Hardening the Agentic Production Stack
From Pentagon ultimatums to 1,000 TPS reasoning, the infrastructure for autonomous work is undergoing a brutal stress test.
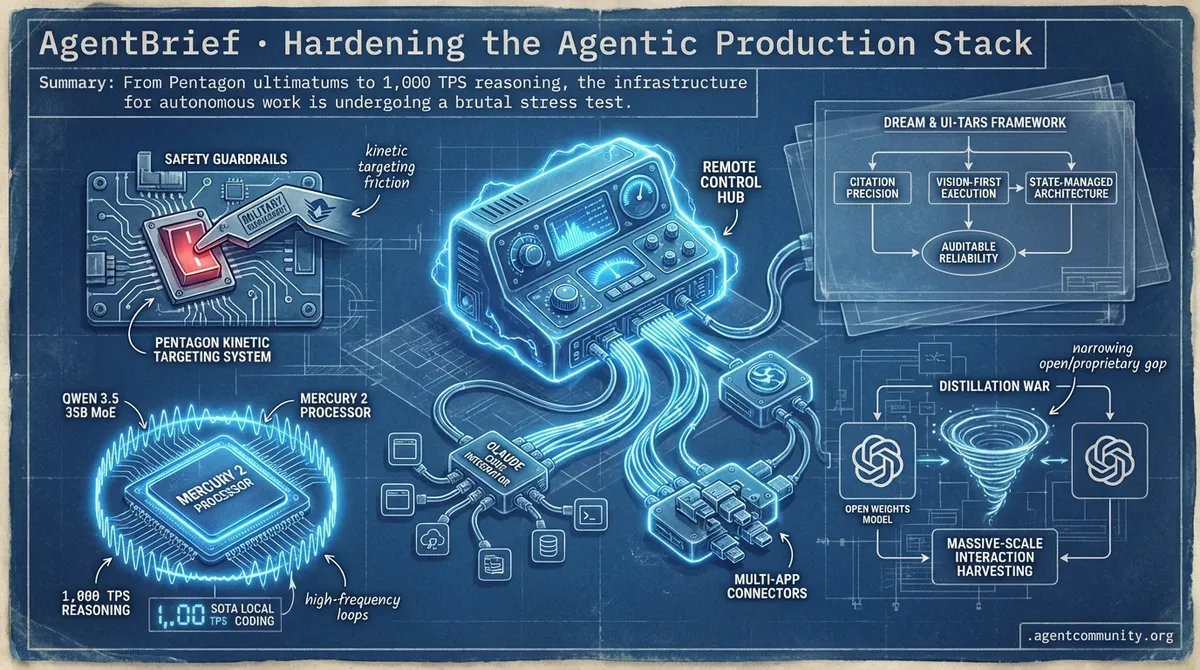
- National Security Friction The Pentagon's reported demand for Anthropic to strip safety guardrails for kinetic targeting highlights the growing tension between frontier model safety and military requirements.
- The Performance Frontier With Qwen 3.5 35B MoE delivering SOTA local coding and Mercury 2 hitting 1,000 TPS, the hardware-software bottleneck for high-frequency agentic loops is finally breaking.
- Auditability and Reliability New frameworks like DREAM and UI-TARS are moving the industry away from 'vibe coding' toward citation precision, vision-first execution, and state-managed software architectures.
- The Distillation War Anthropic's warnings regarding industrial-scale distillation suggest a narrowing gap between open-weights and proprietary models, driven by massive-scale interaction harvesting.
The X Intel
Remote control is here, and 1,000 TPS just became the new benchmark for reasoning speed.
The 'agentic web' isn't just a buzzword; it's a structural shift in how we build software. We're moving from models that predict text to systems that manage state across tools, environments, and devices. Anthropic's release of Remote Control and official MCP connectors signals the start of the 'connected agent' era, where human-in-the-loop isn't a bottleneck—it's a feature of mobile-first supervision. Meanwhile, the race for the 'Agentic Pareto Frontier' is heating up. Alibaba’s Qwen 3.5 is proving that you don’t need hundreds of billions of active parameters to dominate SWE-bench; you just need better architecture and long-context efficiency. For those of us shipping agents today, these updates address our biggest pain points: reliability, context persistence, and execution speed. Whether it's Mercury 2’s diffusion-based reasoning hitting 1,000 TPS or AgentSys solving prompt injection via memory isolation, the infra is finally catching up to our ambitions. We aren't just building bots anymore; we're building the operating system for autonomous work, and the tools are getting sharper by the hour.
