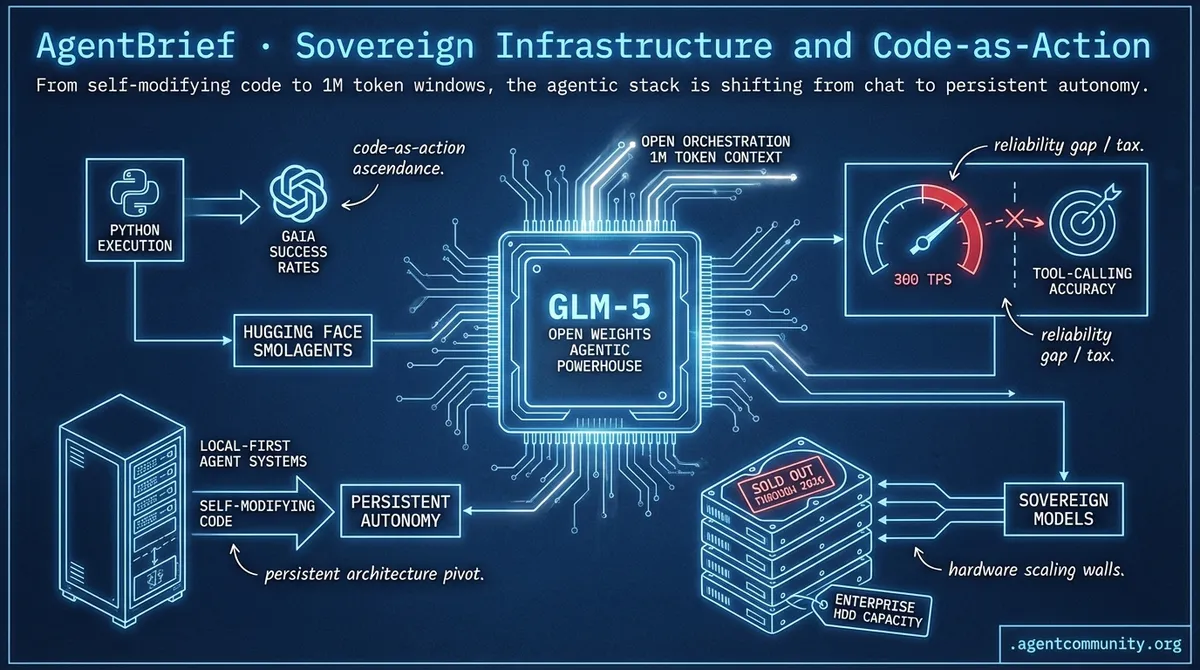
- Code-as-Action Ascendance Hugging Face’s smolagents and Python execution are killing the 'JSON tax' to improve GAIA success rates.
- Persistent Architecture Pivot OpenAI’s hiring of the OpenClaw creator signals a move toward self-modifying, local-first agent systems.
- The Reliability Gap As providers hit 300 TPS, practitioners face a 'Reliability Tax' where raw speed costs tool-calling accuracy.
- Hardware Scaling Walls The shift toward sovereign models meets physical reality with enterprise HDD capacity reportedly sold out through 2026.
X Intel & Infrastructure
Your agents are learning to rewrite themselves—if they don't get hacked first.
The agentic web is no longer a collection of clever prompts; it is becoming a robust, self-healing infrastructure. This week, we saw the release of GLM-5, a 744B parameter beast that proves open weights can go toe-to-toe with the closed-source elite on hardcore engineering benchmarks like SWE-bench. But more importantly, the rise of frameworks like OpenClaw—despite its terrifying security profile—shows us where the puck is going: self-modifying code. Builders are moving away from rigid tool-calling and toward agents that can rewrite their own logic to solve problems.
We are also seeing the 'un-siloing' of the agentic stack. Tools like Memex are solving the 'context rot' that happens when you jump between Cursor and Claude Code, while Cloudflare’s Moltworker is bringing the sovereign agent to the edge. The bottleneck is no longer just the model; it’s the orchestration, the memory, and the operational reliability. For those shipping today, the message is clear: focus on the execution layer and the session continuity. The models are getting bigger and the frameworks are getting weirder, but the builders who master the state and the sandbox will win.
