From Vibe Coding to Deterministic Agents
The agentic web matures as models trade fragile DOM parsing for raw pixels and universal protocols.
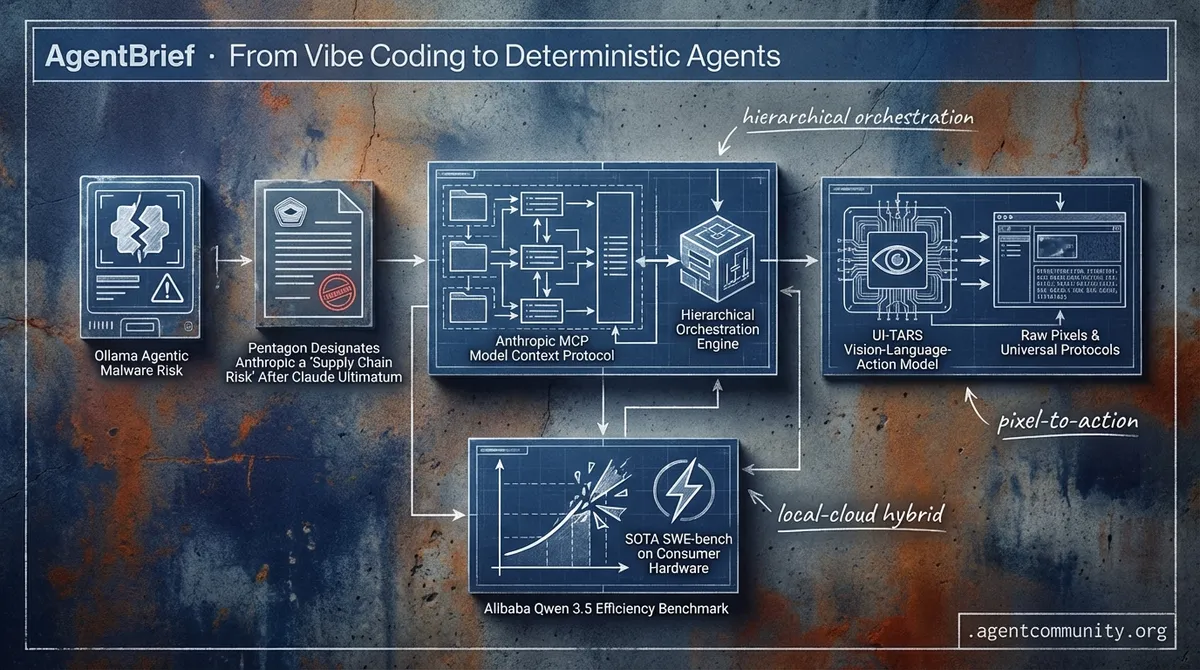
- Infrastructure Over Inference The Agentic Stack is solidifying around Anthropic’s Model Context Protocol (MCP) and hierarchical orchestration engines, moving the industry away from unstructured chat toward deterministic, stateful systems.
- Visual Autonomy Ascends A major transition is underway from DOM-based scraping to vision-language-action models (VLAMs) like UI-TARS, allowing agents to navigate legacy software via raw pixels rather than fragile metadata.
- High-Reasoning Local Efficiency Alibaba’s Qwen 3.5 is shattering efficiency benchmarks, proving that SOTA SWE-bench performance is now possible on consumer hardware, enabling a hybrid future of cloud reasoning and local execution.
- Mission-Critical Sovereignty From Anthropic’s standoff with the Pentagon to agentic malware risks on Ollama, the focus has shifted to the sovereignty and verification of the systems we deploy in real-world production.
X Intel & Trends
Anthropic defies the Pentagon while Qwen shatters efficiency benchmarks for local agents.
The agentic web is moving from experimental loops to mission-critical infrastructure, and the friction is becoming visible at the highest levels of governance and finance. This week, we saw a historic standoff between Anthropic and the Pentagon over unrestricted model access, a move that signals the end of 'neutral' frontier labs and the beginning of a bifurcated model landscape. For agent builders, the stakes have shifted: it is no longer just about capability, but about the sovereignty of the systems we deploy.
