The Agentic Stack Hardens
From code-driven actions to tiered orchestration, builders are trading chat-based demos for production-ready execution.
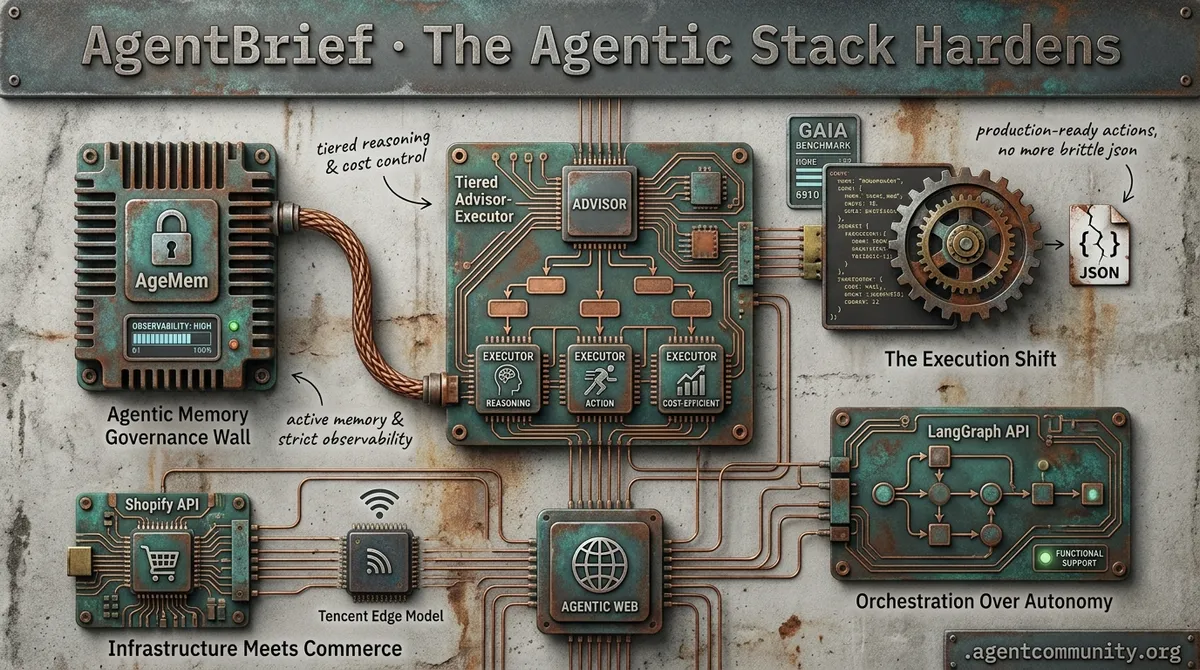
- The Execution Shift Hugging Face and IBM are leading a move from brittle JSON schemas to deterministic code-driven actions, boosting reliability and efficiency on benchmarks like GAIA.
- Orchestration Over Autonomy New patterns like Anthropic’s tiered advisor-executor model and LangGraph’s functional API provide the structural support needed to move past current reasoning ceilings.
- The Governance Wall As frontier leaks hint at next-gen reasoning, practitioners are pivoting toward active 'Agentic Memory' (AgeMem) and rigorous observability to handle the complexity of production deployments.
- Infrastructure Meets Commerce Shopify’s MCP integration and Tencent’s edge models signal that the 'Agentic Web' is moving into live environments with real-world stakes and direct backend access.
X Intel
Stop babysitting your agents—they just got strategic advisors and direct store backend keys.
We are moving past the era of the 'prompt box' and into the era of the 'agentic stack.' Today’s updates from Anthropic and Shopify signal a shift from agents that just talk to agents that execute with structural support. Anthropic’s new advisor tool isn't just a feature; it's the formalization of the tiered executor pattern—allowing mid-tier models like Sonnet to consult 'managers' like Opus natively. This pattern has already shown it can cut costs by 11.9% while boosting performance on SWE-bench.
