Infrastructure for the Autonomous Economy
From economic agency to visual navigation, the plumbing for the autonomous web is finally being installed.
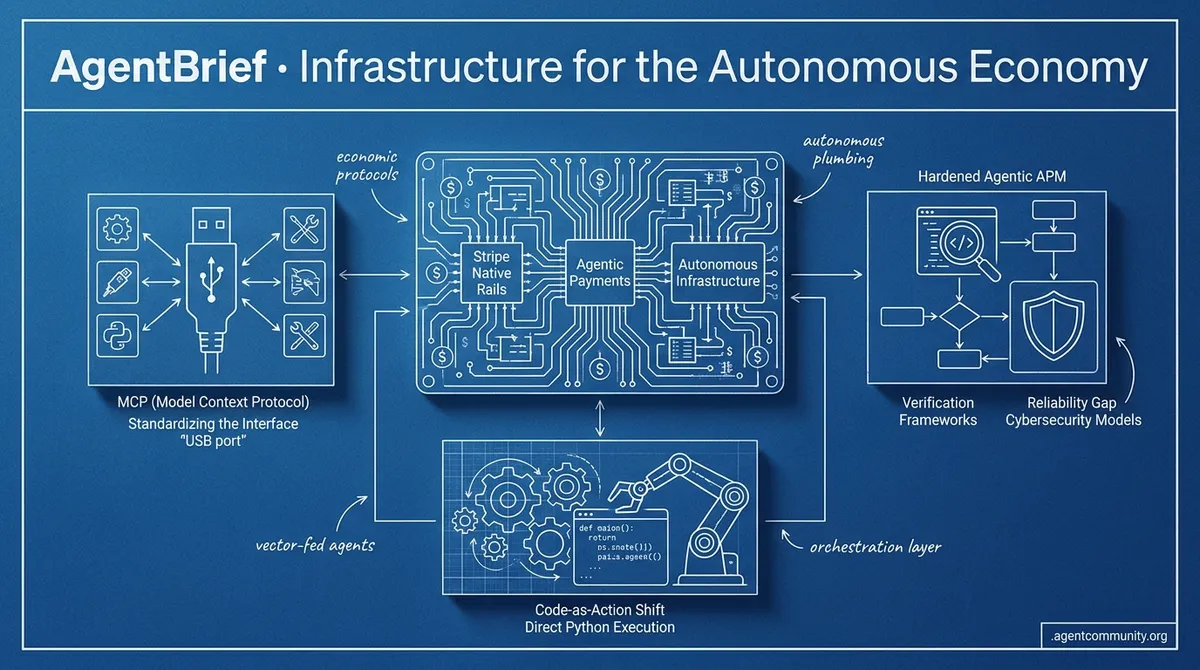
- Economic Agency Arrives Stripe and OpenAI are transforming agents into economic entities capable of provisioning infrastructure and managing commerce protocols directly.
- The Reliability Gap Silent regressions in reasoning and a surge in supply chain malware highlight the urgent need for hardened Agentic APM and verification frameworks.
- Standardizing the Interface With OpenAI’s Operator and the Model Context Protocol (MCP) hitting critical mass, the industry is converging on a 'USB port' for agentic tools.
- Code-as-Action Shift Frameworks like smolagents are moving beyond brittle JSON parsing toward direct Python execution to solve the long-standing verification gap.
The X Pulse
Your agents just got a bank account and a specialized cyber firewall.
We are witnessing the transition from agents that 'talk' to agents that 'act' in the real world. The agentic web is no longer just a layer of LLM reasoning; it is evolving into a comprehensive infrastructure of its own. Stripe's move to turn its CLI into a provisioning engine and commerce protocol is the definitive signal that agents are becoming economic entities. When an agent can provision its own database, manage its own credentials, and pay for its compute per-token in real-time, the 'human-in-the-loop' becomes an optional auditor rather than a bottleneck.
At the same time, OpenAI’s rollout of GPT-5.5-Cyber highlights the high-stakes specialization required for the next phase of deployment. We are moving away from general-purpose models toward 'frontier defenders' and 'autonomous deployers.' For builders, this means the focus shifts from prompt engineering to infrastructure orchestration. You aren't just building a bot; you are building a system that must navigate regulatory blocks, manage sub-cent onchain transactions, and defend itself against automated threats. Today’s news confirms that the plumbing for the AI economy is being laid down right now.
