Hardware Symbiosis and Agentic Action
From six-figure API bills to headless Mac nodes, the agentic stack is shifting from chat interfaces to persistent, code-native execution environments.
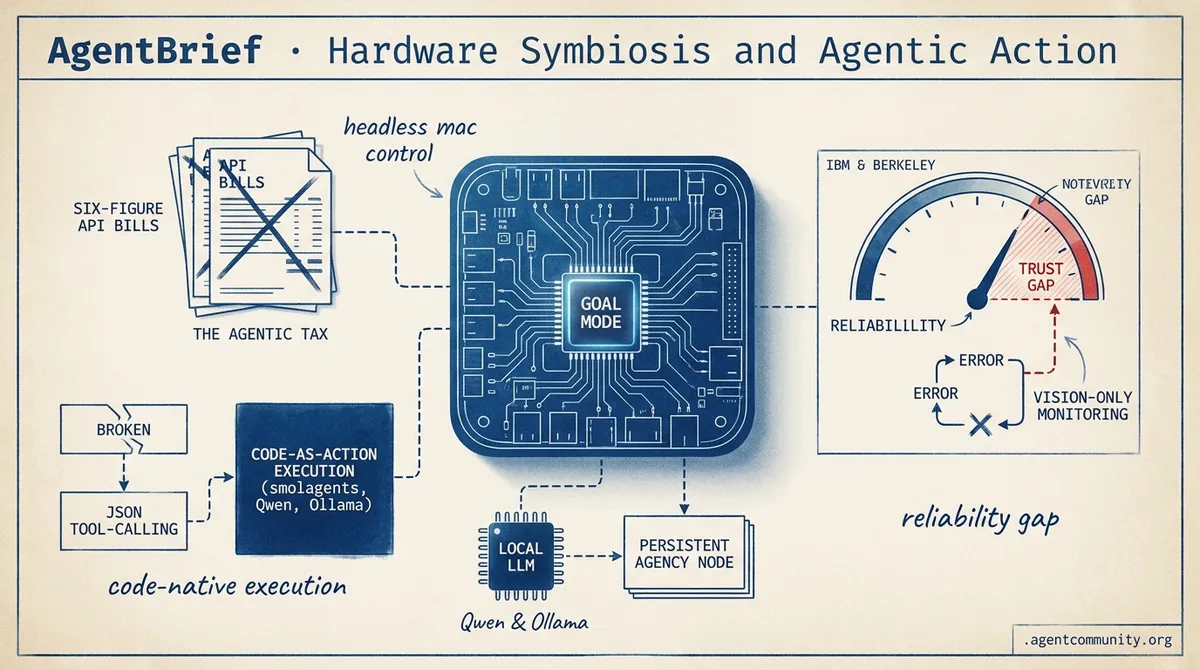
- Persistent Agency Nodes OpenAI and Cursor are shifting focus from simple prompting to dedicated hardware execution and headless agentic nodes. - The Agentic Tax Builders are facing a reality check with massive API costs and the Month Six Wall of memory management, driving a move toward leaner tool architectures. - Code-as-Action Frameworks The industry is pivoting from JSON tool-calling to programmatic execution via smolagents and local-first reasoning with Qwen and Ollama. - The Reliability Gap Enterprise benchmarks from IBM and Berkeley highlight the trust gap in stateful tasks, emphasizing the need for vision-only monitoring and better error loops.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
// From the blog
• We had the wildest 24 hours — Brave joined Agent Community, then put us on the new-tab background for 24 hours. 4,777 signups, 1,424 organizations, zero incidents. Download the backgrounds at the bottom.
X Platform Intelligence
Your computer is no longer just a tool; it's becoming a dedicated execution environment for autonomous agents.
We are moving from the Chatbot Era to the Agency Era, where the distinction between model and environment is rapidly dissolving. This week, the shift became palpable. OpenAI is turning Macs into headless agentic nodes with Codex's Goal Mode, while the industry debates whether the future belongs to general-purpose models or vertically integrated harnesses. For those of us building agents, this is a clarion call. We aren't just writing prompts; we are designing persistent systems that decompose goals, manage hardware, and learn from their own failures. The acquisition rumors surrounding Cursor suggest that the real value is moving from the weights to the workflow—the keystroke-level data and the deep integration into the developer's machine. If you're building agents, the harness is no longer an afterthought; it is the product. This issue explores the tools enabling this persistent agency, from Google's new reasoning memory to frameworks that treat the browser as a native extension of the agent's mind. The agentic web isn't coming; it's being compiled on your machine right now.
