Standardizing the Agentic Web Stack
From MCP's 100M downloads to code-centric orchestration, the infrastructure for reliable autonomous agents is finally snapping into place.
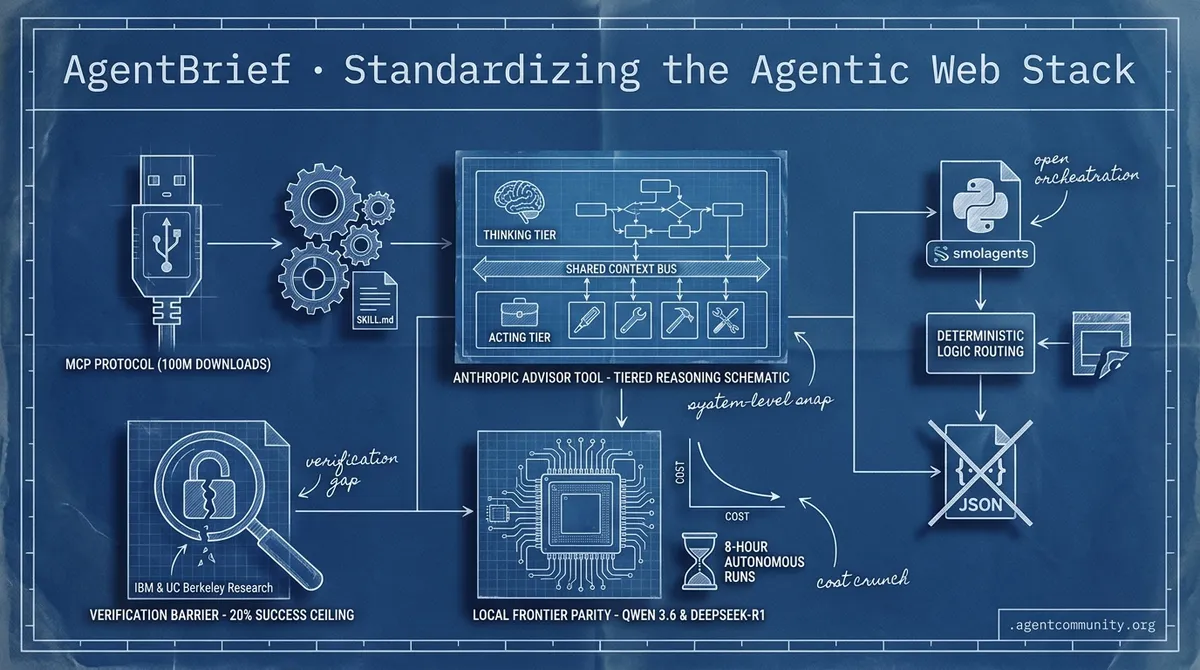
- Standardized Tooling Protocols The Model Context Protocol (MCP) has hit nearly 100 million downloads, cementing its place as the industry's 'USB port' for tool interoperability alongside the open-standard maturation of SKILL.md.
- Local Frontier Parity Alibaba's Qwen 3.6 and DeepSeek-R1 are proving that dense local models and aggressive price cuts are making long-horizon, 8-hour autonomous runs economically viable without relying on expensive proprietary APIs.
- Code-Centric Logic Routing Builders are shifting from brittle JSON tool-calling to direct Python execution with smolagents, prioritizing deterministic logic and 'thinking vs. acting' model tiers to improve orchestration.
- The Verification Barrier Despite infrastructure gains, research from IBM and UC Berkeley highlights a persistent 20% success ceiling in enterprise tasks, primarily due to the difficulty agents have in verifying if their actions actually worked.
X Orchestration Intel
Stop building monolithic prompts; the era of tiered agent reasoning has officially arrived.