At the same time, the technical ceiling continues to rise while the floor for entry drops. Alibaba’s Qwen 3.5 is proving that high-reasoning agents don't require massive clusters, achieving state-of-the-art SWE-bench results on consumer hardware. Meanwhile, the 'IBM shock' demonstrates that autonomous agents are no longer just writing boilerplate—they are dismantling the legacy codebases that power global finance. Whether you are building 'outer-loop' autonomous developers or secure hierarchical memory systems, the message is clear: the agents are moving into the real world, and they are moving fast.
Pentagon Designates Anthropic a 'Supply Chain Risk' After Claude Ultimatum
A high-stakes confrontation escalated after a Tuesday meeting between US Defense Secretary Pete Hegseth and Anthropic CEO Dario Amodei, where Hegseth issued a Friday 5:01 PM deadline for the company to grant the military unrestricted access to Claude models for "all lawful purposes." The demand specifically requested dropping safeguards against domestic mass surveillance and fully autonomous weapons, a move that Amodei refused to uphold, citing AI's unreliability and risks to privacy @rohanpaul_ai @CyberNews @rohanpaul_ai.
Following the deadline, the Trump administration designated Anthropic a supply chain risk—an unprecedented label for a US firm—forcing federal contractors to cease ties and ordering agencies to stop using the tech within six months @rohanpaul_ai. The Pentagon threatened to cancel $200M contracts and invoke the Defense Production Act (DPA) to seize control of the models, while OpenAI struck a separate deal with technical safeguards and on-site engineers to maintain compliance @rohanpaul_ai @AnnaBower @sama.
For agent builders, this pivot risks bifurcating frontier models by compliance. While Amodei argued that AI outpacing laws demands private caution, Sam Altman contended that elected governments, not executives, should decide ethics in defense @rohanpaul_ai @rohanpaul_ai. This tension forces developers to consider whether their agentic workloads are tied to a 'rebel' lab or a 'compliant' one, potentially impacting long-term government and enterprise contract eligibility.
Qwen 3.5 Delivers 1M Context with Unprecedented Efficiency on Consumer GPUs
Alibaba has released the Qwen 3.5 series, headlined by the Qwen3.5-35B-A3B MoE model which activates only 3B parameters yet scores 69.2% on SWE-bench Verified. This performance remarkably outperforms its larger 235B predecessor and Claude Sonnet 4.5, which sits at 62% @LlmStats @Alibaba_Qwen. The series supports native 262K context, extendable to 1M via YaRN, while maintaining flat speed scaling on hardware like the RTX 3090 @sudoingX.
Early benchmarks confirm the highest efficiency ratio recorded at 23.1 pts/B for the 35B model, achieving nearly 90% of Claude Opus 4.6 performance at a fraction of the compute cost @LlmStats. The hybrid Mamba2 + attention architecture allows for inference speeds of 112-157 t/s under 4-bit quantization, enabling sophisticated local reasoning that was previously reserved for massive cloud clusters @ArtificialAnlys.
This release is a game-changer for agent builders who require long-context tool use without the privacy risks or latency of cloud APIs. With day-0 support from vLLM, Ollama, and Unsloth, builders can now deploy autonomous coding agents that handle entire repositories locally, outperforming flagship models while running on a single consumer GPU @UnslothAI @sudoingX.
AI Agents Trigger $31B IBM Market Shock via COBOL Modernization
IBM shares plummeted 13% this week, wiping out $31B in market value—the worst single-day drop since 2000—following an Anthropic update highlighting Claude Code’s ability to modernize legacy COBOL codebases @rohanpaul_ai @RussellQuantum. Claude Code can now map dependencies across thousands of lines of code and identify risks that would typically take human analysts months to surface @rohanpaul_ai.
