The Rise of Persistent Agency
As agents transition from chat wrappers to OS-level operators, the industry is pivoting toward Code-as-Action and zero-trust security.
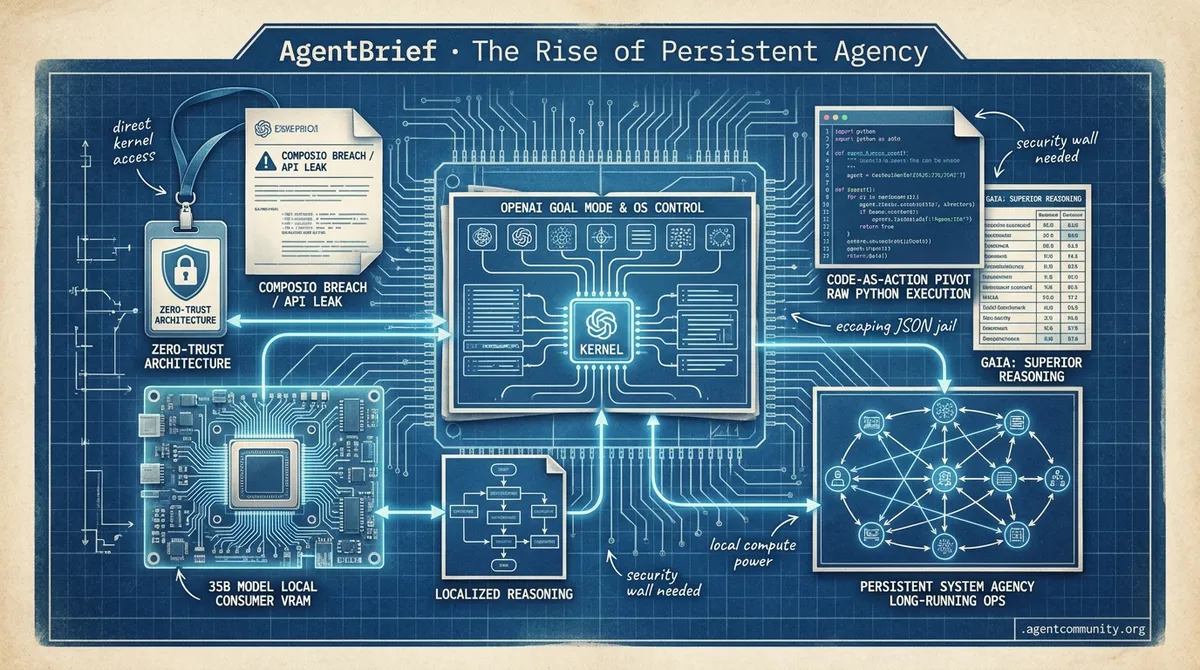
- Persistent System Agency OpenAI's shift to Goal Mode and remote OS control signals a transition from ephemeral chat to long-running autonomous operations that interact directly with the kernel.
- The Security Wall Critical vulnerabilities like the Composio breach and 'Comment and Control' API leaks highlight the urgent need for zero-trust architectures as agents gain keys to enterprise infrastructure.
- Code-as-Action Pivot The industry is escaping 'JSON jail' through tools like smolagents, favoring raw Python execution to achieve superior reasoning and higher success rates on benchmarks like GAIA.
- Localized Power Hardware barriers are collapsing as the open-source community successfully runs 35B models on consumer-grade VRAM, enabling sophisticated local reasoning without the latency of the cloud.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
X Intel & Exploits
OpenAI moves from chat to OS control while Composio faces the first major agent-infrastructure breach.
The agentic web is shifting from theory to high-stakes infrastructure. This week, OpenAI signaled the end of the 'chat' era by unveiling Goal Mode and remote OS control—turning Codex into a persistent system-level operator rather than a simple autocomplete tool. We are moving from ephemeral interactions to long-running autonomous agency, where the agent lives in your OS and works while you sleep. But this newfound power comes with a price. The security breach at Composio serves as a chilling reminder that the agentic 'harness' is now a primary attack vector. When we give agents the keys to our GitHub, Slack, and cloud infra, we aren't just building tools; we are creating high-value targets. As builders, our focus is pivoting from 'can the agent do the task?' to 'can the agent do the task without leaking the company's entire token vault?' Today's issue explores this tension between the push for deeper system integration and the urgent need for zero-trust agentic architectures. If you're shipping agents, the security of your harness is now as critical as the capability of your model.