GLM-5 Launches as Open Weights Agentic Powerhouse
Z.ai (@Zai_org) has released GLM-5, a massive 744B parameter Mixture-of-Experts (MoE) model trained on 28.5T tokens entirely on Huawei Ascend hardware, signaling a major shift in frontier model sovereignty @rasbt @itsafiz. This architecture utilizes DeepSeek Sparse Attention (DSA) and multi-head latent attention to handle the long-context requirements of complex agentic workflows while keeping deployment costs manageable for local builders @rasbt @eliebakouch.
Beyond the raw specs, the community is buzzing about the Slime asynchronous RL framework, which reportedly delivers a 3x throughput increase in post-training by decoupling trajectory generation from policy updates @wandb @FreelanceHelper. Early testers like @altryne and @WolframRvnwlf are praising the model’s distinct reasoning and coding quality, which was previously teased on OpenRouter under the 'Pony Alpha' moniker @chetaslua.
For agent builders, the 77.8% score on SWE-bench Verified and top-tier performance on Vending Bench 2 (outperforming Claude Opus 4.5) suggests that frontier-level autonomous engineering is no longer gated by closed-source APIs @LlmStats @HeyAbhishek. With an MIT license and support for local deployment via the @wandb ecosystem, GLM-5 becomes the new baseline for long-horizon agentic tasks that require high reasoning density without the latency or privacy costs of the cloud.
OpenClaw Framework Surpasses 200k Stars as Creator Joins OpenAI
OpenClaw, the self-modifying agent framework, has officially crossed the 200k GitHub star threshold, cementing its place as the standard for 'code-as-action' architectures @trending_repos @modelpingai. Creator Peter Steinberger @steipete recently detailed how the system evolved from a simple assistant into a recursive agent that reads its own source code to identify and patch its own logic bugs @lexfridman @stevederico.
While the hype is massive—fueled by use cases ranging from autonomous PR shipping to self-healing 5G networks—the security community is sounding the alarm @ryancarson @AlexJinsungChoi. Experts have flagged severe RCE vulnerabilities (CVSS 8.8) and over 42k exposed instances, warning that the same self-modification features builders love are being targeted by infostealers looking for agent identities @AkiraLabs01 @ThreatSynop.
Despite the risks, the momentum is unlikely to slow as Steinberger moves to OpenAI while transitioning OpenClaw to an independent foundation to ensure its longevity @steipete @levelsio. For developers, this represents a shift toward agents that don't just use tools, but actively improve their own execution layer in real-time—a pattern @swyx identifies as the logical next step for the 'smolagents' philosophy.
In Brief
Azure and Cisco Pioneer AgenticOps for Scalable Cloud and Network Automation
Microsoft and Cisco are redefining IT operations by deploying context-aware agents across the full cloud and network lifecycle. Microsoft Azure's new Agentic Cloud Operations model aims to accelerate decision-making and mitigate risks through autonomous agents @Azure, while Cisco is expanding its AgenticOps capabilities to create self-driving networks that proactively detect and resolve issues before they impact performance @Cisco. Analysts suggest this shift will empower junior staff to handle advanced tasks, though integration and governance challenges remain as networks move from reactive to truly autonomous states @AlanWeckel @SargisChilingar.
Memex and Contrail Unlock Shared Session Context for Multi-Agent Coding
Developer @krishnanrohit has released 'memex,' a Rust-based context layer designed to prevent 'context rot' in multi-agent coding workflows. By unifying transcripts from tools like Cursor, Claude Code, and Codex into a local directory, memex allows builders to switch between models without losing the thread of their development sessions @krishnanrohit. Early adopters like @nicoritschel are already using it to bridge the gap between Cursor's context engine and the reasoning capabilities of Claude Code, positioning it as a vital primitive for hybrid agent environments @semisauced.
Moltworker Enables Self-Hosted OpenClaw Agents at the Edge
Cloudflare's new Moltworker middleware is bringing OpenClaw agents to the edge, offering a sandboxed alternative to local hardware for low-latency personal assistants. Early reports suggest this approach is up to 80% cheaper than traditional VPS setups, with persistent storage managed via R2 @Cloudflare @migcort009. However, the transition hasn't been seamless; builders like @dr00shie and @NGaneshan report frequent lockups, backup failures, and region-deployment errors, signaling that while the potential for sovereign edge infra is high, the tooling is still maturing.
Quick Hits
Agent Frameworks & Orchestration
- Swarms Cloud is rolling out improvements for cloud-based multi-agent orchestration per @KyeGomezB.
