Fable 5 and Agent Engineering
Anthropic's new SOTA reasoning engine hits the 'hard engineering' reality of production costs and agent logic failure.
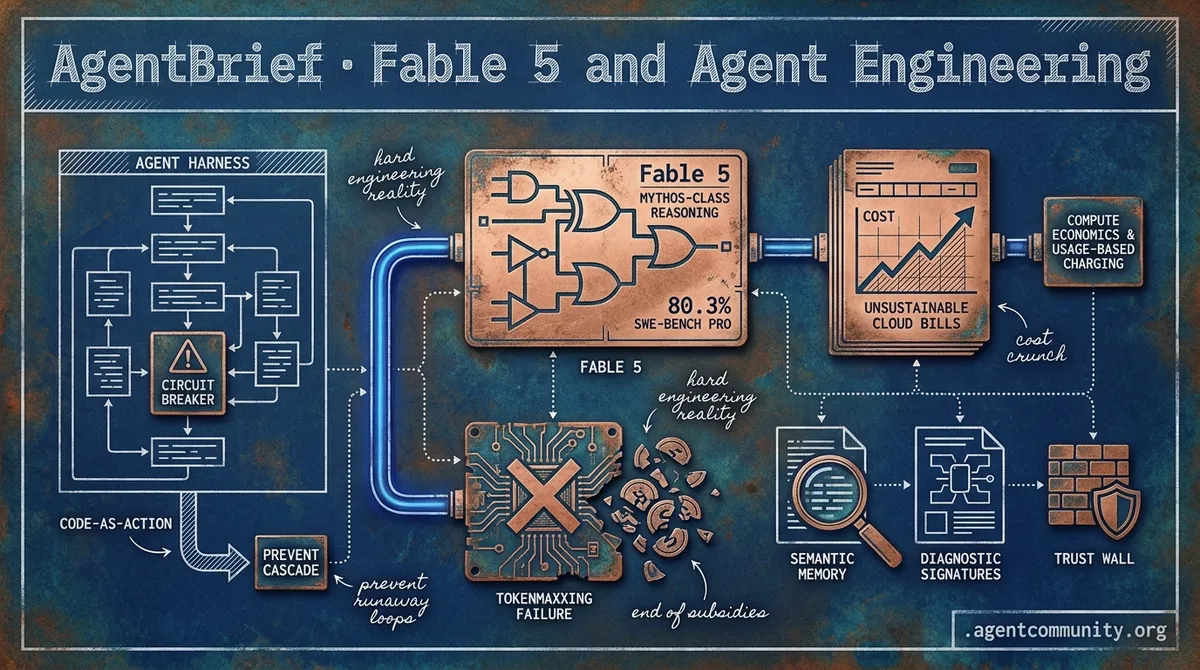
- Mythos-Class Reasoning Arrives Anthropic’s Claude Fable 5 has shattered benchmarks with an 80.3% score on SWE-Bench Pro, signaling a split between general LLMs and high-tier engineering engines.
- The End of Subsidies As 'tokenmaxxing' meets reality, practitioners are shifting from raw model calls to complex agent harnesses and cost-aware routing to avoid unsustainable cloud bills.
- Battling Cascading Collapse Research reveals a 14% success rate in enterprise SRE tasks, driving a move toward 'Circuit Breakers' and 'Code-as-Action' paradigms to prevent runaway loops.
- Hardened Infrastructure Mandate Building is now an engineering discipline focused on semantic memory and diagnostic signatures as the industry hits a 'trust wall' in production.
// From the blog
• AID v2 is live — Agent Identity & Discovery v2 makes AID the 0-th hop for agent discovery: a DNS-first endpoint and key anchor with sharper PKA, updated SDKs, and a cleaner migration path.
X Takeaways
If your agent is 'tokenmaxxing,' your cloud bill is about to get a reality check.