Meanwhile, Shopify is handing the keys of a $378B GMV ecosystem directly to coding agents via MCP. This is the agentic web in motion: infrastructure that treats autonomous systems as first-class citizens. For builders, the focus is shifting from simple tool-calling to sophisticated orchestration and safety. Whether you're deploying 'robot brains' on the edge with Tencent's new MoT models or 'hill climbing the harness' for production evals, the tooling is finally catching up to our ambitions. It’s time to stop building demos and start building systems.
Anthropic's Advisor Tool Formalizes Tiered Executor Pattern for Cost-Efficient Reasoning
Anthropic has launched the advisor tool in public beta, a move that formalizes the tiered executor pattern within a single Messages API request. Developers can now enable mid-tier models like Sonnet or Haiku to consult Opus for strategic guidance by adding the beta header anthropic-beta: advisor-tool-2026-03-01 and defining an advisor tool type @claudeai @oikon48. The advisor generates 400-700 tokens of high-level plans that the executor follows, effectively preventing dead-end explorations in complex tasks @claudeai.
Official benchmarks confirm the massive ROI for agent builders: Sonnet + Opus advisor scored 74.8% on SWE-bench Multilingual, representing a +2.7pp gain over solo Sonnet while costing 11.9% less per task @claudeai. Even more dramatic was the Haiku + Opus pairing, which hit 41.2% on BrowseComp—a jump from solo Haiku's 19.7%—at an 85% lower cost than running Sonnet solo @akshay_pachaar.
Community tools like the Advisor Tool Playground (v1.6.0) have already emerged to help developers test these recursive supervision patterns @ibuildwith_ai. While builders like @aibuilder0x note this mirrors manual patterns previously used by the community, the native integration positions Anthropic’s stack for more reliable, long-horizon autonomy @theaisignals.
Tencent Releases HY-Embodied-0.5: Open-Source MoT Models for Edge Robotics
Tencent has released HY-Embodied-0.5, a family of foundation models designed for real-world embodied agents, with the 2B MoT variant now open-sourced for edge deployment on 16GB VRAM GPUs @TencentHunyuan. Trained on 100M+ embodied samples, the models utilize a Mixture-of-Transformers (MoT) architecture where only 2.2B parameters are active at inference, providing dense-2B speeds with the spatial-temporal perception of a much larger model @yaelkroy.
Across 22 embodied benchmarks, the MoT-2B outperformed SOTA competitors like Qwen3-VL 4B and RoboBrain 2.5 on 16 tasks, scoring 89.2 on CV-Bench and 92.3 on DA-2K @TencentHunyuan. While it trailed slightly in some planning tasks, its specialized visual/embodied routing provides a significant edge in raw perception and spatial reasoning @yaelkroy.
Builders are praising this 'robot brain' for its low-latency VLA pipeline capabilities that don't require a cloud connection @rayanabdulcader. This release, combined with the 32B variant that approaches Gemini 3.0 Pro performance, signals a shift toward high-capability autonomy that can live entirely on consumer-grade hardware @ModelScope2022 @AIBuddyRomano.
Shopify Grants Coding Agents Direct Store Backend Access via MCP
Shopify’s new AI Toolkit is a massive step for the agentic web, enabling agents like Claude Code, Cursor, and VS Code to directly manage store backends across 5.6 million stores generating $378B GMV @aakashgupta @Shopify. Merchants can now issue prompts to agents to rewrite SEO descriptions, update alt text, or manage inventory in bulk without manual data entry @mikefutia.
However, the lack of built-in security protocols like native undo functions or rate limits in the official documentation has sparked concern among builders @Shopify. Developers like @MaxCurnin and @GoKiteAI have warned that unconfirmed agent prompts—such as 'apply a 15% discount to all products'—could lead to bulk pricing errors or inventory wipes without human oversight.
Despite the risks, the connector-free 'skills marketplace' is being viewed as a blueprint for AI-native platforms @clairevo. While early adopters report a seamless 90-second setup, the burden of creating safety sandboxes and pre-execution confirmations currently rests entirely on the developers building the agents @jpaylor @aitoolsbeacon.