- @tom_doerr shared a new tool for orchestrating agents across multiple devices and platforms.
- CrewAI is dropping a major update for agent building and observation tomorrow per @joaomdmoura.
Model Capabilities & Benchmarks
- Anthropic released a 53-page sabotage risk report for the upcoming Opus 4.6 model @rohanpaul_ai.
- The ALE-Bench for measuring AI algorithm engineering has received a significant update from @SakanaAILabs.
- New 1.7B parameter dots.ocr model is reportedly outperforming GPT-4o on document parsing benchmarks @techNmak.
Tool Use & Developer Experience
- Supabase now allows copying AI assistant prompts directly into local agentic workflows per @kiwicopple.
- n8n released a tutorial on low-code LLM evaluation frameworks for complex AI workflows @n8n_io.
- Cursor significantly increased usage limits for Individual plans using Composer 1.5 @cursor_ai.
Agentic Infrastructure & Scale
- OpenRouter inference volume exploded to 12.1 trillion tokens per week, rivaling Azure scale @deedydas.
- xAI's 'Macrohard' cluster now utilizes 27,000 GPUs across 12 data halls for Grok agents @rohanpaul_ai.
The Reddit Pulse
As OpenAI consolidates agentic talent, Anthropic breaks the context barrier and hardware supply chains hit a wall.
The agentic web is moving from 'chat' to 'always-on' systems, and the industry giants are positioning themselves accordingly. OpenAI’s hiring of Peter Steinberger, the mind behind the OpenClaw framework, signals a pivot toward persistent, local-first agent architectures that move beyond the ephemeral sessions we have grown used to. This isn't just about better models; it is about the infrastructure of autonomy. At the same time, Anthropic is throwing down a high-context gauntlet with Opus 4.6, pushing a 1M token window that challenges developers to rethink how much state an agent should actually hold. But as we scale, the cracks are showing. Whether it is the 'Confused Deputy' security risks in multi-agent systems or the alarming reality that enterprise HDD capacity is sold out through 2026, the Agentic Web is hitting its first major scaling wall. Today’s issue explores how builders are navigating this transition—from optimizing 397B parameter models on consumer hardware to avoiding the 'More Agents' trap that plagues production deployments. The era of toy agents is ending; the era of persistent, validated systems is here.
Anthropic’s Opus 4.6: The 1M Context Era Begins r/ClaudeAI
Anthropic has officially released Opus 4.6, introducing a massive 1M token context window accessible via the new Claude Code CLI and a specialized 'Claude Max' terminal mode u/-Two-Moons-. Technical benchmarks shared by @AnthropicAI reveal that the model maintains a 99.2% retrieval accuracy across the full window, narrowly edging out Gemini 1.5 Pro’s 98.1% at the same scale.
To facilitate migration, Anthropic is providing $50 in usage credits, though early adopters like u/-Two-Moons- warn of 'prompt too long' errors when context state isn't cleared. This release accelerates the move toward 'Validation-First' architectures, such as Boris Tane’s workflow which utilizes the massive context to ingest entire codebases for planning u/hareld10.
However, the community remains divided on reliability. While the model excels at retrieval, some users like u/Impressive-Deal-6022 report 'instruction drift' where the model autonomously modifies features despite explicit constraints. These 'Day 10' production challenges for high-context agents are a growing focus for developers like @alexalbert__.
OpenAI Hires OpenClaw Creator for 'Always-On' Strategy r/AI_Agents
The agentic ecosystem saw a major consolidation as OpenAI hired Peter Steinberger, the creator of the OpenClaw framework, to join its autonomous agents team @steipete. OpenClaw gained traction for its 'always-on' architecture designed to run on local hardware like a Mac Mini, moving away from the ephemeral sessions of standard LLM chats u/Deep_Ladder_4679.
This hire signals a strategic shift as OpenAI looks to bolster its 'Operator' browser agent with persistent, task-oriented logic. While the community celebrates the hire as a power move, developers remain divided on current tool stability; some report monetizing deployments within 3 days u/stanlyya, while others warn that OpenClaw still struggles with 'token-eating' loops during non-deterministic tasks u/timenowaits.