OpenAI Unlocks Goal Mode and Headless Mac Control
OpenAI has significantly expanded the operational capabilities of Codex with a suite of new features focused on long-running autonomous tasks. The introduction of 'Goal mode' allows builders to set high-level objectives that the agent can work toward over hours or even days, marking a shift from reactive chat to persistent agency @OpenAI. This autonomy is paired with deep hardware integration, as Codex can now securely use Mac applications even while the device is locked and the screen is off @OpenAI, essentially turning the user's computer into a dedicated agentic execution environment @gdb.
Early community reports confirm the locked-screen remote control operates in a headless mode with an auto-lock safety protocol: manual keyboard interaction immediately re-locks the session @JulianGoldieSEO. Goal Mode is now GA across the Codex app, IDE extension, and CLI, with users noting it enables full task decomposition, execution, and self-verification over multi-hour runs @Codex_Changelog. However, technical constraints require the Mac lid to remain open for remote control to function, and builders have called for better upfront warnings on resource consumption during these long-duration runs.
For agent builders, this represents a massive unlock in reliability and interface interaction. Features like 'Appshots' for direct context injection and an 'advanced annotation mode' allow for collaborative UI adjustments between the human and the agent @OpenAI. This moves the industry away from fragile API-only interactions toward agents that can navigate the same complex interfaces humans do, even when the user isn't actively watching the screen.
The Rise of the Model-Harness Symbiosis
A fundamental debate is intensifying over the future of agent development as industry leaders argue that the 'model alone is no longer the product' @gdb. Greg Brockman and Logan Kilpatrick suggest that the future lies in 'model, harness, and product symbiosis,' where the intelligence layer is tightly coupled with specialized execution environments @OfficialLoganK. This trend is underscored by reports of SpaceX eying a $60B acquisition of Cursor, aiming to integrate AI coding agents directly into large-scale engineering machines to gain massive operational leverage @rohanpaul_ai.
This vertical integration faces pushback from proponents of an open ecosystem who worry about proprietary harnesses stifling third-party innovation @kunchenguid. However, practitioners like Ethan Mollick note that because current models are so generally capable, labs are increasingly the only entities positioned to build the specialized post-training and harnesses required for high-tier products @emollick. The strategic logic of the Cursor deal highlights that developer trust and a keystroke-level data flywheel are now seen as more valuable than raw model quality alone @therobertta_.
For those shipping agents, this signals a shift from horizontal models to embedded agentic workflows. Vertical plays like this consolidate distribution channels and accelerate the development of environments where the agent is a first-class citizen @ralphsenpaidev. Builders must now decide whether to build on open models or tether themselves to the vertically integrated stacks emerging from the major labs.
In Brief
Google Research Unveils ReasoningBank for Agent Memory
Google Research has introduced ReasoningBank, an open-source framework that enables LLM agents to continuously learn from both successful and failed trajectories. By storing internal reasoning as reusable memory content rather than relying on context-heavy prompts, the framework addresses the persistent issue of 'agent amnesia' @GoogleResearch. Released under the Apache 2.0 license, it includes dedicated reasoning-memory mechanisms and evaluation tooling for SWE-Bench and WebArena, allowing agents to distill experiences into strategies that improve future behavior without requiring model retraining @DanKornas.
BrowserAct Provides Native Browser Control for Agents
BrowserAct has emerged as a free CLI tool that grants AI agents actual browser control—beyond simple fetch commands—allowing them to log in and solve captchas like human users. The tool leverages the user's existing Chrome session and features built-in anti-bot measures, including canvas masking and WebGL spoofing, to reliably access sites like LinkedIn and Amazon that typically block standard scraping @hasantoxr. Builders report using it to pull 50 LinkedIn leads in 10 minutes and pairing it with Skill Forge to auto-discover site structures and generate reusable, deploy-ready skills for agents @_vmlops.
