Reflexive Agents and Sovereign Infrastructure
Low-latency loops and local-first weights are redefining the agentic frontier.
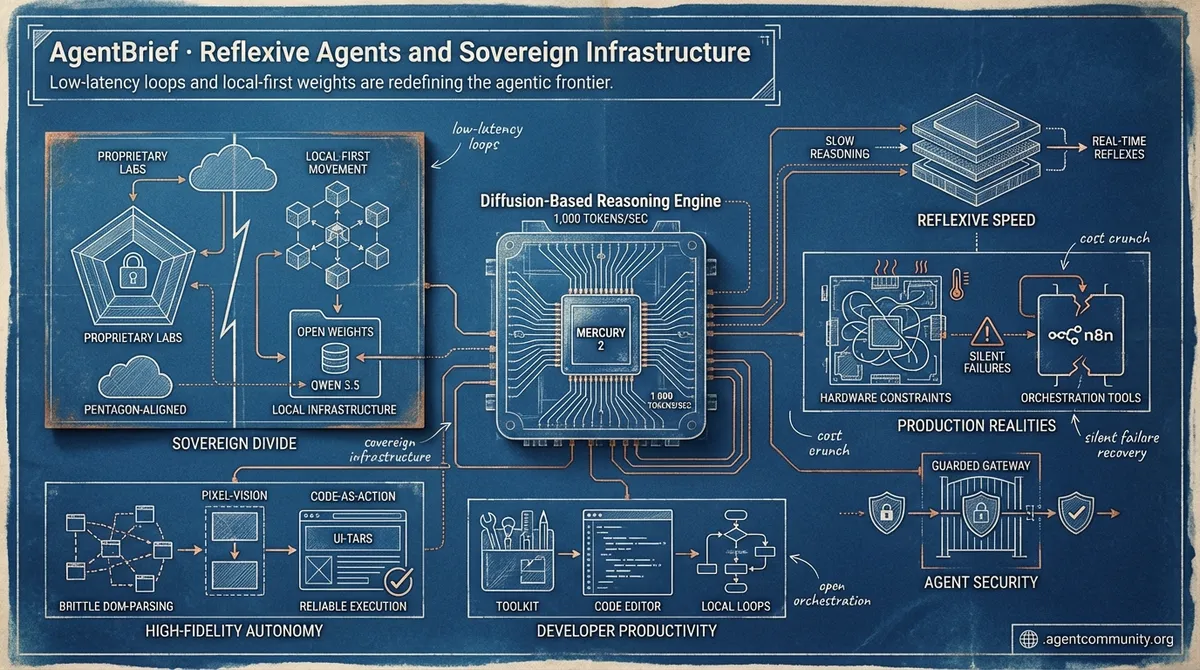
- Reflexive Speed Mercury 2 hits 1,000 tokens per second, moving agents from slow reasoning to real-time reflexes through diffusion-based generation.
- Sovereign Divide The industry is splitting between Pentagon-aligned proprietary labs and a robust local-first movement centered on open weights like Qwen 3.5.
- High-Fidelity Autonomy UI-TARS and smolagents are replacing brittle DOM-parsing with pixel-vision and code-as-action to ensure reliable, multi-step execution.
- Production Realities Despite massive model gains, developers are still battling hardware constraints and silent failures in orchestration tools like n8n.
The Reflexive Feed
When reasoning hits 1,000 tokens per second, the agentic loop becomes a reflex.
We are entering the era of the reflexive agent. For the last year, we’ve obsessed over 'reasoning'—those long, slow pauses where models chew on thoughts. But with Inception Labs' Mercury 2 hitting 1,000 tokens per second through diffusion, the latency barrier for complex agentic loops is evaporating. We’re moving from agents that 'think' to agents that 'act' in real-time. This isn’t just about speed; it’s about the architectural shift from monolithic contexts to isolated, OS-style memory management as seen in the new AgentSys framework. Meanwhile, the political landscape is fracturing. Anthropic’s standoff with the Pentagon highlights a growing divide: do you build on 'compliant' models optimized for state surveillance, or 'safety-first' models that prioritize user privacy? For those of us shipping agents today, the choice of infrastructure—from AMD’s price-to-performance gains to Alibaba’s hyper-efficient Qwen MoE—is becoming as critical as the prompt itself. The 'vibe-coding' era is ending; the era of auditable, high-velocity agentic systems is here. Let’s get to work.