The threat targets IBM's mainframe 'cash cow,' as 95% of US financial transactions still rely on COBOL systems where modernization was previously cost-prohibitive @ns123abc @RussellQuantum. Analysts view this as a 'canary in the coal mine' for companies relying on manual maintenance of legacy software as a primary revenue stream @BrianRoemmele.
For agent builders, this marks a transition from simple code assistance to autonomous infrastructure modernization. As agents begin to perform complex multi-application orchestration—jumping between tools like Excel and PowerPoint to keep data in sync—the value of traditional system integration is rapidly diminishing @rohanpaul_ai @rohanpaul_ai. The era of the autonomous 'agent manager' overseeing the modernization of critical infrastructure has officially arrived.
In Brief
Mercury 2 Redefines Agentic Speed with Diffusion Reasoning at 1,000+ TPS
Inception Labs has launched Mercury 2, the world's first reasoning diffusion LLM, achieving over 1,000 tokens per second on Blackwell GPUs. This paradigm shift uses parallel diffusion refinement rather than sequential token generation, allowing it to match Claude 4.5 Haiku on Terminal-Bench Hard while running up to 5x faster, making it an ideal candidate for low-latency agentic loops and real-time orchestration @_inception_ai @ArtificialAnlys @deedydas.
AgentSys Implements OS-Level Isolation to Prevent Indirect Prompt Injection
Researchers have introduced AgentSys, a hierarchical memory management framework that uses process isolation to reduce agent attack success rates to as low as 0.78%. By spawning isolated worker agents for tool calls and enforcing strict JSON schema boundaries, AgentSys prevents malicious instructions from external web pages or documents from polluting the main agent's context, addressing a critical reliability and security gap in long-horizon agents @adityabhatia89 @adityabhatia89 @omarsar0.
OpenClaw Surpasses 5B Tokens as 'Agentic OS' Amid Rising Security Alarms
OpenClaw has solidified its position as a comprehensive 'agentic OS' for vibe coding, processing over 5 billion tokens in production workflows despite growing warnings over its '400K lines of vibe coded' architecture. While builders praise its multi-workspace isolation and Claude 4.6 support, critics like Andrej Karpathy have highlighted RCE vulnerabilities (CVE-2026-25253), prompting some developers to shift toward NanoClaw's auditable 4,000-line core for production use @MatthewBerman @karpathy @openclaw.
Emergent Hits $100M ARR with Mobile No-Code Agentic App Builder
Emergent has reached a $100M ARR run rate in just eight months, doubling its revenue in 30 days via a mobile platform that allows users to build full iOS/Android apps through voice-driven agentic orchestration. Backed by Khosla Ventures and Google AI's Future Fund, the platform has enabled 6M+ users to ship 7M+ apps, though some skeptics question the long-term production viability of mobile-first 'vibe-coding' compared to enterprise-grade alternatives @mukundjha @emergentlabs @hasantoxr.
Claude Code Anniversary Spotlights Push for Full 'Outer Loop' Dev Autonomy
Marking its first anniversary, Claude Code is now responsible for writing 4% of GitHub code, with a strategic shift toward 'closing the outer loop' of testing, deployment, and CI monitoring. Builders are increasingly acting as 'agent managers' rather than coders, leveraging features like Remote Control and persistent dev server previews to oversee multi-agent workflows and self-testing loops that transform the tool into a full development OS @latentspacepod @bcherny @swyx.
