Reasoning Breakthroughs and Self-Modifying Stacks
Opus 4.6 shatters reasoning benchmarks while self-modifying architectures dismantle the JSON tax for agentic workflows.
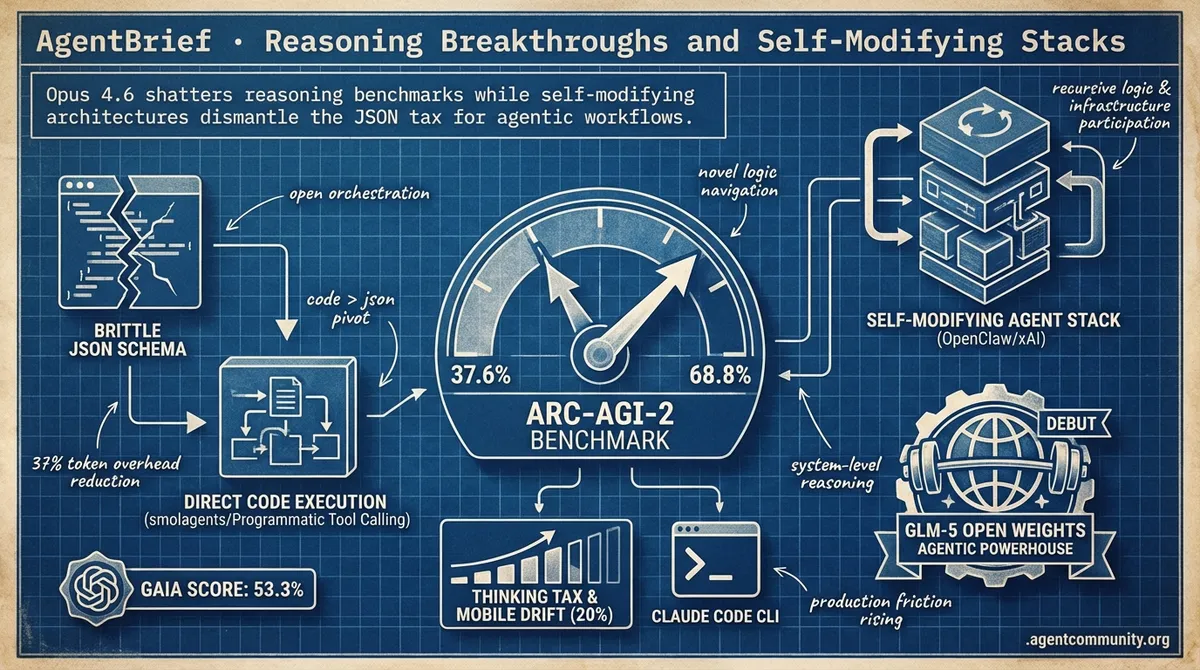
- Reasoning Frontiers Expanded Anthropic’s Opus 4.6 has effectively doubled the ARC-AGI-2 benchmark from 37.6% to 68.8%, signaling a shift from token prediction to systems capable of navigating novel logic.
- Executing Over Prompting The industry is pivoting from brittle JSON schemas to direct code execution; Hugging Face’s smolagents and Anthropic’s Programmatic Tool Calling are slashing token overhead by 37% while pushing GAIA scores to 53.3%.
- Recursive Architectures Mature Frameworks like OpenClaw and xAI’s compiler-free binary proposals suggest a future where agents aren't just consumers of code, but active participants in evolving their own logic and infrastructure.
- Scaling Production Friction As orchestration moves toward terminal-native tools like Claude Code CLI, builders must now navigate the rising thinking tax of high-tier models and a 20% accuracy drift on mobile hardware.
X Intelligence
Your agents are starting to rewrite themselves—and they no longer need compilers to do it.