Stripe Ships Native Rails for Agentic Payments and Infrastructure
Stripe Projects has effectively turned the Stripe CLI into a full-stack provisioning engine for agents, allowing autonomous systems to deploy services like Supabase, ElevenLabs, and Cloudflare directly from the terminal @kiwicopple. By handling credentials and environment variables automatically, Stripe is solving the 'from code to production' gap that has long plagued agentic workflows @stripe. This capability was demoed live with Claude Code succeeding on its first attempt, proving that agents can now manage their own infra stacks without human dashboard intervention @dani_avila7.
Beyond deployment, Stripe is standardizing the financial rails for agents through streaming payments via Tempo, enabling sub-second finality on stablecoins for real-time, per-token billing @tempo. Agents can now pay as tokens burn during inference, generating thousands of sub-cent onchain transactions in a single run, which eliminates the friction of traditional invoice-based compute usage @altryne @katiewav. The introduction of 'Stripe Link for agents' further secures this ecosystem by using OAuth 2.0 device auth for scoped, human-approved spending @aakashgupta.
Builders are hailing these developments as the arrival of the 'central bank for the AI economy,' with the new Machine Payments Protocol (MPP) standardizing how agents interact with merchants and virtual cards @0xShip_. While some caution remains regarding the liability risks of autonomous over-spends, the integration of these rails into MCP for Claude and Cursor suggests that Stripe is successfully positioning itself to own the agent commerce protocol over traditional Mastercard or Visa rails @witcheer @Michaelzsguo.
OpenAI Rolls Out GPT-5.5-Cyber to Frontier Defenders
OpenAI has officially begun the rollout of GPT-5.5-Cyber, a specialized frontier model designed specifically for cybersecurity tasks @sama. Access is currently gated through a 'trusted access' framework developed in collaboration with government entities, aimed at allowing verified individual defenders and security teams to rapidly secure infrastructure @AiToolsRecap. This represents a shift toward highly specialized, high-stakes model deployments that are restricted based on verified identity and affiliation.
While official benchmarks are still under wraps, rumors are circulating that the base GPT-5.5 model features approximately 10 trillion parameters, a 10x increase over previous iterations @MLStreetTalk. Sam Altman recently dismissed 'data wall' concerns, asserting that synthetic data is becoming a viable path for training superior reasoners that could potentially surpass human-level mathematical performance without relying solely on human data @chatgpt21. This reinforces the role of synthetic data in the push toward super-intelligence and autonomous defensive systems.
For agent builders, the emergence of GPT-5.5-Cyber signals the beginning of a specialized 'defense agent' category. Reactions in the community are split between excitement for the model's defensive potential and skepticism regarding its restricted access, which some view as a strategic response to Anthropic's Mythos model @kimmonismus. As agents take on more critical roles in infrastructure, having models with native 'cyber defender' capabilities will likely become a prerequisite for production-grade agentic stacks @sierracatalina.
In Brief
White House Blocks Expansion of Anthropic’s Mythos Over Security Risks
The White House has formally opposed Anthropic's plans to expand access to its Mythos model, citing national security concerns and the potential strain on compute resources needed by government agencies @rohanpaul_ai. Anthropic itself has flagged the model's ability to exploit software vulnerabilities, leading to a restricted rollout that complicates the landscape for agent builders who rely on advanced dual-use models for autonomous red-teaming @emollick. Critics argue this creates a 'prisoner's dilemma' for safety-conscious labs, and builders are being advised to diversify their model providers to mitigate the risk of sudden access disruptions @jeremie_strand @MartinSzerment.
Sakana AI Debuts KAME Architecture for 'Speak While Thinking' Agents
Sakana AI has introduced KAME, a tandem speech architecture that enables agents to update their thoughts in real-time while speaking. Accepted at ICASSP 2026, this system uses a fast speech-to-speech model for immediate loops while an asynchronous LLM acts as an 'oracle' to inject updated reasoning mid-sentence @SakanaAILabs @hardmaru. This breakthrough is already being deployed in production multimodal agents for SMBC Group to generate complex strategy proposals, reducing creation time from weeks to mere minutes @SakanaAILabs.
