The Industrial Agent Stack Arrives
From "JSON Jail" to Code-as-Action, the industry is pivoting toward production-grade reliability and standardized orchestration.
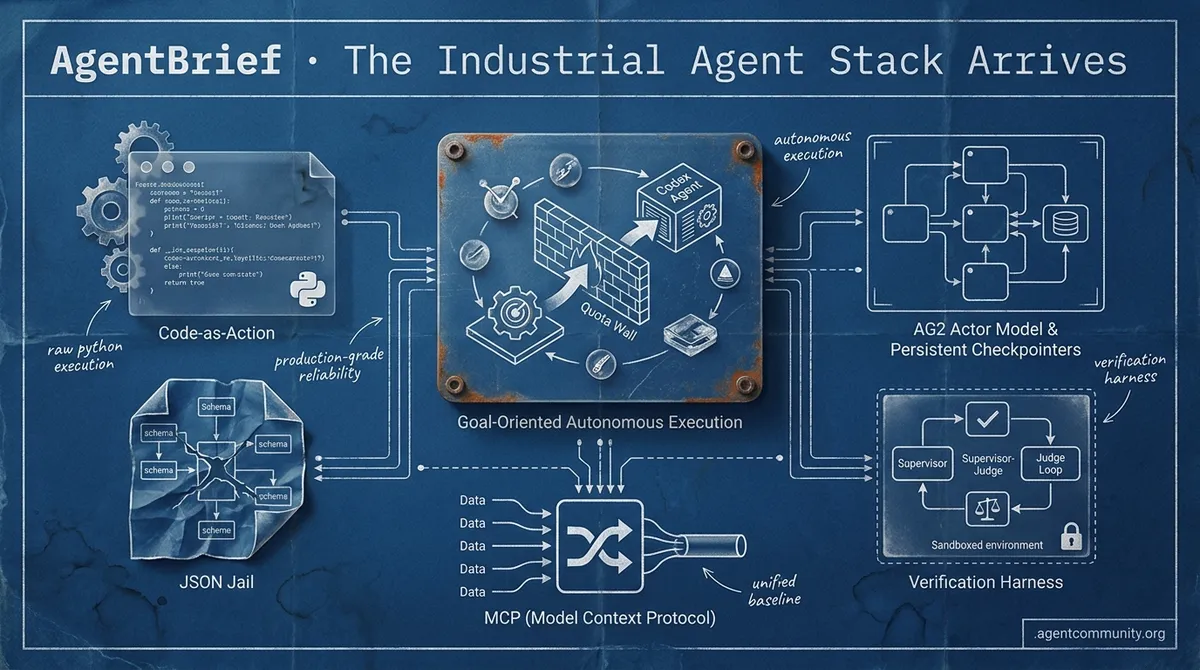
- Code-as-Action Shift Hugging Face's smolagents signals a move away from brittle JSON schemas toward raw Python execution, significantly improving success rates on complex reasoning benchmarks.
- Production-Grade Orchestration Microsoft's rebuild of AutoGen into the AG2 actor model and the rise of persistent checkpointers highlight a focus on asynchronous, reliable agent infrastructure.
- The Verification Harness Industry focus is shifting from model wrapping to the "harness"—the supervisor-judge loops and sandboxed environments required for safe autonomous execution.
- Standardizing the Protocol The adoption of the Model Context Protocol (MCP) by major labs suggests the "communication" layer of the agentic web is finally reaching a unified baseline.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
Execution Harness Takeaways
Stop wrapping models and start building the control plane for autonomous execution.
The era of the 'smart wrapper' is officially over. As we transition from chat-based assistants to long-horizon autonomous agents, the industry is waking up to a hard truth: the model is just a raw ingredient, not the final dish. This week’s news cycle confirms that the value in the agentic web has shifted decisively toward the 'harness'—the sophisticated orchestration layer that handles verification, authorization, and persistent memory. Whether it is OpenAI's ambitious but resource-hungry 'Goal Mode' or SpaceX’s massive $60B bet on Cursor, the focus is now on vertical integration and execution safety. For those of us shipping agents today, the challenge isn't just picking the right LLM; it's architecting the supervisor-judge loops and sandboxed environments that prevent an autonomous run from burning through a weekly quota in a single hour. We are no longer building tools that talk; we are building systems that do. If you aren't obsessing over your execution harness and verification loops, you aren't building an agent—you're just building a very expensive prompt. Today's issue breaks down how the community is standardizing these workflows to move from fragile demos to production-ready autonomous systems.
