Reasoning Models and Deterministic Flows
DeepSeek resets the intelligence floor as practitioners pivot from brittle swarms to deterministic flow engineering.
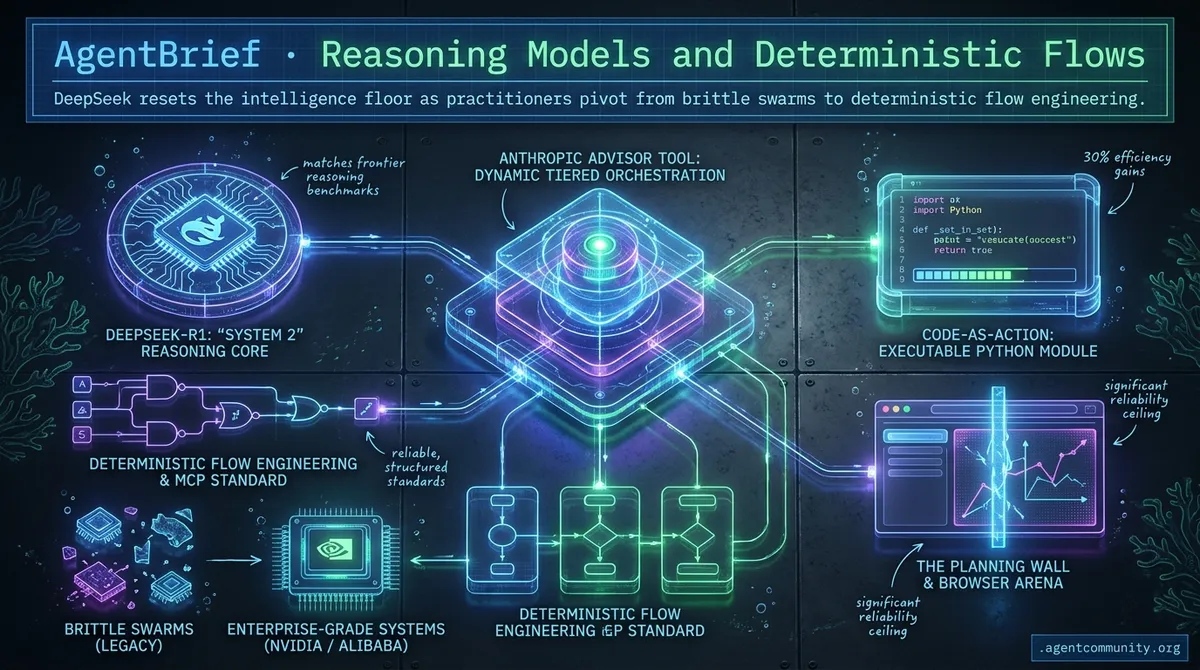
- Reasoning Democratized DeepSeek-R1 matches frontier reasoning benchmarks, shifting agent development from expensive prompting hacks to native 'System 2' reasoning workflows.
- Flow Over Swarms Builders are moving away from hallucination-prone multi-agent hierarchies toward deterministic flow engineering and structured standards like the Model Context Protocol (MCP).
- Code-as-Action The industry is pivoting from fragile JSON schemas to executable Python, with tools like smolagents delivering 30% efficiency gains in autonomous task execution.
- Infrastructure Maturity From Alibaba’s post-LLM architectures to NVIDIA’s physical AI, the plumbing for autonomous workloads is shifting from experimental prompts to enterprise-grade systems.
- The Planning Wall While the browser has become the primary arena for agentic action via OpenAI's Operator, current benchmarks reveal a significant reliability ceiling for multi-step tasks.
X Orchestration Insights
If you're still prompt-stuffing for agency, you're building for the past.
The agentic web is moving away from the 'magic prompt' era and toward a sophisticated architectural era. We are no longer just asking models to do things; we are building systems that manage models. Anthropic’s new Advisor tool is a perfect example—a formalization of the tiered orchestration patterns we’ve been hacking together with custom routing logic for months. It proves that the future of agency isn't just about the smartest model, but the most efficient hierarchy of models.
Simultaneously, the rise of self-evolving agents like Hermes signals a shift in the developer experience. When your agent starts writing its own code and managing its own skills via persistent memory, the line between 'tool' and 'collaborator' blurs. This issue covers the infrastructure shifts—from Shopify’s direct backend access to Alibaba’s $290M bet on post-LLM architectures—that are clearing the path for autonomous systems. For those of us shipping agents today, these updates aren't just features; they are the blueprints for the next generation of autonomous workloads.
