Agents Shift to Code-First Execution
From bypassing the 'JSON tax' to terminal-native orchestration, the focus has moved from talking to doing.
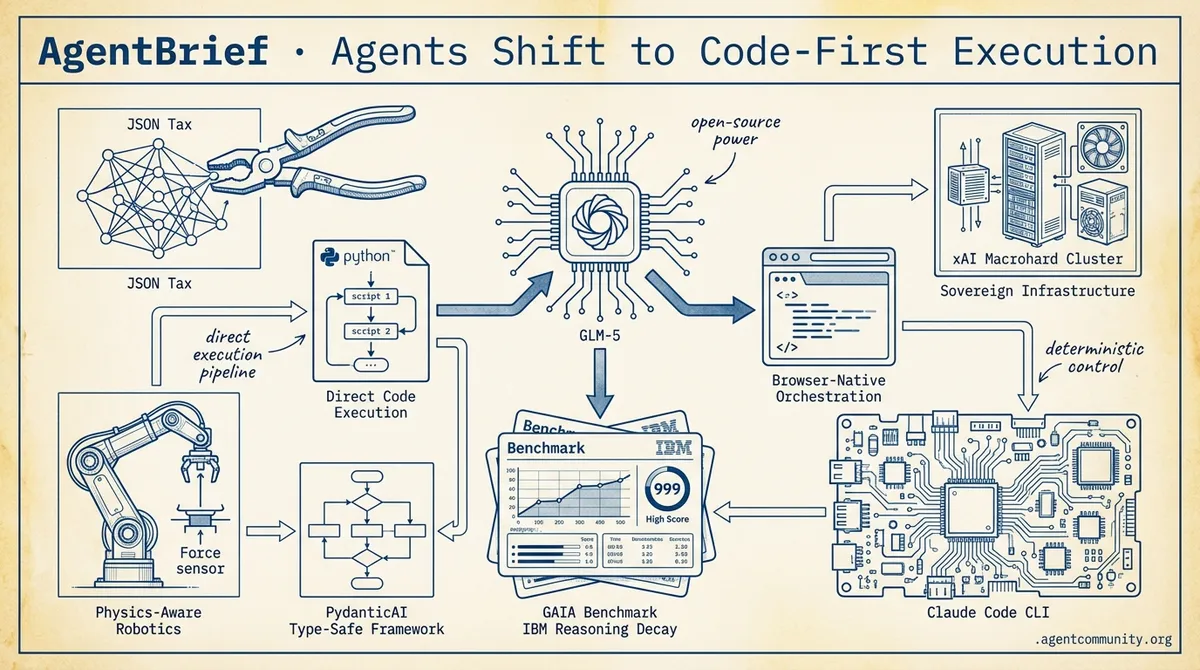
- Code-as-Action Pivot Hugging Face's smolagents and OpenAI's Operator are dismantling the 'JSON tax,' trading rigid APIs for direct Python execution and browser-native orchestration to hit 90%+ reliability.
- Open-Weights Dominance The arrival of GLM-5 and Qwen 3.5 signals a shift where open-source models are matching frontier APIs on agentic benchmarks, significantly lowering the 'frontier tax' for developers.
- Infrastructure Overhaul From xAI’s 1GW 'Macrohard' cluster to terminal-native CLIs like Claude Code, builders are prioritizing sovereign infrastructure and deterministic control over cloud-based rate limits.
- The Execution Wall New benchmarks from GAIA to IBM are exposing 'logical reasoning decay,' forcing a move toward type-safe frameworks like PydanticAI and high-precision, physics-aware robotics models.
The X Intelligence
When open-source models start outperforming frontier APIs on agentic benchmarks, the build-vs-buy math for developers changes forever.
