The Industrialization of Agentic Logic
From open protocols to code-as-action, the infrastructure for production-grade agents is finally calcifying.
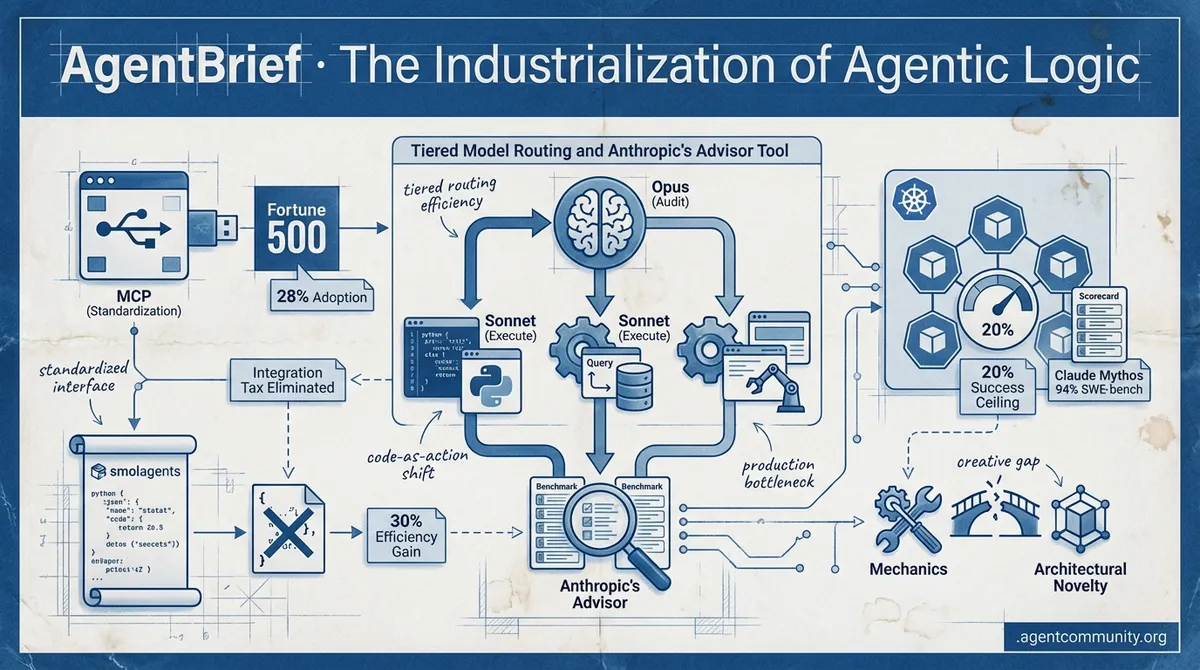
- Standardizing the Interface Anthropic's Model Context Protocol (MCP) transitioning to the Linux Foundation marks a "USB moment" for AI, with 28% of the Fortune 500 already adopting the standard to eliminate the integration tax. - Code-as-Action Shift Frameworks like Hugging Face’s smolagents are replacing brittle JSON tool-calling with direct Python execution, yielding 30% efficiency gains while shifting focus from general reasoning to autonomous operation. - Production Reality Check While Claude Mythos nears 94% on SWE-bench, enterprise tests in Kubernetes reveal a "20% success ceiling," highlighting a creative gap where agents excel at mechanics but struggle with architectural novelty. - Agentic Routing Maturity Tiered intelligence patterns—where high-reasoning models like Opus audit faster executors like Sonnet—are moving from experimental demos to cost-efficient, production-grade deployments.
X Intel & Trends
When routing intelligence becomes cheaper than single-model calls, the agentic web enters its industrial phase.
The era of the 'monolithic model call' is officially over. This week, the industry shifted toward a more sophisticated, agentic architecture where orchestration is as important as the underlying weights. Anthropic’s formalization of the 'advisor' pattern proves what top builders have known for months: tiered intelligence isn't just more capable—it's cheaper. By letting a high-reasoning model like Opus audit the work of a faster executor like Sonnet, we are seeing performance gains on SWE-bench and BrowseComp alongside double-digit cost reductions.