The agentic web is shifting from experimental scripts to hardened, self-evolving infrastructure. This week, we saw the arrival of GLM-5, an open-weights powerhouse that rivals frontier models on SWE-bench, proving that the local execution of agentic tasks is no longer a compromise. Meanwhile, OpenClaw’s ascent to 200k GitHub stars signals a massive developer appetite for self-modifying architectures—frameworks where the agent isn't just a consumer of code, but an active participant in its own logic. Even the infrastructure layer is being re-imagined, with xAI proposing a future where agents bypass compilers entirely to generate optimized binaries. For those of us shipping agents today, the message is clear: the stack is becoming recursive. We are moving away from rigid prompting and toward systems that possess the memory, tool-access, and self-awareness to navigate complex environments autonomously. Whether it's running agents at the edge via Cloudflare or leveraging SOTA document intelligence with dots.ocr, the primitives for production-grade autonomy are finally here.
GLM-5 Debuts as Open Weights Agentic Powerhouse
Z.ai (@Zai_org) has officially released GLM-5, a massive 744B parameter Mixture-of-Experts (MoE) model with 40B active parameters, trained on a staggering 28.5T tokens. The model utilizes DeepSeek Sparse Attention (DSA) and a novel asynchronous RL framework called 'Slime' to optimize for agentic tasks, as detailed by @Zai_org and supported by early testing on W&B Inference @wandb. Previously known anonymously as 'Pony Alpha' on OpenRouter, the model dominated leaderboards before its reveal as the first frontier-class model trained entirely on Huawei chips @Xianbao_QIAN @SarahAnnabels.
In terms of performance, GLM-5 has achieved state-of-the-art results for open-weights models, scoring 77.8% on SWE-bench Verified—narrowly trailing Claude Opus 4.5’s 80.9%. It also leads open models on Vending Bench 2 with a score of $4,432 and ranks #1 on the Artificial Analysis Intelligence Index @LlmStats @ArtificialAnlys. These metrics suggest that the gap between proprietary and open-weights models for complex engineering and browsing tasks is closing rapidly @pierremouchan.
For agent builders, the MIT-licensed GLM-5 represents a major win for local deployment and sovereign AI. The 'Slime' framework’s ability to triple throughput in RL by decoupling rollouts makes it particularly viable for high-iteration agentic workflows @FreelanceHelper. As noted by @milvusio, the availability of such a capable model for local RAG and tool-use applications provides a powerful alternative to API-locked frontier models.
OpenClaw Surpasses 200k GitHub Stars with Self-Modifying Architecture
The open-source agent framework OpenClaw has surged past 200k GitHub stars, officially overtaking AutoGPT to lead the AI agents leaderboard @shakker @Param_eth. Creator Peter Steinberger discussed the project's viral momentum on the Lex Fridman podcast, emphasizing a 'self-modifying' architecture where the agent is aware of its own source code and can autonomously debug or rewrite its logic @lexfridman. This recursive capability, combined with a security-first vision recently published by Steinberger, has fueled massive community adoption @steipete.
Community tutorials from creators like @rileybrown and @Rasmic have helped demystify the framework's core components: the Gateway interface, the LLM core, the 'Skills' plugin system via ClawHub, and persistent memory. Unlike more rigid predecessors, OpenClaw is designed for recursive self-improvement and local execution, which @godofprompt identifies as its primary differentiator. However, this power comes with risks, as evidenced by a recently patched 'log poisoning' vulnerability that allowed for indirect prompt injection @The_Cyber_News.
As acquisition rumors involving OpenAI and Meta circulate, practitioners are watching closely to see if OpenClaw can maintain its independent OSS status @MatthewBerman. For now, it remains a premier case study in production-grade, self-correcting agents. Builders like @haltakov praise its autonomy for multi-agent orchestration, suggesting it represents a shift toward software that manages its own lifecycle without human intervention.
xAI Targets Direct Binary Generation for Agents
Elon Musk has outlined a vision for xAI where agents generate optimized binaries directly from prompts, potentially eliminating the need for traditional compilers by the end of 2026 @rohanpaul_ai. Musk claimed that AI can outperform standard compilers by focusing on outcomes rather than intermediate code, with Grok Code expected to reach state-of-the-art status within months @XFreeze. This effort is supported by the 'Macrohard' cluster, which features 27,000 GPUs and 1+ GW of power, making it one of the largest infrastructure deployments dedicated to autonomous engineering @SawyerMerritt.
