The Era of Sovereign Orchestration
Builders are ditching monolithic model calls for specialized swarms, 'Code-as-Action' patterns, and $7.4B war chests.
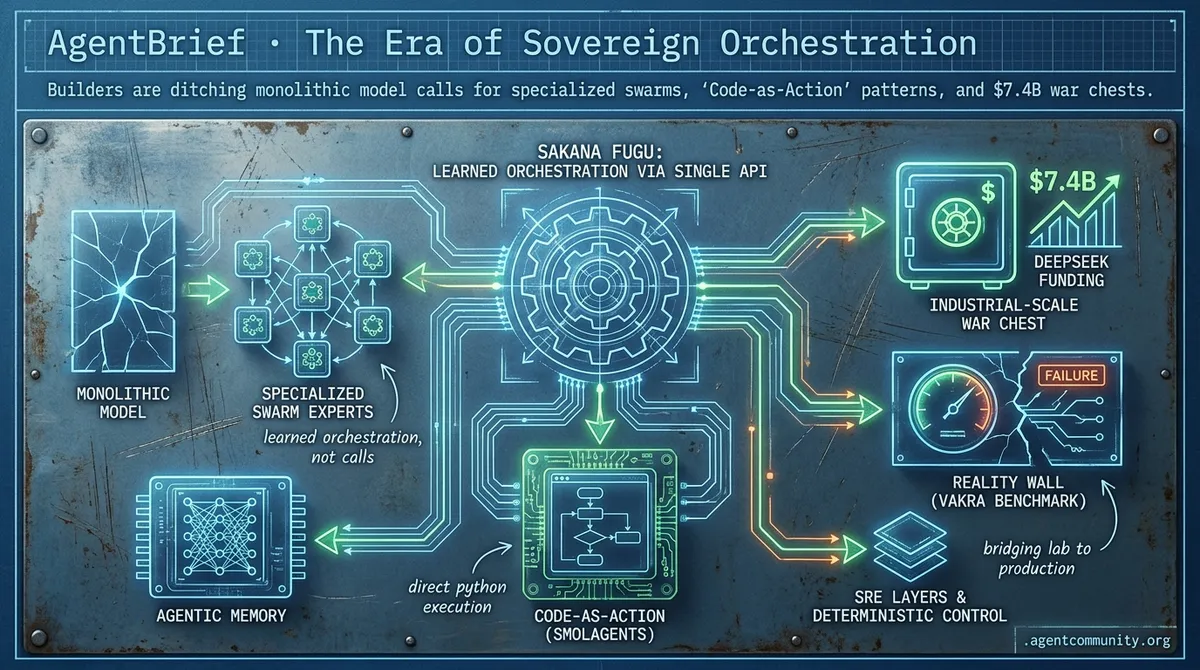
- Orchestration Over Monoliths The industry is shifting from monolithic model calls to learned orchestration, evidenced by Sakana AI’s Fugu Ultra hitting 73.7% on SWE-Bench Pro using a swarm of specialized experts.
- Execution-First Architectures Hugging Face’s smolagents is championing 'Code-as-Action,' replacing brittle JSON parsing with direct Python execution to eliminate hallucination-prone bottlenecks.
- Industrial-Scale Infrastructure DeepSeek’s $7.4B funding and the rise of tools like Cursor as an 'Agentic OS' signal a move toward production-hardened systems capable of extreme inference speeds and sovereign task routing.
- Confronting the Reality Wall As benchmarks like VAKRA expose significant failures in reasoning loops, the focus for practitioners has moved to SRE layers and deterministic control to bridge the gap between lab and production.
// From the blog
• 7,000 organizations. So we built them a planet. — Crossing a dream line called for more than a counter going up. The new member globe shows who is actually building the agentic web, everywhere.
X Intel Stream
Stop prompting models; start building ecosystems.
We are witnessing a fundamental shift in the agentic web: the transition from monolithic model worship to the era of the sophisticated orchestrator. For a long time, the strategy was to wait for the next frontier model to solve complex reasoning, but builders aren't waiting anymore. Sakana AI’s Fugu release is the klaxon for this change, proving that a swarm of specialized experts, managed by a learned conductor, can trade blows with the industry's heaviest hitters. This isn't just about chaining prompts; it's about building recursive, self-verifying systems that treat frontier models as mere components rather than the final product.
