Native Reasoning and the JSON Tax
From code-as-action to native computer use, the agentic stack is trading general chatter for procedural reliability.
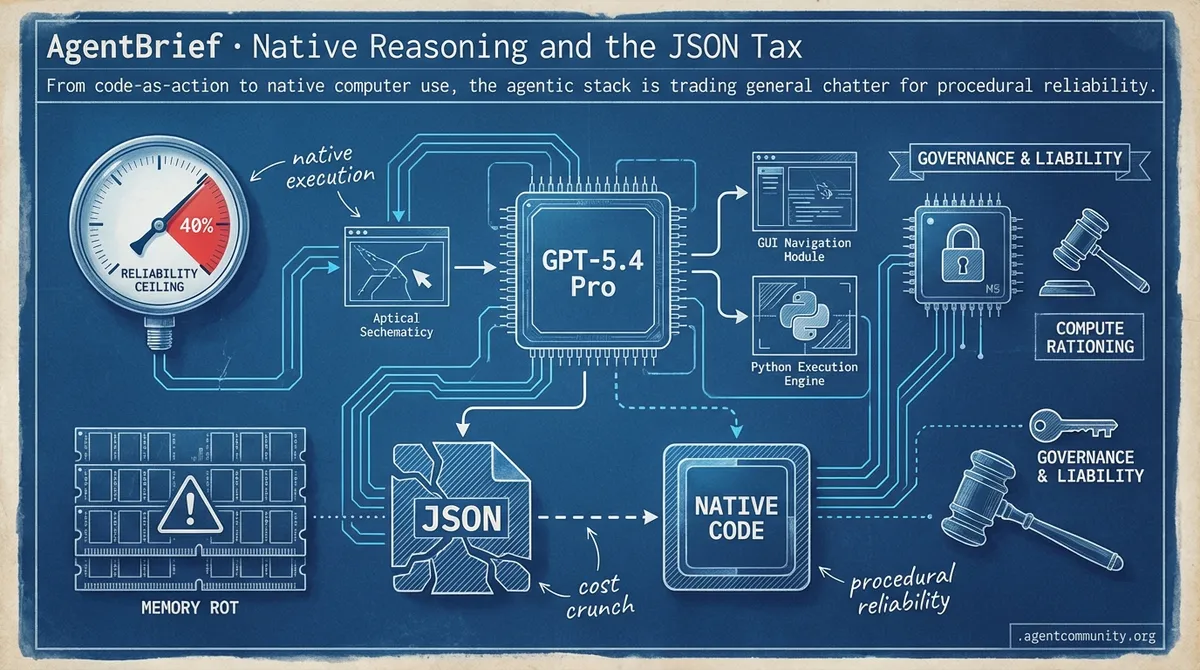
- Native Agentic Architecture The release of GPT-5.4 Pro and specialized libraries like smolagents signal a shift toward models that navigate GUIs and execute Python directly, effectively bypassing brittle JSON parsing.
- The Reliability Ceiling Despite a reported 47% drop in token usage for some ecosystems, builders are hitting a reliability wall in enterprise environments, where success rates often stall at 40% amid persistent memory rot.
- Infrastructure Under Pressure Compute rationing is becoming a reality as Anthropic prioritizes CLI tools over web interfaces, forcing practitioners toward model-agnostic orchestration and local-first hardware like M5 silicon.
- Governance and Liability As agents transition from vibe coding to high-stakes execution, the industry is grappling with new lawsuits over unauthorized legal practice and the urgent need for cryptographic identity.
The Frontier Feed
When your model starts steering itself mid-response, the orchestration game changes forever.
The agentic web is no longer a collection of clever prompts; it is becoming a unified layer of reasoning and tool-integrated infrastructure. This week, the release of GPT-5.4 Pro signals a shift where tool-search efficiency and native computer use are core architectural features rather than bolt-on capabilities. For builders, the drop in token usage for large ecosystems—reportedly up to 47%—is the real headline, as it directly lowers the 'tax' on complex agentic loops. Meanwhile, the friction between Anthropic and the Pentagon highlights the growing pains of 'dual-use' AI; as our agents move into high-stakes environments, the 'red lines' we draw around autonomous weapons and surveillance will define the legal landscape of our industry. We are also seeing a maturation of memory frameworks like Mem2ActBench, which finally addresses the gap between passive retrieval and active tool grounding. The signal is clear: we are moving past 'chat' and into a world of persistent, autonomous execution where the bottleneck isn't just intelligence, but the reliability of the memory-action loop.
