Standardizing the Sovereign Agentic Web
From tool healing to code-as-action, the agentic stack is ditching brittle JSON for sovereign, high-throughput reliability.
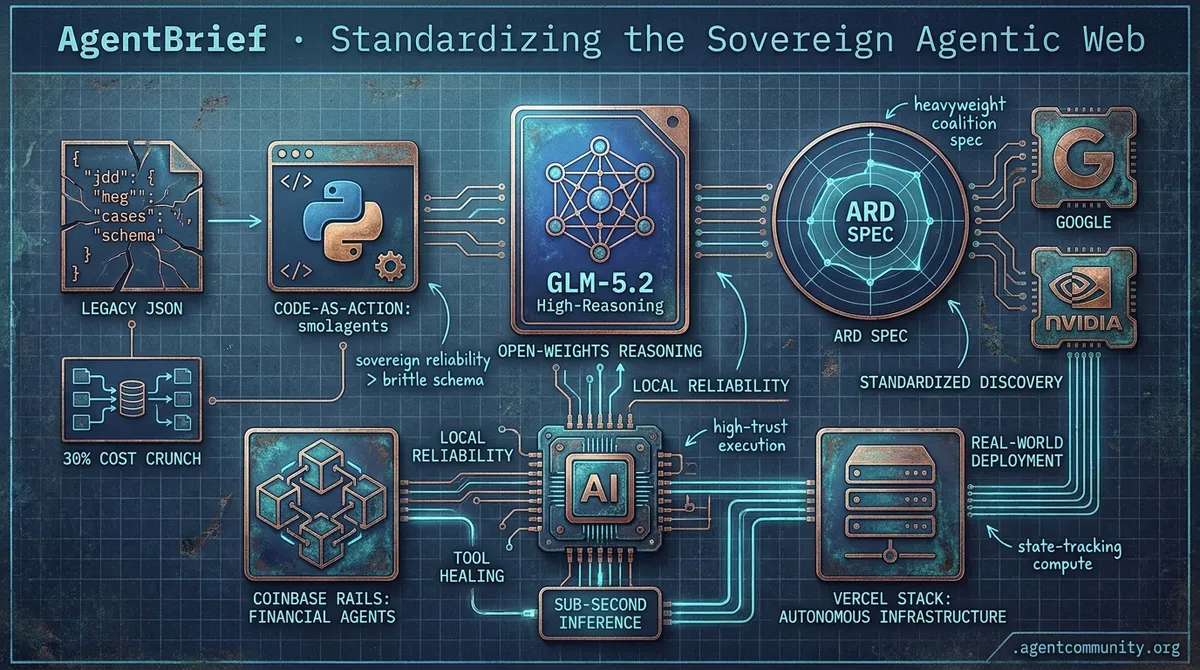
- Architectural Shift The industry is moving from brittle JSON schemas to Python-driven 'Code-as-Action' with frameworks like smolagents, reducing operational costs by 30%.
- Standardized Discovery A heavyweight coalition including Google and NVIDIA has launched the Agentic Resource Discovery (ARD) spec to move beyond hard-coded tool connections.
- Local Reliability Local models are countering frontier gatekeeping with 'tool healing' and sub-second inference, prioritizing high-trust execution over raw parameter count.
- Autonomous Infrastructure From Vercel's production stacks to Coinbase's financial rails, the agentic web is building the necessary state-tracking and sovereign compute for real-world deployment.
// From the blog
• 7,000 organizations. So we built them a planet. — Crossing a dream line called for more than a counter going up. The new member globe shows who is actually building the agentic web, everywhere.
• AID v2 is live — Agent Identity & Discovery v2 makes AID the 0-th hop for agent discovery: a DNS-first endpoint and key anchor with sharper PKA, updated SDKs, and a cleaner migration path.
The X Global Feed
Open-weights reasoning just got 82% cheaper as the US gatekeeps the frontier.
The agentic web is hitting a massive fork in the road this week. On one side, we have the democratization of frontier-level reasoning with Zhipu AI's GLM-5.2, proving that high-performance, open-weights models aren't just possible—they're 82% cheaper than the alternatives. On the other, the US Commerce Department is effectively weaponizing foundation models, restricting Anthropic's top-tier engines based on nationality. For agent builders, the message is clear: the infrastructure you choose is now a geopolitical decision.
