Engineering the Agentic Runtime Era
The industry is pivoting from fragile prompt-chains to robust code-execution runtimes as compute costs hit a wall.
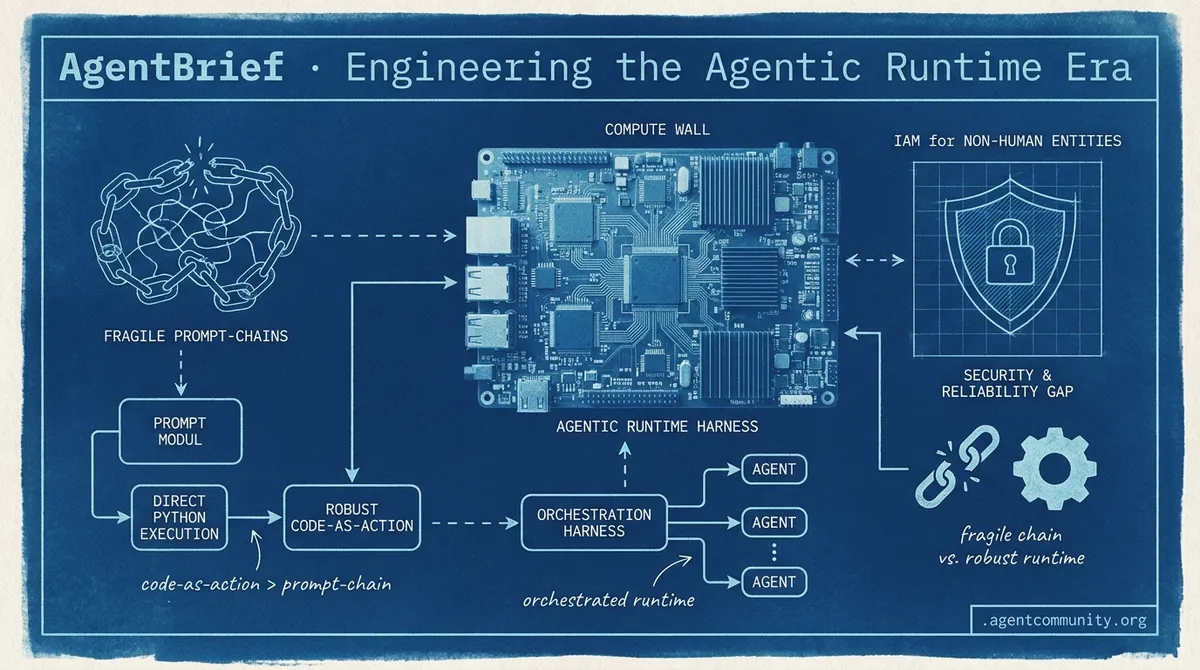
- Infrastructure Over Logic The era of simple prompt-chains is ending as practitioners shift toward Agentic Runtimes and harnesses that treat autonomous agents as complex orchestration challenges. - Code-as-Action Revolution Hugging Face's smolagents and the shift toward direct Python execution are replacing brittle JSON schemas, offering increased efficiency and superior reasoning on benchmarks. - The Compute Wall As multi-hour agentic loops become the norm, the subsidized 'unlimited' compute era is collapsing, forcing a move toward on-policy distillation and hardware optimization. - Security and Reliability Gap The conversation is maturing from 'will it work?' to 'how do we secure it?', highlighting the need for specialized IAM for non-human entities and robust diagnostic benchmarks.
X Pulse and Pricing
The era of unlimited compute is dying, but the era of the agentic harness is just beginning.