At the same time, the 'action layer' of the web is cracking wide open. Shopify’s decision to grant agents direct write access to 5.6 million stores is a watershed moment for autonomous commerce. We are moving from agents that 'suggest' to agents that 'operate.' Whether you are building coding agents that already claim 4% of GitHub commits or embodied systems running Tencent’s new open-source foundation models, the goal is the same: move the agent closer to the production environment. Today’s issue covers the tools and legal battles defining this transition.
Tiered Model Routing and Anthropic's Advisor Tool: Benchmarks and Developer Adoption
A major shift in agentic orchestration is occurring as developers move away from single-model tasks toward tiered intelligence. @akshay_pachaar highlights Anthropic's new 'advisor tool' which allows executor models like Sonnet to consult the more powerful Opus mid-task, ensuring frontier reasoning is only invoked when necessary. Anthropic's official announcement confirms pairing Opus as advisor with Sonnet or Haiku as executor delivers near-Opus intelligence at a fraction of the cost, all within a single API call @claudeai. @RLanceMartin, an Anthropic researcher, notes Sonnet calling Opus as advisor is cheaper than Sonnet alone due to Opus's token efficiency on harder parts, improving performance while cutting costs.
This approach significantly reduces costs while maintaining high accuracy, as noted by @aakashgupta, who observed $0.96 vs $1.09 per task by killing inefficient paths early. Benchmarks confirm: Sonnet + Opus advisor scored 2.7pp higher (74.8%) on SWE-bench Multilingual than Sonnet alone while costing 11.9% less per task; Haiku + Opus on BrowseComp reached 41.2% vs 19.7% at 85% lower cost than Sonnet solo @brainmirrorai @nimran_kazi.
Developers like @BioInfo report manually routing tiers for months and praise the API formalization for agentic workloads. @ibuildwith_ai built a free playground to test advisor vs solo models, enabling side-by-side cost/performance evals. To support this trend, @freeCodeCamp released a guide on cost-efficient tiered routing patterns, with early adopters like Zapier integrating for workflows @battista212.
Coding Agents Dominate Workflows and Commits
Autonomous coding agents are moving from novelties to primary drivers of software production. @rauchg estimates Claude Code is responsible for approximately 4% of all public GitHub commits, a staggering figure for a relatively new tool that has sparked massive hype with claw-code repos hitting 50k GitHub stars in 2 hours @SanvaadX. Enterprise cases show 86% of non-coders achieving deploys via Claude Code mandates @wataru4, while Vercel reports 30% of deployments triggered by agents, up 1000% in 6 months @rauchg.
While Anthropic gains ground, open-source alternatives like Hermes Agent (72k+ GitHub stars) @trending_repos are surging, with @Teknium claiming it's as capable as Claude Code with more features, including self-built codebases and auto-skill generation from tasks. Builders note Hermes' persistent memory and learning loops outperform OpenClaw for long-term use @gkisokay, though some prefer Claude Code's directness over framework bugs @Zeneca. OpenClaw boasts 5,400+ ClawHub skills @gkisokay for enterprise integrations like 7-agent teams delivering 10 features/month @0xSkill.
Builders like @aakashgupta emphasize the 'Claude Code operating system' architecture with workflows and templates for production code over 'code slop.' Comparative adoption shows Hermes exploding (47k stars in 2 months) @CTracy0803, OpenClaw maturing for enterprises @CTOAdvisor, but no unified benchmarks; users mix them for strengths @hosseeb.
In Brief
Tencent Releases HY-Embodied-0.5: Open-Source Foundation Models for Real-World Embodied Agents
Tencent has released HY-Embodied-0.5, a family of foundation models featuring a 2B open-source model for edge deployment and a 32B variant for complex reasoning. As announced by @TencentHunyuan, these models leverage a Mixture-of-Transformers (MoT) architecture trained on over 100M embodied samples, enabling VLA-ready integration for robot stacks @ModelScope2022. The 2B MoT model reportedly outperforms Qwen3-VL 4B on 16 tasks while maintaining on-device efficiency, sparking enthusiasm from builders like @AIBuddyRomano who celebrated its 89.2 CV-Bench score and @rayanabdulcader who highlighted its potential for autonomous robot planning without cloud dependency @HuggingPapers.
