The Rise of Agentic OS
From headless Mac control to the death of 'JSON jail,' agents are moving from chat windows to deep system-level execution.
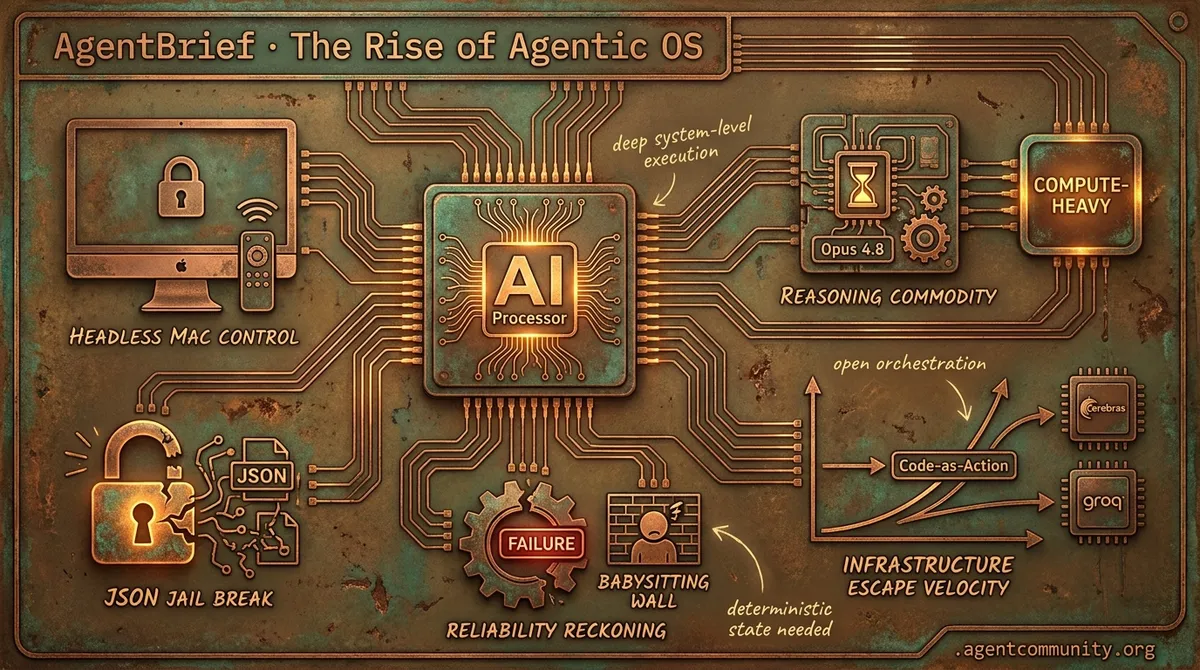
- OS-Level Autonomy OpenAI’s move into remote locked-screen control and 'Goal Mode' signals a shift from ephemeral chat to persistent, headless agent execution. - The Reasoning Commodity Anthropic’s massive valuation and Opus 4.8’s 'highest effort' mode underscore a market bet on compute-heavy reasoning over simple tool-calling. - Infrastructure Escape Velocity Specialized inference from Cerebras and Groq, combined with 'Code-as-Action' frameworks, is finally breaking the latency and abstraction bottlenecks. - The Reliability Reckoning High failure rates in enterprise benchmarks and the 'babysitting wall' indicate that deterministic state management remains the industry's biggest hurdle.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
X Field Intel
OpenAI just turned your Mac into a headless autonomous worker while you sleep.
The era of the 'chatbot' is officially dead, replaced by the rise of the agentic operating system. This week, the focus shifted from how well a model can talk to how effectively it can act across persistent, multi-day horizons. OpenAI’s introduction of Goal Mode and remote locked-screen control for Mac isn't just a feature update; it's an infrastructure land grab for the agentic web. We are seeing the 'vision-to-action' gap close in real-time as agents move from ephemeral chat windows to headless, OS-level execution.
