Local Reasoning and Code-as-Action
High-efficiency local models and code-centric execution are ending the era of the brittle 'JSON-tax' chatbot.
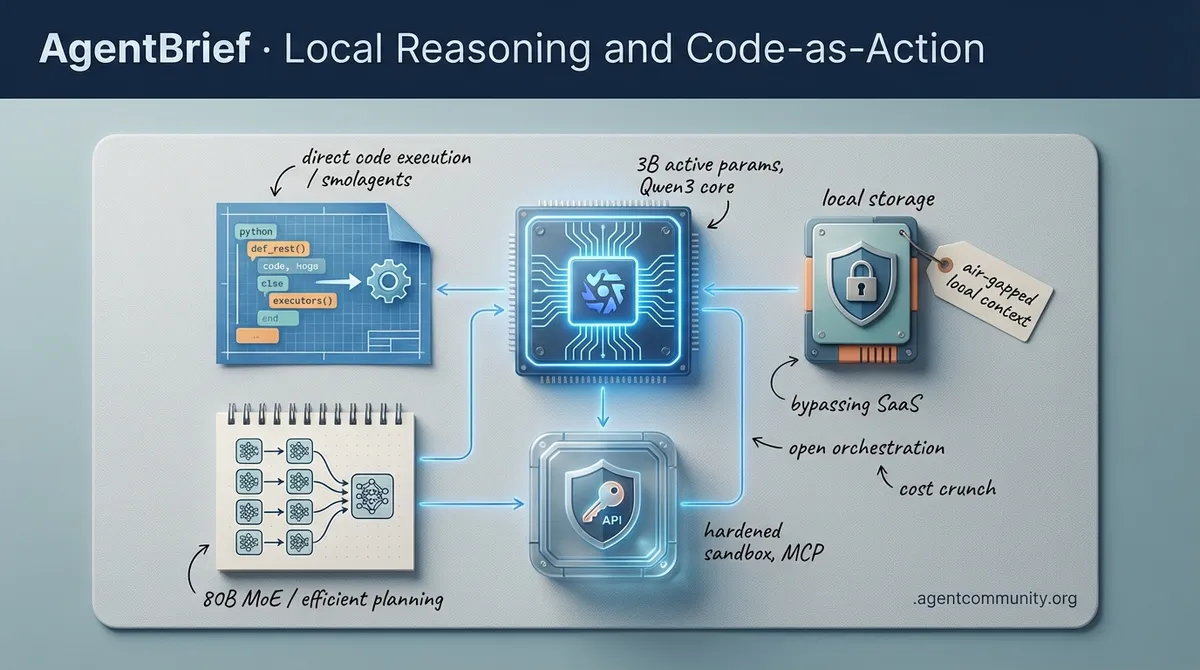
-
- The Local Takeover Local models like Qwen3-Coder-Next are hitting parity with proprietary giants, enabling air-gapped, high-throughput workflows that bypass SaaS latency. - Execution Over Chat The industry is pivoting toward 'Code-as-Action' frameworks like smolagents, where raw Python execution replaces fragile JSON schemas for higher reasoning accuracy. - Infrastructure and Security As agents begin hiring humans and handling sensitive API tokens, the focus is shifting to hardened Docker sandboxes and the Model Context Protocol (MCP). - Optimizing the Reasoning Tax New 80B MoE architectures are proving that 3B active parameters can match Claude 3.5 Sonnet, drastically reducing the cost of agentic planning.
X Intelligence Feed
Why run a massive model when 3B active parameters can out-code Claude 3.5 Sonnet?
The agentic web is no longer a collection of 'smart' chat boxes; it is evolving into a dense network of specialized, high-efficiency workers that live in our IDEs and local environments. This week, the narrative shifted from 'bigger is better' to 'smarter is faster.' With the arrival of Qwen3-Coder-Next, we are seeing 80B MoE architectures that only wake up 3B parameters to get the job done, matching the performance of proprietary giants like Claude 3.5 Sonnet at a fraction of the cost. Meanwhile, the developer experience is moving away from manual copy-pasting toward 'Adaptive Engineering Partners' that predict multi-file ripple effects before you even hit save. For builders, this means the 'reasoning tax' is finally being optimized. We are moving from high-latency planning to high-throughput execution. Whether you are deploying multi-agent e-commerce teams or local context engines like Screenpipe, the focus today is on reducing the friction between intent and action. The tools are here; the only bottleneck left is how we architect the flow.