At the same time, the "boring" infrastructure of agent development is finally hardening. From the formalization of CLAUDE.md for persistent context to the emergence of JSON-first persistence layers like RushDB, the community is moving past the experimental CLI phase. We are now building for production—solving for multi-account authentication, world-model consistency, and parallel development workflows. Today’s issue isn't just about what agents can say; it’s about how they remember, how they interact across platforms, and how we orchestrate their collective intelligence to outpace any single model.
Sakana Fugu: Learned Orchestration via Single API
Sakana AI has unveiled Sakana Fugu, a full multi-agent orchestration system that behaves like a single model API, delivering frontier-level performance by coordinating a pool of expert models @SakanaAILabs. Unlike traditional hand-built agent setups, Fugu utilizes a 7B "Conductor" model trained via Reinforcement Learning (RL) to manage model selection, delegation, and verification automatically @openlabxorg. This architecture allows the system to match the benchmarks of monolithic giants like Fable and Mythos, achieving a 95.5 on GPQA-D and 73.7 on SWE-Bench Pro @TheSuperEng.
The community is already dissecting the trade-offs between this collaborative ecosystem and standalone base models. While @levie argues that these ecosystems are the next frontier, others like @RoundtableSpace point out that Claude Opus 4.8 can still outperform Fugu on quality and stability in specific edge cases. Pricing for the "Fugu Ultra" tier is set at $5/M input and $30/M output, though prompt caching at $0.50/M tokens offers a massive 10x discount for repetitive agentic workloads @grok.
For agent builders, Fugu represents a move away from manual prompt engineering toward recursive model calls. As @ChrissGPT noted, the system is particularly effective for tasks where simple prompts fail, as it can refine its own output by calling various LLMs within its pool. This shifts the developer's role from writing the perfect prompt to managing the constraints and pool of the orchestrator.
Hardening Claude Code for Production Agents
The developer community is rapidly formalizing best practices for Claude Code, moving it from an experimental CLI to a production-grade orchestration tool. New documentation highlights critical patterns including using 'plan mode' for verification and Git Worktrees for parallel development cycles @techNmak. This hardening of the toolset suggests a shift toward agents that don't just write code, but manage the entire lifecycle of a feature.
Power users are now advocating for specialized project briefs via CLAUDE.md to ensure every agent session starts with full context and a stable style guide @Krishnasagrawal. Community discussions confirm that this simple markdown file enables seamless project continuity across machines, reducing the need for repeated explanations by acting as a persistent memory for the agent @kitagrep.
By treating the CLAUDE.md as a persistent context layer, builders can maintain a consistent agent persona across different development environments. As @masonsiamond highlighted, this reduces the overhead of re-contextualizing the agent, making it feasible to jump between machines or team members without losing the agent's understanding of the codebase's specific requirements.
In Brief
New Infrastructure for Agentic Memory and Persistence
Managing agent state is shifting toward unified persistence layers like RushDB, which natively handles relationships and semantics through a single JSON-first endpoint @DanKornas. Designed to eliminate the glue code often required to stitch together multiple databases, RushDB supports managed embeddings that auto-index on future writes and offers MCP integration for direct use with tools like Claude and Cursor @DanKornas.
Research Warns of Limits in Agentic Rule Discovery
New research published on Arxiv suggests LLM agents struggle to turn evidence into stable world models when interacting with environments containing hidden, complex rules @rohanpaul_ai. The study utilized deterministic finite automata learning to show sharp performance drops as hidden structure scales, indicating that agents fail to use memory and feedback effectively to maintain a reliable model of their surroundings @dair_ai.
Executor v1.5.16 Adds Microsoft Graph and OAuth Support
Executor v1.5.16 is expanding the toolkit for agent builders by adding Microsoft Graph support, enabling agents to authenticate via OAuth across multiple accounts @RhysSullivan. The project positions itself as an 'agent cloud' that unifies disparate integration types while supporting multi-account sign-ins and seamless agent swapping without repeated logins @RhysSullivan.
Quick Hits
Agent Frameworks & Orchestration
- A curated index of over 340 AI agents and frameworks is now being updated monthly by @tom_doerr.
- Agent Forge has improved Resend API reliability and added Human-in-the-Loop capabilities via a Telegram bot @AITECHio.
Models for Agents
- DeepSeek successfully completed full-parameter post-training of the V4 Pro model on a 384-supernode cluster @teortaxesTex.
- Open source AGI is expected to accelerate as labs train fine-tuned models on Kimi and GLM data @bindureddy.
Tool Use & DX
- Codex users can now use 'appshots' to maintain visual state and context within their agent boxes @jxnlco.