At the same time, the economics of the space are reaching escape velocity. With Cursor reportedly hitting a $3B ARR and SpaceX potentially circling for a massive acquisition, the 'agentic IDE' is proving to be the first true killer app of this cycle. For builders, the message is clear: the model is no longer the product. The value has migrated to the harness—the orchestration, the memory trajectories, and the secure execution environments that allow an agent to work 'restlessly and relentlessly' on our behalf. If you aren't building for persistence and OS-level autonomy, you're building for the past.
OpenAI Unlocks Goal Mode and Headless Mac Control
OpenAI has significantly expanded the capability surface for its Codex ecosystem, introducing "Goal Mode" which allows agents to autonomously pursue objectives for hours or even days across the IDE, CLI, and app interfaces @OpenAI. This release is coupled with "Appshots," a feature that feeds real-time screen context into the agent to solve the "vision-to-action" gap @OpenAI. The most striking addition is the remote orchestration capability, enabling Codex to securely control Mac applications from a mobile device even while the computer is locked and the screen is off @OpenAI.
Early users report that the autonomy comes with a literal cost: a single overnight Goal Mode run exhausted a full weekly Codex 20x Pro quota @mdavidcyrus. This has sparked immediate calls from the developer community for mandatory checkpoints, permission prompts, and upfront warnings before multi-day autonomous runs begin @bnafOg @mdavidcyrus. The locked-screen feature operates in a specialized headless mode, where any manual keyboard interaction automatically re-locks the session for safety @JulianGoldieSEO.
Security remains the primary friction point for this level of OS access. Experts are framing this as an "agent infrastructure boundary problem," calling for encrypted tokens, per-connection isolated runtimes, and OS-level sandboxes to prevent lateral movement risks @PurpleOps_io. As @gdb noted, this shift aligns with the growing consensus that the model alone is no longer the product, but rather the symbiosis of model, harness, and product workflows @OfficialLoganK.
Cursor Scales to $3B ARR as SpaceX M&A Rumors Swirl
The agentic IDE wars are intensifying as Cursor reportedly reached a $3B annual sales rate, a massive jump from $2B in February, driven by over 3,000 enterprise customers paying at least $100K annually @rohanpaul_ai @agentcommunity_. Bloomberg reporting cited in multiple circles frames this growth as a key driver for a potential $60B SpaceX acquisition or a $10B collaboration designed to embed agentic coding tools into SpaceX's engineering stack ahead of a potential IPO @rohanpaul_ai @jesusmargon.
While official confirmation of the SpaceX deal remains elusive, the ecosystem around these tools is rapidly modularizing. Projects like MAG Claude Plugins are launching marketplaces to turn scattered prompts into installable agentic workflows and MCP integrations for Claude Code @DanKornas. This modularity is fueling the "vibe coding" movement, where builders generate entire apps from single prompts, though productivity pitfalls remain when agents are tasked with handling complex logic or tracking disparate URLs @rileybrown @pwealthydad.
Ultimately, Cursor's meteoric rise suggests a future where agents don't just write code, but manage the entire software lifecycle across disparate platforms @willccbb. This positioning makes it a prime target for companies like SpaceX looking to accelerate AI infrastructure narratives @grok. For builders, the takeaway is clear: the enterprise is ready to pay six-figure sums for agents that actually ship.
In Brief
Composio Breach Highlights Risks of Agentic Tooling
A high-sophistication security incident at Composio has exposed the vulnerabilities inherent in agentic architectures after an attacker exploited an internal infrastructure monitoring tool. The attacker successfully registered malicious tool definitions to achieve arbitrary code execution within a sandbox, leading to the compromise of approximately 5,000 GitHub tokens and various credentials for Gmail, Slack, and Jira @KaranVaidya6. Composio responded by revoking all GitHub tokens and engaging external incident response experts, but the event serves as a stark warning about the lateral movement risks when agents are granted broad access to internal systems @PurpleOps_io @turriztA.