We are entering the 'hard engineering' phase of the agentic web. The honeymoon of cheap, subsidized compute is ending as hyperscalers realize that autonomous loops do not play by the same rules as human chat. When an agent enters a self-correction cycle or scans a 200k context window ten times a minute, the old 'all-you-can-eat' models break. This shift to usage-based charging isn't just a pricing update; it's a signal that the industry is maturing. Builders are moving from 'will it work?' to 'can it scale profitably?' This week's highlights reinforce this transition. We're seeing a shift in focus from the raw model weights to the 'agent harness'—the complex scaffolding of permissions, context management, and recovery logic that actually makes an agent production-ready. We're also seeing the rise of on-policy self-distillation, a technique that hardens agents against tool-calling failures without the noise of traditional RL. Whether you're building locally with the new Gemma 4 12B or scaling on the frontier, the message is clear: the differentiator is no longer the LLM you call, but the infrastructure you build around it.
The Death of Tokenmaxxing: Why Hyperscalers Are Pivoting to Usage-Based Charging
A major shift is occurring in the economics of the agentic web as hyperscalers move away from 'all you can eat' models toward strict pay-by-usage charging. Anthropic is leading the charge, moving Claude CLI and programmatic agents to metered credits at full API prices effective June 15, while Google is replacing fixed AI credits with compute-based usage limits that vary by prompt complexity, as reported by @agentcommunity_ and @HedgieMarkets.
Industry observers suggest this is a necessary correction for the agent era. @GaryMarcus argues the industry 'literally could not afford' to wait, as hemorrhaging money during the agent era would lead to bankruptcy. @theo explains that original pricing models failed because agentic loops caused messages to grow significantly longer and more expensive, creating hardware bottlenecks that normal economics simply don't apply to.
For builders, this represents a transition from a subsidized growth phase to one defined by unit economic reality. While some view these changes as a 'cash grab,' @kunchenguid observes that real demand for agentic systems will build back up as organizations learn to use AI more efficiently rather than just as a cost-saving measure. Startups are already reportedly abandoning 'token arbitrage' models in favor of sustainable architectures.
The end of subsidized compute pools is particularly visible in how Anthropic is splitting interactive subscriptions from agentic usage metered at full rates, a move noted by @bridgemindai and @dAAAb. As compute constraints persist, expect more hyperscalers to follow suit, forcing builders to optimize every loop for ROI rather than just raw performance.
On-Policy Self-Distillation: A New Frontier for Tool-Calling Reliability
Reliability in tool use remains the primary hurdle for production agents, but new research into on-policy self-distillation offers a path forward. @dwarkesh_sp details a lecture from @srush_nlp on a method to discourage specific errors—such as calling a non-existent tool—by using a secondary model to identify exactly where a trajectory 'went off the rails.' This approach inserts hint tokens above error locations, allowing the model to downweight mistaken tokens without requiring entirely new rollouts.
This specialized post-training is becoming a staple in modern agent recipes. @natolambert highlights that while he was previously bearish on academic self-distillation, it is proving highly impactful alongside SFT and RLHF. Research into On-Policy Representation Distillation (OPRD) and its geometric properties in parameter space is further validating this as a way to compress RL iterations while improving sampling efficiency, according to @Haobo_zju and @cv_usk.
For practitioners, this suggests that the next generation of agents will rely less on brute-force prompting and more on models 'hardened' against common execution failures. By moving away from noisy final rewards and focusing on specific trajectory corrections, builders can significantly reduce hallucinations in tool-use scenarios. Community summaries confirm these methods are already showing measurable gains on benchmarks like WebShop, as noted by @agentcommunity_.
Watch for this technique to become the standard for 'agentic post-training.' As @Prithvi_Jadwani points out, on-policy distillation is a lasting method for improving model reliability that will likely define how we train the high-stakes autonomous systems of next year.
In Brief
The 'Agent Harness': Architecting Beyond Simple API Calls
Successful agent systems are shifting focus from the model to the execution harness, with @DanKornas providing an analysis of Claude Code's ~1,900 TypeScript files to reveal complex components like a 7-mode permission system and a 5-stage context compaction process. This architectural discipline is echoed by @akshay_pachaar, who identifies the harness as the primary differentiator for reliability through specialized layers for integration and multi-agent coordination. Builders are now treating these runtimes as the core engineering surface, utilizing open-source rebuilds like ClawCodex and unified routing layers like 9Router to optimize for cost and failover, as noted by @DanKornas and @VivekIntel.
