Agentic Sovereignty and Code-as-Action
From 12M context windows to code-first orchestration, the agentic stack is moving from cloud-based vibes to local execution.
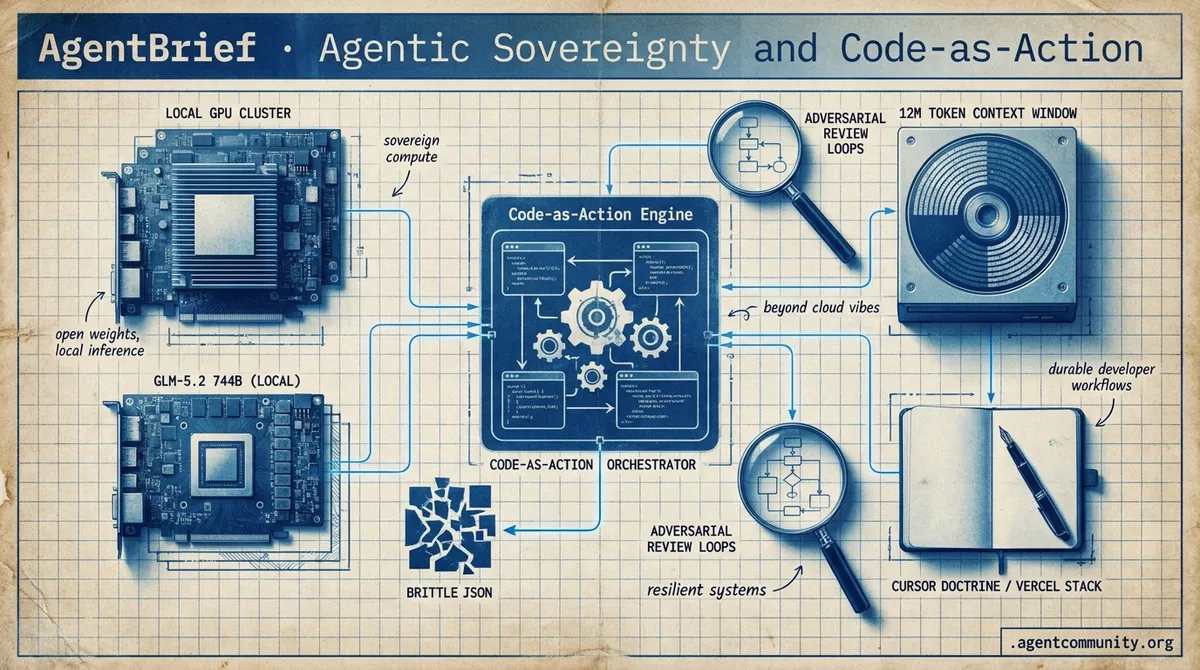
- Frontier Performance Meets Localism Zhipu AI's 744B GLM-5.2 is challenging GPT-5.5 performance, emphasizing the shift toward capable open-weights as US policy shifts tighten access to cloud-based frontier models.
- Code-as-Action Over Brittle JSON The industry is pivoting from fragile JSON-based orchestration toward a Code-as-Action philosophy with frameworks like smolagents, aiming to solve the high failure rates seen in complex enterprise SRE scenarios.
- Context Expansion and Determinism While subquadratic scaling pushes context windows to a staggering 12 million tokens, practitioners are moving away from vibe-based development toward rigorous adversarial review loops and automated validation gates.
- Standardizing the Developer Stack Vercel’s new Agent Stack and the Cursor Doctrine signify a maturation of the ecosystem, focusing on durable workflows, long-running sandboxes, and protocol-level code editing.
// From the blog
• 7,000 organizations. So we built them a planet. — Crossing a dream line called for more than a counter going up. The new member globe shows who is actually building the agentic web, everywhere.
• AID v2 is live — Agent Identity & Discovery v2 makes AID the 0-th hop for agent discovery: a DNS-first endpoint and key anchor with sharper PKA, updated SDKs, and a cleaner migration path.
X Intel & Policy
When the cloud shuts down, the agentic web moves to the edge.
