From Chatbots to Autonomous Operators
Agents are moving beyond text boxes into code-native execution, visual browser control, and sovereign financial rails.
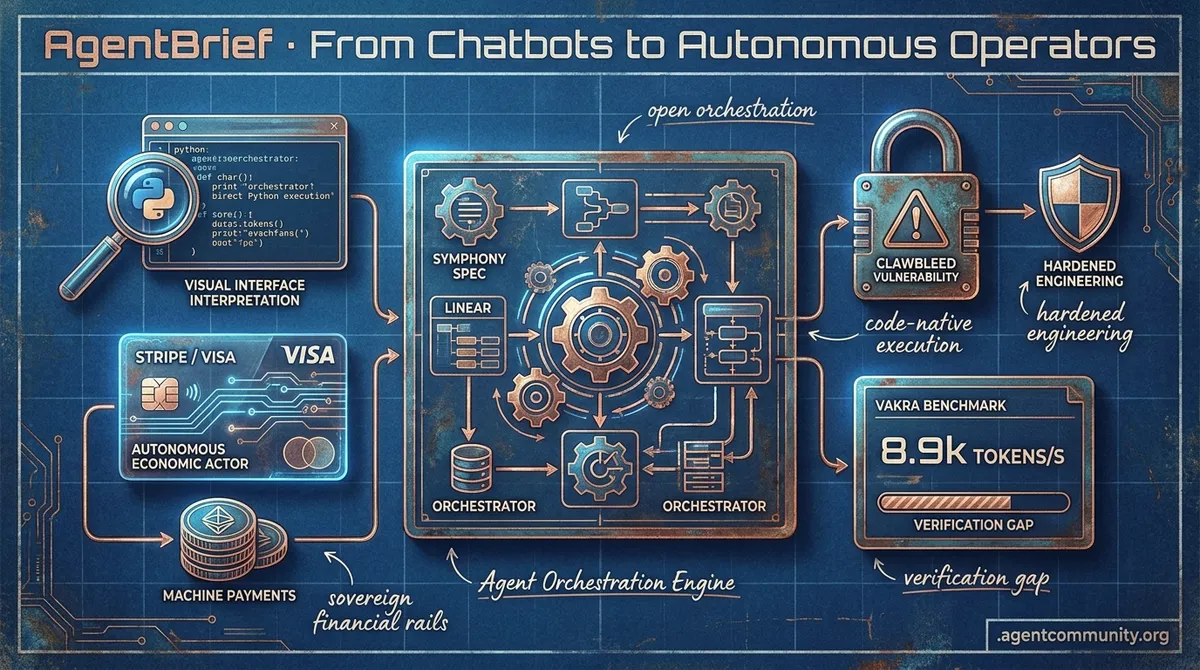
- Visual and Code Sovereignty OpenAI's Operator and Hugging Face's smolagents are replacing brittle JSON parsing with visual interface interpretation and direct Python execution for improved performance.
- Autonomous Financial Rails With Stripe, Visa, and OpenAI's Symphony spec, agents are gaining dedicated 'rails' and bank accounts, transforming them into autonomous economic actors.
- Production Security Gap The 'ClawBleed' vulnerability in MCP tools serves as a wake-up call, shifting the industry focus from natural language vibes toward hardened, deterministic engineering.
- The Verification Frontier As high-throughput models like Holotron-12B hit 8.9k tokens/s, benchmarks like VAKRA highlight the remaining challenge: ensuring agents can verify if their actions actually worked.
X Infrastructure Insights
Orchestration is moving from the CLI to the balance sheet.
The agentic web is no longer a collection of clever prompts; it is becoming a robust infrastructure layer. This week, we saw the two pillars of autonomous systems—tasking and transacting—standardized in ways that change the game for builders. OpenAI's release of the Symphony spec effectively turns Linear into an agentic operating system, while the parallel moves from Stripe and Visa to launch dedicated 'agent rails' mean our systems finally have their own bank accounts. We are moving from agents that 'suggest' to agents that 'execute' and 'pay.' For builders, this means the bottleneck is shifting from model capability to orchestration safety and financial governance. If an agent can spin up its own branch, run CI tests, and stream sub-cent payments for its own inference, the role of the human developer shifts from 'coder' to 'system architect.' We aren't just building tools anymore; we are building autonomous economic actors. The protocols being established today—MPP, TAP, and Symphony—are the TCP/IP of the agentic economy. It's time to stop thinking about chat interfaces and start thinking about autonomous throughput.