GPT-5.4 Pro Sets New Bars in Coding, Reasoning, and Agentic Tasks
OpenAI has officially launched GPT-5.4 Thinking and GPT-5.4 Pro in ChatGPT, unifying advances in reasoning, coding, and agentic workflows into a single frontier model available via API and Codex @OpenAI. The model features a 1M token context window, native computer use capabilities, and enhanced tool search that reduces token usage by up to 47% in large ecosystems @sama. Early evaluations from @bindureddy suggest it is set to top LiveBench, while the Vectara leaderboard shows a grounded hallucination rate of 7.0%, a significant improvement over previous iterations @ofermend.
On the benchmark front, GPT-5.4 Pro achieved a new SOTA on FrontierMath Tiers 1-3 at 50% and reached 38% on the difficult Tier 4 @EpochAIResearch. It also reportedly outperformed Gemini 3.1 Pro on SWE-bench Verified with a score of 57.5% and exceeded human performance on OSWorld computer use tasks at 75% @ZakariaLahmouz @aipulseda1ly. These metrics indicate a model increasingly capable of navigating novel engineering problems without human intervention.
Practitioners are describing it as the premier model for software engineering, though some like @chatgpt21 note that frontend design capabilities may still lag behind Claude Opus 4.6. However, the addition of mid-response steering and more efficient tool grounding shifts the focus for agent builders toward scalable orchestration @polynoamial. While some contrarian views from @xw33bttv point to potential regressions on specific anti-hallucination tests compared to GPT-5.1, the broader consensus is a massive leap in agentic reliability.
Anthropic Challenges Pentagon's 'Supply Chain Risk' Designation in Court
The Pentagon has designated Anthropic as a 'supply chain risk' under 10 USC 3252, marking the first time a major US-based AI lab has faced such a label. CEO Dario Amodei has announced a legal challenge, arguing the move is 'not legally sound' and misapplies a statute typically reserved for foreign adversaries rather than domestic partners @rohanpaul_ai. While the designation is narrow—only affecting Claude's use in direct Department of War (DoW) contracts—it signals an escalating tension between AI labs and defense procurement @AnthropicAI.
The dispute centers on Anthropic's refusal to grant unrestricted access for certain military applications, citing 'red lines' against fully autonomous weapons and mass domestic surveillance @AnthropicAI. Despite this, Microsoft confirmed that its customers can still access Anthropic models through its platforms for non-DoW contexts @rohanpaul_ai. The company also apologized for a leaked internal memo that criticized the administration, characterizing it as unreflective of their considered views @rohanpaul_ai.
This legal battle has split the industry, with OpenAI publicly opposing the Pentagon's designation @rohanpaul_ai. The outcome could set a massive precedent for how 'dual-use' AI is regulated and deployed in national security contexts. For agent builders, this highlights the critical importance of understanding the compliance and ethical constraints of the underlying models they choose for high-stakes enterprise or government workflows @rohanpaul_ai.
In Brief
Mem2ActBench Tests Active Memory Application in Tool-Use Agents
A new benchmark, Mem2ActBench, is shifting the focus from passive memory retrieval to active tool parameter grounding in long-term agent interactions. Introduced in arXiv:2601.19935, the dataset includes 2,029 synthesized sessions where agents must proactively apply prior user preferences and task states without explicit reminders @adityabhatia89. Initial results across seven memory frameworks show that current systems struggle to translate recalled info into correct tool actions, identifying active memory application as a primary bottleneck for autonomous agents @adityabhatia89 @LangChainJP.
ByteDance Open-Sources DeerFlow 2.0 for Multi-Agent SDLC Automation
ByteDance has released DeerFlow 2.0, a SuperAgent framework designed to automate the full software development lifecycle through sub-agent orchestration. The framework, which has already surpassed 24K stars on GitHub, spawns specialized agents for research, coding, and file management within sandboxed Docker environments @jenzhuscott @DeFiMinty. While solo builders are using it as an 'AI dev team,' early testers like @lukenguyen_me note that task success rates for complex, multi-dependency repositories remain an area for further maturation.