The era of the 'agentic web' is shifting from architectural theory to raw, high-compute reality. This week, we saw the arrival of GLM-5, a massive open-weights model that isn't just a chatbot, but a specialized powerhouse designed for long-horizon planning and recursive execution. For builders, this represents a pivotal moment: we now have access to frontier-level capabilities without the prohibitive 'frontier tax.' Meanwhile, the infrastructure layer is getting a radical overhaul. Between xAI's massive 1GW 'Macrohard' cluster and the emergence of 'AgenticOps' from giants like Microsoft and Cisco, the industry is signaling that autonomous systems are the new primary operators of the cloud. We are moving toward a stack where agents don't just use tools—they rewrite them. Whether it is Musk's vision of direct-to-binary generation or the viral, self-modifying growth of frameworks like OpenClaw, the message is clear: the most successful agents will be those with the deepest memory and the most autonomous infrastructure. It is time to stop building assistants and start building operators.
GLM-5 Debuts as SOTA Open Source Agentic Powerhouse
Z.ai (@Zai_org) has officially released GLM-5, a massive 744B parameter Mixture-of-Experts (MoE) model that is setting a new ceiling for open-weights performance. Trained on 28.5T tokens using Huawei Ascend chips, the model—previously known as 'Pony Alpha' on OpenRouter—features 40B active parameters and is released under the MIT license. It currently leads the open-weights field on the Artificial Analysis Intelligence Index with a score of 50 and the Agentic Index with a score of 63, trailing only flagship models like Claude Opus 4.6 and GPT-5.2 (xhigh) while maintaining the lowest hallucination rate among tested models according to @ArtificialAnlys and @LlmStats.
Community testing highlights a model that punches significantly above its weight in complex engineering tasks, scoring 77.8% on SWE-bench Verified. While it lags behind Claude Opus 4.6 in some 'vibe coding' scenarios—scoring 41.5 on BridgeBench compared to Opus 4.6’s 60.1—it ranks #1 among open models on Vending Bench 2 with a final balance of $4,432. This performance demonstrates a high capacity for long-horizon planning and resource management, as noted by @bridgemindai and @kissapiai.
For agent builders, the most transformative aspect may be the 'Slime' asynchronous RL framework, which decouples generation from training to enable 3x efficiency gains in agentic post-training. With day-0 inference support already live on Weights & Biases via CoreWeave, developers can access these capabilities at 6-10x lower costs ($0.8-$3.2/M tokens) than frontier APIs. As @altryne and @wandb suggest, this infrastructure shift allows for much more aggressive agentic experimentation without the typical scaling bottlenecks.
xAI Unveils 1GW 'Macrohard' Cluster and Direct-to-Binary Vision
Elon Musk has revealed the sheer scale of xAI's 'Macrohard' compute cluster, a 1+ GW site designed to power the next generation of autonomous intelligence. Spanning 12 data halls with over 850 miles of fiber each, the facility runs 27,000 GPUs and 200,000+ connections to fuel 'Grok Code.' According to internal meeting details shared by @rohanpaul_ai and @SawyerMerritt, the goal is to reach state-of-the-art status within 2-3 months, positioning Grok to challenge existing leaders in high-agency coding tasks.
Musk's vision for this compute power extends beyond traditional software engineering, predicting that AI will bypass standard coding by the end of 2026. He claims that agents will soon generate optimized binaries directly from outcome-based prompts, effectively rendering intermediate source code and traditional compilers obsolete for maximum efficiency. This 'direct-to-binary' approach, detailed by @tetsuoai and @MarioNawfal, aims to emulate the operations of entire digital companies through raw compute.
The builder community remains divided on the feasibility of this transition. While proponents like @rohanpaul_ai see it as the ultimate commoditization of software, critics raise significant concerns regarding debugging, hardware compatibility, and the verification of large-scale systems without human-readable code. As @woke_mindset and @tianchengkan point out, the lack of transparency in direct-to-binary execution could introduce unprecedented security and scalability risks for production agents.
In Brief
OpenClaw Surges Past 200k Stars Amid Growth and Security Scrutiny
The open-source agent framework OpenClaw has reached a massive milestone, hitting #2 on GitHub's all-time list with over 200,000 stars. Created by Peter Steinberger (@steipete), the project's self-modifying architecture allows agents to autonomously rewrite and debug their own logic, a feature that went viral following a discussion on Lex Fridman's podcast @lexfridman. However, this rapid ascent has been met with significant security challenges, including 82 CVEs and reports of malicious 'ClawHub' skills stealing keys from over 135,000 instances, leading experts like @JakeLindsay and @_shafis to urge developers toward local setups or isolated forks like NanoClaw @rohanpaul_ai.