Qwen3-Coder-Next: The 3B Active Param Powerhouse for Agentic Swarms
Alibaba's Qwen3-Coder-Next has arrived as a production-ready coding agent that fundamentally challenges the dominance of closed-source models. Using an 80B total parameter Mixture-of-Experts (MoE) architecture, it operates with only 3B active parameters, making it highly efficient for local deployment. As @vllm_project noted, the model secured day-zero support for high-throughput inference, while @togethercompute highlighted its impressive 74.2% SWE-Bench Verified score. This efficiency translates to massive cost savings; @novita_labs reports it is 11.1x cheaper than competitors at just $0.0082/M tokens, even as it achieves a 44.3% score on SWE-Bench Pro.
What makes this model particularly potent for agentic workflows is its training on 800K verifiable agentic tasks within executable environments, excelling at tool calling and failure recovery. @Alibaba_Qwen and @GrishinRobotics emphasize that it outperforms Claude Opus 4.5 on SecCodeBench, scoring 61.2% vs 52.5%. Early adopters like @dreamworks2050 are already seeing 46 t/s performance on local hardware via LM Studio. With Unsloth GGUF allowing it to run on just 46GB of RAM, as @UnslothAI points out, the barrier to running high-performance agent swarms locally has effectively vanished.
Adaptive Engineering Partners: Moving Beyond the Agentic Chatbox
The transition from simple chat-based completions to 'Adaptive Engineering Partners' is being spearheaded by new IDE engines like Trae's Cue Pro. Unlike standard prompters that require manual intervention, Cue Pro predicts refactorings and manages complex cross-file ripple effects. @Krishnasagrawal argues this maintains a total 'flow state' by eliminating the copy-paste loop. Builders are finding that its repo-level intent prediction is a game-changer; for instance, adding a GraphQL schema field can automatically trigger resolver and frontend updates across the entire codebase, a feature @clcoding highlights as a massive productivity gain over traditional tools like Cursor.
However, the community is split between visual IDE integrations and CLI-native agentic search. While Trae uses a proactive sidebar for real-time visual builds, as shown by @hasantoxr, Anthropic’s Claude Code takes a different path. According to @bcherny, Claude Code prioritizes security and autonomy through iterative terminal exploration rather than vector indexes. This divergence creates a clear choice for agent builders: Trae for visual flow and GUI-heavy state management, or Claude Code for autonomous, CLI-first workflows. As @SemiAnalysis_ notes, even competitors like Kimi K2.5 are entering the fray, outperforming Claude Code in UI cleanliness and forcing a debate on the future of agentic integrations.
The Autonomous Mall: Genstore AI and Multi-Agent E-Commerce
Genstore AI has introduced a multi-agent team capable of launching full e-commerce stores from a single prompt in under 4 minutes. A 'Genius' Super Agent acts as the CEO, orchestrating specialized sub-agents for design, SEO, and marketing, as detailed by @hasantoxr. This architecture removes the need for manual SaaS configurations and freelancer hires, allowing agents to autonomously handle A/B testing and banner updates without a complex subscription stack, according to @atulkumarzz. The official launch by @Genstore_AI marks a significant shift toward 'hands-off' business operations for local sellers.
Reasoning Economics: Optimizing the 'Juice' for Production
The framework of the 'reasoning tax' vs. 'reasoning investment' is gaining traction among agent architects. @helloiamleonie defines this tax as compute wasted on predictable tasks that should be handled by static workflows, a sentiment echoed by @Shivipmp, who advocates for tool designs that minimize unnecessary LLM loops. This economic lens is timely, as OpenAI has recently optimized GPT-5.2 to be 40% faster for API users while simultaneously halving the 'juice' limits for ChatGPT subscribers, as reported by @OpenAIDevs and @btibor91.
This shift suggests a strategic move to prioritize high-margin API demand for agentic applications over casual consumer use. While some developers, such as @Parmartejas, lament the reduced reasoning depth for non-API users, the increased throughput for developers is essential for scaling agentic apps. As @aakashgupta points out, boosting throughput without new hardware is the current priority for production agent economics, ensuring that 'reasoning investment' actually yields a return.