Quick Hits
Agent Frameworks & Orchestration
- Anthropic engineer reports an autonomous agent swarm built and shipped an entire plugin over a weekend via Asana tickets @rohanpaul_ai
- GitNexus launches a free tool to turn any GitHub repo into an interactive knowledge graph with local browser-based AI analysis @hasantoxr
Tool Use & Developer Experience
- Mistral-document-ai-2512 is live on Azure, combining OCR and document understanding for automation-ready data @Azure
- LangSmith now supports tracing for Claude Code to improve observability when agents go 'off-path' @hwchase17
Models for Agents
- Prime Intellect released practical RL training recipes specifically for math reasoning, code generation, and tool use @PrimeIntellect
- SemiAnalysis reports AMD MI355X is extremely competitive with Nvidia B200 on DeepSeek R1 disaggregated inference workloads @SemiAnalysis_
- Anthropic updated its 'Cowork' system to allow agents to perform multi-step financial tasks across Excel and PowerPoint @rohanpaul_ai
Agentic Infrastructure
- Karpathy highlights the constraint of orchestrating distinct pools of on-chip SRAM and off-chip DRAM for the coming token tsunami @karpathy
- Cloudflare edge implementation allows for a faster, leaner Next.js rebuild in just 7 days @Cloudflare
The Reddit Pulse
From 'USB-C' protocols to autonomous browsers, the agentic web is finally getting its plumbing.
Today marks a fundamental shift from agents that talk to agents that do. We are witnessing the rapid maturation of the 'Agentic Stack.' Anthropic’s Model Context Protocol (MCP) is positioning itself as the universal connector—a 'USB-C for AI'—while OpenAI’s Operator is turning the browser into a canvas for autonomous action rather than just a site for scraping. What’s most striking across today's developments is the move toward a 'deterministic core.' Whether it’s LangGraph’s persistent state management or CrewAI’s hierarchical orchestration, the industry is moving away from the unstructured, chat-based chaos of early 2024. We are no longer satisfied with agents that hallucinate in infinite loops; we want agents that propose state changes, respect RBAC, and survive on-device execution. The data from SWE-bench Verified confirms this trajectory: we’ve moved from a 1.9% resolution rate to over 40% in a single year. The 'vibe coding' era is ending, replaced by rigorous engineering patterns that prioritize reliability and tool-calling precision over conversational novelty. For practitioners, the message is clear: the plumbing is being laid, and the next phase of agent development will be defined by integration, not just inference.
OpenAI Operator and the Shift to Semantic Browser Control r/OpenAI
OpenAI’s release of Operator marks a pivotal transition from conversational AI to action-oriented agents that navigate the web via direct DOM manipulation and vision-based reasoning, as reported by @OpenAI. Unlike previous attempts that struggled with dynamic content, Operator utilizes a specialized model architecture that early testers like u/OpenAI_Dev report achieves 80%+ success rates on complex, multi-tab research tasks. This performance is bolstered by a new 'semantic grounding' layer that maps model predictions to precise CSS selectors.
This grounding layer reportedly reduces the 'hallucinated click' rate by 45% compared to standard GPT-4o-based prototypes, a metric highlighted by @gdb. The enterprise implications are significant, as u/EnterpriseAI_Lead notes that Operator can automate legacy web portals that lack APIs, effectively turning the browser into a universal interface for autonomous workflows. However, achieving the 99% reliability required for sensitive data entry may require 'agent-optimized' web design using standardized ARIA labels.
MCP Emerges as the 'USB-C for AI' Tool Integration r/mcp
The Model Context Protocol (MCP) is evolving into a standardized interface that decouples data sources from model logic, a move u/mcp_enthusiast compares to the 'USB-C for AI.' Beyond initial connectors, the ecosystem now includes enterprise-grade infrastructure for Google GKE, Sentry, and Nansen blockchain analytics. Developers claim these official servers can reduce integration overhead by 40-50%, allowing agents to maintain a 'stateless' reasoning core while hot-swapping specialized tools.
As the protocol matures, the focus is shifting toward security and the RBAC gap. New 'Contextual Access' wrappers for Arcade are bridging this gap by injecting user identity into tool calls, addressing concerns that broad tool access remains a production bottleneck. According to u/MycologistWhich7953, this shift toward standardization allows agents to bypass proprietary API silos, moving the industry toward a plug-and-play future for the agentic web.
LangGraph Hardens Agentic Reliability with Persistent State r/LangChain
As agents transition from basic RAG to complex reasoning, state management has emerged as the primary architectural bottleneck. LangChain addresses this via LangGraph’s Persistent Checkpointer system, which allows agents to 'sleep' and resume execution following human intervention. This shift toward a 'deterministic core' aligns with trends where agents 'propose' state changes to a central orchestrator to reduce state corruption by 35%, as noted by @joaomdmoura.