Diffusion-Based Reasoning: Mercury 2 Hits 1,000 Tokens Per Second
Inception Labs has shattered the latency floor for agentic workloads with the launch of Mercury 2, the first production-ready reasoning model powered by diffusion rather than autoregression. By iteratively refining multiple tokens in parallel, the model achieves over 1,000 output tokens per second on NVIDIA Blackwell hardware—a 3x to 5x speedup over optimized autoregressive models like Claude 4.5 Haiku and GPT-5 mini @ArtificialAnlys @_inception_ai. Priced at just $0.75 per million tokens, it represents a fundamental shift in the price/latency pareto frontier for builders @deedydas.
Despite the extreme speed, Mercury 2 remains highly capable in agentic environments, matching Claude 4.5 Haiku on the code-heavy Terminal-Bench Hard and scoring 70% on IFBench for instruction following @ArtificialAnlys. It supports a 128K context window, native tool use, and an OpenAI-compatible API, making it a drop-in replacement for multi-step agents that require instant feedback, such as real-time coding assistants or voice-based autonomous systems @_inception_ai.
For agent builders, this changes the game by removing the 'thought latency' that often breaks the user experience in autonomous loops. As noted by @ArtificialAnlys, diffusion enables better controllability for complex tasks, positioning Mercury 2 as the engine for high-velocity loops where latency was previously the primary bottleneck. While it may not yet reach the frontier intelligence of a Claude 4.6, its role as a high-speed 'reasoning engine' for the agentic web is clear.
Anthropic Scales Agent Frameworks Amid High-Stakes Pentagon Standoff
Anthropic is significantly expanding the 'outer loop' capabilities of its agent ecosystem with the introduction of Remote Control for mobile-to-desktop handoffs and Cowork for multi-app orchestration across Excel, Slack, and PowerPoint @swyx. These features solve a major friction point for agent builders by enabling persistent, secure workflows that use short-lived TLS credentials and outbound HTTPS connections to maintain oversight across different environments @rohanpaul_ai.
However, these very capabilities have drawn intense fire from the U.S. government. Defense Secretary Pete Hegseth issued a deadline for Anthropic to provide unrestricted access to Claude for 'all lawful purposes,' including mass surveillance and autonomous weapons—requests CEO Dario Amodei rejected due to AI unreliability and risks to democratic values @rohanpaul_ai @kawsarlog. Following the missed deadline, the Pentagon labeled Anthropic a supply chain risk, threatening a seizure under the Defense Production Act @BusinessMirror.
This standoff forces a strategic choice on agent builders: build on 'compliant' models like OpenAI, which reportedly accepted the Pentagon's terms, or stick with 'safety-first' models that may face federal bans @rohanpaul_ai. While Amodei is currently in talks to avert a full ban, the bifurcation of the model market creates a new layer of political risk for enterprise agent deployments @krishnanrohit.
AgentSys: Secure Your Agents with OS-Style Process Isolation
A new research framework called AgentSys is tackling the critical threat of indirect prompt injection by treating agent memory like an operating system treats process isolation @adityabhatia89. Instead of dumping raw, untrusted tool outputs into a shared context window, AgentSys spawns isolated worker agents that handle external data in sandboxes. These workers only return schema-validated JSON results to the main agent, effectively blocking malicious instructions hidden in web pages or documents @adityabhatia89 @adityabhatia89.