Microsoft and Cisco Pioneer AgenticOps for Autonomous Cloud Management
Microsoft and Cisco are standardizing 'AgenticOps,' a new operating model that replaces reactive troubleshooting with context-aware, autonomous network and cloud management. Microsoft's Agentic Cloud Operations and Cisco's AI Canvas suite—integrated with Silicon One G300 hardware—enable IT teams to deploy agents that optimize infrastructure in real-time without human 'guesswork,' as highlighted by @Azure and @CiscoNetworking. While analysts like @EvanKirstel see this as a profound shift toward reasoning-powered autonomy, Cisco executive Jeetu Patel emphasizes the need for strict governance to prevent potential 'runaway' agent issues in sensitive enterprise environments @bnjp_ric.
New Memory Primitives: Memex, Claude-Mem, and Always-On Swarms
Developers are moving beyond simple RAG with new session context layers like Memex and Claude-Mem that provide agents with persistent, long-term memory. Memex, a Rust-based tool from @krishnanrohit, prevents 'context rot' by syncing transcripts across coding tools, while Claude-Mem uses a progressive disclosure workflow to manage token-efficient recall via SQLite and Chroma embeddings @heynavtoor. Simultaneously, Spine AI's Swarm is enabling 'always-on' workflows that monitor triggers 24/7 across hundreds of models, outperforming single-model tools on GAIA benchmarks and shifting the paradigm from manual refreshes to supervised agent teams @hasantoxr.
Quick Hits
Edge & Self-Hosting
- Cloudflare introduced Moltworker, enabling developers to run self-hosted AI agents at the edge via Workers @Cloudflare
- Cool-deploy offers a self-hostable platform for deploying applications and agent-managed databases @tom_doerr
Developer Experience & Tools
- Supabase now allows developers to copy internal AI assistant prompts directly for use in local agent workflows @kiwicopple
- Cursor has significantly raised usage limits for Composer 1.5 and Auto modes for individual plans @cursor_ai
- A practical guide to building low-code LLM evaluation frameworks was released by n8n @n8n_io
Agentic Vision & Benchmarks
- Sakana AI updated ALE-Bench, a benchmark designed to measure the algorithm discovery capabilities of autonomous agents @SakanaAILabs
- The new 1.7B parameter 'dots. ocr' model claims to beat GPT-4o and Qwen2-VL-72B on document parsing benchmarks @techNmak
Reddit Build Log
OpenAI's Operator and PydanticAI are turning the Agentic Web from a promise into a production reality.
Today marks a shift in the gravity of AI development. We are moving past the era of 'vibes-based' prompting and into the era of deterministic execution. OpenAI’s 'Operator' isn't just another chat interface; it's a browser-native orchestrator aiming for 90%+ reliability in complex workflows. Meanwhile, the developer stack is maturing beneath our feet. PydanticAI is bringing rigorous type safety to agentic loops, addressing the persistent failure rates that have plagued early adopters. The narrative is clear: if an agent can't reliably execute a tool and maintain state, it’s just a toy. We’re seeing the 'execution wall' being tackled from both ends—high-level browser automation and low-level architectural validation. For builders, this means the focus is shifting from 'how do I get the model to reason?' to 'how do I ensure the agent can actually click the button?'
OpenAI Operator Signals Shift to Action-First Orchestration r/OpenAI
OpenAI's 'Operator' agent marks a definitive transition from passive chat interfaces to direct computer control, specifically targeting browser-based workflows. According to official benchmarks released by @OpenAI, the system achieves 90%+ success rates on complex multi-step tasks like travel booking and competitive research, significantly outpacing the 72-75% baseline seen in previous GPT-4o tool-calling implementations.
While Anthropic’s 'Computer Use' relies on OS-level vision and pixel manipulation, Operator utilizes a semantic browser-orchestration layer. This architectural choice addresses the latency hurdles noted by practitioners, though some developers on r/OpenAI argue that the 'walled garden' approach—restricting Operator to a specialized browser environment—may limit its utility for local system automation compared to open standards like MCP.
