The Shift to Stateful Agentic Execution
DeepSeek crashes token prices while the industry pivots from brittle JSON prompts to persistent, code-based execution.
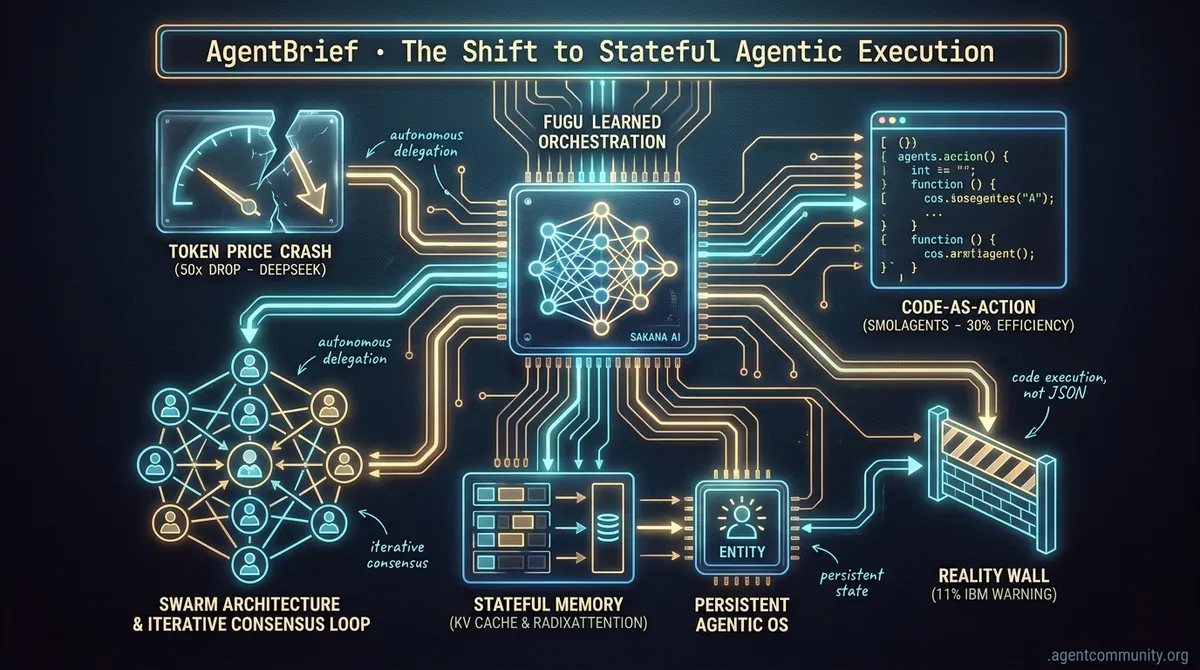
- Orchestration Moves to Weights Sakana AI's Fugu signals a shift from hard-coded if-else statements to trained orchestrators that delegate and verify autonomously.
- The Death of Token Scarcity DeepSeek's 50x price drop for frontier-level function calling enables iterative consensus loops and swarm architectures that were previously cost-prohibitive.
- Stateful Memory Breakthroughs Technologies like RadixAttention and KV cache persistence are transforming agents from ephemeral session bots into persistent Agentic OS entities.
- Execution Over JSON The move toward Code-as-Action via smolagents is slashing operational overhead by 30%, though IBM warns of an 11% reality wall in complex environments.
// From the blog
• 7,000 organizations. So we built them a planet. — Crossing a dream line called for more than a counter going up. The new member globe shows who is actually building the agentic web, everywhere.
X Intelligence Stream
Why your hand-coded agent graph is about to become a learned weights file.
The agentic web is shifting from brittle, hand-crafted state machines to learned, dynamic coordination. Sakana AI's Fugu represents a significant milestone: an orchestrator that isn't a script of if-else statements, but a trained model that knows how to delegate, verify, and recurse. For those of us building agents, this signals the end of the 'hard-coded workflow' era and the beginning of the 'orchestration-as-a-service' era. However, this intelligence comes with a steep toll. As we see runs hitting $2 per task, the focus for developers must pivot toward economic optimization and rigorous governance. We aren't just managing prompts anymore; we are managing high-volume, high-cost workloads that require specialized memory layers like RushDB and robust safety frameworks like Shield. The transition from 'cloud for humans' to 'cloud for agents' is happening now, and the tools we choose today—whether it's MCP gateways or self-hosted memory—will define the architecture of the 100x agentic economy.