- A new collection of verified skills allows users to turn Claude into a specialist for sales, legal, and product roles @tom_doerr.
Reddit Field Reports
Sakana AI’s Fugu Ultra hits a 73.7% SWE-Bench Pro score, signaling a shift toward multi-model orchestration.
We are witnessing the end of the "vibe-based" agent era. Today's synthesis points to a hardening of the Agentic Web, where monolithic model calls are being replaced by sophisticated, sovereign orchestration. Sakana AI’s Fugu Ultra isn't just another benchmark climber; its 73.7% SWE-Bench Pro score signals a transition toward "Sovereignty-First" systems that route tasks across heterogeneous model pools to optimize cost and performance. This is a direct response to the "agentic tax"—the reality that single-step success is a vanity metric if your multi-step reliability, or Pass^k, collapses in production. From Microsoft’s specialized 4B "scout" models solving the "terminal duty" problem to the rise of dedicated SRE layers like RiskKernel, the focus for builders has shifted from raw intelligence to deterministic control. Whether it’s navigating the bimodal biases of automated judges or moving toward "plan-approval" UX to prevent rubber-stamping, the infrastructure is finally catching up to the autonomy. This issue explores how these layers of reliability, memory, and local optimization are converging to make autonomous systems actually viable for the enterprise.
Sakana AI Launches Fugu Ultra r/AgentsOfAI
Sakana AI has officially launched Fugu, an OpenAI-compatible API designed to provide "AI sovereignty" through a dynamic orchestration layer. The flagship Fugu Ultra variant achieved a 73.7% score on the SWE-Bench Pro leaderboard, positioning it as a direct competitor to Anthropic’s Fable 5 and GPT-5.5 u/HeadWoodpecker5237. Unlike static endpoints, Fugu utilizes evolutionary routing logic to identify task complexity in real-time, delegating sub-tasks to a heterogeneous pool of open and closed models.
Technical practitioners highlight that Fugu's real innovation lies in its "Agentic Knowledge" retrieval, specifically its ability to manage complex CAD designs and large-scale GPU experiments through a unified interface u/y4mat000. This approach optimizes "Change Budgets" and maintains high-volume routing without the "context rot" typical of 1M+ token windows, effectively addressing the "agentic tax" through sub-second inference across a distributed model catalog.
Users on r/OpenAI emphasize the sovereignty aspect as a move to decouple from U.S.-centric infrastructure. By treating models as interchangeable sub-components, Fugu provides a robust contender for production-grade Agentic SDLCs where performance and infrastructure flexibility are non-negotiable.
The Pass^k Reliability Reckoning r/LLMDevs
The transition from Pass@1 to Pass^k is becoming the new gold standard for production reliability as developers realize single-step metrics mask multi-step failure. u/Substantial_Step_351 argues that agents running in loops face a "Reliability Tax," where a 90% single-step success rate drops to 59% over a 5-step trajectory. While frontier models like Gemini 3.5 Flash (42.4) lead traditional boards, Tau Bench reveals a significant gap in professional workflows, with Llama 3.1 405B achieving only 34.0 on the retail domain compared to Claude 3.5 Sonnet's 47.0 sierra-soft/tau-bench, confirming that success rates degrade exponentially as tool calls increase.
Microsoft Open Sources FastContext r/LocalLLaMA
Microsoft’s release of FastContext-1.0, a 4B parameter subagent, aims to solve the "terminal duty" problem by decoupling repository exploration from code generation. As noted by u/formatme, the model acts as a specialized "scout" that maps codebase structures to preserve the primary solver's context window. This hierarchical approach achieves 92% retrieval accuracy compared to the 74% ceiling of standard Vector-RAG, resulting in a 60-70% reduction in token overhead Hugging Face.
RiskKernel and Agentic SRE Layers r/AI_Agents
RiskKernel introduced an open-source SRE layer that enforces hard budgets, crash recovery, and approval gates to mitigate runaway loops and uncontrolled token spend u/Dry_Sport7254.
Shared Memory vs. Explicit Handoffs r/aiagents
The architectural debate intensifies as developers weigh the "state bleed" of shared memory against the auditable, type-safe trails of explicit handoffs in multi-agent systems u/GlitteringAngle8601.
Qwen 3.6 Hits 100 t/s via Tensor Splitting r/LocalLLaMA
Local agents reached 100.4 t/s on Qwen 3.6-27B by using row-wise tensor splitting to parallelize matrix multiplication across multi-GPU arrays u/Shoddy_Bed3240.
