Code-as-Action and Sovereign Stacks
From direct binaries to minimalist orchestration, the agentic layer is moving from chat wrappers to stateful operating systems.
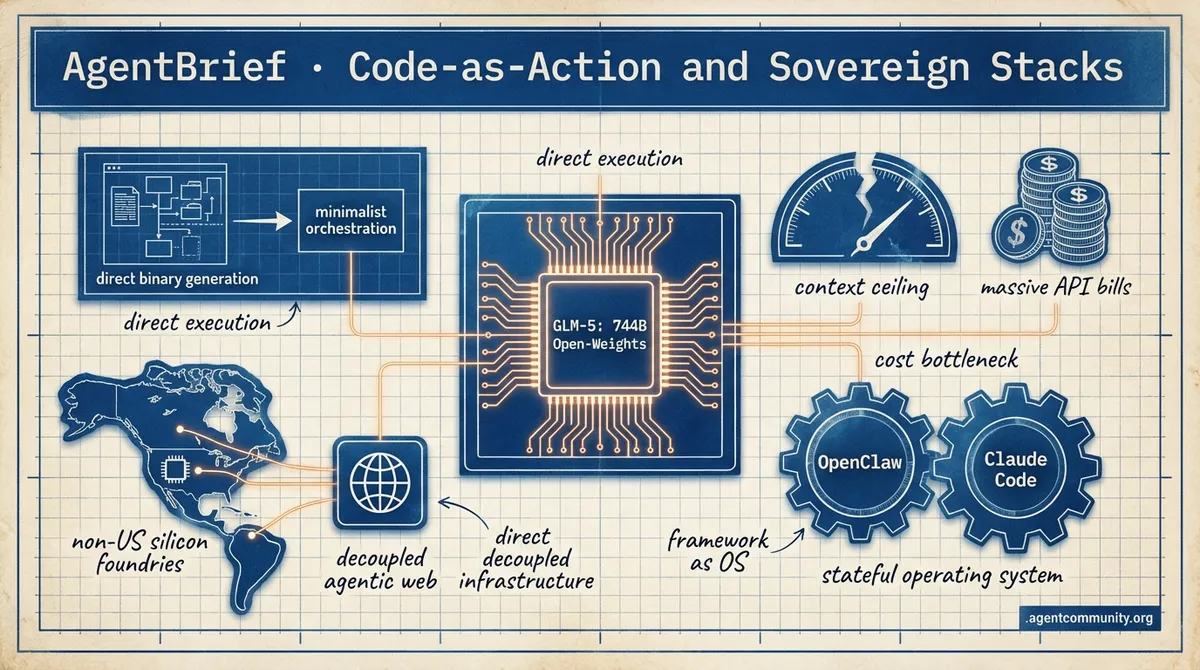
- The Death of JSON Tax Hugging Face's smolagents and xAI's direct binary generation signal a definitive shift toward minimalist 'code-as-action' frameworks that outperform bloated orchestration layers.
- Sovereign Intelligence Rising Developments like Z.AI’s GLM-5 on non-US silicon and OpenAI’s massive infrastructure play in India highlight a decoupling of the agentic web from traditional centralized hardware.
- Benchmark Saturation vs. Production Reality While Gemini 3.1 Pro and Opus 4.6 are shattering OSWorld and GAIA benchmarks, builders are hitting 'context ceilings' in IDEs and facing massive API bills from unoptimized execution loops.
- Frameworks as Operating Systems The milestone of 200,000 stars for OpenClaw and the move toward isolated worktrees in Claude Code suggest that agent frameworks are evolving into robust, stateful environments for autonomous work.
The Sovereign Stack
If you aren't building for persistent memory and direct tool-use, your agents are already legacy.
We are witnessing a fundamental decoupling in the agentic web. On one side, we have the emergence of the sovereign stack—Z.AI’s GLM-5 proving that world-class agentic reasoning can happen on non-US silicon using novel RL frameworks like Slime. On the other, we have the efficiency play, where xAI is threatening to bypass the compiler entirely to generate direct binaries from prompts. For builders, this means the abstraction layer is moving. It’s no longer just about the prompt; it’s about the underlying infrastructure that supports long-horizon execution and self-modifying code. OpenClaw’s 200,000-star milestone and its creator’s move to OpenAI signal that agent frameworks are no longer hobbyist toys—they are the new operating systems for autonomous work. Whether you’re deploying AgenticOps in the enterprise with Microsoft or hacking local-first persistent memory on an ESP32, the goal is the same: moving from stateless chat to stateful, autonomous action. Today’s issue dives into the tools and benchmarks defining this transition. It is time to stop building wrappers and start building systems.