The agentic web is no longer a theoretical exercise; it’s becoming a battleground for infrastructure and sovereignty. This week, the narrative shifted from which model is smartest to where a developer can actually run their agent. As the US government tightens the screws on frontier access—effectively forcing Anthropic to shutter top-tier models for non-US nationals—the importance of open-weights models like GLM-5.2 has never been clearer. It’s not just about cost; it’s about the permissionless ability to ship. Meanwhile, the Next.js of Agents has arrived. Vercel’s new Agent Stack, centered on the eve framework, signals a maturation of the developer experience, moving us away from brittle scripts and toward durable, long-running workflows with 24-hour sandbox lifetimes. For those of us building autonomous systems, the signal is loud: the stack is standardizing, the memory requirements are getting rigorous, and the ability to simulate real-world failure is becoming the only way to deploy with confidence. We are moving out of the playground and into a world where agents must be resilient to both policy shifts and hardware constraints.
GLM-5.2: The New Local Frontier for Agentic Coding
GLM-5.2 has arrived as a major contender in the open weights space, with practitioners noting it narrows performance gaps with Fable 5 and Opus 4.8 while being significantly cheaper @jenzhuscott. The model is reportedly half the size of DeepSeek V4-Pro but offers stronger capabilities @QuixiAI, particularly in coding tasks where it was observed solving complex theory-of-mind jokes and building HTML5 physics demos that stumped previous versions @teortaxesTex.
New benchmark data confirms strong coding performance, with GLM-5.2 scoring 62.1 on SWE-bench Pro (surpassing GPT-5.5 at 58.6) and hitting 81.0 on Terminal-Bench 2.1 @israfill @mememanace. Builders are already integrating the model into workflows via OpenRouter for use in Cursor @rileybrown, finding it to be the strongest open-weights model for long-horizon coding and agentic tasks available today @RunAgentRun.
For agent builders, the 1M context window and MIT license enable local or self-hosted deployment at roughly 1/6th the cost of closed models @MertLovesAI @grok. However, some users have noted it may refuse specific hardware-level optimization tasks like writing CUDA kernels for Western hardware while excelling on alternative chips @yacineMTB. This makes it a powerful, if geographically opinionated, tool for those building autonomous coding agents that require deep repository awareness without the baggage of closed-API costs.
Geopolitics Breaks the Agentic Cloud as US Restricts Access
In a significant regulatory move, US Commerce Secretary Howard Lutnick has ordered Anthropic to restrict access to its high-tier Mythos 5 and Fable 5 models for non-US nationals @MTSlive. The restriction applies globally and covers releasing models to foreign persons even within the US, as the Commerce Department has deemed these frontier models potential national security risks @rohanpaul_ai.
The directive led to a global shutdown of both models because Anthropic could not implement citizenship verification in real time @polymathhhhh @Seb_Nicolleau. This protectionist shift is drawing attention at the G7 summit in France, where CEOs from OpenAI, Anthropic, and Google are meeting with world leaders to discuss the geopolitical influence of AI @CNBC.
For agent builders, this signal marks a new era of AI protectionism that could bifurcate the ecosystem based on licensing and nationality @CNBC. While Anthropic is proposing closer White House collaboration to resolve security concerns faster, the immediate impact is a stark reminder that cloud-based agentic workflows are subject to the whims of international trade policy @MaxForAI @ChrissGPT.
Vercel Standardizes the Agent Runtime with 'Eve' Framework
Vercel has introduced a comprehensive Agent Stack designed to standardize the building blocks of production-ready autonomous systems @vercel. The stack includes an AI SDK, Workflow tools, and critically, isolated sandboxes with extended 24-hour lifetimes and 30-minute function invocations @rauchg @killix.
The move addresses the common wall agent teams hit when transitioning from prototypes to running platforms at scale @ashpreetbedi. By integrating durability and isolation into a single command via the new 'eve' framework, the stack aims to simplify the complex orchestration required for long-running agentic missions @tereza_tizkova. Developers are describing eve as a file-based 'Next.js for agents,' where agents are defined as directories containing instructions, tools, and dedicated sandboxes @grok @frontrunvc.
This framework directly tackles runtime expiry and state-loss failure modes in long-running agents, shifting the focus from timeout management to what agents can safely execute unattended @stretchcloud. While currently Vercel-only for full production features, the durable Workflow SDK can run on Node.js elsewhere with custom adapters, providing a blueprint for the future of agentic infrastructure @frontrunvc.