Anthropic Launches Advisor Tool for Dynamic Tiered Orchestration
Anthropic's new advisor tool, currently in public beta, formalizes tiered orchestration by allowing executor models like Sonnet or Haiku to consult Opus for strategic guidance within a single Messages API request @claudeai. Developers can activate this capability using a specific beta header and defining the advisor tool to generate 400-700 token plans that remain hidden from the user, billing at Opus rates only for those specific reasoning tokens @hata_AI_master @akshay_pachaar.
Official benchmarks demonstrate the efficiency of this tiered approach: the Sonnet + Opus combination scored 74.8% on SWE-bench Multilingual, representing a +2.7pp increase over Sonnet alone while reducing costs by 11.9% per task @claudeai. Even more striking, the Haiku + Opus pairing hit 41.2% on BrowseComp, a massive jump from Haiku's solo 19.7%, making it 85% cheaper than using Sonnet alone @akshay_pachaar.
For agent builders, this formalizes the 'advisor model' pattern, potentially solving the 'agent cost wall' for long-horizon tasks as noted by @aakashgupta. While the community praises the one-line integration for reliable orchestration without manual handoffs, @ai_hakase_ cautions that rate limits may still act as a bottleneck for high-frequency production use.
Codex 5.4 Emerges as Deep Planning Powerhouse
Codex 5.4, powered by the GPT-5.4 Pro/Mythos engine, is gaining a reputation as a high-inference compute specialist designed for high-complexity reasoning. @Vtrivedy10 describes it as a 'wicked good' planning model that solves problems where other models fail, though its high API costs of 30/180 likely restrict its use to supervisor or architect roles in a multi-agent system.
The model exhibits a unique 'jagged intelligence' where performance scales non-linearly with task size. @rileybrown observed that the model actually performs better on larger, more complex tasks, while @NickADobos suggested it might struggle with shorter tasks simply because it has too much 'space' to overthink or hallucinate.
While users still prefer Opus for consistent frontend execution, Codex 5.4's tool-use capabilities are formidable, with recent GPT-5.5 evals showing a Terminal Bench score of 82.7% @chatgpt21. For builders, this reinforces the need for task-specific routing—using Codex for the deep architectural planning and leaner models for the actual execution @patliu007.
Hermes Agent Challenges Claude Code with Self-Evolution
Nous Research’s Hermes Agent has surged to over 100k GitHub stars, positioning itself as a powerful open-source competitor to Anthropic’s Claude Code @NousResearch. A standout feature is its recursive self-evolution; according to lead engineer @Teknium, the agent has written all of its own code since launch, using episodic memory to extract and reuse skills from completed tasks.
The framework utilizes a sophisticated 4-layer memory architecture—including local SQLite session search and curated procedural skills—that prioritizes on-demand retrieval over standard prompt stuffing @witcheer. This approach allows for full CLI and workspace access that isn't locked to a single directory, which @Teknium claims provides a superior coding experience when paired with Opus.
As Claude Code already accounts for roughly 4% of public GitHub commits @rauchg, the battle for the agentic IDE is heating up. Hermes’ swappable memory and self-evolving skill set offer a distinct alternative to the more static, session-heavy context of proprietary competitors @fancylancer3991.
In Brief
GLM-5.1 Delivers Frontier Agent Performance at Half the Cost
The release of GLM-5.1, a 754B MoE open-weight model, provides a cost-effective alternative for frontier agent capabilities, topping SWE-Bench Pro as the #1 open-source model. Integrated into frameworks like Droid, it handles 8-hour autonomous runs with over 6,000 tool calls at half the cost of prior models, though some builders note occasional timeouts when running via local setups like Ollama @Zai_org @agentcommunity_ @rschmelzer.
Shopify Grants Agents Direct Backend Write Access
Shopify has fundamentally expanded the scope of e-commerce automation by granting AI coding agents direct write access to store backends for products, orders, and SEO. This change allows agents to execute massive SEO optimizations across thousands of listings from a single prompt, effectively removing the human-in-the-loop bottleneck for catalog management @aakashgupta.
Tencent Releases HY-Embodied-0.5 Foundation Models
Tencent has open-sourced the 2B version of its HY-Embodied-0.5 family, a Mixture-of-Transformers (MoT) model designed specifically for real-world robot spatial-temporal perception. While a 32B version is reserved for complex reasoning, the release marks a significant step in the convergence of foundation models and physical robotics @TencentHunyuan @NandoDF.