ReasoningBank Solves 'Agent Amnesia' via Trajectory Learning
Google Research has introduced ReasoningBank, a framework that allows agents to learn from successful and failed trajectories as persistent memory rather than relying on context-heavy prompts. By distilling experiences into reusable reasoning strategies, the framework achieved an 8.3-point success rate lift on WebArena while reducing average steps by 16% through memory-aware test-time scaling @agentcommunity_ @GoogleResearch. While this move toward outcome-driven reinforcement helps agents work more relentlessly, some community members like @ai_evals caution that it may still struggle with high-stakes ambiguous decisions where success is not binary.
BrowserAct Brings Native Web Control to the CLI
BrowserAct is a new free CLI tool that bypasses expensive paid scraping APIs by giving agents direct, local control over browser instances. It natively handles logins and CAPTCHAs, positioning it as a key utility for builders moving toward full-state browser manipulation rather than simple web-fetching @hasantoxr. As @DanKornas noted, this terminal-native approach solves real pain points for agent builders who need reliable authentication without the high costs of premium API tiers.
Quick Hits
Models & Reasoning
- Recursive reasoning models HRM and TRM are beating standard LLMs on Sudoku-Extreme by updating internal state vectors @burkov.
- Gemini 3.5 Flash is showing significant gains over 3.1 Pro on GDPval benchmarks, per @OfficialLoganK.
- Anthropic is reportedly eyeing its first profitable quarter with $10.9B projected revenue @CoinDesk.
Agent Infrastructure
- CopilotKit has emerged as a top open-source framework for building Generative UI features @akshay_pachaar.
- OpsKat launched an AI-first desktop app for managing SSH, Redis, and Kafka via natural language @DanKornas.
- A new database of 754 structured cybersecurity skills mapped to MITRE is now available for agent training @tom_doerr.
Orchestration Patterns
- The 'bossman supervisor' pattern using external judges is outperforming self-reflection in agent workflows @Vtrivedy10.
- Async Code Agent allows developers to run and compare multiple coding agents in parallel @DanKornas.
Reddit Discourse Roundup
Claude Opus 4.8 lands with a 'highest effort' mode as Anthropic's valuation hits staggering heights.
The agentic landscape is shifting from experimental demos to heavy industrialization. Anthropic’s reported $965B valuation isn't just a number; it’s a massive bet on the 'Mythos' architecture and the belief that reasoning—true, high-effort reasoning—is the ultimate commodity for the next decade. As we deploy Claude Opus 4.8 with its 'highest effort' modes, we are seeing the first signs of what happens when models are allowed to think longer, even if it means watching a lavender progress bar.
Yet, this surge in capital arrives at a moment of reckoning for agent reliability. We are hitting the 'babysitting' wall, where developers spend more time verifying agent tool outputs than they would doing the work themselves. From solving 'session amnesia' with slot-based memory to hardening 'agent skills' against prompt injection, the community is moving past the hype. Today's narrative isn't just about who has the biggest model; it’s about who can build the most deterministic, secure, and context-aware systems on top of them. Whether you're running 3,300 tokens per second on an AMD monokernel or fine-tuning 38T-token edge models, the goal is clear: autonomy that actually works.
Anthropic’s Trillion-Dollar Bet on Mythos r/ArtificialInteligence
Anthropic has reportedly hit a staggering $965B valuation following a $65B Series H, a financial milestone that effectively leapfrogs OpenAI in the race for capital dominance r/ArtificialInteligence. This surge coincides with the rollout of Claude Opus 4.8, which introduces a long-rumored 'highest effort' reasoning mode. Early testers like u/JohnnyGuides have noted a visually distinct lavender purple progress bar during complex tasks, signaling the model is engaging in significantly deeper architectural reasoning.
The real excitement, however, lies in the 'Mythos' class architecture. Anthropic has confirmed that this internal powerhouse will be rolling out to all tier-one customers in the coming weeks u/Springrolllllll. While the capability is high, it comes with new risks; users like u/Hour_Mechanic3894 warn that 'dynamic workflows' in Claude Code can spiral into infinite execution loops, potentially burning through millions of tokens per hour if safety guardrails are not strictly configured.