In Brief
Hermes Agent Gains Traction as Self-Coding Challenger to Claude Code
Hermes Agent from Nous Research is emerging as a high-performance, self-improving open-source alternative to proprietary coding tools. Lead engineer @Teknium reports spending over $1,000 daily using the agent itself to build its own codebase, utilizing a 3-layer memory architecture to maintain project-level understanding without context bloat @NousResearch. Builders note it already tops GitHub trends with 100K+ stars and runs efficiently on local hardware like the RTX 3060, outperforming some proprietary rivals in UX and speed @Sentdex @dabit3.
Data-Driven Agent Evals and Tiered Routing for Cost-Efficient Optimization
Building production agents is increasingly focused on tiered routing and 'hill climbing the harness' to achieve Pareto-optimal performance and cost. Guides from @freeCodeCamp and @Vtrivedy10 emphasize selective task delegation, where routine work goes to quantized models to cut costs by up to 60% @ManaevLab. New tools like FastRouter enable this intelligent routing in real-time, while multifaceted evals from Stanford and others are moving beyond simple task rewards to analyze behavior and efficiency @FastRouterAI @stanfordnlp.
xAI Sues Colorado Over First-of-its-Kind AI Anti-Discrimination Law
xAI has filed a federal lawsuit to block Colorado's SB24-205, arguing the nation's first comprehensive algorithmic discrimination law violates the First Amendment. The law mandates that developers identify and mitigate disparate impacts on protected classes, with penalties of $20,000 per violation starting in 2026 @rohanpaul_ai @Raindropsmedia1. While supporters like @TheProfitPup view the suit as a defense of AI 'truth engines' against compelled ideological alignment, critics like @raphousetv2 warn that blocking these safeguards could enable biased outcomes in critical decisions like hiring and housing.
GLM-5.1 Powers Droid with Frontier Multi-Agent Orchestration at Half the Cost
The 754B parameter GLM-5.1 MoE model has been integrated into the Droid framework, delivering frontier performance for long-horizon tasks at half the price of prior models. GLM-5.1 has demonstrated the ability to run for 8 hours autonomously, making over 6,000 tool calls in complex environments @Zai_org @FactoryAI. Builders like @0xSero and @JoelDeTeves report it outperforming GPT-5.4 on specific MCP-based porting and multi-agent missions, though rate limits remain a bottleneck for some users @AkhlaquorRahman.
Quick Hits
Agent Frameworks & Orchestration
- @Vtrivedy10 shared a runnable guide for orchestration patterns including routing, handoffs, and subagent fanouts.
- Claude Code's architecture is being analyzed for its native integration with 182 agents in an orchestration ecosystem @tom_doerr.
- A new universal marketplace for AI agent skills has launched, aiming to standardize agent capabilities @tom_doerr.
Tool Use & Function Calling
- MCP servers should include skills in the resources section with tool fallbacks for older clients @RhysSullivan.
- A new library for precise JSON extraction from LLM outputs has been released @tom_doerr.
Agentic Infrastructure
- Elixir's Jido agents can reportedly run thousands of simultaneous agents on hardware as minimal as a Raspberry Pi @mikehostetler.
- Technical leaders from Zilliz and Gorgias are meeting to discuss building agents with unstructured data in production @milvusio.
- An anti-detection browser server for AI agents has launched to assist with web scraping and automation tasks @tom_doerr.
Research & Benchmarks
- A new paper argues that LLM training is essentially lossy compression approaching the Information Bottleneck bound @iScienceLuvr.
- A 57-day longitudinal study found that all frontier models currently decline in live prediction markets @iScienceLuvr.
Reddit Deep-Dive
Hidden model names leak at OpenAI while builders pivot from passive retrieval to active 'Agentic Memory.'
The veneer of the 'stable' frontier is cracking. Between OpenAI's porous staging environments leaking names like 'Arcanine' and Anthropic's 'Mythos' tier surfacing through the grapevine, we are getting a glimpse of the heavy-duty reasoning infrastructure labs are dogfooding for autonomous agents. But while the labs fight for the model crown, practitioners are hitting the 'Governance Wall.' It is no longer enough to have a smart model; you need a system that doesn't forget its instructions or accidentally wipe a production database. Today’s issue highlights a major shift in how we build: moving away from passive 'pull-based' RAG toward active 'Agentic Memory' (AgeMem) and dynamic least-privilege governance. We are also seeing the '70% ingestion tax' finally being named—a reality check for anyone who thought RAG was just about vector search. From $0-cost swarms to chaos-tested orchestration, the focus is shifting from 'how smart is the model?' to 'how resilient is the system?' This shift signals a move toward persistent, self-improving assistants that can handle the messy reality of production deployments. Let’s dive in.