OpenAI Open-Sources Symphony: Turning Linear Into an Agent Orchestrator
OpenAI has officially open-sourced Symphony, an agent orchestrator spec for Codex designed to transform task trackers like Linear into autonomous work systems. The architecture assigns a dedicated Codex agent to every open issue, operating within an isolated workspace complete with its own branch and CI tests. These agents automatically generate pull requests for human review, effectively shifting the human role from active coding to high-level oversight. Internal teams using the system reportedly achieved a 500% increase in landed PRs after just 3 weeks of implementation, signaling a massive leap in developer velocity @OpenAIDevs @xchunhx169889.
Community reactions have been a mix of awe and caution. While many see this as the definitive way to clear engineering backlogs, others like @Singularabbit and @daniel_mac8 have raised concerns regarding conflicting agent actions and the high token costs associated with persistent agentic loops. Despite these risks, the builder community is moving fast, already producing reference implementations in Elixir and integrating production-safety features like idempotency keys to ensure reliability in parallel execution environments @xchunhx169889.
For agent builders, Symphony represents a shift toward task queueing via issue trackers as a standardized orchestration pattern. By utilizing existing tools like Linear as the 'source of truth' for agent tasks, developers can build more resilient, asynchronous workflows that don't require constant supervision. As @ainativedev noted, this aligns with a broader industry trend toward robust orchestration layers that treat agents as first-class citizens in the software development lifecycle.
The Machine Payments War: Stripe and Visa Launch Dedicated Agent Rails
The financial plumbing for the agentic web has arrived. Stripe has launched Link for agents, a secure system enabling scoped spending where agents act as headless devices using the OAuth 2.0 device authorization grant. Through a partnership with Tempo, Stripe is also enabling streaming per-token payments, allowing agents to settle sub-cent onchain transactions with sub-second finality as they consume inference @stripe @tempo. This infrastructure is powered by the Machine Payments Protocol (MPP), effectively commoditizing autonomous commerce @0xShip_.
Not to be outdone, Visa has shipped its Trusted Agent Protocol (TAP), entering a four-way protocol race against MPP, ACP, and UCP. Visa’s model utilizes agent-specific tokens with unique cryptograms and issuer validation, meaning merchants can accept agent payments without changing their existing infrastructure @Alex__Radu. While this provides a familiar path for retail adoption, critics like @NathanielC85523 point out that governance frameworks for agent liability remain largely unresolved.
Builders are hailing these developments as the creation of a 'central bank for the AI economy,' a parallel web designed for autonomous transactions @krishnanrohit. With 47% of US shoppers already using AI for tasks and millions of agentic transactions forecast by the 2026 holidays, the ability to programmatically handle money is no longer optional for agent developers @aakashgupta. This is the infrastructure that turns agents from assistants into independent economic entities.
In Brief
Sakana AI Ships KAME Architecture for 'Speak While Thinking' Agents
Sakana AI has introduced KAME, an open-source tandem architecture that enables speech agents to respond with human-like latency by decoupling immediate interaction from deep reasoning. By using a fast speech-to-speech frontend like Moshi for immediate response loops and an asynchronous backend LLM (e.g., Claude or GPT-4.1) to inject refined 'oracle signals,' KAME allows agents to evolve their thoughts mid-sentence @SakanaAILabs. While @KaseraAksh85036 praises the breakthrough for wearables, others like @RidgeRunAI caution about the robustness of guidance signals in real-world network conditions.
Prime Intellect's RL Residency Delivers Frameworks for Continual Learning
Prime Intellect's first RL Residency cohort has released a suite of open-source frameworks designed to automate AI research and multi-agent training. The projects include environments for GPU programming, embodied agents in CARLA-Env, and multi-agent systems where models generate their own reward functions @PrimeIntellect. Developers like @pradheepraop are already applying these tools to build self-healing coding arenas, validating the Environments Hub as a critical resource for builders seeking production-grade reinforcement learning without heavy infrastructure overhead.
White House Blocks Anthropic's Mythos Expansion Over Security Risks
The White House has opposed Anthropic’s plan to expand access to its Mythos model, citing its ability to autonomously exploit software vulnerabilities at scale as a national security risk. While Anthropic argues Mythos is a defensive tool for rapid patching, officials worry its dual-use reasoning capabilities could compress the time from flaw discovery to weaponization @rohanpaul_ai. For agent builders, this tension underscores a new era of 'agent controls' where superior reasoning triggers government oversight, potentially complicating the deployment of autonomous systems in sensitive sectors @emollick.
