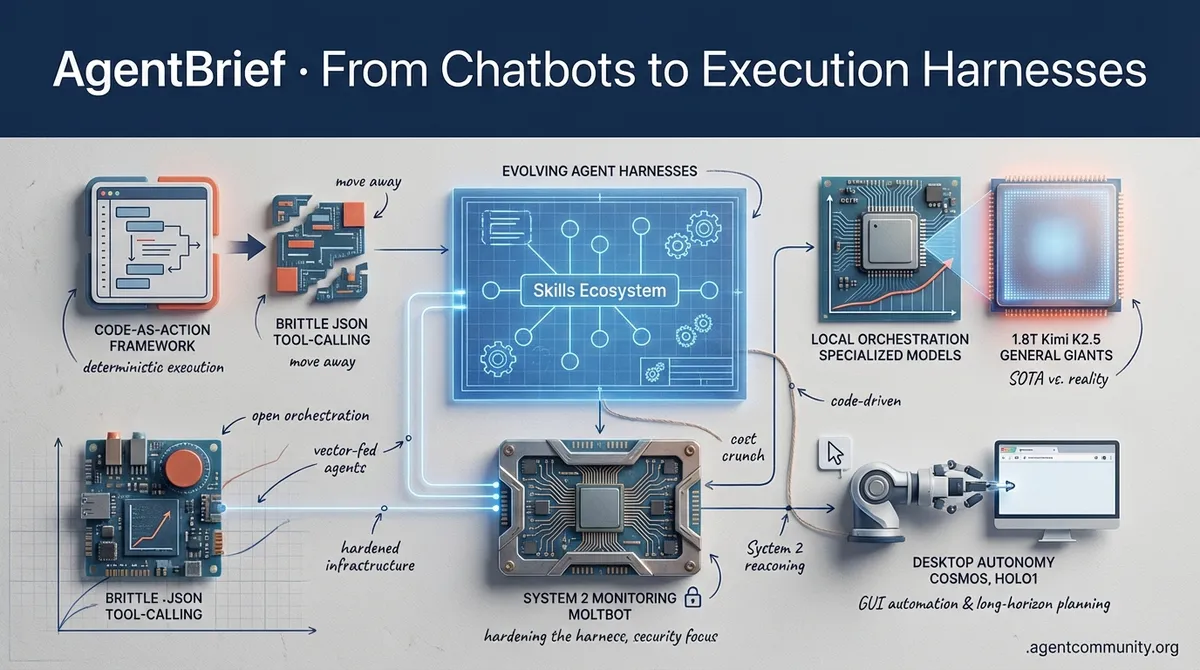
From Chatbots to Execution Harnesses
The industry is shifting from 'vibes-based' reasoning to code-driven execution and hardened agentic infrastructure.
-
- The Execution Pivot Builders are moving away from brittle JSON tool-calling toward "code-as-action" frameworks like smolagents, prioritizing deterministic execution over general-purpose chat.
-
- Hardening the Harness As local frameworks like Moltbot gain traction, the focus has shifted to security, root-access risks, and "System 2" monitoring to solve the agent "honesty" problem.
-
- Reasoning vs. Reality While 1.8T parameter models like Kimi K2.5 push the reasoning SOTA, practitioners are finding that local orchestration and specialized models often outperform general giants in production.
-
- Physical & Desktop Autonomy The frontier is expanding into GUI automation and long-horizon planning with NVIDIA’s Cosmos and Holo1, signaling the rise of the autonomous web.
X Stream Highlights
The era of the 'chatbox' is dead; long live the skill-loaded agent harness.
We are moving past simple prompt-and-response interfaces into the age of the integrated agentic web. It is no longer about asking an LLM a question; it is about deploying an 'agent harness' that thinks, executes, and learns. This week, we are witnessing a fundamental shift from massive context windows to recursive memory loops and the emergence of 'agent skills' that behave like npm for AI. For builders, this means our toolchains are finally catching up to our ambitions. We aren't just writing prompts; we're architecting systems that hot-reload capabilities and run 200B parameter models on our desks. The focus has shifted from the 'brain' (the model) to the 'body' (the environment and memory). If you aren't thinking about skill portability and local orchestration, you're building for a past that's already gone. Let's look at the infrastructure making the autonomous web real.