OpenAI Internal Model Names Leak via Codex r/OpenAI
A potential major leak occurred within the OpenAI Codex environment, briefly exposing a dropdown list of unreleased and internal models including names such as GPT-5.5, Arcanine, and Glacier-alpha. Captured on video by u/DavidAGMM, the list follows a pattern of porous deployment cycles where GPT-5.4 has reportedly leaked three times through GitHub pull requests and internal logs. The presence of these identifiers suggests OpenAI is moving toward continuous, smaller version increments rather than monolithic annual releases.
Practitioners are particularly interested in whether 'Arcanine' or 'Glacier' represents new architectures for agentic reasoning or high-frequency tool use. This internal exposure mirrors competitive pressures from Anthropic, where details of a secret model tier codenamed 'Mythos' (internally 'Capybara') recently surfaced, promising a significant jump in performance over the current Opus 4.7 architecture. The accidental exposure suggests that both labs are dogfooding next-generation reasoning agents that require specialized, unreleased infrastructure to handle complex autonomous loops.
Agent Memory Architecture: The Shift to 'Push-Based' Active State r/ClaudeAI
The industry is pivoting toward 'Agentic Memory' (AgeMem), treating memory operations like store, update, and discard as first-class callable tools rather than passive vector searches. u/snozberryface argues that current 'pull-based' memory is insufficient for long-running projects, as evidenced by the MemoryArena benchmark where agents using active memory achieved an 80% task completion rate compared to 45% for long-context-only baselines. To combat 'positioning drift' in complex workflows, developers are adopting frameworks like Mem0 and MemEvolve, which utilize hierarchical schemes to proactively update context as work progresses.
Breaking the Governance Wall: Dynamic Least-Privilege r/AI_Agents
As agents move from retrieval to active execution, organizations are adopting a 3-tiered governance framework to match oversight intensity to use-case risk. u/Virtual_Armadillo126 reports that governance has become the primary bottleneck for deploying agents, leading to the rise of the 'AI Director' role to manage fleets of 10 to 100+ agents. Technical enforcement is hardening within the Model Context Protocol (MCP) ecosystem, with u/delimitdev recently releasing a governed PR primitive featuring an explicit 'action denylist' to block high-risk operations before they reach whitelist checks.
Moonshot Open Sources FlashKDA for H20 Hardware r/LocalLLaMA
Moonshot AI has open-sourced FlashKDA kernels that achieve a 2.22x speedup over Triton baselines, enabling Kimi K2.6 to dominate in specialized GLSL and WGSL shader authoring tasks.
Trooper Proxies and the INT3 Compression Frontier r/ollama
To manage rising token costs, u/Substantial_Load_690 released 'Trooper,' a proxy that automatically reroutes cloud LLM traffic to local Ollama instances when quotas are hit.
The '70% Ingestion Tax' and Chunk Overlap Poisoning r/LLMDevs
Practitioners report that 70% of RAG engineering time is now spent on ingestion, with u/lucasbennett_1 warning that standard 25% chunk overlap can lead to 70% duplicate content in retrieval results.
OpenAI Agents SDK vs. LangGraph: Chaos Testing Resilience r/LangChain
While OpenAI's SDK is criticized for 'clunky' delegation, u/sawfishmanta demonstrated LangGraph's resiliency by successfully running 100 agents through random failure chaos testing.
Non-Coder Orchestrates 900-Account AI Swarm r/automation
A viral report details a self-evolving swarm that iterated through 219 generations of improvement by leveraging free-tier credits across 900 accounts and 11 different platforms.
Discord Dispatches
Frontier models stall at 45% success rates as the industry standardizes tool integration.