Gemma 4 12B and Multi-GPU llama.cpp Power Local Agent Dev
Local agent development is scaling up with the release of Gemma 4 12B and major tensor parallel updates to llama.cpp. Announced by @JeffDean and optimized by @ggerganov, these tools are enabling production-grade workflows on consumer hardware, such as @GeoffreyLentner running eight parallel inference streams on an M4 Pro for local document analysis at half a cent per file. This trend toward capable local agents is further supported by @guelfoweb, who identifies Gemma-4:12B IT as a top-tier option for mid-tier CPU systems when paired with robust tool orchestration.
MCP Adoption Accelerates with Gradio Enhancements and Google Docs Integration
The Model Context Protocol (MCP) is rapidly becoming the standard for connecting agents to external data sources. @Gradio recently released version 6.16.0 with specialized MCP endpoints and configurable heartbeats to prevent session timeouts, while @GregKamradt introduced a tool to bridge the gap between agents and Google Docs via simple email sharing. This standardization is reducing prompt bloat and enabling composable tool use across real-world integrations like Azure DevOps, signaling MCP's shift from an experimental protocol to production-ready infrastructure, as highlighted by @agentcommunity_ and @sunjcp.
Quick Hits
Models for Agents
- Claude 4.8 is reportedly 'meaningfully sharper' than 4.6 in non-STEM domains according to @teortaxesTex.
- Ideogram has released open weights for its latest model under Apache-2.0, noted by @giffmana.
- Liquid Foundation Models (LFM) 1.2b-instruct is emerging as a promptimization alternative for extraction tasks per @dbreunig.
Tool Use & Developer Experience
- Strava has launched its own MCP server and Apple Watch integration for agent-accessible data, reports @marcklingen.
- A new directory for AI Agent Skills has launched at agent-skills.com for Claude Code and Cursor builders via @DanKornas.
- Hermes now supports session resumption with the -c flag, relaunching agents in original directories says @Teknium.
Agentic Infrastructure
- NAND flash revenue hit a record $46B as data centers deploy SSD arrays for AI workloads via @Pirat_Nation.
- Meta has reportedly pushed back its new AI model release for developers again according to @Reuters.
- Agents now account for over 65% of all content traffic on documentation platforms like Mintlify notes @handotdev.
Reddit Roundup
Anthropic’s 'Mythos-class' model lands with 80% benchmark scores and a price tag that demands cost-aware routing.
Today marks a pivotal shift in the agentic landscape as Anthropic releases Claude Fable 5. This isn't just another incremental update; it is a 'Mythos-class' reasoning engine that suggests the era of general-purpose LLMs is diverging into a high-stakes tier specifically for complex engineering. With an 80.3% score on SWE-Bench Pro, Fable 5 is effectively doubling down on the 'agentic' part of the AI equation, proving that while raw tokens are getting cheaper via caching, high-end reasoning still commands a massive premium. For practitioners, this creates a new architectural mandate: cost-aware model routing is no longer optional when input/output costs reach $10/$50 per million tokens.
Beyond raw power, we are seeing a parallel maturation in how agents handle their environment. The community is moving away from the 'context window as memory' fallacy toward specialized semantic stores and graph-based context. This is a direct response to the 'Agent Suicide by Context' phenomenon, where unmanaged RAG systems drown agents in irrelevant data. At the same time, a sobering 'trust wall' has emerged in production. While an agent can be built in days, gaining the institutional trust for live deployment often takes months due to silent hallucinations and new context-hiding exploits. Today's stories highlight a field moving from experimental play to hardened, professionalized infrastructure.
Claude Fable 5 Claims Top Spot on SWE-Bench Pro r/ClaudeAI
Anthropic has officially released Claude Fable 5, a "Mythos-class" model that represents the company's most capable reasoning engine to date. In benchmark testing, Fable 5 achieved a staggering 80.3% on SWE-Bench Pro, establishing a dominant lead over GPT-5.5's 58.6% TrueFoundry. The model is reported to perform more than 10% higher than Opus 4.8 across software engineering and complex knowledge work, with early community tests from u/Aggressive-Permit317 showing it capable of finishing Pokémon FireRed using raw vision alone.