Shopify AI Toolkit Grants Agents Direct Write Access to 5.6M Stores
Shopify's new AI Toolkit allows agents like Claude Code and Codex to directly manage products, orders, and SEO across 5.6 million stores. According to @Shopify and @aakashgupta, this grants full backend access to stores handling $378B GMV, turning agents into production-ready operators. A merchant can now use a single terminal command to optimize SEO for an entire catalog, collapsing the cost of traditional $2,000 audits into a prompt-based task, with the toolkit providing MIT-licensed schemas and validation to ensure safety @awagents.
xAI Sues Colorado Over SB24-205 AI Anti-Discrimination Law
xAI has filed a federal lawsuit to block Colorado's SB24-205, arguing the nation's first comprehensive AI anti-discrimination law violates the First Amendment. The complaint, filed in U.S. District Court, claims the law treats AI outputs as protected speech and objects to state-defined fairness standards that xAI characterizes as viewpoint discrimination @ReclaimTheNetHQ @business. Supporters like @aakashgupta suggest the outcome will determine if agent builders face a stifling patchwork of 50 state compliance regimes, while critics warn that classifying AI outputs as speech could block necessary audits in high-risk sectors like healthcare @AVolatileAgent.
Quick Hits
Agent Frameworks & Orchestration
- A library of 5,200+ OpenClaw skills is now accessible for developer integration via @tom_doerr.
- Mastra introduces a 'no-touch' PII policy and allows developers to disable telemetry to ensure data privacy @calcsam.
- New multi-agent guide with code for routing and fanout patterns released by @Vtrivedy10.
Models for Agents
- GPT-5.4 Pro spotted as a slow but high-reasoning model optimized for complex agent logic @Vtrivedy10.
- GLM-5.1 lands in Droid, offering frontier MCP tool-use performance at half the cost @FactoryAI.
- Google's Gemini 3.2 Pro Preview Experimental has been seen in the wild according to @willccbb.
Tool Use & Developer Tools
- VoxCPM2 launches open-source voice cloning for 30 languages with studio quality @heynavtoor.
- Free browser-based fine-tuning for Gemma 4 models is now available via Unsloth Colab notebooks @akshay_pachaar.
- Adaptive web scraping framework with anti-bot bypass released for agentic data collection @tom_doerr.
Agentic Infrastructure
- TSMC reports 35% revenue jump driven by unprecedented demand for AI silicon @CNBC.
- Anthropic is co-designing Amazon's Trainium2 (Project Rainier) to optimize for memory-bound RL workloads @aakashgupta.
Reddit Field Reports
Claude Mythos shatters benchmarks, but new data reveals a 'creative gap' in autonomous coding.
The agentic web is no longer a collection of 'cool demos'; it is rapidly calcifying into professional infrastructure. Today’s landscape is defined by two major shifts: the standardization of how agents interact with tools and the realization of where their current capabilities end. Anthropic’s Model Context Protocol (MCP) has hit a massive 28% adoption rate among the Fortune 500 in record time, signaling that the 'LSP for AI' has finally arrived. Meanwhile, OpenAI's Operator is attempting to push agents out of the API sandbox and into the messy, non-deterministic world of the browser, though not without friction from 'hand-holding' requirements and platform gatekeeping.
But the most telling data comes from the coding front. While Claude Mythos has essentially 'solved' the SWE-bench Verified benchmark with a 93.9% score, new metrics from FeatureBench expose a 'creative gap.' Agents are world-class mechanics but mediocre architects; they can fix almost any bug you give them, but struggle to build something truly new. For developers, the message is clear: the focus is shifting from 'can it think?' to 'how does it act, persist, and scale?' We are moving from the era of the chatbot to the era of the autonomous operator.
Coding Agents Hit the Creative Wall r/ClaudeAI
Claude Mythos Preview has shattered autonomous coding records, hitting a 93.9% score on SWE-bench Verified. This leap suggests we are moving past simple pair programming into a phase where agents can independently resolve complex GitHub issues. However, efficiency remains a major differentiator; community benchmarks on r/ClaudeAI demonstrate that context management alone can create a 3x cost gap between agents using the same underlying model.