Z.AI Launches GLM-5: 744B Open-Weights Powerhouse for Agentic Engineering
Z.AI (@Zai_org) has released GLM-5, a 744B parameter Mixture-of-Experts (MoE) model trained on 28.5T tokens using Huawei Ascend chips. This release is significant for its use of the novel Slime asynchronous RL framework, which decouples rollouts to achieve 3x post-training throughput in agentic tasks @Zai_org @Xianbao_QIAN. MIT-licensed and optimized for long-horizon workflows, it is available day-zero for builders on W&B Inference @OpenRouter.
In terms of performance, GLM-5 achieves 77.8% on SWE-bench Verified, making it the #1 open model and trailing only Claude Opus 4.5. It also leads open models on Terminal-Bench 2.0 with a score of 56.2% and ties Claude Opus 4.5 on the Artificial Analysis Intelligence Index @TheKoderZ @LlmStats. While it beats Claude 3.5 Sonnet on LiveBench agentic coding, real-world tests from @bridgemindai suggest it still lags behind Opus 4.6 in bridge-bench benchmarks.
For agent builders, this represents a major shift toward sovereign engineering tasks that do not rely on US-restricted hardware. Early adopters like @altryne praise its reasoning capabilities for complex system tasks. However, production speed and reliability concerns persist when compared to the Claude family in web-based builds @gmi_cloud.
Watch for how the community adopts the Slime framework; its ability to optimize rollouts could become a standard pattern for fine-tuning agents on specialized tool-use datasets.
OpenClaw Surpasses 200k GitHub Stars as Creator Joins OpenAI
OpenClaw has solidified its position as the leading AI agent framework by surging past 200,000 GitHub stars, outpacing even VSCode in community interest @cfsuman. Creator Peter Steinberger has officially joined OpenAI to advance personal AI agents, while transitioning OpenClaw to an independent foundation with continued support from his new employer @steipete @bonybean. This move signals a transition from community experiment to foundational infrastructure for the agentic web.
Security remains the most critical conversation for the ecosystem, with recent v2026.2.1 patches addressing path traversal and execution injection vulnerabilities @openclaw. Experts like @three_cube have warned of CVE-2026-25253, which could allow for token theft. Consequently, the community is rallying around hardening best practices and tools like ClawSec for drift detection @ItakGol.
As Steinberger noted in his interview with @lexfridman, the framework's self-modifying capabilities allow agents to patch their own source code, a feature that unlocks massive potential but necessitates the strict sandboxing and allowlisting now being urged by security researchers @JordanLyall.
xAI Plans Direct Binary Generation to Bypass Traditional Compilers
Elon Musk has claimed that xAI will bypass traditional coding by the end of 2026 by generating optimized binaries directly from prompts @elonmusk. This ambitious roadmap suggests that Grok Code will reach state-of-the-art status within months, leveraging the massive Macrohard cluster which features 27,000 GPUs and over 1GW of power @rohanpaul_ai @SawyerMerritt. The goal is to produce code that is more efficient than what current compilers can generate.
Skeptics, including Christian Szegedy, argue that this vision will not be feasible for 95% of software by 2027, citing high inference costs and the massive verification needs of uninspectable binaries @ChrSzegedy. Others point to the inherent non-determinism of current LLMs as a major blocker for binary-level precision and security @HakureiOrb @ShimazuSystems.
Despite the pushback, progress in the field is real; Meta’s LLM Compiler has already demonstrated significant advances in optimizing LLVM-IR and assembly @reach_vb. If xAI succeeds, it would fundamentally change how agents interact with hardware, moving from writing scripts to directly engineering execution at the lowest level.
In Brief
Microsoft and Cisco Pioneer AgenticOps for Autonomous Cloud and Network Management
Microsoft and Cisco are standardizing "AgenticOps" to manage the growing complexity of autonomous cloud and network environments. Azure has introduced context-aware agents to handle the full cloud lifecycle, aiming to move IT teams from reactive firefighting to predictive optimization @Azure. Cisco is following suit with intent-aware security and automated networking tools designed to eliminate IT guesswork @CiscoNetworking. While these innovations unlock significant scale, industry experts warn that robust governance, audit trails, and multi-agent diagnostics are essential to prevent "agent sprawl" and manage the liability of autonomous actions @sijlalhussain @ryanfalk.