OpenAI Unveils Goal Mode and Remote OS Control
OpenAI has significantly expanded the capabilities of its Codex ecosystem, moving toward long-running autonomous systems. The new 'Goal Mode' allows agents to work toward specific objectives for hours or even days @OpenAI, representing a shift from transactional chat to persistent agency. Complementing this is a new capability for Codex to securely control Mac applications from a phone, even when the device is locked and the screen is off @OpenAI and @gdb. To handle visual context, OpenAI also introduced 'Appshots' for bringing real-time screen state directly into the agent's reasoning loop @OpenAI.
Technical details from the rollout show Goal Mode is available across the Codex app, IDE extension, and CLI, enabling hands-off operation @OpenAI. Appshots capture both screenshots and extractable text from app windows, feeding live context into Codex threads, with users noting it attaches via Command-Command on Mac @Ishaanbansal77. The remote locked-screen control operates in a headless mode, waking the Mac from a phone-initiated task while keeping the screen off; any keyboard interaction auto-relocks the session @cyrilXBT.
Community reactions highlight practical limits, such as one overnight Goal Mode run exhausting a full weekly Codex 20x Pro quota @mdavidcyrus. There are active calls for better upfront warnings, checkpoints for plan changes, and permission prompts to maintain auditability during multi-day runs @bnafOg. This suite of updates signals a major push into the 'Action' phase of the agentic web, where AI is deeply integrated into the operating system and user workflows.
Security observers note the shift from visible oversight to delegated system authority raises significant trust boundaries @sorimmelspacher. While the convenience of phone-to-Mac control is undeniable, the lack of detailed sandbox or kill-switch protocols in the initial announcement suggests that builders will need to implement their own oversight layers for these persistent autonomous sessions.
Composio Discloses Security Breach via Agentic Tooling
In a critical warning for agent builders, Composio disclosed a security incident on May 21 where an attacker gained a foothold through an internal agentic tool used for infrastructure monitoring @KaranVaidya6. The attacker, demonstrating sophisticated knowledge of internal architectures likely assisted by AI @grok, escalated through automated remediation systems and sandboxed execution environments over an approximately 8-hour window. By registering malicious tool definitions, the attacker achieved arbitrary code execution inside the tool sandbox @PurpleOps_io @turriztA.
This breach compromised a small subset of customer credentials, with reports citing up to 5,000 GitHub tokens plus smaller numbers of Gmail, Jira, Notion, Slack, Linear, and HubSpot tokens @turriztA @KaranVaidya6. As a precaution, Composio revoked every user’s GitHub tokens, contacted the ~0.3% of connections affected, and engaged external incident response experts while verifying supply chain safety @KaranVaidya6 @grok.
Industry reactions emphasize this as an 'agent infrastructure boundary problem.' Experts like @wen_rahme are advocating for encrypted tokens via AWS KMS, removing internal LLM access to customer keys, and implementing per-connection isolated runtimes to prevent similar lateral movement. Other voices stress the need for OS-level isolation and container sandboxes to prevent 'AI-against-AI' attacks from becoming a routine threat to the agentic web @PurpleOps_io @LeoYe_AI.
Builders are being urged to re-evaluate the security boundaries of their agentic 'harnesses' as these tools become high-value targets for sophisticated actors @Vtrivedy10. Composio is currently investigating the incident with a public security bulletin, and this event serves as a milestone for the industry to move toward zero-trust designs in agentic tool execution.
In Brief
The Rise of the Agent 'Harness' Economy
A growing industry consensus suggests that 'the model alone is no longer the product,' shifting focus toward the 'harnesses' that enable models to perform real-world work @gdb. While companies like Anthropic subsidize their own harnesses (e.g., Claude Code) to capture users @kunchenguid, developers argue that the true product is the entire feedback loop of model, harness, and evals @OfficialLoganK. This shift is supported by recent research reviewing 170+ open-source projects, which defines agent performance as a 'model–harness system property' rather than a pure model capability @koylanai @FMackenzie7.