Qwen 3.5: Alibaba’s MoE Giant Challenges Llama r/LocalLLaMA
Alibaba's Qwen team has launched Qwen 3.5, a massive Mixture-of-Experts (MoE) model featuring 397B total parameters. The model establishes a new open-weight performance ceiling with an MMLU score of 89.4%, narrowly edging out Meta's Llama 3.1 405B in coding and logic tasks @qwen_official. While its native context is 262k tokens, the architecture is extensible up to 1M tokens for large-scale repository analysis u/segmond.
Local inference enthusiasts are rapidly optimizing the model for consumer hardware. u/mazuj2 reported achieving 39 t/s on a dual RTX 5070 Ti setup using 'Layer-Shifting' optimizations. For workstations, u/VoidAlchemy released IQ2_XS quants that shrink the model to 113 GiB, allowing it to run within 128GB of RAM while maintaining high coherence.
Securing the 'Confused Deputy': OCAP Models Take Root r/aiagents
As multi-agent systems move into production, the 'Confused Deputy' problem has become a top priority for security researchers. This vulnerability, where an agent is tricked via indirect prompt injection into acting outside its authority, is now a core focus of the OWASP Top 10 for LLM Applications OWASP Top 10 for LLM. The community is increasingly gravitating toward Object Capability (OCAP) models to limit agent authority to specific, pre-defined tools u/Eastern-Ad689.
To bridge this gap, developers like u/MacFall-7 have released open-source 'governance spines' to decouple execution and permissions. This hardening is exemplified by u/kduman's MCP Gateway 0.10.0, which introduces transport-layer isolation and explicit 'Least Privilege' flows. These controls are arriving just in time, as u/Sufficient-Owl-9737 recently reported that AI-driven browsers can now autonomously complete corporate compliance modules.
The 'More Agents' Trap: Moving to Deterministic Loops r/aiagents
A growing debate centers on the 'More Agents' trap, where architectural complexity is used as a band-aid for model limitations. u/Reasonable-Egg6527 argues that adding agents for planning often introduces compounding failure modes. Critics like @skirano suggest this 'agentic bloat' masks poor prompt engineering, leading to 'state drift' where the context is polluted by recursive error-correction loops @charles_irl.
To combat the fragility described by u/NormalGuess6645, developers are adopting 'Validation-First' workflows. This includes using frameworks like Modelab for A/B testing prompts u/marro7736 and rigorous sandboxing u/Icy-Cartographer23. Recent benchmarks from @weights_biases indicate that 80% of agentic failures are caused by tool-calling errors and environment mismatches rather than reasoning gaps.
OpenAI’s Mission Pivot: Safety Constraints Removed r/ChatGPT
OpenAI’s latest IRS Form 990 filings reveal a significant revision of the organization’s core purpose, officially removing the commitment to remain 'unconstrained by a need to generate financial return' and the goal to build AGI 'safely' u/policyweb. This shift aligns with OpenAI's restructuring into a for-profit benefit corporation.
Simultaneously, the company has reportedly intensified internal surveillance to combat unauthorized disclosures, allegedly utilizing a custom version of ChatGPT to perform forensic analysis on employee communications u/EchoOfOppenheimer. This aggressive stance has led to a shift in community sentiment, with developers on r/ClaudeAI increasingly pivoting toward Anthropic as the standard for 'principled' AI development.
Storage Bottlenecks: HDD Supply Sold Out to 2026 r/ArtificialInteligence
The physical infrastructure supporting the agentic web is hitting a supply-chain wall. Western Digital has officially sold out its 2026 hard drive capacity, with CEO Irving Tan confirming that hyperscalers are locking in supply through 2028 to mitigate 'storage-induced latency' in RAG pipelines r/ArtificialInteligence discussion.
On the edge, developers are finding workarounds for local compute. On r/LocalLLaMA, users have identified kernel-level fixes to run large MoE models on the RTX 5070 Ti. To solve the VRAM bottleneck, the community is rallying around High Bandwidth Flash (HBF), which offers a 10x cost advantage over traditional VRAM for storing static weights u/DeltaSqueezer.
MCP Ecosystem: From iPhone Control to Code Indexing r/mcp
The Model Context Protocol (MCP) ecosystem has breached the mobile hardware barrier. u/jfarcand released a server that grants LLMs direct control over a physical iPhone, enabling agents to navigate mobile-only apps and handle complex authentication flows. This hardware expansion is mirrored in the industrial sector with the Tulip MCP Server for manufacturing platforms.