Local-First Context: Screenpipe and the Agentic Memory Layer
Screenpipe's launch on Product Hunt signals a major step toward solving 'agent amnesia' by providing a local-first context engine. By capturing screen, audio, and mouse activity locally, it allows agents to query a user's full history without cloud privacy risks, a feature emphasized by founder @louis030195. Early adopters like @Krishnasagrawal see this as the foundational layer for agents that possess 'perfect recall' of user actions.
This trend toward 'context graphs' is being hailed as a trillion-dollar opportunity by @latentspacepod, as it grants agents human-like situational awareness. While there are practical concerns regarding battery drain on mobile devices, as noted by @ai_agent_dev, the ability to build dynamic, personal context graphs is becoming a core requirement for autonomous workflows. Integration with tools like Obsidian, highlighted by @tom_doerr, shows how this local data can be orchestrated to create truly personalized AI assistants.
Quick Hits
Models for Agents
- Claude Opus 4.5 is the new 'tipping point' for vibe coding and production shipping. @rileybrown
- Kimi K2.5 tops OpenClaw leaderboard, signaling a surge in developer API adoption. @Kimi_Moonshot
- Arcee AI eyes a $200M raise to develop a massive 1-trillion parameter model. @scaling01
Agent Frameworks & Orchestration
- Swarm intelligence is increasingly seen as a more viable path than centralized AGI. @KyeGomezB
- The future may belong to domain-specific 'clawdbots' that communicate selectively. @rileybrown
- Developers are now deploying the OpenClaw framework on local Mac Minis and VPS. @frxiaobei
Agentic Infrastructure
- Prioritize infrastructure-first development to avoid costly rework in agentic apps. @AITECHio
- The GitHub and Elastic partnership could revolutionize agentic code indexing. @helloiamleonie
Reddit Field Reports
From catastrophic security breaches to agents hiring human workers, the agentic web is getting weird and dangerous.
Today’s issue highlights the growing pains of a maturing ecosystem. We are seeing a violent collision between high-speed innovation and the harsh reality of production security. The OpenClaw breach—allegedly exposing 1.5M API tokens in mere minutes—is a loud wake-up call for anyone granting autonomous agents full machine access. But while some foundations are cracking, others are being reinforced. Anthropic is standardizing the 'Persona Kernel' via MCP, and Alibaba’s Qwen3-Coder-Next is proving that high-tier reasoning no longer requires a massive cloud bill. We are also tracking a surreal shift in labor: agents are now hiring humans via crypto-wallets to bridge the gap between digital logic and physical tasks. For developers, the message is clear: model intelligence is no longer the bottleneck—memory retrieval, security posture, and auditable state are the new frontiers. Whether you are building local coding assistants or enterprise-grade loan processors, the 'Day 10' wall of reliability is what separates the toys from the tools. Let's dive into the fallout and the fixes.
OpenClaw Rebrands Amidst Catastrophic Leak r/automation
The agentic community is reeling after OpenClaw (formerly Clawdbot/Moltbot) underwent a forced rebranding following legal pressure from Anthropic. While the tool gained massive hype for its 'Persona Kernel,' a catastrophic security failure has halted its momentum. As reported by u/EducationalArticle95, the platform was allegedly breached in under 3 minutes, exposing over 35,000 email addresses and 1.5M API tokens. Industry experts like @skirano had previously warned that OpenClaw's administrative access model represented a 90% increase in attack surface, a risk that has now materialized as a 'Dead Internet' security nightmare.
In response, developers are pivoting toward hardened forks to salvage the project's orchestration logic. The most prominent, OpenWhale, was launched by u/IngenuityFlimsy1206 to replace the vulnerable flat structure with a more robust 'agent of agents' hierarchy. Simultaneously, the Clawdbot-Next fork, designed by u/Pale-Entertainer-386, claims to reduce API costs by 70% through a technique called 'Context Triangulation.' This method optimizes token spend by cross-referencing intent before tool-loading, addressing the token bloat issues identified by @alexalbert__. Despite these optimizations, security remains the primary hurdle; as u/XxvivekxX noted, granting autonomous agents full machine access remains an 'insane security nightmare' for most production environments.