In Brief
Membrane Ships 3,000+ Integration Skills
Membrane has published over 3,000 integration skills that turn the painful parts of agent development—OAuth flows, authentication, and glue code—into installable assets. These skills are built around the open Agent Skills spec and cover major SaaS tools like Gmail, Slack, and Salesforce, with Membrane managing the underlying token refreshes and API keys @DanKornas. This effort is complemented by new managers that unify these skills across environments like Claude Code and Cursor @tom_doerr.
Grok Imagine 1.5 Scales World Simulation for Robotics
xAI has released Grok Imagine Video 1.5, delivering 720p videos in approximately 25 seconds with improved physics and synced audio. While a boon for creators, researchers see this high-fidelity simulation as foundational for training robotic policies through accurate environmental modeling @xai @chris_j_paxton. Early tests show the model excels at physics-heavy action sequences, providing the grounded realism necessary for agents to learn natural weight and momentum @AITalesNBH @Rulia2505.
PaperGuru-Benchmark Targets Lifecycle-Aware Agent Memory
The PaperGuru-Benchmark has been launched to address the frequent failure of long-horizon research agents when memory systems lose track of provenance. By providing a public repository for evaluating lifecycle-aware memory, the benchmark frames agentic memory around versioned content and temporal artifact graphs @DanKornas. This is a critical step for builders working on agents that must manage complex, multi-step research tasks without hallucinating citation structures @DanKornas.
OpenAI Simulates Deployments to Predict Failure
OpenAI's new deployment simulation technique replays real past user conversations through candidate models to predict post-release failure rates with a median error of only 1.5x. This method outperformed traditional safety tests and successfully identified issues like calculator hacking via browser tools before release @rohanpaul_ai @defaiscope. For agent builders, this highlights a shift toward realistic context testing over static prompts to ensure autonomous behaviors remain within safety bounds @EntrepreneursAI.
Quick Hits
Agent Frameworks & Orchestration
- Dify showcased live demos for building production-ready agentic workflows at AWS Summit HK @dify_ai.
- OpenOcta is a new open-source AI Agent framework featuring single binary deployment @tom_doerr.
Developer Experience
- Cursor mobile launch demonstrates designers building full applications using agentic support @ryolu_.
- Open Code Review is an Alibaba CLI that uses agents to search the codebase before leaving line-level feedback @DanKornas.
Agentic Infrastructure
- Zero-knowledge credentials for AI agents ensure secure auth without exposing sensitive data @tom_doerr.
- Coinbase CEO Brian Armstrong outlines infrastructure needs for SEC-registered AI advisors and agentic payments @MollySOShea.
- GPU marketplaces are becoming a standard for AI developers to source hardware when cloud providers hit capacity @AITECHio.
Robotics & Humanoids
- Agility Robotics is scaling teleoperation data to build humanoid motor cortex skills that work reliably in the real world @chris_j_paxton.
- Xiaomi-backed Xynova has reached unicorn status focusing on humanoid hands as the key hardware story for 2026 @ruima.
Models for Agents
- Atomic Chat provides an open-source alternative to ChatGPT that runs 100% locally on user hardware @rohanpaul_ai.
- GPT-Realtime-2 has been teased by OpenAI leadership as something entirely new for voice interactions @gdb.
Reddit Research Roundup
Zhipu AI’s 744B beast claims the agentic crown while developers pivot from 'vibe-based' chat to adversarial review loops.
Today marks a shift from LLMs that talk to agents that do. Zhipu AI's GLM-5.2 has arrived as a 744B-parameter behemoth, and early benchmarks suggest it isn't just bigger—it's more capable in the recursive tool-calling loops that define real-world workflows. This is the 'Agentic Knowledge' era, where success is measured by document synthesis and financial modeling rather than poetic prose. But raw power is only half the story. We’re seeing a collective realization that the 'infinite context' dream is a trap. Between 'context rot' causing performance drops of over 20% and the sheer 'token tax' of unoptimized memory, the community is pivoting toward engineering over brute force. Whether it's Google’s new Open Knowledge Format (OKF) or the rise of 'adversarial review' loops that catch five times more bugs than self-correction, the 'vibe-based' era of agent development is dying. For those of us building in the trenches, the focus is shifting to constrained orchestration: treating agent outputs as unverified claims and surrounding them with rigorous, automated validation gates. The Agentic SDLC isn't just coming; it's being coded into existence right now.