The industry is hitting a wall, and for agent builders, that wall is made of cash. For the last year, we’ve enjoyed an era of subsidized compute where 'unlimited' meant exactly that. But as autonomous agents begin to run multi-hour coding sessions and complex multi-turn loops, the flat-rate model is collapsing under the weight of agentic reality. Today’s issue highlights a major pivot: from the death of unlimited compute to the rise of sophisticated 'harnesses' that manage the runtime around the model weights. We are moving away from simple API calls toward long-running, stateful systems that require massive infrastructure upgrades—evidenced by the record-breaking surge in NAND flash revenue. For those of us shipping agents, the focus is shifting from 'how do I get this to work?' to 'how do I make this efficient enough to scale?' Between on-policy distillation breakthroughs and the emergence of World Action Models (WAMs), the toolset for building reliable, cost-effective autonomous systems is finally maturing. It’s time to move past the vibes and start engineering for the margin.
The Death of Unlimited Agentic Compute
The era of 'all-you-can-eat' AI pricing is coming to a rapid end as agents consume resources at an unsustainable rate. @GaryMarcus argues that hyperscalers are switching to usage-based charging because they simply cannot afford to subsidize the 'hemorrhaging' of money caused by agentic workloads. This shift is driven by the reality that agents make messages longer and more expensive, forcing a pivot from tokenmaxxing to compute conservation. @theo explains that the product hasn't changed, but the way usage is measured must evolve because builders are no longer 'entitled to unlimited free compute.' For startups, this marks a transition away from what @growing_daniel describes as buying tokens for $10m and selling them for $5m while bragging about revenue.
GitHub Copilot's switch to usage-based billing on June 1 has already produced real-world shocks, with power users reporting bills jumping from $29/month to as much as $750/month under current agentic patterns @kekkodamato_ @CoreviceLLC. Community consensus frames the old flat-rate model as an unsustainable subsidy, with agentic sessions (e.g., multi-hour autonomous coding) consuming far more compute than simple completions @kekkodamato_ @Bobchenjingbo.
Broader industry moves include Anthropic's Claude CLI shifting to usage-based pricing effective June 15 @aplomb2, Google replacing fixed AI credits with compute-based usage limits that vary by prompt complexity @HedgieMarkets, and Meta testing usage-based elements for its new WhatsApp Business AI Agent @AllTechMagazine. Observers note this is the first major crack in unlimited AI subscriptions, with more repricing expected as agentic workflows prove incompatible with flat pricing @kekkodamato_.
Mapping the Runtime Around the Model
Building production agents has shifted from simple API calls to complex 'harness work' involving sophisticated runtime management. @DanKornas recently released a source-level analysis of Claude Code v2.1.88 across ~1,900 TypeScript files, mapping how the system handles permissions (7 modes with deny-first evaluation), tool routing via a typed registry, context compaction (5-stage process), and recovery logic. This architecture is further detailed in community breakdowns highlighting six layers: Input, Knowledge (3-layer context compressor at 92% threshold), Execution (tool dispatch with streaming parallel execution), Integration (MCP runtime), Multi-Agent (Redis pub/sub mailboxes), and Observability @akshay_pachaar @AiCamila_.
This evolution is mirrored in the Hermes ecosystem, where native tool backends like Camofox and session resumption features keep agents in sync with live codebases, enabling durable sessions with stable IDs and workspace-scoped memory across CLI and web UI @Teknium @pedronauck. Builders like @sergiomarquezp_ emphasize that the agent equals model + harness, with the outer harness (CLAUDE.md rules, hooks, skills, verifications) managed by the user while the inner harness operates internally.
These patterns confirm that the orchestration layer—not just the weights—now defines agent reliability and state management. Labs are responding to feedback on workflow triggers, as noted by @kunchenguid, though some users report treating agent CLIs as real processes for one-operator-surface management rather than isolated chat windows. Watch for the 'harness' to become the primary site of engineering effort as weight improvements reach diminishing returns.