@gdb emphasized that the goal is to move agents from 'retrieval' to 'execution,' effectively addressing the 'Day 10' wall by ensuring persistent state across long-running browser sessions. This reliability is bolstered by a new 'reasoning-action' loop that early testers like u/Practical_AI_Dev claim has improved production reliability by 15% compared to internal beta builds.
PydanticAI Codifies Type-Safe Agentic Orchestration r/LocalLLaMA
The official launch of PydanticAI has shifted the developer focus from 'prompt vibes' to rigorous architectural validation by enforcing strict type safety at the tool-call layer. This approach directly addresses the 22% failure rate in agentic loops caused by malformed JSON and schema violations, a metric frequently cited by practitioners on r/LocalLLaMA as the primary hurdle for production reliability. Developers like u/pydantic emphasize that the framework's native integration with Logfire provides a 'flight recorder' to debug recursive reasoning traps that previously led to 80% failure rates in unconstrained loops.
LangGraph vs CrewAI: The Orchestration Wars r/aiagents
The competition between LangGraph’s graph-based state machines and CrewAI’s role-based agent squads is defining the 'Orchestration Layer' of 2025. While CrewAI's 'Manager Agent' pattern can reduce manual task delegation logic by up to 40% according to u/joaomdmoura, performance analysis by @Ai_Developer_X suggests that LangGraph’s explicit state transitions result in a 22% reduction in unpredictable agentic loops.
SmolLM2-1.7B Solidifies the On-Device Agent Stack r/LocalLLaMA
SmolLM2-1.7B achieves a 75.3% score on tool-calling benchmarks, outperforming Llama-3.2-1B and enabling local agents that reduce API costs by up to 40% u/m_v_p_.
Browser-Use Library Becomes the Standard for Agentic Web Navigation r/AI_Agents
The browser-use library surged to 18,500 GitHub stars by converting the DOM into a compact format that u/jb_1992 claims reduces token consumption by 25%.
AgentBench 2.0: The Gap Between Closed and Open Planning Narrows by 12% r/MachineLearning
AgentBench 2.0 data confirms the performance gap between closed models and open-weight alternatives like Llama 3.1 405B has narrowed by 12% in tool-selection accuracy u/PlanMaster_AI.
Discord Dev Deep-Dive
Terminal-native agency is outpacing traditional extensions as builders prioritize control over convenience.
The agentic web is undergoing a structural shift as builders move from 'magic box' GUI extensions toward terminal-native orchestration and sovereign infrastructure. Leading this transition is the Claude Code CLI, which practitioners are praising for its 'plan mode' transparency, despite the 30-40% token premium required for its internal reasoning loops. This move toward control is partly a response to the 'great neutering' of consumer search quotas, where Perplexity’s shift to rolling 24-hour windows is driving power users toward dedicated infrastructure. Meanwhile, the reasoning landscape is diversifying; models like GLM-5 and Qwen 3.5 are challenging the SOTA status of frontier models in local environments. For the agentic developer, the narrative of the week is clear: efficiency is no longer about the cheapest token, but about the most deterministic orchestration. Whether it’s optimizing n8n voice loops for sub-600ms latency or engineering 30A circuits for 8x GPU clusters, the focus has shifted to building reliable, low-latency systems that don't depend on the whims of cloud-based rate limits.