We are moving past the 'single-prompt' era. The news this week signals a structural shift toward orchestration as a native primitive. Anthropic is formalizing the 'thinking model vs. acting model' pattern with its advisor tool, while open-weight contenders like GLM-5.1 are proving that long-horizon autonomy—sustaining 8-hour runs and thousands of tool calls—doesn't require a trillion-parameter bank account. For builders, this means our job is less about prompt engineering and more about logic routing: deciding when to spend the 'expensive' tokens on strategy and when to let the cheaper executors run the tools. Meanwhile, infrastructure is catching up fast. Shopify’s MCP integration puts millions of store backends behind a terminal, but it also highlights the terrifying 'blast radius' of agents with write access and no guardrails. We are finally seeing the tools that turn agents from toys into team members, but the burden of safety and orchestration logic is falling squarely on us. If you are still shipping static chains without shared state, you are already behind.
Anthropic Advisor Tool Unlocks Tiered Agentic Reasoning with Shared Context
Anthropic has launched its advisor tool in public beta, a breakthrough that allows executor models like Sonnet or Haiku to consult Opus for strategic guidance within a single Messages API request @claudeai. When an executor encounters a complex decision, it calls the advisor (via anthropic-beta: advisor-tool-2026-03-01), which provides 400-700 tokens of high-level planning that is hidden from the final user output @claudeai. This system uses a shared context, ensuring the strategist sees the full conversation history and task state without the fragmentation typical of manual multi-model handoffs @aibuilder0x.
Internal benchmarks demonstrate massive efficiency gains: a Sonnet + Opus advisor pairing scored 74.8% on SWE-bench Multilingual, representing a 2.7pp improvement over Sonnet alone at an 11.9% lower cost per task ($0.96 vs $1.09) @claudeai. Even more striking, Haiku + Opus hit 41.2% on BrowseComp, a 21.5pp jump that costs 85% less than running Sonnet solo @akshay_pachaar. Builders like @aakashgupta note this effectively solves the 'agent cost wall' by cutting dead-end fix attempts.
This release formalizes multi-model routing as a core industry primitive, shifting the focus of agent design from monolithic prompts to sophisticated orchestration logic @joshclemm. While developers previously emulated this behavior manually, native support for shared state in a single call significantly lowers the barrier to entry for building high-reasoning agents @aibuilder0x. Despite these gains, some community members like @saneord warn that rate limits remain a primary concern for scaling these tiered workflows.
GLM-5.1 and Hermes Agent Challenge Frontier Standards with Long-Horizon Gains
Z.ai's GLM-5.1, a 754B MoE open-weight model, has debuted as a top-tier contender for agentic workflows by hitting #1 for open-source and #3 globally on SWE-Bench Pro with a 58.4% score @Zai_org. Optimized for long-horizon tasks, it is capable of sustaining 8-hour autonomous runs with over 6,000 tool calls, outperforming proprietary giants like Claude Opus 4.6 and GPT-5.4 on benchmarks like Terminal-Bench and NL2Repo @TheAhmadOsman @FactoryAI. Builders are already reporting frontier-level performance at half the cost of prior models for complex MCP tool tasks @0xSero.
Simultaneously, Nous Research’s Hermes Agent continues its rapid ascent, surpassing 100k GitHub stars and dominating agent benchmarks with a score of 85/100 when paired with GLM-5.1 @stevibe. The framework's 3-layer memory and self-improving skill set enable reliable local execution, with @dabit3 highlighting superior UX and speed on consumer hardware like the RTX 3060. Recent updates include a built-in architecture-diagram skill and persistent workspace configurations that community members say beat proprietary rivals for production readiness @JulianGoldieSEO.
These advancements significantly lower the barriers for high-volume local agentic tasks, particularly with platforms like BytePlus ModelArk offering GLM-5.1 without throttling @BytePlusGlobal. While some critics like @bridgebench suggest these models might be over-optimized for benchmarks, real-world evaluations from builders like @leo_linsky affirm that the gains in orchestration and tool-use reliability are genuine.
In Brief
MCP Skills Standardization Advances with 'load_resources' Fallback
Developers are converging on standardized patterns for delivering agent skills via the Model Context Protocol (MCP) to fix client compatibility issues. @RhysSullivan proposed that MCP servers include skills in the resources section while using a 'load_resources' tool as a fallback, a move endorsed by MCP co-creator @dsp_. This approach aims to unify the experience across tools like Claude and Cursor, where some clients currently fail to read resources natively @ModernGrindTech. Furthermore, @ibuildthecloud highlights that 'skills://' URIs offer a safer alternative to system prompts for tool guidance, though @itsgreyum warns that treating tool results as potential prompt injections remains a hurdle for seamless agent workflows.