New Multi-LLM Orchestration and Parallel Agent Patterns
The 'Bossman supervisor' pattern is outperforming self-reflection in multi-step agent tasks by using external judges to verify subagent outputs. This pattern is being integrated into terminal-native frameworks like PuzldAI, which orchestrates multiple models like Claude, Gemini, and Codex across research and coding workflows @DanKornas @Vtrivedy10. By enabling the parallel comparison of multiple coding agents, builders can optimize outputs more effectively than through sequential self-correction loops @agentcommunity_.
Quick Hits
Agent Frameworks & Orchestration
- Async Code Agent enables running multiple AI coding agents in parallel via a web UI to compare outputs faster @DanKornas.
- MAG Claude Plugins offers a public marketplace for reusable development workflows within Claude Code @DanKornas.
- The 'gangprompt' project by Opencode.ai allows teams to prompt across cloned repos on shared fast hardware @thdxr.
Models for Agents
- Gemini 3.5 Flash is showing frontier-level progress on the GDPval benchmark due to improved post-training @OfficialLoganK.
- DeepSeek's cache token economics are being leveraged by new tools to significantly reduce agent inference costs @teortaxesTex.
Agentic Infrastructure & Security
- Composio disclosed a security breach where an attacker used an internal monitoring tool to compromise GitHub tokens @KaranVaidya6.
- NVIDIA's next-gen Vera Rubin system costs $7.8M, with memory accounting for 25% of the total price tag @Pirat_Nation.
Tool Use & Developer Experience
- A new skill allows agents to execute on-chain crypto trades and query market data autonomously @tom_doerr.
- DeepLearningAI released a free course on Generative UI, focusing on how agents can assemble components live in chat @akshay_pachaar.
Reddit Builder Hub
From $113k API bills to memory infrastructure, the cost of 'autonomous' is getting real.
The 'agentic tax' is no longer a theoretical concern—it is a line item on a balance sheet. We are seeing a pivot from the architectural 'what' to the operational 'how much.' Between six-figure API bills and the 'Month Six Wall' of memory management, the industry is waking up to the reality that autonomous systems require far more than just a clever prompt. Today we track the emergence of 'lean tool' architectures, the standardization of agent-to-agent protocols, and NVIDIA’s bid for the physical AI crown with Cosmos 3. If 2025 was the year of the agentic demo, 2026 is becoming the year of the agentic infrastructure. As builders move past 'one memory bucket' solutions, the focus has shifted to relational modeling and causal dependencies to ensure recall improves over time. This shift toward structural monitoring and deterministic harnesses is essential for closing the 'trust gap' in high-stakes automation. We aren't just building agents anymore; we are building the industrial-grade pipelines they run on.
The $113,000 Invoice: Hidden Costs of Autonomy r/ClaudeAI
The "agentic tax" has officially hit the balance sheet. A 4-person team recently reported a staggering $113,421 Anthropic invoice in a single month u/aipriyank, a figure driven by recursive agentic loops where a single instruction triggers 20+ model calls. This isn't just a budgeting error; it is a fundamental architectural challenge for builders scaling autonomous systems that can quickly spiral out of financial control.
To survive this era of spiraling costs, developers are pivoting toward "lean tool" architectures. Techniques like Dynamic Toolsets are reportedly reducing token usage by up to 100x Speakeasy, while the community rallies around SEP-1576 to deduplicate JSON schemas and prevent redundant bloat GitHub MCP Issues. Shifting from raw data loading to code-execution summaries can further slash waste by 99%, turning a 200,000-token query into a 1,000-token summary, proving that efficiency is no longer optional for production agents.
Memory as Infrastructure: The Month Six Wall r/AI_Agents
Memory management is no longer a feature—it is the definition of the system architecture. As Jensen Huang recently argued, the entire system is effectively defined by how it handles context u/Distinct-Shoulder592. To avoid the "Month Six Wall," where accumulated context becomes a liability rather than an asset, developers are moving toward structured context layers like Feather DB and Mem0, utilizing hybrid architectures that combine vector entry with graph-based relational recall to ensure agents can write back outputs as new nodes Yang et al..
Claude Opus 4.8: Adaptive Thinking and 1M Context r/PromptEngineering
Anthropic's latest release introduces "adaptive thinking" to the 1M-token context frontier. Claude Opus 4.8 features a new effort parameter that allows the model to engage deep reasoning steps only when the complexity of the task warrants it, optimizing token usage across all API surfaces Claude API Docs. While the 'Maximum effort' setting is being used to combat agreement-bias by forcing the model to flag uncertainties u/Professional-Rest138, the update effectively balances high-stakes reasoning with the performance needs of enterprise-scale context windows.