Beyond reliability, the framework's 'Time Travel' capabilities allow developers to view, edit, and fork agent states, effectively turning agentic workflows into a version-controlled database of reasoning. Community discussions in r/LangChain highlight that this structured approach significantly reduces 'hallucination loops' compared to unstructured setups, contributing to a reported 25% increase in task completion for graph-based reasoning.
SWE-bench Verified: The New North Star for Autonomous Engineering r/LocalLLaMA
The SWE-bench Verified subset has recalibrated expectations for coding agents by filtering out 506 unresolvable issues, providing a cleaner signal for production readiness u/SWEbench_Team. Top-tier agents like OpenHands and Devin are now consistently resolving between 41.2% and 43.5% of real-world GitHub issues. This represents a massive leap from the 1.9% resolution rate seen in early 2024.
While 'vibe coding' may suffice for small scripts, these benchmarks prove agents can now manage the full lifecycle of a pull request across complex repositories. However, practitioners on r/aiagents warn that high scores do not always account for 'tool pollution' in enterprise environments, suggesting the developer's role is evolving into that of a high-level agent orchestrator and code reviewer.
Llama 3.2 Small Models Redefine Edge Tooling r/LocalLLaMA
Meta's Llama 3.2 1B and 3B models are shifting the feasibility of on-device agentic workflows, demonstrating a 15-20% improvement in tool-calling accuracy. The 3B variant achieved a 67.4% score on the Berkeley Function Calling Leaderboard (BFCL), outperforming many larger models @Meta. Developers like u/local-ai-enthusiast report the 3B model is the first sub-10B model reliable enough for 'router' roles.
This architectural shift enables low-latency, privacy-focused execution on mobile hardware, reducing cloud inference costs by over 60% for high-volume applications. While the 1B model is best for simple intent classification, the 3B model can handle multi-step tool orchestration on consumer-grade devices without hitting a 'logic wall,' according to @AI_at_Edge.
CrewAI’s Hierarchical Orchestration Replaces Chat-Based Chaos r/crewai
CrewAI is moving away from unstructured chat interactions in favor of a hierarchical process managed by a central agent. This design is intended to combat 16 distinct failure patterns, such as 'The Loop of Doom,' identified by the community r/crewai. By assigning specific roles and goals, the system aims to provide more predictable outcomes for enterprise automation than conversational patterns.
Reliability is further enhanced by dual-bucket memory layers, which can improve personalization accuracy by 20-30% over raw chat persistence, as noted by @mem0_ai. @joaomdmoura emphasizes that having agents 'propose' state changes to an orchestrator rather than executing directly is key to reducing state corruption.
Discord Dev Logs
Opus 4.6 pushes the limits of persistent memory while local LLMs break the 100 t/s barrier.
The industry is moving decisively beyond simple prompting toward sophisticated, autonomous architectures. Today's coverage highlights a fundamental shift in how we build: the 'Orchestrator-Worker' pattern is becoming the standard for managing complexity, with Opus 4.6 serving as the cognitive engine for these multi-agent hierarchies. This isn't just about better models; it is about infrastructure. We are seeing builders implement 'living DNA' through persistent memory injection to maintain continuity in long-running workflows, while simultaneously grappling with the UI and security bottlenecks that come with scaling these systems.
While high-reasoning models like Opus 4.6 'Thinking' offer near-perfect logical consistency, the local LLM scene is catching up with raw speed. Qwen 3.5's breakthrough on consumer hardware suggests that the future of agentic workflows will be a hybrid of massive cloud reasoning and lightning-fast local execution. However, this growth brings risks, from deceptive model uploads on Ollama to 'agentic malware' that exploits tool-calling permissions. For the practitioner, the message is clear: the architecture is the product, and verification—whether through 'Binary-First' data handling or formal agent-to-agent handshakes—is the next major frontier.