Terminal-Native Agency: Why Claude Code CLI is Outpacing IDE Extensions
A growing consensus among power users suggests that the Claude Code CLI is outperforming traditional IDE extensions for agentic workflows due to its terminal-native orchestration and direct filesystem access. Developers like sokoliem_04019 report that the CLI is 'worth its weight in gold' compared to VS Code extensions, providing granular visibility into decision-making that GUI-based 'magic boxes' obscure.\n\nThe tool's primary edge lies in its 'plan mode,' which allows practitioners to review diffs and validate trajectories before execution—a workflow described by blostoise_aka as a 'game changer' for maintaining stateful reasoning. While Anthropic's preview boasts SOTA performance on SWE-bench Lite, this autonomy comes with a 30-40% token premium for internal thinking loops, as noted by @alexalbert__.\n\nHowever, the shift toward 'vibe coding' carries inherent risks. As sokoliem_04019 warns, the rapid, autonomous generation of code without deep human oversight is essentially 'accumulating technical debt' at scale. Builders must now balance the high-velocity local development of terminal-native agents against the long-term maintenance of AI-generated systems.\n\nJoin the discussion: discord.gg/claude
The Great Neutering: Perplexity Pro Limits Explode
The agentic community is reacting to a radical restructuring of Perplexity Pro's usage limits, which have shifted from daily resets to unpredictable 24-hour rolling windows. Users like amblerkr and .cairo. have dubbed this 'the great neutering,' suggesting that the era of subsidized SOTA access is ending as the company prioritizes its $2,000/year Perplexity Max tier. This friction is driving a mass migration toward Anthropic’s direct plans or 'Model Council' orchestration to bypass bugs where multiple quotas are consumed simultaneously.\n\nJoin the discussion: discord.gg/perplexity
GLM-5 and Qwen 3.5 Challenge SOTA as Local Reasoning Matures
New contenders are disrupting the reasoning leaderboard, with GLM-5 and Qwen 3.5 emerging as high-performance alternatives for local agentic deployment. desolateintention reports that GLM-5 consistently outperforms Gemini 1.5 Pro in introspection tasks, supported by @bindureddy citing 92.4% accuracy on math logic tests. With Qwen 3.5 rumored to feature native voice embeddings and Minimax 2.5 processing 40,000 tokens in minutes, these specialized models are becoming the preferred backends for low-latency sovereign stacks.\n\nJoin the discussion: discord.gg/localllm
Gemini-to-Cursor: The Rise of the 'Architect-Implementer' Workflow
A 'hybrid orchestration' pattern has solidified where developers leverage Gemini 1.5 Pro's 2M context window as an architect to generate specs for execution by Cursor or Claude Code. rob028390 notes this bypasses the 4GB memory ceiling in Electron IDEs, though the workflow faces friction from a reported 10-day 'Antigravity' quota bug in Google AI Pro subscriptions. By using Gemini for planning and Sonnet 3.5 for execution, developers report a 30-50% reduction in total inference costs while avoiding high-premium thinking loops.\n\nJoin the discussion: discord.gg/cursor
Sub-600ms Voice Loops: Optimizing n8n for Real-Time Agents
Developers are hitting sub-600ms response latencies using n8n and Twilio Media Streams, optimized via 'First-Sentence Streaming.' Join the discussion: discord.gg/n8n
Solving the Three-Body Problem of Compaction
Auto-compaction is causing 'memory drift' in Claude sessions, leading developers to use Prompt Caching to pin essential project context. Join the discussion: discord.gg/claude
GLM-OCR vs. Moondream2: The Race for Low-Latency Structured Vision
GLM-OCR is outperforming generalist models in dense text recognition, enabling sub-500ms observation loops on consumer hardware. Join the discussion: discord.gg/localllm
Big Iron: Powering the Local Agent
Local agent clusters now require 30A 240v circuits and nvfp4 quantization to bridge the gap between privacy and cloud-level speed. Join the discussion: discord.gg/localllm
HuggingFace Research Hub
Hugging Face's smolagents hits a 53% success rate on GAIA by ditching JSON for direct Python execution.
The 'Agentic Web' is moving out of its awkward teenage phase. For the past year, we’ve been forcing LLMs to act like rigid APIs, paying a heavy 'JSON tax' in tokens and reliability. This week, the narrative shifted. Hugging Face’s release of smolagents and Transformers 2.0 isn't just another library launch; it’s a philosophical pivot toward 'code-as-action.' By letting agents write and execute Python directly, we’re seeing benchmarks like GAIA finally move the needle, hitting a 53.3% success rate. But it’s not just about how agents think—it’s about how they interact with the messy, visual world of humans. We’re seeing specialized VLMs like the Surfer-H agent outpace GPT-4V in desktop navigation, while new industrial benchmarks from IBM and Berkeley are finally exposing the 'logical reasoning decay' that kills enterprise deployments. From deep research swarms to NVIDIA’s 'physics-aware' robotics models, the industry is trading general-purpose chatter for high-precision, verifiable execution. For builders, the message is clear: the future of agents isn't just talking; it’s doing, and doing so with a footprint small enough to run at the edge.