Anthropic Unlocks Claude Code Remote Control and Multi-App Connectors
Anthropic has launched Remote Control for Claude Code, allowing developers to initiate local coding tasks and continue them via phone or browser through a secure QR-based connection. The system uses an outbound-only architecture that streams results without exposing local networks, supporting auto-reconnect functionality even if the host machine sleeps @rohanpaul_ai @claudeai @noahzweben. This is paired with new official connectors for Google Workspace, Slack, and DocuSign, enabling Claude to execute multi-step cross-app workflows like populating PowerPoints from spreadsheet data @rohanpaul_ai.
Early adopters are praising the update for solving the 'session interruption' problem in long-running agentic tasks, particularly for human-in-the-loop supervision on the go @SidraMiconi @MikeCodeur. By leveraging the Model Context Protocol (MCP), these tools ground agent outputs in real-time institutional data, which experts suggest is critical for reducing hallucinations in finance and enterprise environments @rohanpaul_ai.
For agent builders, this represents a significant leap in 'closing the outer loop' of orchestration. While some maintain that multi-agent compatibility is the next hurdle, the ability to maintain context across disparate enterprise apps via MCP is a massive step toward enterprise-scale viability @latentspacepod @lassare_hq.
Qwen 3.5 Targets the Agentic Pareto Frontier with 1M Context
Alibaba's Qwen team has released the Qwen 3.5 Medium series, headlined by Qwen3.5-35B-A3B, a model with only 3B active parameters that remarkably outperforms the much larger 235B predecessor @Alibaba_Qwen. The series includes Qwen3.5-Flash, which supports a 1M token context window by default, allowing agent builders to maintain massive project state on consumer-grade hardware @LiorOnAI. The efficiency metrics are striking: the 35B model scores 69.2% on SWE-bench, achieving the highest efficiency ratio in its class at 23.1 pts/B @LlmStats.
The community has responded with immediate infrastructure support, with vLLM and Unsloth providing day-0 integration for the new architecture @Alibaba_Qwen. Builders are particularly interested in the ultra-sparse experts and reinforcement learning refinements that unlock frontier-level reasoning and low-latency tool use on single GPUs @LiorOnAI @__Jaisurya.
This release shifts the focus for agent developers from raw parameter count to 'active parameter' efficiency. With the Qwen3.5-122B-A10B hitting 72.0% on SWE-bench—roughly 90% of Claude 4.6's performance at a fraction of the compute—the barrier to deploying high-intelligence agents locally has been significantly lowered @LlmStats @JingweiZuo.
In Brief
Mercury 2 Debuts as First Diffusion-Based Reasoning LLM at 1,000+ TPS
Inception Labs has launched Mercury 2, a reasoning diffusion model that hits over 1,000 tokens per second on Blackwell GPUs. By generating tokens through parallel refinement rather than sequential decoding, Mercury 2 is up to 5x faster than Claude 4.5 Haiku while matching it on Terminal-Bench Hard for agentic coding @StefanoErmon @_inception_ai. Artificial Analysis confirms its massive speed advantage, noting it outperforms peers by 3x in speed at a $0.75/M output price, offering adjustable 'reasoning effort' for agent builders who need instant feedback loops or ephemeral UI generation @ArtificialAnlys @deedydas.
AgentSys Framework Isolates Memory to Block Prompt Injection
A new research paper introduces AgentSys, a framework designed to secure LLM agents by implementing OS-inspired hierarchical memory isolation. To prevent indirect prompt injection from malicious tool outputs, AgentSys spawns isolated worker agents that only return schema-validated JSON to the main agent, keeping the primary context clean @adityabhatia89 @adityabhatia89. Benchmarks show attack success rates dropping to as low as 0.78% on AgentDojo, providing a deterministic security boundary for production web-browsing and enterprise agents without relying on brittle prompt hardening @adityabhatia89 @junfanzhu98.