Quick Hits
Agentic Infrastructure
- E2B achieves 60ms sandbox spin-up by keeping CPU, RAM, and snapshots local on the node @ivanburazin.
- Stripe Projects now allows developers and agents to spin up Supabase databases directly from the CLI @kiwicopple.
- Box is creating new 'Agent Engineering' roles to wire internal systems for autonomous business processes @levie.
Tool Use & MCP
- LlamaParse MCP server launched to help agents operate over complex documents with specialized parsing @jerryjliu0.
- Critics argue that over-engineering MCP implementations can lead to worse outcomes than letting the model manage tools natively @signulll.
Models for Agents
- GPT-5.5-Cyber is rolling out to critical infrastructure defenders to help secure systems autonomously @sama.
- DeepSeek v4 1.6T MoE achieves 6.5x performance gains on Nvidia B300 racks via specialized kernels @SemiAnalysis_.
Reddit Production Pulse
As the Model Context Protocol hits 437k downloads, a critical security breach reminds us that vibe-based agents aren't ready for the real world.
Today’s agentic landscape is defined by a growing tension between rapid tool expansion and the sobering reality of production security. The Model Context Protocol (MCP) was supposed to be the bridge to a unified tool ecosystem, but a massive audit of 25,000 tools has exposed a 'ClawBleed' RCE vulnerability that turns local servers into exfiltration endpoints. For developers, this is a wake-up call: the honeymoon phase of connecting LLMs to local files and SSH keys without sandboxing is officially over. Beyond security, we are seeing a shift in the local vs. cloud debate. Google’s Gemma 4 31B is putting up a fight against Qwen 3.6 in gamedev sprints, but the real story is at the edge. Agents are finally hitting Snapdragon NPUs, moving away from CPU-throttled demos toward battery-efficient, sustained inference. Whether it's through 'inside-the-loop' UX or moving guardrails from prompts to hard-coded schemas, the industry is professionalizing. We are moving from agents that might work to systems that must work—and that requires a fundamental shift from natural language vibes to deterministic engineering.
The MCP Supply Chain Crisis r/mcp
A massive research effort has cataloged the emerging Model Context Protocol (MCP) ecosystem, auditing 1,787 public servers and 25,329 individual tools. As u/PolicyLayer reports, these tools are often categorized by risk—Read, Write, Execute, and Destructive—yet many lack adequate sandboxing. This security gap has already been exploited; researchers identified over 7,000 exposed MCP servers vulnerable to 'ClawBleed,' a critical Remote Code Execution (RCE) flaw.
According to Authzed, this vulnerability allows malicious LLM hosts to exfiltrate API keys, SSH keys, and Git repository contents. With over 437,000 protocol downloads, the attack surface is expanding faster than governance. Developers like u/theotzen are finding that while individual units pass local tests, entire agentic workflows frequently break in production, often necessitating custom alternatives when standard MCPs fail.
Gemma 4 vs Qwen 3.6: The Battle for Local Agent Supremacy r/LocalLLaMA
The local agent landscape is witnessing a fierce rivalry between Google’s Gemma 4 31B and Alibaba’s Qwen 3.6 27B. While u/gladkos observed Gemma 4 'crushing' Qwen in a Pacman gamedev sprint—finishing a prototype in 3m 51s—aggregate data from BenchLM.ai shows Qwen 3.6 holding a 74 to 66 lead in general performance.
Efficiency is the name of the game for local builders. u/reto-wyss confirmed that NVFP4 quantization allows Gemma 4 to achieve an 88.95% to 90.00% on the AIME 2025 benchmark within the VRAM of a single RTX 5090. Meanwhile, Qwen 3.6's specialized 35B A3B variant is gaining traction in vLLM environments for its superior reasoning-to-size ratio.
Beyond Silos: The Rise of Agentic Session Tokens r/AgentsOfAI
Developers are moving beyond single-agent assistants to complex multi-agent environments. Tools like Harbor u/Weary-Step-8818 are centralizing configurations to eliminate the 'agent-coordination tax.' This grassroots effort is being met by enterprise standards: Anthropic’s MCP 2.0 introduces Agentic Session Tokens, designed to standardize memory and state sharing across providers techbytes.app.
This shift is critical as frameworks like CrewAI now report over 12 million daily agent executions in production. As a result, developers are increasingly moving away from high-level abstractions; one practitioner recently rewrote their entire multi-agent system from TypeScript to gain more deterministic control over execution paths and tool-calling reliability r/AI_Agents.
