The Rise of Agentic Standards
Industry giants and open-source pioneers are aligning on protocols that move agents from experimental wrappers to production-grade software.
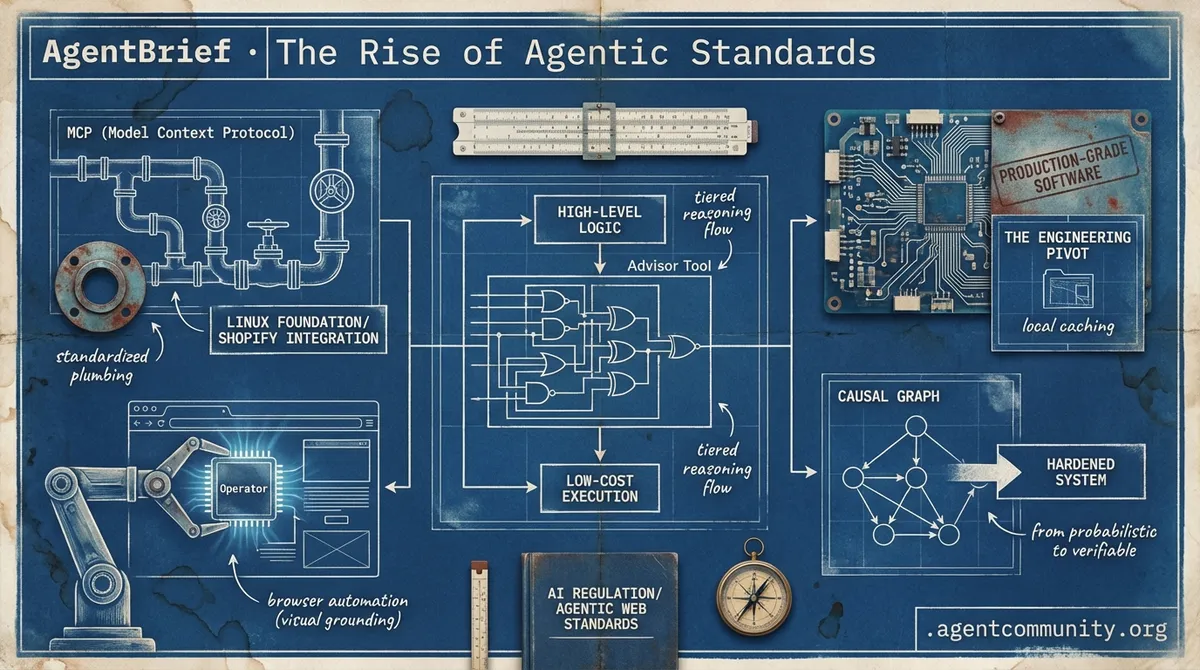
- Standardizing the Plumbing The migration of the Model Context Protocol (MCP) to the Linux Foundation and Shopify’s massive integration heralds a new era of standardized agentic interoperability. - Browser Automation Supremacy OpenAI’s 'Operator' has redefined the state-of-the-art in visual grounding, while Hugging Face’s smolagents approach is crushing benchmarks by stripping away framework bloat. - The Engineering Pivot From deterministic causal graphs to local caching, the community is moving away from probabilistic 'vibes' toward hardened, verifiable production systems. - Tiered Reasoning Architectures New patterns like Anthropic’s Advisor Tool are treating compute as a tiered resource, separating high-level logic from low-cost execution to scale agentic workflows.
The X Intel
Stop building wrappers; start building systems that think before they act.
We are moving past the era of the 'chat box' and into the era of the 'agentic socket.' This week, the shift became palpable. Anthropic’s new Advisor Tool isn't just another API parameter; it’s a blueprint for tiered reasoning that treats compute like a supply chain—using cost-efficient models for the execution and calling in frontier-grade 'specialists' only when the logic gets fuzzy. This is the pattern that actually scales in production: high intelligence, low overhead.
Meanwhile, Shopify just handed the keys to 5.6 million store backends to any agent that can speak the Model Context Protocol (MCP). This is the 'agentic web' in its rawest form: autonomous systems with direct write access to global commerce. For builders, the focus has shifted from prompt engineering to system orchestration. We aren't just writing code; we are designing the protocols for how these systems interact with the world. Whether it's Anthropic co-designing silicon for RL-heavy workloads or xAI fighting for the right of agents to speak without state mandates, the infrastructure is finally catching up to our ambitions. If you aren't building with multi-agent coordination in mind, you're already legacy.