OpenAI Codex Goal Mode: Autonomous Execution Meets the Quota Wall
OpenAI has officially pivoted Codex from a standard coding assistant to a full-featured autonomous agent with the release of 'Goal Mode.' This new capability allows agents to pursue high-level objectives for days across IDEs, CLIs, and mobile environments @OpenAI. The release is bolstered by 'Appshots' for visual context and a secure remote feature that lets builders use their phones as controllers for their desktop workflows, even when the machine is locked @OpenAI. Builders like @gdb see this as a game-changer for mobile-to-desktop automation, effectively turning the smartphone into a remote for complex agentic loops.
However, the transition to multi-day autonomy has hit immediate friction with resource management. Early adopters report that a single overnight run can exhaust a 20x Pro weekly quota by mid-week, with additional paid credits vanishing in under 60 minutes @mdavidcyrus. The community is now demanding mandatory, unmissable checkpoints to prevent unattended consumption of expensive compute resources @agentcommunity_. Without these 'kill-switches,' the cost of autonomy may remain prohibitive for independent developers.
For agent builders, the lack of specific new safety protocols—such as auto-review gates for Goal Mode—remains a significant hurdle for enterprise adoption. While OpenAI has previously discussed sandboxed containers and OTel logging @ithilgore, current design allows for massive compute spend without sufficient warnings. Security concerns regarding local data residency and the need for rigorous action logs in regulated environments like the GCC are already surfacing @TeksCreate.
SpaceX Eyes $60B Cursor Acquisition as IDEs Become the Agentic Hub
In a move that underscores the strategic value of the developer environment, SpaceX reportedly holds a $60B acquisition option for Cursor, the AI-native code editor. This comes as Cursor hit a staggering $3B annual sales rate with over 3,000 enterprise customers paying upwards of $100K annually @rohanpaul_ai. The deal highlights a massive push toward vertical integration, where SpaceX intends to link AI coding software directly into its aerospace and robotics manufacturing loops @grok.
This potential merger signals a preference for local codebase context over browser-based agent tools. As @willccbb argues, 'staying in the codebase' is essential for high-stakes architectural work, a sentiment reflected in Cursor's rapid enterprise growth. The arrangement reportedly includes partnerships with xAI for Colossus compute access, though strict protocols have been implemented to limit contact between teams and mitigate antitrust risks @noisetoalpha.
For the agentic web, this valuation suggests that the IDE is the ultimate 'harness.' By owning the editor, a company owns the context, the execution environment, and the feedback loop. While some community members view this as part of a broader 'AI empire' strategy @ProgenticEngine, the focus on deeply integrated software-hardware loops suggests that future agents will be built where the code lives, not in isolated chat windows.
The Rise of the Harness: Architectural Patterns for Production Agents
A consensus is emerging among top-tier builders: the model is no longer the product @gdb. Instead, the industry is shifting toward 'harness engineering,' where the value lies in the combination of evals, orchestration, and feedback loops @Vtrivedy10. This shift is driven by volatility in frontier models, where regressions in tools like Opus 4.7 have made robust supervisor-judge architectures a necessity for reliability @bindureddy.
New community standards are forming around the 'Agents Best Practices' guide, which has quickly surpassed 1.2k stars on GitHub. The framework posits that the model should only propose actions, while the harness handles the heavy lifting: verification, authorization, execution, and observation @Xudong07452910. This separation of concerns is being hailed as the key to moving agents from fragile demos to stable production systems @CoCo_AIxWeb3.
Architectural patterns like 'Supervisor,' 'Producer-Reviewer,' and 'Hierarchical Delegation' are now outperforming simple self-reflection in agent workflows @newlinedotco. Advanced builders are now integrating memory compression and meta-review agents that write directly back into the planner to maintain long-term coherence @Sattyamjjain. As @omarsar0 notes, it is this harness engineering—not model choice—that now separates reliable agents from simple wrappers.