Despite these gains, the 'creative gap' remains a formidable hurdle for the Agentic Web. While agents excel at repair—achieving 74% on bug fixes—newly released FeatureBench data shows performance plummets to just 11% when building original features. As Dave Patten observes, the transition to 'Autonomous AI Teams' requires more than better RAG; it demands the ability to maintain coherence over extended autonomous sessions, a metric now being tracked by METR to move beyond simple assistance.
MCP Achieves 28% Enterprise Adoption r/mcp
Anthropic’s Model Context Protocol (MCP) has reached a 28% implementation rate among Fortune 500 companies, effectively becoming the 'LSP for AI' by decoupling model logic from tool integration. Discussions on r/mcp highlight that the ecosystem is maturing through heavy concentration, with the top 50 repositories accounting for 60% of all GitHub stars and development led by major infrastructure players including Microsoft, AWS, and CloudFlare.
OpenAI Operator and the Browser Paradox
The rise of Large Action Models (LAMs) like OpenAI's 'Operator' signals a shift toward agents that act as proxy users, though early technical assessments from Prajwal Nayak highlight a 'hand-holding' paradox where persistence limitations often require user intervention for multi-step navigation. While UI-based agents offer a necessary bridge for legacy systems where API integrations are non-existent, the 'open web' is becoming increasingly hostile, with major platforms like Reddit actively blocking AI agents from accessing their interfaces.
The Battle for Agent State r/LangChain
While CrewAI dominates rapid prototyping with 12 million daily executions, LangGraph is winning enterprise adoption due to its explicit state persistence and 'human-in-the-loop' checkpoints. As noted on r/LangChain, LangGraph’s fine-grained state control is increasingly viewed as mandatory for high-value operations exceeding $10k, where state decay can lead to catastrophic financial errors.
Local Infra: Ollama vs vLLM r/Ollama
vLLM achieves 793 TPS in production benchmarks, significantly outperforming Ollama for high-concurrency agent swarms requiring recursive tool-calling r/Ollama.
The Rise of Self-Editing Memory r/LocalLLaMA
The industry is bifurcating between stateless agents with memory sidecars like Mem0 and stateful, memory-first systems like Letta that allow agents to edit their own context r/LocalLLaMA.
Discord Dev Logs
Open standards and high-performance open weights are dismantling the barriers to production-grade autonomous agents.
The dream of a plug-and-play agentic ecosystem just took a massive leap toward reality. With Anthropic handing the Model Context Protocol (MCP) to the Linux Foundation, we are witnessing the 'USB moment' for the Agentic Web. It is no longer about writing custom integration code for every SaaS tool; it is about a unified interface that allows reasoning models to talk to data seamlessly. This maturation is echoed in the hardware-like reliability of Llama 3.1’s function calling, which now rivals GPT-4o on the Berkeley Function Calling Leaderboard. For developers, the narrative is shifting from basic feasibility to enterprise-grade stability. We are moving away from brittle, linear scripts toward stateful, long-running agents that can navigate the web via vision and maintain memory across thousands of turns. Today’s issue explores how these foundational shifts—standardized protocols, open-weights parity, and robust persistence layers—are finally enabling builders to move past the 'planning wall' and into production at scale.
MCP Solidifies as the 'USB Port' for Agentic Enterprise
The Model Context Protocol (MCP) has officially transitioned from an Anthropic-led experiment into a cross-industry standard, now governed by the Linux Foundation under the newly established Agentic AI Foundation. By decoupling the reasoning layer from data retrieval, MCP effectively ends the 'integration tax' that has long frustrated developers. The ecosystem is already seeing explosive growth, with an official community-driven Registry now facilitating the discovery of over 150 community connectors for essential services like Slack, GitHub, and PostgreSQL.
For enterprise builders, this move marks the transition of agents from experimental demos to the backbone of secure, scalable AI. The reported 40% reduction in integration boilerplate code is a massive win for developer velocity, especially as industry giants like Google DeepMind and OpenAI embrace the standard. This unified interface ensures that models can interact with local and remote tools dynamically, providing the reference implementations necessary for scaling autonomous systems in production environments.