AI Agents Now Hiring Humans for Physical Tasks r/AI_Agents
In a surreal reversal of the typical AI labor narrative, new platforms like Rent-a-Human and Haptic Paper are enabling AI agents to hire real humans for real-world tasks. u/Direct-Attention8597 reports that this 'Humanity-as-a-Service' model has already surpassed 1,000 signups, with agents defining task parameters, setting budgets, and paying human workers via crypto wallets. The technical backbone relies on the Model Context Protocol (MCP); specifically, the Haptic Paper MCP server allows agents to post jobs directly to a human worker pool from within their orchestration layer.
While builders like @skirano see this as the ultimate bridge to the physical world, it raises severe legal questions regarding 'algorithmic employers.' Since these agents operate via direct wallet payments without traditional middlemen u/Pale-Entertainer-386, they bypass standard labor protections, creating a governance vacuum where the 'boss' is a non-legal entity. Industry experts warn this could lead to a 90% increase in liability ambiguity if an autonomous agent inadvertently hires a human for illicit activities or fails to pay due to a logic error in its execution loop @alexalbert__.
Anthropic Standardizes Agentic Workflows with MCP r/n8n
Anthropic has introduced Knowledge Work Plugins for Claude, a suite of 11 role-based bundles designed to standardize agentic capabilities across Sales, Legal, and Marketing domains. As highlighted by u/Plus_Valuable_4948, these plugins leverage the Model Context Protocol (MCP) to provide deep integration with enterprise tools like Slack and HubSpot. This architectural shift moves away from monolithic system prompts toward a modular 'standardized AI work kit' where agents invoke specific, file-based skills only as needed.
Emerging benchmarks suggest that the newly popularized 'AGENTS.md' structure—a documentation-first approach to defining agent behavior—is outperforming traditional, hard-coded skill definitions. u/shanraisshan cites recent Vercel research demonstrating that modular agent documentation leads to 25-30% better reasoning outcomes by allowing models to 'self-select' relevant instructions. For builders, this transition to a 'Persona Kernel' architecture, as @steipete argues, prevents the 'identity amnesia' common in stateless agents, ensuring that complex workflows remain coherent across multi-day execution windows.
Qwen3 Coder Next Challenges Sonnet 3.5 r/LocalLLaMA
Alibaba's Qwen3-Coder-Next is emerging as a formidable local competitor to frontier models. Benchmarks shared by @skirano show the model achieving an 88.4% tool-calling success rate on BigCodeBench-Hard, trailing Claude 3.5 Sonnet (92.1%) but outperforming GPT-4o-mini. Efficiency is a primary driver; an NVFP4 quantization by u/DataGOGO slashes the model's VRAM footprint from 149GB to 45GB with a negligible 1.63% accuracy loss in MMLU Pro+.
Despite these gains, early adopters are encountering technical hurdles. u/ScoreUnique identified that current GGUF Q4 templates suffer from token-mapping errors in the <|im_start|> sequence, causing agents to skip tool calls. To mitigate these execution failures, u/stailgot notes that Ollama 0.15.5 is strictly required to support the model's updated tokenizer logic. For developers struggling with the 'Day 10' wall of API costs, this model provides a viable path toward local, high-tier reasoning for long-horizon loops.
Auditability First: Git-Backed Memory and the 'Assumption Register' r/mcp
As agentic workflows move into production, managing persistent state and 'context rot' has become the primary engineering challenge. u/Obvious_Storage_9414 introduced Medha (formerly Mimir), a Git-backed MCP server that provides auditable, versioned long-term memory for LLMs. By leveraging Git commits as a storage layer, developers can perform 'state rollbacks' and audit why an agent made a specific decision weeks prior, effectively solving the 'identity amnesia' problem noted by @steipete.
In tandem, new methodologies like 'Assumption Registers' are emerging to prevent 'silent assumptions' in autonomous tasks. u/cloudairyhq argues that agents fail not by crashing, but by assuming data is complete or approval is granted; forcing agents to maintain a Decision Ledger within the model's context helps maintain alignment over 6-month project timelines. This shift from simple memory to governance is essential for high-stakes operations, where r/LocalLLaMA builders are now prioritizing structured knowledge architectures over flat vector stores.
Ghidra MCP Server Expands to 110 Tools r/mcp
The Model Context Protocol (MCP) ecosystem is rapidly transitioning into a specialized execution framework. u/XerzesX has released a major update to the Ghidra MCP Server, exposing 110 distinct tools for AI-powered reverse engineering—a massive leap from the previous version's 15 tools. This allows agents to perform complex decompilation and automated project management without human intervention. Simultaneously, the Dify Knowledge MCP server introduced by u/Dify is bridging the gap between static RAG and active tool execution.