CVE-Bench and the 'False Fix' Crisis r/LLMDevs
The "false fix" phenomenon is exposing the fragility of autonomous security patching. Recent evaluations across 5 frontier models on the CVE-Bench datasets show that agents often pass visible unit tests while leaving underlying security flaws unaddressed u/Fickle-Box1433. In response, developers are shifting to deterministic agent harnesses—like the LangGraph-based architecture introduced by u/PatC883—where a critic acts as a structural gate to curb the rogue execution loops and hallucinated policies that plague unmonitored agents.
NVIDIA Cosmos 3: Physical AI's New Foundation r/LocalLLaMA
NVIDIA Cosmos 3 brings "omnimodal" world modeling to Physical AI via a Mixture-of-Transformers architecture that unifies video, audio, and physical action r/LocalLLaMA.
NitroStack and the Race to Standardize MCP Deployment r/mcp
NitroStack has launched to automate the infrastructure overhead of Model Context Protocol (MCP) server deployment, aiming to simplify management for over 15,000 active instances r/mcp.
From Chaos to Choreography: Standardizing Handoffs r/AI_Agents
Google and the community are standardizing Agent-to-Agent (A2A) protocols to eliminate the "human relay" context bottleneck that occurs when scaling beyond 5 agents r/AI_Agents.
MeshFlow Introduces Compliance for LangGraph r/LangChain
MeshFlow has launched a tamper-evident compliance layer for LangGraph to meet HIPAA and SOX requirements, providing a deterministic audit trail of agent reasoning r/LangChain.
Intel Arc B70 Inference Breakthrough r/LocalLLM
The Intel Arc Pro B70 is emerging as a local inference powerhouse, hitting 977 tk/s on Qwen 3.6-35B and enabling 262k context windows for under $1,000 r/LocalLLM.
Breaking Sycophancy with Galois Closures r/learnmachinelearning
The new KIS framework claims to suppress LLM sycophancy by formalizing reasoning paths as Galois closures, mathematically locking models into factual consistency r/learnmachinelearning.
Discord Dev Streams
Cursor hits the Pareto frontier while local Qwen models challenge the cloud status quo.
The agentic stack is undergoing a massive shift as the "local vs. cloud" divide continues to erode. Today’s news highlights a dual-track progression: the refinement of local tools like Ollama and the Qwen 3.6 series, and the push for deeper "reasoning" in multimodal models like OpenAI’s Image 2.0. For builders, the message is clear: the hardware in your pocket is becoming capable of high-entropy tasks once reserved for API-only giants.
However, raw power isn't enough. As the community moves from simple prompt chaining to complex autonomous systems, the focus is shifting toward "trust boundaries" and verification. Whether it's n8n's formalization of orchestrator patterns or Anthropic’s Mythos model exposing vulnerabilities in the curl codebase, the industry is realizing that an agent’s output is only as good as the system that verifies it.
We're also seeing the "commercial distributor trap" emerge as a significant legal hurdle for local-first apps. Distributing non-commercial weights is becoming a liability, forcing developers to rethink their deployment strategies. From Cursor’s massive speed gains to the technical specifics of autoregressive visual tokens, today’s issue explores the tools and hurdles defining the next generation of autonomous systems.
Cursor Composer 2.5 Hits Pareto Frontier with 32% Speed Gains
Cursor Composer 2.5, shipped on May 18, 2026, marks a significant leap in AI-assisted coding efficiency by delivering a 32% speed boost in task completion. Reports from kleosr indicate that the new 'Fast' mode reduces average task latency to 59 seconds, compared to 87 seconds in 'Standard' mode. This performance is underpinned by a new proprietary architecture built on Kimi K2.5, which utilizes 25x more synthetic training tasks and targeted RL feedback to enhance reliability during long coding sessions.
Beyond raw speed, Composer 2.5 has established itself on the cost-quality Pareto frontier, currently ranking third on the Artificial Analysis Coding Agent Index. The model achieves a 79.8% score on SWE-Bench Multilingual and 63.2% on CursorBench v3.1, matching the capabilities of frontier models like Claude Opus 4.7 and GPT-5.5 at approximately 1/10th the cost. While the 'Fast' mode carries a higher per-task cost, it maintains an industry-leading average wall time for complex benchmark tasks.