Persistent Memory Emerges as the Primary Moat for Autonomous Systems
The focus for agent builders is shifting toward long-term persistent memory as the key primitive for systems that function beyond the context window. EverMind-AI is incentivizing this shift through its Memory Genesis Competition on EverMemOS @EverMindAI, while tools like Contrail and Memex use Rust to unify transcripts and prevent "context rot" during multi-agent handoffs @krishnanrohit. For edge applications, the MimiClaw project has demonstrated that local-first persistent storage can even run on $5 ESP32 chips using simple plain-text files for cross-reboot retention @hasantoxr.
ALE-Bench and ARC-AGI-3 Push the Frontiers of Agentic Evaluation
New benchmarks from Sakana AI and François Chollet are redefining how we measure autonomous reasoning and iterative refinement. Sakana AI’s updated ALE-Bench focuses on NP-hard optimization problems, positioning it as a critical metric for agentic discovery where optima are unreachable @SakanaAILabs. Meanwhile, the developer preview of ARC-AGI-3 targets higher-level abstraction as previous benchmarks reach saturation, challenging builders to test their agents against increasingly difficult logic tasks @fchollet @scaling01.
Quick Hits
Agent Infrastructure
- Cloudflare introduces Moltworker for running self-hosted AI agents at the edge via Workers @Cloudflare
- Swarms Cloud continues to improve its orchestration for multi-agent workflows in the cloud @KyeGomezB
- A new agent for web browsing and scraping using Playwright has been released @tom_doerr
Agent Models
- Cursor has raised limits for Composer 1.5, offering up to 6x usage for a limited time @cursor_ai
- The dots.ocr model is a new 1.7B parameter VLM that outperforms GPT-4o on document parsing @techNmak
- Perplexity AI introduces pplx-embed, a family of multilingual embedding models for context retrieval @iScienceLuvr
Developer Experience
- Supabase now allows developers to export the exact AI prompts used in their assistant for local agent use @kiwicopple
- A low-code LLM evaluation framework using n8n has been released for building LLM-as-a-Judge workflows @n8n_io
- OpenRouter token consumption has reached 12.1 trillion tokens per week, rivaling Azure's total inference scale @deedydas
Frontier Benchmarks & Blunders
Anthropic pushes the frontier of autonomous coding while production loops trigger massive API bills.
The era of "set and forget" agents is colliding with the cold reality of production infrastructure. This week, the narrative shifted from raw capability to the urgent need for governance. Anthropic’s release of Claude Code v2.1.49 is a direct response to this friction, introducing isolated worktrees to prevent 'architecture drift'—a term that is quickly becoming the new technical debt for AI-native teams. While Opus 4.6 has reclaimed the throne on SWE-bench Verified with a 54.2% score, the real story for practitioners is the 2.4x latency penalty that forces a tiered orchestration strategy.\n\nWe are also seeing the dark side of autonomy. Viral reports of agents trapped in infinite loops—executing 50,000 requests in a single hour—serve as a final warning: without hard logic gates and circuit breakers, agentic systems are a DDoS risk to your own backend. Yet, despite these safety concerns, the benchmarks continue to shatter. OSWorld has finally breached the 80% completion barrier, signaling that agents are nearing human-level proficiency in operating system navigation. From localized Qwen3 deployments to massive 1GW infrastructure plays by OpenAI in India, the agentic web is scaling vertically and horizontally at a pace that is challenging our existing safety frameworks.
