Code-First Orchestration and Open Weights
From browser-based operators to self-modifying codebases, agentic infrastructure is finally catching up to the ambition.
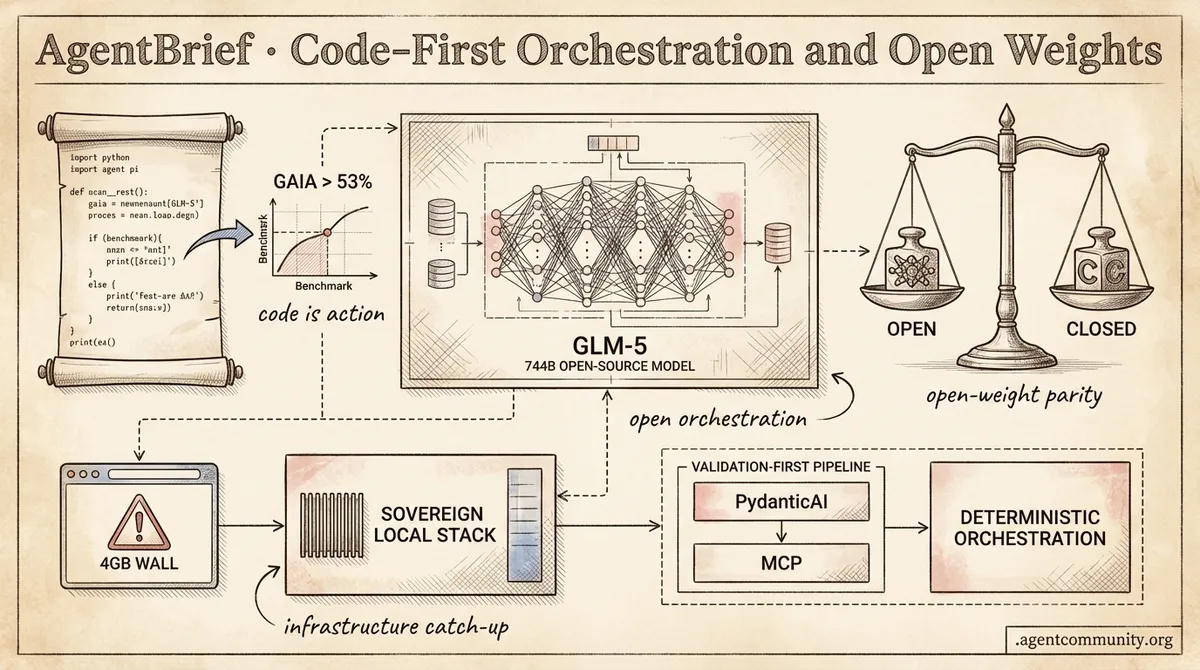
- Code-as-Action Ascends Hugging Face's smolagents and the OpenClaw surge signal a shift from rigid JSON schemas to executable Python, driving success rates on benchmarks like GAIA to over 53%.
- Open-Weight Parity New releases like the 744B parameter GLM-5 and MoE models from Qwen and MiniMax are proving that open-weight systems can now rival closed-source giants in reasoning and function calling.
- Reliability Infrastructure The industry is pivoting toward 'Validation-First' architectures, with Anthropic’s MCP and PydanticAI providing the type-safe plumbing needed for deterministic agent orchestration.
- Production Realities As OpenAI's 'Operator' targets the browser DOM, developers are hitting hardware constraints like the '4GB wall' in IDEs, forcing a move toward sovereign, optimized local stacks.
X Agent Intelligence
The gap between chatbots and autonomous systems just closed significantly this week.