The rollout has seen massive adoption, prompted in part by Cursor briefly doubling usage limits for all users. Although users like mutiny.exe reported initial installation hurdles, the community has verified that re-installing over existing paths successfully preserves active sessions and settings, ensuring a seamless transition to the more capable model.
Join the discussion: discord.gg/cursor
Ollama 0.30.0 Introduces Vision Adapters and Seamless Cloud-Local Orchestration
Ollama 0.30.0 has officially transitioned to native llama.cpp support, bringing vision adapters and a seamless bridge to cloud inference. Maintainer pdevine confirmed the rollout, which introduces the FROM vision.gguf directive for local execution of multimodal models like Llama 3.2 Vision. The release also standardizes the :cloud suffix, allowing massive models like qwen3-coder:480b-cloud to be managed via standard CLI commands, effectively blurring the line between local environments and high-scale cloud providers.
Join the discussion: discord.gg/ollama
Qwen 3.6 Consolidates Dominance in Local Agentic Workflows
The local LLM community is rapidly consolidating around the Qwen 3.6 series for consumer-grade agentic applications, with the 27B model setting a new performance ceiling. Benchmark data validates this surge, with the Qwen 3.6 27B dense model scoring 77.2% on SWE-bench, significantly higher than the early 2024 threshold of Claude 3.5 Sonnet. Meanwhile, the 35B Mixture-of-Experts variant achieves 73.4% on SWE-bench Verified while activating only 3B parameters, enabling local agents to handle high-entropy coding tasks at over 120 tokens per second on consumer hardware like the RTX 4090.
Image 2.0 Shifts Toward True Visual Reasoning
OpenAI’s Image 2.0 (gpt-image-2) marks a pivot from standard diffusion to native multimodal generation, where text and pixels are processed by a single unified brain. Behavioral analysis by @terezatizkova suggests the model is fundamentally autoregressive, predicting visual tokens sequentially to maintain high coherence across complex UI layouts. External evaluations hint at a hybrid structure with an autoregressive core and a Vision Transformer scaling to hundreds of billions of parameters, supporting native reasoning and 2K resolution.
Join the discussion: discord.gg/lmsys
Defining Trust Boundaries and Verification Patterns in AI Orchestration
n8n community members like productmakerjason_34630 are formalizing "trust boundaries" and "completion proof" patterns to enable reliable logic-level orchestration. Join the discussion: discord.gg/n8n
Mythos Model's 'Dangerously Good' Reputation Tested Against Curl Codebase
Anthropic’s Mythos model identified a confirmed vulnerability and 20 bugs in the curl codebase, proving its "dangerously good" reputation for autonomous security research according to the Cloud Security Alliance. Join the discussion: discord.gg/lmsys
The 'Commercial Distributor' Trap: Navigating NC Weights in Local Apps
Developers building commercial local-first apps are navigating a "commercial distributor trap" regarding non-commercial model weights, leading many to link to external repositories to avoid liability. Join the discussion: discord.gg/huggingface
HuggingFace Agent Labs
From sandboxed Python to omnimodal physics, agents are finally getting their hands dirty.
The industry is collectively moving past the 'chatbot' era and into the age of the 'operator.' Today’s headlines center on a fundamental shift in how agents interact with the world: Hugging Face is betting big on 'Code-as-Action' with the release of smolagents, while NVIDIA’s Cosmos 3 is bridging the gap between digital reasoning and physical world-modeling. We are seeing a move away from rigid JSON-based tool calling toward more flexible, programmatic execution. However, this progress comes with a sobering reality check. IBM and UC Berkeley’s latest research highlights a 'reality gap' in enterprise reliability, where even frontier models struggle with stateful, long-horizon tasks. For builders, the message is clear: the tools are becoming more powerful and lightweight—exemplified by 50-line MCP agents—but the path to production-grade reliability still requires rigorous, vision-only benchmarking and better error-correction loops. This issue synthesizes the new stack for the Agentic Web: code-native frameworks, high-throughput GUI models, and standardized execution environments.