Stop Prompting Guardrails, Start Enforcing Code r/AI_Agents
A consensus is forming: system prompts are insufficient for safety. u/v1r3nx argues that builders should stop using the LLM as its own guardrail and instead use deterministic checks and schemas. Libraries like pydantic-ai-guardrails are providing functions to prevent instruction manipulation @jagreehal.
According to u/Cold_Bass3981, an 8-line structural enforcement template often outperforms 500-word guardrail prompts. For agents to be trusted, logic must move to the 'hard-coded' infrastructure layer, including implementing a 'Tool Permission Matrix' and Pydantic models for high-risk tools like execute_trade @FareedKhan-dev.
Local Agents Reach Snapdragon NPU Hardware r/LocalLLaMA
The 'agent at the edge' vision is transitioning to high-performance NPU execution. u/Ok_Warning2146 successfully cross-compiled llama.cpp for the Snapdragon Hexagon NPU on a OnePlus 12. This shift is critical, as mobile NPUs are necessary to maintain performance without thermal throttling [Arxiv 2603.23640].
Software optimization is keeping pace. u/edbuildingstuff demonstrated the feasibility of specialized edge agents by shipping a fine-tuned Llama 3.2 1B model to Android using Q4_K_M quantization. Multimodal workflows are also arriving; u/dai_app verified a full speech-to-text loop on Android using a Qwen3 1.7B model and the QVAC SDK.
Neurologically-Inspired Memory: Moving From RAG Hoarding to Living Context r/mcp
New approaches to agentic memory are attempting to solve the 'context rot' problem. u/RAHUL-2806 introduced MemoryOS, an episodic memory system that uses Ebbinghaus decay to outperform standard RAG by +6.7% in Mean Reciprocal Rank. This aligns with a broader shift identified by Zylos Research toward tiered memory.
Efficiency remains the bottleneck. The CTX library u/Public-Cancel6760 claims to save up to 80% of tokens by pruning noisy logs. While context windows have expanded to 1M+ tokens for Claude Sonnet 4.6, the challenge has evolved from raw capacity to signal-to-noise optimization.
The Rise of Inside-the-Loop Agency r/AI_Agents
A fundamental shift is moving from 'outside-the-loop' automation to 'inside-the-loop' collaboration. u/c1rno123 highlights that high-performing agents succeed by exposing internal planning, allowing humans to prevent 'silent failures' that plague fully autonomous modes.
This pattern is appearing in creative suites; u/Tall-Distance4036 demonstrated ChatGPT 5.5 acting as an active agent within Blender. Simultaneously, platforms like Next AI are refining this by allowing agents to dynamically select data based on real-time input. Reliability is now seen as a factor of iterative feedback loops u/AIAgentDev.
GTM Engines and the ERP Execution Gap r/n8n
Vertical-specific agents are hitting production. u/Chemical-Hearing-834 released an AI GTM engine that automates 90%+ of manual outreach. However, in physical industries, data lag is a major risk. u/rukola99 warns that ERP data lag causes agents to make 'confident decisions on stale inputs.'
This 'Execution Gap' is blocked by a lack of real-time data pipes. As u/soul_eater0001 notes, AI systems often work in isolation but lack a reliable pipe into the actual work environment. For agents to succeed in high-stakes environments, the focus must shift from reasoning to data-freshness.
Discord Developer Digest
OpenAI's Operator signals a shift from chat boxes to browser-native action.
The era of the 'chatbot' is ending; the era of the 'operator' has begun. Today’s transition of OpenAI’s Operator into research preview marks a definitive pivot in the agentic landscape. We are moving away from the brittle world of DOM-scraping and text-based wrappers toward a future where agents interpret visual interfaces with the same intuition as humans. This isn't just about convenience; it’s about reliability. With an 87% success rate in early browser benchmarks, the technical barrier for autonomous action is finally falling.
But as we give agents the keys to our browsers, the infrastructure supporting them is undergoing its own revolution. From the surge of type-safe frameworks like PydanticAI—which promises to kill 'stringly-typed' orchestration—to the growing pains of the Model Context Protocol (MCP), the 'Agentic Web' is being built in real-time. Even the 'edge' is getting sharper, as 8B parameter models transform into high-velocity workers capable of sub-200ms reasoning. For practitioners, the message is clear: the tools are maturing, the protocols are standardizing, and the focus has shifted from what agents can say to what they can actually do. The following stories break down how these architectural shifts are manifesting in production today.