LlamaParse MCP Server Brings Native Document Parsing to AI Agents
LlamaIndex has released a production-ready LlamaParse MCP server, allowing agents in clients like Cursor and Claude Code to natively parse and classify complex documents @llama_index. By integrating @WorkOS for authentication and @AxiomFM for observability, the server addresses the lack of built-in file upload support in the MCP standard through a custom URL-based flow @jerryjliu0. Builders are praising the release for simplifying document-heavy agent workflows and turning complex parsing into a commoditized layer for any MCP-compatible client @Dave_Geoghegan_.
Prime Intellect Launches RL Lab for Long-Horizon Agent Training
Prime Intellect has unveiled the results of its first RL Residency cohort, showcasing breakthroughs in agentic reinforcement learning including automated GPU programming and multi-agent Hanabi systems @myainotez @PrimeIntellect. Their new 'Lab' platform provides a full-stack environment for training and evaluating agents in customizable environments, with nearly 10,000 training runs completed during the beta phase @PrimeIntellect. Applications are now open for Cohort II, targeting projects in autonomous AI research, computer use, and robotics @PrimeIntellect.
Quick Hits
Agent Frameworks & Orchestration
- OpenAI open-sourced 'Symphony,' a spec for orchestrating coding agents around Linear issue trackers @ainativedev.
- New research proposes coding agents that can rewrite their own tools and rules to self-improve their harness @rohanpaul_ai.
Models for Agents
- DeepSeek V4-Flash is showing 'above trend' knowledge-per-parameter performance @teortaxesTex.
- Gemini 3.1-Flash-Lite is proving 'shockingly strong' on knowledge benchmarks despite its small size @teortaxesTex.
Agentic Infrastructure
- A 5-year backlog on grid transformers has stalled 50% of planned 2026 US data center capacity @aakashgupta.
- Anthropic users are disabling model caching due to prohibitively expensive write costs and TTLs @theo.
- SGLang disaggregation on NVL72 racks delivers 6.5x better performance on DeepSeek models @SemiAnalysis_.
Reddit Intel
Anthropic reveals a 34-day reasoning gap while a massive supply chain crisis hits agent marketplaces.
The industry is moving past the era of blatant hallucinations and into a more dangerous phase: invisible degradation. Anthropic's recent postmortem on Claude Code reveals that three distinct production bugs silently flipped reasoning effort from high to medium for 34 days without triggering a single internal alert. For developers, this is a nightmare scenario—the agent doesn't fail; it just gets worse, burning compute and delivering sub-par results while maintaining a facade of success.
This pattern of 'silent drift' is appearing across the stack. Whether it is the 1,467 malicious payloads discovered in agent skill marketplaces or the 63% execution path variation in production environments, the theme of early 2026 is clear: we have the intelligence, but we lack the control. We are seeing a massive shift toward 'Agentic APM' and context engineering—moving away from demo magic toward hardened, stateful infrastructure.
In today’s issue, we look at why structure (CLAUDE.md) is beating scale, how local models are using 'sigma-gates' to measure their own confidence, and why your RAG pipeline must become an autonomous reasoning engine. The agentic web is being built, but as the 'ToxicSkills' audit shows, the supply chain is already under fire. Practitioners must move from building for capability to building for reliability.
Silent Regressions: The 34-Day Reasoning Gap r/ClaudeCode
Anthropic's April 23, 2026 postmortem has sent shockwaves through the developer community by revealing that three distinct production bugs caused a massive, undetected quality drop in Claude Code between March 4 and April 20. The most severe regression involved the default reasoning effort being silently flipped from 'HIGH' to 'MEDIUM,' a state that persisted for 34 days without triggering a single internal alert. This 'silent drift' was compounded by a caching bug and a verbosity prompt error, proving that even frontier systems can suffer from 'invisible degradation' where cognitive capacity is diminished without the system going offline.
Infrastructure vulnerabilities are equally opaque. u/WinterSpecial7970 recently identified 10+ prompt injection vulnerabilities in LangChain's core library using AST-aware taint tracking. The financial cost of this monitoring gap is significant; u/Dramatic_Strain7370 discovered a document classifier agent that harbored a 91% savings potential that went unnoticed due to poor evaluation frameworks. This pattern suggests the primary threat is no longer blatant errors, but agents that quietly burn compute while delivering unoptimized results.