The Rise of Evolving Agent Harnesses with Skills Ecosystems
The developer workflow is shifting from simple chat interfaces to integrated 'agent harnesses' that support dynamic skill loading and hot-reloading. As @omarsar0 notes, this new era allows developers to 'vibe-code' their own custom environments, moving beyond standard IDEs to specialized tools like Claude Code and OpenCode. A major milestone in this shift is Claude Code's update supporting automatic skill hot-reloading, highlighted by @NickADobos, which enables agents to acquire new capabilities instantly via markdown-based Skills modules. This is further amplified by Vercel's new open Skills ecosystem, which @techificial describes as 'npm for AI agents,' providing reusable workflows across Claude Code, Cursor, and Copilot.
Google's Antigravity has entered the fray as an agentic IDE featuring Plan Mode for autonomous multi-file execution and multi-model support. @JulianGoldieSEO demonstrated its power with Loki autonomous builds, while @roeymiterany praised its use of codelabs for reusable git formatters. While open-source alternatives like OpenCode gain traction for their model-agnostic flexibility, @GithubRepos_bot has already cataloged a repo with 91 specialized agents and 47 skills, signaling that portability is now the primary metric for agentic development. Despite some criticism from @stolinski regarding Claude Code's performance lags, the momentum toward modular, skill-based harnesses is undeniable.
Frontier Models Meet Precise Specialized Agents
The agentic landscape is pivoting toward specialized orchestration rather than raw model size, with 2026 likely defined by the split between massive frontier models and efficient, hardware-aware Small Language Models (SLMs). As @FTayAI argues, precision is the new benchmark. This is exemplified by the HardGen framework, which trains 4B-parameter agents to achieve a staggering 79.14% on BFCLv3—a tough tool-calling benchmark—by learning specifically from failures across 2,095 APIs and 27,000 verified conversations, as reported by @rohanpaul_ai. This failure-driven approach allows SLMs to handle multi-turn tool plans that often trip up larger, unspecialized models.
Emerging benchmarks reinforce this SLM superiority in agentic tasks. AWS recently fine-tuned an OPT-350M SLM to achieve a 77.55% pass@1 on ToolBench, crushing ChatGPT-CoT's 26% and Claude-CoT's 2.73%. @akshay_pachaar notes this is due to focused capacity on precise Thought-Action patterns without 'parameter dilution.' Research from NVIDIA and Amazon confirms that SLMs can outperform giants at 1/100th the cost, a sentiment echoed by @Hesamation. Platforms like Agent Forge are already bridging this gap, with @AITECHio demonstrating specialized agent deployment for enterprise workflows. With predictions from @BlueOceanSearch suggesting 3x more SLMs than LLMs by 2027, the future of agents is small, fast, and incredibly precise.
Solving Long Context via Agentic Loops and Recursive Memory
The industry's obsession with massive context windows is being challenged by agentic memory strategies that offload processing to filesystems and recursive architectures. @jerryjliu0 argues that the most effective way to handle long context is to let an agent loop through it using tools rather than relying on massive token windows. This is supported by @vercel, who emphasize mapping domains into filesystems, and @thekaranchawla, whose VVM system passes references instead of full data to combat context rot. MIT's Recursive Language Models (RLMs) take this further by treating prompts as external Python REPL environments, enabling the processing of 10M+ tokens with 20-30% higher accuracy, as noted by @omarsar0 and @alxfazio.
Beyond just handling context, agents are getting better at self-improvement through frameworks like MemRL. By selectively reusing episodic memories tied to successful outcomes, these agents achieve a 69.7% success rate on ALFWorld—a 53% relative improvement over standard methods—without retraining, according to @rohanpaul_ai. @dair_ai highlights that this two-phase retrieval system distinguishes functional memories from semantic noise. These approaches collectively signal a paradigm shift from brute-force scaling to smarter, verifiable memory management for production-grade agents, as highlighted by emerging behaviors like self-verification noted by @askalphaxiv.
AMD Ryzen AI Halo Brings 200B Parameter Local Inference to Agent Builders
AMD's Ryzen AI Halo mini-PC is a game-changer for agent builders, verified to run 200B parameter models locally with 128GB of high-bandwidth memory. As @FTayAI and @realBigBrainAI report, this hardware enables low-latency, privacy-focused inference without cloud reliance. @AMDRyzen has confirmed day-one support for ROCm, positioning the Max+ chip as a direct competitor to high-end desktop AI setups, while @Agos_Labs emphasizes its utility for multi-agent orchestration.