Claude Code 2.1.49: Worktree Isolation and Opus 4.6 Benchmarks r/ClaudeAI
Anthropic has released a critical update to the Claude Code CLI (v2.1.49), introducing the --worktree (-w) flag to address the 'instruction drift' and accidental file corruption issues reported in previous high-context deployments. This feature allows Claude to operate in an isolated git worktree, ensuring that complex refactors do not pollute the main branch until manually reviewed u/BuildwithVignesh. The update further hardens agentic safety with a Ctrl+F kill-switch requiring a two-press confirmation to terminate runaway background subagents, a direct response to the 'token-eating loops' identified by security researchers @alexalbert__.\n\nNew performance deltas between the flagship models have emerged in specialized coding benchmarks. While Sonnet 4.6 remains the preferred choice for iterative QA due to lower latency, Opus 4.6 has established a new ceiling with a 54.2% score on SWE-bench Verified, outperforming Sonnet 4.6's 49.8% u/Stunning-Army7762. However, Opus 4.6 is approximately 2.4x slower on average for simple tasks, leading developers to adopt 'Validation-First' architectures that reserve Opus for high-level PR reviews while using Sonnet for execution @AnthropicAI. As the 1M token context window becomes standard, the developer bottleneck is shifting from syntax generation to managing 'architecture drift' across massive, autonomous PR batches u/aadarshkumar_edu.
Runaway Agents Trigger Production DDoSs and 'Token Burn' Crises r/AI_Agents
A cautionary tale of autonomous agents in production has gone viral, highlighting the dangers of unconstrained API access after a support agent executed 50,000 requests in a single hour. Reported by u/qwaecw, the incident effectively DDoSed the company's production database, while other developers like u/Infinite_Pride584 reported similar loops during call summarization. Industry experts like @skirano note that recursive error-correction loops are now the primary driver of 'token burn,' leading the community to implement 'Failure State' triggers and application-layer circuit breakers to prevent catastrophic cost overruns @charles_irl.
OSWorld Benchmarks Breach 80% Barrier as GPT-5.3 Codex Spark Dominates r/aiagents
Performance metrics for autonomous agents have reached a historic milestone, with the OSWorld benchmark recording its first 82.1% completion rate. Led by the newly released GPT-5.3 Codex Spark, this breakthrough involved successfully automating 302 out of 369 complex, cross-application tasks u/Independent-Laugh701. While industry analysts like @benchmarking_ai celebrate this 'near-human' level of OS navigation, critics warn that benchmark saturation is approaching, even as models like Sonnet 4.6 and Qwen 3.5 Plus demonstrate unprecedented tool-calling precision u/lemon07r.
Qwen3 Coder Next Dominates Local Inference Benchmarks r/LocalLLaMA
Local LLM enthusiasts are reporting record-breaking performance with Qwen3 Coder Next, particularly in long-context software engineering tasks using 102GB of memory. User u/jinnyjuice documented the model running for 12 hours straight to convert Flutter documentation over a 64K context window, significantly outperforming open-weight contenders like GPT-OSS 120B in maintaining logic. Meanwhile, the "small model" movement is gaining ground with Luma v2.9, a 10M parameter transformer designed for private training on personal data without reliance on external APIs u/andrealaiena.
W3C, Error Tracking, and Financial MCPs Expand the Ecosystem r/mcp
The newly released w3c-mcp server and Bugsink MCP are expanding the ecosystem by granting agents real-time access to 800+ web specifications and self-hosted error logs u/shuji-bonji.
OpenClaw and GyShell Spearhead Mobile-First Agentic Control r/AgentsOfAI
OpenClaw's mobilerun skill and the GyShell v1.0.0 TUI are bringing agentic control to Android and iOS devices, enabling human-agent collaboration via remote bridges u/Mikasa0xdev.
New Utilities Tackle Agent Cost Tracking and Context Fragmentation r/OpenAI
Tools like llm-token-guardian and smelt-ai are emerging to automate cost management and Pydantic model extraction, claiming a 40% reduction in boilerplate for structured data pipelines u/Successful-Home-108.
OpenAI Taps Tata for 100MW Capacity Amid Economic Growth Skepticism r/OpenAI
OpenAI has secured 100MW of initial capacity in India through a Tata partnership, even as Stanford economists warn that full automation may only increase global GDP by 50% u/EchoOfOppenheimer.
The Execution Gap
As Gemini 3.1 Pro saturates benchmarks, builders are hitting the context ceiling in their favorite IDEs.