The Bimodal Judge Trap r/LLMDevs
Evaluator bias poses a risk to the Agentic SDLC as GPT-4o exhibits a bimodal distribution that penalizes minor trace errors, unlike Claude Opus 4's nuanced Gaussian scoring u/MysticLine.
The Failure of 'Rubber Stamp' Gates r/AI_Agents
Research indicates humans only catch bad agent actions 9–26% of the time, prompting a shift from granular action-approval to higher-level plan-approval UX u/brennhill.
Discord Dev Pulse
Massive funding meets swarm intelligence as the agentic stack moves local and deep.
The AI race is no longer just about who can build the biggest model; it’s about who can fund the most autonomous future. DeepSeek’s staggering $7.4B round, backed by $3B of founder Liang Wenfeng’s own capital, signals a massive shift toward specialized agentic infrastructure. This isn't just "compute spend"—it's a war chest for scaling the inference and orchestration layers necessary for true autonomy. Meanwhile, the tools we use are morphing. Cursor is transitioning from a code editor into an "Agentic OS," and models like Qwen 3.6 are introducing "Swarm Arena" learning, turning static inference into self-improving cycles. For practitioners, the message is clear: the "Agentic Web" is moving out of the lab and into high-stakes production. Whether it's achieving 64 tokens per second on a CPU or leveraging Odysseus for 1,000 t/s cloud orchestration, the focus has shifted to reliability, speed, and the ability to handle long-running, complex tasks without human intervention. We are witnessing the birth of the infrastructure that will power the next decade of autonomous systems.
DeepSeek Secures $7.4B to Fuel Agentic Ambitions
DeepSeek has finalized a landmark $7.4B funding round at a $60B valuation, cementing its status as a primary contender in the global AI race. Most notably, founder Liang Wenfeng contributed $3B of his own capital to the round, a move that signals intense internal conviction in DeepSeek’s trajectory. TrentBot noted that this funding secures DeepSeek's grip as China's AI rivalry heats up, providing the massive compute resources needed for next-generation agentic models.
The capital injection is earmarked for scaling inference infrastructure and optimizing multi-agent orchestration, building on the momentum of the DeepSeek-V3 series which has become a staple for autonomous workflows due to its efficiency LocalLLM general. This war chest allows DeepSeek to aggressively compete on cost and performance, potentially disrupting the current frontier giant hierarchy by doubling down on agent-centric optimizations SCMP.
Join the discussion: discord.gg/localllm
Cursor IDE Transitions to 'Agentic OS' with Composer 2.5
Cursor is rapidly evolving from a VS Code fork into a standalone agentic operating system, a shift punctuated by the release of the Agent Window and Composer 2.5 Fast. According to broken.wind, the new Composer 2.5 interface is "spammable" and maintains high reliability even during complex, long-running tasks, supported by proprietary models designed for deep GitHub integration. While speculation regarding a $500M funding round involving SpaceX remains unverified, practitioners suggest such a capital injection would explain the massive compute scaling required to hide the complexity of autonomous agent loops behind a streamlined interface Cursor Technical Keynote.
Join the discussion: discord.gg/cursor
Qwen 3.6 Pioneers Native Swarm Intelligence
The local LLM community is shifting focus toward Qwen 3.6, specifically the 35B A3B variant, which introduces a 'swarm arena' learning system. This architecture allows sub-agents to learn and refine reasoning during idle cycles, utilizing internal tokens to bypass the "quantization tax" that typically degrades performance in compressed models. .plunder claims the model is far ahead of existing options for local agentic deployment, especially when utilizing 1.58-bit configurations supported by Unsloth Studio's repair layers @unslothai.
Join the discussion: discord.gg/localllm
Odysseus Framework Emerges as 'Linux-Style' Hub
The Odysseus framework is gaining traction as a highly customizable, open-source alternative for managing local and cloud API keys for agentic loops. According to reeper_718_44101, the framework is a '10/10' solution for developers leveraging SambaNova Cloud, which delivers inference speeds verified at over 1,000 tokens/sec for Llama 3 models. This throughput allows for real-time 'tool healing' and complex multi-turn reasoning that remains responsive even under heavy workloads mnotgod96/Odysseus.