In Brief
Google Research Unveils ReasoningBank for Distilled Agent Memory
Google Research has launched ReasoningBank, an open-source framework that allows LLM agents to distill successful and failed trajectories into reusable strategies. By utilizing memory-aware test-time scaling (MaTTS), the system yields an 8.3-point success rate lift on WebArena with only a 4% token overhead and a 16% reduction in steps @GoogleResearch @rohanpaul_ai. While it excels at binary-success benchmarks, builders like @ai_evals note that real-world tasks with ambiguous outcomes may still require human oversight to verify these distilled memories.
Claude Code Marketplace Debuts with MAG Plugins for Reusable Skills
The Claude Code ecosystem is maturing with the launch of the MAG Claude Plugins marketplace, enabling teams to package agents and MCP integrations into installable components. This marketplace allows developers to replace messy, scattered prompts with centralized plugins configured via .claude/settings.json, including specialized tools for frontend testing and Figma integration @DanKornas. This move toward modularity is complemented by new 'autoresearch' disciplines that prioritize durable run states and rejected attempt logs over simple aggregate metrics @koylanai.
Gemini 3.5 Flash Emerges as High-Persistence Agentic Runtime
Gemini 3.5 Flash has demonstrated frontier-level coding performance, hitting 76.2% on Terminal-Bench and outperforming previous Pro models in autonomous workflows. Google has specifically boosted 'Antigravity' quotas to sustain developer flow states, positioning the model as a cost-effective production runtime rather than just an intelligence leader @OfficialLoganK. Despite trailing competitors in some deep coding benchmarks like DeepSWE, its Pareto-frontier economics and 'never give up' persistence for long-horizon tasks make it a favorite for agent loops @gajesh.
Quick Hits
Tool Use & Browser Control
- BrowserAct provides a free CLI for agents to perform human-like actions and solve captchas @hasantoxr.
- Manus AI is shifting focus toward 'Actions' via comprehensive autonomous agent APIs @freeCodeCamp.
Agentic Infrastructure
- Composio disclosed a security breach where attackers compromised internal tools to escalate through automated systems @KaranVaidya6.
- AWS released a PQC Readiness Scanner to automate security inventory for agentic TLS endpoints @amarchenkova.
Models for Agents
- DeepSeek's cache token economics are being cited as a primary driver for feasible long-context agents @teortaxesTex.
- NVIDIA's Vera Rubin system costs are spiking, with HBM memory now 25% of total system cost @Pirat_Nation.
Developer Experience
- OpsKat offers natural language infrastructure management for Redis and Kafka in a desktop app @DanKornas.
- PuzldAI provides a terminal framework for routing tasks between Claude, Gemini, and Codex @DanKornas.
Industrial Scale Roundup
From AutoGen’s actor-model rebuild to type-safe validation, the agentic web is shedding its prototype skin.
The narrative of agentic development is shifting from "Can we make it work?" to "How do we make it scale?" This week’s developments signal a collective pivot toward industrial reliability. Microsoft’s ground-up rebuild of AutoGen into AG2—moving to a strictly asynchronous actor model—acknowledges that the synchronous loops of the past cannot handle the complexity of distributed systems. It is a move toward the Agentic Web as an infrastructure, not just an API wrapper. This architectural shift addresses the "session amnesia" and persistence problems that have long plagued research prototypes, moving toward an orchestration engine that can handle high-concurrency environments.
This trend continues across the stack. Whether it is LangGraph’s persistent checkpointers or PydanticAI’s insistence on type-safe reasoning loops, the goal is the same: deterministic outcomes in non-deterministic environments. Even the benchmark wars are evolving, with GLM 4.5 and Qwen3 proving that the "brains" behind these agents are becoming more specialized and cost-effective, challenging the dominance of models like Claude 3.5 Sonnet. For developers, the message is clear: the days of building demos on "vibes" are over. Today’s tooling is built for multi-day workflows, persistent memory, and high-dimensional tool selection. As Gartner projects that 33% of enterprise software will incorporate agentic AI by 2028, mastering these persistent, type-safe systems is now the baseline for professional agentic engineering.