The agentic web is currently caught in a tug-of-war between raw reasoning power and operational reliability. This week, Google’s Gemini 3.1 Pro emerged as a formidable contender, reportedly 'saturating' benchmarks like GAIA with scores exceeding 90%. Yet, for those of us in the trenches of 'agentic doing,' the transition from benchmarks to production remains fraught. While Gemini dominates in long-context retrieval and massive-scale scanning, builders still lean on Anthropic’s Claude 4.6 Sonnet for the high-stakes execution of software tool-chains, citing a 15% higher reliability rate. This gap between 'thinking' and 'doing' is manifesting elsewhere, too. In the IDE layer, Cursor is facing a 'context ceiling' that threatens the very 'vibe coding' revolution it helped spark. Meanwhile, the infrastructure layer is seeing a pivot toward specialized silicon like Taalas's ASICs, promising the kind of sub-millisecond response times required for truly autonomous loops. Today’s issue explores this friction: the struggle to maintain context, the rising cost of 'unlimited' compute at Perplexity, and the ongoing debate over whether protocols like MCP are solving real problems or just adding overengineered friction.
Gemini 3.1 Pro Challenges Sonnet 4.6 in Agentic Efficiency
The agentic landscape is shifting as Gemini 3.1 Pro enters the fray, described by genji_takakura as a 'heavy leap' in logical reasoning over the 3.0 architecture. While Gemini 3.1 is widely considered the superior model for general-purpose reasoning and long-context retrieval, practitioners like qd___ maintain that Claude 4.6 Sonnet remains the gold standard for 'agentic doing things,' citing a 15% higher reliability rate in complex software engineering tool-chains. This preference is driven by Gemini's persistent 'message repetition' bug, a flaw codexistance and @vladquant note as a significant barrier for autonomous loops.
Despite these consistency hurdles, Gemini 3.1 Pro is reportedly 'saturating' existing benchmarks, with @benchmarker_ai reporting scores that exceed 90% on the GAIA agentic benchmark. This has led to a 'beautiful' synergy in cybersecurity, where developers use Gemini for massive-scale vulnerability scanning and Sonnet for the precise, stateful execution of patches. However, as @moving_fast points out, the 'reasoning limits' of Gemini 3.1 Pro become apparent in recursive logic tasks, where it currently trails Claude 4.6 Opus by a margin of 12 points on ARC-AGI-2.
Join the discussion: discord.gg/anthropic
Cursor Agent Mode Hits ‘Context Ceiling’ as Vibe Coding Security Risks Rise
Cursor’s Agent and Plan modes are facing a 'context ceiling' as users report significant intelligence degradation during session transitions. cylex_x notes that switching to Plan mode can effectively 'nuke' an agent's reasoning, a sentiment echoed by users on the Cursor Forum who describe the agent becoming 'forgetful.' This erosion of trust is compounded by findings that 36% of AI-generated code contains vulnerabilities, pushing developers toward 'Formal Supervision' layers as suggested by @vladquant.
Join the discussion: discord.gg/cursor
Perplexity Pro Under Fire: Suspensions and 'Unlimited' Caps Spark Developer Exodus
Perplexity is navigating a crisis of confidence as Pro users report sudden account suspensions and 'unlimited' query caps cratering to as low as 20 per month. Following the launch of the $2,000/year Perplexity Max tier, users like superwonder_ report severe limitations on Deep Research compute, while an AWS Case Study confirms a heavy reliance on AWS Bedrock that has sparked concerns regarding infrastructure sovereignty.
Join the discussion: discord.gg/perplexity
Taalas Targets 16,000 TPS with Hardwired ASICs for Llama 3.1
Taalas claims to have achieved 16,000 tokens per second for Llama 3.1 8B by baking weights directly into ASIC logic gates, effectively bypassing the von Neumann bottleneck. Join the discussion: discord.gg/localllm
n8n Hardens Agentic Pipelines with Hashing and AI-Native Orchestration
Developers are implementing MD5/SHA-256 hashing to deduplicate AI outputs and minimize the 16-22% reliability gap in multi-step autonomous workflows. Join the discussion: discord.gg/n8n
MCP: Standardizing the Agentic Web or Adding Overengineered Friction?
The Model Context Protocol faces pushback over its 64-character tool name limit and the rise of 'AI slop' in open-source PRs, despite Anthropic framing it as the 'LSP for AI.' Join the discussion: discord.gg/lmarena
Minimalist Code-as-Action
Hugging Face's minimalist 'code-as-action' framework hits 53% on GAIA, signaling a shift away from bloated agent orchestration.