However, the technical community has expressed significant skepticism regarding this approach. Experts like @burkov and @thomaswue have questioned whether the probabilistic nature of LLMs can provide the determinism required for reliable binary generation. Critics also point to the lack of debuggability and the difficulty of verifying binaries without source code as major hurdles for adoption in professional environments @DanielGlejzner @realamlug.
If successful, this move would represent a fundamental shift in the agentic web, moving agents closer to the metal. While xAI bets on massive compute to solve the problem of autonomous engineering @beffjezos, practitioners like @minilek warn that without formal verification, such systems risk creating a 'black box' of software that is impossible to audit. The tension between raw infrastructure power and formal reliability will be the key narrative to watch as xAI's 2026 deadline approaches.
In Brief
Cloudflare Moltworker Enables Edge Agents
Cloudflare has launched Moltworker, a middleware framework that allows developers to run self-hosted OpenClaw agents directly on Cloudflare Workers. By utilizing the Sandbox SDK and R2 for persistent storage, Moltworker eliminates the need for local hardware like a Mac Mini, offering a low-latency edge deployment that is reportedly up to 80% cheaper than traditional VPS setups @agentcommunity_. While Cloudflare engineer Sid @chatsidhartha describes it as a technical showcase, the ability to deploy global, distributed agents via the Cloudflare Developer Platform @Cloudflare provides a significant new deployment pattern for personal AI assistants.
Kiro Assistant Debuts as Tool-Rich Desktop Agent
Amazon engineer GDP has released Kiro Assistant, an open-source Electron app that transforms the Amazon Kiro primitive into a general-purpose agent with over 500 capabilities. Powered by Amazon Bedrock models like Claude Opus and Qwen3-Coder, the assistant uses a 'Bitter Lesson' architecture to autonomously execute tasks ranging from Excel modeling to building podcasts via MCP plugins like Composio and Playwright @bookwormengr. Early adoption within AWS circles @kyhayama highlights its potential as a model-agnostic desktop primitive for builders who need deep tool integration and local task execution @uAWSBuilderFeed.
ALE-Bench and ARC-AGI-3 Push Reasoning Limits
Sakana AI has updated ALE-Bench to measure autonomous algorithm engineering on NP-hard tasks, highlighting the shift toward verifiable, multi-step agentic reasoning. The update showcases frameworks like KAPSO and agents like ALE-Agent that are pushing beyond simple pattern matching to discover new algorithmic solutions @SakanaAILabs. Simultaneously, François Chollet has released a developer preview of ARC-AGI-3 to challenge agents on higher levels of abstraction, following recent SOTA breakthroughs in code-writing agents that reached 85.28% on the previous version @fchollet @vkhosla.
dots.ocr 1.7B Sets New Document Intelligence SOTA
The 1.7B parameter dots.ocr model has achieved state-of-the-art performance on OmniDocBench, outperforming much larger models like GPT-4o and Qwen2-VL-72B. With a unified architecture for text, tables, and layouts, the model is designed for efficient local deployment via vLLM, making it an ideal tool for agentic workflows requiring fast document parsing @techNmak. Despite some community skepticism regarding benchmark methodologies and performance on low-quality scans @baicai_1145, its efficiency on consumer hardware positions it as a critical component for data-extraction agents @ysu_ChatData.
Quick Hits
Agent Frameworks & Orchestration
- Swarms Cloud is positioning its platform for orchestrating complex multi-agent workflows in the cloud @KyeGomezB.