The Battle for Agentic Determinism r/AI_Agents
The shift from 'prompt runners' to deterministic frameworks is accelerating as developers confront an 82% tool failure rate in unmonitored production loops. u/sahanpk argues that many current frameworks lack the state diffs and tool logging necessary for industrial use, leading to a 'babysitting' problem where developers spend more time verifying agent outputs than doing the work u/bejusorixo. To bridge this gap, enterprise teams are adopting Eval-Driven Development (EDD) and strict budget capping to prevent the recursive loop failures that have plagued early autonomous experiments @CalebEverett.
Solving Session Amnesia with Slot-Based Memory r/LLMDevs
Long-horizon agent stability is being redefined by 'slot-based' memory architectures that prevent the 'context rot' inherent in traditional recursive summarization. u/WeWinBro notes that what is often mistaken for model degradation is actually 'session amnesia' caused by losing track of repository state. By using hybrid stacks like Honcho for persistent user modeling and LanceDB for multi-project RAG, developers are achieving continuous runtimes exceeding 7 hours without the performance decay that typically consumes up to 40% of token budgets in large-scale sessions u/betozip.
Edge Reasoning and the 38T Token Frontier r/LocalLLaMA
New models like StepFun 3.7 Flash and Liquid AI’s LFM 2.5 are shattering local benchmarks, proving high-parameter MoE can thrive on consumer-pro silicon. Step 3.7 Flash recorded a 56.26% solve rate on SWE-Bench Pro, outperforming DeepSeek V4 Flash while running at 62.8 t/s on M5 Max hardware u/Beamsters. Meanwhile, Liquid AI’s architecture, trained on a massive 38T tokens, leverages a non-transformer design to prevent context rot across its 128K context window u/PauLabartaBajo.
Standardizing Context Containers r/ContextEngineering
MCPOrb introduces 'context containers' to combat agentic paralysis by standardizing how data is retrieved for 2-million token windows u/dqj1998.
Local Inference Hits 3,300 Tokens/Sec r/MachineLearning
A custom monokernel for the AMD MI300X maps memory patterns directly to the die topology to achieve 3,300 output tokens/s u/averne_.
Hardening the Agentic Supply Chain r/LLMDevs
'Prompt-as-a-Service' architectures and skill scanning via Pluto-Aguard are emerging to protect proprietary IP from indirect prompt injection u/__maximux.
Skill-Learning and the Browser Trust Gap r/ollama
Open-source browser agents are shifting toward 'skill-learning' by observation, though users remain hesitant to delegate high-stakes actions like reservation calls u/jasonhon2013.
Discord Developer Sync
OpenAI's Operator signals a pivot from tool-calling to true autonomous web navigation.
The agentic web is no longer a concept; it’s an active deployment zone. This week, OpenAI’s launch of Operator has fundamentally shifted the conversation from what models can say to what agents can do within the browser. By treating the DOM not just as text to be scraped but as a dynamic environment to be navigated, the new Computer-Using Agent (CUA) architecture aims for a 95% success rate that traditional automation wrappers simply could not touch.
But autonomy requires more than just a clever model; it demands infrastructure that can keep up. As Cerebras and Groq engage in a high-speed inference war—pushing up to 1,800 tokens per second—the reasoning overhead that once crippled agentic loops is evaporating. Meanwhile, developers are moving away from heavy, black-box frameworks in favor of type-safe minimalism like PydanticAI, ensuring that when an agent does take an action, it does so with 100% schema compliance.
Today we explore this convergence of browser-native autonomy, ultra-low latency, and the sobering reality of the SWE-bench Pro gap. For those building in the trenches, the message is clear: the bottleneck is moving from intelligence to execution speed and reliable state management.