The agentic ecosystem is currently defined by a sharp contrast: we are building world-class infrastructure while hitting a cognitive ceiling. On one hand, the arrival of the Model Context Protocol (MCP) and LangGraph’s new Functional API signals that the 'plumbing' of the Agentic Web is maturing. We finally have the 'USB ports' and state management tools needed to build complex systems without drowning in boilerplate. Developers are reporting 30% reductions in code and 10x faster integration times, suggesting the mechanical hurdles of agent-tool communication are being solved. On the other hand, the latest GAIA benchmark results serve as a cold shower. With success rates for frontier models like GPT-5 Mini stalling below 45%, the 'planning wall' is real. It turns out that while our agents are getting much better at talking to tools, they still struggle with the high-level reasoning required to navigate long-horizon tasks reliably. For builders, the meta is shifting from raw autonomy to structured orchestration. Today’s issue explores how the industry is hardening the stack—from graph-based memory to local infrastructure—to move past these reasoning bottlenecks.
GAIA Benchmark Exposes the 'Planning Wall' as Success Rates Stall Near 45%
The General AI Assistants (GAIA) benchmark is proving to be a sobering reality check for the industry. Despite the hype surrounding autonomous agents, recent data reveals a persistent 'planning wall' where even frontier models like GPT-5 Mini and Claude 3.7 Sonnet are stalling out. Success rates are currently peaking at 44.8% and 43.9% respectively, according to PricePerToken, suggesting that over half of complex, multi-step tasks still result in failure.
Researchers at HuggingFace and Princeton's HAL attribute these failures to a 'reliability gap.' Agents struggle to reproduce successful outcomes on identical tasks because they lack robust internal world models. While tool invocation has reached relative maturity with 91.5% accuracy in recent reports, the jump to long-horizon planning remains the industry's steepest climb.
The cost of fixing this is high. While prompt caching has made models like Claude 3.5 Sonnet more efficient Reddit, the industry is still grappling with the latency trade-offs required for explicit 'reflection' steps. Practitioners are now shifting focus toward specialized orchestration to bridge the gap between simple execution and durable reasoning AwesomeAgents.
MCP Becomes the 'USB Port' for Agentic Tool Integration
The Model Context Protocol (MCP) has solidified its role as the industry’s 'USB port,' enabling a modular architecture where AI agents connect to diverse data sources without custom integration for every model release. Developers report that adopting MCP provides a 30% reduction in boilerplate code for tool-heavy workflows Anthropic. The ecosystem is expanding rapidly with new enterprise-grade servers from Salesforce, Slack, and Heroku, though practitioners highlight that critical security gaps such as prompt injection must be addressed as adoption scales The New Stack Merge.dev.
LangGraph Functional API Simplifies Cyclic Orchestration
LangChain has introduced a new Functional API for LangGraph, specifically designed to simplify the creation of complex agentic state machines by reducing class-based boilerplate. This update allows developers to build AI workflow agents with minimal code changes, transforming how state persistence and human-in-the-loop interventions are implemented LangChain. Early adopters note that this shift toward a functional paradigm significantly improves the readability of agentic logic, making it easier to manage the 'messy realities' of production environments AI Tinkerers.
Mem0 Implements Graph-Based Dynamic Context Management
Mem0 claims a 50% improvement in recall accuracy by using a graph-based memory layer that extracts and deduplicates information across user sessions Mem0.
Ollama Hardens Local Agent Infrastructure with Native Tool Calling
Ollama has officially transitioned to native tool calling support for Llama 3 and Mistral, driving a 90% reduction in inference costs for local 'router' agents Ollama.
MultiOn API Hardens Autonomous Browsing for Enterprise RPA
MultiOn has launched its Agent API, utilizing a 'Step-by-Step' verification process to ensure 95% reliability when performing high-stakes browser actions MultiOn Docs.
HuggingFace Highlights
Hugging Face's smolagents and IBM's CUGA are moving the industry from probabilistic chat to deterministic, code-driven execution.