Anthropic's Advisor Tool Unlocks Cost-Efficient Tiered Reasoning
Anthropic has introduced an 'advisor tool' in public beta on the Claude Platform, allowing lower-cost models like Sonnet or Haiku to consult the frontier-grade Opus model mid-task. According to the official announcement, developers can activate this via the anthropic-beta: advisor-tool-2026-03-01 header, enabling the executor model to hit a hard decision, consult Opus for a strategic plan, and continue the task—all within a single API request. This pattern delivers near-Opus intelligence at a fraction of the cost, as verified by @claudeai and @ninja_prompt.
Benchmarks show that this tiered routing significantly boosts accuracy while cutting expenses. A Sonnet + Opus advisor configuration scored higher on SWE-bench than Sonnet alone—74.8% vs 72.1%, a 2.7pp gain—while costing 11.9% less per task ($0.96 vs $1.09). As @aakashgupta and @nimran_kazi noted, the efficiency comes from Opus killing dead-end paths early before the cheaper model wastes tokens on a failed execution. Anthropic researcher @RLanceMartin emphasized that this token efficiency is the primary driver of the lower overall cost.
This framework is rapidly gaining traction in production-grade agentic workflows. Community guides from @freeCodeCamp and @thishivam are already circulating, helping builders implement the advisor/executor pattern. The release aligns with broader updates to Claude Code (v2.1.100+) and the Managed Agents public beta, signaling a move toward cloud-hosted, multi-agent orchestration for complex software engineering tasks @PuntoyComaTech.
For builders, the game has changed from selecting a single model to designing a reasoning hierarchy. Early adopters like @pblrueda report using Opus for high-level planning and Sonnet for subagent execution, effectively creating a 'manager-worker' dynamic that was previously too expensive or too slow to run at scale. This beta marks the official productization of tiered reasoning as a core primitive of the agentic web.
Shopify Grants Coding Agents Full Write Access via AI Toolkit
Shopify has officially entered the agentic web by launching an AI Toolkit that grants coding agents like Claude Code, Codex, and Cursor direct write access to the backends of over 5.6 million stores. This toolkit enables agents to perform bulk SEO optimizations, manage inventory, and update orders from a single prompt, potentially collapsing $2,000 professional audits into simple terminal commands @Shopify @aakashgupta. The toolkit is MIT-licensed and includes official API schemas and MCP integration for seamless store execution @awagents.
This move capitalizes on the explosive adoption of agentic coding tools. According to @rauchg, Claude Code alone is estimated to be responsible for approximately 4% of all public GitHub commits, while Vercel reports that agentic workflows now trigger 30% of its deployments. As agents become the primary users of developer tools, Shopify is positioning itself as the 'socket' for this new workforce. Architectural deep-dives from builders like @tom_doerr suggest that this direct integration significantly reduces the friction of managing complex e-commerce stacks.
However, the community is raising red flags regarding the lack of native safety protocols. The toolkit currently lacks built-in guardrails, undo functions, or 'draft modes' for live writes, which @MarkSilen and @OneManSaas warn could lead to catastrophic inventory or pricing errors due to model hallucinations. Beyond technical risks, some developers like @MRRunciss suggest that this automation could threaten the revenue models of third-party Shopify apps that previously charged for these manual tasks.
In Brief
GLM-5.1 Tops Open-Weight Agentic Benchmarks; HY-Embodied-0.5 Enables Edge Robotics
Z.ai's GLM-5.1 has launched as a 754B MoE open-weight model delivering frontier performance at half the cost of proprietary rivals, ranking #3 globally on SWE-Bench Pro with a score of 58.4. The model excels in long-horizon tasks, sustaining up to 1,700 steps over 8 hours for complex tool use and cybersecurity experiments @Zai_org @OpenRouter. Simultaneously, Tencent’s HY-Embodied-0.5 family is pushing agentic capabilities to the edge with a 2B model that outperforms Qwen3-VL on vision benchmarks, enabling spatial-temporal perception for robotics without cloud dependency @TencentHunyuan @AdinaYakup.
MCP Resource Fallbacks Gain Traction as Skills Marketplaces Proliferate
Developers are standardizing agent capabilities via the Model Context Protocol (MCP), with new proposals to formalize 'skills' loading through official extensions and 'skills://' URIs. As @RhysSullivan and Anthropic's @dsp_ discuss official fallbacks for client-side tool support, the ecosystem is exploding with modular repositories like the 5,200-skill list curated by @tom_doerr. New marketplaces such as AGNTMarketplace and skills.sh are aggregating tens of thousands of vetted skills, though security warnings from @capodieci emphasize the need for sandboxing to prevent malicious prompt injections.