Testing on the AgentDojo benchmark shows that this isolation strategy reduces the attack success rate (ASR) to a staggering 0.78%, compared to much higher rates for undefended baselines @adityabhatia89. Crucially, this security layer does not degrade performance; in fact, researchers noted a slight improvement in benign utility, as the hierarchical structure helps agents stay focused on long-horizon tasks without being distracted by noise in the context window @adityabhatia89.
For developers building enterprise-grade agents that browse the web or process customer files, AgentSys provides a roadmap for moving security from the prompt level to the architectural level @agentcommunity_. By treating external data as inherently untrusted and enforcing deterministic parsing between agent tiers, builders can finally deploy autonomous systems that are resilient to the 'cascading failures' typical of compromised tool calls @omarsar0.
In Brief
Alibaba's Qwen 3.5 Medium Series Shatters Efficiency Records with 69.2% SWE-bench
Alibaba's Qwen 3.5 Medium MoE model is redefining 'smarter, smaller' by activating only 3B parameters per token to achieve a record-breaking 69.2% on SWE-bench Verified. This efficiency ratio of 23.1 pts/B outperforms much larger models, including Claude 4.5 Sonnet, while maintaining a 262K context window and hitting speeds of up to 157 t/s on consumer RTX 4090 GPUs @LlmStats @sudoingX. For agent builders, this enables high-fidelity autonomous coding and repository analysis locally, bypassing cloud latency and privacy concerns as demonstrated by its ability to generate 3,000+ line applications in a single shot @sudoingX.
Karpathy Critiques OpenClaw's Security as Containerized NanoClaw Emerges
Andrej Karpathy has sounded the alarm on OpenClaw, labeling it a '400K lines of vibe coded monster' prone to critical RCE vulnerabilities and supply chain attacks. While OpenClaw has seen massive production adoption, Karpathy praised NanoClaw as a safer alternative that uses a lean, 4,000-line auditable core and runs agents in isolated containers by default to limit the blast radius of potential breaches @karpathy @AIContextWindow. This shift underscores a maturing orchestration ecosystem where security isolation and auditability are becoming prioritized over rapid, unvetted feature sprawl @NanoClaw_AI.
AMD MI355X Matches NVIDIA B200 on DeepSeek R1 FP8 Throughput
New benchmarks from InferenceX reveal that AMD's MI355X hardware is now highly competitive with NVIDIA's B200 for serving DeepSeek R1, matching or exceeding it in FP8 throughput. The MI355X offers a significantly lower TCO for agent builders running high-throughput MoE workloads, though it still lags behind NVIDIA in state-of-the-art FP4 configurations due to software optimization gaps in stacks like SGLang @SemiAnalysis_ @SemiAnalysis_. This performance parity in FP8 regimes suggests that hardware choice for agentic inference is increasingly a question of software stack maturity rather than raw silicon limits @tomshardware.
Stripe CEO Sees 'Phase Transition' to Singularity-Level Startup Productivity
Stripe CEO Patrick Collison reports a dramatic 'phase transition' in developer productivity, noting that AI agents have made 2026 startups far more efficient than their 2024 predecessors. This observation is backed by Cognition CEO Scott Wu, who revealed his team has effectively 'stopped typing code,' with nearly all GitHub commits now being AI-generated via prompts @rohanpaul_ai @rohanpaul_ai. This shift signifies a world where bespoke AI-generated tools are replacing traditional SaaS, accelerating the economic 'singularity' of software production @a16z.
Quick Hits
Agent Frameworks & Orchestration
- A new framework for orchestrating swarms of agents has been released by @tom_doerr.
- Subagents for Claude Code can now be used to analyze and implement complex tasks @tom_doerr.
- OpenClaw has processed 5 billion tokens and is functioning as a full OS for some firms @MatthewBerman.
Models for Agents
- Mistral-document-ai-2512 combines OCR and document understanding for automation-ready extraction @Azure.
- Qwen 3.5 series maintains near-lossless accuracy even under 4-bit weight quantization @Alibaba_Qwen.