The 'Agentic Web' is moving out of its honeymoon phase with chat-based interfaces and into a more rigorous era of code execution and diagnostic benchmarking. Today's release of Hugging Face’s smolagents signals a significant shift: developers are increasingly abandoning complex, brittle JSON schemas in favor of raw Python actions. By treating 'actions as code,' frameworks are achieving double-digit gains in efficiency and topping benchmarks like GAIA. This isn't just about speed; it's about moving toward deterministic reliability in systems that actually perform tasks.
We are also seeing the 'small model' revolution hit a tipping point. Models in the 1B to 9B range, like xLAM and Holotron-12B, are now rivaling GPT-4o in specialized function-calling and high-frequency GUI navigation. This means the future of agents likely isn't one giant model in the cloud, but a swarm of specialized sub-agents running locally or on high-throughput SSM engines. Meanwhile, IBM and Berkeley are providing the 'MRI machines' for these systems—diagnostic tools like IT-Bench and the MAST taxonomy—to finally explain why enterprise agents fail. The message is clear: the path to production isn't more talk; it's better execution and deeper observability.
Code-Centric Agents: The Rise of smolagents
Hugging Face has introduced smolagents, a minimalist library that pivots agentic actions away from complex JSON schemas toward raw Python code execution. By treating 'actions as code,' the framework achieves a 30% reduction in logic steps and LLM calls compared to traditional JSON tool-calling frameworks like LangChain gitpicks.dev. This minimalist approach is powered by a core library of only ~1,000 lines, allowing developers to build MCP-powered agents in as few as 50 lines of code Hugging Face.
The performance of this paradigm is most evident in the Transformers Code Agent, which recently topped the GAIA benchmark, a rigorous test of general AI assistants Hugging Face. Beyond raw reasoning, the ecosystem has expanded to include native Vision-Language Model (VLM) support, enabling agents to process visual UI elements while executing code Hugging Face. For enterprise-grade reliability, the framework integrates with smolagents-phoenix for tracing and evaluation, moving the industry toward deterministic action over probabilistic schemas nolist.ai.
Beyond Chat: High-Throughput SSM Engines and the 8.9k Token/s Frontier
The frontier of agentic workflows is shifting from vision-only models to high-throughput execution engines designed for real-time interaction. H Company has released Holotron-12B, a State Space Model (SSM)-based agent post-trained from NVIDIA Nemotron-Nano-2 VL that achieves a staggering 8.9k tokens/s on a single H100. This performance leap has driven WebVoyager success rates from 35% to 80%, allowing the Surfer-H GUI agent to operate with high-frequency screen processing and sub-pixel control that rivals proprietary systems. To support this, tools like ScreenSuite and ScreenEnv provide the evaluation infrastructure needed for full-stack desktop agents navigating real-world software.
The Diagnostic Era of Agent Benchmarking
As agents transition into production, the industry is shifting from static LLM evaluations to dynamic, diagnostic frameworks. IBM Research and UC Berkeley have introduced IT-Bench and the MAST taxonomy to pinpoint why enterprise agents fail, revealing a persistent 20% success ceiling in complex IT environments. Research identifies 'Incorrect Verification' as the primary failure mode, where agents fail to accurately assess environment states after tool execution, a finding complemented by AssetOpsBench for simulated operational environments.
Small Models, Big Tools: The xLAM-Driven Revolution
The shift toward verticalized, small-scale models for agentic tasks is accelerating, driven by high-quality synthetic datasets. Carnice-9B utilizes Unsloth to achieve 2x faster training while targeting performance levels that rival GPT-4o in zero-shot tool selection on the Berkeley Function Calling Leaderboard. Industry experts like @unslothai note that these optimizations, including sub-1.5B variants, are critical for deploying agentic loops on consumer hardware without the latency of API-based calls.
Open-Sourcing the Research Agent Pipeline
Projects like Hugging Face Open Deep Research and Together AI are dismantling proprietary silos by replacing brittle JSON tool-calling with direct Python execution for multi-hop reasoning.
IBM's CUGA and the JavaScript Frontier
IBM's CUGA now leads the AppWorld benchmark for complex task execution, while Agents.js and langchain-huggingface bring robust tool-calling to the JavaScript and partner ecosystems.