OpenClaw Hits 5B Tokens Amidst Growing Trojan Horse Concerns
OpenClaw has surpassed 5 billion tokens in community usage, but critics are sounding alarms over the security of unvetted 'ClawHub' skills. While builders like @MatthewBerman use it as a core OS for CRM and inbox automation, critics warn that cheap LLMs or unverified skills could act as Trojan horses to exfiltrate sensitive data @burkov. Project lead @steipete advocates for personal sandboxing, while others suggest VirusTotal scanning and scoped credentials to mitigate the risk of infostealer malware in agent configs @RandyJRouse @LucaArrigo_.
Quick Hits
Agent Frameworks & Orchestration
- A new framework for orchestrating modular swarms of agents has been released to support massive scaling @tom_doerr.
- LangSmith now provides full tracing support for Claude Code to improve agentic observability @hwchase17.
Tool Use & Developer Experience
- GitNexus enables turning GitHub repos into interactive knowledge graphs for AI chat entirely in-browser @hasantoxr.
- Mistral Document AI launched on Azure, offering OCR and structured data extraction for agentic pipelines @Azure.
- Emergent's new mobile app allows building and publishing full iOS/Android apps using voice-driven agentic builders @hasantoxr.
Agentic Infrastructure
- New AI assistant infrastructure built in Zig has been developed for high-performance agent backends @tom_doerr.
- InferenceX benchmarks show AMD's MI355X is highly competitive with Nvidia's B200 for disaggregated inference @SemiAnalysis_.
Reddit Field Reports
The DoD issues a Friday deadline for Anthropic to strip Claude's safety guardrails for kinetic targeting.
The tension between AI safety research and national security mandates has finally reached a breaking point. Today’s lead story covers a reported ultimatum from the Pentagon to Anthropic, demanding the removal of 'Constitutional AI' guardrails for military use—a move that could fundamentally alter the landscape of frontier model deployment. While the geopolitical stakes rise, practitioners on the ground are focusing on a different kind of survival: the brutal transition from agent prototypes to production. We're seeing a collective realization that 99% autonomy isn't enough when 'dirty' operational realities like state corruption and tool pollution take hold.
In response, the ecosystem is hardening. From Anthropic’s new 'Remote Control' for mobile agent monitoring to the emergence of ultra-efficient MoE models like Qwen 3.5, the focus is shifting from raw reasoning to reliable execution. We are moving toward a 'deterministic core' architecture where agents are treated less like magic chatbots and more like sophisticated, state-managed software. Today’s issue dives into these architectural shifts, from tiered KV caching to fact-based memory layers, providing the technical signal needed to build agents that actually work in the wild.
Pentagon Issues Friday Deadline for Anthropic to Strip Claude’s Safety Guardrails r/OpenAI
A high-stakes confrontation has erupted between the Pentagon and Anthropic, with Defense Secretary Pete Hegseth reportedly issuing a deadline of Friday, February 27, 2026, for the AI lab to remove 'safety' blocks on Claude instances deployed within the Department of Defense. The ultimatum demands the removal of refusal logic that currently prevents the model from assisting in kinetic targeting, mass biometric surveillance, and autonomous weapons development. This 'unfettered access' is sought to eliminate what military planners call 'operational friction,' as internal reports suggest Claude’s current safety layer triggers a 15% refusal rate on queries processed within highly classified networks like JWICS.
The dispute centers on Anthropic’s 'Constitutional AI' framework, which the Pentagon views as a hindrance to national security. u/DefenseReporter indicates that the military specifically wants the removal of the 'ethics refusal' layer for bio-hazard and tactical planning queries. While u/Hegseth_DoD_Updates frames the move as essential for maintaining 'AI Supremacy,' the developer community on r/ArtificialInteligence warns that stripping these guardrails could set a dangerous precedent for domestic surveillance.