- Pi-0.6 models are now in production, showing significantly higher autonomy than previous versions @chelseabfinn.
Developer Experience
- LangSmith now supports tracing for Claude Code to improve observability for agentic loops @hwchase17.
- GitNexus turns any GitHub repo into an interactive knowledge graph with local AI chat @hasantoxr.
- A new platform for RAG and agentic applications has been released by @tom_doerr.
Agentic Infrastructure
- Emergent doubled its ARR to $100M in 30 days and launched a mobile app builder @hasantoxr.
- Cloudflare edge is hosting a faster Next.js implementation rebuilt in just 7 days @Cloudflare.
- Unitree Robotics released the As2, a 4-legged robot for rough terrain with 90N·m torque @rohanpaul_ai.
Sovereign Subreddit Recap
As the Pentagon forces an ethical divide between labs, the community is pivoting toward local weights and sub-penny payment rails.
Today’s news highlights a fundamental bifurcation in the agentic landscape. On one side, we see the 'Sovereign Capability Gap' widening as OpenAI and Anthropic diverge over military surveillance guardrails—a conflict driven as much by ethical alignment as it is by the staggering $5B-$7B annual burn rates of proprietary labs. On the other, a robust 'Local-First' movement is maturing, fueled by Qwen’s commitment to open weights despite leadership shifts and MiniMax M2.5’s ability to match SOTA performance at 1/20th the cost. For builders, the message is clear: the frontier isn't just about raw power anymore; it’s about control, cost, and context. Whether it's bypassing the 'Context Wall' with dynamic MCP loading or bypassing traditional payment rails to enable sub-penny agent-to-agent transactions, the infrastructure for truly autonomous systems is moving from the cloud to the edge and the ledger. We are witnessing the birth of agents that aren't just chat interfaces, but economic actors with their own belief systems and local servers. The transition from stateless assistants to persistent, on-device entities is no longer a theoretical goal—it is the engineering reality for 2025.
Anthropic and OpenAI Diverge on Pentagon Deals r/OpenAI
The ethical divide between the industry’s leading labs has reached a fever pitch following reports that Anthropic CEO Dario Amodei refused a Pentagon demand to strip safety language from a potential contract. According to a leaked staff memo, the specific point of contention was a clause 'precluding the use of AI for mass surveillance of populations,' which the Department of Defense requested be removed to allow for broader intelligence applications.
While Anthropic remains in high-stakes negotiations to preserve these 'Constitutional AI' guardrails, OpenAI has reportedly moved to fill the vacuum, inking a deal for classified reasoning workloads just hours after Anthropic’s initial refusal. This strategic pivot has triggered immediate internal and external friction, with protests erupting at OpenAI’s San Francisco headquarters. The conflict highlights a growing 'sovereign capability gap,' where OpenAI prioritizes the capital required to sustain its $5B-$7B annual burn rate through military integration.
Critics in the r/OpenAI discussion suggest that Anthropic’s 'Ethics Alpha' positioning is attracting a new class of enterprise developers who view safety constraints as a prerequisite for secure, non-adversarial agentic deployment. Anthropic is effectively betting on the long-term value of alignment-first architectures while OpenAI moves toward rapid state-level integration to solve its liquidity pressures u/EchoOfOppenheimer.
Qwen Leadership Exodus Triggers Strategic Pivot r/LocalLLaMA
Alibaba's Qwen ecosystem is weathering a significant leadership transition following the resignation of lead researcher Junyang Lin, yet remains committed to its open-source roadmap. Alibaba CEO Eddie Wu has issued a 'permanent commitment' to ensure Qwen remains the primary alternative for practitioners avoiding proprietary 'logic loops' u/Bestlife73. This reassurance comes as the new Qwen 3.5 9B (MoE) model achieves a staggering 88% MMLU score, effectively rivaling the 91% performance of Claude 4.6 Opus while maintaining a significantly smaller footprint for on-device inference—a critical factor for overcoming the 275x 'token tax' issues identified in recent infrastructure audits u/samimandeel.