Sakana AI Unveils Fugu Learned Orchestration
Sakana AI has launched Sakana Fugu, a multi-agent orchestration system that presents as a single model API while dynamically coordinating a pool of expert models. According to @SakanaAILabs, the system matches the performance of Fable and Mythos classes while delivering frontier capabilities without export control risks. Unlike traditional hand-built agent setups, Fugu utilizes a learned coordinator model trained specifically to manage delegation, verification, and recursive self-calls @rohanpaul_ai.
The architecture focuses on handling messy, multi-step tasks that go beyond a single prompt, with @altryne noting that the evals are remarkably high for a non-frontier lab. However, industry veterans like @teortaxesTex warn that a full cost analysis is needed, as throwing excessive tokens at problems via an orchestrator may not always outperform optimized best-of-n sampling.
Early independent tests show Fugu Ultra at $5/M input and $30/M output (with $0.50/M cached), but real-world runs have hit ~$0.51 per complex task and ~$2 per run (4x GPT-5.5). One user reported spending $30 in a single day @stretchcloud @VamsiBuilds. Pricing is confirmed on OpenRouter as $5.00 / $30.00 per 1M tokens for sakana/fugu-ultra @gptbotio.
For builders, this represents a shift toward recursive task delegation via an OpenAI-compatible endpoint, allowing for complex autonomous behaviors without manually managing every model handoff @beffjezos.
Infrastructure for the 100x Agentic Economy
As agents begin to use software significantly more than human users, a massive shift in infrastructure is required to prevent data leaks and incorrect state changes. @levie argues that enterprise platforms must be redesigned to support logging, auditing, and authoritative truth sources specifically for agentic queries. This transition requires a new class of governance that can handle queries pulling in more data in one task than a human touches in a month @grinich.
Key architectural questions are emerging regarding where these guardrails should live: whether they should be per-app, such as specialized Salesforce guardrails, or per-agent as they cross between applications @GregKamradt. Emerging open-source approaches include retrieval-based systems that adapt to attacks @sparshshahh and policy layers like Compass for budget and spend limits on coding agents @so_sthbryan.
Local enforcement tools such as Shield now sandbox actions like rm -rf or DROP TABLE @ScottAperionCTO, while projects like Bridgekit are releasing patterns for permissions and audit logs @royalpinto007. For developers, this means the 'Cloud for Agents' may eventually look more like a collaborative environment like Discord rather than a simple hosting provider like Vercel @RhysSullivan.
This infrastructure layer is critical for secure autonomous agent design, especially as new policy frameworks from groups like the R Street Institute emphasize the cybersecurity risks inherent in autonomous system autonomy @AgentBreak40737.
Mastering Advanced Workflows for Claude Code
Detailed best practices for Claude Code are emerging, focusing on moving from simple prompting to structured session management. @techNmak highlights the importance of 'Plan Mode' and the use of Git Worktrees for parallel development, while recommending the /loop command to schedule recurring maintenance tasks. To improve reliability, power users suggest initializing sessions with a CLAUDE.md file to load project rules and style guides immediately @Krishnasagrawal.
Additionally, developers are seeing success by creating verified 'Agent Skills' and using cross-model (Cl-Cl) reviews to catch bugs that the original agent might miss @tom_doerr. Community contributions are accelerating this: a widely shared open-source collection of 20 production-grade engineering skills paired with 7 slash commands works across Claude Code and similar tools @Saboo_Shubham_.
Other builders point to repositories like awesome-claude-code-plugins for hidden slash commands, proven MCP workflows, and custom agent setups that can be deployed in one evening @alifcoder @tom_doerr. This shift toward phase-wise gated plans suggests that the most effective agentic workflows are those that treat the agent as a junior engineer requiring structured oversight and clear verification steps @techNmak.
In Brief
New Memory and State Layers for Autonomous Agents
Infrastructure for agentic memory is maturing with the release of RushDB and self-hosted Mem0. RushDB serves as a database layer that converts JSON into graph relationships and semantic search, allowing agents to inherit files and permissions between runs, while Mem0 now supports self-hosting for durable, private memory surfaces @DanKornas @Teknium. These tools address the 'durable surface' problem, with users noting that hybrid vector-graph approaches outperform simple context stuffing and enable reliable multi-agent handoffs without repeated re-contextualization @stretchcloud @shesaidmewakeup.