OpenAI Operator and the Rise of the Computer-Using Agent (CUA)
OpenAI has officially launched Operator, a research preview for an AI agent capable of controlling a virtual browser to execute complex, multi-step workflows like travel booking and research HPCWire. Built on a specialized Computer-Using Agent (CUA) model, Operator utilizes a continuous perception-reasoning-action cycle to independently execute actions on the web Anchor.
This architecture allows it to handle UI drift and dynamic page changes with significantly higher reliability than traditional automation wrappers, as noted by agent_dev, who describes the system's DOM navigation as a potential game-changer for the industry. While internal goals aim for 95% success rates on common tasks, early benchmarks already show Operator outperforming competitors such as Google DeepMind’s Mariner and Anthropic’s Computer Use HPCWire.
By 2026, the ecosystem is expanding toward no-code platforms that allow small-to-medium enterprises (SMEs) to automate back-office work without dedicated engineering teams ACTGSYS. This shift toward a virtual-browser-first approach marks a pivot from simple LLM tool-calling to true autonomous web navigation Department of Product.
Join the discussion: discord.gg/openai
High-Speed Inference Wars: Cerebras and Groq Race for Agentic Dominance
The demand for low-latency inference is skyrocketing as agents move toward real-time interaction and multi-step reasoning. While Groq initially set the pace, Cerebras AI has recently claimed a new record, delivering over 1,800 tokens per second for Llama 3.1 8B—reportedly up to 2.5x faster than Groq's current offerings Cerebras AI. Community experts like infra_lead emphasize that latency is now the primary bottleneck for agentic performance, with a new industry standard emerging at sub-50ms per token to ensure that multi-step reasoning overhead doesn't break the user experience Fastio.
Join the discussion: discord.gg/cerebras
PydanticAI Challenges Heavyweight Frameworks with Type-Safe Minimalism
PydanticAI is rapidly gaining traction as a streamlined alternative to complex orchestration frameworks by prioritizing type safety and structured outputs. Built by the Pydantic team, the framework leverages Python type hints to ensure 100% schema compliance during tool-calling, a stark contrast to the heavyweight state-machine persistence of LangGraph Paul Simmering. According to framework_fan, its built-in support for dependency injection drastically simplifies the testing of autonomous systems by allowing developers to mock external services easily Finn Andersen.
Join the discussion: discord.gg/pydantic
SWE-bench Verified Scores Soar to 94% as Pro Benchmarks Expose Reasoning Gaps
SWE-bench Verified scores have reached a staggering 94%, yet the Pro version of the benchmark reveals massive remaining gaps in agent reasoning. While Claude Mythos Preview currently leads the human-validated subset, the community is pivoting toward SWE-bench Pro, where the highest performance sits at only 46% BenchLM. This divergence, discussed heavily in the frameworks-dev community, underscores the difference between resolving curated issues and navigating high-entropy, real-world production repositories Morph.
Join the discussion: discord.gg/swe-bench
LangGraph Reducer-Driven Schemas Harden Multi-Agent Handoffs
LangGraph's new reducer-driven schemas and checkpointers have reportedly led to a 30% reduction in boilerplate code for handling complex multi-agent handoffs Syed Muhammad Hassan.
Join the discussion: discord.gg/langchain
HITL Patterns Evolve for Autonomous Computer Use
Developer focus is shifting toward Confidence-Based Escalation models for computer-use agents, utilizing visual confirmation steps to maintain trust during high-risk autonomous actions Galileo.
Join the discussion: discord.gg/anthropic
HuggingFace Research Pulse
Hugging Face’s smolagents and the new MCP standard are finally killing the 'abstraction tax' of brittle tool calling.
We are witnessing the death of the 'abstraction tax.' For too long, agent developers have been trapped in 'JSON jail,' wrestling with brittle schemas and stateless tool-calling that breaks at the slightest hint of complexity. This week, the narrative shifted toward 'Code-as-Action.' Hugging Face’s release of smolagents isn't just another library; it's a minimalist manifesto—1,000 lines of code that prove Python-native execution is 30% more efficient than traditional tool calling.