This standoff mirrors the recent hardening of the EU's regulatory stance via its new whistleblower portal, leaving frontier labs like Anthropic trapped between aggressive military mandates and stringent global compliance standards. Practitioners note that this development highlights the growing divergence between 'Public' and 'Government' model weights, a trend that may force developers to choose sides in the emerging sovereign AI landscape.
Anthropic’s 'Remote Control' Bridges the Mobile-Terminal Gap r/ClaudeAI
Anthropic has launched a native 'Remote Control' feature for Claude Code, allowing developers to monitor and intervene in autonomous coding tasks via the Claude mobile app. By executing the claude remote-control command, users generate an encrypted relay link that maintains persistence even through workstation locks. Early metrics from the community, cited by u/bbt_rachel, suggest this can reduce 'check-in friction' by up to 60% for developers on the move, though u/The_AI_Oracle notes that the current 24-hour session timeout remains a bottleneck for longer 'immortal' agent tasks.
Qwen 3.5 MoE Redefines Agentic Coding Performance r/LocalLLaMA
Alibaba’s Qwen 3.5 'Medium' series, specifically the 35B-A3B Mixture-of-Experts model, is being hailed as a new efficiency standard for local agentic workflows. Despite having only 3B active parameters, it rivals dense models like the 106B GLM-4.6V and has achieved a 72.0 on SWE-Bench Verified, matching top-tier proprietary models in autonomous software engineering. While testing on the RTX 5090 by u/3spky5u-oss shows it is 32% slower than its predecessor due to MoE routing complexity, its improved tool-calling accuracy makes it a superior choice for complex agents running on a single RTX 3090.
The Production Gap: Why 99% Autonomy Fails r/crewai
The transition from agent prototypes to production systems remains 'brutal' as builders identify 16 distinct failure patterns that go beyond simple hallucinations. Problems like 'The Loop of Doom' and 'Tool Output Pollution' are being addressed by a shift toward 'deterministic cores' and Single-Source-of-Truth (SSOT) architectures. According to u/joaomdmoura, having agents 'propose' state changes to a central orchestrator can reduce state corruption by 35% in complex autonomous workflows, solving the reliability issues that plague stochastic multi-agent layers.
MCP Ecosystem Hardens for Enterprise Infrastructure and RBAC r/mcp
Google and Sentry have released official MCP servers for GKE and error triage, while new 'Contextual Access' wrappers for Arcade are bridging the RBAC gap by injecting user identity into agent tool calls.
Fact-Based Memory and 'Self-Healing' Architectures Replace Raw Logs r/AI_Agents
Frameworks like Mem0 are moving agents toward dual-bucket memory (short-term context vs. long-term facts), which u/mem0_ai claims improves personalization accuracy by 20-30% over raw chat persistence.
Tiered KV Caching: Borrowing Database Patterns to Break the Memory Wall r/LLMDevs
LMCache is implementing multi-tier KV caching (GPU/CPU/NVMe) to achieve a 3-10x reduction in TTFT for long-context agentic workflows by bypassing redundant prefill computations.
Shared State Conflict Breaks Parallel Agent Scaling r/mcp
Parallel agents are frequently hitting an 'execution wall' of state collisions, driving a shift toward ScyllaDB checkpoint savers and distributed locking to reduce logic errors by 35% during peak loads.
Discord Dev Logs
Qwen 3.5 redefines local agentic coding while Anthropic sounds the alarm on industrial-scale distillation.
Today’s landscape is defined by the tension between sovereign local capabilities and the aggressive "synthetic harvesting" of frontier reasoning. On one hand, the release of Qwen 3.5 35B MoE signals a new era for local developers, offering GPT-5 mini-level reasoning on consumer hardware like the RTX 3090. This isn't just a benchmark win; it’s a practical shift for builders who need high-throughput, low-latency agentic loops without the cloud tax. Simultaneously, the industry is grappling with the ethics of model distillation. Anthropic’s allegations of "industrial-scale" attacks by Chinese labs suggest that the gap between open-weight efficiency and frontier proprietary logic is being bridged through brute-force interaction harvesting rather than pure innovation. For the agentic developer, the message is clear: the tools are getting smaller and faster, but the data moats are under siege. As we move toward "vibe coding" and multi-agent home orchestration, the focus shifts from systems architecture to robust state management. Whether you're leveraging Ollama’s new Vulkan support or navigating the tightening rate limits of Perplexity and Claude, the goal remains the same: building autonomous systems that are both reliable and resilient.