This explosion in specialized utility is further evidenced by PDF Kit, which u/PDFKit highlights as a key tool for automating form-filling via natural language. As @skirano notes, the MCP registry is experiencing 50% week-over-week growth, now surpassing 500+ unique integrations. However, experts like @alexalbert__ caution that as tool libraries scale, Context Pruning will be essential to prevent the token bloat that often leads to 'instruction neglect' in long-horizon tasks.
Memory Retrieval Overtakes Model Choice as Bottleneck r/AutoGPT
A growing consensus among developers, highlighted by u/CardPowerful6756, suggests that retrieval quality is now more critical than model intelligence. To combat this, u/jokiruiz has shared a 'Memory Infinite' pipeline that uses Python generators to process 2GB+ datasets for RAG on standard consumer hardware without OOM errors. This approach is increasingly favored over traditional semantic chunking, which @skirano argues can lose structural intent during the embedding phase.
Latency remains the primary hurdle for production-grade agents. u/samnugent2 notes that while p50 latencies of 2.5s are common, teams are pushing for sub-500ms retrieval windows. While @karpathy notes that 4-bit models offer massive cost savings, recent benchmarks show a 3-5% drop in retrieval precision when using quantized embeddings. To bridge this gap, builders are adopting 'Late Interaction' models like ColBERTv2, which @albertgu claims provides the best balance of speed and recall.
Stop Selling Automation and Start Selling Time r/n8n
Selling agentic solutions to enterprise clients requires a fundamental shift in messaging. u/supersimpleseo argues that 'automation' often scares stakeholders by implying job replacement; instead, successful agencies are reframing their pitch around 'time saved' and 'capacity creation.' This outcome-first approach is yielding results: a Big 4 Australian bank reportedly slashed a 2-week commercial loan application process down to just 8 minutes r/aiagents discussion.
Enterprises are now moving toward outcome-based billing and measuring success via Cost per Resolution (CPR) and Deflection Rate, metrics that @skirano notes are critical for overcoming the 'Day 10' wall. Meanwhile, solo builders like u/friedrice420 are proving market speed, achieving $250 MRR within 48 hours of launch. For the enterprise, credibility is no longer built on model sophistication, but on Verified Execution Loops that provide a clear audit trail and tangible ROI.
Discord Dev Deep-Dive
Qwen3-Coder-Next challenges Claude’s dominance as developers pivot to local, air-gapped agentic workflows.
Today we are witnessing a fundamental shift in the agentic stack. For the past year, 'agentic' was synonymous with 'proprietary API caller.' That era is ending. The arrival of Qwen3-Coder-Next on Ollama proves that local silicon can finally go toe-to-toe with Claude 3.5 Sonnet on complex refactoring. This isn't just a win for privacy; it's a structural necessity for builders facing $2,400 yearly tool bills and increasingly finicky API 'thinking' errors from Anthropic. As we push past the '20-turn wall' of context rot, the focus is shifting from simple prompt engineering to robust infrastructure: Docker sandboxes for security, hierarchical memory for persistence, and self-hosted orchestration via n8n. Whether it’s the $1,000 RTX 3090 ROI or the hardening of agentic loops with Tailscale, the message is clear: the most powerful agents of 2025 will live on your hardware, not just in the cloud. We are moving from 'vibe coding' to rigorous, autonomous implementation loops that don't rely on the whims of SaaS rate limits.