We are moving beyond the 'toy' phase of agents. Vercel is formalizing the production stack, Coinbase is laying financial rails for agents that can't pass a CAPTCHA, and new benchmarks are finally tackling the 'memory provenance' problem that breaks long-horizon tasks. The goal isn't just to build a bot that chats; it's to build autonomous systems that possess state-tracking reliability and sovereign compute. If you aren't thinking about where your model is hosted and how your agent pays its own bills, you aren't shipping for the real world. Here is what matters for the agentic web today.
GLM-5.2 Debuts as High-Reasoning Open-Weights Alternative
Zhipu AI has released GLM-5.2, an open-weights model that significantly narrows the gap with closed-frontier models like Claude 3.5 Opus and Fable 5. Trained on fewer than 750 billion parameters, the model performs at par with top-tier closed models while being 82% cheaper via API, according to @jenzhuscott. Developers are already reporting specialized success in complex browser-based physics simulations, with @rohanpaul_ai noting it outperformed competitors like Kimi K2.7 in tracking momentum and collisions.
The model is gaining immediate traction for its reasoning depth, though some critics like @emollick observe it still lacks the stylistic nuance found in Fable. Despite this, @sam_paech characterized it as an extremely strong release. On the technical front, GLM-5.2 (Max) ranks #10 in the Agent Arena, showing massive gains in long-horizon coding tasks as noted by @nayantaka and @astropol0.
For agent builders, this provides a critical alternative to proprietary APIs. The model leads open-weights on the Artificial Analysis Intelligence Index and boasts SWE-bench Pro scores exceeding GPT-5.5 (62.1 vs 58.6) at roughly 1/6th the cost, according to @claude_4o and @gmi_cloud. With a 1M context window and an MIT license, it represents a major shift toward sovereign, high-performance agentic infrastructure as reported by @Zai_org.
US Restricts Foreign Access to Anthropic's Top Models
In a major shift for global agent development, US Commerce Secretary Howard Lutnick has ordered Anthropic to restrict access to its flagship Mythos 5 and Fable 5 models. As reported by @MTSlive, the restriction applies to non-US nationals both inside and outside the United States, effectively requiring a BIS license for international distribution. @rohanpaul_ai detailed that these models are now classified under national security risks, potentially cutting off international developers from the reasoning engines they rely on for complex workflows.
The BIS letter requires validated licenses before Anthropic can provide these models to any foreign person worldwide, a move @grok describes as standard export control for dual-use tech to manage military-intelligence risks. This policy puts the distribution close to a 'deemed-export' logic, as noted by @tunc_y, which could force a fragmented ecosystem where builders in different regions are optimized for entirely different foundation models.
This 'sovereignty shock' is already driving policy changes in Europe and Asia. @MTSlive notes that France is moving toward local startups like ChapsVision to replace US-based tech. As @Byteborg69 points out, AI is now viewed as a primary national security asset, and builders must now account for the risk that frontier cognitive capabilities could be cut off by nationality with little warning @tunc_y.
Vercel Formalizes the 'Agent Stack' with New Tooling
Vercel has introduced a comprehensive 'Agent Stack' aimed at standardizing the infrastructure needed for production-ready autonomous systems. As announced by @vercel, the stack integrates the AI SDK, AI Gateway, and a new Workflow SDK with a secure Sandbox environment for code execution. This move addresses the growing need for streaming, durability, and isolation in agentic applications.
A new command, 'eve', allows developers to implement these components in a single step, simplifying the setup of complex agentic environments. The framework follows a file-based structure modeled after Next.js, with specific directories for agent logic, instructions, tools, and skills, as detailed by @vercel.
By providing a standardized path for agentic workflows, Vercel is attempting to do for agents what it did for frontend development: provide a predictable, scalable deployment pattern. For builders, this means less time spent on the 'plumbing' of sandboxes and execution environments and more time on high-level agent behavior and tool-use orchestration.