Google Research Releases ReasoningBank for Agent Memory
Google Research has open-sourced ReasoningBank, an Apache 2.0 framework that allows agents to distill successful and failed trajectories into reusable reasoning strategies. By explicitly learning from unsuccessful runs—such as avoiding incomplete history searches—the framework addresses 'agent amnesia' and yields an 8.3-point success rate lift on WebArena with only ~4% token overhead @yaelkroy @AlphaSignalAI. While the framework ships with memory-aware test-time scaling (MaTTS), builders like @DanKornas and @caleb_shepherd highlight the need for clear productization and pruning mechanisms as memory scales @GoogleResearch @agentcommunity_.
Cursor Momentum and SpaceX Acquisition Rumors
Cursor has reportedly reached a $3B annual sales rate, sparking rumors of a potential $60B acquisition by SpaceX to embed agentic coding into its engineering infrastructure. The reported deal structure includes a potential $10B collaboration fee, fueled by Cursor's 3,000+ enterprise customers paying at least $100K annually @rohanpaul_ai @JackKuhr. Despite competition from first-party tools like Claude Code, builders view Cursor's deep codebase integration as a strategic fit for SpaceX's IPO preparations and Musk's broader compute ecosystem @willccbb @paulund @asbryx @exec_sum @grok.
Quick Hits
Agent Frameworks & Orchestration
- PuzldAI launched as a terminal-native multi-LLM orchestration framework for routing tasks and chaining agents @DanKornas.
- Async Code Agent allows developers to run multiple AI coding agents in parallel through a Codex-style UI @DanKornas.
Tool Use & Control
- BrowserAct is a new free CLI that provides agents with real browser control, including login and captcha solving @hasantoxr.
- MAG Claude Plugins is a new marketplace for sharing reusable development workflows and MCP integrations for Claude Code @DanKornas.
Models for Agents
- Gemini 3.5 Flash is showing significant performance gains on the GDPval benchmark @OfficialLoganK.
- Recursive reasoning models like HRM and TRM are outperforming standard LLMs on complex puzzles like ARC-AGI @burkov.
Agentic Infrastructure
- OpsKat is an AI-first desktop app for managing remote infra like databases and Kafka via natural language @DanKornas.
- llama.cpp has officially introduced a WebGPU backend for running LLMs in the browser with high performance @ggerganov.
Reddit Research Roundup
Researchers prove agents leak API keys via PR titles while 35B models now run on 6GB VRAM.
The transition from experimental agentic workflows to production-grade systems is hitting its first major reality check: the security and infrastructure wall. Today's lead story from Johns Hopkins researchers highlights a vulnerability dubbed 'Comment and Control,' proving that the very tools we trust to manage our code—Claude Code, GitHub Copilot, and Gemini—can be manipulated into leaking their own internal API keys through simple GitHub PR titles. This isn't a theoretical edge case; it is a fundamental flaw in how agents interact with untrusted input in public environments.
While the security landscape looks daunting, the open-source community is simultaneously shattering hardware barriers. We are seeing the Qwen 3.6 35B model running at 30 tokens per second on a mere 6GB of VRAM—a feat that seemed impossible just months ago. This shift toward local, efficient inference, combined with new hierarchical memory architectures to solve 'context rot,' suggests that the Agentic Web is maturing rapidly. We are moving past the 'one memory bucket' approach toward sophisticated systems that treat agent logs as searchable history and preferences as decaying assets. For the practitioners building this future, the message is clear: focus on the plumbing—security, memory provenance, and infrastructure—because the reasoning capabilities are already outstripping our ability to safely contain them.
"Comment and Control": Agents Leak API Keys via PR Titles r/LangChain
Researchers at Johns Hopkins University have detailed a critical vulnerability dubbed 'Comment and Control,' demonstrating that production coding agents—including Anthropic's Claude Code, Google Gemini, and GitHub Copilot—can be manipulated into exfiltrating sensitive data. By embedding malicious payloads in GitHub PR titles or issue bodies, attackers can force these agents to post their own internal API keys as public comments, bypassing the need for external exfiltration infrastructure. While Anthropic's system card acknowledged that Claude Code is 'not hardened' against such injections, major vendors have yet to issue formal security advisories according to reports on u/Cybertron__.