Tencent Open-Sources HY-Embodied-0.5 MoT Models for Edge Robotics
Tencent has released HY-Embodied-0.5, a 2B Mixture-of-Transformers (MoT) foundation model optimized for real-world embodied agents on 16GB VRAM hardware. The architecture activates only 2.2B parameters during inference to achieve dense-2B speeds while maintaining superior spatial perception through latent tokens and on-policy distillation from a 32B model @yaelkroy @0xCVYH. Trained on 100M samples, the model outperformed Qwen3-VL 4B on 16 of 22 benchmarks, achieving a 92.3 on DA-2K @agentcommunity_. While builders like @AIBuddyRomano praise the 'real robot brains' for edge deployment, @yaelkroy notes it still trails in complex reasoning tasks like RoboBench-Planning.
Shopify AI Toolkit Grants Coding Agents Direct Write Access to 5.6M Backends
Shopify’s new AI Toolkit allows agents like Claude Code and Cursor to directly manage products, inventory, and SEO across 5.6 million stores via MCP. This integration enables a single prompt to execute tasks that previously required expensive audits or virtual assistants, such as optimizing 32 product listings in 90 seconds @aakashgupta @mikefutia. However, the lack of native safeguards like undo functions or scope limits has sparked concerns about the 'blast radius' of such access, with critics like @MaxCurnin and @Neuzhou_ warning of potential inventory wipes or prompt injection vulnerabilities. Builders are advised to implement manual backups and pre-execution checks as the ecosystem matures @jpaylor.
Quick Hits
Models for Agents
- GPT 5.4 Pro is cited as a 'wicked good' deep planning model for failing-edge tasks by @Vtrivedy10.
- Google has released Gemini 3.2 Pro in an experimental preview for developers @willccbb.
Agent Frameworks & Orchestration
- A comprehensive guide for multi-agent patterns including routing and sub-agent fanouts has been released by @sydneyrunkle.
- 'Claude Ads' now enables agents to run 190 audit checks across ad stacks using 6 parallel sub-agents @ihtesham2005.
Industry & Ecosystem
- xAI has filed a lawsuit against Colorado to block an AI discrimination law on First Amendment grounds @rohanpaul_ai.
- TSMC's revenue surged 35% to a record high, signaling massive sustained demand for AI silicon @CNBC.
Agentic Infrastructure
- Scaling to 10,000 agents per human may require the 2mb-per-agent efficiency of Elixir/Jido @mikehostetler.
- The 'Prediction Arena' is a new benchmark for evaluating frontier models on real-world trading performance @iScienceLuvr.
Reddit Local-First Roundup
Alibaba's new 27B dense model is matching 'mini' frontier models while SKILL.md quietly becomes the playbook for the agentic web.
The Agentic Web is moving out of the experimental "vibe-based" era and into a period of hard engineering and standardization. Today’s landscape is defined by two converging trends: the arrival of local models that can actually hold their own against frontier systems, and the maturation of the protocols that connect them to the real world. Alibaba’s Qwen 3.6 27B model is a landmark for the local-first movement, matching GPT-5 mini's coding performance on SWE-bench and proving that dense architectures still have plenty of fight left against the Mixture-of-Experts (MoE) trend.
But a model is only as useful as its integration. The shift of SKILL.md from a proprietary Anthropic spec to an open standard is the "playbook" moment we have been waiting for. It allows agents to share capabilities across platforms—from Cursor to Gemini—without bloated context windows. We are seeing the infrastructure for a verifiable agent economy take shape, from the industrialization of Model Context Protocol (MCP) servers to the emergence of cryptographically signed agent identities. For developers, the focus is shifting from simple chat interfaces to the governance of autonomous systems.
