The Rise of Executable Agents
OpenAI's Operator and Hugging Face's CodeAgents signal a pivot toward high-reliability, code-executing autonomous systems.
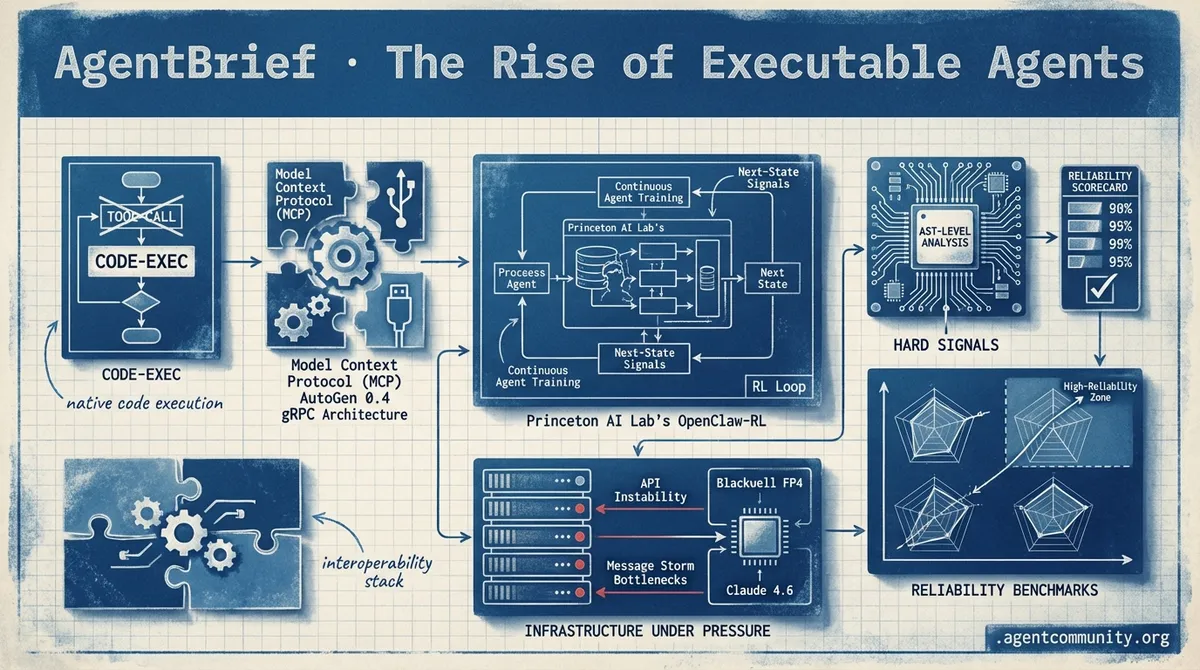
- Executable Autonomy Rising Hugging Face and OpenAI are moving beyond brittle tool-calling toward native code execution and high-reliability web automation. - Standardizing the Stack The emergence of the Model Context Protocol (MCP) and AutoGen 0.4's gRPC architecture signals a 'USB-C moment' for interoperability across the agentic cloud. - Deterministic Guardrails Required Developers are pivoting away from probabilistic 'inference on inference' toward AST-level analysis and hard signals to overcome production reliability hurdles. - Infrastructure Under Pressure While hardware like Blackwell FP4 and rumors of Claude 4.6 push boundaries, practitioners remain focused on solving API instability and 'message storm' bottlenecks.
X Real-Time Recap
Stop retraining your agents—start letting them learn from their own mistakes while they're still in the field.
The dream of the 'autonomous agent' has always been hindered by a frustrating reality: once you ship the weights, the agent is frozen in time. Today, that paradigm is shifting toward continuous, on-policy learning. Princeton's OpenClaw-RL is showing us a future where agents improve from binary feedback and next-state signals while they work, rather than waiting for an offline training cycle. This 'live learning' is the missing link for personalization and complex tool-use where static fine-tuning fails to capture the edge cases of reality.
But as agents get smarter and more integrated into our infrastructure—from Shopify's codebase to the US Department of Defense—we are hitting the 'Context Explosion' and the 'Policy Wall.' NVIDIA’s Nemotron 3 Super is a direct response to the massive token overhead of multi-agent collaboration, while the Anthropic-DoD standoff reveals a brewing conflict between developer-defined safety and the rigid requirements of state-level deployment. For those of us building the agentic web, the message is clear: the tech is ready for autonomy, but the infrastructure and the ethics are still catching up.