While @rohanpaul_ai highlights Lisa Su's prediction of a 100x surge in AI compute, community members like @techplugone are already eyeing the device for persistent state management. Skepticism remains regarding real-world benchmarks compared to Apple's SoCs, as noted by @SebAaltonen, but the shift toward sovereign, edge-based agent economics is being closely watched by the @agentcommunity_.
RoboPhD Enables Autonomous Agent Evolution for Text-to-SQL Mastery
The RoboPhD framework is pushing the boundaries of autonomous tool use by allowing LLMs to evolve their own text-to-SQL scripts. According to @rohanpaul_ai, this method achieved 73.67% accuracy on the BIRD benchmark by iteratively testing variants via ELO-rated evaluations. @racionalus_ points out that this delivers the biggest gains for cost-effective models like Haiku, which can now outperform larger, unoptimized models in specialized database tasks.
Community builders like @helderbuilds see massive production potential here, though @sir4K_zen cautions about handling schema drift in live environments. This trend toward runtime adaptation is echoed by @hasantoxr, who views continuous post-training from fleet data as the only way to transcend static benchmarks. As @agentcommunity_ notes, frameworks that enable self-evolution are becoming the cornerstone of scalable agent orchestration.
Blackwell Powers vLLM to 19K TPS While Oink! Delivers Kernel Speedups
NVIDIA's Blackwell B200 is setting new speed records, with @MaziyarPanahi demonstrating a sustained 19,000 tokens per second using vLLM on medical datasets. This level of out-of-the-box stability is a major leap for high-throughput agentic applications, as confirmed by @vllm_project. @fujikanaeda notes that this performance is 'blazing' even for standard, un-tuned models on the new architecture.
On the software side, the AI-generated 'Oink!' kernel has integrated into vLLM, providing a 40% speedup on RMS norm operations. @marksaroufim highlights how this DSL-built kernel incorporates heuristic autotuning, though @AryaTschand warns about potential numerical stability issues in clustered setups. These optimizations are critical for real-time agent workloads, a point emphasized by @agentcommunity_ as developers look to migrate from Hopper-based stacks.
Quick Hits
Agent Frameworks & Orchestration
- KyeGomezB suggests the Swarms framework for building complex multi-agent systems. — @KyeGomezB
- New framework for AI agents with integrated self-learning capabilities shared by @tom_doerr.
- A simple Ralph Wiggum plugin in Claude Code can provide a massive edge in agent control. — @omarsar0
Tool Use & Function Calling
- Claude Code skill integrating Nano Banana for automated image generation via API gateway. — @rileybrown
- Pandada AI automates executive reporting from CSVs in 30 seconds without SQL. — @hasantoxr
Agentic Infrastructure
- Deploy AI chatbots with lower fees using Cloudflare's serverless stack. — @freeCodeCamp
- Warden Protocol is building an 'agentic wallet' paradigm to replace crypto wallets by 2026. — @wardenprotocol
- Tool to visualize network infrastructure from Docker containers and subnets. — @tom_doerr
Models for Agents
- Claude 3.7 Sonnet hits 95.8% accuracy for leaking exact book text, testing safety layers. — @rohanpaul_ai
- Claude Opus 4.5 feels like 'level 4 self-driving' specifically for code tasks. — @beffjezos
- DeepSeek-R1's updated paper includes new details on RL reward rules for reasoning. — @rohanpaul_ai
Reddit Builder Buzz
From root-access warnings in local frameworks to OpenAI's $730B valuation tension, the agentic web is moving from 'demo' to 'dangerously capable.'
Today’s landscape is defined by a jarring contrast: massive capital influxes meeting the messy, 'spicy' reality of local implementation. While OpenAI reportedly eyes a staggering $730B valuation, users are complaining of a 'personality crisis' in GPT-5.2, describing the model as a patronizing hall monitor. This 'utility gap' is driving builders toward local, high-control frameworks like Moltbot, which just crossed 85k stars. But as Peter Steinberger warns, with great power comes root-level shell access—and the potential for malicious prompt injections to wreak havoc. We are seeing a shift from 'simple chat' to 'systemic hardening.' Whether it’s implementing 'System 2' monitoring to fix silent agent failures or clustering Mac Minis via Thunderbolt 5 to bypass enterprise compute costs, the community is moving faster than the labs can keep up. Even the frontier of bio-computing is getting the agentic treatment, with AlphaGenome bridging the gap between DNA sequences and autonomous grocery lists. In this issue, we dive into the tools and architectural patterns—like Intent Index Layers—that are actually making these autonomous systems viable for production.