MiniMax M2.5 Matches Opus at Fractional Cost r/LLMDevs
A new efficiency benchmark has been set by MiniMax M2.5, which is reportedly matching Claude Opus on coding tasks at 1/20th the cost while achieving an 80.2% on SWE-Bench Verified. This signals a massive shift in the unit economics of autonomous software engineering, reducing daily workloads of 10M input tokens from hundreds of dollars to approximately $4.70 u/ML_DL_RL. In tandem, developers at Syncause reported that injecting 'runtime tracing context' into Gemini 3 Pro boosted its SWE-bench score from 77.4% to 83.4%, allowing agents to verify their own fixes using execution logs and stack traces before submission @Syncause_AI.
The Rise of On-Device Agentic Servers r/LocalLLM
The 'local-first' agent movement is accelerating as high-performance vision models like Qwen 3.5 VL 2B now run natively on mobile devices in airplane mode, bypassing cloud bottlenecks. Benchmarks for similar architectures on Snapdragon 8 Gen 3 hardware show inference speeds reaching 22 tokens per second, while enterprise builders are deploying entire vision-based automation products on single Mac Mini M2 units u/PublicAstronaut3711. For low-level researchers, the 'Orion' project has successfully bypassed the opaque CoreML stack to natively train Transformers on the Apple Neural Engine, achieving a 300% increase in training efficiency for small-scale models u/No_Gap_4296.
Diagnosing 'Context Decay' and Shorthand Emergence r/ClaudeAI
Practitioners report that sessions crossing 80% context capacity experience a silent degradation in quality, leading to 'shorthand emergence' where agents communicate in opaque, compressed JSON to save tokens u/YUYbox.
MCP Ecosystem Expands to VNC and UX Auditing r/mcp
The Model Context Protocol (MCP) now supports remote VNC control and automated UX law auditing, though developers warn that managing 9+ servers simultaneously triggers massive 'Context Bloat' u/UntoldBrobot.
Breaking the $0.30 Ceiling for Agent Payments r/LangChain
Specialized rails like Skyfire and NRail are bypassing Stripe's $0.30 minimum fees by utilizing Layer-2 protocols to enable the sub-penny transactions required for the agent-to-agent economy @SkyfireAI.
The Rise of Agentic Belief Systems r/MachineLearning
'The Orchard' cognitive architecture implements a local SQLite-backed knowledge graph to track 'Beliefs' and 'Doubts,' reducing reasoning drift by 22% via multi-agent Watchman-Worker loops u/Edenisb.
Engineering Digest
Open-source models close the gap while developers battle Windows performance papercuts and production networking gaps.
Open-weights are no longer the 'budget' option; they are becoming the foundation of the agentic web. Alibaba’s Qwen 3.5 series has fundamentally shifted the landscape, with its 122B model rivaling the likes of Claude 4.5 and GPT-5.1-medium in coding benchmarks. This isn't just about leaderboard ELO; it's about the feasibility of running high-fidelity, 100-step agentic loops locally or in private clouds without the 'Deep Research' limits of closed platforms. However, the path to production remains littered with friction. From 'execrable' performance of Claude's tools on Windows to silent 100% failure rates in n8n's Docker queue mode, the gap between a model's raw capability and a reliable agentic workflow is where the real engineering is happening. We are also seeing a massive hardware pivot. As models demand more VRAM, the community is moving toward high-bandwidth unified memory systems like AMD’s Strix Halo and even 'Frankenstein' GPU mods. Today’s issue dives into these frontiers: the models getting smarter, the hardware getting heavier, and the community-driven fixes keeping the agentic stack stable.