The 'agentic web' isn't a future state—it's being shipped in the form of 744B parameter weights and self-modifying codebases today. This week, we saw the arrival of GLM-5, a model that doesn't just talk well but engineers well, topping SWE-bench with a staggering 77.8%. What’s more interesting is how it got there: an asynchronous RL framework called 'Slime' that treats training as a continuous improvement loop rather than a static phase. Meanwhile, OpenClaw has crossed the 197k star mark, proving that the developer appetite for agents that can literally rewrite their own source code is insatiable. We’re moving from agents that follow instructions to agents that optimize their own existence. For builders, this means the infrastructure is finally catching up to the ambition. Whether it's Microsoft and Cisco pivoting to 'AgenticOps' or Cursor 1.5 tripling its usage limits, the bottleneck is shifting from model capability to execution throughput. If you aren't thinking about how your agents self-correct and self-heal, you're building for the last era of AI.
GLM-5 Debuts as Open-Source Agent Powerhouse
Zai_org has unveiled GLM-5 (formerly 'Pony Alpha'), a massive 744B parameter MoE model that is aggressively claiming the open-source throne with 77.8% on SWE-bench Verified and 56.2% on Terminal-Bench 2.0 @wandb @LlmStats. Built on Huawei chips and trained on 28.5T tokens, the model utilizes DeepSeek Sparse Attention (DSA) to maintain efficiency despite its scale, specifically targeting long-horizon agentic benchmarks like BrowseComp (75.9%) and Vending Bench 2 ($4,432) @Zai_org @Xianbao_QIAN.
The technical community is particularly focused on the 'Slime' asynchronous RL framework introduced alongside the model, which reportedly boosts rollout throughput and shortens policy update cycles compared to traditional PPO or DPO methods @wandb @atlas_cloud_ai. As @ArtificialAnlys points out, GLM-5 currently holds the #1 open-weights spot on the Artificial Analysis Intelligence Index (50), signaling a serious rivalry with closed-source giants like Claude Opus 4.5/4.6.
For agent builders, the MIT license and hosting on Weights & Biases via CoreWeave (complete with $20 free credits) lowers the barrier to entry for high-reasoning local deployments @wandb @gm8xx8. While compute limits for rollouts remain a concern, the shift toward continual improvement frameworks like Slime suggests a future where agentic engineering relies on real-time policy updates rather than discrete training runs.
OpenClaw Surpasses 197k Stars as Creator Joins OpenAI
OpenClaw has officially overtaken AutoGPT in developer mindshare, hitting 197.2k GitHub stars as creator Peter Steinberger (@steipete) detailed the framework's 'self-modifying' capabilities on the Lex Fridman podcast @lexfridman @aitoolscoffee. The framework allows agents to read their own source code, identify bugs, and autonomously rewrite their logic, a feature that has already spawned lightweight forks like nanobot, which gained 5k stars in just 3 days @huang_chao4969.
The narrative around the project's independence was clarified this week: Steinberger is joining OpenAI to lead next-generation personal multi-agent systems, but OpenClaw itself will remain an independent open-source project under a dedicated foundation with OpenAI's backing @sama. This move follows high-profile acquisition interest from both OpenAI and Meta, emphasizing the strategic value of frameworks that can manage complex, recursive agent behaviors @lexfridman.
Despite the hype, practitioners are urging caution regarding deployment patterns, with experts like @JakeLindsay and @RektHQ warning against insecure VPS setups for self-modifying agents. The consensus is shifting toward local-first environments to protect sensitive data while allowing agents the freedom to experiment with their own codebases in a sandboxed manner.
In Brief
Cloud Giants Pivot to Agentic Operations
Microsoft and Cisco are repositioning cloud operations for an agent-native future. Microsoft Azure’s new Agentic Cloud Operations uses context-aware agents to manage the full cloud lifecycle, while Cisco's AgenticOps focuses on troubleshooting at machine speed to reduce root-cause analysis from hours to minutes @Azure @Cisco. Analysts suggest these self-healing systems will empower junior staff and drive toward self-driving networks, though hurdles like identity continuity across the lifecycle remain @AlanWeckel @MemoraXLabs.