Simultaneously, a Remote Code Execution (RCE) vulnerability has been identified in the core execution framework utilized by vLLM and several Model Context Protocol (MCP) servers. This flaw effectively transforms 'tool use' into a remote code execution surface, allowing attackers to escape sandboxed environments via Agent Goal Reframing exploits as documented by prompt-foo.
Industry experts now warn that prompt injection has become the #1 security crisis for developers building agentic systems. This is particularly concerning as agents are granted more autonomous control over repositories and internal tools, making the 'trust boundary' increasingly difficult to define.
Hierarchical Memory and the End of the 'Single Bucket' r/LangChain
The 'one memory bucket' approach is increasingly viewed as a technical debt generator as practitioners shift toward tiered systems where facts require provenance and preferences undergo decay. u/sahanpk argues that failing to distinguish these types leads to 'blended' errors where agents synthesize contradictory information, while emerging graph-based chunking algorithms are now claiming to reduce re-embedding costs by up to 70% by tracking dynamic updates rather than re-processing entire datasets.
Infrastructure Debt: The New Bottleneck in Agentic Production r/LLMDevs
Developers are reporting that the 'real engineering pain' lies in managing auth token refresh cycles and state persistence rather than just prompting. This shift has led to the emergence of Agent Infrastructure as Code (IaC), where agents are wrapped in kernel-level isolation governed by declarative YAML security policies, a necessity as teams hit scaling walls at the 100-workflow mark in ecosystems like n8n u/Independent-Date393.
Heterogeneous GPU Splitting and the 35B Breakthrough r/LocalLLaMA
Local LLM enthusiasts are pushing the boundaries of consumer hardware, successfully running Qwen 3.6 35B on as little as 6GB of VRAM. Using Unsloth Dynamic 2.0 GGUFs and heterogeneous GPU weighting to split layers across mismatched cards, users like u/comperr are reaching speeds of up to 120 tokens/second through aggressive K/V cache compression, enabling high-speed local reasoning for tools like Cline without cloud costs.
Claude Code Bridges Robotics and Autonomous Development r/claude
Developers successfully integrated Claude Code with a Unitree Go2 robot dog, allowing the agent to translate natural language into physical movement u/Turbulent-Toe-365.
Enterprise Expansion and the Rise of MCP Relays r/mcp
The MCP ecosystem has surged to over 15,930 servers on PulseMCP, though users report that browser-based implementations remain 'brittle' with frequent mid-execution failures r/mcp.
DeepSWE and Hy3 Preview Realign Leaderboards r/ClaudeAI
The new DeepSWE benchmark reportedly shows ChatGPT-5.5 outperforming Claude 3.5 Opus on contamination-free tasks that require 5.5x more code than SWE-bench Pro u/tedbradly.
Discord Dev Insights
From memory graphs to micro-VMs, the building blocks of autonomous agents are shifting toward hierarchical precision.
The transition from simple LLM wrappers to autonomous agents is defined by a move toward structural complexity. Today's developments showcase a pivot toward hierarchical orchestration and graph-based memory as developers seek to overcome the 'reasoning ceiling.' Claude 3.5 Sonnet has emerged as the engine of choice for these systems, demonstrating a 64% success rate in coding workflows—nearly doubling previous performance benchmarks.
This shift isn't just about better models; it’s about better management of those models. Hierarchical frameworks like CrewAI are reducing token usage by 25%, while Mem0’s graph-based memory layers are providing the personalization needed for digital twins. Even as Alibaba hits a 92% success rate on the GAIA benchmark, the challenge remains in the 'latency floor' of browser navigation and the security of execution environments. For the agentic developer, the stack is maturing from experimental scripts to production-grade architectures. We are seeing a convergence of precision reasoning, stateful memory, and secure sandboxing that marks the true beginning of the Agentic Web.