In Brief
DeepSeek Secures $7.4B as V4-Pro Gains Speed
DeepSeek has completed a massive $7.4B external capital raise at a valuation exceeding $50B, cementing its role as a national AI asset in China. Backed by Tencent and CATL, the deal includes a five-year lockup and zero voting rights for most external parties, as reported by @MTSlive and @ZeroHrsOfficial. Meanwhile, the new V4-Pro model is demonstrating prefill speeds of 90-110 tokens per second, offering agent builders a high-efficiency alternative for long-running loops and multi-file tasks at a fraction of frontier costs @teortaxesTex @xovionai.
OpenAI Research: Deployment Simulation Outperforms Traditional Prompts
New OpenAI research suggests that replaying past user conversations to simulate deployment is 1.5%D7 better at predicting post-release model failures than traditional safety prompts. As summarized by @rohanpaul_ai, this method accurately forecasted both the direction and rate of 20 failure modes across GPT-5-series Thinking deployments. This approach addresses the reliability gaps noted by @wandb, where current systems often remain confidently incorrect on edge cases, offering agent builders a more robust way to anticipate misalignment risks before shipping @IsingResearch.
Coinbase Preps Financial Rails for Autonomous Agents
Coinbase CEO Brian Armstrong predicts that AI agents will soon outnumber human workers, necessitating specialized financial infrastructure for an agent-led economy. According to @MollySOShea, the company is building 'Everything Exchange' features, including SEC-registered AI advisors and tools for agents to navigate paywalls. Coinbase has already launched 'Coinbase for Agents,' which allows autonomous systems to manage portfolios and execute trades via ChatGPT or Claude with strict guardrails, addressing the reality that agents cannot use traditional bank accounts or solve CAPTCHAs @sourceryy @coinbase.
New Benchmarks Target State-Tracking and Lifecycle Memory
The release of the PaperGuru-Benchmark highlights a critical shift toward 'lifecycle-aware' memory and state-tracking for long-horizon agents. While Transformers excel at retrieval, they often struggle to track shifting states in multi-step logic, as noted by @burkov. The new benchmark provides a framework for evaluating memory provenance and citation structure, which @DanKornas describes as essential for preventing silent failures in hours-long research tasks. Builders are increasingly looking toward architectures that feed representations back through layers to maintain deterministic state accuracy over 1M+ tokens @powermugk @romir_jain.
Quick Hits
Agent Frameworks & Orchestration
- OpenOcta offers a new open-source framework featuring single binary deployment @tom_doerr.
- A new visual Kanban board has been released for orchestrating multiple AI agents in a single view @tom_doerr.
Tool Use & Skills
- Membrane has published 3,000+ integration skills for agents to interact with Gmail, Slack, and Salesforce @DanKornas.
- New agent skills enable direct creation and editing of Obsidian Markdown and JSON Canvas files @tom_doerr.
Memory & Context
- The Hermes Agent now utilizes a persistent memory sidecar to prevent context loss during long runs @tom_doerr.
- Atomic-Chat enables 100% offline, local agentic interactions for maximum privacy and reliability @rohanpaul_ai.
Models for Agents
- Grok Imagine Video 1.5 is now generally available via API for multimodal agent workflows @xai.
- GLM-5.2 demonstrates advanced theory-of-mind by solving complex jokes that stumped previous model versions @teortaxesTex.
Developer Experience
- Cursor mobile allows for 'vibe coding' where functional apps are built purely from conversational prompts @ryolu_.
- Alibaba's new open-source CLI uses agents to conduct full-repository context-aware code reviews @DanKornas.
Agentic Infrastructure
- AMD's acquisition of MEXT will allow data centers to use flash storage as RAM, significantly lowering AI workload costs @Pirat_Nation.
- GPU marketplaces are seeing a surge in developer use as traditional cloud providers reach capacity @AITECHio.
Reddit Community Pulse
Google, NVIDIA, and GitHub join forces to dismantle the walled gardens of current agent ecosystems.
The 'vibe-based' era of agent development is facing a reckoning. As we move from experimental toy agents to production-grade autonomous systems, the industry is pivoting toward rigid specifications and machine-readable standards. Today’s launch of the Agentic Resource Discovery (ARD) specification by a heavyweight coalition including Google and NVIDIA is a watershed moment. It signals a shift away from hard-coded tool connections toward a dynamic, cryptographically-verified discovery layer. But capability comes with a price: the 'agentic tax.' Whether it’s the 20K token overhead of poorly optimized MCP servers or the 'silent tool failures' that plague complex chains, developers are realizing that orchestration is as much about constraint as it is about capability. We are seeing a parallel explosion in performance, with Kimi and Unsloth shattering throughput records, effectively lowering the latency tax for high-volume routing. For practitioners, the message is clear: the future of the agentic web will be built on standardized discovery, accountability-as-code, and sub-second inference. This issue breaks down the frameworks helping builders navigate this transition without burning their budgets or losing their context.