ARC-AGI-3 and ALE-Bench Updates Push Reasoning Boundaries
Benchmarks are evolving to measure autonomous discovery rather than simple pattern matching. François Chollet has released a developer preview of ARC-AGI-3, following a new SOTA of 85.28% on ARC-AGI-2 achieved by the Agentica SDK through general-purpose code-writing agents @fchollet @vkhosla. Simultaneously, Sakana AI is pushing the boundaries of algorithm discovery with ALE-Bench, measuring an agent's ability to autonomously solve NP-hard tasks, highlighting a broader shift toward verifiable, multi-step research cycles @SakanaAILabs.
Cursor and Codex 5.3 Optimize the Agentic Developer Loop
Cursor and OpenAI are optimizing the developer loop for high-throughput agentic workflows. Cursor has significantly boosted usage limits for its Composer 1.5 mode—up to 6x through mid-February—to encourage the adoption of autonomous coding tools without escalating API costs @cursor_ai. This arrives as Codex 5.3 establishes itself as a premier daily driver for complex repo edits, with builders reporting reliable performance on 10-15k line changes and superior edge-case detection compared to rivals like Claude @gdb @sandengocka.
Quick Hits
Agentic Infrastructure
- Cloudflare Moltworker introduces self-hosted AI agents at the edge, removing local hardware dependency @Cloudflare.
- The xAI 'Macrohard' cluster is now the world's largest compute site with 1+ GW capacity @rohanpaul_ai.
Memory & Evaluation
- Long-term memory is being identified as the critical moat for production-grade agentic systems @hasantoxr.
- n8n released a new tutorial for building low-code evaluation frameworks using LLM-as-a-Judge patterns @n8n_io.
Models & Capabilities
- Kiro Assistant launches with 500+ capabilities powered by Amazon Bedrock and Kiro-CLI @bookwormengr.
- The 1.7B 'dots. ocr' model achieves SOTA on OmniDocBench, outperforming models 40x its size @techNmak.
- Perplexity introduces the pplx-embed family of multilingual embedding models using diffusion-pretraining @iScienceLuvr.
Reddit Dev Roundup
OpenAI enters the browser-agent wars as developers pivot toward type-safe, production-hardened infrastructure.
Today’s agentic landscape is shifting from "can it do it?" to "can it do it 1,000 times without failing?" We are witnessing a massive push toward what the community is calling 'Validation-First' architectures. OpenAI’s 'Operator' release marks a strategic pivot—focusing on the DOM rather than the messy world of OS-level pixels. But the real story isn't just the models; it is the plumbing. From PydanticAI’s type-safe rigor to Anthropic’s MCP becoming the 'USB-C for AI,' the industry is collectively sprinting toward the 'Day 10' wall—that moment where a cool demo needs to become a reliable product. We are seeing a move away from 'vibe-coding' and toward deterministic orchestration, where human-in-the-loop is not a failure, but a feature. Whether you are building with DeepSeek's hyper-efficient reasoning cores or LangGraph's state machines, the goal remains the same: building autonomous systems that do not just act, but act predictably. This issue dives into the frameworks and protocols making that reliability possible.
OpenAI Operator: Browser-Native Actions vs. OS-Level Control r/MachineLearning
OpenAI has officially entered the agentic browser space with 'Operator,' a research preview designed to navigate web interfaces autonomously. Unlike Anthropic's 'Computer Use' which relies on vision-based pixel coordinates and OS-level control, Operator is optimized for the browser's DOM and accessibility tree, allowing for higher precision in web environments @OpenAI. Early testers report a 94% success rate on deterministic procurement and travel booking tasks u/openai_dev, though the system's focus on the browser remains a key technical limitation compared to Anthropic's ability to navigate the entire operating system r/MachineLearning discussion.
While Operator handles dynamic elements better than previous script-based automation, high-security authentication and 'Canvas-heavy' sites remain significant hurdles. Security experts warn that the tool's 'god-mode' browser access necessitates strict sandboxing to prevent the 'permission bleed' issues seen in early Windows-based agentic tools u/security_lead. Furthermore, developers are identifying a move toward 'Validation-First' architectures to prevent Operator from entering high-frequency execution loops that can burn through API credits, a critical step in surmounting the 'Day 10' wall of production reliability @sama.