Huawei and University Research Push Post-Training Frontiers
The DeepSeek team has reportedly completed full-parameter post-training of its V4 Pro model on a CloudMatrix 384 supernode. This achievement, utilizing Huawei Ascend hardware like the 910C cluster, represents a broader wave of Chinese lab experiments in post-training that persist despite performance-per-watt disadvantages versus U.S. clusters @teortaxesTex @MasterBaba. Debate continues regarding the necessity of reasoning traces, with some noting that leading models like DeepSeek R1 predated any public sharing of such data by major labs @bookwormengr.
Executor v1.5.16 Adds Microsoft Graph and Attachment Support
Executor v1.5.16 introduces native Microsoft Graph support, enabling agents to authenticate via OAuth across Microsoft 365 services. A new emit() function allows agents to output attachments directly into chats from Google and other integrations, serving as a unified MCP gateway that reduces the 'human routing problem' in complex deployments @RhysSullivan @RhysSullivan. Builders can now swap agents while preserving permissions and approvals without special config, supporting hot-reloading of new integrations @RhysSullivan.
Study Finds LLM Agents Struggle with Complex Rule Discovery
Research indicates that LLM agents' performance drops sharply as hidden environmental complexity increases in deterministic tasks. While agents can sometimes discover structures through interactive queries, they remain weak at planning effective queries and converting feedback into stable world models compared to classic automata-learning algorithms @rohanpaul_ai. Furthermore, introducing AI into professional workflows may erode human skills, as seen in a Polish medical trial where endoscopists' unaided detection rates fell by over 6% after AI assistance began @rohanpaul_ai @Vanarchain.
Quick Hits
Agent Frameworks & Orchestration
- A new monthly index categorizes over 340 AI agents and frameworks to help builders navigate the ecosystem @tom_doerr.
- Agent Forge has improved Resend API reliability and added human-in-the-loop capabilities via a Telegram bot @AITECHio.
- Visual drag-and-drop builders for agent workflows are becoming more common for rapid prototyping @tom_doerr.
Tool Use & Developer Experience
- Codex now supports 'appshots', allowing builders to quickly capture and iterate on agentic interface states @jxnlco.
- Developers can now expose hooks to let AI agents play and fuzz games for testing purposes @ThePrimeagen.
- Claude 3.5 Sonnet showed an emergent ability to guess tool capabilities by attempting to use a summarization tool on a new file format @QuixiAI.
Models for Agents
- DiffusionGemma models revise entire answers across rounds, making them harder to monitor via standard token streams @burkov.
- Zhipu AI is reportedly working on advanced models that could serve as specialized data sources for RL environments @teortaxesTex.
Reddit Sentiment Analysis
DeepSeek crashes prices by 50x while Anthropic fights a massive distillation war.
Today we are witnessing the Great Decoupling of intelligence and cost. On one side, the price of model interaction is hitting a floor so low it is effectively zero. DeepSeek's V4 Flash is delivering frontier-level function calling for pennies, enabling the 'swarm' architectures we have long discussed but could rarely afford. This isn't just a discount; it's a phase shift for agent developers who can now trade token efficiency for iterative consensus loops. On the other side, the value of that intelligence is being fiercely defended. Anthropic’s allegations against Alibaba reveal the industrial scale of 'distillation attacks'—where reasoning patterns are harvested like natural resources to fuel domestic competitors. For agent builders, the signal is clear: the moat isn't the model; it's the operational layer and the specialized memory you wrap around it. As the 'agentic tax' of high-volume requests evaporates, the bottleneck shifts to reliability and human-in-the-loop UX. We are moving from a world of 'how do I afford this?' to 'how do I control this?' This issue covers the shift from vector dumps to dynamic memory, the rise of task-aware 'postures,' and the experimental hardware clusters keeping local inference alive.
DeepSeek Flash Triggers a 50x Price Collapse r/AI_Agents
The release of DeepSeek V4 Flash is being hailed as a 'revolutionary' moment for agentic workflows, offering pricing of $0.01 per 1M input tokens—nearly 50x cheaper than current OpenAI or Anthropic frontier models u/BodybuilderLost328. This price gap is forcing a fundamental shift in design; instead of optimizing for token efficiency, builders are deploying "swarm" architectures where 100+ agents collaborate via iterative consensus loops for pennies u/ddxv.