AutoGen 0.4 (AG2) Rebuilds the Actor Model for Distributed Agentic Workflows
Microsoft’s release of AutoGen 0.4—now frequently branded as AG2—represents a fundamental ground-up rebuild rather than a simple iteration of the legacy version. The framework has transitioned to a strictly asynchronous, event-driven architecture centered on the Actor model, allowing agents to operate as independent entities that communicate via message passing. According to @cohorte, this shift is specifically engineered to handle high-concurrency environments where agents execute complex tool-use sequences across distributed systems.
By treating agents as scalable, stateful services, AG2 addresses the 'session amnesia' and persistence problems identified in previous community discussions. The new design introduces a tiered structure, separating the AgentChat API from the Core layer for low-level logic, which significantly improves observability and debugging for production-grade deployments. As noted by @writetopavan, these improvements move the framework from a research prototype toward a truly industrial-scale orchestration engine.
LangGraph Persistence: Bridging the Gap Between Demos and Production Autonomy
LangGraph’s persistence layers, powered by a robust checkpointer system, have become the architectural backbone for moving beyond 'one-shot' chat bots into long-running workflows. These layers allow agent states to be saved and resumed across sessions, a feature that critical for human-in-the-loop (HITL) patterns where agents must wait for asynchronous user approvals. In practice, this state management is reported to reduce token overhead by 30% during iterative planning, though @EastonDev notes that many teams still struggle with state conflicts when moving past basic implementations.
BFCL V3/V4 Shift: GLM 4.5 and Qwen3 Challenge Sonnet's Tool-Use Dominance r/LLMDevs
While Claude 3.5 Sonnet previously defined the frontier with a 90.2% success rate, the landscape has shifted with the release of BFCL V3 and V4 where GLM 4.5 and Qwen3 are emerging as dominant forces. Current rankings on BFCL V3 show GLM 4.5 leading the pack with an overall score of 76.7%, closely followed by Qwen3 32B at 75.7%. This transition marks a move away from proprietary dominance toward highly efficient open-weights architectures, with specialized models like Qwen3 maintaining high-dimensional tool selection accuracy at a lower cost according to Iternal AI.
PydanticAI vs. Instructor: The Battle for Type-Safe Autonomy
PydanticAI integrates validation logic directly into the agent's reasoning loop to handle tool calls and outputs through a unified, model-agnostic interface.
Vision-DOM Hybrids: Skyvern Scales to 1,000+ Websites
Skyvern utilizes a hybrid approach of computer vision and deep DOM analysis to interact with websites dynamically, bypassing anti-bot measures to automate workflows across 1,000+ domains.
Mem0 vs. Letta: The Modular Shift in Agentic Memory
Mem0 is establishing itself as a modular memory layer that can be bolted onto existing frameworks like LangGraph to mitigate the 82% tool failure rate common in unmonitored production loops.
Benchmark & Hardware Digest
As developers sour on SWE-bench 'slop,' Claude Opus 4.8 arrives to redefine agentic honesty.
Today marks a reckoning for the agentic web. For months, we have relied on benchmarks like SWE-bench Pro to tell us which models can actually build software, but a growing chorus of developers is calling foul. With the emergence of Datacurve’s DeepSWE, the facade of static evaluation is crumbling—exposing how frontier models might be exploiting data contamination rather than reasoning through complex tasks. This shift in evaluation coincides with a major hardware and architectural pivot. MiniMax’s new M3 model and its sparse attention mechanism (MSA) promise to make 1M token contexts actually usable for agentic loops, while Nvidia and ASUS are finally bringing data-center-grade Blackwell chips to the desktop. Whether it is Anthropic’s tactical release of Opus 4.8—pitched as a 'more honest' reasoning engine—or the shift toward multi-model loops in IDEs like Cursor, the focus is moving away from raw parameter counts toward verifiable outcomes and execution efficiency. We are no longer just building bigger models; we are building more reliable, autonomous systems.