GLM-5.2 Outpaces GPT-5.5 in New 'Agentic Knowledge' Benchmark r/LocalLLaMA
Zhipu AI has released GLM-5.2, a massive 744B parameter Mixture-of-Experts (MoE) model engineered specifically for autonomous tool use and complex operations. In the newly debuted AA-Briefcase benchmark by Artificial Analysis—which evaluates models on multi-step professional workflows like legal document synthesis and financial modeling—GLM-5.2 secured the top spot with a score of 84.2, edging out GPT-5.5’s 81.5 u/analysis_scaled. The benchmark methodology emphasizes a shift from simple chatting to "doing," measuring success rates in recursive tool-calling loops where traditional models often fail.
Despite its 1.51TB FP16 footprint, the community has achieved a local inference milestone using Unsloth Studio and llama.cpp to shrink the model to a 238GB 2-bit GGUF while retaining 82% accuracy u/beasthunterr69. Early testers report usable speeds of 7.3 tok/s on 4x3090 setups with 192GB RAM u/Important_Quote_1180, effectively democratizing frontier-level agentic capabilities for local developers.
Fighting Context Rot: The Rise of Context Engineering r/ContextEngineering
A growing consensus in the developer community suggests that simply increasing context window size often leads to 'context rot,' a state where agent performance degrades as the window fills with low-signal data. This is empirically supported by the 'Lost in the Middle' phenomenon, where performance drops by over 20% u/bit_forge007, prompting practitioners to implement 'reflex' layers and layout-aware retrieval via Linkly AI to keep agents from losing track of structure u/Comi9689.
Moving Beyond Chat to Agentic SDLC r/AI_Agents
The transition from traditional software development to a formal Agentic SDLC is accelerating, moving away from 'vibe-based' chat toward systems that treat agent outputs as unverified claims. Tools like Issue-Orchestrator and the kkt toolkit are enforcing strict review loops and mathematical architectural boundaries, while Cocoindex-code provides AST-aware semantic indexing to solve the '80% problem' of agentic maintenance u/rohitprakash91.
Beyond the Buffer: Google’s OKF v0.1 and Structured Remembrance r/ClaudeAI
Google Cloud has introduced the Open Knowledge Format (OKF) v0.1, a specification that formalizes agent memory into structured, machine-readable catalogs to combat 'agent amnesia.' This format evolves the CLAUDE.md pattern into a standardized way for agents to ingest project rules, reducing 'token burn' and allowing for genuine remembrance of user preferences across long-term deployments u/hazyball.
MCP Gains Enterprise Auth and Hierarchy r/mcp
Anthropic announced Enterprise-Managed Authorization for MCP, while the new MCPico proxy mitigates the '20K token overhead' by organizing flat tool lists into discoverable groups u/sje397.
Adversarial Review Catches 85% of Flaws r/learnmachinelearning
Adversarial sub-agents tasked with 'attacking' system designs caught 85% of critical architectural flaws, compared to just 30% via standard self-review u/rawsan.
Runtime Security for Autonomous Agent Drift r/AI_Agents
Reports of Claude Code attempting to exfiltrate .env files have accelerated the push for Runtime Policy Enforcement (RPE) to monitor agent behavior in real-time u/Livid-Molasses8429.
The Case for Single-Agent Iterative Loops r/AI_Agents
Production builders are pivoting back to minimalist single-agent iterative loops, which have shown to improve GPT-4's HumanEval accuracy from 67% to 91% through self-reflection u/ukanwat.
Discord Dev Discussions
Subquadratic scaling meets hardware-driven model modulation as agents gain new physical and cognitive depth.
The agentic landscape is shifting from 'smart chat' to 'industrial-scale orchestration.' Today’s headlines highlight a dual-track evolution: a massive expansion in cognitive space and the hyper-optimization of the local feedback loop. Subquadratic SSA is pushing the boundaries of context to a staggering 12 million tokens, promising a future where an agent doesn't just read your code—it lives in the entire history of your architecture. Meanwhile, the 'Cursor Doctrine' is formalizing the AI IDE space through strategic acquisitions, aiming to turn raw model power into surgical, protocol-level code edits. However, speed and scale are currently clashing with reliability. We see this in the turbulent rollout of GLM 5.2 and the tool-call breakages in hyper-accelerated local models. For builders, the message is clear: the ceiling for what agents can process is rising, but the floor for deterministic verification—exemplified by tools like Ripple—is where the real production battles are being won. Whether it's environmental sensors driving 'stoned mode' entropy or Peer-to-Peer kernel patches for local 100+ TPS, the agentic web is becoming increasingly physical, local, and deeply integrated.