Join the discussion: discord.gg/lm-arena
Local Inference Performance Hits 64 Tokens Per Second
Local quants achieve 64 tok/s on CPU using A4B schemes, while Gemma 4 12B emerges as the stable reasoning choice for 12GB VRAM cards shawn__1001. Join the discussion: discord.gg/localllm
Markdown Conversion and Anti-Freeze Protocols Stabilize RAG
AgentKey prevents scraping freezes while LlamaParse improves RAG accuracy by converting complex PDFs into structured Markdown whizbeats. Join the discussion: discord.gg/n8n
HuggingFace Technical Deep-Dive
Hugging Face kills the JSON-parsing bottleneck while Holotron hits 8,900 tokens per second.
We are witnessing the death of the JSON-parsing agent. For years, developers have forced LLMs to act as translators between natural language and structured data, only to watch them hallucinate commas and break entire workflows. Today, Hugging Face is leading a pivot toward 'Code-as-Action' with smolagents, proving that letting agents write and execute their own Python snippets isn't just more natural—it's 30% more efficient. This architectural shift marks a move away from complex, brittle DAGs toward lean, execution-first systems.
This isn't just about orchestration; it’s about execution speed and diagnostic clarity. While smolagents simplifies the developer experience, Hcompany’s Holotron-12B is pushing GUI interaction to 8,900 tokens per second, making real-time desktop control a reality rather than a latency-filled dream. Meanwhile, new benchmarks like VAKRA are finally exposing the '11% reality wall,' showing exactly where our reasoning loops fail. The message for builders today is clear: stop over-architecting your prompts and start focusing on verifiable execution and specialized models that can handle the messy reality of production environments.
The Rise of Tiny Code-Centric Agents: Standardizing on Execution-First Orchestration
Hugging Face is fundamentally shifting the agentic paradigm with the release of smolagents, a minimalist library that replaces brittle JSON tool-calling with a 'Code-as-Action' philosophy. By allowing agents to write and execute Python snippets directly, the framework has demonstrated a 30% reduction in LLM steps and operational costs. This architectural pivot was validated on the GAIA benchmark, where the Transformers Code Agent reached the top of the leaderboard by bypassing the structural parsing errors that frequently derail traditional JSON-based orchestration.
The movement toward lean execution is further distilled in the Tiny Agents project, which enables developers to build fully functional, MCP-powered agents in just 50 lines of code. This shift away from complex, DAG-based architectures is supported by the release of dedicated agent libraries and agents-js, the latter of which brings production-grade agentic reasoning directly to browser environments.
For practitioners, the focus has moved from static prompting to dynamic execution, prioritizing transparency and reduced abstraction overhead. By treating code as the primary interface for action, Hugging Face is providing a path to more reliable autonomous systems that are easier to debug and significantly cheaper to run in production environments.
High-Throughput GUI Agents Reach Desktop Maturity
The frontier of 'Computer Use' is pivoting toward high-performance local execution with the release of the Holo3.1 and Holotron-12B models. Developed by Hcompany, the Holotron-12B architecture utilizes a hybrid SSM-Attention design to solve the 'KV Cache' bottleneck, achieving a massive 8,900 tokens/sec throughput and propelling WebVoyager success rates from a 35.1% baseline to 80.5%. This jump in speed, paired with standardized evaluation frameworks like ScreenSuite and ScreenEnv, allows developers to benchmark agents against real-world desktop environments with industrial-grade reliability.
Beyond Pass/Fail: The Rise of Diagnostic Agentic Benchmarking
As agents transition to production, evaluation metrics are shifting from simple accuracy scores to granular diagnostic frameworks that identify specific failure modes. Hugging Face recently introduced GAIA2 and the Agent Research Environment (ARE) to simulate real-world web interaction, while VAKRA provides a diagnostic lens into the '11% reality wall' of enterprise performance. VAKRA's analysis reveals that 45% of agent failures stem from tool-calling errors and 38% from reasoning hallucinations, helping developers solve the 'black box' problem of multi-hop SRE scenarios.
DeepSeek-V4 and NVIDIA Cosmos Reason 2 Push Context and Planning
DeepSeek-V4 introduces a 1,000,000-token context window with 100% recall, while NVIDIA Cosmos Reason 2 enables causal inference for physical AI task planning.
Standardizing the Open Agent Ecosystem
The OpenEnv initiative provides a Gymnasium-style API for RL-based agent training, complemented by a new Agentic Resource Discovery protocol for autonomous tool fetching.
Specialized Architectures for Tool-Calling and Logic
New models like the 27B osmFableQwopus and the 1.7B smolstruct are prioritizing multi-turn CoT and structured JSON output over general conversation.