Prediction Arena Benchmarks Frontier Agent Accuracy
A new longitudinal study on real-world prediction markets shows that GPT-5.4 leads the arena with a +1.22% return in paper trading, highlighting the difficulty of maintaining objective accuracy in agentic tasks. Many other frontier models have struggled to maintain consistent returns over long-term trading horizons, suggesting that dynamic agency still faces a significant reliability gap @iScienceLuvr.
Alibaba Invests $290M in Post-LLM Architectures
Alibaba has led a $290 million investment into new AI model architectures, signaling a strategic pivot away from traditional transformers to better support long-term reasoning. This move suggests that the industry is looking for new scaling laws specifically designed for autonomous agent behaviors as current transformer architectures reach diminishing returns @CNBC.
Quick Hits
Agent Frameworks & Orchestration
- A new open-source platform for orchestrating AI agent workflows has been released by @tom_doerr.
- AgentCraft's keynote focused on emerging UI patterns specifically designed for agent interaction @idosal1.
- Multi-agent orchestration guides now emphasize patterns for subagent fanouts and structured handoffs @Vtrivedy10.
Tool Use & MCP
- Claude Code users can now deploy an SEO audit skill that executes 190 automated checks via @tom_doerr.
- Developers are advised to include skills in the resources section of MCP servers to ensure better client compatibility @RhysSullivan.
- A universal marketplace for AI agent skills is currently under development by @tom_doerr.
Memory & Infrastructure
- Hermes Agent manages persistent state using local MEMORY.md and USER.md files for better workspace context @Teknium.
- Elixir is being touted as the ideal language for high-density agent workloads due to its low memory footprint @mikehostetler.
- TSMC revenue surged 35% on the back of massive demand for chips powering the agentic web @CNBC.
Reddit Community Consensus
DeepSeek resets the pricing floor with a 1.6T MoE monster as builders trade agent swarms for deterministic flows.
Today marks a collision between massive scale and architectural sobriety. On one hand, DeepSeek-V4 is resetting the pricing floor for frontier-class intelligence, offering a 1.6T MoE model at costs that make GPT-4o look like a luxury good. For agent builders, the massive 384K output limit opens a door to single-shot application generation that bypasses traditional chunking. Yet, as raw power grows, the community is hitting a 'Loop of Death' with complex multi-agent hierarchies. The trend is shifting decisively toward Flow Engineering—treating LLMs as specific components within deterministic systems rather than letting them run wild in hallucination-prone swarms. Between the institutionalization of the Model Context Protocol (MCP) by the Linux Foundation and new 'Agent Vaults' for security, we are seeing the Agentic Web mature from a collection of experimental prompts into a structured, governed, and increasingly local-first ecosystem.
DeepSeek-V4 Drops as 1.6T MoE Monster r/ArtificialInteligence
DeepSeek has officially released DeepSeek-V4, a massive 1.6T parameter Mixture-of-Experts (MoE) model that activates only 49B parameters per token. The release includes a 'Flash' version priced at an aggressive $0.028 per million input tokens—roughly 18x cheaper than GPT-4o. Developers on r/ArtificialInteligence are highlighting its 10x KV-cache compression and manifold-constrained hyperconnections (mHC) architecture, which utilizes Engram O(1) knowledge retrieval to maintain performance in long-context agentic tasks.
Of particular interest to agent builders is the model's 384K max output capability. As noted by u/zsydeepsky, the model can generate entire single-file web applications in one go, significantly reducing the need for iterative chunking in coding agents. However, early reports from u/Right-Law1817 indicate that multimodality is currently missing from this V4 iteration, even though it reportedly matches GPT-4's reasoning performance at a fraction of the cost.
The Great Multi-Agent Swarm Reality Check r/AI_Agents
The practitioner community is reporting that complex multi-agent hierarchies are failing in production due to high-latency overhead and 'Loops of Death' where agents burn tokens without progress. This has sparked a transition toward Flow Engineering and deterministic designs like the open-source Switchplane, which keeps core logic in standard code while using LLMs only for judgment calls, moving away from the 'hallucination fests' of 12-agent swarms reported by u/Upper_Bass_2590.
Agentic AI Foundation Anchors MCP and A2A as Production Standards r/AI_Agents
The Agentic AI Foundation (AAIF), hosted by the Linux Foundation, has officially become the permanent governance home for the Model Context Protocol (MCP), A2A, and OpenAI’s AGENTS.md standards. This move transitions these protocols from experimental patterns into infrastructure-grade standards backed by founding members like Anthropic and OpenAI, with the A2A protocol already surpassing 150 supporting organizations according to u/BalluMolly.