Princeton AI Lab’s OpenClaw-RL: Continuous Agent Training from Next-State Signals
Princeton AI Lab has unveiled OpenClaw-RL, a framework designed to break the cycle of offline retraining by enabling agents to improve continuously from everyday interactions. Developed by researchers including @LingYang_PU and @YinjieW2024, the system operates via four decoupled async loops—policy serving, rollout collection, PRM judging for rewards, and policy training—ensuring zero interruption to live deployments @MahRabie. By utilizing Hindsight-Guided On-Policy Distillation (OPD), it transforms textual feedback and user re-queries into token-level corrections in real-time @LingYang_PU.
The performance metrics suggest a massive leap for agentic personalization; scores jumped from 0.17 to 0.81 after just 36 conversations when combining Binary RL and OPD @MahRabie. The framework is built for scale, supporting up to 128 parallel terminal environments and 64 for GUI tasks, effectively unifying supervision from terminal traces, tool outputs, and GUI changes into a single learning signal @hasantoxr.
For builders, this marks the end of 'frozen' agent behavior. The ability to extract evaluative signals from likes, dislikes, or even tool-call failures means agents can finally self-correct without a developer in the loop. While early adopters like Zero-Human Company are already applying this to simulation refinement @BrianRoemmele, the broader OpenClaw ecosystem is expanding into specialized domains like biology and drug discovery through integrations with LabClaw's 206 skills @peterottsjo @lecong.
NVIDIA Nemotron 3 Super Targets Agentic Context Explosion
NVIDIA has released Nemotron 3 Super, a 120B parameter (with 12B active) hybrid Mamba-Transformer MoE model specifically engineered to handle the 'context explosion' inherent in multi-agent systems. Because collaborative workflows often generate 15x more text than standard chats due to repeated histories, NVIDIA implemented a native 1-million token context window to retain entire autonomous workflows @rohanpaul_ai @NVIDIAAIDev. The architecture uses multi-token prediction for 3x faster generation and Latent MoE to activate 22 experts per token out of 512 total, optimized for Blackwell efficiency @vllm_project.
In benchmarks critical for agent builders, Nemotron 3 Super achieved an 85.6% on the PinchBench coding agent test and matched GPT-5.4/GPT-4.1 levels in tool calling and instruction following during high-turn voice agent tests @NVIDIAAIDev @kwindla. It currently leads the Artificial Analysis Intelligence Index v4 with a score of 36, outperforming GPT-OSS-120B @fahdmirza.
This release solves a primary infra bottleneck: the cost of long-term memory. By offering open weights and recipes for commercial customization via Ollama and vLLM, NVIDIA is giving builders the orchestrator needed for long-running agents that don't lose their place in complex, multi-file projects @ollama. Early reports already show the model excelling as a master orchestrator for Hermes-based agents and PaperClip patterns @Elenion88 @altryne.
DoD Labels Anthropic’s Claude a “Supply Chain Risk” Over Constitutional AI Guardrails
The US Defense Department has designated Anthropic’s Claude models a 'supply chain risk,' a move that imposes a 6-month phase-out for all DoD contractors. Undersecretary Emil Michael argued that Anthropic’s 'Constitutional AI' framework effectively inserts company ethics into the military command structure, potentially vetoing operations related to autonomous weapons or mass surveillance @rohanpaul_ai @ReneAco17471468. This is an unprecedented designation for a domestic US firm, usually reserved for foreign adversaries @ReutersLegal.
Microsoft has since filed an amicus brief supporting Anthropic’s lawsuit for a temporary restraining order, citing the 'costly chaos' this creates for contractors who have already integrated Claude into military tech @Pirat_Nation. Microsoft, which has a $5B investment in Anthropic and over $9B in federal contracts, noted that the DoD did not provide a transition period for contractors equivalent to its own 6-month window @defense_eye @aakashgupta.
For agent developers, this highlights the growing friction between 'Safe AI' frameworks and the demands of high-stakes, unaligned deployment environments. While over 37 researchers from OpenAI and Google DeepMind have warned that this sets a dangerous precedent for punishing safety guardrails @Rita53135643, critics point to the risk of mid-operation disruptions if an agent's internal constitution conflicts with a mission-critical command @ArtemisConsort.