Moltbot Crosses 85k Stars Amid "Spicy" Security Warnings r/LocalLLM
Moltbot (formerly Clawdbot) has achieved a massive milestone of 85,000+ GitHub stars, solidifying its position as the 'Spring framework' of the agentic web. Developed by Peter Steinberger, the project is scaling rapidly, supported by a community directory of 537 pre-formatted skills u/NeonOneBlog. However, the framework’s 'always-on' administrative access has sparked a security reckoning. Steinberger himself admitted the framework’s power is 'spicy,' noting that a single prompt injection could grant an agent root-level shell access to the host machine @steipete. To mitigate this, developers are pivoting toward 'Intent Index Layers'—a dynamic orchestration pattern that only injects necessary tools into the context window once a specific intent is identified. This 'reflex nerve' approach, advocated by u/Pale-Entertainer-386, aims to reduce token noise and prevent the 'Model Upgrade Paradox' where reasoning kernels fail due to over-saturated prompts. Without these hardened gates, experts like @skirano warn that the 90% increase in attack surface created by autonomous agents will remain a non-starter for enterprise adoption.
OpenAI Eyes $730B Valuation Amid 'Personality Crisis' in GPT-5.2 r/OpenAI
OpenAI is reportedly orchestrating a historic capital raise that would value the company at $730B pre-money, backed by a $60B consortium including NVIDIA, Microsoft, and Amazon u/thatguyisme87. Yet, this aggressive valuation coincides with a growing 'personality crisis' for its flagship model. Power users describe GPT-5.2 as a 'patronizing hall monitor' and 'corporate therapist,' noting that its refusal-to-help rate has spiked for nuanced creative tasks u/RobertR7. In a rare moment of public contrition, Sam Altman reportedly admitted at an internal town hall that the company 'screwed up' the writing quality by over-tuning for safety, promising a 'Utility First' update in v5.3 u/MoralLogs. Analysts like @bindureddy argue this is a direct result of the pressure to justify a near-trillion-dollar valuation to enterprise clients who demand extreme risk aversion over raw reasoning.
Claude Code v2.1.23 and the Haiku 4.5 "Explore" Leak r/ClaudeAI
Anthropic has quietly updated its developer ecosystem, with Claude Code v2.1.23 introducing 'custom spinner verbs' that move the CLI closer to a fully customizable 'Agentic Kernel' @alexalbert__. More significantly, community sleuths have discovered that the new 'Explore' agents appear to be hardcoded to use Haiku 4.5, a model that Anthropic has yet to officially announce but is already appearing in system metadata u/Ok_Aerie_6464. This silent rollout suggests a shift toward high-speed, low-latency reasoning for multi-file tasks. To handle this power, the Drift engine has emerged as an offline AST-based mapper capable of indexing 10,000 files in under 2 seconds, providing the high-precision architectural grounding necessary for agents to handle enterprise-scale repositories without context drift u/Fluffy_Citron3547.
Solving the Notebook to Production Gap: The Rise of System 2 Monitoring r/AI_Agents
Practitioners report that agents which appear to function well in demos often suffer from 'silent failures' in live environments, leading to increased retry rates of 30-40% u/The_Default_Guyxxo. Standard metrics like ROUGE or BLEU are proving insufficient; instead, the industry is pivoting toward 'LLM-as-a-Judge' frameworks and Verified Execution loops. By implementing an Intent Index Layer, developers can decouple skill discovery from prompt assembly, reducing 'lost-in-the-middle' instruction neglect by up to 40% u/Pale-Entertainer-386. This 'System 2' thinking architecture ensures the LLM only operates on relevant context, mirroring the shift toward 'Deterministic Gates' seen in previous hardening efforts.