But as the interface simplifies, the benchmarks are getting harder. New data from IBM and Artificial Analysis shows that even frontier models are failing more than 50% of enterprise IT tasks. We're moving past the 'vibe check' era. Whether it's NVIDIA's Holotron-12B pushing 8.9k tokens/s for real-time GUI navigation or the Model Context Protocol (MCP) becoming the industry's 'USB-C,' the focus has moved to throughput, reliability, and standardized context. In today’s issue, we break down how the agentic web is moving from fragile demos to stateful, code-centric systems that can actually survive the chaos of a production environment.
Hugging Face’s Code-Centric Pivot: Killing the 'Abstraction Tax'
Hugging Face is leading a 'Code-as-Action' (CodeAct) revolution with the launch of smolagents, a framework designed to help developers escape 'JSON jail.' By allowing agents to execute Python directly rather than wrestling with brittle schemas, the framework achieves the same results in 30% fewer LLM steps than traditional tool-calling architectures. This minimalist approach—clocking in at just 1,000 lines of code—is already yielding production-grade results, powering a 67% success rate on the GAIA benchmark.
The speed of this shift is best illustrated by Hugging Face’s recent open-source Deep Research implementation, which replicated proprietary search capabilities in just 24 hours. By leveraging the CodeAgent architecture, these systems can write and execute raw Python for data synthesis, moving beyond the monolithic, proprietary loops of OpenAI or Perplexity. This ecosystem is rapidly expanding with Tiny Agents, which allows developers to deploy MCP-powered agents in under 50 lines of code while integrating with secure, sandboxed execution environments like E2B.
While frameworks like LangGraph remain the standard for complex state-machine orchestration, the 'developer-first' simplicity of smolagents is increasingly favored for its seamless integration with the Hugging Face Hub. As the industry moves toward standardized protocols, the ability to pull or share specialized tools is consolidating this framework as the central repository for open-source agentic logic, prioritizing flexibility and self-correction to avoid vendor lock-in.
The Race for High-Throughput GUI Agents
The race for autonomous desktop navigation is shifting from accuracy-only to throughput-first, with new models like Holotron-12B achieving 2x higher throughput than previous generations. Developed by H Company and NVIDIA, the Holotron-12B model enables agents like Surfer-H to navigate complex UIs at 8.9k tokens/s, significantly reducing the latency gap that plagues general-purpose models. To validate these gains, the ScreenSuite framework has emerged as the definitive tool for measuring agent effectiveness in sandboxed, real-world interfaces like ScreenEnv.
Enterprise Reality Check: Benchmarking Industrial Failure
Enterprise reality is hitting agent developers hard as new specialized benchmarks reveal that even frontier models score below 50% on agentic IT tasks. Data from ITBench-AA reveals critical faults across SRE domains, while researchers using VAKRA have diagnosed an average of 5.3 failure modes per trace in long-horizon browser tasks. To combat these 'fatal' reasoning-action loops, frameworks like ServiceNow AI's EVA are shifting the focus toward conversational flow and latency rather than simple text accuracy.
The 'USB-C for AI' Standard
The Model Context Protocol (MCP) has effectively become the industry standard for resolving agentic tool-calling fragmentation, replacing brittle 'glue code' with a universal interface for context-aware workflows.
Hybrid Infrastructure and the 1M Token Context
Architectural design is shifting toward a tiered hierarchy where DeepSeek-V4 provides a one-million-token context window for massive 'active memory' while NVIDIA’s Nemotron-3 Nano handles local, multimodal edge inference.
Hermes 3 and Verifiable Vertical Logic
Nous Research has released Hermes 3, the first full-parameter fine-tune of Llama 3.1 405B, while Google’s EHR Navigator demonstrates a 35x acceleration in clinical study building via autonomous FHIR data navigation.
Lightweight Math and Open Notebook Reasoning
The Intel DeepMath project and Jupyter-Agent-2 are proving that lightweight agents can now navigate massive information spaces and execute code directly within computational notebooks for high-precision research.