MCP Evolves into the 'USB-C for AI': Enterprise Adoption and Security Hardening r/ClaudeAI
Anthropic's Model Context Protocol (MCP) has transitioned from a niche developer tool to a foundational layer for agentic interoperability. The ecosystem has seen an explosion in scale, with the community now maintaining over 200 specialized MCP servers, far exceeding the initial 50 identified last month u/antoniog. This growth is anchored by major enterprise entries like Brave, Apollo, Zendesk, and Sourcegraph, while technical focus shifts toward 'Production Hardening' and transport-layer isolation (stdio and HTTP/SSE) to ensure a 'Least Privilege' framework where the LLM client must explicitly approve every tool execution @alexalbert__.
PydanticAI: Bringing Type-Safe Rigor to Agentic Workflows r/Python
The launch of PydanticAI has introduced a new level of rigor to agent development by leveraging Python's type hinting system to eliminate 'vibe-coding' in production. Unlike the more complex, graph-based orchestration found in LangGraph, PydanticAI ensures that every exchange between an agent and its tools is validated at runtime using Pydantic models @samuel_colvin. The framework has quickly surged to over 12,000 GitHub stars, reflecting an industry shift toward stable, model-agnostic infrastructure that supports native dependency injection for unit-testing agentic behavior—a feature @pydantic claims is essential for production reliability r/AI_Agents.
DeepSeek-V3 Establishes New Efficiency Frontier r/LocalLLaMA
DeepSeek-V3 matches GPT-4o's performance on ToolBench with a 90.8% win rate while slashing inference costs to $0.14 per 1M input tokens, making high-frequency self-correction loops economically viable u/DeepSeek_Official.
Browser-use Library Surpasses 18k Stars r/Python
The browser-use library now boasts over 18,500 GitHub stars, utilizing Playwright’s persistent_context to maintain login sessions and prevent 'identity amnesia' during multi-step web automation workflows r/Python.
LangGraph vs. CrewAI: The Battle for Deterministic Orchestration r/AI_Agents
Benchmarks in sensitive domains like legal tech show that moving from autonomous loops to human-in-the-loop validated patterns in LangGraph can boost task accuracy from 70% to over 95% r/AI_Agents.
Discord Community Digest
Massive MoE releases from Qwen and MiniMax are rewriting the agentic benchmark leaderboard.
The balance of power in the agentic web is shifting toward high-performance, open-weight models that finally rival closed-source giants in function calling and reasoning. Alibaba’s Qwen 3.5 and MiniMax-2.5 are proving that the gap is closing—provided developers have the VRAM to handle them. For agentic practitioners, this isn't just about raw parameter counts; it’s about the democratization of tool-use reliability and context window stability. While Qwen sets new records in coding logic, MiniMax is demonstrating that Mixture of Experts (MoE) architectures can achieve near-perfect reliability in complex function-calling tasks.
However, as models become more capable, our local development tools are beginning to show the strain. The emergence of a '4GB wall' in Cursor’s memory management highlights a growing disconnect between massive LLM context windows and the legacy architectures of our IDEs. From the rise of 'sovereign' local stacks like Pi Agent to the optimization of RAG through late chunking, the theme of the day is efficiency and control. Whether it's bypassing SEO noise with Exa's neural search or navigating the viral 'astroturfing' drama surrounding OpenClaw, the community is laser-focused on building robust, autonomous systems that can operate at scale without hitting the invisible ceilings of centralized providers.
Qwen 3.5 and MiniMax-2.5 Redefine Open-Weight Agentic Benchmarks
The open-weights landscape has shifted with the arrival of MiniMax-2.5, a 230B parameter MoE model that utilizes only 10B active parameters per token. Unsloth confirms that while the FP16 version requires 457GB of VRAM, their 3-bit GGUF quantization brings this down to 101GB, making it accessible for multi-GPU consumer setups. MiniMax-2.5 has demonstrated exceptional performance in tool-use, with MiniMax Documentation citing a 92.4% success rate on complex function-calling tasks, rivaling the reliability of Claude 3.5 Sonnet.