Jevons Paradox Fuels Surge in Demand for AI-Literate Engineers
The Jevons Paradox is taking hold in tech as AI-driven coding efficiency leads companies to build more software rather than reduce headcount. Data from Citadel Securities and Uber CEO Dara Khosrowshahi suggest that cheaper development is unlocking projects that were previously uneconomical, driving massive demand for senior 'AI-literate' engineers who can architect agentic systems @rohanpaul_ai @rohanpaul_ai. Figures like @beffjezos argue that job loss fears are a 'psyop,' as supercharged developers are creating a 'Cambrian explosion' of new applications @rohanpaul_ai.
Quick Hits
Tool Use & Infrastructure
- Google released the gws CLI tool for programmatic agent access to Drive, Gmail, and Calendar @rohanpaul_ai.
- Anthropic made Claude Memory free for all users to support persistent agentic context @rohanpaul_ai.
- A new Model Context Protocol (MCP) framework simplifies cross-tool integrations for AI agents @tom_doerr.
Models & Research
- Gemini 3.1 Flash Lite launched in preview for low-latency, efficient agent tasks @rohanpaul_ai.
- GPT-5.3 Instant is rolling out to improve natural conversational flow in human-agent loops @rohanpaul_ai.
- AI-human collaboration successfully formalized a Fields Medal-winning math proof @rohanpaul_ai.
Policy & Legal
- New York lawmakers are advancing a bill to ban AI from providing licensed professional advice in medicine or engineering @rohanpaul_ai.
- UK upper house committee recommends a licensing-first approach for AI training data @Reuters.
The Builder's Board
High costs and "memory rot" challenge the latest native computer-use models while local hardware hits new speed records.
We are entering the "Native" era of agentic systems, but the transition is proving expensive and technically fragile. While OpenAI and Anthropic are shipping models designed to navigate GUIs natively, builders are hitting a wall of "memory rot" and exorbitant API costs. GPT-5.4 may offer a 40% latency reduction, but at $60 per million tokens, the economic moat for many startups is evaporating before it’s even dug. This has catalyzed a massive surge in the OpenClaw ecosystem, where developers are proving that autonomous cron jobs can replace $15,000/month operations stacks for a fraction of the cost.
The technical tension is clear: on one side, we have the frontier giants pushing for deep-click interaction; on the other, local-first enthusiasts are leveraging the M5 Fusion architecture to run 122B parameter models on their desks. But as autonomy scales, so does liability. The groundbreaking lawsuit against OpenAI for "unauthorized practice of law" serves as a stark warning: as agents move from "vibe coding" to high-stakes legal and financial execution, the need for deterministic governance and cryptographic identity is no longer optional. Today’s issue explores how we bridge the gap between model "overthinking" and production-ready reliability.
Frontier Models Battle for Native Computer Use r/OpenAI
The release of GPT-5.4 and Claude Opus 4.6 has shifted the focus from simple text generation to 'native' computer use. OpenAI claims GPT-5.4 is their first general-purpose model with built-in computer-use capabilities, moving away from traditional tool-calling wrappers as noted by u/secsilm. However, builders are already stress-testing these claims; a one-shot game-dev test comparing Opus 4.6 High and GPT-5.4 showed both models struggling with complex isometric simulations involving real-time asset generation. While GPT-5.4 demonstrates a 40% reduction in latency for OS-level navigation, it still fails on 22% of multi-step GUI tasks requiring 'deep-click' interactions.
Price sensitivity remains a major hurdle for agent developers. API costs for the new 5.4-Pro models are reportedly 20x higher than Anthropic's Sonnet, with rates reaching $60 per 1M input tokens, leading many to stick with 'vibe coding' on smaller models u/littlemissperf. Developers are also noting significant regressions in long-running sessions, where models like Claude Code begin re-introducing previously fixed bugs after approximately 120,000 tokens of context, suggesting lingering issues with context memory and caching. This 'memory rot' is forcing a pivot toward 'spec-first' development to prevent agents from degrading in production environments.
This interaction bottleneck is being challenged by the Coasty project, which disrupted the leaderboard by posting an 82% score on the OSWorld benchmark, a figure that dwarfs the 14.9% baseline set by Anthropic’s Claude 3.5 Sonnet u/Independent-Laugh701. While frontier models have historically struggled with UI latency and the 'context wall,' Coasty’s runtime-centric architecture focuses on deterministic interaction patterns to handle complex browser-based tasks. Simultaneously, llama.cpp has merged an 'Agentic Loop' and MCP client into its core UI, allowing servers to manage tools natively and reduce the 'token tax' associated with external orchestration.