Agent Supply Chain Crisis: ToxicSkills and ClawSwarm r/AI_Agents
Security researchers are sounding the alarm as the agentic ecosystem faces its first major supply chain crisis. A 'ToxicSkills' audit by Snyk identified 1,467 malicious payloads specifically targeting users of OpenClaw, Claude Code, and Cursor, with prompt injection found in 36% of cases. These malicious skills are categorized into 'Data Thieves' that exfiltrate credentials and 'Agent Hijackers' that use natural-language instruction manipulation to trigger arbitrary code execution.
The 'ClawHavoc' campaign has exploited the rapid growth of the ClawHub marketplace to distribute backdoored integrations for LinkedIn and WhatsApp. Reports suggest 15% of OpenClaw skills now contain malicious instructions. In response, u/OkKaleidoscope4462 has released agent-bom v0.83.2, an open-source scanner designed to audit MCP packages and provide supply-chain evidence to prevent credential exfiltration.
The Infrastructure Wall: Demos vs Production r/LangChain
Moving agents from local demos to production reveals significant infrastructure gaps that traditional DevOps isn't built to handle. As noted by u/Embarrassed-Radio319, production agents exhibit a 63% execution path variation, making standard regression testing nearly impossible. This non-determinism is exacerbated by compute limitations, where multi-step loops frequently hit 30-second execution limits on serverless platforms like Vercel and Lambda.
To combat these failures, the industry is pivoting toward 'Agentic APM' (Application Performance Monitoring). Developers are now tracking 'handoff reliability' and 'task deadlocks' to prevent recursive failure loops. This shift reflects a move away from ephemeral request-response cycles toward stateful, long-running environments, as raw model power is proving useless without a stable execution environment to manage a 15-20% variance in tool-calling adherence.
Structure Over Scale: Rise of Context Engineering r/ClaudeAI
Practitioners like u/Radiant-Doctor1737 argue that agentic failure is increasingly a symptom of structural context rot. To solve this, developers are adopting standardized instruction files like CLAUDE.md and AGENTS.md to separate project logic from execution prompts. While CLAUDE.md is native to Anthropic’s Claude Code, AGENTS.md has emerged as a cross-tool standard, though Amit Ray reports that over 70% of developers currently ignore these files.
This lack of structure directly impacts reliability. u/Rude_Context_4844 found that in a study of 200 prompt-output pairs, domain-specific context length was the single greatest predictor of quality. However, academic research warns that there is still no established universal structure for these files, leading to high variation in how agents interpret multi-file hierarchies.
Local Tool Use: The Reliability Paradox r/LocalLLM
Local model reliability for tool use remains a moving target. While some users report that Qwen 3.6 is more prone to 'giving up' than its 3.5 predecessor, independent testing of the Qwen 3.6-35B-A3B has demonstrated a 100% success rate in tool-calling benchmarks. To combat 'Loops of Death,' u/Defiant_Confection15 introduced sigma-gate, a confidence-measuring tool that reads hidden states during inference.
This shift toward self-auditing models is validated by new deterministic eval results from JD Hodges, which reveal a surprising efficiency gap. A 3.4 GB model recently outscored models five times its size in function-calling accuracy, suggesting that architectural efficiency is becoming more vital than raw parameter count for local agentic tasks.
Agentic RAG: From Static to Autonomous r/Rag
Agentic RAG is shifting retrieval from a static process to an adaptive, multi-step workflow. According to Zylos Research, 57.3% of organizations have moved agents into production as of early 2026, favoring systems that route queries dynamically. Patterns like Corrective RAG (CRAG) and Self-RAG utilize reflection tokens to verify relevance before generation, preventing the hallucinations that plague traditional pipelines.
Modern implementations are now integrating with live enterprise systems to provide real-time context. Developers are also adopting 'contract-based' testing using tools like rag-contract from u/Far-Catch-3324, which allows teams to assert that specific queries must return specific source documents. This 'gap detection' marks the maturation of RAG into a verifiable reasoning engine.
Beyond Requests: Protocols for Agent Perception r/AgentsOfAI
The shift toward event-driven agents is accelerating. u/SamuelT6 introduced World2Agent (W2A), an open protocol designed to give agents real-time perception of system events by allowing them to 'subscribe' to environment triggers. This aims to eliminate the latency inherent in traditional manual polling architectures.