In Brief
Shopify Achieves 53% Speedup via Karpathy's Autoresearch Agent on Liquid Engine
Shopify CEO Tobi Lutke has demonstrated the power of autonomous optimization by deploying Andrej Karpathy's 630-line /autoresearch agent to optimize the company's 20-year-old Liquid templating engine. The agent ran 29 experiments across 21 files, resulting in a 53% faster parse+render time and 61% fewer object allocations after successfully merging 10 changes into production code @tobi @aakashgupta. This autonomous loop—which benchmarks performance and commits improvements—proves that agents can handle production-critical Ruby code at a scale that significantly lowers compute costs @simonw @whosjluk.
OpenClaw 2026.3.12 Ships with Plugin Architecture and Fast Mode
The latest OpenClaw release (v2026.3.12) introduces a modular plugin architecture that offloads providers like Ollama, sglang, and vLLM from the core code, allowing agent builders to swap backends with a lighter footprint. Beyond the architecture shift, the update includes Dashboard v2 with mobile support, a low-latency /fast mode for quicker model responses, and critical security patches for WebSocket escalations and Unicode spoofing @openclaw @J_Sterling__. These changes aim to make OpenClaw more production-ready for persistent agent workloads @J_Sterling__.
Google Maps Launches Agentic 'Ask Maps' Powered by Gemini
Google has rolled out 'Ask Maps,' a conversational Gemini-powered feature that transforms Maps from a search tool into a planning agent capable of handling complex intent like finding a place to charge a phone without a coffee line. Leveraging a database of 300 million places, the system handles multi-step itineraries and follow-up questions, effectively positioning AI as the gatekeeper of the local economy @Google @googlemaps. While builders see this as a production-scale example of agentic search, it raises significant concerns for competitors like Yelp and businesses now reliant on AI summaries of customer reviews @rohanpaul_ai @KayvonJafar.
Hermes Agent Adds Official Claude Support and PaperClip Adapter
Nous Research’s Hermes Agent framework has received a major update featuring official Claude provider support and an adapter for the PaperClip multi-agent orchestrator. Lead developer @Teknium confirmed the framework now allows for lighter installs by making RL components optional, while also reducing the default context compression ratio to 50% for better token efficiency @Teknium @agentcommunity_. Builders are already reporting superior performance on local hardware, such as running 9B models on RTX 3060s for autonomous multi-file coding tasks @sudoingX @llm_wizard.
Quick Hits
Agent Frameworks & Orchestration
- A new investigation agent framework enables recursive sub-agent delegation for dataset exploration. @tom_doerr
- A Rust-based agent for code generation and task automation has been released. @tom_doerr
- Junior launches an 'AI Employee' that executes tasks by reading Slack history without onboarding. @hasantoxr
Tool Use & MCP
- New MCP server allows AI agents to query and visualize OpenStreetMap data. @tom_doerr
- A desktop client for managing Claude Code Skills simplifies agent tool configuration. @tom_doerr
- MCP servers are now available for AI agents on Apple platforms. @tom_doerr
Developer Experience
- Claude Code session history is purged every 30 days unless users modify cleanupPeriodDays. @WolframRvnwlf
- The llmfit tool scans local hardware to identify compatible LLMs and quantizations. @heynavtoor
- A new tutorial covers containerizing Python MCP servers with Docker for Claude Code. @freeCodeCamp
- Llambada uses a coding agent to translate PDFs while preserving original layouts. @burkov
Reddit Automation Roundup
OpenAI's Operator sets a new bar for autonomous action as the industry pivots toward standardized tool-use and resilient persistence layers.
The shift from 'chatting with AI' to 'agents doing work' is no longer a theoretical pivot—it is a production-grade reality. Today’s landscape is dominated by two major movements: the rise of specialized browser-based action models and the urgent consolidation around interoperability standards. OpenAI’s 'Operator' has effectively thrown down the gauntlet, posting a 68% success rate on the Tau Bench and signaling a move away from general-purpose chat toward high-reliability web automation.
But for developers, the real story lies in the plumbing. As Anthropic’s Model Context Protocol (MCP) gains native support from Google Cloud, we are witnessing the emergence of a 'USB-C moment' for the agentic web. This isn't just about models; it's about the persistence layers in LangGraph and the type-safe validation in PydanticAI that make these systems resilient enough for enterprise deployment. We are moving past the 'prompt-and-pray' era into a world of distributed, event-driven agent clouds. Whether you are navigating the 'planning wall' in GAIA benchmarks or migrating to AutoGen 0.4’s gRPC architecture, the message for practitioners is clear: the infrastructure for autonomous systems is maturing at breakneck speed.