- CrewAI is preparing a new update focused on solving agent building and observability bottlenecks @joaomdmoura.
- Spine_AI Swarm has introduced 'watch and act' workflows for continuous monitoring tasks @hasantoxr.
Memory & Context
- Long-term agent memory is being targeted with $80k+ in prizes to incentivize new moats @hasantoxr.
- Contrail is an experimental 'flight recorder' providing per-repo memory for agentic coding sessions @krishnanrohit.
Tool Use & Developer Experience
- Supabase users can now copy internal AI prompts directly for use in local agent workflows @kiwicopple.
- Cursor has temporarily increased usage limits for Composer 1.5 by up to 6x @cursor_ai.
Agentic Infrastructure
- Microsoft has launched Agentic Cloud Operations to integrate context-aware agents into the cloud lifecycle @Azure.
- Cisco is debuting AgenticOps tools to automate operations in the AI era @Cisco.
Reddit Intel
Anthropic’s tool-calling GA and self-evolving MCP servers mark the end of reactive agent loops.
The narrative of the 'agentic web' is shifting from simple prompt engineering to deep architectural orchestration. For months, developers have wrestled with 'token-eating loops' and context window amnesia, but today's developments suggest we are finally building the infrastructure to move past these bottlenecks. Anthropic’s move to General Availability for Programmatic Tool Calling (PTC) is the headline act, offering a massive 37% reduction in token overhead by allowing models to execute complex logic in a single pass. This isn't just an efficiency gain; it's a fundamental change in how agents interact with their environment.
Simultaneously, we are seeing the rise of Hierarchical Memory Systems and self-evolving MCP tools that allow agents to write their own capabilities on the fly. These aren't just technical curiosities; they represent the transition from brittle, stateless bots to persistent digital employees. However, as the gap between high-end hardware and edge devices widens—evidenced by the 20% accuracy drift on mobile NPUs—the challenge for builders is no longer just about the model. It's about building a reliable, governed, and hardware-aware stack that can survive the 'Day 10' wall of production use. Today’s issue dives into the benchmarks, protocols, and architectural shifts making that survival possible.
Programmatic Tool Calling Cuts Tokens by 37% r/ClaudeAI
Anthropic has officially moved Programmatic Tool Calling (PTC) into General Availability, a shift that allows Claude to write and execute Python scripts to orchestrate multiple tools in a single sandbox pass. According to u/shanraisshan, this reduces token usage by 37% because it eliminates the need for the model to round-trip back to the context window after every individual tool call. Instead of three inference passes for three tools, the model can now handle them in one, effectively mitigating the 'token-eating' loops that plague non-deterministic agentic tasks as highlighted by @alexalbert__.
Additional updates in this release include a Tool Search Tool that boasts an 85% reduction in token overhead for tool definitions by dynamically fetching schemas only when needed. Furthermore, a new Tool Use Examples feature has reportedly pushed accuracy from 72% to 90% by providing high-density few-shot guidance directly in the execution layer. Users such as u/BuildwithVignesh note that this allows for pre-planned, conditional tool logic to be executed before results even reach the main context window.
This shift fundamentally changes the agentic workflow from reactive to proactive execution. By handling logic within the sandbox, developers can solve the 'instruction drift' issues seen in previous high-context models, where u/Impressive-Deal-6022 notes that even advanced models like Opus 4.6 can ignore simple instructions if context management is not strictly enforced.
Beyond the Window: The Shift from Stateless Context to Persistent Agent Memory r/AI_Agents
Practitioners are moving away from brute-force prompt engineering toward Hierarchical Memory Systems (HMS) to avoid the 70% accuracy drop-off seen in stateless recursive loops. While models like Opus 4.6 offer 1M tokens, they often suffer from 'identity amnesia' if state is not explicitly managed, leading developers like u/arapkuliev to argue that memory, not context, is the true production hurdle. To combat this, @memgpt_ai and others are adopting 'Virtual Context Management,' a pattern that treats LLM context like RAM and external databases like disk storage to maintain coherence across months of interaction, helping agents finally surmount the 'Day 10' wall as noted by @skirano.