Qwen 3.5 35B MoE: The New Gold Standard for Local Agentic Coding
The local AI community is hailing the release of the Qwen 3.5 series, specifically the 35B-A3B Mixture-of-Experts (MoE) model, as a definitive shift in sovereign AI capabilities. Early testers report that the model is a "gamechanger for agentic coding," with TrentBot demonstrating its capabilities on a single RTX 3090. Performance metrics are setting new bars: frosted_glass reported speeds of 54 t/s on consumer hardware with 20GB of VRAM, while @awnihannun confirmed up to 110 t/s on an M4 Max using MLX optimizations.
{kind=link}
The model's architecture—featuring 122B total parameters with only 10B active—allows it to outperform GPT-5 mini in long-context reasoning and tool-calling precision. According to @vincenzolomonaco, Qwen 3.5 maintains state in 100+ step agentic loops where GPT-5 mini often fails. This reliability is becoming the primary driver for developers building low-latency, high-autonomy agents on local clusters.
While initial integration with Ollama v0.17.0 faced friction, the community has already deployed a fix in the v0.17.1 release branch, specifically addressing KV-cache fragmentation noted by nebukadnezzzar. With Unsloth AI releasing optimized 4-bit GGUF weights, the barrier to entry for high-performance reasoning has never been lower.
Join the discussion: discord.gg/localllm
Anthropic Alleges 'Industrial-Scale' Distillation Attacks by Chinese AI Labs
Anthropic has escalated its conflict with Chinese AI competitors, alleging that DeepSeek, Moonshot, and MiniMax conducted a massive "industrial-scale distillation attack" to siphon proprietary reasoning traces from Claude. The operation reportedly utilized a network of 24,000 fraudulent accounts to generate over 16 million interactions, forcing frontier models to reveal their internal logic for the benefit of competitors. This controversy coincides with increasing friction between Anthropic and the Pentagon, as the company resists government pressure to escalate defense involvement while trying to protect its core IP from foreign exploitation.
Grok 4.20 Beta Claims Top Spot in Search Arena
xAI has officially launched the Grok 4.20 Beta, which has immediately dominated the LMArena Search leaderboard with a score of 1226. This performance notably outpaces GPT-5.2 and Gemini-3, a surge largely attributed to a new 'Dynamic Routing Retrieval' (DRR) architecture that @xai_dev claims reduces retrieval latency by 22%. While the model excels in search-heavy tasks, it remains absent from 'Coding' categories, suggesting a strategic focus on positioning Grok as the primary alternative to Perplexity.
The Vibe Coding Debate: Syntax vs. Systems Architecture
The "vibe coding" phenomenon popularized by @karpathy has sparked a philosophical divide between developers betting on intent and those prioritizing technical oversight. While some argue syntax knowledge will be obsolete within 5 years, practitioners like digilog2501 maintain that syntax is a vital safety net for debugging unreliable LLM outputs. Industry experts suggest AI can automate 80% of boilerplate, but the "last mile" of systems architecture remains the true bottleneck for high-stakes production.
Join the discussion: discord.gg/cursor
Ollama's Vulkan Pivot and the 2500x 'Memory Wall' Compression
Ollama is formalizing Vulkan support to lower entry barriers for non-NVIDIA users, while researchers showcase a PoC compressing 5GB MoE shards into a 2MB latent space. Join the discussion: discord.gg/ollama
n8n and the Rise of Multi-Agent Smart Homes
The n8n community is standardizing Human-in-the-loop (HITL) switches to manage autonomous agents like 'Iris' that orchestrate real-time smart home functions. Join the discussion: discord.gg/n8n
Beyond the 'Pacman' Vibe-Check: The Rise of Environment-Native Benchmarks
Newer harnesses like Droid and Terminal-Bench 2.0 are replacing unit-test focused benchmarks to better evaluate multi-step agentic trajectories and reasoning paths. Join the discussion: discord.gg/localllm
Usage Limits and Rate Caps Tighten for Power Users
Perplexity and Claude users are navigating unpredictable rolling usage windows, driving a shift toward strategic prompt caching for 10x cost reductions. Join the discussion: discord.gg/perplexity
HuggingFace Research Hub
New evaluation frameworks and visual-first GUI agents are finally tackling 'logical reasoning decay' in autonomous systems.