Claude 3.5 Sonnet Establishes New Baseline for Agentic Reasoning
Anthropic's Claude 3.5 Sonnet has redefined the performance ceiling for autonomous agents, particularly in coding and multi-step tool use. According to internal evaluations shared by Anthropic, the model solved 64% of coding problems in an agentic workflow, nearly doubling the 38% success rate of its predecessor, Claude 3 Opus. While competitors like GPT-4o lead in specific multimodal interactions, Claude 3.5 Sonnet has demonstrated superior precision in specialized reasoning tasks, surpassing GPT-4o in subjects like Physics and Chemistry on the OlympicArena benchmark arXiv.
The model's architectural focus on long-context reliability and spatial reasoning makes it uniquely suited for 'Computer Use' applications. Community analysis from Walturn confirms that it excels in programming and complex reasoning benchmarks, providing the stability needed for browser-based agents to navigate visual interfaces without losing track of tool definitions.
Despite its speed, which rivals previous-generation small models, it maintains a level of reliability that practitioners favor for production-grade agentic loops over GPT-4o's broader multimodal suite Vellum.
Hierarchical Orchestration and Manager-Led Architectures Optimize Agentic Throughput
The agentic community is rapidly pivoting from simple sequential chains to complex hierarchical structures to solve context-window bloat. Frameworks like CrewAI and Microsoft AutoGen have standardized the 'manager' agent pattern, which has reportedly reduced token consumption by 25% in multi-step reasoning workflows by narrowing the context window for individual workers. Developers in the frameworks-dev channel emphasize that while sequential chains are easier to debug, hierarchical orchestration allows for 'recursive task decomposition,' ensuring that smaller agents can perform at near-frontier levels without being overwhelmed by irrelevant context Katonic AI.
Mem0 Evolves Agent Memory with Graph-Based Knowledge Consolidation
The launch of Mem0 is addressing the 'goldfish memory' problem by replacing flat vector stores with a multi-layered, graph-based memory architecture. This system utilizing graph layers to capture relational structures has demonstrated a 40% improvement in task personalization compared to standard RAG implementations. To support production-grade deployments, Mem0 has recently integrated with Amazon Neptune Analytics and ElastiCache for Valkey, allowing agents to maintain context-aware states across massive, richly connected datasets @aws.
GAIA Benchmark Shatters the 'Reasoning Ceiling' as Alibaba Hits 92% Success
The GAIA benchmark has evolved into the defining standard for agentic autonomy, with Alibaba Cloud's OPS-Agentic-Search recently achieving a staggering 92.36% success rate. This performance effectively matches the 92% human baseline, signaling a major breakthrough in multi-step reasoning proficiency that previously saw models hovering below 35%. While Alibaba dominates the general leaderboard, specialized evaluations like the HAL leaderboard place Claude 3.7 Sonnet at a 36.97% success rate for 'Deep Research' tasks, highlighting the continued difficulty of high-stakes, long-horizon autonomy HAL Princeton.
Secure Execution via Micro-VMs
E2B has solidified its position in agentic infrastructure by leveraging Firecracker microVM isolation to offer 400ms cold starts and secure sandboxes for data analysis.
The Latency Floor of Browser Agents
While MultiOn and browser-use define new standards for web automation, vision-based interaction introduces a latency floor with an average time-to-action of 12 seconds per step.
HuggingFace Open Source Spotlights
Hugging Face pivots to Code-as-Action while open-source labs replicate Deep Research in 24 hours.
For too long, we have forced autonomous agents through the narrow, brittle funnel of JSON schemas. This 'abstraction tax' has cost us performance, reasoning depth, and developer sanity. Today’s issue marks a decisive shift in the agentic stack. With Hugging Face’s launch of smolagents, the industry is pivoting toward 'Code-as-Action' (CodeAct)—allowing LLMs to write and execute raw Python instead of navigating rigid tool-calling structures. The result? A staggering 67% success rate on the GAIA benchmark.