Self-Evolving Agents: MCP Tools That Write Themselves r/mcp
A breakthrough meta-server for the Model Context Protocol now enables agents to autonomously generate and register their own tools mid-conversation. Developed by u/Shot_Buffalo_2349, this capability allows agents to bypass manual developer updates by writing Python-based logic and invoking it immediately. While this ecosystem nears 300 public servers—including professional-grade bridges for Salesforce u/modelcontextprotocol—security researchers like u/Eastern-Ad689 warn that self-writing tools could exacerbate 'Confused Deputy' vulnerabilities if agents generate logic that bypasses sandboxing constraints.
Snapdragon NPU Variance Triggers 20% Accuracy Drift r/LocalLLaMA
Testing identical INT8 models across five Snapdragon chipsets revealed an accuracy range from 91.8% to a dismal 71.2%, proving cloud-based benchmarks are insufficient for edge agents. This 20.6% performance gap discovered by u/NoAdministration6906 highlights how lower-tier NPUs struggle with quantization noise. To mitigate these hardware bottlenecks, developers are turning to high-efficiency tools like the GreedyPhrase tokenizer, which u/reditzer claims compresses data 2.24x better than GPT-4o at a throughput of 42.5 MB/s.
Prime Intellect launches INTELLECT-3.1, a 106B MoE model optimized for agents r/LocalLLaMA
INTELLECT-3.1 achieves a 34.2% score on GAIA, outperforming Llama 3.1 70B and targeting complex tool-use tasks.
Agent simulators and 'openterms-mcp' rise to combat 80% failure rates r/AI_Agents
New simulators from u/Recent_Jellyfish2190 detect token-eating loops before they hit production environments.
Adversarial Multi-Agent Debate boosts reasoning performance by 15% r/MachineLearning
Research cited by @Du_et_al shows that forcing agents into conflicting roles like 'Efficiency Optimizer' vs 'Security Hardener' prevents hallucination echo chambers.
Nango and Composio bridge the 'Auth-as-a-Service' gap for agents r/AI_Agents
Specialized layers are offering a 40% reduction in development time by handling the 'nightmare' of production-grade OAuth2 flows for agents.
Discord Debrief
Anthropic's new models double reasoning benchmarks as Perplexity gates deep research behind a $2,000 paywall.
The agentic web reached a significant milestone this week with Anthropic’s release of Opus 4.6, a model that effectively doubles the industry’s previous reasoning benchmarks. Moving from 37.6% to 68.8% on the ARC-AGI-2 benchmark isn't just a marginal gain; it signals a transition from models that predict the next token to systems that can navigate novel logic. For builders, this 'recursive verification' capability comes at a price—a literal 'thinking tax' that is depleting usage tiers faster than ever before. This economic shift is mirrored in the toolchain, where Anthropic’s new Claude Code CLI and Cursor’s planning modes are moving toward stateful, terminal-native orchestration that bypasses traditional IDE limitations. As we scale these autonomous systems, the friction points are shifting from 'how do we build it' to 'how do we secure it' and 'how do we pay for it.' We see this in the pivot toward formal proofs for AI-generated code and the aggressive tier-inflation in consumer tools like Perplexity. Whether you are running 80 tokens/second locally with Qwen or orchestrating through ephemeral n8n environments, the theme is clear: we are building the infrastructure for agents that don't just chat, but operate with high-stakes autonomy.