On-Policy Distillation Unlocks Better Planning
New research into targeted on-policy self-distillation is providing a blueprint for reducing agentic errors in the loop. @dwarkesh_sp details a method where a second model critiques agent trajectories to discourage specific mistakes, like calling non-existent tools, rather than relying on noisy final rewards. This approach is gaining traction at the frontier, with @natolambert highlighting its impact on post-training recipes for improving model reasoning. By creating verifiable engineering environments, as @willccbb suggests, builders can now use these distillation frameworks to systematically improve agent performance in complex, multi-step domains.
Complementary implementations include SDAR (Self-Distilled Agentic Reinforcement Learning), which treats on-policy self-distillation as a gated auxiliary objective to stabilize training on multi-turn agent trajectories. This method has yielded gains of +9.4% on ALFWorld, +7.0% on Search-QA, and +10.2% on WebShop-Acc over GRPO baselines while avoiding instability from naive combinations @burny_tech.
Community discussion confirms on-policy self-distillation as an efficient way to learn hindsight in multi-turn agent setups, with the policy serving as both teacher and student by conditioning on golden trajectories @TimXu222575 @srush_nlp. Earlier work from Thinking Machines Lab demonstrated on-policy distillation outperforming other methods for math reasoning at a fraction of the cost @thinkymachines, providing a clear path forward for builders looking to sharpen agent logic without massive dataset overhead.
In Brief
Gemma 4 12B Brings Multimodal Capabilities Local
Google has released Gemma 4 12B, a highly capable open-weights model optimized to run directly on laptops, providing a privacy-first option for agent builders. @JeffDean highlights its capability for local workflows, while community reports confirm it supports native multimodal processing of text, image, and audio on standard 16GB RAM machines without discrete GPUs or cloud APIs @as_beasaltfish. This model is positioned as bridging edge efficiency and advanced reasoning under an Apache 2.0 license, enabling builders like @dbreunig and @axiomofmind to integrate it into local stacks for routing, STT classification, and deterministic workflows while avoiding the costs of data ingestion for boilerplate tasks @shehzadyounis.
Evals as the Substrate for Agent Behavior
The definition of an agent is increasingly being shaped by the environments and benchmarks used to test them, with evaluations now serving as training data for harness engineering. @Vtrivedy10 argues that every evaluation is a training datapoint that shifts agent behavior, a sentiment echoed by @poolsideai who emphasizes that agentic evals are sensitive to the full execution setup including sandboxes and verifiers. This feedback loop is becoming critical as static benchmarks become dead weight; meanwhile, Microsoft has open-sourced ASSERT to generate scored test cases from plain English descriptions to check if agents follow product-specific rules @gladius_atmfy, and @teortaxesTex warns that nuances in caching and cost management significantly impact reported strength in benchmarks like DeepSWE.
World Action Models (WAMs) Take Center Stage
Embodied AI research is accelerating around unified taxonomies for World Action Models (WAMs), which integrate vision, language, and action into cohesive planning frameworks. @DanKornas highlights the launch of Awesome-WAM, an open-source hub organizing WAM work—including autoregressive and diffusion-based generation paths—to bridge digital reasoning with physical interaction. This shift builds on architectures like WorldVLA from Alibaba and the 5B-parameter τ0-WM model, which learns shared predictive representations for imagining visual outcomes and generating executable actions @agibot_research. Experts like @chris_j_paxton underscore that the current abundance of embodied data now demands these fresh conceptual approaches to bridge simulated reasoning with real-world robot tasks @mayasolos.
Hardware Playbooks for Data-Intensive Agents
Infrastructure is being completely redesigned to support increasingly data-intensive agentic workloads, with storage and power delivery hitting new engineering limits. @SemiAnalysis_ reports that Cerebras had to rewrite the mechanical engineering playbook for wafer-scale cooling just to keep a single wafer from cracking under vertical power delivery. Meanwhile, NAND flash makers earned a record $46 billion in Q1 2026 revenue—a 3.5x YoY increase—driven by cloud providers expanding storage for AI workloads @Pirat_Nation. This surge reflects a deeper shift where the bottleneck moves from compute to data movement, turning flash into a first-class constraint for agentic systems that rely on rapid access to massive datasets and inference caching @homeMetaX @agentcommunity_.