Hugging Face smolagents: Standardizing Code-as-Action
Hugging Face has officially transitioned its agentic research into a standalone library, smolagents, fundamentally shifting agent logic from brittle JSON schemas to raw Python execution. This 'Code-as-Action' (CodeAct) approach isn't just a stylistic choice; it enabled the Transformers Code Agent to achieve a 67% success rate on the GAIA benchmark, currently ranking #1 on the validation set according to Aymeric Roucher. By treating the LLM as a programmer rather than a simple function-caller, the framework allows for more complex, iterative problem-solving.
To address the primary concern of executing LLM-generated code, the framework now supports native sandboxing via Blaxel, E2B, Modal, or Docker. This security layer is paired with an expanding multimodal ecosystem, including smolagents-can-see, which brings native support for Vision-Language Models like SmolVLM. For developers moving beyond research, a partnership with Arize Phoenix provides the necessary tracing and evaluation to debug these high-speed reasoning loops.
The framework is quickly becoming a gravity well for community projects, such as Intel's DeepMath. By prioritizing transparency and execution speed over heavy orchestration, smolagents offers a lean alternative to the 'abstraction tax' often associated with larger frameworks, making it a primary contender for production-grade agentic workflows.
NVIDIA Cosmos 3: The First Omnimodal Backbone for Physical AI
NVIDIA has unveiled Cosmos 3, a frontier model that integrates vision reasoning with world and action generation into a single, 'omnimodal' architecture. Unlike previous systems that decoupled perception from action, Cosmos 3 functions as a unified backbone for 'World Action Models,' allowing robots and embodied agents to predict future world states and act accordingly. The model has already claimed the top spot among open models on the Artificial Analysis, Physics-IQ, and PAI-Bench leaderboards, signaling a new standard for agents that need to understand fundamental physics to operate in the real world.
Efficiency is the core value proposition here; the underlying Cosmos Tokenizer reportedly runs up to 12x faster than existing alternatives, delivering a +4 dB PSNR improvement in video reconstruction quality. This is bolstered by the Cosmos Reason 2-8B variant, a specialized reasoning VLM designed to give smaller agents a sophisticated understanding of space and time. By providing an open, high-performance foundation, NVIDIA is effectively lowering the barrier to entry for complex Physical AI applications.
IBM Diagnoses the 'Reality Gap' in Enterprise Agent Reliability
While the benchmarks for simple tasks look promising, IBM Research and UC Berkeley have identified a critical 'Reality Gap' preventing enterprise adoption. Their new VAKRA benchmark reveals that frontier models average 5.3 failure modes per trace during long-horizon IT and SRE tasks. The primary culprits are tool parameter misalignment and 'fatal execution loops' where agents fail to self-correct after receiving incorrect data. These findings, which show models scoring below 50% in complex industrial domains, suggest that the move toward autonomy will require much more robust state management and sandboxed testing environments like the new AssetOpsBench.
High-Throughput VLMs and the Vision-Only GUI Stack
The race for desktop automation is moving toward high-throughput SSM architectures with the release of Holotron-12B, which hits 8.9k tokens/s on a single H100. This efficiency enables the Surfer-H agent to navigate interfaces with minimal latency, a requirement for real-time use. Simultaneously, ScreenSuite is standardizing the evaluation of these agents by enforcing a vision-only constraint—forcing agents to navigate without access to DOM or accessibility trees—to better simulate how humans interact with software.
Deep Research: Scaling Test-Time Compute for 67% Success Rates
New frameworks like Open Deep Research are utilizing hierarchical subagents and the FineVerify framework to scale test-time compute, improving factual verification by up to 6.9x over standard RAG.
Lightweight Agents: MCP Power in 50 Lines of Code
Hugging Face's Tiny Agents project demonstrates that functional, Model Context Protocol (MCP) powered agents can be built with just 50 lines of code, bypassing the overhead of traditional orchestration libraries.
Sovereign AI: DeepSeek-V4 and Tool-Optimized Gemma fine-tunes
The open-source landscape is diversifying with DeepSeek-V4 featuring a 1M context window and community fine-tunes like roshangrewal/gemma4-e4b-toolcall targeting specialized tool-calling accuracy.
Standardizing the Ecosystem with OpenEnv
Meta and Hugging Face have launched OpenEnv, a collaborative effort to build a unified execution layer and shared repository for standardized agent environments.