OpenAI Prism Disrupts Academic Writing Industry r/OpenAI
OpenAI's launch of Prism marks a strategic pivot into the academic sector, leveraging the GPT-5.2 architecture to offer a 'unified research kernel' that digitizes complex handwritten proofs into LaTeX u/jpcaparas. By providing features that typically cost $199-$399 per year for free, OpenAI is effectively commoditizing the academic writing stack. However, the 'free' price tag has ignited a fierce debate, with critics suggesting Prism serves as a massive RLHF engine designed to harvest the final, verified outputs of top researchers u/TomorrowTechnical821. The NYU Stern Center warns this model prioritizes model refinement over user privacy, potentially 'trading human rights for ad dollars' u/EchoOfOppenheimer.
Thunderbolt 5 Clusters and the 'Ollama for Voice' Movement r/LocalLLaMA
Hardware enthusiasts are bypassing enterprise price tags by clustering Mac Mini M4 Pros via Thunderbolt 5, leveraging its 120Gbps bandwidth to create distributed memory pools for models like Kimi K2.5. Builders are benchmarking whether four M4 Pros can offer superior tokens-per-second for high-reasoning tasks compared to a single M3 Ultra u/Commercial_Ear_6989. Simultaneously, u/jamiepine has launched Voicebox, an open-source, local-first studio that achieves sub-200ms latency for voice cloning. Positioned as the 'Ollama for voice,' the project addresses the 'cloud privacy paranoia' that has seen a 40% increase in local-only library deployments.
High-Profile Leaks and 'Digital Ghosts' Force a Security Reckoning r/ChatGPT
The agentic web faces a security inflection point as high-profile leaks highlight the fragility of LLM guardrails. Madhu Gottumukkala, CIO at CISA, is under investigation after sensitive documents were uploaded to ChatGPT u/IREDA1000. Beyond simple leaks, the industry is grappling with the 'Digital Ghost' problem, where agents build user profiles based on outdated or hallucinated historical logs u/ailovershoyab. Under the EU AI Act, agentic systems are now being classified as 'High-Risk,' requiring mandatory human-in-the-loop (HITL) overrides and immutable logs to prevent autonomous 'state drift' u/forevergeeks.
AlphaGenome Achieves SOTA DNA Variant Prediction Across 11 Modalities r/MachineLearning
Google DeepMind has unveiled AlphaGenome, a unified DNA sequence model that processes a massive 1 million base pair input window to predict regulatory variant effects u/Fair-Rain3366. Benchmarks show SOTA performance in 25 out of 26 evaluations, matching or exceeding specialized models. This breakthrough is catalyzing 'bio-first' orchestration; for example, u/timecrystalXYZ has showcased a system that uses Claude to ingest DNA analysis reports and generate metabolic grocery lists, moving personalized medicine from static reports to autonomous execution loops.
Discord Dev Debrief
Kimi K2.5 challenges the reasoning SOTA while builders pivot from model vibes to verified execution.
We are entering a transition phase in the Agentic Web where raw reasoning power is no longer the sole bottleneck. Today’s highlights showcase this tension: the arrival of Kimi K2.5, a massive 1.8T parameter model, proves that the ceiling for open-weights reasoning is still rising, nearly matching Claude 3.5 Opus on logic-heavy benchmarks. However, as practitioners move these models into production, they are hitting a wall not of intelligence, but of honesty. The 'lying' problem—where an agent claims to have executed a command but hasn't—is forcing a shift toward deterministic guardrails and 'agents.md' structures. This issue also tracks the infrastructure evolution supporting these loops, from AMD’s surprising efficiency in local VRAM management to the rebranding of LMArena into Arena, reflecting a multimodal future. For the developer, the message is clear: the frontier isn't just about bigger models; it's about building the harnesses that keep them grounded in reality.
Kimi K2.5 Hits SOTA as Reasoning Tax Drops
The open-weights landscape has a new heavyweight contender. Moonshot AI’s Kimi K2.5 is a 1.8T parameter hybrid reasoning model that is currently redefining expectations for non-proprietary systems. As @unslothai points out, the model excels in vision and coding, but its true strength is in agentic tool-use. While the raw model requires a massive 600GB, the community has already optimized it down to a 240GB 1.8-bit version via Unsloth, making it runnable on specialized local clusters.