Google, NVIDIA, and GitHub Launch ARD Specification to Standardize Agentic Web r/PromptEngineering
A powerhouse coalition including Google, GitHub, and NVIDIA has officially released the Agentic Resource Discovery (ARD) specification, an open standard designed to dismantle the proprietary 'walled gardens' of current agent ecosystems. According to u/BarnacleAlert8691, the spec allows agents to dynamically locate and verify tools via a machine-readable /.well-known/ai-catalog.json file hosted on root domains. This discovery layer acts as a precursor to invocation protocols like MCP or A2A, ensuring that agents find the right capabilities at runtime rather than relying on hard-coded connections.
The technical framework introduces a robust cryptographic verification model that anchors trust to DNS records. By mandating that authority anchors be valid Fully Qualified Domain Names (FQDNs), orchestrators can programmatically cross-reference domain ownership with a trustManifest to prevent malicious actors from claiming unauthorized namespaces. NVIDIA has further hardened this architecture by integrating OpenSSF Model Signing (OMS), which requires agents to verify skill signatures against a root certificate before execution.
Industry experts suggest that by standardizing how agents 'search' for resources, ARD addresses the fragmentation that has made building multi-agent systems feel like a '5000 piece puzzle while the power's out.' This move toward a machine-readable discovery layer is expected to streamline how orchestrators manage complex toolsets across disparate domains.
The 260 TPS Barrier: Kimi K2.7 and Unsloth Optimize Agentic Economics r/AI_Agents
Moonshot’s Kimi K2.7 Code High Speed variant is fundamentally shifting the unit economics of agentic pipelines, delivering 260 tokens per second on short-context tasks. This performance represents a 5x throughput increase over standard models at only 2x the cost, effectively lowering the 'latency tax' for high-volume routing, while Unsloth has pushed the local ceiling with DiffusionGemma, achieving 2000 tokens per second on just 18GB RAM as reported by u/BankApprehensive7612.
The MCP Bloat Crisis: New Servers and Strategies for Context Management r/mcp
The Model Context Protocol (MCP) ecosystem is rapidly expanding, but developers are hitting a 'hidden token tax' where servers like TickTick can add 15-20K tokens to a single message. To combat this, practitioners are rallying around SEP-1576 and utilities like 'Skill Router' to prevent agents from being overwhelmed by unoptimized schemas, as u/Emergency-Context-72 and Gil Feig of Merge warn that excessive tool descriptions are causing severe scaling problems in production.
Accountability-as-Code: Hardening the Agentic Budget and Governance Layer r/LangChain
As agents move into production, tools like AgentKavach and AgenRACI are emerging to solve the 'agentic tax' and the 'Change Budget' problem through hard budget limits and RACI matrix mapping. u/camerongreen95 identified 'Silent Tool Selection' as the most common failure mode, accounting for 40% of logic failures, prompting a shift toward specialized governance platforms that enforce permissions and idempotent tool design.
Beyond the 'Chat Graveyard': Scaling Context for 1M+ Token Codebases r/AI_Agents
u/Any_Focus2631 confirms 'drop-oldest' strategies result in 0% recall, leading to the rise of Rust-based context layers like BaseMind for high-speed codebase mapping.
Latency in Voice Agents: The Battle of the 'Listening Layer' r/aiagents
The LLM isn't the bottleneck; u/GrayZetsu notes that Voice Activity Detection and STT endpointing add 500ms-1000ms of silence to most agent interactions.
Breaking the 100 tok/s Barrier on Intel Arc r/LocalLLM
u/RagingNoper achieved 100 tok/s on Qwen3.6-35B using custom XPUGraph on Intel Arc GPUs, while u/lon1xxx successfully trained a neural network on a 4GB Android phone.