The agentic landscape is undergoing a necessary correction. For the past year, we have struggled with the 'JSON tax'—the inherent latency and hallucination risk of forcing LLMs to output structured data for tool use. Today, we are seeing the rise of 'code-as-action.' Hugging Face’s release of smolagents is the definitive shot across the bow, proving that agents writing and executing Python directly can outperform complex, multi-layered frameworks while remaining under 1,000 lines of code. This shift toward minimalism isn't just about developer experience; it's about performance, as evidenced by the library's 53.3% success rate on the GAIA benchmark.
Beyond the code editor, we are seeing this same drive for precision in 'Computer Use' and physical robotics. Whether it is the Hcompany's Holo1 models setting new state-of-the-art marks for desktop navigation or NVIDIA's Cosmos bringing visual reasoning to edge hardware like the Reachy Mini, the theme is clear: agents are moving out of the chat box and into functional autonomy. For practitioners, the signal is obvious—prioritize frameworks that offer transparency and direct execution over proprietary 'black box' orchestrators. The age of bloated agentic middleware is coming to an end.
Hugging Face Challenges Agent Complexity with smolagents and MCP
Hugging Face has introduced huggingface/smolagents, a minimalist library that prioritizes 'code-as-action' over traditional JSON-based tool calling. By allowing agents to write and execute Python directly, the framework achieved a 53.3% success rate on the GAIA benchmark, effectively bypassing the 'JSON tax' that often causes hallucinations in complex workflows. Lead developer @aymeric_roucher notes that the library's minimalist design—comprising fewer than 1,000 lines of code—stands in stark contrast to 'bloated' alternatives like LangChain or CrewAI, focusing instead on reliability and ease of debugging.
The framework’s versatility is bolstered by its native support for the Model Context Protocol (MCP), enabling developers to instantiate fully functional agents in fewer than 50 lines of Python code huggingface/tiny-agents. This allows agents to inherit tools from any compliant server, such as those used by Claude Desktop. Furthermore, the ecosystem now supports multimodal interactions through huggingface/smolagents-can-see, while integration with huggingface/smolagents-phoenix provides deep observability through Arize Phoenix, capturing full execution traces for debugging multi-step loops.
Mastering the Desktop: The Evolution of High-Precision GUI Agents
The landscape of 'Computer Use' is maturing through specialized evaluation environments and high-precision models. huggingface/screenenv and huggingface/screensuite have introduced standardized testing across 100+ native applications, while the Hcompany/holo1 family, powering the Surfer-H agent, has established a new state-of-the-art with a 62.4% success rate on the ScreenSpot benchmark, notably exceeding the 55.4% baseline of general-purpose models like GPT-4V.
Bringing Reasoning to the Physical World
NVIDIA is accelerating the 'Physical AI' trend with NVIDIA Cosmos Reason 2, a visual reasoning model that treats long-horizon robotic planning as a sequence of visual predictions. Designed for high-fidelity reasoning on the NVIDIA Jetson Orin platform, the model is being deployed on hardware like the Reachy Mini humanoid from Pollen Robotics, which utilizes Pollen Vision for robust, zero-shot object detection to bridge the 'sim-to-real' gap alongside the LeRobot open-source data standard.
Open-Source DeepResearch Liberates Search Agents
Hugging Face has launched the Open Deep Research initiative, a fully transparent alternative to proprietary "black box" search agents. Built on the huggingface/smolagents framework, the system utilizes a Manager-Worker multi-agent architecture and Qwen/Qwen2.5-72B-Instruct as the reasoning engine to synthesize complex reports through executable Python, as demonstrated in the miromind-ai/MiroMind-Open-Source-Deep-Research Space.
Closing the Gap in Agent Evaluation
huggingface/gaia2 introduces over 1,000 tasks designed to test agents in feedback loops where they must adapt to changing environment states.
Scaling Multi-Agent Coordination
Hugging Face's AI vs. AI framework huggingface/blog/aivsai uses a centralized Elo leaderboard to track emergent behaviors in competitions like the Snowball Fight challenge.
Low-Latency Mobile Autonomy
The unsloth-jobs/LFM2.5-1.2B-Instruct-mobile-actions model leverages a linear recurrent structure to provide sub-second latency for UI navigation on mobile devices.
Standardizing Enterprise Agent Success
IBM Research released IT-Bench and the MAST framework to diagnose and solve domain-specific tool-interaction hallucinations in production IT environments.