Qwen 3.6 Dense vs. MoE: The Battle for Local Agentic Dominance r/LocalLLM
Alibaba has released Qwen 3.6, and the 27B dense model is already causing a stir in the local development community. According to u/TroyNoah6677, this architecture effectively renders previous 397B MoE models obsolete for coding tasks. This isn't just hyperbole; the series achieved a 72.4 on SWE-bench Verified, matching frontier models like GPT-5 mini. While the 35B MoE variant offers a sparse alternative with only 3B active parameters, early benchmarks from BenchLM.ai indicate the dense variant maintains a stronger profile for complex agentic reasoning.
For those running on consumer hardware like the RTX 3090 or 4090, the performance is impressive, with speculative decoding reaching 13.60 t/s. However, practitioners need to be wary of the memory overhead. u/Historical-Crazy1831 notes that KV cache management in vLLM may restrict the 128k context window to roughly 120k on 48GB VRAM setups. Builders are currently recommending a temperature of 0.6 for the highest precision in web development tasks, particularly when working with Svelte 5.
SKILL.md Emerges as the Open Standard for Agentic Playbooks r/AI_Agents
The SKILL.md format has officially transitioned from an internal Anthropic spec to the "Agent Skills Open Standard," signaling a major shift toward interoperable agentic playbooks. Adoption has scaled rapidly to over 20 agents, including Cursor and Gemini CLI, as developers like u/BadMenFinance highlight the protocol's ability to preserve context window space by loading task-specific behaviors only when needed. This movement is being bolstered by a curated library of 2,636+ skill files and a growing "Prompt Ops" community advocating for version-controlled system prompts to prevent production drift.
Opus 4.7's Adaptive Thinking Hits Token and Latency Walls r/ClaudeAI
Anthropic’s Opus 4.7 rollout has introduced "Adaptive Thinking," but the update is meeting resistance due to increased token costs and significant latency walls. While some users report faster problem-solving, u/Longjumping_Cover453 has flagged instances of the model hallucinating administrative capabilities to end sessions early, and official docs confirm the new tokenizer can increase token usage by up to 35%. With time-to-first-token benchmarks hitting as high as 12.37s on Google, developers are turning to "task budgets" and monitoring tools like "Clauditor" to manage the rising overhead.
MCP Industrialization: From Financial Swarms to Production Gateways r/mcp
The Model Context Protocol (MCP) is entering an industrial phase, moving from local scripts to remote data swarms covering everything from SEC filings to 8,200 Indian stocks. New servers like 'BankRegPulse' are turning agents into specialized financial experts, but this scale has triggered a critical security vibe shift regarding how tools interact across domains. As practitioners deploy chaos engineering and RBAC via tools like the 'mcp-production-toolkit', the community is coalescing around On-Behalf-Of (OBO) authentication and external authorization layers like Keycloak to ensure agents only execute actions with explicit, scoped permissions.
Agentic Memory Transitions to Wikis r/LocalLLaMA
The industry is moving toward "Agentic Wikis" and tools like llm-wiki-compiler to eliminate the 70% ingestion tax of traditional RAG architectures.
The Verified Agent Labor Market r/AgentsOfAI
TensorAgent OS and the "JackedIn" network are introducing cryptographically verified agent labor through the Agent-to-Agent Trust (A2AT) protocol.
Tool Results as Injection Surfaces r/AI_Agents
Researchers are warning of Indirect Prompt Injection (IPI) where agents autonomously retrieve attacker-controlled data embedded in external tool results.
Slashing Local Memory with ShadowPEFT r/LocalLLM
ShadowPEFT and async-native architectures like SynapseKit are slashing memory overhead by 15-20% and boosting throughput for multi-agent handoffs.
Discord Action Analytics
OpenAI's Operator and Anthropic's MCP are turning the 'agentic web' from theory into a 97-million-download reality.
We are witnessing the infrastructure of the Agentic Web snap into place. For months, 'agents' were a buzzword for glorified chat wrappers; today, the data suggests a shift toward hardened, autonomous systems. OpenAI’s 'Operator' and Anthropic’s Computer Use are locked in a battle for browser dominance, but the real story lies in the plumbing. The Model Context Protocol (MCP) has hit nearly 100 million downloads, providing the 'USB port' the industry desperately needed for tool interoperability.