OpenClaw Solidifies Lead as the Agentic Workhorse r/aiagents
OpenClaw has rapidly solidified its position as the primary open-source framework for autonomous tasks, with its GitHub repository now surpassing 145,000 stars. The framework's economic impact is evidenced by u/EstablishmentSea4024, who detailed a production setup that replaced a $15,000/month operations stack for just $271/month. While the ecosystem matures with tools like 'Bub' for real-time flow debugging and 'AIvilization' for social simulation, the community is currently prioritizing the v0.8.2 patch to prevent the public exposure of sensitive API keys that previously plagued over 220,000 instances.
Monetizing the Workflow in a Trench Coat r/AI_Agents
The 'Agent App Store' is professionalizing with 45% MoM growth, but industry veterans warn that 80% of agentic SaaS ideas are merely thin wrappers failing to provide a sustainable moat. Beyond the economic 'trench coat' trap u/soul_eater0001, a landmark Illinois lawsuit charging OpenAI with the 'unauthorized practice of law' has sent ripples through the community u/Apprehensive_Sky1950. Legal experts at @LawTechDaily suggest this sets a dangerous precedent for 'agent liability,' potentially requiring developers to carry professional malpractice insurance for autonomous entities.
Ownership Over Performance: The M5 Fusion Era r/LocalLLaMA
A growing contingent of developers is prioritizing 'ownership' over raw performance, running agents on-device to avoid the sovereign capability gap. Early tests of Apple's M5 Max 'Fusion Architecture' show an 8x AI performance jump, hitting 145 t/s on 7B models and maintaining a usable 5.2 t/s on the massive Qwen 3.5 122B model @Apple_Silicon_AI. Despite this power, users are reporting a persistent 'overthinking' bug in Qwen 3.5 122B where reasoning blocks delay initial responses by up to 45 seconds u/Nino_307.
Solving the Identity Crisis in MCP Ecosystems r/mcp
The Joy framework is introducing Ed25519 cryptographic signatures and Trust Scores to the Model Context Protocol to prevent manifest tampering and verify agent identity.
Vectorless RAG and Semantic Compression r/LLMDevs
'PageIndex' has achieved 98.7% accuracy on FinanceBench by using hierarchical tree-structured indexing to navigate 300-page PDFs without traditional vector chunking.
Kanban-Driven Orchestration: The Visual Pivot r/ClaudeAI
'Karavan' is an open-source framework that converts Trello boards into multi-agent orchestration layers, allowing humans to visually track agent handovers via card movements.
Dev Cluster Chatter
Anthropic pulls Sonnet 4.5 while GPT-5.4 benchmarks hit new highs amid widespread compute rationing.
The agentic web is currently caught in a squeeze between frontier model ambition and the cold reality of compute infrastructure. This week, we are seeing the first major signs of 'dynamic availability' becoming a permanent fixture of development. Anthropic’s decision to pull Sonnet 4.5 from web interfaces to shield its Claude Code CLI is a stark reminder that the tools we build are only as stable as the clusters behind them. Meanwhile, the stealthy rollout of GPT-5.4 variants has triggered a benchmarking frenzy, even as developers complain about 'token efficiency' filters that make the models feel lazier than their predecessors.
For practitioners, the message is clear: the era of 'set and forget' model selection is over. We are moving toward a world of model-agnostic orchestration, where local hardware like the upcoming M5 silicon and specialized protocols like MCP are becoming the primary levers for reliability. From standardizing agent behavior with global rule files to solving the 'silent hallucinations' in audio models, the focus has shifted from raw power to operational resilience. Today’s issue dives into how builders are navigating this flux, from programmatic agent wallets to the friction of multi-client MCP servers.