To address production costs, the mcp-codebase-index server introduced by u/Ok-Patient6458 significantly reduces token overhead by indexing structural metadata rather than full files. This technical maturation is supported by enterprise-grade integrations from Atlassian and Playwright that are currently topping GitHub trending lists.
Builder Discord Debrief
As OpenAI chases 300 TPS, developers are weighing the high cost of model 'thinking' and centralized rate limits.
The agentic web is currently caught in a pincer movement between two opposing forces: the drive for raw inference speed and the necessity for rock-solid reliability. Today’s lead story on the 'Spark Gap' highlights this tension perfectly. While OpenAI and Cerebras are pushing the boundaries of throughput with 300 TPS, the 16% drop in tool-use success rates suggests that we are trading logic for velocity—a dangerous bargain for autonomous agents.
At the same time, we’re seeing a 'Thinking Paradox' emerge in tools like Claude Code, where deeper reasoning leads to redundant token consumption. This economic friction, combined with Perplexity’s drastic 99% reduction in Deep Research limits, is fueling a significant shift toward local, sovereign models. Whether it’s Nanbeige’s efficient 3B architecture or the massive Qwen 3.5 Coder, developers are increasingly looking for ways to bypass the 'kill switches' and rate limits of centralized providers. In this issue, we explore how builders are navigating these infrastructure hurdles, from optimizing MCP tool naming to building persistent human-in-the-loop workflows using ClickUp and n8n.
The Spark Gap: Speed vs. Tool Call Reliability
The infrastructure war has reached a boiling point as OpenAI and Cerebras reportedly finalize a deal to host the GPT-5.3-Codex-Spark variant, reaching unprecedented speeds of 250-300 TPS on CS-3 clusters. However, technical benchmarks shared by kerunix suggest a significant 'reasoning tax' for this velocity; while the vanilla GPT-5.3 maintains a 94% success rate on complex tool-use benchmarks, the Spark version drops to 78%, frequently hallucinating arguments in multi-step JSON schemas. This performance degradation is attributed to aggressive distillation and weight-stripping designed to fit the specific memory constraints of the Cerebras Wafer-Scale Engine.
In contrast, Anthropic’s deployment strategy for Opus 4.6 appears to prioritize architectural consistency over raw throughput. According to discussions in LMArena, Opus 4.6 maintains its full reasoning integrity even in high-speed 'Turbo' modes, avoiding the 'Spark confusion' that plagues OpenAI’s distilled counterparts. This has led to a growing preference among agentic developers for Anthropic's stack when handling autonomous loops that require precise state management, despite the slightly higher latency compared to the Cerebras-hosted Spark models.
Critics argue that while the 300 TPS milestone is impressive for simple chat, it remains a 'vanity metric' for agents that require recursive logic and zero-shot tool reliability. Builders are increasingly forced to choose between the 'raw speed' of the Cerebras-OpenAI partnership and the 'reliable reasoning' offered by Anthropic, particularly as agentic workflows move from simple text generation to complex system orchestration.
Join the discussion: discord.gg/anthropic
Perplexity Slashes Deep Research Limits by 99%
Perplexity Pro users are reporting a massive reduction in service limits for high-reasoning 'Deep Research' mode, with queries being slashed from 600 daily to as low as 20 per month for some accounts. This 99% reduction, noted by users like wetsand24 and johnnyboy04876, has sparked a developer exodus toward Abacus AI, which recently launched its own 'Deep Research' agent with significantly higher usage caps for a lower $10/month price point.
Join the discussion: discord.gg/perplexity
Claude Code’s ‘Thinking’ Paradox: Higher Reasoning at the Cost of Redundancy
Practitioners using Claude Code (v2.1.44) and Sonnet 4.5 are reporting a 'redundancy loop' where models over-analyze trivial file edits, effectively doubling token consumption. As omar_j2 noted, the model frequently drafts entire code blocks within its internal thinking space before spawning a sub-agent to perform the identical write operation, leading to 30-40% higher costs without measurable performance gains in non-mathematical contexts according to @alexalbert__.
Join the discussion: discord.gg/anthropic
Nanbeige 4.1-3B and Qwen 3.5 Coder Set New Baselines for Local Reasoning
Nanbeige 4.1-3B and Qwen 3.5 Coder (via Unsloth GGUFs) are redefining local reasoning with 256k contexts and frontier-level performance for sovereign agent developers.