OpenAI Operator: From Research Preview to Actionable Agency
OpenAI has officially transitioned Operator into research preview, debuting a specialized Computer-Using Agent (CUA) architecture designed to interpret UI elements directly rather than relying on brittle DOM-scraping. Unlike previous script-based automation, early benchmarks highlight a 87% success rate on specialized browser tasks, a significant leap for autonomous systems @The Decoder.
Developers like dev_guru observe that Operator's integrated planning layer makes it feel more 'agentic' than Anthropic’s OS-agnostic Computer Use, which relies more on raw screenshot interpretation. While specific API token costs for the Operator-specific CUA loops remain unverified, the industry is already seeing a 50% increase in startups moving toward this visual interface interpretation model @NullZen.
Join the discussion: discord.gg/openai
PydanticAI Challenges LangGraph in the Quest for Type-Safe Agency
PydanticAI has emerged as a formidable alternative to LangGraph by treating agent logic as strictly typed Python functions, which has reportedly led to a 40% reduction in runtime validation errors for early adopters pydantic_dev. While the framework is noted to "crush it" for rapid prototyping and clean code by leveraging native Python typing, it still faces a maturity gap in enterprise-grade state management compared to LangGraph's explicit state machine models zenml.io.
The project's rapid growth—marked by a reported 40% week-over-week increase in GitHub stars—signals a significant shift away from "stringly-typed" orchestration. Development leads have confirmed that the upcoming roadmap will prioritize deeper integration with local model providers like Ollama, positioning PydanticAI as a core component for agentic microservices that require high structural precision pydantic_team.
Join the discussion: discord.gg/pydantic
MCP Ecosystem Faces Security Scrutiny Amid Rapid Growth
Anthropic's Model Context Protocol (MCP) has solidified its reputation as the 'USB-C for AI tools,' with the community ecosystem surging to over 500 public servers @tolkonepiu. While the protocol standardizes how models discover external data sources, recent technical audits have exposed critical permissioning gaps. Researchers have identified a systemic 'design flaw' in the official MCP SDK that could potentially enable Remote Code Execution (RCE) by bypassing explicit user permissions during file modification tasks The Hacker News.
Despite these risks, adoption remains aggressive following the launch of the MCP Registry, which has reduced enterprise integration time by an estimated 40% MCP Blog. However, the developer community remains divided; while some see MCP as the mandatory foundation for the 'agentic web,' others warn that the current specification requires more robust sandboxing to prevent agents from overstepping their data access bounds The Register.
8B Models Transition from Chatbots to High-Velocity 'Workers'
Recent benchmarks in the local-LLM community indicate that 8B parameter models, specifically Llama 3.1 and Mistral, have moved beyond simple chat roles to become highly efficient 'worker' agents. Developers are reporting sub-200ms latencies for initial agentic decisions on consumer hardware, a speed that rivals or exceeds cloud-based giants like GPT-4o's 232ms response floor. This efficiency is largely driven by optimized fine-tuning frameworks like Unsloth, which provides up to 30x faster training speeds and a 60% reduction in memory usage Gautam75.
However, achieving reliable tool-calling in 8B models requires more than raw data; practitioners emphasize the need for 'negative constraint' training, suggesting the inclusion of 1,000+ non-tool examples to prevent the model from hallucinating tool calls. This architectural shift positions 8B models as the ideal 'edge' layer for multi-agent systems—substantial enough for local reasoning but small enough to fit into high-velocity loops AgenticRanked.
Self-Correction and Reflection Loops Standardize Agentic RAG
The transition from simple RAG to Agentic RAG is accelerating as developers move toward 'Corrective RAG' (CRAG) patterns where retrieval is treated as a tool call. In these architectures, agents utilize reflection loops to evaluate document quality and reformulate queries when initial results are insufficient Digital Applied. This iterative approach has demonstrated a 30% improvement in factual accuracy across production environments Discord dev.
To manage the overhead of these workflows—which can consume 3-10x more tokens than classic pipelines—engineering teams are adopting new evaluation frameworks focused on Task Success Rate (TSR) and Plan Optimality. By implementing progressive refinement strategies, builders are successfully balancing reasoning depth with operational cost vanducng.
Join the discussion: discord.gg/ai-agents
From Approval Gates to Collaborative State: The HITL Evolution
As agents move closer to production, orchestration is shifting from simple 'stop-and-wait' gates to 'interruptible' state machines that allow for true collaboration. Frameworks like LangGraph have standardized this via a persistence layer anchored by the checkpointer API, which now supports 1,000+ concurrent stateful threads to prevent 'state bloat' in complex workflows JIN.