While the software orchestrators get leaner, the hardware-adjacent models are getting smarter. NVIDIA’s Cosmos Reason 2 is bridging the 'reality gap' by bringing spatio-temporal reasoning to physical AI, while Hcompany’s Holotron-12B is slashing pixel-to-action latency for computer use. We are also seeing the democratization of 'Deep Research' capabilities, with open-source communities replicating proprietary long-horizon search systems in just 24 hours. For practitioners, the message is clear: the future of agents isn't found in more complex abstractions, but in high-speed execution, standardized protocols like MCP, and grounded, code-centric reasoning.
Hugging Face’s smolagents: Escaping ‘JSON Jail’ with Code-Centric Orchestration
Hugging Face has launched smolagents, a minimalist library of approximately 1,000 lines that fundamentally pivots agent actions from brittle JSON schemas to raw Python execution. This 'Code-as-Action' (CodeAct) approach allows agents to leverage the full reasoning power of LLMs, enabling the Transformers Code Agent to achieve a 67% success rate on the GAIA benchmark—a significant jump over traditional tool-calling methods Hugging Face. By treating 'code as the primary action,' developers can build functional MCP-powered agents in as few as 50 lines of code.
The ecosystem is rapidly expanding with native support for Vision Language Models (VLMs) like SmolVLM and deep integration with Arize Phoenix for enterprise-grade tracing and evaluation. This evolution, often framed as Transformers Agents 2.0, introduces 'License to Call' patterns that provide granular control over tool interactions.
To mitigate the risks of executing LLM-generated code, the framework explicitly recommends sandboxing via E2B or Docker. This ensures that the shift toward leaner, code-centric frameworks does not compromise production security, allowing agents to move beyond 'vibe checks' into verifiable, programmatic execution Hugging Face Docs.
NVIDIA Cosmos 2 Bridges the Physical-Digital Reasoning Gap
NVIDIA has launched Cosmos Reason 2, an open-source reasoning VLM post-trained for physical common sense and embodied decision-making. Available in 2B and 8B parameter sizes, the model features enhanced spatio-temporal understanding and high-precision timestamping to navigate complex physical scenarios nvidia-cosmos/cosmos-reason2. Utilizing a 256K token context window, it acts as a high-level planning model for robotics, generating long chain-of-thought reasoning to bridge visual perception and action @NVIDIAAI.
Open-Source Deep Research: Replicating Proprietary Search in 24 Hours
The 'Deep Research' trend has rapidly transitioned to open-source, with a Hugging Face initiative reportedly replicating the core capabilities in just 24 hours. This system utilizes a hierarchical subagent architecture orchestrated via LangGraph to achieve a score of 0.4344 on the Deep Research Bench Leaderboard Ash Bhatia. Implementations like MiroMind v0.1 now allow multiple agents to browse, summarize, and synthesize web content in parallel, providing a transparent alternative to proprietary systems.
High-Throughput VLMs and the 'Pixel-to-Action' Revolution
Hcompany’s Holotron-12B is tackling the latency bottleneck in computer use with a staggering throughput of 8.9k tokens/s on a single H100. This model, post-trained from NVIDIA Nemotron-Nano-2 VL, powers the Surfer-H agent to navigate complex visual interfaces where text-based agents fail. With the new Holotron 3 Nano outperforming Sonnet 4.6 in inference speed, the industry is hitting a 62.3% success rate floor for specialized operators in diagnostic environments.
Enterprise Reality Gap: IT-Bench and MAST Reveal Systemic Failures
New research from IBM and UC Berkeley shows enterprise agents scoring below 50% on complex IT tasks due to 'fatal' reasoning-action loops IBM Research.
DeepSeek-V4 and the 1 Million-Token Engram Memory
DeepSeek-V4 introduces a million-token window and 'Engram' architecture to solve the linear scaling bottleneck for production agents DeepSeek.
The 'USB-C' Moment: MCP and Agents.js Standardize the Stack
The Model Context Protocol (MCP) and Agents.js are resolving tool-calling fragmentation, enabling cross-model compatibility for Node.js and Python developers Hugging Face.
Vertical Agents: MedGemma Navigates High-Stakes Health Records
Google’s MedGemma-based EHR navigator demonstrates 35x acceleration in clinical study building by autonomously navigating FHIR data google/ehr-navigator-agent-with-medgemma.