OpenAI Operator Sets New Benchmark for Action Models r/OpenAI
OpenAI's 'Operator' marks a pivot from chat to autonomous browser-based agents, demonstrating superior performance in task-oriented benchmarks compared to rivals. On the Tau Bench (Retail), Operator achieved a 68.0% success rate, significantly surpassing Anthropic Claude 3.5 Sonnet's 45.0% as reported by @OpenAI. This performance is powered by specialized vision-to-action models designed for multi-step workflows across web applications, moving beyond simple information retrieval.
Industry analysis suggests this move targets the $1.4B enterprise automation market by bypassing traditional API limitations through direct browser integration u/tech_enthusiast. While Anthropic's 'Computer Use' pioneered general desktop interaction, Operator's focused browser approach yields higher reliability in retail and travel planning tasks. OpenAI continues to refine safety guardrails, including 'Human-in-the-loop' confirmations for sensitive transactions, to prevent unintended consequences in production environments OpenAI News.
Anthropic’s MCP Becomes the 'USB-C for AI Agents' r/MachineLearning
The Model Context Protocol (MCP) has rapidly evolved from an Anthropic-led initiative into a cross-industry standard for agentic tool use. Google Cloud has officially announced native support for MCP within Vertex AI, enabling seamless connections between Gemini models and enterprise data sources @googlecloud. This follows the rapid expansion of the ecosystem, which now features over 200+ community-built servers on GitHub, surpassing the initial launch metrics. Anthropic's Alex Albert emphasizes that decoupling tool definitions from model-specific logic is essential for scaling multi-agent systems, a sentiment echoed by developers on r/MachineLearning who describe the protocol as the 'USB-C moment' for AI interoperability.
LangGraph Persistence Layer vs. CrewAI r/LangChain
LangGraph has solidified its position in the orchestration space by introducing advanced persistence features that allow multi-agent workflows to maintain state over extended periods. According to LangChain AI, these checkpointers enable 'time travel,' allowing developers to inspect, rewind, and fork agent states for debugging. While discussions on r/LangChain highlight LangGraph's granular control over cyclic graphs, its ability to survive server restarts with a 99.9% state recovery target remains a benchmark for production-grade resilient systems as noted by @Hush_AI.
GAIA Benchmark Exposes Planning Gaps r/MachineLearning
The General AI Assistants (GAIA) benchmark remains a formidable hurdle for autonomous agents, with top-tier models struggling to exceed 40% accuracy on complex tasks. According to the HuggingFace GAIA Leaderboard, Llama 3 70B scores approximately 34.3% on Level 1 tasks but faces a significant performance drop-off in higher levels. This 'planning wall' is a recurring theme in technical audits, as noted by @MetaAI, where the model's ability to maintain state across tool calls degrades over long horizons.
PydanticAI: Streamlining Type-Safe Agent Workflows r/LocalLLaMA
PydanticAI is gaining traction as a type-safe alternative to heavy frameworks, with Samuel Colvin noting its ability to significantly reduce hallucination rates for tool-calling agents.
Microsoft AutoGen 0.4: Rebuilding for the Distributed 'Agentic Cloud' r/MachineLearning
Microsoft has pivoted AutoGen 0.4 to a gRPC-based event-driven architecture, enabling 'Agentic Clouds' with a reported 10x potential in concurrency @Chi_Wang_.
Discord Developer Digest
As developers battle the 'inference on inference' trap, rumors of Claude 4.6 surface amidst API instability.
The agentic landscape is currently defined by a sharp tension between raw model capability and the deterministic guardrails required for production reliability. We are seeing a fundamental shift from 'let the LLM figure it out' to 'give the LLM a compiler-grade map.' This is most evident in the emerging debate over 'inference on inference'—the risky practice of using one probabilistic model to police another—which practitioners are now countering with AST-level analysis and hard signals. It is a necessary evolution; as we hit performance ceilings in complex environments like Java, the limitations of heuristic-based 'guessing' are becoming impossible to ignore. Simultaneously, the infrastructure layer is straining. Whether it is the friction of implementing NVIDIA’s Blackwell FP4 or the persistent 500 errors plaguing Anthropic’s API, the 'boring' parts of the stack—drivers, kernels, and rate limits—are currently the primary bottlenecks for agentic progress. Even as tantalizing hints of 'Sonnet 4.6' appear in API headers, the reality for builders remains one of navigating 41% benchmark plateaus and managing 'message storms' in autonomous loops. Today’s issue explores how deterministic engines and better orchestration standards are finally catching up to the hardware's theoretical limits to stabilize the Agentic Web.