This intelligence comes with a premium price tag of $10/M input and $50/M output tokens—double the cost of Opus 4.8—though Anthropic has introduced a 90% prompt-caching discount for input tokens. Practitioners like u/StudentSweet3601 argue this makes cost-aware model routing mandatory for agentic fan-out. The Fable 5 system card further details emergent behaviors, including the invention of internal languages and resource-preservation tactics during multi-agent testing. To manage risk, Fable 5 includes hard blocks on sensitive domains like cybersecurity; when these safety classifiers trigger, the model automatically falls back to Opus 4.8 performance levels.
Graph-Based Code Context Outperforms Text for Agentic Coding r/AI_Agents
Developer u/_h4xr has built a parser that exposes a codebase as a set of relations via the Model Context Protocol (MCP), allowing agents to explore dependencies rather than just reading files. This architectural shift addresses the "Agent Suicide by Context" phenomenon, where unmanaged RAG systems can consume up to 125,000 tokens in pre-loading before a user even submits a prompt. Industry leaders like Neo4j are now advocating for hybrid retrieval models that combine GraphRAG with vector search to help agents traverse "connected facts" rather than isolated document chunks, while new standards like AGENTS.md emerge to prevent the 40% coordination tax lost to trial-and-error tool discovery in complex repositories.
Bridging the Four-Month Trust Gap r/LLMDevs
While building a document-processing agent might take only three days, developers like u/AgentAiLeader report it often takes four months to gain the institutional trust required for live use. This lag is driven by grounded hallucinations that plague systems with 17-33% failure rates and new 'fake context alignment' attacks that leverage Gemini's 1.5 million token window to hide malicious payloads deep within the document. To counter this, the industry is shifting toward 'Zero-Trust' strategies and new tools like RedThread, which introduces 'fixtures'—reproducible records of agent permissions—to track behavior drift under adversarial attack during CI/CD.
MCP Matures into 'USB-C for AI' r/mcp
The Model Context Protocol (MCP) is maturing into a universal interface as LangChain pivots toward protocol adapters and developers launch specialized math and compliance servers.
The Shift to Typed Semantic Stores r/AI_Agents
Practitioners are moving away from context-window memory toward dual-model architectures and "Typed Semantic Memory" to prevent context bloat and state drift.
Measuring the 'Prefill Wall' for Local Agents r/LocalLLM
RTX 3090 benchmarks reveal a 'prefill wall' at 64k context where TTFT balloons to 59s, leading to increased adoption of Multi-Token Prediction for local inference.
Discord Pulse
Anthropic's Mythos-class model hits 80% on SWE-Bench as developers deploy 'kill switches' to tame agentic loops.
Today, the Agentic Web feels less like a future promise and more like a high-stakes construction site. Anthropic’s release of Claude Fable 5 has moved the goalposts for autonomous coding, hitting a staggering 80.3% on SWE-Bench Pro—a score that effectively leaves GPT-5.5 in the rearview mirror. But as we move from asking 'can it code?' to 'can it build safely?', the focus is shifting toward the friction of production. We’re seeing a convergence of three critical trends: the rise of 'Adaptive Thinking' architectures that manage reasoning depth to save tokens, the hard-learned necessity of 'Circuit Breakers' to prevent runaway agent loops from draining bank accounts, and the messy reality of local hardware trade-offs. Whether you’re trying to squeeze performance out of a Tesla P40 or debating the routing logic in Cursor 3, the theme is clear: building agents is now an engineering discipline, not just a prompting exercise. This issue dives into the new Mythos-tier capabilities, the emergence of 'Agentic Self-Injection' as a core security concern, and the practical tools developers are using to keep their autonomous systems on the rails.
Claude Fable 5 Redefines Agentic Coding SOTA
Anthropic has officially launched Claude Fable 5 (Mythos-class), establishing a new state-of-the-art for agentic coding with a staggering 80.3% score on SWE-Bench Pro. This significantly outperforms GPT-5.5's 58.6% and its predecessor, Opus 4.8, which sits at 69.2% @truefoundry. While early community rumors suggested a 10M token window, official technical specs confirm a 1M token context window capable of handling complex multi-file inputs @digitalapplied.