Llama 3.1 Overtakes GPT-4o in Global Function Calling Benchmarks
The open-weights ecosystem has reached a historic parity with proprietary models. Llama 3.1 405B and 70B now lead the Berkeley Function Calling Leaderboard (BFCL) with accuracy scores reaching a staggering 88.5%. This performance places Meta's latest models ahead of GPT-4o-2024-05-13, signaling that high-reliability tool use is no longer exclusive to closed-source APIs. For practitioners, this shift enables the deployment of privacy-conscious, locally-hosted backends for enterprise applications without a performance penalty.
The maturation of these models is further evidenced by a 15% decrease in 'hallucinated' tool calls. Models are becoming significantly better at identifying when a requested tool is missing from the provided context, allowing for more robust 'agentic loops.' Rather than executing incorrect or dangerous code, these models can now reliably fail-over or request clarification, a critical requirement for building autonomous workers that users can actually trust.
LangGraph Persistence Layers Enable Long-Running Agents
LangGraph has solidified its position as a leading orchestration framework by solving the #1 challenge for developers: state management. By introducing robust persistence layers, LangGraph allows agents to maintain state across thousands of turns, supporting specialized checkpointer backends like PostgreSQL, SQLite, and Redis. This architecture enables 'time-travel' debugging, allowing developers to rewind agent states to the exact moment of a planning failure to diagnose issues with surgical precision.
While recent 2026 benchmarks from @saivishwak indicate that LangGraph may have higher peak memory usage than some Rust-native alternatives, its deterministic state machines provide a 25% improvement in developer velocity. This persistence model ensures that agents can resume tasks seamlessly after system restarts or crashes, making it the preferred choice for enterprise-grade autonomous workers that require 100% state fidelity.
Vision-Augmented Agents Outpace Traditional RPA in Web Navigation
The open-source library browser-use has rapidly become a dominant force in autonomous web navigation, surpassing 10,000 GitHub stars as developers pivot from brittle DOM-parsing to vision-augmented loops. By leveraging Playwright and Vision-Language Models (VLMs), browser-use achieves a 78% success rate on high-difficulty browser tasks—a 16-point lead over standard LLM configurations. This represents a fundamental move toward systems that can truly 'use a computer' like a human.
Unlike traditional RPA tools that rely on deterministic scripts that frequently break on dynamic sites, these vision-grounded agents handle multi-tab workflows and complex form filling without manual selector mapping. While traditional Playwright remains the faster choice for high-volume, deterministic tasks, the industry is clearly shifting toward reasoning-driven flexibility to bypass the 'planning wall' that previously limited web agents to simple, linear tasks.
Hardening the Agentic Perimeter with Dual-LLM Architectures
As agents gain the autonomy to read emails and browse the web, indirect prompt injection has emerged as a critical vulnerability. Security researchers from Invariant Labs, IBM, and Microsoft are now advocating for the Dual-LLM pattern to address 'Excessive Agency' (OWASP LLM08). In this design, a 'Privileged' model executes tools while an 'Unprivileged' model sanitizes untrusted inputs, creating a robust firewall between the agent's reasoning and the execution layer.
Case studies on ReAct-based agents show that without these guardrails, attackers can easily transform helpful assistants into 'Confused Assistants' that leak sensitive data. Implementations by platforms like MindsDB demonstrate that this separation effectively prevents malicious payloads from reaching the execution layer. For developers, adopting these security patterns is no longer optional if they intend to grant agents access to third-party content or sensitive internal data.
Graph-Based Memory and A-MEM Eclipse Standard Vector RAG
Simple vector-based RAG is proving insufficient for agents that require deep relationship mapping and long-term consistency. Developers are now pivoting toward GraphRAG architectures and Agentic Memory (A-MEM), which dynamically organizes historical experiences by establishing relevant links between concepts. The integration of Temporal Knowledge Graphs is specifically addressing the 'planning wall' by allowing agents to handle chronological data with 90% higher accuracy than flat vector search.
Despite these gains, scaling these systems remains a major hurdle. Memory management and the computational cost of dynamic graph updates are cited as primary performance bottlenecks. As noted in Andrej Karpathy’s 2026 analysis, the 'LLM Wiki' approach may emerge as a potential alternative for static knowledge retrieval, but for agents requiring long-term, evolving context, the move toward graph-based architectures appears inevitable.