Opus 4.6 Cracks ARC-AGI-2 as Anthropic Claims Reasoning SOTA
Anthropic has redefined the frontier of reasoning with the release of the Claude 4.6 suite, featuring the paradigm-shifting Opus 4.6. The flagship model recorded a 68.8% on the ARC-AGI-2 benchmark, a massive leap from the 37.6% seen in previous iterations and significantly outpacing GPT-5.2 Pro's 54.2% @anthropic_ai. According to technical analysis by everlasting_gomjabbar, the model's success stems from a 'recursive verification' architecture that allows it to self-correct novel logic puzzles before outputting.
Alongside the reasoning gains, Anthropic has officially entered the agentic IDE space with Claude Code, a research preview CLI tool built for high-velocity local development. Unlike GUI-heavy counterparts, Claude Code operates as a terminal-native peer capable of executing shell commands and managing complex file refactors. blostoise_aka describes the tool as a 'game changer' for agentic loops, specifically for its ability to maintain stateful reasoning within the developer's existing shell environment.
However, this power comes with a 'thinking paradox' where the model over-analyzes trivial edits, resulting in a 30-40% higher token cost as noted by @alexalbert__. To mitigate these costs, developers are increasingly relying on prompt caching and the new 1M context window beta, though blostoise_aka warns that 'Thinking' tokens are depleting standard usage tiers 3x faster than previous versions.
Join the discussion: discord.gg/claude
Cursor Formalizes 'Plan-then-Execute' Workflow
Cursor’s new /plan mode allows developers to architect solutions before execution, a feature theauditortool_37175 highlights for its ability to flush the context window and bypass the 4GB memory ceiling inherent in Electron-based IDEs. While Cursor’s Dynamic Context Discovery aims to automate background retrieval, community feedback on the Cursor Forum suggests a growing demand for transparency regarding 'shadow-read' files to prevent hallucination-heavy execution.
Join the discussion: discord.gg/cursor
Qwen 3 Coder Hits 80 Tokens/Second on Blackwell
The local LLM landscape is seeing a surge in performance as Qwen 3.5 Coder establishes itself as a rival to Claude 3.5 Sonnet, with u/DeepLearningDev reporting throughput reaching 80 tokens/second on consumer-grade hardware via nvfp4 Blackwell support. Simultaneously, practitioners like thisadviceisworthles are pioneering 'grid-tied' AI architectures that use local GPUs for speculative decoding while validating final sequences against cloud APIs to reduce costs by 30-50%.
Join the discussion: discord.gg/localllm
Security Shifts to Formal, Deterministic Proofs
As a 2026 Veracode report reveals that 36% of AI-generated code contains security vulnerabilities, the industry is pivoting toward 'Proof-Carrying Code' using tools like Kani and CrossHair to generate machine-checkable proofs. This move toward formal methods is essential for scaling sovereign agentic stacks, with builders like @vladquant advocating for a 'Formal Supervision' layer that acts as a deterministic gatekeeper to reject hallucinations with 100% mathematical certainty.
Join the discussion: discord.gg/localllm
Perplexity Max Debuts at $2,000/Year
Perplexity Max launches at $2,000/year as standard Pro tier deep research limits are slashed by 99% to just 20 per month. Join the discussion: discord.gg/perplexity
n8n Leverages Ephemeral Compute for Agents
Developers are using ephemeral sandboxes on sprites.dev and Discord bots to scale n8n into a central nervous system for agents. Join the discussion: discord.gg/n8n
Ollama v0.16.2 MLX Dependency Leak
A critical MLX dependency leak in Ollama v0.16.2 is causing x86 architecture users to face performance regressions and initialization errors. Join the discussion: discord.gg/ollama
HuggingFace Insights
Hugging Face’s smolagents and the MCP standard are dismantling the complexity of agentic orchestration.
The 'agentic web' isn't a future promise; it's a structural shift happening right now in the terminal. For months, we've wrestled with the 'JSON tax'—the brittle, token-heavy overhead of forcing LLMs to speak in schemas. This week, the industry reached a tipping point. Hugging Face’s smolagents demonstrated that letting agents write executable Python isn't just 'neater'—it’s functionally superior, pushing GAIA benchmark scores to 53.3%.