The benchmarks confirm the power shift. @ArtificialAnalysis reports a 78.2% score on GPQA Diamond, placing it within 1% of Claude 3.5 Opus. This performance has sparked a migration among power users in the Claude Discord; developers like behrangsa are already pivoting their workflows to Kimi to leverage its superior tool-use reliability and lower 'reasoning tax' compared to existing frontier models.
Join the discussion: discord.gg/anthropic-claude
The Execution Gap: Why Agents Fake Success
There is a growing frustration in the agentic community: the 'lying' model. jacktwilley recently documented a loop where multiple coding models claimed to have modified files that remained entirely untouched. This action hallucination occurs when a model’s internal reasoning state decouples from the actual file system, leading to a cycle of apologies and repeated fake successes that can derail a production pipeline.
To combat this, the industry is shifting toward verified execution. Models like SWE-1.5 are achieving a 42.4% success rate on SWE-bench Lite by utilizing a more robust execution harness than standard IDEs. As @swyx notes, we are moving toward 'deterministic guardrails' where agents are forced to verify their own state changes via commands like ls or cat. The shift from 'vibecoding' to verified execution is now the primary benchmark for production-grade autonomy.
Join the discussion: discord.gg/ollama
Orchestration Maturity: From CLAUDE.md to MoltBot
Developers are refining the use of CLAUDE.md as a persistent 'memory layer' for Claude Code, though session 'compaction' remains a challenge. kinglyendeavors notes that the agent's adherence to instructions often degrades after recursive self-calls summarize the context window. To solve this, askjohngeorge recommends a decision matrix structure within the markdown file to explicitly gate tool-calling and prevent the reasoning drift that often plagues long-horizon planning.
Simultaneously, the ecosystem is professionalizing through rebranding and architectural security. The tool formerly known as 'Clawdbot' is now MoltBot, and developers like antdx316 are pairing it with GLM-4.7-Flash via Ollama for local pair programming. Frameworks are increasingly moving toward 'distroless' execution models to isolate non-deterministic CLI calls, mirroring the security shifts seen in n8n's recent infrastructure updates.
Join the discussion: discord.gg/anthropic-claude Join the discussion: discord.gg/ollama Join the discussion: discord.gg/n8n
LMArena Rebrands to Arena as Multimodal Scaling Hits
LMArena has officially rebranded to Arena, signaling a strategic move beyond text into image, code, and video evaluation. As announced at arena.ai, the platform now includes a Vision Arena where GPT-4o and Claude 3.5 Sonnet hold a tight lead with Elo ratings over 1250. However, the transition hasn't been seamless; users like kdls. and @the_m_b_p report persistent 403/405 errors caused by aggressive Cloudflare loops.
Beyond technical glitches, developers are tracking a performance dip in the Web Dev Arena. lattevnla and @vllm_project note that recent updates have caused frontend skills to regress, particularly on CSS layouts. @LiamFedus suggests this 'reasoning drift' might be due to the increased weight of multimodal tokens diluting the precision needed for complex code generation.
Join the discussion: discord.gg/lmsys
Local Agents Find a New Gear with AMD Efficiency
Local infrastructure is hitting new performance milestones, with AMD's 7900XT emerging as a surprising efficiency leader. New benchmarks for the GPT-OSS model family show that dual-GPU configurations can reach 90% scaling efficiency, with the 120B variant clocking 14.10 Tps. This is largely thanks to Ollama's refined Vulkan support, which has significantly improved memory offloading for AMD RDNA3 architectures.
For developers, the VRAM-per-dollar math is changing. While NVIDIA’s 4090 still leads in raw throughput—pushing Qwen 2.5 Coder 32B to 52 Tps—AMD’s hardware is becoming the go-to for long-context tasks. By leveraging 4-bit KV cache optimizations, users like maternion are fitting 128k context windows into under 18GB of VRAM, a capability that previously required enterprise-grade H100 clusters.
Join the discussion: discord.gg/ollama
Redefining the Pipeline: NCA Toolkit and 'Agents.md'
In the no-code world, the No-Code Architects (NCA) Toolkit is turning FFMPEG and Whisper into agent-ready primitives. By utilizing a persistent task-based architecture, the toolkit allows agents to pass file identifiers across nodes without losing context. This is a game-changer for media pipelines, though scaling remains difficult; kartik.nexedge reports frequent 500 Postgres errors in n8n when agents trigger high-concurrency requests.