Claude Code and Codex Cross-Review Loops r/ClaudeAI
Advanced developers are moving beyond single-agent coding by implementing cross-model review loops, such as using Claude Opus 4.7 to generate PRs while the Codex CLI performs code review in a parallel session. While this catches edge cases, team synchronization remains a bottleneck, leading developers like u/Disastrous_Bag8512 to rely on the CLAUDE.md file as a makeshift standard for persistent project state.
Persistent Artifacts Replace Ephemeral Agent RAG r/ArtificialInteligence
The industry is shifting toward structured knowledge bases like the Heptabase CLI and OpenContext to prevent the 'knowledge reset' inherent in current RAG architectures.
Qwen3.6 MoE Hits 2.94x Compression r/LLMDevs
u/ENIAC-85 demonstrated a compressed Qwen3.6-35B-A3B MoE that maintains 80.7% MMLU while slashing disk requirements, though practitioners are still battling 'reasoning leaks' on vLLM.
Agent Vault and the Rise of Autonomous Defense r/LocalLLM
Infisical has open-sourced Agent Vault, a credential proxy designed to prevent API key theft by isolating secrets from the agent's execution environment u/TroyHay6677.
Debugging Silent Failures and the Browser Persistency Gap r/mcp
Developers are pivoting from local extensions to persistent cloud browsers like Browserbase to solve the 'context rot' and silent JSON-RPC failures common in MCP tool development.
Discord Research Dispatch
DeepSeek-R1 matches o1's reasoning benchmarks while OpenAI's Operator begins the battle for the browser.
The agentic web is no longer a theoretical horizon; it is being built in the open and at the edge. This week’s developments signal a massive shift in how we think about model intelligence and deployment. DeepSeek-R1 has shattered the belief that high-tier reasoning is a proprietary secret, matching OpenAI’s o1 on key benchmarks through reinforcement learning alone. This democratization of 'System 2' thinking allows developers to treat reasoning as a native agentic workflow rather than an expensive prompting hack.
Simultaneously, the 'action' layer is maturing. OpenAI’s Operator has moved from rumor to research preview, signaling a direct challenge to Anthropic’s computer-use capabilities. We are seeing a bifurcation in the market: while high-level orchestration frameworks like LangGraph and standards like MCP provide the necessary plumbing for enterprise data, new browser-native tools like browser-use are solving the fragility of web automation. However, as the GAIA benchmarks suggest, we are hitting a 'planning wall' for complex, multi-step tasks. The next phase of development won't just be about bigger models, but about inference-time search and better world models to push past the current ceiling of autonomous reliability.
DeepSeek-R1 Sets New Bar for Agentic Reasoning
DeepSeek-R1 has emerged as a formidable open-weight competitor, excelling in long-chain reasoning tasks essential for autonomous agents. Its performance on the AIME benchmark reached 79.8%, matching proprietary models like OpenAI’s o1-0912 DeepSeek Team. This performance demonstrates that models can develop sophisticated reasoning abilities through reinforcement learning alone, as evidenced by the R1-Zero precursor which achieved a 71.0% pass rate on AIME 2024 without initial fine-tuning Elvis Saravia.
Developers are leveraging R1's 'thought' blocks to reduce hallucinations in complex workflows, effectively treating reasoning as a 'baked-in' agentic workflow rather than a separate prompting step The Batch. The model's multi-stage training—combining chain-of-thought fine-tuning with reasoning-focused RL—minimizes the need for supervised fine-tuning in complex logic paths, making it a prime candidate for local agent orchestration DeepSeek News. While R1 provides immense reasoning power, practitioners note it is best utilized for 'System 2' thinking within multi-model agentic RAG systems due to the latency associated with deep reasoning DataCamp.
OpenAI Operator: From Rumor to Research Preview
OpenAI has officially launched Operator as a research preview, signaling a pivot from conversational chatbots to functional 'do-bots' capable of navigating the web autonomously. Powered by a specialized Computer-Using Agent (CUA) model, the tool targets high-stakes browser tasks like travel booking and complex research synthesis with a reported 87% success rate @helicone. The shift toward vision-based interaction allows the agent to interact with dynamic UI elements directly, mitigating the risk of agents breaking when a website's CSS changes GitHub Gist.
Anthropic’s MCP Solidifies Dominance as the Enterprise 'Agentic USB'
The Model Context Protocol (MCP) has transitioned from an experimental release to the defining standard for enterprise agent connectivity following its 97 million download milestone. This architecture allows agents to query Postgres, Slack, and GitHub with zero custom glue code by decoupling the model from specific tool implementations Anthropic. Industry focus has now shifted toward making MCP safe, governable, and observable at scale, which experts like David Soria Parra highlight as a critical prerequisite for mass enterprise adoption and agentic interoperability Medium.