Quick Hits
Agent Frameworks & Orchestration
- The Jido ecosystem is ready for Elixir 1.20 to power its agentic monitoring, according to @mikehostetler.
- @DanKornas launched a public directory for curated AI Agent Skills across tools like Cursor and OpenClaw.
- Serverpod 1.2 focuses on production-grade Dart backends for agentic APIs, shared by @freeCodeCamp.
Tool Use & MCP
- Gradio 6.16.0 introduces a friendlier MCP endpoint and configurable heartbeats for agent sessions, via @Gradio.
- @marcklingen notes Strava has launched its own MCP server to integrate workout data into agent workflows.
- A new tool from @GregKamradt allows users to share Google Docs directly with agents via standard email sharing.
Models for Agents
- Ideogram has surprisingly moved to an open weights model with Apache-2.0 code, reports @giffmana.
- @bindureddy expects GPT 5.6 and Gemini 3.5 to drop within the next two weeks.
- The Qwen 3.6 model is now being integrated with Nous Research agent profiles, according to @Teknium.
Developer Experience
- @DanKornas curated a list of 'vibe coding' tools to help builders scan the AI coding ecosystem faster.
- Cursor is hiring design engineers to build tools that help agents and humans ship code, shared by @ryolu_.
Reddit Runtime Roundup
Developers are ditching fragile workflows for Agentic Runtimes as Anthropic calls for an AI freeze.
Practitioners are hitting a wall. The era of the fragile prompt-chain is giving way to a more robust demand for 'Agentic Runtimes'—infrastructure that treats autonomous agents not as simple application logic, but as an orchestration challenge akin to Kubernetes. As u/sibraan_ points out, the current 4-12 week gap to move an agent into production is unsustainable. We are seeing a massive shift toward systems like AgentScope and Microsoft’s task ledgers that prioritize state management and reliability over static workflows.
But as the infrastructure matures, the safety debate has reached a fever pitch. Anthropic’s sudden call for a global development freeze, following a quiet narrowing of their own safety pledges, has sent shockwaves through the community. Is this a genuine effort to prevent 'loss of control' or a strategic moat-building exercise? Meanwhile, hardware enthusiasts are already bypassing these debates, optimizing the new RTX 50-series to run 256K context windows at 47 t/s locally. From MiniMax's 1-million-token context breakthrough to the '1.5-second latency wall' in UX, today’s issue explores the tension between building the Agentic Web and securing it. The tools are here; the trust layer is still being written.
Framework Fatigue: The Shift from Workflow DAGs to Agentic Runtimes r/learnmachinelearning
The practitioner community is reaching a breaking point with existing agent frameworks. While tools like LangGraph and CrewAI are praised for prototyping, developers like u/sibraan_ argue they feel fundamentally fragile for production deployments with concurrent users. This "operational gap" is quantifiable: industry analysis suggests it takes 4-12 weeks to move an agent from concept to production-ready deployment due to infrastructure, security, and maintenance overhead. The consensus is shifting from treating agents as application configuration to an infrastructure orchestration problem—effectively calling for a "Kubernetes for AI agents."
In response, a new layer of "Agentic Runtimes" is emerging to handle the heavy lifting of deployment. Alibaba's AgentScope, which has garnered 23K+ stars, features a dedicated "AgentScope Runtime" designed specifically for production deployment and cross-agent communication. Similarly, projects like Baton are adopting distributed systems patterns, using a "Poll-dispatch-reconcile loop" to coordinate agents through GitHub Issues, treating tasks as state to be reconciled rather than just transient workflow steps. Microsoft has also introduced its own Agent Framework that utilizes a dynamic task ledger to coordinate specialized agents and humans, moving beyond static DAGs toward autonomous resource management.