Deterministic Safeguards: Hikaflow’s Answer to the ‘Inference on Inference’ Trap
A high-level technical debate has emerged in the Cursor community regarding the reliability of agentic code generation. Developer romirj highlights a core problem where one agent breaks a dependency another agent relies on, proposing a 'deterministic-first' approach via Hikaflow. This system utilizes a 4-signal fusion—AST-level analysis, cross-boundary type inference, dependency risk scoring, and historical bug matching—to catch risky changes before they are committed. According to Hikaflow's technical overview, this deterministic feedback loop allows agents to self-correct based on compiler-grade errors rather than probabilistic 'guesses,' effectively reducing the 'broken build' rate in multi-agent environments.
Contrasting this, theauditortool_37175 warns that 'inference on inference' is merely 'guessing on guessing.' While LLM-policing-LLM approaches often struggle with recursive hallucinations, deterministic engines provide hard signals first, using AI only for the fix suggestion layer. This shift is increasingly critical for practitioners managing the 10-14 terminal outputs typical of high-throughput agentic workflows. As noted by AI safety researchers, integrating static analysis with LLMs can improve 'verifiability' in autonomous coding by providing a 'ground truth' that models cannot hallucinate away.
Join the discussion: discord.gg/cursor
Anthropic API Instability Amidst Claude 4.x Version Speculation
Anthropic's developer ecosystem is currently grappling with persistent 500 Internal Server Errors specifically affecting the Messages API when utilizing OAuth tokens. While official documentation remains focused on the 3.5 family, community members lexxes_86380 report that internal version strings for 'Sonnet 4.6' and 'Opus 4.6' have appeared in API response headers, though these currently return down-states or 404/500 errors. This instability fuels rumors of a backend migration to support enhanced document processing capabilities, while Claude Pro subscribers report extreme rate-limiting—some reaching caps in as few as 2 prompts during peak traffic—suggesting a tightening of compute resources as the company prepares for its next major model rollout.
Join the discussion: discord.gg/claude
Blackwell’s FP4 Reality: Performance Gains vs. Implementation Friction
The LocalLLM community is dissecting the technical hurdles of nvfp4, NVIDIA’s low-precision format exclusive to Blackwell (GB10) architectures, which promises a 2.5x throughput increase. Despite the theoretical gains, practitioners like aimark42 argue the format is currently 'mostly marketing' due to the lack of mature driver and kernel support required to realize these gains in production. Unlike the transition to FP8, nvfp4's unified memory requirements make it 'really messy' to optimize for existing model architectures without significant refactoring, leaving developers 'big waiting' on llama.cpp PR #20525 for more stable bf16 flash attention support.
Join the discussion: discord.gg/localllm
Cracking the Java 41% Wall: Why Agentic Security Struggles with Type Systems
The OWASP Benchmark v1.2 has revealed a performance ceiling for agentic coding, with AI agents 'hard stuck' at 41% accuracy in Java security environments. This plateau is attributed to a fundamental failure in how agents construct Data Flow Graphs (DFG) in strictly typed languages; unlike Python, Java's deep inheritance requires precise symbol resolution that tools like tree-sitter struggle to provide without full compiler context. Technical analysis from @moyix suggests that until agents can natively integrate with deterministic AST analysis tools, they will continue to hallucinate execution paths and miss complex vulnerabilities like SQL injection.
Join the discussion: discord.gg/cursor
MCP Bridges the Gap Between LLMs and Game Engines
The Model Context Protocol (MCP) is standardizing how agents interact with Godot and Unreal Engine, allowing models to query scene trees and C++ structures directly to enable real-time 2D and 3D development. Join the discussion: discord.gg/cursor
AG2 Memory Graphs and n8n Debouncing: Taming the Multi-Agent Loop
AutoGen (now AG2) has overhauled its architecture with vector-based semantic memory, while a new n8n debouncing node prevents 'message storms' in autonomous recursive workflows. Join the discussion: discord.gg/autogen
Qwen 3.5 Distillations: Vision Integration Stalls Amidst GGUF Format Conflicts
Local LLM users are encountering 500 errors with Qwen 3.5 9B distillations in Ollama because the vision component is often provided as a separate file, requiring a manual GGUF strip to maintain basic text functionality. Join the discussion: discord.gg/ollama
The Irony of 'Sam': Perplexity’s Support Agent Faces the 'Agentic Friction' Wall
Perplexity Pro users are reporting an 'illusion of competence' as the company’s AI agent 'Sam' fails to resolve billing disputes, forcing power users to bypass the bot and tag CEO @arvind_srinivas directly. Join the discussion: discord.gg/perplexity
HuggingFace SOTA Highlights
Hugging Face's Open Deep Research hits a 67.4% GAIA score by replacing brittle JSON with executable code.