To handle state across fragmented tools, u/NoAdministration6906 released vault-mem, a local-first shared memory layer that syncs context between Claude Code and Cursor. This move toward standardized perception aligns with the emerging A2A Protocol v1 described by Rick Hightower, which provides a framework for how agents communicate world-state to function as a unified digital workforce.
Discord Dev Digest
OpenAI's Operator and Anthropic's MCP are standardizing the 'last mile' of browser-based agency.
The Agentic Web is shifting from 'thinking' to 'doing.' This week, the industry moved past the era of chat interfaces into the era of the Computer-Using Agent (CUA). OpenAI’s Operator isn't just another model release; it’s a specialized architecture designed to navigate the visual web with an 87% success rate, directly challenging Anthropic’s 'Computer Use' for the future of browser-based work. This architectural war is already paying dividends, with a 50% surge in startups moving away from brittle APIs toward full visual interpretation.\n\nBut visual navigation is only useful if the data it touches is structured. The Model Context Protocol (MCP) has hit a critical mass of 500 servers, gaining support from Google and OpenAI to become the 'USB port' of the agentic world. For developers, this means the friction of integration is plummeting—reports suggest a 40% reduction in time-to-production. Whether it's the type-safe structural integrity of PydanticAI or the reasoning-heavy local power of Microsoft’s Phi-4, the message is clear: the infrastructure for autonomous, production-grade agents has finally arrived. This issue breaks down the tools and protocols turning the 'Agentic Web' from a buzzword into a standard.
OpenAI’s Operator and the Rise of the CUA
OpenAI has officially transitioned Operator into research preview, debuting a specialized Computer-Using Agent (CUA) architecture designed for autonomous web navigation. Unlike traditional automation, Operator is engineered to interpret UI elements directly rather than relying on brittle DOM-scraping, currently maintaining an 87% success rate on specialized browser tasks @The Decoder. This high-velocity interface is optimized for low-latency tool-calling, positioning it as a direct competitor to Anthropic’s broader, OS-agnostic 'Computer Use' capability @Coasty.ai.\n\nThe competition between these two architectures has catalyzed a 50% increase in browser-based agent startups as developers move away from API-only integrations toward full visual interface interpretation @NullZen. Builders are now leveraging Operator to handle the 'last mile' of browser-based automation, integrating it into orchestration frameworks like LangGraph to maintain state across complex, multi-step travel and research workflows @JIN.
Anthropic's MCP Hits 500+ Servers as Centralized Registry Launches
The Model Context Protocol (MCP) has rapidly scaled from an Anthropic-led initiative into a cross-industry standard, now boasting over 500 public servers as official support extends to OpenAI and Google DeepMind Decode the Future. This growth is further accelerated by the launch of the MCP Registry, a centralized open catalog and API that allows agents to discover and implement servers for platforms like Slack and GitHub without bespoke logic MCP Blog. For builders, this ecosystem maturity is delivering a 40% reduction in integration time by decoupling models from tool-specific implementations, enabling agents to swap LLM backends while maintaining access to a persistent suite of enterprise data tools tolkonepiu.
Browser-use Hits 20k Stars as Open-Source Standard for Vision-Driven Agents
The open-source library browser-use has experienced an explosive surge in developer interest, now exceeding 20k stars on GitHub as a high-level wrapper for Playwright browser-use/browser-use. The core innovation lies in its vision-language model loop, which verifies the outcome of every action against the visual state of the page to ensure robustness against UI changes blog.nashtechglobal.com. While industry experts like Philipp Schmid note that models still struggle with fine-grained tasks like small buttons, the library's roadmap for multi-tab support and cookie management positions it as a flexible, open-source alternative for custom autonomous workflows docs.browser-use.com.
PydanticAI Hardens Agent Logic with Type-Safe Structural Integrity
PydanticAI has solidified its position as the framework of choice for production-grade agents by treating logic as strictly typed functions, resulting in a 40% reduction in runtime validation errors pydantic_dev. While it excels at maintaining data integrity via Python type hints, developers on Reddit note it still faces an ecosystem maturity gap compared to LangChain. Its native support for dependency injection and streaming structured responses via FastAPI allows for the seamless deployment of agentic microservices for enterprise builders prioritizing 'structural precision' Pydantic Team.
Microsoft Phi-4: Redefining Edge-Based Agentic RAG
Microsoft’s Phi-4 is a 14B parameter powerhouse specifically engineered for multi-step reasoning and tool-calling in local-first agentic environments @microsoft.