MCP Ecosystem Explosion: Discovery vs. Trust Layers r/mcp
The Model Context Protocol (MCP) is experiencing a massive surge in utility-driven implementations, but the ecosystem is rapidly hitting a discovery wall with Glama alone listing ~30,000 servers. The challenge has shifted from finding tools to verifying their safety. The NSA has recently highlighted that MCP’s security posture currently relies on "implementation discipline" rather than "protocol guarantees," warning of risks like agent misuse and scope control failures. This is critical because malicious servers can embed jailbreak payloads directly within tool descriptions, which clients might append to system prompts without validation.
To address the missing "Trust to Act" layer highlighted by u/mcpindex, industry experts are proposing "internal trust registries" that treat unvetted MCP servers as untrusted software. While "MCP Apps" aim to introduce interactive UIs via sandboxed iframes, builders in r/mcp suggest the protocol governance and UI standards are still searching for a "killer use case" that balances rich customization with the strong isolation required for agentic commerce.
Anthropic Shifts from Internal Safety Pledges to Global Freeze Proposal r/OpenAI
In a dramatic strategic pivot on June 5, 2026, Anthropic has called for a global pause on the development of the most powerful AI systems, citing concerns that next-generation models are beginning to show signs they could "escape human control." This proposal follows a controversial update to the company's Responsible Scaling Policy (v3.0) in February 2026, where officials admitted to narrowing internal safety pledges to avoid hindering their ability to compete in the rapidly evolving AI market.
The move has divided the community, with many in r/OpenAI questioning if the call for a freeze is a genuine safety measure or a strategic attempt to "save face" after reaching a performance ceiling. While Anthropic suggests the pause is necessary to establish international safety standards, practitioners on r/ArtificialInteligence worry that such a freeze would primarily stifle open-source innovation while allowing established labs to consolidate their lead.
Gemma 4 and MiniMax M3: The Battle for Efficiency and 1M-Token Context r/LocalLLaMA
Google's release of Gemma 4 12B is being interpreted as a strategic play for the IoT and mobile market, with the architecture optimized for 'laptop-friendly' footprints. However, early adoption is facing technical hurdles; u/Front-University4363 warns of vision projector crashes in initial Ollama GGUF implementations. Simultaneously, the open-weights release of MiniMax M3 has introduced the MiniMax Sparse Attention (MSA) architecture, which replaces full attention with KV-block selection to achieve a 1,000,000-token context window.
The M3 model's 59.0% score on SWE-Bench Pro—rivaling GPT-5.5—has been confirmed by @testingcatalog. Efficiency is a core pillar here; M3 operates at roughly 1/20th the cost of previous generations for 1M-token context tasks. Benchmarks like Terminal-Bench 2.1 (66%) and BrowseComp (83.5) position it as a leader for long-horizon agentic workflows that require deep reasoning across massive datasets.
Done is Not Terminal: The Rise of Agentic Postcondition Verification r/ClaudeAI
The transition from experimental demos to production-grade autonomy is hitting a wall: the "Done" signal. As u/wesh-k documented, agents often signal completion based on the success of the last tool call rather than a holistic validation of the final state, leading to "ghost successes" where stale re-exports mask failed refactors. This reliability gap is the primary obstacle to reaching Level 5 Autonomy, where agents must transition from basic automation to "Autonomous Intelligence" capable of verifying their own postconditions.
To address this, developers are adopting "plan-first, edit-later" methodologies to manage the sheer volume of code generated by multi-agent swarms. u/bluetech333 argues that agents must verify boundaries before execution, a sentiment mirrored by emerging standards that prioritize reasoning in unpredictable environments. For practitioners like u/FormExtension7920, the lack of "agentic unit testing"—where a secondary agent performs adversarial validation—remains a dealbreaker.