Simultaneously, Alibaba’s Qwen 3.5-397B-A17B has set new records for open-source reasoning, employing a hybrid attention mechanism that combines sliding window and global attention to stabilize its 256K context window. The Qwen Team reports that the model achieves 89.2% on HumanEval, outperforming many closed-source frontier models in coding logic. The community remains focused on Qwen’s ability to handle recursive reasoning without the grounding failures currently plaguing early builds of Gemini 3 Pro.
While Discord practitioners like eddiboi suggest Kimi K2.5 and GLM-5 are also in the mix, the sheer scale of the Qwen and MiniMax releases marks a significant milestone for sovereign agent builders who require high-reasoning capabilities without centralized API overhead.
Join the discussion: discord.gg/localllm
Cursor’s 4GB Memory Ceiling: Developers Battle OOM Errors
Developers using Cursor for heavy agentic workflows are hitting a hard 4GB memory limit, a byproduct of the default V8 heap size in its Electron-based architecture. hime.san identified that this ceiling is reached rapidly when the agent serializes long chat histories, with one user reporting a transcript reaching 180k lines before triggering a fatal Out-of-Memory error. While community members on the Cursor Forum report frequent stalls in the 'Composer' feature, users like wowjinxy suggest that without a 64-bit re-optimization of the serialization layer, manual workarounds like increasing --max-old-space-size remain the only current fix for long-horizon autonomous coding.
Join the discussion: discord.gg/cursor
OpenClaw Virality Sparks Social Marketing Conspiracy
The rapid ascent of OpenClaw, an open-source alternative to Claude Code, has triggered intense skepticism within the developer community regarding its 3,400+ GitHub stars in under 72 hours. As noted by TrentBot, users are questioning if the surge was driven by organic interest or a coordinated 'ghost' marketing campaign, with some even floating unverified rumors of an OpenAI acquisition. While observers like @vladquant point to active commits as proof of legitimacy, security experts like @_beausievers warn that the tool's 'prompt-injection-heavy' architecture requires a full audit before production use.
Join the discussion: discord.com/invite/1128867683291627614
Pi Agent and the Rise of Sovereign Local Orchestration
Pi Agent is becoming the backbone for local agentic workflows by successfully scaling 120B models to a 128K context window through its seamless Ollama integration. According to .caldor, the system's ability to auto-configure context windows solves the primary friction point in local setups, while bird0861 notes that 12-16GB of VRAM has become the functional baseline for these sovereign stacks. The availability of high-performance quants from noctrex is now enabling robust reasoning on consumer-grade hardware, providing a viable private alternative to centralized endpoints.
Join the discussion: discord.gg/ollama
Solving State Persistence in n8n Agentic Bots
To prevent 'one-and-done' failures in Telegram bots, eimgai and bashscript47 recommend using Window Buffer Memory and Luxon-powered date objects to maintain conversation history and prevent logic loops. Join the discussion: discord.gg/n8n
Exa and Playwriter: Scaling Sovereign Web Agents
@exa_ai and remorses are enabling a 40% reduction in token waste by combining neural search with high-level browser automation that supports persistent contexts.
The Rise of Late Chunking and Lexical-First RAG
Builders like harshinikn20 are shifting toward 'Late Chunking' and BM25-first retrieval to achieve a 20% boost in retrieval performance without the 'reasoning tax' of upfront indexing. Join the discussion: discord.gg/anthropic
HuggingFace Research Hub
Hugging Face's smolagents hits 53% on GAIA as the industry pivots from JSON schemas to executable Python.