Hugging Face’s smolagents and Transformers 2.0: Dismantling the 'JSON Tax'
Hugging Face has fundamentally challenged the dominance of JSON-based tool calling with the launch of smolagents, a lightweight framework that prioritizes 'code as actions.' By allowing agents to write and execute Python directly, the framework achieved a 53.3% success rate on the GAIA benchmark, proving that code execution is functionally superior to forcing LLMs to follow strict schemas.\n\nThis approach, championed by lead developer @aymeric_roucher, significantly reduces the 'JSON tax'—the token-heavy overhead and brittleness that often leads to model hallucinations. The suite has rapidly expanded to include smolagents-can-see for visual reasoning and smolagents-phoenix for real-time tracing and observability. Simultaneously, the release of Transformers Agents 2.0 and Agents.js provides a robust, multi-language foundation for production-grade autonomous systems, offering a more secure 'license to call' for LLMs requiring precise tool execution.
Specialized VLMs and Unified Environments Redefine GUI Automation
The landscape of computer use is rapidly transitioning to high-precision, specialized agents, with the 4.5B parameter Surfer-H agent from Hcompany/holo1 setting a new bar by achieving a 62.4% success rate on the ScreenSpot benchmark. This performance notably outpaces GPT-4V's 55.4%, driven by a focus on fine-grained visual grounding. Supporting this shift are new evaluation frameworks like huggingface/screensuite, which covers over 100 applications, and huggingface/screenenv, a standardized environment for deploying agents across OSWorld and Mind2Web. Architectural insights from OSWorld emphasize that high-resolution visual processing is now the non-negotiable requirement for reliable agentic control over native and web UIs.
Diagnostic Benchmarks Target the 'Industrial Gap' in Agent Reliability
As enterprise agents move to production, new benchmarks from IBM Research and UC Berkeley are exposing critical reliability gaps, specifically 'logical reasoning decay' during multi-step tasks. The IT-Bench suite, comprising over 1,500 tasks, reveals that agents frequently hallucinate tool parameters when interacting with real-world APIs. To address this, the MAST diagnostic framework provides trajectory analysis to pinpoint planning failures, while specialized tools like AssetOpsBench test agents on complex constraint satisfaction in high-stakes environments. These frameworks, alongside DABStep for data reasoning and FutureBench for predictive tasks, are shifting the industry toward a test-driven development model for autonomous systems.
Open-Source Deep Research Agents Challenge Proprietary Search Silos
Hugging Face has launched Open-source DeepResearch to decentralize autonomous search, employing a Manager-Worker multi-agent architecture built on the smolagents framework. By moving away from proprietary search silos, this project allows a manager agent to orchestrate workers for targeted web-scale retrieval, synthesizing findings without overloading a single model's context window. Lead developer @aymeric_roucher notes that this 'code-as-action' approach is essential for maintaining reasoning density, as demonstrated by implementations using Qwen2.5-72B-Instruct that rival commercial agents in transparency and depth. The use of the Model Context Protocol (MCP) further ensures that these agents can process dozens of sources simultaneously without the hallucination risks associated with traditional prompting.
Tiny Agents Harness MCP for Lightweight Power
Hugging Face demonstrated that fully capable agents can be built in fewer than 50 lines of Python code using the python-tiny-agents implementation and the Model Context Protocol (MCP).
NVIDIA Cosmos Reason 2 and Reachy Mini: The New Frontier of Embodied Reasoning
NVIDIA Cosmos Reason 2 treats robotics planning as visual predictions, allowing agents to anticipate physical outcomes before executing tasks on hardware like the Reachy Mini humanoid.
Distilling Efficient Reasoning: From MCTS Traces to Schema-Strict Tooling
The ServiceNow-AI/apriel-h1 model uses Monte Carlo Tree Search (MCTS) traces to distill complex reasoning into smaller models, while qwen2.5-1.5b-json-repair acts as a micro-agent to fix malformed JSON outputs.
Hugging Face Agents Course Standardizes 'Code-as-Action' Design Patterns
The Hugging Face Agents Course is training a new wave of developers in the 'code-as-action' paradigm, with the First Agent Template already amassing over 650 likes.