LangGraph Checkpoint v4.0.2 Hardens Long-Running Agentic State
LangGraph has solidified its orchestration position with Checkpoint v4.0.2, introducing deploy source tracking and functional APIs to reduce 'state bloat' in persistent multi-agent systems [LangChain].
Browser-use vs. Stagehand: The Rise of Autonomous Web Orchestration
The browser-use library has surged to 10,000 GitHub stars by enabling agents to process accessibility trees and visual tokens, achieving a 15% higher success rate than traditional scraping gregpr07.
GAIA Benchmark: Claude Mythos Breaks 50%
The new Claude Mythos Preview has officially crossed the halfway mark on the GAIA benchmark with a score of 52.3%, even as Level 3 tasks continue to hit a 'planning wall' at 35% success BenchLM.ai.
HuggingFace Framework Feed
Hugging Face's 24-hour sprint and the rise of code-as-action are dismantling the proprietary lead in autonomous systems.
Today's edition highlights a fundamental pivot in how we build agents: the death of the brittle JSON schema in favor of executable Python. Hugging Face's smolagents isn't just another framework; it's a minimalist manifesto for 'code-as-action' that is already yielding 30% efficiency gains. For developers, this means moving away from the prompt engineering dark ages toward deterministic, auditable logic. We're also seeing the 'moat' around proprietary deep research evaporate. In just 24 hours, an open-source replication achieved over 70% of OpenAI's performance, proving that the gap between closed and open systems is closing faster than anyone predicted. However, the path to production isn't all green lights. New benchmarks like IT-Bench reveal a sobering 20% success ceiling in enterprise environments, primarily driven by poor state verification and reasoning loops. As we look at NVIDIA's new physical AI models and high-throughput GUI agents like Holotron, the message is clear: the hardware and frameworks are ready, but the reasoning gap remains the final frontier for practitioners. We have the speed and the tools; now we need the reliability.
Open Source Deep Research and the Code-as-Action Shift
Hugging Face's smolagents framework is steering the industry away from brittle JSON tool-calling toward a 'code-as-actions' paradigm, where agents generate and execute Python snippets directly. This shift has yielded significant performance gains, with benchmarks showing a 30% reduction in logic steps and LLM calls compared to traditional JSON-based workflows. The framework's minimalist design—reflected in a core library of only ~1,000 lines—enables the creation of MCP-powered agents in as few as 50 lines of code.
In a parallel move to dismantle proprietary silos, Hugging Face launched Open-source DeepResearch. In a 24-hour hackathon, the team replicated the core agentic framework of OpenAI's Deep Research, achieving 72-82% of its performance on the GAIA benchmark. This initiative, led by Thomas Wolf, empowers developers to build multi-step research loops that remain fully auditable, unlike closed-source alternatives that maintain a 'black box' approach to reasoning.
High-Speed GUI Automation with Holotron-12B
The race for reliable Computer Use is accelerating with the release of H Company Holotron-12B, a high-throughput agent designed for desktop automation. Engineered from the NVIDIA Nemotron-Nano-2 VL architecture, Holotron-12B achieves a staggering 8.9k tokens/s on a single H100, helping the Surfer-H agent improve its WebVoyager success rates from 35% to 80% while handling enterprise applications that contain 90% more visual complexity than standard web benchmarks.
The 20% Success Ceiling: A Reality Check for Enterprise Agents
New diagnostics from IBM Research and UC Berkeley reveal that even frontier models hit a persistent 20% success ceiling in complex IT environments. Through the IT-Bench and MAST frameworks, researchers identified that models like Gemini-1.5-Flash often suffer from 'Isolated Failures,' averaging 2.6 failure modes per trace, with 'Incorrect Verification'—the inability to accurately assess environment state after a tool execution—acting as the single largest predictor of task failure.
Quick Hits: Models, Physics, and Specialized Logic
Nous Research released Hermes 3, a full-parameter fine-tune of Llama 3.1 405B designed for agentic autonomy and superior tool-calling accuracy. NVIDIA Cosmos-Reason2-8B brings physical reasoning to robotics, enabling agents to process spatial and temporal data through structured planning. Intel/DeepMath uses the smolagents framework to rival GPT-4o on mathematical benchmarks by treating logic as deterministic Python scripts. The Skill Bank Agents paper proposes modular skill libraries to help agents navigate interactive environments by retrieving sub-routines rather than re-planning from scratch.