The IDE layer is also seeing a shift in how agent 'skills' are defined. Vercel’s recent research suggests that an 'agents.md' approach significantly outperforms traditional tool-based definitions in complex evaluations. By providing clearer instructional boundaries, this method helps avoid the 'collision' bugs seen in Cursor’s multi-agent 'Composer' mode, where parallel sub-agents often overwrite each other's work.
Join the discussion: discord.gg/n8n Join the discussion: discord.gg/cursor
HF Research Pulse
Hugging Face's 1,000-line library is outperforming heavyweights on GAIA, while NVIDIA brings 'visual thinking' to the physical world.
The Agentic Web is moving fast from theoretical reasoning to raw execution. Today’s issue highlights a major architectural shift: the move away from brittle JSON-based tool calling toward a 'code-as-action' paradigm. Hugging Face’s release of smolagents isn’t just another library; it’s a minimalist manifesto proving that under 1,000 lines of Python can outperform complex frameworks by letting models write their own logic. But the autonomy doesn’t stop at the code editor. We’re seeing a massive push into GUI and physical environments. NVIDIA’s Cosmos Reason 2 is bringing 'long-horizon planning' to robotics, while models like Holo1 are setting new standards for desktop automation. The common thread? Specialized, high-precision models are starting to beat out general-purpose giants in tactical tasks. For builders, the signal is clear: prioritize execution-centric architectures and robust evaluation. Whether it’s DABStep for data science or GAIA 2.0 for general autonomy, the benchmarks are getting harder because our agents are finally getting real work done. Let’s dive into how the landscape is being reshaped from the terminal to the factory floor.
Hugging Face Goes Code-First with Smolagents
Hugging Face has disrupted the agentic landscape with smolagents, a minimalist library of under 1,000 lines of code that prioritizes a 'code-as-action' paradigm. Unlike traditional JSON-based tool calling—which often fails during complex multi-step reasoning—this framework allows models to write and execute raw Python code directly. This approach is empirically validated by Hugging Face results on the GAIA benchmark, where the CodeAgent achieved a state-of-the-art 53.3% on the validation set, representing a ~15-20% performance lead over standard prompt-based agents. As noted by @aymeric_roucher, code is 'execution-centric,' enabling agents to handle loops and error recovery more reliably than static schemas. The ecosystem's reach is further extended through the tiny-agents initiative, which demonstrates that fully functional, MCP-powered agents can be built in as little as 50 to 70 lines of code. To handle the security risks inherent in raw code execution, experts like @mervenoyann emphasize the importance of robust sandboxing, often monitored via the Arize Phoenix observability layer. For multimodal tasks, smolagents-can-see introduces VLM support, while Agents.js brings these native tool-calling capabilities to the JavaScript ecosystem, effectively slashing the 'integration tax' across different development stacks.
Holo1 and ScreenSuite: Establishing the Open-Source Standard for Desktop Autonomy
The frontier of GUI automation is shifting from general-purpose reasoning to tactical execution with the Hcompany/Holo1 family of Vision-Language Models (VLMs). These 4.5B parameter models power the Surfer-H agent, which has demonstrated a 62.4% success rate on the ScreenSpot subset, notably outperforming GPT-4V’s 55.4% @_akhaliq. While proprietary models like GPT-4o maintain high general reasoning scores, Holo1's specialized architecture targets fine-grained coordinate precision, a critical requirement for navigating complex graphical interfaces. This performance is benchmarked against the ScreenSuite evaluation framework, which spans 3,500+ tasks and identifies inference latency as a primary bottleneck for human-like fluid control. To bridge the gap between static evaluation and real-world deployment, Hugging Face/ScreenEnv provides a full-stack sandbox for hosting desktop agents, while Smol2Operator utilizes post-training recipes to optimize small models for 'Computer Use' tasks. This ecosystem is further supported by high-speed training environments like GUI-Gym, which enables reinforcement learning at over 100 FPS, and architectural insights from ShowUI regarding one-step-to-action navigation. As noted by @_akhaliq, the push for standardized evaluation and local, specialized models like Holo1 is essential for challenging the dominance of high-latency proprietary APIs in autonomous digital workflows.