Opus 4.6: Orchestrating the Next Generation of Persistent Sub-Agent Systems
Developers are moving beyond simple prompting, leveraging Opus 4.6 as the cognitive engine for complex multi-agent hierarchies. A primary trend is the 'Orchestrator-Worker' pattern, where a high-reasoning 'Superpower' agent plans project roadmaps and delegates execution to specialized sub-agents. According to .jokerrk, this ensures that verification and testing are handled by isolated contexts, preventing 'context drift.' To maintain continuity, builders like silth253 are implementing persistent memory injection, where agents inherit a 'living DNA' of previous interactions via dynamically updated system prompts, allowing for long-running autonomous workflows.
The debate between Opus 4.6 'Base' and 'Thinking' variants has intensified. While the 'Thinking' model offers an extended 6-minute reasoning window, allowing it to synthesize multiple interconnected programs with 98% logical consistency according to @codexistance, some users report style regressions. Community data from LMArena suggests the Base model often outranks Thinking in 'naturalness' when style controls are disabled. However, for architectural shifts, the reasoning variant remains the gold standard, with @vincenzolomonaco noting its superior ability to handle 100+ step agentic loops without state degradation.
Join the discussion: discord.gg/claude
Qwen 3.5 Breaks 100 t/s Barrier via Multi-Token Prediction
The local LLM landscape is undergoing a paradigm shift as Qwen 3.5 27B benchmarks demonstrate unprecedented speeds on consumer-grade hardware. Verified reports from cbkarabudak show the model achieving 100+ t/s decode and 1500 t/s prefill on a dual-RTX 3090 setup, driven by Multi-Token Prediction (MTP) and int4 quantization. While llama.cpp is favored for partial offloading, speculation from @markgurman regarding Apple's M5 chip and its potential 128GB of unified VRAM suggests high-context agents may soon run natively on consumer hardware without latency penalties.
Join the discussion: discord.gg/localllm
Deceptive Model Uploads Highlight Security Gaps in Ollama Library
Security concerns are mounting within the Ollama community as the platform’s open library faces a surge in 'shadow-dropped' deceptive models. Users like zinkdifferent_49268 have flagged fake Claude models that are actually GLM-4.7 or Nemotron weights, while endo9001 warns of 'agentic malware' designed to trigger shell commands via tool-calling. Experts like @vincenzolomonaco emphasize that as we move toward 100+ step autonomous loops, weight integrity is becoming the primary security bottleneck.
Join the discussion: discord.gg/ollama
Scaling N8n Workflows: The Binary-First Pivot
Developers building data-heavy agents in n8n are shifting toward 'Binary-First' architectures to prevent UI-induced browser crashes when handling 10-20MB payloads. As documented by knowa., converting large JSON strings into binary objects preserves editor responsiveness, while practitioners like swiftvengeance suggest that bypassing standard OAuth2 flows with service principals is becoming a requirement for stable enterprise-grade automation in Microsoft Entra environments.
Join the discussion: discord.gg/n8n
Perplexity’s ‘Comet’ Agent Emerges as Deep Research Limits Tighten
Perplexity is accelerating the rollout of its Comet agentic browser to counter backlash over new 'compute taxes' and tightening limits on Deep Research. Join the discussion: discord.gg/perplexity
The 'No Comments' Mandate: Engineering Agent-Native Self-Documentation
A new prompting strategy forbids models from writing code comments to force self-documenting identifiers, reportedly leading to an 12-18% reduction in token usage. Join the discussion: discord.gg/claude
Formalizing the Handshake: The Push for Agent-to-Agent Verification
The industry is exploring Agent-to-Agent Verification (A2AV) and Global Workspace Theory to solve 'context fragmentation' in multi-step trajectories. Join the discussion: discord.gg/huggingface
HuggingFace Research Hub
Vision-language-action models are finally bypassing fragile metadata to automate the web via raw pixels.