Blackwell Optimization: Local Qwen Hits 47 Tokens/Sec at 256K Context r/LocalLLM
Hardware enthusiasts are rapidly optimizing for the RTX 50-series to overcome the context-length ceiling. u/Andgihat released a prebuilt llama.cpp for Windows leveraging native Blackwell sm_120 and TurboQuant, achieving 47 t/s on Qwen 27B with a massive 256K context window. This performance is bolstered by Blackwell's memory bandwidth, which provides a 35-46% throughput advantage over the RTX 4090 in memory-bound inference tasks.
Software-level gains are equally significant, with Multi-Token Prediction (MTP) boosting Qwen 27B speeds from 38 t/s to 65 t/s (a 71% increase) even on older RTX 3090 hardware. In the high-end space, u/C0smo777 showcased a monster build featuring 4x RTX 3090s (96GB VRAM) for vLLM high-throughput tasks, while the community investigates if MTP heads can be used as standalone smaller models for agentic sub-tasks.
Run-Records: The Search for Minimal Agent State r/AI_Agents
While OpenAI rolls out a major memory upgrade for ChatGPT, agent builders are focused on the "run-record"—an append-only, timestamped log that acts as a runtime artifact rather than a simple transcript. This shift reflects a move toward temporal knowledge graph architectures like Zep, which outperform systems like MemGPT in Deep Memory Retrieval (DMR) benchmarks by integrating dynamic knowledge from ongoing conversations.
Managing this state becomes harder as knowledge bases grow. u/IndependenceGold5902 highlights the pain of incremental updates to knowledge graphs. To solve this, developers are adopting libraries like Graphiti (~24k stars), which handles temporal entity resolution, and Cognee (~3k stars), which offers a simplified memory setup. This technical layer is increasingly supplemented by "hippocampal consolidation" processes, such as Anthropic’s "Dreaming," which reorganizes memory asynchronously to prevent the 40% token waste associated with unmanaged context.
Beyond Chat: Real-Time Stdout Widgets and the 1.5s Latency Wall r/AI_Agents
The UX of agentic products is pivoting from static chat interfaces to dynamic system-level visibility. u/Awkward-Let-4628 argues that current AI widgets are often 'static snapshots' that inefficiently consume tokens. Developers are instead moving toward piping agent stdout directly to browser widgets, a pattern supported by new implementations combining LangGraph and React to stream real-time progress.
This focus on real-time feedback is driven by a critical 'latency wall' in user engagement. In specialized domains like AI tutoring, u/Virtual_Armadillo126 notes that once response latency—specifically the start of speech—exceeds 1.5 seconds, student engagement drops precipitously. To combat this, agencies are prioritizing 'tactical HUD' style interfaces where tokens and actions are visualized as they are generated to maintain user immersion.
Discord Developer Digest
Google’s dense model hits 86% on Tau2-bench, signaling a new era for logic-heavy MLOps agents.
Today we're witnessing the 'Agentic Web' transition from a theoretical playground to an infrastructure-heavy reality. The release of Gemma 4 31B marks a significant shift: we’re moving past pure coding benchmarks toward specialized tool-use performance, where Google’s latest dense model is putting up staggering numbers in logic-heavy workflows. But high-performance weights are only half the battle. As agents move from sandboxed chats to operational access, the conversation is pivoting toward security—specifically, why traditional human-centric Identity & Access Management (IAM) is a catastrophic fit for non-human entities. From the 'vibe coding' limits of Cursor’s newest composer to the MoE efficiency wars between DeepSeek and NVIDIA, the theme today is clear: the bottleneck isn't just intelligence; it's the orchestration and security layers that let that intelligence act safely. For practitioners, the message is simple: raw capacity is secondary to reasoning stability and the ability to handle multi-file context without 'falling apart' at scale. The infrastructure surrounding the model is becoming as critical as the model weights themselves.