Open-Weights Surge: Qwen 3.5 Rivals Proprietary Giants
Alibaba’s Qwen 3.5 series has fundamentally shifted the open-weights landscape, with the 122B model securing a 1384 ELO in the LMArena Code Arena, placing it neck-and-neck with proprietary heavyweights like Claude 4.5 and GPT-5.1-medium LMArena Announcements. This performance surge is mirrored in the smaller tiers; the 27B variant achieved a staggering 1375 in coding tasks, effectively outperforming several 'Large' class proprietary models from the previous cycle. Verified data shared by @lmsysorg confirms that the 35B model is now performing on par with Gemini 1.5 Pro across general reasoning benchmarks, while its efficiency makes it a prime candidate for local orchestration.
In a strategic move for the agentic ecosystem, Alibaba CEO Eddie Wu reaffirmed that Qwen will remain open-source to serve as a 'global foundation' for AI development, a commitment lauded by the LocalLLM community as a critical counterweight to the tightening limits seen in closed platforms. Expert analysis from @vincenzolomonaco suggests that the 27B model remains the 'sweet spot' for local 100-step agentic loops due to its optimized balance of inference speed and high-fidelity reasoning.
Join the discussion: discord.gg/lmsys
Troubleshooting Claude Code: Navigating the Windows 'Papercuts'
Developers are navigating a series of performance bugs and connectivity issues in the latest Claude Code and Cowork releases, with Windows users bearing the brunt of the friction. bergamota_ reported 'execrable' performance on Windows OS following recent updates, with users describing latency spikes exceeding 5 seconds for simple directory listings. To stabilize these environments, ssj102 identified that enabling Hyper-V is a critical prerequisite for the underlying containerized execution, while community workarounds like deleting the .claude configuration folder have become the standard 'hard reset' for sessions plagued by 429 errors.
Join the discussion: discord.gg/anthropic
Strix Halo and Modded VRAM: The New Frontiers of Local Inference
The LocalLLM community is shifting focus toward high-VRAM hardware like the AMD Ryzen AI Max 300 series to sustain massive reasoning models locally. Offering up to 96GB of unified LPDDR5X-8000 memory, these 'Strix Halo' chips provide a bandwidth-heavy alternative to discrete GPUs for agent clusters Framework. Simultaneously, hardware modding has moved from niche hobbyism to a necessity, with discussions around 48GB modded RTX 4090s becoming frequent as models like Qwen 3.5 122B demand higher VRAM floors for sophisticated agent planning.
Join the discussion: discord.gg/localllm
Persistence and Precision: The Rise of Specialized MCP Memory Servers
New developments in the Model Context Protocol (MCP) ecosystem are targeting long-term memory with solutions like Anamnesis 5.0 and graph-based memory servers. neural_forge_13784 introduced Anamnesis 5.0 to provide cross-platform memory between Claude Desktop and Claude Code, though practitioners on the Claude #mcp channel note that multi-step tool reliability still requires a 10-15% increase in reasoning tokens to verify outputs.
Join the discussion: discord.gg/anthropic
Solving the n8n Agent Node Production Gap
Misconfigured Docker network settings are causing a 100% failure rate for agents in queue mode, requiring workers to have explicit outbound access to external APIs like OpenAI and Anthropic. Join the discussion: discord.gg/n8n
Bypassing the 'Thinking' Tax: Ollama's API-Level Optimization
Disabling 'thinking' mode in Ollama models can reduce response times by up to 40%, while the new 0.17.6 release officially resolves GLM-OCR vision regressions. Join the discussion: discord.gg/ollama
LMArena Adds Stop Button as GPT-5.4 Stealth Models Appear
LMArena has implemented a 'Stop' button to mitigate token waste during reasoning stalls, just as stealth 'GPT-5.4' and 'GPT-5.3' variants have begun appearing in the model selector. Join the discussion: discord.gg/lmsys
Open Source Frontier
UI-TARS shatters GUI benchmarks as the industry moves from brittle DOM-parsing to raw pixel vision.