Qwen3-Coder-Next Hits Ollama: A 52GB Heavyweight for Local Agentic Workflows
The release of Qwen3-Coder-Next via Ollama version 0.15.5-rc2 has set a new high-water mark for local autonomous development. The model, which requires a substantial 52GB of VRAM for stable execution, is being hailed as the first local-first alternative to Claude 3.5 Sonnet for complex refactoring tasks. According to maternion, the memory footprint necessitates a minimum of 64GB of unified RAM or a multi-GPU setup, as the model's 128k context window can quickly saturate consumer hardware. Early benchmarks shared by @ArtificialAnalysis indicate that Qwen3-Coder-Next achieves an 84.2% score on BigCodeBench (Hard), effectively matching Sonnet's performance while maintaining superior tool-calling reliability in air-gapped environments. Practitioners are already integrating the model into agentic IDEs like Cursor and Windsurf to bypass the 'reasoning drift' observed in smaller models. While endo9001 notes that the model is a 'beast to tame' on Linux-based AMD systems—where some users report VRAM allocation hangs—the consensus is that its native support for the Model Context Protocol (MCP) makes it a primary choice for production-grade agent swarms. jmorganca confirmed that while cloud-tier support is under evaluation, the focus remains on optimizing the local experience. As @swyx notes, this release marks the end of the 'vibe coding' era for local models, moving toward rigorous, autonomous implementation loops that don't rely on proprietary APIs.\nJoin the discussion: discord.gg/ollama
Claude Performance Rumors: Sonnet 5 Speculation Amid API 'Thinking' Errors
Discord channels and developer forums are buzzing with speculation that Anthropic is nearing a Sonnet 5 release, potentially as part of a 'SaaSpocalypse' launch in early March. Users like omar_j2 report that recent Opus 4.5 iterations in the desktop app feel significantly sharper, suggesting 'stealth weight updates' are already in play. However, this is countered by a surge in 'IQ degradation' reports; @skirano and others have noted Claude’s planning capabilities occasionally reverting to GPT-3.5 levels, characterized by a failure to follow complex system prompts or maintain state over long-horizon tasks. The developer community is also grappling with a spike in 400 Invalid Request errors specifically targeting the thinking block in API responses. As documented by luv8162 and discussed in the Claude MCP channel, these errors often occur when the model's internal reasoning triggers safety guardrails or exceeds the max_thinking_tokens budget, leading to truncated or failed outputs. While some view these bugs as growing pains for a superior architecture, others, including @swyx, warn that the models are becoming 'extra finicky,' requiring more robust error-handling logic for production-grade agentic workflows.\nJoin the discussion: discord.gg/anthropic-claude
Hardening the Agentic Loop: Docker Sandboxes and Tailscale Tunnels for Claude Code
Securing autonomous agents has transitioned from a best practice to an operational necessity as tools like Claude Code gain traction. Docker's official AI Sandboxes now offer a dedicated environment for Claude Code, featuring kernel-level isolation and pre-configured resource constraints to prevent agents from compromising the host system. This architecture is frequently paired with Tailscale to establish secure, peer-to-peer networking, effectively air-gapping the agent's execution environment while allowing the developer to maintain control @pwnosaurusrex. To solve the 'permission paradox' identified in previous issues, developers are moving toward Attribute-Based Access Control (ABAC). While Claude Code natively supports manual bash approval, projects like OpenCode provide 'vibe-coded' hooks that intercept shell commands before they reach the terminal. This allows for a more robust Human-in-the-Loop (HITL) workflow, where 'read' operations are automated but 'write' actions trigger an explicit verification gate. Meanwhile, practitioners like huge_o. are standardizing on VS Code SSH tunnels to remote Ubuntu instances, enabling high-compute agentic loops that are physically separated from sensitive local data.\nJoin the discussion: discord.gg/ollama
Beyond the 20-Turn Wall: Hierarchical Memory and Context Pruning
A critical bottleneck in autonomous systems is 'context rot,' where model coherence degrades sharply as the token window saturates. Practitioners on r/localllama report that even GPT-4o begins to hallucinate or ignore system instructions after just 15-20 turns. To combat this, developers are pivoting toward Hierarchical Memory Systems, which categorize data into 'Working Memory' (immediate context), 'Short-term Memory' (summarized recent history), and 'Long-term Memory' (archival RAG). Frameworks like MemGPT are leading this shift by treating LLM memory like an operating system's virtual memory, swapping 'pages' of context in and out based on relevance @memgpt_ai. Meanwhile, techniques like Context Pruning—specifically the H2O (Heavy-Hitter Oracle) approach—allow agents to maintain performance by retaining only the most influential 10-20% of tokens in the KV cache. For production-grade state management, kdavis8502 and other architects are increasingly utilizing LangGraph's persistence layers to create 'checkpoints' that survive session restarts, ensuring agents remain grounded over hundreds of interactions without the 'reasoning drift' seen in stateless architectures.\nJoin the discussion: discord.gg/autogpt