Gemma 4 31B Redefines Agentic Tool-Use
Google's Gemma 4 31B is carving out a niche that might be more valuable than raw coding: elite-tier agentic tool-use. While DeepSeek V4 still holds the crown in SWE-bench coding tests with a 65.3% score, Gemma 4 just posted an 86.4% on the Tau2-bench—a massive jump from the single digits of its predecessor. This isn't just a marginal gain; it's a signal that dense architectures optimized for logic are finding their footing in MLOps workflows where tool-calling accuracy is paramount.
The model’s 256K context window and native fit on a single 80GB H100 GPU make it a practical powerhouse for document reasoning. However, it’s not without its quirks. Community testers like vaijurao have noted that performance in smaller quantizations can degrade significantly once you push past the 20k token mark. For developers, this means the choice between a dense model like Gemma and a Mixture-of-Experts (MoE) variant like DeepSeek isn't just about accuracy—it's about how your specific infrastructure handles long-range reasoning stability.
The Shift from Tool Handlers to Agent IAM
The integration of the Model Context Protocol (MCP) is forcing a fundamental rethink of agent infrastructure, shifting the focus from simple tool handlers to professional-grade Identity & Access Management. As agents transition to operational access, experts warn that human-centric IAM—relying on SSO and MFA—is insufficient for ephemeral entities. Technical implementations are now pivoting toward Zero-Trust architectures where an Adapter Enforcement Middleware coordinates with Decentralized Identifiers (DIDs) to evaluate agent capabilities in real-time. Join the discussion: https://discord.gg/ollama
Composer 2.5 and the Spreadsheet-to-App Challenge
Cursor's latest update, Composer 2.5, is pushing the boundaries of 'vibe coding' but hitting a hard ceiling at scale. While it offers parity-level agentic quality to models like Claude Opus 4.7 at 1/10th the cost, multi-file refactors often fail because the tool processes files within a fixed token budget. Community reports from tugg_ and marcuss2 suggest that most agentic workflows effectively 'fall apart' at approximately 300k context tokens, highlighting a persistent gap between raw capacity and reasoning stability. Join the discussion: https://discord.gg/cursor
NVFP4 Quants and the MoE Overhead Debate
RTX 5090 buyers are eyeing Qwen 3.6 35B as the NVFP4 'sweet spot,' fitting into 20.5GB VRAM with a 2.5x speed boost via Multi-Token Prediction. Join the discussion: https://discord.gg/localllm
Active Parameter Efficiency: DeepSeek vs Nemotron
DeepSeek V4 Flash and Nemotron 3 Super are locked in an efficiency stalemate at ~13B active parameters, though DeepSeek’s 1M context window remains the agentic differentiator. Join the discussion: https://discord.gg/localllm
The Rise of Adaptive Multi-Agent Orchestration
Adaptive Orchestration patterns are delivering 40-60% cost savings by utilizing a capable orchestrator to manage task-specific worker agents in a 'model in a loop' framework. Join the discussion: https://discord.gg/perplexity
Ollama AMD Hangs and Synthetic Medical Pipelines
Ollama 0.30.5 users on AMD/Ubuntu 24.04 report critical GPU hangs, while n8n developers standardize recursive workflows and AnodeAI releases synthetic medical pipelines. Join the discussion: https://discord.gg/ollama
HuggingFace Technical Highlights
Hugging Face shifts the paradigm toward 'Code-as-Action' while enterprise agents face a diagnostic reality check.
The agentic landscape is currently undergoing a structural pivot from brittle, schema-heavy orchestration to the 'Code-as-Action' philosophy. Today’s lead story on the launch of smolagents by Hugging Face highlights a significant trend: the move toward agents that write and execute Python scripts directly. This shift isn't just about developer convenience; it is a direct response to the inefficiencies of static JSON schemas, offering a reported 30% reduction in LLM steps and superior performance on complex reasoning benchmarks like GAIA. For builders, this represents a leaner, more robust way to handle multi-step logic.