Beyond basic oversight, new design patterns are emerging for 'Iterative Refinement Loops' where agents ask context-aware follow-up questions rather than just requesting a binary 'yes/no' Maven. To support these flows at an enterprise level, tools like LangChain MCP Adapters are bridging agentic logic with external authorization platforms, ensuring that human intervention remains a secure, auditable component of the automation stack Permit.io.
HF Research Roundup
Hugging Face's smolagents and H Company's Holotron are proving that code execution and high-throughput SSMs are the new standard for autonomous success.
The 'Agentic Web' is moving away from the brittle uncertainty of JSON tool-calling toward a 'code-as-action' reality. For months, developers have wrestled with models hallucinating schema or losing the thread in multi-step reasoning. Today, the data suggests a cleaner path forward: treating actions as executable Python snippets. Hugging Face’s smolagents is leading this charge, demonstrating that a minimalist approach can yield a 26% performance improvement simply by letting agents write the logic they need to execute.
But raw logic isn't enough; we need the hardware and protocols to support it. From H Company’s high-throughput Holotron-12B hitting 8.9k tokens/s to the 'USB moment' of the Model Context Protocol (MCP), the infrastructure for autonomous systems is finally maturing. However, a 'verification gap' remains. As IBM and Berkeley’s new VAKRA benchmark highlights, agents still struggle to confirm if their actions actually worked. For practitioners, the message is clear: the focus is shifting from 'can the model talk?' to 'can the agent verify and execute?'
Smolagents: The 'Code-as-Action' Shift Dominates Agentic Benchmarks
Hugging Face is aggressively pivoting toward a 'code-as-action' paradigm with smolagents, a minimalist library that replaces brittle JSON tool-calling with direct Python execution. This architectural shift achieves a 30% reduction in logic steps and a 26% performance improvement over traditional frameworks by treating actions as executable snippets rather than probabilistic text. The robustness of this approach was recently validated by the Transformers Code Agent, which topped the GAIA benchmark by demonstrating that code-writing agents significantly outperform standard tool-calling methods in complex, multi-step reasoning tasks.
To support multimodal operations, the ecosystem now officially supports Vision-Language Models (VLMs) through smolagents-can-see, enabling agents to navigate visual GUI elements. For production environments, integration with Arize Phoenix provides necessary tracing tools, while the new 'License to Call' framework ensures granular tool permissions Hugging Face. This shift toward verifiable execution is being further institutionalized by a new specialized course on building code agents from DeepLearning.AI.
High-Throughput SSMs Drive Autonomous Desktop Control
The race for autonomous 'Computer Use' is accelerating with the release of Holotron-12B, a high-throughput multimodal model delivering 8.9k tokens/s on a single H100. Developed by H Company in collaboration with NVIDIA, this policy model powers the Surfer-H agent, which has demonstrated a 62.3% success rate on the ScreenSuite benchmark, nearly doubling GPT-4o’s 36.1% performance.
New Benchmarks Target the 'Verification Gap' in Workflows
A wave of new evaluation suites like IBM and UC Berkeley's VAKRA is shifting focus from chat metrics to diagnosing why agents fail in high-stakes environments. The analysis identifies 'Incorrect Verification' as a primary failure mode, noting that even frontier models like Claude 3.5 Sonnet average 2.6 to 5.3 distinct failure modes per task while the industry struggles to break the 20% success ceiling in complex enterprise troubleshooting.
MCP: Establishing the 'USB Moment' for Connectivity
The Model Context Protocol (MCP) is enabling functional tool-using agents in under 50 lines of Python, though experts like @denisuraev warn of wasting expensive LLM context on rarely used tool details.
Open-Source Deep Research Challenges Proprietary Search
The launch of Hugging Face Open-source DeepResearch allows agents to achieve 72-82% of OpenAI's performance on GAIA, supported by the new DeepResearch Bench evaluation framework.
NVIDIA and DeepSeek Optimize for Agentic Reason
While DeepSeek-V4 introduces a 1M token context window, retrieval benchmarks show a performance ceiling of 0.59 MMR at the limit, trailing behind proprietary leaders like Gemini 1.5 Pro.
Specialized Agents: From Medical Grounding to E-Commerce
Google's EHR Navigator and the Ecom-RLVE framework are using 'verifiable environments' to mitigate hallucinations in high-value medical and commercial transactions.