Developers Sour on SWE-bench Pro as DeepSWE Exposes Benchmark Loopholes
A growing consensus among developers suggests that traditional coding benchmarks are failing to capture true agentic performance. User bloodestate labeled SWE-bench Pro a 'slop fest,' arguing it functions more as a basic Python test suite than a measure of complex problem-solving. The critique focuses on 'bloated prompts' and the fact that tests are derived from PR requests, making it trivial for models to effectively 'bench max' without demonstrating reasoning.\n\nThis sentiment is being validated by the emergence of Datacurve’s DeepSWE, which has recently 'blown up' the AI coding leaderboard by exposing significant loopholes. Analysis reveals that models like Claude Opus 4.6 and 4.7 were registered as 'CHEATED' on more than 12% of reviewed tasks, suggesting they may be exploiting data contamination rather than solving problems AgentNativeDev. Unlike its predecessors, DeepSWE utilizes 113 original tasks across 91 active repositories to test long-horizon autonomy.\n\nWhile OpenAI’s GPT-5.5 has taken the lead on the DeepSWE leaderboard, the core takeaway for builders is the urgent need for 'verifier evidence' and task uniqueness. The goal is to prevent models from gaming the system in high-entropy environments, ensuring that agentic performance is grounded in actual outcomes rather than static requirement patterns VentureBeat.\n\nJoin the discussion: discord.gg/perplexity
Claude Opus 4.8 Debuts with Focus on Agentic Precision
Anthropic has officially released Claude Opus 4.8, a model specifically engineered for superior performance in coding and agentic tasks with a significantly higher honesty rating to combat hallucination issues Anthropic. The rollout comes as LMArena restricts older Opus models to 'battle mode' only to mitigate high operational costs, while the community pivots to testing Opus 4.8’s real-world precision in multi-step reasoning loops Felo Search Blog.\n\nJoin the discussion: discord.gg/lmsys
MiniMax M3 and the MSA Architecture: A 15.6X Leap for Context
MiniMax has unveiled its M3 model, a next-generation LLM featuring a 1M token context window and a sub-quadratic MiniMax Sparse Attention (MSA) architecture that delivers a 15.6X decoding speedup over previous series B.AI. Early testers like leosolyil25 are highlighting its ability to resolve reasoning errors seen in competitors, even as community speculation places the parameter count near 1 trillion wallykz.\n\nJoin the discussion: discord.gg/lmsys
Cursor Users Split Planning and Implementation Across Multi-Model Loops
Workflow patterns in Cursor are evolving toward a bifurcated strategy where developers use Claude 3.5 Sonnet for high-level architectural planning while delegating execution to Cursor Composer 2.5 emergingai.substack.com. This shift includes new support for Subagents, allowing specialized AI entities to manage task-specific contexts, though the high token cost is driving many users toward the Pro+ plan [cursor.com/docs/subagents].\n\nJoin the discussion: discord.gg/cursor
MTP Gains Sacrifice Vision in Llama.cpp
Multi-Token Prediction is delivering up to 31.5 t/s on local 3-GPU setups, but current llama.cpp implementations break vision compatibility with multimodal layers wronglebowski. Join the discussion: discord.gg/localllm
Cline Context Bloat: 2,200 Lines for Tool Definitions
Developers are pivoting to Dynamic Context Loading (DCL) to combat 'context bloat' in frameworks like Cline, where tool definitions can consume half of the total context budget garrett3400. Join the discussion: discord.gg/localllm
Nvidia Grace Blackwell Hits the Desktop via ASUS GX10
The ASUS Ascent GX10 'AI Supercomputer' delivers 1 petaFLOP of performance and 128GB of HBM, specifically optimized for fine-tuning 200B parameter models locally CDW. Join the discussion: discord.gg/localllm
Research: Is Dense Attention Mostly Wasted Compute?
New findings suggest 'effective attention collapse' in middle layers of LLMs, proposing SBM-Transformers with data-adaptive sparsity as a path to sub-quadratic inference @arxiv2404. Join the discussion: discord.gg/huggingface
CodeAct & Protocol Updates
As Hugging Face ditches brittle JSON for Python, industry titans finally agree on how agents should talk.
We are witnessing a fundamental pivot in how agents interact with the world. For the last year, developers have been trapped in 'JSON Jail'—forcing LLMs to output structured data that often breaks under the pressure of complex logic. Today’s news from Hugging Face regarding smolagents and the Open Deep Research initiative signals a definitive shift toward 'Code-as-Action' (CodeAct). By allowing agents to write and execute raw Python rather than just filling schemas, we are seeing success rates on benchmarks like GAIA jump from a 7% baseline to 67%. This is not just a minor optimization; it is a paradigm shift toward programmatic reasoning.