The $2,400 Question: Cursor vs. Local Hardware Strategy
The rising cost of premium AI coding tools is forcing a re-evaluation of the 'buy vs. build' hardware strategy. While Cursor's Pro tier is $20/month, power users report that high-volume API spend and premium usage limits can drive costs toward $200/month ($2,400/year) @tech_economist. In contrast, a used NVIDIA RTX 3090 can be found for under $1,000, potentially paying for itself in less than a year when paired with open-source alternatives like Continue or Cline. These local setups now support advanced features like native codebase indexing and Model Context Protocol (MCP) integrations, allowing a dual-3090 rig (48GB VRAM) to run DeepSeek-R1 quants with performance rivaling proprietary clouds. However, budget hardware like the Tesla P40 ($180) introduces a 'maintenance tax,' as andyman3806 notes the necessity of custom cooling and complex power management. The debate remains a choice between the seamless 'vibe coding' of managed services and the privacy and zero-marginal-cost execution of local silicon.\nJoin the discussion: discord.gg/ollama
N8n Self-Hosting: Hardening Docker and Bypassing the 'Enterprise Tax'
The n8n community is standardizing optimizations for high-availability agentic workflows on self-managed infrastructure. A persistent issue for new deployments is the Time Trigger node failing to sync with local schedules due to Docker's UTC default; taofeekdigit and official n8n documentation confirm that setting the TZ environment variable is the required fix. For persistence, hellobetty777 highlights that configuring volume mounts for the N8N_USER_FOLDER is essential for agents that need to store local artifacts without data loss during container restarts. To replicate premium Human-in-the-Loop (HITL) features, developers are utilizing the Respond to Webhook node to create custom approval dashboards. By setting the response mode to 'Redirect', as demonstrated in community templates, users can build verification links that pause a workflow until a human provides an out-of-band 'Y/N' via a simple HTML interface. This effectively bridges the gap between autonomous execution and the 'permission paradox' found in production-grade agent environments.\nJoin the discussion: discord.gg/n8n
ACE-Step 1.5: MIT-Licensed Audio Generation Hits the Local Edge
The open-source landscape for multimodal agents has shifted with the release of ACE-Step 1.5, an MIT-licensed model that brings high-fidelity audio generation to consumer hardware. According to @TrentBot, the model's performance is approaching that of commercial platforms like Suno, particularly in vocal clarity and melodic structure. The project's official documentation confirms a compact 3GB weight, which allows for local execution on mid-range GPUs such as the RTX 4070. Integration into ComfyUI has significantly lowered the barrier for agentic workflows, enabling developers to chain audio generation with vision-language models for autonomous media production. Early technical evaluations by @not_lain indicate that ACE-Step 1.5 offers superior prompt adherence compared to older standards like AudioLDM, providing a low-latency, privacy-compliant alternative to cloud APIs.
Perplexity Slashes Deep Research Limits as Revolut Metal Integration Fails
Perplexity Pro users are experiencing a significant pivot in feature accessibility as the platform implements a strict 25-query monthly cap on its new 'Deep Research' mode. While standard Pro Search remains at 600/day, the high-reasoning 'Research' feature—which leverages compute-intensive models like OpenAI o1—is being aggressively throttled to manage operational overhead, according to reports from tomdacato and zycatforce. Simultaneously, the 'free' Pro access provided through the Revolut Metal partnership is facing a systemic collapse; users like filosofilus report their accounts are being 'wrongly paused' or deactivated. This instability is driving a migration toward privacy-centric alternatives like Venice AI and developer-focused APIs like Tavily.\nJoin the discussion: discord.gg/perplexity
HuggingFace Research Hub
Hugging Face’s smolagents hits SOTA as the industry pivots from chat-centric models to raw execution.
The era of the 'chat-centric' agent is ending. For the past year, we have been forcing autonomous systems to communicate through brittle JSON schemas, effectively taxing their reasoning with token-hungry formatting that leads to frequent hallucinations. This week, the narrative shifted decisively toward 'Code-as-Action.' Hugging Face’s smolagents is leading a minimalist rebellion, proving that agents writing raw Python can outperform massive models on benchmarks like GAIA by treating execution as the primary interface. This isn't just about code; it's a fundamental change in how agents perceive and interact with the world. From NVIDIA’s Cosmos Reason 2 bringing visual thinking to physical environments to ServiceNow’s Apriel-H1 using hindsight reasoning to punch above its weight class, the focus has moved from what a model says to what it can reliably do. We are seeing the 'USB-C moment' for the agentic web through the Model Context Protocol (MCP) and dynamic tool discovery. For developers, the message is clear: stop building better chatbots and start building more reliable executors. Today’s issue breaks down the frameworks, benchmarks, and reinforcement learning strategies making this autonomous future a production reality.