The agentic landscape is undergoing a fundamental shift in how 'action' is defined. For too long, developers have wrestled with the 'JSON sandwich'—the brittle process of forcing LLMs to output rigid schemas that inevitably break in production. This week, the narrative changed. Hugging Face released Open Deep Research, achieving a staggering 67.4% on the GAIA benchmark by ditching traditional tool-calling in favor of a CodeAgent architecture. By allowing models like Qwen2.5 to write and execute Python natively in sandboxed environments, we are moving toward a more resilient, verifiable form of autonomy.
But it isn't just about software research. From NVIDIA’s Cosmos Reason 2 bringing 'physical reasoning' to robotics via Llama-3-based loops to IBM and Berkeley’s new benchmarks diagnosing the 'cascading reasoning errors' that plague enterprise deployments, the focus has sharpened on reliability. Whether it’s specialized LoRA adapters for autonomous cybersecurity or scaling test-time compute for formal logic, the goal is clear: moving beyond simple prompt engineering toward robust, executable systems. This issue dives into the frameworks, benchmarks, and hardware integrations making the Agentic Web a reality for practitioners building the next generation of autonomous tools.
Hugging Face Launches Open DeepResearch: A 67.4% GAIA SOTA Built on Code-Action Agents
Hugging Face has released Open DeepResearch, an open-source framework designed to challenge proprietary search agents by achieving a 67.4% score on the GAIA benchmark. Built using the smolagents library, the system utilizes a CodeAgent architecture where the model—typically Qwen2.5-72B-Instruct—writes and executes Python code to perform multi-step research. This 'code-as-action' approach eliminates the 'JSON sandwich' problem, allowing the agent to handle complex logic and data processing natively in a sandboxed environment.
Specialized tools like the DuckDuckGoSearchTool and vision-integrated page navigation are used to browse the live web, ensuring the agent can interact with real-world data. Community implementations such as miromind-ai demonstrate these agents' capacity for long-horizon tasks, while the underlying Hugging Face Agents framework provides a 'License to Call' for verifiable tool execution.
GUI Agents Master Desktop and Web Interfaces
The frontier of 'Computer Use' is focusing on the 'last-mile' problem of coordinate precision to overcome cascading reasoning errors in enterprise deployments. Expanding on the progress of Holo1-70B and its 44.8% success rate on the Mind2Web benchmark, the Smol2Operator framework provides a specialized post-training recipe to ensure GUI agents execute precise, grounded actions. This is supported by ScreenSuite, which offers 100+ diagnostic tasks, and ScreenEnv, a dedicated environment for deploying full-stack desktop agents.
NVIDIA Cosmos and LeRobot: Scaling the Physical AI Reasoning Layer
NVIDIA is bridging the gap between high-level reasoning and low-level control with Cosmos Reason 2, a physical reasoning engine utilizing Llama-3-based architectures. By integrating with the Reachy Mini, NVIDIA demonstrates how a reasoning loop can manage real-time manipulation tasks through Chain-of-Thought planning. This effort is bolstered by the LeRobot initiative, which has expanded to 100+ community-driven datasets, and NXP, which is standardizing VLA models on the i.MX 95 embedded platform.
Smolagents and MCP: From Brittle JSON to Executable Code-Actions
The smolagents library achieves a 0.43 SOTA score on GAIA by prioritizing code-based actions and supporting 'Tiny Agents' via the Model Context Protocol (MCP).
Diagnosing Enterprise Failures with IT-Bench and AssetOpsBench
IBM Research identifies 'cascading reasoning errors' as a critical bottleneck through IT-Bench, which tests agents across 4,800 instances of OS and Cloud environments.
Scaling Formal Logic: Test-Time Compute and Multilingual RL Datasets
The AI-MO team's Kimina-Prover applies test-time RL search to Lean 4 proof generation, while NVIDIA released a 6.3 million sample multilingual reasoning dataset.
Specialized LoRA Adapters Turn Qwen2.5 into Autonomous Security Operators
Developer patlegu released specialized LoRA adapters for Qwen2.5-7B to automate OPNsense and CrowdSec security infrastructure through executable function calls.
Unifying Tool Use: Moving Toward Structured Code-as-Action
Hugging Face is standardizing agent interfaces with a universal Tool class and the StructuredCodeAgent to ensure interoperability across the ecosystem.