Join the discussion: discord.gg/ollama
MCP Metadata Constraints: Navigating the 64-Character Tool Name Limit
Developers are navigating a strict 64-character limit on MCP tool names, which forces the truncation of essential metadata during model tool discovery.
Join the discussion: discord.gg/mcp
Asynchronous HITL: Using ClickUp as Persistent Memory for n8n Agents
A new 'callback' pattern using ClickUp webhooks allows n8n agents to transition to a suspended 'wait' state, enabling multi-day persistence for human review.
Join the discussion: discord.gg/n8n
Disney Targets AI Video: The Open Source Defense
Disney's cease-and-desist against ByteDance’s 'Seedance' has accelerated the shift toward open-weight models as developers seek resilience against centralized 'kill switches.'
Join the discussion: discord.gg/localllm
HuggingFace Research Hub
Hugging Face’s smolagents hits a 53.3% GAIA success rate by ditching schemas for executable Python.
The era of 'guessing' what an LLM meant to do with a JSON schema is coming to a close. For over a year, developers have wrestled with the 'JSON tax'—the massive token overhead and brittle logic required to force models into rigid tool-calling structures. Today, the narrative shifts toward 'Code-as-Action.' By allowing agents to write and execute Python directly, we are seeing a massive leap in autonomy. Hugging Face’s smolagents is leading this charge, proving that minimalist, code-first frameworks can outperform complex orchestration layers on grueling benchmarks like GAIA.
This isn't just about cleaner code; it’s about capability. When agents can handle nested loops and multi-step error correction through native execution, they move from being chatbots with plugins to true autonomous systems. Whether it is navigating a desktop with 2B parameter models or conducting deep research with transparent execution traces, the industry is converging on a single truth: the most efficient way to interact with a computer isn't through a schema, but through the language the computer already speaks. Today’s issue dives into this architectural pivot and the specialized models making it possible.
Hugging Face’s smolagents and the Rise of Open Deep Research
Hugging Face has solidified its shift toward 'code-as-action' with the release of huggingface/smolagents, a minimalist library that replaces rigid JSON tool-calling with executable Python code. This architectural pivot directly addresses the cognitive and token overhead required for models to map intent into schemas. By allowing models to write and execute code directly, smolagents achieved a 53.3% success rate on the GAIA benchmark, a significant jump over traditional JSON-based orchestration. Lead developer @aymeric_roucher highlights that this approach enables agents to handle complex logic, such as nested loops and multi-step error correction, which often break in schema-heavy environments.
Building on this momentum, the Open Deep Research initiative is leveraging smolagents to challenge proprietary search giants. Unlike 'black box' models, this open-source alternative provides a full execution trace, allowing users to verify every source and reasoning step in real-time. Live implementations like the MiroMind-Open-Source-Deep-Research Space demonstrate the agent's ability to perform autonomous, multi-step research tasks using models such as Qwen/Qwen2.5-72B-Instruct.
GUI Agents: Small Models, Big Performance
The 'Computer Use' paradigm is rapidly maturing through specialized architectures like smol2operator, a 2B parameter model optimized for low-latency desktop navigation. While proprietary models set the early baselines, open-source alternatives like the Hcompany/holo1 family are now leading in precision with a 62.4% success rate on the ScreenSpot benchmark, significantly outperforming GPT-4V's 55.4%.
Physical AI: Reasoning in the Real World
NVIDIA has advanced the 'Physical AI' frontier with Cosmos-Reason-2, a visual reasoning model that treats planning as a visual prediction task. This integrates with the LeRobot initiative and hardware like the Reachy Mini humanoid robot from Pollen Robotics, which uses NVIDIA Jetson Orin for edge-based inference to bridge the 'sim-to-real' gap.
Quick Hits: Benchmarks, Tools, and Ecosystem
huggingface/gaia2 introduces over 1,000 tasks for evaluating agents in dynamic feedback loops.
huggingface/unified-tool-use standardizes model-function interactions using Pydantic-validated schemas and the Model Context Protocol (MCP).
ServiceNow-AI/apriel-h1 uses reasoning-aware distillation to bring high-fidelity logic to 7B and 32B parameter models.
ibm-research/assetopsbench launches a playground for evaluating agents in industrial maintenance and operations.
LangChain and Hugging Face released a partner package to optimize tool-calling for models like Qwen2.5 and Llama-3.1.
Agents.js extends autonomous agent capabilities to the JavaScript and TypeScript ecosystems for native DOM interaction.