Discord Technical Deep-Dive
Local models are outperforming frontier giants in reliability as 'tool healing' becomes the new agentic standard.
The 'bigger is better' era is hitting a wall of practical reality, and the Agentic Web is responding with a pivot toward local resilience. This week, we are seeing a fascinating divergence: while frontier platforms like Perplexity are tightening the screws on compute-heavy 'Deep Research' with aggressive rate limits, the local community is building its own escape hatches. The real story isn't just the raw power of the Qwen 3.6 family or the efficiency of Liquid LFM 2.5; it is the emergence of 'tool healing.' We are entering a phase where models are expected to fix their own malformed JSON and identify their own hallucinations in real-time. For developers building autonomous agents, this reliability is the difference between a prototype and a production-ready fleet. Whether it is Cursor potentially leveraging xAI’s massive Colossus cluster for background 'agent workers' or practitioners doubling their local TPS through tensor parallel optimizations, the goal is the same: high-trust, low-latency execution. In this issue, we look at how the infrastructure of the agentic web is maturing to handle the 'quantization tax' without sacrificing the reasoning depth required for complex, multi-turn tasks.
The Rise of Local Agentic Resilience and Tool Healing
The local LLM community is shifting focus toward the Qwen 3.6 family, particularly the 27B dense model, which is being hailed for its efficiency-to-power ratio. wearifulpoet reports stable performance at 10 t/s on an M1 Pro using 3-bit quants, while technical evaluations from kaitchup suggest that MoQ support allows the model to maintain instruction-following even at extreme 1-bit configurations.\n\nBeyond raw throughput, the Liquid LFM 2.5 8B is emerging as a new standard for local reasoning, notably surpassing the older 24B variant with a 76.2% MMLU. Developers are praising its 'bullshit detection' and native 'tool healing'—a protocol that allows the model to autonomously fix malformed JSON or invalid API calls. This reliability makes it highly effective for complex system administration tasks, even when compressed to 4-bit quants on limited hardware like the Steam Deck.\n\nThis evolution is supported by Unsloth Studio's 'tool call healers,' which are now critical for maintaining functionality in models like Qwen 3.6 35B at ultra-low bitrates. By applying a 'repair' layer to ensure schema compliance, these healers allow 1.58-bit models to outperform much larger, unhealed models. As @unslothai notes, this shift suggests a future where model size is secondary to the quality of the orchestration and healing layers surrounding it.\n\nJoin the discussion: discord.gg/localllm
Cursor Prepares for Agent Worker Era with xAI
Speculation is intensifying regarding a rumored partnership between Cursor and xAI to integrate a variant of Grok-3. According to tomtowo, this collaboration could provide 10-20x more compute than the current Composer interface, potentially leveraging xAI's 100,000 H100 GPU Colossus cluster to power the leaked agent worker start command.\n\nJoin the discussion: discord.gg/cursor
Perplexity Pro Faces Backlash Over Rate Limits
Changes to Perplexity Pro usage limits are triggering widespread frustration as the platform throttles power users to as few as 3 to 5 'Deep Research' attempts per day. While the expected quota is 600 queries, updated documentation confirms that specialized reasoning tasks draw from a more restricted pool, pushing developers toward local RAG sovereignty.\n\nJoin the discussion: discord.gg/perplexity
Scaling Local Inference for Agentic Swarms
Practitioners are optimizing local hardware by disabling mmap and shifting to tensor parallel across dual 3090 setups to nearly double tokens-per-second. User eggfooyounguyen noted these gains are essential for models like Qwen 3.6, though bottlenecks in PCIe bandwidth—measured at 3.9GBps on Gen3 x4 lanes—continue to challenge multi-GPU configurations.\n\nJoin the discussion: discord.gg/localllm
GLM-5.2 Pulled from LMArena
The model has been removed from leaderboards following reports of 'hallucinatory loops' and reasoning regressions confirmed by lm_mod_4. Join the discussion: discord.gg/lmarena
Nano-Models for Edge TTS
Inflect-Nano-v1 delivers text-to-speech with just 4.63 million parameters, enabling sub-100ms latency on ARM-based devices with a tiny 10-15MB RAM footprint. Join the discussion: discord.gg/localllm
HuggingFace Open Science
Hugging Face pivots to Python-driven agents while local GUI models break throughput records.