Technical benchmarks on the Berkeley Function Calling Leaderboard (BFCL) show DeepSeek V4 Flash achieving 89.2% accuracy in nested JSON extraction, notably outperforming GPT-4o-mini's 84.5% in multi-step tool sequences r/AI_Agents discussion. This efficiency is driving major adoption, with reports that Microsoft is now utilizing DeepSeek to offload 40% of low-complexity intent classification for Copilot to manage the 'agentic tax' of high-volume requests u/ddxv.
Anthropic Accuses Alibaba of Massive Distillation Attack r/ClaudeAI
Anthropic has officially accused Alibaba Group's AI lab of orchestrating a large-scale 'distillation attack' to illicitly extract model capabilities via approximately 25,000 fraudulent accounts. The filing alleges the campaign targeted Claude’s proprietary reasoning patterns to harvest high-quality synthetic data for the Qwen model family, highlighting a growing conflict over model-based IP as competitors attempt to bridge the performance gap between frontier systems and open-weight models u/BeginningSink1094.
The Hard Part of Agents is Now Operations r/LLMDevs
The primary bottleneck for agents has shifted from initial development to 'Day 2' operations, with reliability and state management becoming the dominant challenges for production builders. Developers in r/LLMDevs report that eval costs can jump 3x when adding just a few new tools, prompting a rise in frameworks like Burr for state machine control and observability platforms like AgentOps that focus on tool-calling health and human-in-the-loop UX u/BedOk331.
Multi-Token Prediction: The 53% Speed Boost r/LocalLLaMA
Multi-Token Prediction (MTP) is delivering speed boosts of up to 53% in new Gemma 4 and Qwen 3.6 releases, though some practitioners warn of a potential 'precision tax' in complex reasoning tasks. While MTP helps reduce latency for real-time agentic interactions, some developers report that standard autoregressive versions may still produce superior findings in high-stakes code reviews u/Significant_Bar_460.
From Vector Dumps to Dynamic Feedback r/aiagents
Mem0 and Letta are replacing static vector dumps with tiered, OS-like memory hierarchies that use dynamic feedback to manage context bloat r/aiagents.
NVIDIA Nemotron-TwoTower: Diffusion Speed r/LocalLLaMA
NVIDIA's Nemotron-TwoTower uses a diffusion denoiser tower to achieve 30B reasoning depth with only 3B active parameters, slashing throughput costs for long-form planning r/LocalLLaMA.
Task-Aware Postures and SKILL.md r/ClaudeAI
The SKILL.md standard and coding-posture modes are achieving an 88% success rate in finding bugs by forcing agents into specialized mental frameworks r/ClaudeAI.
USB4 RDMA vs. The $16k Dell Tax r/LocalLLaMA
Experimental USB4 RDMA setups and M4 Mini clusters are emerging as local alternatives for agent orchestration as enterprise GPU cluster quotes reportedly double overnight r/LocalLLaMA.
Discord Dev Logs
Developers are ditching ephemeral sessions for RadixAttention-backed memory to build low-latency logic engines.
The era of the 'ephemeral agent' is ending. Today’s developments signal a massive shift toward stateful, persistent intelligence. We are seeing the rise of the 'Agentic OS,' where memory isn't just a retrieval-augmented search, but a deeply integrated logic core. The breakthrough in KV cache persistence via RadixAttention is transforming agents from simple prompt-response machines into complex behavior trees that retain their 'persona' and planning state across cycles.
This movement is mirrored in the tooling layer, with Cursor’s 'Max Mode' pushing context limits to 1M tokens and AgentKey consolidating the fragmented API stack. For builders, the message is clear: the bottleneck is moving from raw model capability to context utilization and system architecture. Whether it's managing 'node debt' in orchestration or mitigating thought loops in smaller models like Gemma, the focus has shifted to the infrastructure that keeps an agent coherent over time. We are no longer just building bots; we are architecting autonomous memory systems that can navigate the live web with the same persistence as a human developer.