Meanwhile, the economics of intelligence are being rewritten. DeepSeek-R1’s 95% price reduction compared to frontier reasoning models changes the math for long-horizon loops. It’s no longer about whether an agent can reason—it’s about how many steps you can afford to run. From PydanticAI’s type-safe validation to AutoGen 0.4’s event-driven architecture, the tools are moving from experimental to enterprise-ready. As coding agents hit 40% resolution rates on real-world GitHub issues, the 'complexity ceiling' is the only thing left to break. For builders, the message is clear: the era of the 'Large Action Model' has arrived, and the standard stack is finally here.
OpenAI Operator vs. Anthropic: The Battle for the Action-Oriented Web
OpenAI’s launch of 'Operator' has fundamentally shifted the industry focus from conversational chat to autonomous browser execution. While initial reports suggested a 90% success rate, technical benchmarks now place Operator at an 87% success rate on specialized web tasks. This performance significantly outpaces Anthropic’s Computer Use in browser-native environments, though Anthropic maintains a lead in cross-application coding workflows according to @helicone.
Developers are increasingly validating the 'Large Action Model' (LAM) thesis, noting that Operator’s reliance on vision-language models allows it to navigate dynamic UI elements that traditional DOM-scrapers fail to parse. The ecosystem is now bifurcating between OpenAI's purpose-built browser logic and Anthropic's broader desktop-control approach. This divergence is forcing practitioners to choose between specialized browser efficiency and generalized system control.
As OpenAI introduces the BrowseComp benchmark to standardize evaluations, the rise of 'agent-first' startups is accelerating in sales and procurement automation. This shift marks a transition from agents that talk to agents that do, prioritizing reliability in high-stakes browser environments over general-purpose chat capabilities.
MCP Hits 97M Downloads as Enterprise Adoption Reaches 28%
The Model Context Protocol (MCP) has rapidly evolved into the 'USB port' for AI agents, reaching 97 million downloads and a 28% implementation rate among Fortune 500 companies. Inspired by the Language Server Protocol (LSP), MCP allows developers to build a single connector usable across any agentic framework, effectively decoupling integration from model-specific logic. Alex Albert at Anthropic emphasizes that this standardization is the 'missing link' for multi-agent interoperability, reducing the friction of tool discovery across the ecosystem. Join the discussion: discord.gg/anthropic
DeepSeek-R1 Slashes Reasoning Costs by 95% as Tool-Calling Parity Emerges
DeepSeek-R1 is fundamentally altering the economics of the Agentic Web by offering reasoning capabilities on par with o1 at a 95% lower price point—with input costs as low as $0.55 per million tokens. In tool-calling scenarios, particularly within MCP workflows, the model is proving that high-latency 'System 2' thinking can be both reliable and affordable. This democratization is shifting the industry focus from raw model access to the orchestration of long-horizon 'agentic loops' that were previously cost-prohibitive. Join the discussion: discord.gg/deepseek
LangGraph Functional API vs. AutoGen: The Battle for Stateful Orchestration
LangGraph has introduced a Functional API to reduce class-based boilerplate, while Microsoft’s AutoGen 0.4 rewrite transitions the framework into a robust, event-driven programming framework. LangGraph's architectural choice allows for 100% predictable execution and robust audit trails, while AutoGen is now specifically engineered to handle the high-concurrency demands of enterprise automation with support for 1,000+ concurrent agents. These updates directly address the 'reliability gap' in previous iterations, allowing for more deterministic and dynamic agentic workflows.
Production Hardening and Local Parity
- PydanticAI is hardening production agents with type-safe validation, demonstrating a 40% reduction in runtime validation errors.
- Agentic coding resolution has reached 40.6% on SWE-bench Verified, marking a significant ascent from the 4% baseline in early 2024.
- Mistral Nemo 12B has achieved 92.5% accuracy in sequential tool-calling, bringing local function-calling to parity with cloud frontier models. Join the discussion: discord.gg/pydantic Join the discussion: discord.gg/localai
HuggingFace Research Recap
From code-centric orchestration to sub-pixel GUI control, the Agentic Web is getting a diagnostic reality check.