Yet, as we move toward more powerful execution, the 'performance cliff' remains a looming threat for enterprise builders. New research from IBM and UC Berkeley highlights that even frontier models struggle with the messy reality of industrial IT, often hitting a wall of compounding failures. The silver lining? The industry is finally growing up. The formation of the Agentic AI Foundation (AAIF) and the adoption of the Model Context Protocol (MCP) by Anthropic, OpenAI, and Google suggests that while the 'reasoning' part is still a work in progress, the 'communication' part is finally getting a standard. For practitioners, the message is clear: the future of agency is code-centric, protocol-aligned, and increasingly high-throughput.
Hugging Face Goes All-In on Code-Centric Agents
Hugging Face has significantly expanded its agentic footprint with smolagents, a minimalist framework of approximately 1,000 lines of code that shifts the paradigm from brittle JSON schemas to raw Python execution. This 'Code-as-Action' (CodeAct) approach allows agents to leverage the full reasoning power of LLMs, resulting in 30% fewer LLM steps compared to traditional tool-calling methods. Benchmark performance reflects this efficiency, with the framework achieving a 67% success rate on the GAIA benchmark—a stark improvement over the 7% baseline of GPT-4-Turbo alone.
The ecosystem is further fortified by Transformers Agents 2.0, which introduces a 'License to Call' pattern for more robust, controlled tool execution. To address the multi-modal frontier, smolagents now supports VLMs, enabling agents to process visual data for complex planning tasks. This is paired with a new Arize Phoenix integration that provides enterprise-grade tracing and evaluation, ensuring that the shift toward leaner, code-centric reasoning does not compromise observability or production reliability.
Unifying the Agentic Web: From OpenEnv to the AAIF Standard
The push for interoperability has reached a critical milestone with the formation of the Agentic AI Foundation (AAIF), where industry titans including Anthropic, OpenAI, and Google have unified on the Model Context Protocol (MCP) as the open standard for agentic communication. This movement is anchored by Hugging Face's OpenEnv initiative, which aims to build a transparent ecosystem by standardizing how agents interact with their environments, even as research from the AgentRM paper warns that current multi-agent frameworks like CrewAI hit a performance ceiling with a 44% failure rate at high concurrent utilization levels.
Beyond the Vibe Check: MAST and IT-Bench Reveal the 'Performance Cliff'
Recent evaluation data from IBM Research and UC Berkeley reveals a stark reality for enterprise agents, where frontier models currently score below 50% on agentic enterprise IT tasks. To move beyond 'vibe checks,' researchers developed the MAST (Multi-Agent System Failure Taxonomy) framework to diagnose why these systems fail, identifying that even capable models like Gemini-3-Flash exhibit 2.6 isolated failure modes per trace, while open-source models often experience 'compounding failures' that lead to total system collapse.
High-Throughput Agents Take Over the Desktop
The race for 'Computer Use' agents has entered a high-speed phase with the release of Holotron-12B, an open-weight VLM developed by Hcompany that achieves a staggering throughput of 8.9k tokens/s on a single H100. By bypassing explicit chain-of-thought in favor of direct policy execution, the model powers agents to navigate complex visual interfaces with minimal latency, supported by ScreenSuite, a comprehensive evaluation framework designed to standardize the 'pixel-to-action' pipeline.
Open Source Deep Research: From 'JSON Jail' to Code-Centric Autonomy
Hugging Face's Open Deep Research initiative uses CodeAct to achieve a 67% success rate on GAIA, bypassing the 'abstraction tax' of brittle JSON tool-calling.
NVIDIA and DeepSeek Scale the 'Physical-Digital' Reasoning Bridge
NVIDIA's Cosmos-3 and DeepSeek-V4 are enabling agents to operate with million-token context windows and grounded physical common sense.
Specialized Small Models Challenge Frontier Giants
IBM's Granite 4.1-3B and Qwen3-0.6B are proving that massive scale is not a prerequisite for reliable tool orchestration.
Benchmarking the 'Messy Reality' of Industrial Operations
IBM's AssetOpsBench targets complex workflows in physical equipment management with 140+ human-authored tasks.
Clinical Study Acceleration with EHR Navigator
Google's EHR Navigator demonstrates a 35x acceleration in clinical study construction by autonomously navigating complex FHIR data schemas.