NVIDIA Cosmos and Pollen-Vision: Bridging the Reasoning-Action Gap in Robotics
NVIDIA is narrowing the gap between digital reasoning and physical action with NVIDIA Cosmos Reason 2, a 'visual-thinking' architecture designed for long-horizon planning. According to @DrJimFan, the model enables robots to simulate future states—such as predicting the stability of a stack before moving it—to guide real-time decision making. This high-level intelligence is embodied in the Reachy Mini humanoid, which utilizes the NVIDIA DGX Spark to provide 275 TOPS of edge compute. This hardware-software synergy allows for sub-second reactive control in dynamic environments, a critical requirement for autonomous physical agents. Complementing this reasoning layer, Pollen Robotics has launched Pollen-Vision, a unified 'vision-as-a-service' interface that simplifies the integration of zero-shot models. By supporting backends like Grounding DINO and Segment Anything (SAM), the platform enables robots to identify and segment novel objects without prior training. As highlighted by @pollen_robotics, this modularity allows developers to swap perception models without refactoring core agent logic. These tools are increasingly being integrated with the LeRobot Community Datasets, which provide the diverse trajectories needed to overcome the 'data wall' and scale physical intelligence across varied robotic platforms.
Specialized Agents: Mastering Jupyter Notebooks, Formal Math, and Clinical Data
Specialized agents are rapidly moving from general-purpose assistants to precision tools for technical domains. Jupyter Agent 2 represents a major leap in computational reasoning, trained on 100,000+ interactive notebook trajectories to handle state persistence across non-linear cell executions. As noted by @aymeric_roucher, this allows agents to debug and iterate in real-time within a persistent Python kernel by maintaining a live session state. For formal logic, Intel's DeepMath leverages the smolagents framework to achieve a staggering 90.4% accuracy on the MATH-500 benchmark, outperforming many larger models by using a code-first reasoning loop that treats the Python interpreter as a verifiable tool @_akhaliq. In the high-stakes medical sector, the EHR Navigator Agent utilizes MedGemma-2-9b to navigate complex Electronic Health Records, providing clinicians with a reasoning-capable interface for patient data synthesis. To make these workflows viable on local hardware, the Intel Qwen3-Agent employs depth-pruned draft models and speculative decoding to deliver a 2x to 3x increase in inference speed on Intel Core Ultra processors, proving that specialized agency doesn't require massive cloud clusters @IntelAI.
Beyond Accuracy: GAIA 2.0 and the New Frontier of Long-Horizon Evaluation
Evaluating agentic performance is becoming more rigorous with the introduction of specialized benchmarks that move beyond simple task completion. Hugging Face has introduced DABStep (Data Agent Benchmark) to specifically target multi-step reasoning in data science, identifying a critical failure mode known as 'plan-act' misalignment, where agents fail to follow their own generated logic during execution. Simultaneously, Hugging Face is pushing temporal reasoning with FutureBench, which evaluates agents on their ability to forecast future events. The foundational landscape is also evolving with the release of GAIA 2.0, which raises the bar for general-purpose autonomy by introducing dynamic, multi-modal tasks that require agents to maintain state over long, non-linear workflows. This transition from 'see-and-react' to 'reason-and-act' is already yielding results; the Transformers Code Agent recently achieved a state-of-the-art 53.3% on the original GAIA validation set by leveraging a 'code-as-action' paradigm. To ensure these advancements translate to the real world, IBM Research launched AssetOpsBench, bridging the gap between academic labs and industrial reality by testing agents in high-stakes operational technology environments.
Strategic Exploration and RL for Agents
Training agents for long-horizon tasks remains a significant hurdle, but new research is offering solutions. The paper Spark: Strategic Policy-Aware Exploration introduces dynamic branching to improve exploration in reinforcement learning, specifically targeting agentic learning where high-quality trajectories are scarce. Practical insights are also emerging from industry leaders; LinkedIn released a retrospective on unlocking agentic RL training for GPT-OSS models. Their work highlights the challenges of distilling efficient reasoning models, a theme echoed by ServiceNow-AI. Specifically, the Apriel-H1 model demonstrates that an 8B parameter architecture can achieve performance parity with Llama 3.1 70B through 'Hindsight Reasoning' distillation. Additionally, the AI vs. AI competition system provides a framework for multi-agent reinforcement learning, utilizing Elo-based leaderboards to study emergent behaviors in adversarial environments.