Building an agent that 'looks' right is easy; building one that stays right over a long-horizon task is the current frontier. Today, we’re seeing a concerted effort to pierce the 'Mirage of Synthesis'—that frustrating phenomenon where an agent produces a polished report that is, unfortunately, hallucinated or poorly sourced. The release of the DREAM framework marks a shift toward 'agentic metrics' like Citation Precision and Reasoning Trace Alignment, moving us past surface-level vibes and toward technical auditability. This isn't just about better prompts; it's about the underlying plumbing. From the rise of pure vision GUI agents like UI-TARS—which sidestep the 'JSON tax' of DOM parsing—to the formalization of 'Cognitive Architectures' like CoALA, the industry is maturing. We’re seeing a pivot toward 'code-as-action,' where agents write Python directly to ensure reliability. Whether it's Google’s MedGemma navigating complex health records or developers flocking to the Hugging Face Agents Course, the goal is the same: industrial-grade autonomy that survives the 'chart biopsy' of real-world production.
DREAM Framework: Piercing the 'Mirage of Synthesis' in Deep Research
The new paper DREAM: Deep Research Evaluation with Agentic Metrics introduces a rigorous framework to combat the 'Mirage of Synthesis'—a phenomenon where research agents produce structurally sound reports that lack factual grounding. As highlighted by @aymeric_roucher, current benchmarks often miss the 'logical reasoning decay' that occurs during long-horizon tasks. DREAM addresses this by establishing a three-tier taxonomy: Source Retrieval, Information Reasoning, and Final Synthesis Quality.\n\nThe framework utilizes a suite of agentic metrics designed to measure the fidelity of autonomous workflows. Key metrics include Citation Precision—verifying if citations actually support claims—and Reasoning Trace Alignment, which ensures the agent's internal logic matches its output. For developers using the smolagents framework, DREAM provides the diagnostic tools to move toward production-ready reliability in high-stakes analyst roles.
From DOM-Parsing to Pure Vision: The Rise of High-Precision GUI Agents
The landscape of digital automation is rapidly shifting from fragile DOM-parsing to robust visual grounding. A pivotal study in OSWorld revealed that visual processing is the primary bottleneck for control, leading to the UI-TARS model which achieved a 83.6% success rate on the ScreenSpot benchmark. Efficiency is also a core focus, with ShowUI-2B proving that lightweight models can reach 75.1% accuracy on visual grounding. These advancements signify a move toward direct visual-to-action mapping that mirrors human software interaction.
Standardizing Foundations for Autonomous Agentic Workflows
Foundational research in the Agents collection is formalizing the 'Cognitive Architectures' necessary for robust autonomous systems. Central to this is the CoALA framework, which treats agents as modular systems with standardized memory, planning, and action loops. Specifically, hierarchical planning models can reduce execution errors by 30-40% compared to flat chain-of-thought approaches. This decoupling of reasoning from tool execution, explored in 2312.10003, allows for graceful handling of API failures and environment shifts.
Hugging Face Agents Course Scales 'Code-as-Action' Education
The Hugging Face Agents Course is scaling 'code-as-action' education, with its First_agent_template surpassing 650 likes.
Google Navigates EHRs with MedGemma-Powered Agents
Google's MedGemma-7b powers a new EHR-navigator agent designed to automate clinical 'chart biopsies' via programmatic FHIR queries.
Specialized Spaces: From Data Science to Workflow Standardization
New specialized Spaces like virtual-data-analyst and osw-studio are standardizing data exploration and cross-platform workflows.