KV Cache Persistence Enables Persona-Conditioned Agents
Developers are leveraging KV cache persistence to transform agents into low-latency logic engines. By utilizing RadixAttention, a technique pioneered by SGLang, systems can achieve up to 5x higher throughput by sharing and reusing the KV cache for common prefixes according to @lmsysorg. This approach is central to 'persona-conditioned' agents; singulardev87 reported loading a 500MB Qwen 2.5 model with a 'Hunter Persona' directly into its memory core, allowing the AI to function as a real-time behavior tree.
This shift toward 'AI as the Behavior Tree' is supported by research into LLM-generated logic structures that store planning as memory snapshots, as seen in arXiv:2409.10444. Furthermore, vLLM’s automatic prefix caching has been verified to reduce first-token latency in multi-agent swarms, enabling responsive autonomous behavior on consumer-grade hardware according to vLLM.
Join the discussion: discord.gg/huggingface
Cursor MCP Browsers and 'Max Mode' Scale Agentic Web Access
The Cursor developer community is increasingly leveraging the Model Context Protocol (MCP) to bypass traditional scraping obstacles and unlock 1M token context windows. vraestin reports that agents using MCP-integrated browser tools can successfully navigate Cloudflare-protected sites, while kleosr confirmed that 'Max Mode' allows models like Gemini 1.5 Pro to maintain coherence across massive, multi-file architectures without the performance degradation typically seen in standard context windows.
Join the discussion: discord.gg/cursor
Qwen AgentWorld Framework Debuts with Focus on Swarm Orchestration
Weights for the Qwen AgentWorld framework have officially arrived on Hugging Face, centering on the Qwen 2.5-Coder-8B-Instruct model's superior performance in logic-heavy agentic tasks. According to therealkenc, the framework’s integration with the 'Swarm Arena' allows sub-agents to autonomously refine reasoning paths during idle cycles, while technical comparisons from camollo5602 show the 8B variant outpaces standard 14B models in multi-step tool-calling accuracy.
Join the discussion: discord.gg/huggingface
AgentKey and OpenClaw: Consolidating the Agentic API Stack
A new pattern is emerging around AgentKey, a consolidated MCP server providing unified access to social and web data to prevent 'scraping freezes' and configuration bloat. xpes2273 successfully implemented this in a Telegram bot to avoid juggling separate credentials, though security practitioners like scamir warn that centralizing keys necessitates deterministic firewalls to prevent exfiltration.
Join the discussion: discord.gg/n8n
The CUDA Moat and Hardware Gaps
Practitioners on r/localllama are finding that LLMs still struggle to automate the hardware gap between CUDA and alternative silicon due to the lack of training data for custom low-level kernels.
Join the discussion: discord.gg/ollama
Prioritizing System Design Over Node Sprawl
Experts like cephalik_ are urging builders to use pseudocode and modular sub-workflows to prevent 'node debt' from ballooning during autonomous agent iteration.
Join the discussion: discord.gg/n8n
Mitigating Gemma Thought Loops
Developers are using cosine similarity thresholds and repetition penalties to break infinite logic cycles in Gemma-based agents performing multi-turn reasoning.
Join the discussion: discord.gg/ollama
HuggingFace Research Hub
From Hugging Face's code-as-action to IBM's 11% reality wall, the agentic web is moving past brittle JSON and into raw execution.
We are witnessing a fundamental shift in how agents operate: the move from 'asking' to 'doing.' For too long, agentic orchestration was a fragile dance of JSON parsing and prompt engineering. Today, the industry is pivoting toward 'Code-as-Action.' Hugging Face’s smolagents is leading this charge, demonstrating that direct Python execution can slash operational steps by 30% and finally crack benchmarks like GAIA. However, the path to enterprise-grade autonomy remains steep. IBM’s latest research highlights an '11% reality wall'—a sobering reminder that while our models are getting faster, they still struggle with the noisy, long-horizon tasks found in real-world site reliability engineering. Tool-calling errors and reasoning hallucinations remain the primary bottlenecks.
The solution seems to be coming from two directions: massive context and specialized reasoning. DeepSeek-V4’s 1M token context window and NVIDIA’s Cosmos Reason 2 suggest that memory and causal inference are the next hurdles to fall. For developers, the message is clear: the 'Agentic Web' is no longer a theoretical layer; it is an execution layer, and the tools to build it—from MCP to OpenEnv—are finally reaching maturity. We are moving beyond simple pass/fail metrics and into the era of granular, diagnostic evaluation of autonomous systems.