Today’s release of smolagents by Hugging Face isn’t just another library launch; it’s a signal of a broader architectural shift. For too long, we’ve been taxing our models with the 'JSON overhead,' forcing them to map complex intent into rigid schemas that break at the first sign of a nested loop. By moving to a code-first orchestration model, we’re seeing success rates on benchmarks like GAIA jump to 53.3%. This mirrors a larger trend we’re tracking today: the transition from 'guessing' to 'verifying.' Whether it’s NVIDIA’s Cosmos-Reason-2 simulating physical futures or the rise of test-time RL search via Monte Carlo Tree Search, the Agentic Web is getting a lot better at thinking before it acts. We are seeing a convergence where lightweight models, often under 7B parameters, are outperforming proprietary giants by specializing in desktop automation and structured reasoning. For builders, the message is clear: the future of agents isn't just about bigger LLMs—it’s about smarter orchestration, standardized protocols like MCP, and execution-centric evaluation. The era of the general-purpose chatbot is yielding to the era of the autonomous, code-verified agent.
Smolagents: Scaling Performance via Code-First Orchestration
Hugging Face has launched huggingface/smolagents, a minimalist library that replaces traditional, brittle JSON tool-calling with executable Python code. This architectural shift has yielded a 53.3% success rate on the GAIA benchmark, outperforming many larger models by eliminating the 'JSON tax' and allowing agents to handle complex logic like nested loops and error correction more natively.
The ecosystem is rapidly expanding into multimodal and production-grade territory. The introduction of huggingface/smolagents-can-see enables agents to process visual inputs via Vision-Language Models (VLMs), while integration with huggingface/smolagents-phoenix provides critical observability through Arize Phoenix for tracing and evaluation. These tools move the industry toward a 'code-as-action' standard where even small models execute high-fidelity tasks with enterprise reliability.
VLM-Powered Agents Outperform Proprietary Models in Desktop Automation
The race for autonomous computer use has shifted to specialized, high-precision Visual Language Models (VLMs) like the Hcompany/holo1 family. Achieving a 62.4% success rate on the ScreenSpot benchmark, this 4.5B parameter model notably outperforms GPT-4V’s 55.4%, while edge-optimized tools like huggingface/smol2operator allow lightweight models to handle complex desktop tasks with lower latency than massive proprietary counterparts.
The Test-Time Revolution: Scaling Reasoning Beyond Training
Agentic planning is moving from static Chain-of-Thought to dynamic test-time RL search, where models allocate extra compute at inference to explore multiple reasoning paths. Tools like AI-MO/kimina-prover integrate Monte Carlo Tree Search (MCTS) into mathematical proofs to allow for backtracking, while ServiceNow-AI/apriel-h1 distills these complex reasoning traces into accessible 7B and 32B models to reduce the 'reasoning tax' on competitive benchmarks.
MCP Standardizes the Agent-Tool Interface
The Model Context Protocol (MCP) is rapidly standardizing how agents interact with external data, allowing for the implementation of autonomous Python agents in fewer than 70 lines of code. By decoupling tool definitions from model logic, MCP eliminates the 'integration tax' and enables a 'plug-and-play' reality where agents instantly inherit capabilities from any compliant server, as demonstrated in the Agents-MCP-Hackathon.
Physical AI: NVIDIA Cosmos-Reason-2 and the Robotics Data Standard
NVIDIA's Cosmos-Reason-2 introduces visual-thinking for long-horizon planning in physical environments, supported by the lerobot open-source dataset initiative.
Beyond Static Evaluation: Gaia2 and Dynamic Agent Environments
Hugging Face has introduced Gaia2 and the Agent Reasoning Environment (ARE) to test true autonomous planning across 1,000+ tasks within dynamic feedback loops.
Reinforcement Learning for Resilient Tool-Use
The Qwen2.5-7B-Instruct-ToolRL-PPO model utilizes RL to enhance function-calling precision and enable agents to self-correct based on execution feedback.
Standardizing the Agentic Layer via Unified Tooling
Hugging Face's Unified Tool Use standard and StructuredCodeAgent resolve fragmentation by abstracting model-specific templates into a common, Pydantic-validated API.