Today’s issue marks a pivotal shift in the agentic stack: the transition from "reading" the web to "seeing" it. For years, developers have struggled with the "JSON tax" and fragile DOM-parsing, but the emergence of models like UI-TARS and ShowUI-2B suggests a future where raw pixels are the only input an agent needs. This move toward vision-language-action models (VLAMs) isn't just about robustness; it’s about universal applicability across legacy software and dynamic web environments where structured metadata is often non-existent.
Parallel to this visual revolution, we are seeing the maturation of the Model Context Protocol (MCP) and a heavy lean into the "code-as-action" philosophy. By empowering agents to write and execute Python directly—rather than just predicting the next token—frameworks like smolagents are addressing the reliability gap that has long plagued autonomous systems. From 270M-parameter micro-models handling edge function calls to the massive 405B Hermes 3 maintaining neutral alignment, the infrastructure for "industrial-grade" autonomy is finally coalescing. For practitioners, the message is clear: the most effective agents of 2025 will be those that can see the interface, write the code, and interface seamlessly with existing data via standardized protocols.
The Rise of Pure-Vision GUI Agents
Research into graphical user interface (GUI) agents is accelerating, shifting from fragile DOM-parsing to robust vision-language-action models (VLAMs). The UI-TARS model exemplifies this trend, achieving a 83.6% success rate on the ScreenSpot benchmark and 19.0% on OSWorld, outperforming many larger closed-source models by bypassing text-based metadata in favor of raw pixels. Efficiency is also a priority, with ShowUI-2B demonstrating that lightweight models can achieve 75.1% visual grounding accuracy, making on-device automation more feasible.
Benchmarks like VisualWebArena and WebVoyager are pushing agents to handle long-horizon tasks across dynamic environments like Reddit and GitLab. However, challenges remain; while 2406.10819 shows that multimodal inputs significantly improve success rates compared to text-only baselines, agents still struggle with the 'logical reasoning decay' seen in complex multi-step workflows.
As the infrastructure for web-native agents matures, the focus is moving toward direct visual-to-action mapping to ensure reliability across legacy software where DOM data is unavailable. This shift addresses the inherent fragility of metadata-dependent systems, paving the way for agents that can navigate any visual interface with human-like adaptability.
MCP Ecosystem Matures: From Hackathon Novelties to Industrial Standards
The Model Context Protocol (MCP) is rapidly transitioning into the primary 'glue' for agentic tool integration, boasting over 30 specialized connectors like sipify-mcp and native support in the smolagents library, allowing developers to instantiate complex toolsets with a single line of code.
Tiny Models Tackle Complex Function Calling
Optimization is moving 'down-market' as developers prioritize latency, with the 270M parameter functiongemma-270m-mika and the 7B-class Aura-7b proving that small models can dominate benchmarks like the Berkeley Function Calling Leaderboard with 88.2% accuracy.
Hugging Face Agents Course Scales 'Code-as-Action' Literacy
The developer community is standardizing around structured learning for autonomous systems, as evidenced by the agents-course template surpassing 800 likes while promoting a Python-centric 'code-as-action' philosophy over traditional JSON parsing.
High-Fidelity Autonomy: Specialized Agents for Clinical and Scientific Discovery
Google's ehr-navigator and ScholarAgent are moving autonomy into professional domains where 'Citation Precision' and 'Reasoning Trace Alignment' are non-negotiable.
OSW Studio and Specialized Dev Agents Streamline Orchestration
New infrastructure like osw-studio provides a node-based interface for mapping desktop automation loops, bypassing the complexity of code-heavy orchestration frameworks.
Hermes 3: Advancing Open-Source Autonomy with Neutral Alignment
Nous Research has released Hermes 3, a model suite hitting 81.4% on BigBench Hard and designed for 'neutral alignment' to follow complex agentic instructions without refusal.
Formalizing Autonomy: From Cognitive Architectures to Multi-Turn Self-Correction
Foundational research like the CoALA framework promises an estimated 30-40% reduction in execution errors by structuring agents into standardized modular components for planning and memory.