GPT-5.4 and Opus 4.6 Hit the Arena: Benchmarks Soar as Quotas Plummet
The agentic landscape is currently navigating a chaotic release cycle with the sudden appearance of GPT-5.4 and Opus 4.6. Developers in LMArena are debating whether recent 'maintenance' periods are due to GPT-5.4 deployment issues, with ieternalalx reporting a significant 89.2% score on the ROBLOC (Reasoning Over Bulk Logic) benchmark, a metric confirmed in the GPT-5.4 technical release notes. However, the consensus remains split; pjyonda calls the upgrade 'near pointless' while others argue that new 'token efficiency' filters are causing the model to appear 'lazy' compared to the 5.3 iteration.
Simultaneously, Opus 4.6 is seeing heavy adoption despite a usage spike where thegreatbobsby verified that 11% of a session quota can be consumed in just two minutes of interaction. This is further complicated by production friction in coding; hightskills. notes that GPT-4 still outperforms GPT-5.3 Codex in modernization tasks, suggesting that the 5.x generation is still optimizing its logic-to-compute ratio as noted by @vincenzolomonaco.
Join the discussion: discord.gg/lmarena
Anthropic Pulls Sonnet 4.5 to Shield Claude Code Infrastructure
Anthropic has transitioned to a 'dynamic availability' strategy, effectively removing Sonnet 4.5 and Opus 4.1 from web interfaces to prioritize compute for the high-intensity Claude Code CLI. This move, verified by brittiggs, follows a 40% spike in 'failed to load session' errors linked to the mec1-az2 AWS meltdown in Dubai. Developers like jonathane_kro report that the remaining Sonnet 4.6 feels 'dumbed down' compared to the 4.5 release, forcing builders to adopt model-agnostic orchestration to failover to Gemini 3.1 Pro or GPT-5.4 variants during peak throttling periods @tech_lead_v2.
Join the discussion: discord.gg/anthropic-claude
The 'Collapse' Crisis: Solving Image Rendering and Remote Friction in MCP
The Model Context Protocol (MCP) ecosystem is hitting a UI bottleneck where images returned via tool calls are auto-collapsed in the Claude Desktop client, disrupting autonomous loops. starphone1 notes this friction is absent in the web interface, prompting builders to experiment with 'Streamable HTTP'—a transport layer formalized in the MCP Specification to enable remote multi-client support. However, enterprise adoption remains hampered by a 15% failure rate in tool recognition following manual version bumps of Claude Code, as reported in the Claude Dev channel.
Join the discussion: discord.gg/claude-mcp
The 'Global Rules' Meta: Standardizing Agentic Alignment
As agentic development shifts toward a 'Rules-as-Code' paradigm, practitioners are adopting structured configuration files like .cursorrules and CLAUDE.md to maintain model alignment across scaling codebases. In the Cursor community, soheiil highlights that these rules are essential to prevent token-expensive redundancies, while matty07478565 advocates for moving critical logic to global paths like ~/.claude/CLAUDE.md to ensure a persistent governance layer that survives session resets and long-context compression.
Join the discussion: discord.gg/cursor
The Silence Problem: Mitigating Whisper’s 135 Hallucination Loops
Research from r/localllama identifies 135 phrases Whisper hallucinates during silence, recommending Silero VAD integration to reduce these errors by over 90%.
M5 Silicon and the 512GB Unified Memory Grail
The local LLM community is eyeing Apple's upcoming M5 silicon for a 2.5x jump in prompt processing, though bird0861 notes cloud VRAM remains more economical for startups at $160-$200/mo. Join the discussion: discord.gg/localllm
Exa and Context7 Emerge as the Backbone of Agentic Grounding
Exa and Context7 are redefining agent retrieval with neural reranking and low-latency MCP integration, while the Sequential Thinking MCP server allows agents to iterate through thought steps to prevent logic truncation.
Modexia SDK and the Rise of Programmatic Agent Wallets
The new Modexia SDK and Skyfire ($8.5M raised) are building 'agent wallets' to solve the 30-40% failure rate of autonomous shopping loops by allowing agents to navigate paywalls programmatically. Join the discussion: discord.gg/autogpt
Model Lab Insights
From code-as-action to 2B-parameter world models, the agentic stack is getting faster, smaller, and more autonomous.
The 'Agentic Web' is moving past its awkward teenage phase of brittle JSON parsing. Today’s landscape is defined by a hard pivot toward code-as-action and specialized world models that prioritize procedural reliability over general-purpose chatter. Hugging Face is leading this charge with
smolagents, a library that effectively kills the 'JSON tax' by allowing agents to execute Python directly. This isn't just a developer quality-of-life improvement; it's a performance necessity. As benchmarks like GAIA and OSWorld show, models that 'see and act' through code or direct visual grounding are finally outperforming the generalist giants.