We are witnessing a fundamental architectural shift in the agentic web. For the last year, developers have largely been forcing LLMs to output brittle JSON schemas to trigger tools—a process that is as inefficient as it is frustrating for production systems. This week, Hugging Face signaled the end of that era with the launch of smolagents, a framework that treats Python code as the primary action language. By moving to a 'Code-as-Action' philosophy, they are not just simplifying the developer experience; they are reporting a 30% reduction in operational costs and model steps. This isn't just about cleaner code; it’s about reliability and reasoning as validated by the GAIA benchmark.
While smolagents streamlines the logic, new hardware-aware models like Holotron-12B are addressing the speed bottleneck, pushing GUI interaction speeds to nearly 9,000 tokens per second. The message for builders today is clear: the path to production agents lies in high-throughput local execution and code-first orchestration. We are moving past the 'toy' phase and into standardized environments like OpenEnv that treat agents like reinforcement learning entities in the real world. This issue explores the tools making that transition possible, from industrial-grade benchmarks to minimalist 50-line agent implementations.
Hugging Face Redefines Agentic Efficiency with Code-First smolagents
Hugging Face has officially transitioned its agentic ecosystem from the experimental Transformers Agents 2.0 to a production-ready, minimalist library called smolagents. This shift marks a definitive move away from brittle JSON-based tool calling toward a 'Code-as-Action' philosophy, where agents execute Python snippets directly. This architectural change has yielded massive efficiency gains, specifically a 30% reduction in LLM steps and operational costs compared to traditional JSON-heavy orchestration methods smolagents.org.
The framework's effectiveness was validated on the GAIA (General AI Assistants) benchmark, where the Transformers Code Agent reached the top of the leaderboard, effectively 'beating' the benchmark's previous state-of-the-art scores by leveraging its ability to iterate on code-based actions huggingface/blog. The ecosystem now supports multimodal inputs via VLMs in smolagents and provides production-grade observability through Arize Phoenix integration.
OpenEnv Standardizes Agentic RL with First Reference Environments
The community is rallying around OpenEnv, a new initiative led by Meta’s PyTorch team and Hugging Face to build a unified open ecosystem for evaluating tool-using agents. The project addresses fragmentation in agentic Reinforcement Learning (RL) by providing a standard Gymnasium-style API that allows agents to interact with real-world software stacks rather than just isolated simulations [OECD.AI]. This movement signals a decisive shift toward training agents through environmental feedback, supported by the Agentic RL initiative, with early practitioners already using the stack to build poker-playing agents with Deepseek-v3 @ben_burtenshaw.
Local GUI Agents Break Throughput Barriers with Hybrid SSM Architectures
The landscape of Computer Use agents is shifting toward high-throughput local execution, led by the release of Holotron-12B and Holo3.1. Developed in collaboration with NVIDIA, Holotron-12B utilizes a hybrid SSM-Attention architecture that effectively solves the 'KV Cache' bottleneck, enabling generation speeds of 8,900 tokens/sec [ThursdAI]. In practical benchmarks, this architecture has propelled WebVoyager success rates from 35.1% to 80.5%, outperforming previous Qwen-based baselines and facilitating real-time GUI interactions [Hcompany].
Beyond Terminal Success: New Benchmarks Target Multi-Step Industrial Reasoning
IBM’s AssetOpsBench evaluates agents across six critical dimensions for industrial Asset Lifecycle Management, moving evaluation beyond simple lab settings to address the reliability gaps identified by 306 surveyed AI practitioners.
Open-Source DeepResearch Challenges Proprietary Search Agents
The Open-source DeepResearch initiative is closing the gap with proprietary tools by prioritizing transparency and cost-effective retrieval via the Tavily search API and specialized architectures like Tongyi-DeepResearch-30B.
NVIDIA and Qwen Release Agent-Optimized Edge Models
NVIDIA's Nemotron 3 Nano Omni unifies audio, vision, and language into a single 30B architecture to eliminate latency and context loss in multi-model pipelines on local hardware.
MCP and CLI Tools Simplify Agent Deployment
Hugging Face is leading deployment simplification with Tiny Agents, demonstrating that functional, MCP-powered agents can be built in as few as 50 lines of code for local execution.