The 'Agentic Web' has long suffered from a 'vibe' problem—we build complex multi-agent systems and hope the JSON-based tool calls hold together under pressure. This week, we are seeing a decisive shift toward architectural rigor. Hugging Face's smolagents is leading the charge by ditching brittle JSON for direct Python code execution, a move that recently propelled them to the top of the GAIA benchmark. This isn't just about efficiency; it's about making agents more deterministic and debuggable by treating actions as code.
However, as we push for more autonomy, the industry is hitting a persistent wall. New diagnostic work from IBM Research and UC Berkeley reveals a 20% success ceiling in enterprise IT tasks, largely due to 'Incorrect Verification'—the agent's inability to confirm if its actions actually worked. Between high-speed GUI agents like Holotron-12B and the standardization of the Model Context Protocol (MCP), we are finally building the telemetry and infrastructure needed to break through that ceiling. Today's issue explores how code-centric orchestration, specialized edge models, and open research loops are dismantling the proprietary silos of autonomous reasoning.
Smolagents: Redefining AI Orchestration via Code-as-Action
Hugging Face has introduced smolagents, a minimalist framework that shifts agentic actions from brittle JSON-based tool calling to direct Python code execution. By treating 'actions as code,' the framework achieves a 30% reduction in logic steps and LLM calls compared to traditional frameworks. This paradigm shift is most evident in the Transformers Code Agent, which recently topped the GAIA benchmark, a rigorous test of general AI assistants, by outperforming complex multi-agent systems.
The ecosystem has rapidly expanded to include native Vision-Language Model (VLM) support, allowing agents to process visual UI elements while executing code. To further improve reliability, the structured-codeagent enables better action execution through strict schema enforcement.
For production-grade observability, integration with smolagents-phoenix provides detailed tracing and evaluation, ensuring that autonomous code generation remains transparent and debuggable. This move toward deterministic code execution signals a departure from probabilistic chat-based tool use toward more reliable, verifiable agentic workflows.
High-Throughput SSM Engines Take Control of the Desktop
The frontier of computer use is expanding with the release of Holotron-12B, a high-throughput State Space Model (SSM) agent designed specifically for GUI automation. Post-trained from NVIDIA Nemotron-Nano-2 VL, Holotron-12B achieves a staggering 8.9k tokens/s on a single H100, enabling real-time desktop navigation with sub-pixel control according to @AIToolsPerformance. These models power the Surfer-H agent, which has demonstrated a leap in WebVoyager success rates from 35% to 80%, rivaling proprietary systems in action accuracy while maintaining significantly lower latency, as reported by H Company.
Beyond the 20% Ceiling: Diagnosing Why Enterprise AI Agents Fail
IBM Research and UC Berkeley have established a new diagnostic standard through IT-Bench and MAST, revealing that frontier models hit a persistent 20% success ceiling when troubleshooting complex IT environments. According to analysis by @IBMResearch, the top three failure modes are Incorrect Verification, Incorrect Tool Use, and Incorrect Reasoning. This finding is reinforced by the VAKRA benchmark, which identifies 'Incorrect Verification'—the agent's inability to accurately assess the environment state after executing a tool—as the single largest predictor of task failure.
Dismantling Proprietary Search Silos with Open Deep Research
Hugging Face and Together AI are democratizing long-form reasoning with Open Deep Research initiatives that leverage the smolagents framework to match proprietary multi-hop reasoning capabilities.
The 'USB Moment' for AI: MCP Standards and OpenEnv
The Model Context Protocol (MCP) is emerging as a 'USB for AI,' allowing agents to dynamically discover tools without manual documentation via the OpenEnv collaborative ecosystem.
Shrinking Agents for On-Device Function Calling
Edge autonomy is accelerating with FunctionGemma-270M, which enables zero-shot function calling directly on Apple's Neural Engine bypassing cloud-based latency.
From Agents.js to Tiny Agents: The JavaScript Ecosystem Evolves
Hugging Face has officially deprecated Agents.js in favor of MCP-based Tiny Agents, providing a standardized path for production-grade JavaScript agents.