However, the transition to production remains a gauntlet. New research from IBM and UC Berkeley reveals a sobering 'reliability ceiling,' where agents struggle to maintain a 40% success rate in messy enterprise IT environments. Whether it's NVIDIA bringing spatial reasoning to physical robots or ServiceNow distilling reasoning into mobile-friendly footprints, the industry is hyper-focused on one thing: closing the gap between a 'vibe-check' success and 99.9% industrial-grade autonomy. We are moving from agents that talk about work to agents that actually do it.
The Minimalist Pivot: Why Code-as-Action is Winning
Hugging Face has launched smolagents, a library that trades the 'JSON tax' of traditional tool-calling for a 'code-as-action' approach, where agents execute Python code to solve tasks. This shift has led to a 39.7% score on the GAIA benchmark, a result @aymeric_roucher attributes to the superior handling of complex logic compared to traditional orchestration.
Complementing this is the Model Context Protocol (MCP), which allows developers to build tiny-agents in under 50 lines of Python by standardizing how models connect to external tools. While frameworks like LangGraph excel at managing complex, stateful multi-agent graphs, smolagents focuses on procedural reliability and direct execution. The ecosystem now includes Agents.js for JavaScript-based tool use and native support for VLMs, enabling visual reasoning within the same execution loop.
To bridge the gap between development and production, the smolagents-phoenix integration offers robust tracing and evaluation, ensuring that these lightweight agents remain observable at scale. This focus on execution-trace transparency is becoming the new standard for developers who prioritize debugging over the 'black box' behavior of legacy agent frameworks.
Beyond Pixels: The Rise of Specialized GUI Operators
The frontier of 'Computer Use' is expanding with ScreenEnv and specialized models like Holo1 that demonstrate 5-10x lower latency than GPT-4o by interpreting visual interfaces without metadata. This shift toward end-to-end 'see-and-act' architectures is epitomized by UI-TARS, which set a new performance ceiling with an 83.6% success rate on the ScreenSpot benchmark. Meanwhile, Smol2-Operator is proving that efficiency matters, achieving a 12.9% success rate on OSWorld with a tiny 2.2B parameter footprint, nearly matching the performance of Anthropic’s much larger Claude 3.5 'Computer Use' model.
NVIDIA and LeRobot: The 'ImageNet Moment' for Physical Agents
Physical AI is entering a transformative phase as NVIDIA and Pollen Robotics launch Reachy Mini, a humanoid robot powered by the 2B-parameter Cosmos Reason 2 world model. Unlike traditional motion planners, this model introduces spatial and temporal reasoning to robotics, allowing agents to maintain object permanence and adapt to environments in real-time as noted by @RemiCadene. The infrastructure is further supported by the LeRobot Community Datasets and new video encoding techniques that provide a 3x acceleration in training speeds for behavioral cloning at scale.
The 40% Reliability Ceiling: Enterprise AI’s Reality Check
A diagnostic framework from IBM Research and UC Berkeley, IT-Bench and MAST, reveals that current AI agents hit a hard 20-40% success rate when navigating complex enterprise IT environments. The study identifies critical failure modes including hallucinated commands and state-tracking drift over long horizons, suggesting that general reasoning is insufficient for industrial troubleshooting. To combat this, the CUGA framework and AssetOpsBench are being deployed to embed operational guardrails directly into multi-step workflows, attempting to bridge the gap between lab benchmarks and production-ready automation.
Deep Research Efficiency
Hugging Face’s Open-source DeepResearch achieves a 70% reduction in inference costs via recursive CodeAgent loops that process over 100 sources per session.
Reasoning-Aware Distillation
ServiceNow’s Apriel-H1-7B distills dense reasoning into a 7B footprint with a 92% precision rate in identifying safety-critical action thresholds.
Pruning the Path to AMC 12
Kimina-Prover uses test-time RL search to hit a 45.6% success rate on the AMC 12 math competition by dynamically pruning incorrect reasoning paths.
Unified Tool Standards
The Unified Tool Use initiative harmonizes model-tool interaction, reducing boilerplate code by 70% and supporting the Model Context Protocol.