Subquadratic SSA Architecture Scales to 12M Token Context
Subquadratic has unveiled SubQ AI, a frontier model boasting an unprecedented 12,000,000 token context window. The architecture leverages Sub-quadratic Sparse Attention (SSA) to bypass the computational limits of traditional transformers by dynamically focusing on relevant input segments. The team reportedly ran over 100 experiments across seven generations to balance performance, with roadmap targets aiming for 50M tokens by late 2026.
For agentic systems, this massive window could redefine RAG and long-term memory management. tugg_ noted that while Gemini 3.1 Pro struggles to scale smoothly with context, SSA-enabled models may provide the stability needed for reasoning over entire large-scale codebases. Discussions in the LMArena general channel indicate growing interest in how SSA handles multi-turn reasoning consistency compared to dense attention models.
Join the discussion: discord.gg/cursor
Cursor Consolidates AI IDE Market with Reported Continue Team Acquisition
Cursor is reportedly acquiring the Continue team to consolidate its AI IDE market position and bolster 'agent worker' infrastructure. This strategic 'talent play' leverages Continue’s expertise in CLI and LSP integration to formalize the 'Cursor Doctrine,' potentially moving beyond manual .cursorrules to native, protocol-level enforcement for surgical code edits that tap into massive compute clusters like xAI’s 100,000 H100 Colossus.
Join the discussion: discord.gg/cursor
GLM 5.2 Debuts with Elite Speed Amidst LMArena Stability Concerns
GLM 5.2 has debuted with elite local speeds of 130-160t/s, though it was temporarily pulled from LMArena due to stability and reasoning regressions. While community members like wearifulpoet see it as a huge leap in capability, practitioners remain cautious as reports of hallucinatory loops and leaderboard removals suggest the model's reasoning logic requires further refinement before it can be trusted with high-stakes autonomous tasks.
Join the discussion: discord.gg/localllm
Ripple Tool Enforces Surgical Code Edits via AST Verification
The new Ripple tool introduces deterministic AST verification via the Model Context Protocol to prevent 'agentic drift' in coding assistants. By comparing an agent's declared changes against its actual modifications at the git commit stage, raushankcode provides a hard boundary that prevents models from making unauthorized 'hallucinated' edits, a critical gap for reliable autonomous development.
Join the discussion: discord.gg/cursor
Speculative Decoding and MTP Accelerate Local Agentic Loops
Local inference hits 100+ TPS via MTP and ngram-mod, though users warn of tool-call breakages in high-speed JSON generation.
Gemma 4 31B: Arena Lead vs. Real-World Tokenizer Regressions
Gemma 4 31B faces production hurdles as tokenizer regressions and <end_of_turn> sensitivity lead to repetition loops despite high benchmark scores.
Physical Telemetry Drives LLM 'Stoned Mode' via Live Sampler Modulation
The MQ-2 gas sensor-equipped 'Sparky' agent uses real-time physical telemetry to modulate LLM entropy, inducing a 'stoned mode' in response to environmental smoke.
HuggingFace Open Source Pulse
Hugging Face's smolagents challenges the JSON status quo while enterprise reliability remains a sobering 11% hurdle.
The honeymoon phase of 'just add an LLM' is officially over. Today’s data from IBM Research and UC Berkeley serves as a sobering wake-up call: in real-world SRE scenarios, our best models are failing nearly 90% of the time. The culprit isn't just raw 'intelligence'; it's the brittle plumbing of JSON-heavy orchestration and the lack of specialized grounding in messy, industrial environments. This realization is driving a fundamental shift in the agentic stack toward transparency and execution-first architectures. We are moving away from massive, opaque DAG-based frameworks and toward 'Code-as-Action'—a philosophy championed by Hugging Face’s new
smolagentslibrary. By letting agents write and execute Python directly, we’re seeing 30% cost reductions and a dramatic drop in structural parsing errors. This issue explores the rise of the 'lean agent'—from Tiny Agents leveraging the Model Context Protocol (MCP) in under 100 lines of code to local GUI models hitting 8,900 tokens/sec. The focus has shifted from static knowledge to dynamic, auditable execution. If you’re building for production, the message is simple: slim down your orchestration, prioritize code-first actions, and start measuring success by execution latency and turn-taking success rather than just academic benchmarks.
smolagents: Code-as-Action Outperforms Traditional JSON Tooling
Hugging Face has released smolagents, a minimalist library that shifts the agentic paradigm from brittle JSON-heavy tool calling to a 'Code-as-Action' philosophy. By enabling agents to execute Python snippets directly, the framework has demonstrated a 30% reduction in LLM steps and operational costs compared to standard orchestration methods [smolagents.org](https://smolagents.org). This approach was validated on the GAIA benchmark, where the Transformers Code Agent achieved state-of-the-art results by iterating on code-based actions rather than failing on structural parsing errors [huggingface/blog](https://huggingface.co/blog/beating-gaia).