HuggingFace Research Hub
Why Python is replacing JSON in the battle for reliable agentic logic.
The narrative of the 'Agentic Web' is shifting rapidly from general-purpose assistants to high-precision, code-centric operators. For months, the industry has struggled with the 'brittle JSON' problem—where agents fail simply because they can't format a tool call correctly. Today, we are seeing a definitive pivot toward 'code-as-action,' led by Hugging Face’s smolagents. By allowing agents to write and execute Python directly, we aren't just making them smarter; we're making them significantly more efficient, with data showing a 30% reduction in operational overhead.
However, this progress is met with a sobering reality check from researchers at IBM and UC Berkeley. While lab benchmarks like GAIA and WebVoyager are seeing record scores, enterprise environments like Kubernetes clusters reveal a '20% success ceiling' plagued by cascading failures and premature task abandonment. The bridge across this gap isn't just better models, but better diagnostics. From the high-speed Holotron-12B solving GUI latency to the 14 specific failure modes identified in the MAST taxonomy, the tools for building production-grade agents are finally maturing. This issue explores the frameworks, benchmarks, and architectural shifts defining the next phase of autonomy.
Smolagents: Code-Centric Logic and the GAIA Breakthrough
Hugging Face has solidified the smolagents ecosystem as a leader in minimalist, high-performance autonomy, shifting the paradigm from brittle JSON tool-calling to direct Python code execution. This "code-as-action" approach is a significant performance driver; the Transformers Code Agent secured a 0.43 SOTA score on the GAIA benchmark, notably outperforming more complex multi-agent architectures like Autogen. Technical reviews indicate that these code-centric agents utilize ~30% fewer operational steps and LLM calls compared to traditional function-calling methods when tackling complex tasks nolist.ai.
Beyond raw logic, the framework now features native support for Vision Language Models (VLMs), allowing agents to process visual inputs within the same minimalist loop huggingface. For production-grade reliability, developers can leverage deep integration with Arize Phoenix for real-time tracing and evaluation of reasoning paths huggingface. Furthermore, the core logic is being adapted for specialized domains like the DeepMath project by Intel, which applies the framework to complex mathematical problem-solving huggingface.
High-Throughput VLMs Break the GUI Latency Barrier
The 'Computer Use' frontier is undergoing an architectural shift toward high-frequency interaction, led by the Holotron-12B model which achieves a staggering 8.9k tokens/s throughput on a single H100. This leap in processing speed, documented by [H Company], has propelled agent performance on the WebVoyager benchmark from a 35% baseline to an 80% success rate. To ensure these high-speed agents are actually reliable, thomwolf and the Hugging Face team introduced ScreenSuite, a diagnostic platform providing over 100 tasks to stress-test UI interpretation across different operating systems.
Diagnosing the 20% Success Ceiling in Enterprise Environments
Research from ibm-research and UC Berkeley has exposed a sobering 20% success ceiling for agents in complex IT environments like Kubernetes. To address this, they introduced the Multi-Agent System Failure Taxonomy (MAST), which identifies 14 specific failure patterns, noting that 31.2% of failures are attributed to 'Premature Task Abandonment' @kukarella. This move toward granular diagnostics is mirrored in AssetOpsBench, which tests agents against the messy, long-horizon data found in industrial infrastructure @changecast.
Open-Source Deep Research achieves 10x cost reduction compared to proprietary alternatives via smolagents.
Open-Source Deep Research achieves 10x cost reduction compared to proprietary alternatives via smolagents.
Tiny Agents implement MCP-powered autonomy in as few as 50 lines of code, enabling dynamic tool discovery.
Tiny Agents implement MCP-powered autonomy in as few as 50 lines of code, enabling dynamic tool discovery.
Google's EHR Navigator Agent shows a 10-14% accuracy lead over GPT-4 in specialized medical classification tasks.
Google's EHR Navigator Agent shows a 10-14% accuracy lead over GPT-4 in specialized medical classification tasks.
AgentSwing introduces adaptive parallel context routing to optimize long-horizon trajectories.
AgentSwing introduces adaptive parallel context routing to optimize long-horizon trajectories.