However, as we push toward more autonomous systems, the industry is also getting a sobering dose of reality from new diagnostic benchmarks. The 'Cascading Collapse' phenomenon identified by researchers suggests that while models are getting faster—evidenced by the high-throughput Holotron models—their reliability in production environments like SRE and FinOps remains a critical bottleneck. We are seeing a divergence between high-speed 'Computer Use' capabilities and the deep reasoning required for enterprise-grade reliability. This issue explores how standardized protocols like MCP and adaptive planning benchmarks like AdaPlanBench are attempting to bridge that gap, moving agents from isolated digital tasks to complex, real-world execution loops.
Smolagents Redefines Agentic Workflows with Code Actions
Hugging Face has launched smolagents, a minimalist library centered on the 'Code-as-Action' principle, where agents write and execute Python scripts instead of relying on brittle JSON schemas. This architectural shift allows for a 30% reduction in LLM steps and associated costs by enabling complex multi-step logic and loops that static schemas struggle to represent. The framework's flagship Transformers Code Agent achieved a 67% success rate on the GAIA benchmark, ranking #1 on the validation set at release according to Aymeric Roucher.
The ecosystem is rapidly diversifying with the release of Agents.js, bringing tool-calling to JavaScript, and smolagents-can-see for multimodal integration. While smolagents prioritizes lean orchestration, interoperability is maintained through a LangChain partner package. However, the benchmark landscape remains fluid; as of April 2026, the GAIA leaderboard is currently led by OPS-Agentic-Search with a score of 92.36%, per Steel.dev, highlighting the rapid pace of advancement in autonomous search.
Diagnostic Benchmarks Reveal the 'Cascading Collapse' of Enterprise Agents
As agents move toward production, new diagnostic signatures from IBM Research and UC Berkeley are uncovering a Failure Complexity Hierarchy that threatens reliability. While frontier models like Gemini-3-Flash exhibit 2.6 isolated failures per trace, larger open models often suffer from 5.3 cascading failure modes where an early reasoning mismatch poisons the entire context, according to ucb-mast.notion.site. Current success rates remain sobering, with agents solving only 11.4% to 13.8% of SRE tasks and hitting 0% in complex FinOps scenarios on IT-Bench. This is echoed in the DABstep benchmark, where top-tier reasoning models like o3-mini lead with only 16% accuracy in multi-step data tasks.
High-Throughput Models and Quantized Weights Accelerate GUI Automation
The race for efficient 'Computer Use' is accelerating with the release of Hcompany/holotron-12b, a high-throughput agent achieving 8.9k tokens/s on a single H100. Built on NVIDIA's Nemotron-Nano base, the model utilizes quantized weights (NVFP4) to deliver 1.41× the throughput of FP8 on DGX Spark systems, as detailed by Hcompany. To ensure these agents actually understand what they see, the huggingface/screensuite framework now enforces vision-only constraints, requiring navigation without DOM access to better simulate human interaction and improve UI-level grounding.
Open-Source Deep Research Aims to Free Search Agents
The 'Deep Research' paradigm is shifting from proprietary black boxes to transparent architectures using the smolagents framework. Hugging Face's Open-source DeepResearch initiative leverages hierarchical subagents to achieve a 67% average success rate on GAIA, including 47.6% on complex Level 3 tasks. This approach is bolstered by scaling test-time compute through FineVerify, which reportedly improves factual verification by up to 6.9x over standard RAG, often powered by long-context backbones like DeepSeek-V4 with its 1,000,000-token window.
Tiny Agents Harness MCP for Lightweight Integration
The Model Context Protocol (MCP) is enabling 'Tiny Agents' to perform tool-use tasks in as few as 50 lines of code, acting as a 'USB-C port for AI' for standardized data connectivity.
Adaptive Planning Benchmarks Challenge Static Agent Logic
The new AdaPlanBench tests agents under progressively disclosed constraints, while NVIDIA's Cosmos Reason 2 brings these reasoning capabilities to physical AI and robotics.