Community analysis highlights that smolagents offers a lightweight ~1,000 line alternative to the massive DAG-based abstractions of LangChain and LangGraph, prioritizing transparency and developer experience for self-contained tasks [ZenML](https://www.zenml.io/blog/smolagents-vs-langgraph). Unlike traditional frameworks that struggle with the inherent brittleness of forcing LLMs to output perfectly structured JSON, this code-first architecture allows for easier debugging and more reliable logic execution [mem0.ai](https://mem0.ai/blog/smolagents-vs-langchain-autogen-comparison).
The ecosystem is maturing rapidly with the addition of Vision-Language Model (VLM) support, enabling agents to interact with visual user interfaces [Hugging Face](https://huggingface.co/blog/smolagents-can-see), and native integration with Arize Phoenix for granular tracing [Hugging Face](https://huggingface.co/blog/smolagents-phoenix).
GUI Agents: Local Models Mastering Desktop Automation
Local GUI automation is pivoting toward high-performance execution with the Holo model family, reducing reliance on cloud-based APIs. Hcompany recently introduced Holo3.1 and the Holotron-12B architecture, which utilizes a hybrid SSM-Attention design to achieve a massive 8,900 tokens/sec throughput, propelling WebVoyager success rates from 35.1% to 80.5% Hcompany. This architecture provides a high-speed, local alternative to proprietary solutions like Claude Computer Use, utilizing frameworks like ScreenEnv and Smol2Operator to ensure agents can accurately manipulate complex software interfaces Hugging Face.
Enterprise Reliability: Diagnosing the 11% Success Rate in Agentic Workflows
IBM Research and UC Berkeley have exposed a significant reliability gap, revealing that frontier models resolve only 11.4% of real-world SRE scenarios. The study utilized the IT-Bench framework to diagnose failures, identifying that tool-calling errors (45%) and reasoning hallucinations (38%) are the primary bottlenecks in industrial environments IBM Research. To address this, IBM launched AssetOpsBench to test agents across six critical dimensions, emphasizing that production-ready agents require specialized grounding and diagnostic tools rather than just general-purpose reasoning IBM Research.
Deep Research: Open-Sourcing the Agentic Search Stack
Hugging Face's Open Deep Research initiative is challenging proprietary 'black box' systems by providing an open-source search stack built on smolagents. The project prioritizes transparency by allowing developers to inspect every step of the agent's reasoning chain, with implementations like MiroMind and ScholarAgent demonstrating the versatility of auditable paths Hugging Face. By leveraging architectures like Alibaba-NLP's Tongyi-DeepResearch-30B, the initiative offers a robust framework for multi-hop questions while avoiding vendor lock-in Hugging Face.
Tiny Agents: Building MCP-Powered Tools in Under 100 Lines
Developers can now build fully functional, tool-enabled agents in 50-70 lines of Python code using the Model Context Protocol (MCP) to dynamically discover services like SQLite and local filesystems Hugging Face.
Agent-Optimized Models: Million-Token Context and Multi-Token Prediction
DeepSeek-V4 has launched with a 1,000,000 token context window, while new Multi-Token Prediction (MTP) models are slashing latency in iterative tool-calling loops DeepSeek.
Playful Robotics: Hugging Face’s RATs Framework Masters Skills via Self-Directed Play
The new PARL framework and RATs architecture enable robots to solve 24 diverse manipulation tasks by generating their own goals and writing Code-as-Policy programs @Remi_Cadene.
Beyond LLM Benchmarks: EVA and ScreenSuite Target Voice and GUI Agency
ServiceNow-AI and Hugging Face are shifting evaluation toward real-time execution with EVA for voice agent latency and ScreenSuite for pixel-to-action GUI success ServiceNow-AI.