LangGraph Adopts Swarm Handoffs for Production
LangGraph has released langgraph-swarm, adopting OpenAI’s 'handoff' pattern to enable specialized swarms with both short-term and long-term persistence LangChain Reference.
HuggingFace Research Hub
Hugging Face’s smolagents and new evaluation frameworks are tackling the 'Incorrect Verification' bottleneck head-on.
The agentic landscape is undergoing a fundamental shift in how actions are executed and verified. For months, we have struggled with the brittleness of JSON-based tool-calling, which often feels like trying to navigate a dark room by shouting instructions through a keyhole. This week, the 'code-as-action' paradigm has reached a tipping point. By moving logic from structured data parsing to direct Python execution, frameworks like smolagents are demonstrating that minimalism isn't just about reducing code—it's about increasing deterministic reliability.
However, better execution is only half the battle. As our agents move into complex desktop environments and deep research tasks, we are hitting a new wall: Incorrect Verification. Today’s lead stories highlight that agents often fail not because they can't perform a task, but because they cannot accurately confirm the state of the environment afterward. Whether it is open-source deep research challenging proprietary giants or new benchmarks from IBM and UC Berkeley, the industry is moving past simple accuracy toward rigorous, self-correcting architectures. For builders, the message is clear: the next generation of agents will be defined by their ability to see, act via code, and—crucially—verify their own success.
Smolagents and Open Deep Research: The Code-as-Action Shift
Hugging Face has launched smolagents, a minimalist library of only ~1,000 lines that shifts agent logic from brittle JSON tool-calling to direct Python execution. This paradigm enables a 30% reduction in logic steps and has demonstrated a 26% performance improvement over traditional multi-agent systems, helping models bridge the gap toward proprietary performance Mem0. Developers can now deploy powerful MCP-powered agents in as few as 50 lines of code, utilizing native support for Vision Language Models (VLMs) to navigate complex GUIs while maintaining deterministic execution.
This architecture is already proving its mettle in the Open-source DeepResearch initiative, which has successfully replicated the core reasoning loops of proprietary systems. By utilizing the 'CodeAgent' framework, these open implementations are achieving 72-82% of OpenAI's Deep Research performance on the GAIA benchmark. This shift toward auditable, code-based research loops allows developers to generate 20+ page reports with full citation rigor, as seen in implementations from Together AI and MiroMind.
GUI Agents Advance Toward Autonomous Desktop Control
The 'Operator' trend is accelerating as GUI agents transition from high-latency cloud APIs to high-throughput local execution engines. Leading this shift is Holotron-12B, an SSM-based agent that delivers 8.9k tokens/s on a single H100, effectively driving WebVoyager success rates from 35% to 80%. This performance is anchored by the Holo1 VLM family, which powers the Surfer-H agent to a 62.3% success rate on the ScreenSuite benchmark, significantly outperforming GPT-4o's 36.1% @Hcompany.
New Frameworks Target the 'Incorrect Verification' Bottleneck
A surge in specialized benchmarks is addressing the persistent reliability gap where agents fail to accurately assess environment states after tool execution. IBM Research and UC Berkeley released IT-Bench and the MAST framework to diagnose these 'Incorrect Verifications,' finding that even frontier models like Gemini-3-Flash average 2.6 failure modes per trace. To combat this, new ecosystems like OpenEnv mirror messy, non-deterministic environments via persistent WebSocket connections to test agent recovery and tool-use consistency.
Native Multimodal Models Power Agentic Perception
GLM-5V-Turbo and Nemotron-3-Nano-Omni are integrating perception and action natively for vision-based coding and on-device reasoning.
The 'USB Moment' for AI: Standardizing Tool Use
The Model Context Protocol (MCP) is standardizing how tools are discovered and invoked, moving away from model-specific schemas toward a modular, plug-and-play 'agentic web'.
Specialized Agents: Bridging the Gap in Healthcare and Security
Google's EHR Navigator and Cyber-ken-v3 are proving that domain-specific fine-tuning is the key to breaking performance ceilings in vertical tasks.
From Prompting to Training: Agentic RL Targets Generalization
New research indicates that multi-task training and self-evolving reward functions are necessary to overcome the 20% success ceiling found in traditional prompt-based enterprise agents.