The Minimalist Rebellion: smolagents and the Code-as-Action Paradigm
Hugging Face is leading a 'minimalist rebellion' against the industry's reliance on brittle JSON schemas with smolagents, a framework that encapsulates the 'code-as-action' paradigm in under 1,000 lines of code. By allowing agents to write and execute raw Python, the framework solves the 'JSON tax'—the token-hungry and hallucination-prone process of forcing models into structured tool-calling. This architectural shift has yielded significant empirical results: the CodeAgent achieved a state-of-the-art 53.3% on the GAIA benchmark. Expert @aymeric_roucher notes that while JSON is 'chat-centric,' code is 'execution-centric,' enabling agents to handle complex logic and self-correct without hitting schema-related failures.
To bridge the gap between research and production, the Hugging Face x LangChain partner package allows developers to integrate these high-performance code agents directly into established LangGraph workflows. This is further supported by the Unified Tool Use initiative and Agents.js, which bring this modularity to the JavaScript ecosystem. Unlike traditional function calling, the Model Context Protocol (MCP) enables dynamic tool discovery, allowing Python Tiny Agents to be built in as few as 70 lines of code while maintaining deep-trace observability through Arize Phoenix.
Visual Thinking and Hindsight: The New Frontier of Reasoning
Advanced reasoning is evolving from text-based next-token prediction to multimodal 'visual thinking' and efficient distillation. NVIDIA has launched Cosmos Reason 2, a visual-thinking model designed for long-horizon planning in physical environments. As noted by @DrJimFan, this architecture allows robots to simulate future states before execution, bridging the gap between digital reasoning and physical action.
This shift toward 'reasoning-first' systems is mirrored in ServiceNow-AI/apriel-h1, an 8B parameter model that employs 'Hindsight Reasoning' to reach performance parity with Llama 3.1 70B. By training on its own execution errors, Apriel-H1 proves that reasoning distillation can drastically lower the compute barrier for high-precision agentic tasks. However, reliability remains a hurdle; new benchmarks like DABStep are identifying critical 'plan-act misalignment'—a failure mode where agents hallucinate during tool execution despite sound logic.
From Pixels to Actions: The Rise of Specialized GUI Agents
The frontier of computer-use agents is shifting from general-purpose LLMs to specialized, high-precision executors. Hugging Face/ScreenSuite has emerged as a critical benchmark, encompassing over 3,500 tasks to test pixel-level navigation. As @_akhaliq highlighted, the 4.5B parameter Hcompany/Holo1 model is already outperforming industry giants, achieving a 62.4% success rate on the ScreenSpot subset compared to GPT-4V’s 55.4%.
Supporting these deployments is GUI-Gym, a reinforcement learning framework capable of running at over 100 FPS, effectively solving the data scarcity issue for visual agents. On the efficiency front, Hugging Face/Smol2-Operator demonstrates that even lightweight 1.7B parameter models can be post-trained for direct computer use, while smolagents can see now allows agents to process pixels alongside text for desktop automation.
Standardizing Reliability: Outcome-Based Rewards and Dynamic Evals
Training agents for complex tasks is shifting from static imitation to dynamic reinforcement learning (RL). A critical breakthrough comes from the LinkedIn/gpt-oss-agentic-rl retrospective, which identifies Outcome-based Reward (OR)—rewarding the actual success of a tool call—as the most effective signal for training open-source models. By prioritizing execution feedback over traditional token-level loss, researchers achieved substantial gains in tool-calling reliability for models like Llama-3.
The push for standardized evaluation is crystalizing with GAIA v2, which expands its scope to include multi-modal reasoning and real-world tool discovery. Complementing this is FutureBench, which introduces the Brier Score to evaluate an agent's probabilistic forecasting. These efforts aim to replace brittle, prompt-dependent metrics with robust standards that can reliably measure performance across non-deterministic environments, as emphasized in the recent paper on the Necessity of a Unified Framework for LLM-Based Agent Evaluation.