Hugging Face smolagents Expands with Vision and Observability
Hugging Face is aggressively expanding its agentic ecosystem with the evolution of smolagents, a library focused on the 'Code-as-Action' philosophy. By replacing brittle JSON tool-calling with direct Python execution, this approach has demonstrated a 30% reduction in LLM steps and operational costs. Recent updates introduce native support for Vision Language Models (VLMs), enabling the VisionCodeAgent to process visual inputs directly within the framework to perform complex multi-modal tasks Hugging Face. To address the 'black box' problem in autonomous workflows, a new integration with Arize Phoenix allows developers to trace and evaluate agentic loops with high granularity using OpenInference standards.
The ecosystem's specialized reasoning capabilities are further highlighted by DeepMath, a lightweight math reasoning agent built on smolagents that achieves competitive performance without massive parameter counts. This shift toward code-writing agents is empirically validated by the Transformers Code Agent, which topped the GAIA benchmark by bypassing the structural parsing errors that frequently derail traditional JSON-based orchestration. Unlike DAG-heavy frameworks like LangGraph, smolagents prioritizes a minimalist 'harness' architecture, allowing developers to deploy functional agents in as few as 50-100 lines of code Hugging Face.
High-Throughput Local Agents Reach Desktop Maturity
Local execution for desktop agents is hitting a performance ceiling break with the Holo family of models, which achieve a massive 8,900 tokens/sec throughput. This local capability, powered by the Holo3.1 and Holotron-12B hybrid SSM-Attention architectures, allows agents to bypass API latency and has propelled WebVoyager success rates from a 35.1% baseline to 80.5%. These models power the Surfer-H agent, which leverages vision-language models to interpret screen pixels directly into actions within the ScreenEnv gymnasium-style training environment.
Diagnosing the '11% Reality Wall' in Enterprise AI Agents
New research from IBM and UC Berkeley reveals that frontier models resolve a mere 11.4% of real-world Site Reliability Engineering (SRE) scenarios due to tool-calling errors and reasoning hallucinations. Using the IT-Bench and MAST frameworks, researchers identified that the '11% reality wall' is primarily built on foundational failures in long-horizon planning. These findings are complemented by the VAKRA benchmark analysis and AssetOpsBench, signaling a shift toward granular diagnostics of agentic failure modes in high-stakes industrial operations.
Open-Source Deep Research and Test-Time Compute Reshape Reasoning
The open-source ecosystem is dismantling the 'deep research' monopoly by utilizing the smolagents library to replace static RAG with autonomous, multi-step search loops. This movement toward verifiable research is exemplified by MiroMind's Deep Research and parallel breakthroughs in formal logic like Kimina-Prover, which applies reinforcement learning search to Lean 4 proof spaces. This emphasis on 'thinking' phases allows models to verify logical steps before committing to an answer, a method echoed by ServiceNow AI's Apriel-H1, which distills reasoning traces into smaller, high-efficiency models.
The Model Context Protocol (MCP) enables fully functional, tool-enabled agents in as few as 50 lines of code Hugging Face.
The Model Context Protocol (MCP) enables fully functional, tool-enabled agents in as few as 50 lines of code Hugging Face.
NVIDIA Cosmos Reason 2 introduces causal inference and visual-spatial reasoning to predict physical consequences before robot execution NVIDIA.
NVIDIA Cosmos Reason 2 introduces causal inference and visual-spatial reasoning to predict physical consequences before robot execution NVIDIA.
Meta and Hugging Face launched OpenEnv to standardize agent interaction with software environments via a Gymnasium-style API Hugging Face.
Meta and Hugging Face launched OpenEnv to standardize agent interaction with software environments via a Gymnasium-style API Hugging Face.
DeepSeek-V4 debuts a 1,000,000-token context window with 100% recall to prevent information loss in long-horizon agentic tasks DeepSeek.
DeepSeek-V4 debuts a 1,000,000-token context window with 100% recall to prevent information loss in long-horizon agentic tasks DeepSeek.
Nous Research scales frontier agentic capabilities with Hermes 3 models ranging from 1B to 405B parameters Nous Research.
Nous Research scales frontier agentic capabilities with Hermes 3 models ranging from 1B to 405B parameters Nous Research.