Today’s issue marks a decisive shift in how we build and evaluate agents. We are moving past the chatbox era into high-fidelity autonomy where agents interact with the world like humans do: through raw pixels and executable code. The headline story is UI-TARS, a model that ignores the underlying DOM entirely to navigate desktops with an 83.6% success rate on ScreenSpot. This pixel-only approach, combined with the code-as-action philosophy championed by Hugging Face’s smolagents, represents a rejection of the brittle abstractions that have plagued early agentic frameworks. For developers, the signal is clear: the integration tax is falling. With the Model Context Protocol standardizing tool connections and tiny models like FunctionGemma bringing sub-second reasoning to the edge, the barrier to deploying specialized, vertical agents is vanishing. Whether it's MedGemma for healthcare or QSARion for chemistry, the focus has moved from general conversation to verifiable, audited execution. We are finally building tools that do not just talk about work—they do it.
From DOM-Parsing to Raw Pixels: The Rise of High-Fidelity GUI Agents
The landscape of graphical user interface (GUI) agents is undergoing a paradigm shift, moving away from brittle DOM-parsing toward pixel-only vision-language-action models (VLAMs). Leading this charge is UI-TARS: Next Generation Desktop Automation, which has established a new state-of-the-art with an 83.6% success rate on the ScreenSpot benchmark and 19.0% on the rigorous OSWorld environment, significantly outperforming the 14.9% baseline set by Claude 3.5 Computer Use.\n\nComplementing these high-parameter models is the push for on-device efficiency. ShowUI: One-Step Visual-to-Action for GUI Agents utilizes a lightweight 2B-parameter architecture to reach 75.1% visual grounding accuracy, proving that compact models can handle complex interface navigation without the latency of massive cloud-based APIs. This evolution is further supported by specialized vision-centric tools like OmniParser, which converts raw screenshots into structured, interactable regions.\n\nThese advancements allow agents to tackle long-horizon tasks in dynamic environments like VisualWebArena with increasing reliability. By addressing the logical reasoning decay that previously hindered multi-step workflows, these pixel-based systems are proving more robust than their text-parsing predecessors in cross-website evaluations, where UI-TARS maintains a 20.4% success rate on Mind2Web.
Hugging Face Democratizes Agent Development Education
Hugging Face is rewriting the agentic playbook by replacing brittle JSON schemas with direct Python execution via the smolagents library. This code-as-action philosophy distinguishes itself from frameworks like LangChain by allowing models to write and execute Python loops, a pivot that was instrumental in achieving a record 39.7% score on the GAIA benchmark as noted by @aymeric_roucher. The First_agent_template has already exceeded 800 likes, signaling a massive educational shift toward minimalist, debug-first orchestration that standardizes on the Model Context Protocol (MCP).
Standardizing the Agentic Stack: MCP Ecosystem Expands Beyond Hackathons
The Model Context Protocol (MCP) is rapidly becoming the universal USB-C port for the agentic stack, effectively reducing the integration tax by 70%. Originally launched by Anthropic to connect Claude to local data, the ecosystem has expanded to IDEs like Cursor and frameworks like smolagents. As @alexalbert__ notes, MCP decouples the tool-server from the model-client, a versatility showcased during the Agents-MCP-Hackathon where over 30 specialized servers were submitted for everything from real-time debugging to industrial-grade connectivity.
Structure-of-Thought and Hermes 3 Redefine Logical Adherence
Structure-of-Thought (SoT) and Hermes 3 are redefining logical adherence, with SoT showing significant gains across 14 tasks by forcing models to explicitly model information hierarchies.
Tiny Models Optimized for Mobile Actions
The release of functiongemma-270m-it-eee enables high-precision tool calling on edge devices with sub-second execution, bypassing the latency and privacy risks of cloud-based inference.
High-Fidelity Autonomy: Specialized Agents for Medicine, Science, and Code
Vertical agents like MedGemma and QSARion are bringing deep expertise to medicine and science through auditable reasoning traces and code-as-action workflows.