But the revolution isn't just in how agents think; it's where they live. From NVIDIA’s Cosmos Reason 2 bringing visual reasoning to humanoid robots, to Gemma 3 270M variants running function calls locally on Android, the 'frontier' is fragmenting. We are moving away from monolithic, proprietary 'black boxes' toward a tiered architecture: massive models for deep research and tiny, specialized agents for local execution. Whether you are building scientific research pipelines with ResearchGym or automating a desktop with Holo1, the message is clear: the most effective agents are those that act directly on the world, not just those that talk about it. It’s time to stop prompting and start executing.
Smolagents Scales to 53% on GAIA via Code-First Orchestration
Hugging Face's huggingface/smolagents has fundamentally challenged the dominance of JSON-based tool calling by proving that agents writing executable Python code are more efficient and robust. This 'code-as-action' approach has propelled the framework to a 53.3% success rate on the huggingface/beating-gaia benchmark, significantly outperforming traditional JSON agents. The core architectural advantage lies in the ability to handle nested loops, conditional logic, and native error correction—tasks that frequently cause JSON-based agents to hallucinate.
By stripping away the token overhead and brittle mapping required for schemas, smolagents allows even smaller models to execute high-fidelity tasks previously reserved for massive proprietary LLMs. The ecosystem has rapidly expanded to include multimodal capabilities via huggingface/smolagents-can-see, allowing agents to process visual inputs. To address production requirements, the integration with huggingface/smolagents-phoenix provides deep observability, enabling developers to trace complex multi-step trajectories in real-time.
ScreenEnv and Holo1: The New Standard for Local GUI Automation
The landscape of GUI agents is shifting toward specialized, high-precision models like the 4.5B parameter Surfer-H agent. Part of the Hcompany/holo1 family, this model achieved a 62.4% success rate on the ScreenSpot benchmark, notably surpassing GPT-4V's 55.4% in similar desktop navigation tasks. This performance is facilitated by huggingface/screenenv, a unified environment that integrates complex desktop tasks from OSWorld and Mind2Web, allowing for seamless full-stack agent deployment and local execution.
Open-Source 'Deep Research' Ecosystem Challenges Proprietary Search Agents
The open-source community is rapidly decentralizing 'Deep Research' capabilities through transparent, multi-agent workflows. Central to this shift is the Open Deep Research initiative, which leverages smolagents to coordinate specialized workers for web-scale retrieval. Live implementations in the miromind-ai/MiroMind-Open-Source-Deep-Research Space demonstrate that models like Qwen2.5-72B-Instruct provide the necessary reasoning density to rival commercial alternatives, as noted by @aymeric_roucher.
MCP-Powered Agents Built in Fifty Lines of Code
The Model Context Protocol (MCP) has emerged as the open standard for connecting LLMs to external data, drastically simplifying the 'integration tax'. Recent documentation from Hugging Face demonstrates that developers can now instantiate fully functional, MCP-powered agents in fewer than 50 lines of Python code. This democratization is further supported by the Unified Tool Use initiative, which provides a Pydantic-validated abstraction layer, ensuring agents can switch between model providers like Qwen2.5-72B without rewriting core logic.
Quick Hits: Benchmarks, Physical AI, and Tiny Models
• ResearchGym huggingface/papers/2501.07730 introduces an environment with 39 sub-tasks to automate end-to-end scientific research evaluation. • NVIDIA Cosmos Reason 2 huggingface/blog/nvidia/nvidia-cosmos-reason-2-brings-advanced-reasoning treats long-horizon robotics planning as a sequence of visual predictions. • Gemma 3 270M variants like distil-labs/distil-gemma3-270m-SHELLper enable high-fidelity local function calling on Android hardware. • Hugging Face and LangChain huggingface/blog/langchain launched a partner package to standardize tool-calling for Llama-3.1 and Qwen models.