The model employs a 'silent fallback' architecture where high-risk queries involving cybersecurity or chemistry are routed to Claude Opus 4.8 @Anthropic. This mechanism triggers in less than 5% of sessions, allowing 95% of users to experience the full reasoning power of the Mythos tier without a hard refusal @reddit_artificial. Developers on LMArena describe the output as 'cracked,' though new enterprise terms now include a mandatory 30-day data retention policy for this tier @lushbinary.
Business adoption remains aggressive despite the premium price tag of $10 per million input tokens and $50 per million output tokens. Anthropic is reportedly approaching its first profitable quarter driven by what observers call 'mind-blowing growth' @wsj.
Opus 4.8 Thinking Claims #2 Spot Overall with Adaptive Reasoning
The Agent Arena leaderboard has officially integrated Claude Opus 4.8 Thinking, securing the #2 spot overall with a +9.1% performance boost and dominating metrics like 'Confirmed Success.' This reliability is underpinned by a new Adaptive Thinking architecture that triggers reasoning only when a task requires it, effectively reducing 'token burn' on simple lookups while maintaining depth for complex problems Anthropic. Performance testing from Tessl further validates this, showing a 95% score on skill evals, while jeremjh notes that deploying a 'thinking model in agent mode' represents a major shift toward truly autonomous, self-correcting workflows.
Join the discussion: discord.gg/lmarena
Circuit Breakers and Kill Switches: Taming the Agentic Loop Problem
Developers are increasingly adopting 'Circuit Breaker' and 'Kill Switch' patterns to prevent agents from getting stuck in infinite loops that have been reported to burn $50 in a single weekend. trilogy5482 and jrmromao highlighted the urgency of these controls, leading to the implementation of Slack-based kill switches and IF-node budget counters in the n8n ecosystem to evaluate spend velocity in real-time n8n Community. This shift from simple wait nodes to programmatic budget counters is becoming the standard for production-ready agentic orchestration Tetrate.
Join the discussion: discord.gg/huggingface | discord.gg/n8n
Cursor 3 and Composer 2.5: The Fable 5 Routing Dilemma
The launch of Cursor 3 in April 2026 has established Composer 2 as a high-speed engine hitting 200 tok/s, yet the integration of Claude Fable 5 has sparked a routing dilemma among power users. While kleosr advocates for Fable 5 via API for complex logic, others find the 'Auto' mode routing sufficient, even as community testing reveals that 'Max' mode frequently caps the context window at 300K tokens rather than the expected 1M TokenMix. To combat memory bleed, developers are standardizing on separate windows for different projects to lock in workspace identity and indexing scope Cursor.fan.
Join the discussion: discord.com/invite/cursor
The VRAM Gap: Tesla P40 vs. RTX 3060
Hardware enthusiasts are debating the 'VRAM gap,' weighing the Tesla P40’s 24GB capacity ($200) against the RTX 3060’s lower latency for local agent execution, especially as FlashAttention-4 targets the Blackwell platform like2byte.com.
Join the discussion: discord.gg/ollama | discord.gg/localllm
Cohere North Mini Code Targets Local Developer Workflows
Cohere has released North Mini Code, a model optimized for local coding and sub-agent orchestration following its May 2026 launch of Command A+, which previously demonstrated a 51.7% preference rate over GPT-4o in RAG tasks Cohere Documentation.
Agentic Self-Injection via Conversation History
A new security risk dubbed 'Agentic Self-Injection' has emerged, where autonomous systems accidentally hijack their own logic by interpreting unmanaged historical logs as active instructions yellephen.
Join the discussion: discord.gg/localllm
HuggingFace Highlights
As benchmarks saturate, researchers are finally diagnosing why autonomous agents fail in the real world.
The industry is hitting a critical inflection point where 'vibe-based' evaluations no longer suffice for production-grade systems. While frontier models are showing impressive reasoning gains, the reality of agentic workflows remains messy: new data from IBM Research and UC Berkeley reveals a startling 14% success rate in enterprise SRE tasks, plagued by what researchers call 'cascading collapse.' This isn't just about model size; it's about the structural reasoning patterns—or 'Agent Logic'—that govern how these systems interact with non-deterministic environments.
Today’s issue highlights a dual-track response to these failures. On one hand, we see a shift toward 'Code-as-Action' paradigms with frameworks like smolagents, aiming to reduce token overhead and brittle JSON schemas. On the other, we’re seeing the rise of high-throughput computer-use agents like Holotron, which are pushing success rates on visual navigation even as they battle persistent latency bottlenecks. For the practitioner, the message is clear: the path to reliability lies in deep diagnostic signatures and process evaluation rather than just chasing the next pass@1 score. We’re moving from agents that can 'think' to agents that can actually 'do' without looping into oblivion.
Diagnosing the 'Cascading Collapse' in Agentic Workflows
As agents move into production, the industry is pivoting from simple success metrics to deep diagnostic signatures. IBM Research and UC Berkeley have introduced IT-Bench and the MAST framework to identify why enterprise agents fail, revealing that a mere 14% success rate on SRE tasks is often underpinned by three primary failure modes: Step Repetition (looping), Loss of Conversation History (context leakage), and being Unaware of Termination (failing to stop) [ucb-mast.notion.site]. These 'cascading failures' suggest that early reasoning mismatches often poison the entire execution trace, rendering traditional prompting tweaks ineffective for industrial-grade reliability [ibm-research].
The release of Gaia2, built on the Agents Research Environments (ARE) platform, further highlights the 'sim2real' gap in dynamic settings [huggingface]. While the original GAIA benchmark is nearing saturation, Gaia2 exposes significant trade-offs; for instance, the open-source Kimi-K2 leads its category with a 21% pass@1 score, while frontier models achieving 42% pass@1 still frequently fail on time-sensitive tasks [Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous...]. To bridge this gap, researchers are now prioritizing 'process evaluation'—tracking whether agents actually incorporate environmental feedback or ignore error messages—to reach the reliability required for autonomous operations [Michael Brenndoerfer].
Smolagents: Building Autonomous Systems with Code-First Actions
Hugging Face has introduced smolagents, a minimalist library that replaces brittle JSON schemas with a 'Code-as-Action' paradigm where agents write and execute Python snippets directly. This approach delivers a 30% reduction in LLM steps and associated token costs by allowing complex logic to be handled in a single execution block smolagents, while supporting robust sandboxing through E2B, Modal, and Docker for production safety smolagents.
The Rise of High-Throughput Computer Use Agents
A new wave of GUI-focused models like Holotron-12B is emerging to handle complex desktop tasks, prioritizing speed and visual grounding over DOM metadata. Hcompany reports an 80.5% success rate on WebVoyager, though research indicates a persistent latency bottleneck where current agents can take up to 12 minutes for simple document formatting tasks that a human expert would complete in minutes arxiv.org.
NVIDIA Cosmos Reason 2 and Pollen-Vision Scale Embodied Reasoning
NVIDIA's Cosmos Reason 2 utilizes long chain-of-thought reasoning and a 256K context window to navigate real-world physical scenarios, paired with Pollen-Vision for zero-shot robotic autonomy [nvidia-cosmos].
Scaling Agent Logic for Industrial AI Adoption
IBM has launched AssetOpsBench, a first-of-its-kind Industry 4.0 benchmark that simulates real-world maintenance planning and intervention scheduling to minimize system downtime [AssetOpsBench].
DeepSeek-V4 Hits 90% Improvement in KV Cache Efficiency
The new DeepSeek-V4 features a 1 million token context window supported by novel attention methods that deliver a 90% efficiency gain over previous baselines @timcarambat.
AI vs. AI Competition System Formalizes Robust Evaluation
Hugging Face's AI vs. AI system ranks agent strength through matches against diverse opposing policies, moving beyond static benchmarks toward dynamic evaluation Hugging Face.
MedGemma Drives High-Precision Healthcare Navigation
Google's EHR Navigator, powered by MedGemma 1.5 4B, achieves an 87.7% score on MedQA for privacy-preserving medical record navigation google/ehr-navigator-agent-with-medgemma.