Trainium2 Co-Design Prioritizes Memory Bandwidth for RL Over Raw TFLOPS
Anthropic’s partnership with AWS on the Trainium2 chip highlights a strategic shift toward memory bandwidth as the critical metric for memory-bound reinforcement learning (RL) workloads. While Trainium2 may trail Nvidia's latest chips in raw TFLOPS, its co-design by Anthropic engineers optimizes it for the massive RL rollouts required for frontier models like Mythos @aakashgupta @BourbonInsider. The recent activation of Project Rainier, a 1GW cluster of 500,000 chips, provides the scale necessary for these compute-intensive training needs @zephyr_z9.
xAI Sues Colorado Over SB24-205 AI Anti-Discrimination Law
xAI has filed a federal lawsuit against Colorado to block SB24-205, arguing that mandatory algorithmic bias audits constitute unconstitutional compelled speech under the First Amendment. The suit contends the law forces models like Grok to adopt state-preferred ideological views on equity rather than pursuing 'maximal truth,' according to filings highlighted by @rohanpaul_ai and @DavidSacks. While critics like @AVolatileAgent argue these audits are essential for preventing harm in high-risk sectors like healthcare, the outcome will directly impact the liability and decision-making frameworks of autonomous agents @Newsforce.
Quick Hits
Agent Frameworks & Orchestration
- Jido agents in Elixir support 1,000+ simultaneous instances on a Raspberry Pi due to a tiny 2mb heap footprint @mikehostetler.
- AgentCraft platform for agentic workflows debuted as a keynote at AI Engineer Europe @idosal1.
- Hermes Agent now features workspace integration via
hermes -w, often beating standard assistants @Teknium.
Models for Agents
- Codex 5.4 exhibits strange scaling, performing better on complex tasks than simpler ones @rileybrown.
- Gemini 3.2 Pro Preview Experimental has been spotted in active testing @willccbb.
- Muse Spark is now ranking 4th in the Text Arena, surpassing GPT-5.4 @scaling01.
Tool Use & DX
- A new open-source Power BI CLI allows agents to interact directly with business intelligence data @tom_doerr.
- VoxCPM2 open-sourced, enabling agentic voice cloning in 30 languages @heynavtoor.
- Unsloth released a free Colab notebook for fine-tuning Google Gemma 4 @akshay_pachaar.
Agentic Infrastructure
- TSMC revenue jumped 35% to record highs on the back of insatiable AI chip demand @CNBC.
- The Chutes project locked funds in smart contracts to ensure decentralized team funding on Bittensor @jon_durbin.
Reddit Reliability Log
From deterministic memory vaults to the 40% failure rate of multi-agent systems, reliability is the new frontier.
As the agentic web matures, we are seeing a hard pivot from 'vibes-based' development to rigorous engineering. Today’s top stories reflect this shift: the move from probabilistic vector search to deterministic causal graphs for long-term memory, and the aggressive optimization of tools like Claude Code via LSP hooks. We are witnessing a battle for reliability. While Meta's Muse Spark and new multimodal architectures like NEO-unify push the boundaries of raw capability, developers on the ground are grappling with the 'Agent Retry Storm'—a phenomenon where scaling autonomous loops threatens to overwhelm the very APIs they rely on.
The recurring theme is control. Whether it’s through 'Hot Experts' dynamic caching in local inference or the proposal for a browser-native WebMCP standard, practitioners are demanding more than just smart models; they need predictable infrastructure. As one developer noted, computation—not prediction—must be the bedrock of agentic memory. In this issue, we dive into how these deterministic constraints, structured persistence, and execution-first evaluation metrics are becoming the mandatory toolkit for moving agents from experimental demos into hardened production environments.
Causal Graphs Beat Vector Search for Long-Term Memory r/AI_Agents
Genesys, a newly open-sourced memory system, has set a new high-water mark for agentic persistence by scoring 89.9% on the LoCoMo benchmark, a 22-point lead over the previous leader, Mem0. As detailed by u/StudentSweet3601, the system replaces traditional vector-based RAG with a causal graph architecture. This structure allows agents to navigate memory through logical relationships rather than simple semantic similarity, effectively solving the 'rephrasing failure' where agents lose track of facts when a query doesn't perfectly match the original embedding.
This shift toward structured persistence is echoed by developers who argue that the probabilistic nature of LLMs makes them an inherently unstable foundation for long-term memory. According to u/Beneficial_Carry_530, memory should be treated as a 'deterministic vault' where computation—not prediction—handles the heavy lifting. By using causal nodes to enforce hard constraints, systems like Genesys move retrieval away from 'best-guess' inference and toward deterministic math, ensuring that an agent's world model remains consistent even across thousands of production steps.
LSP Hooks and Semantic Diffs Slash Token Usage r/AI_Agents
Developers are deploying 'LSP Hooks' to aggressively optimize Claude Code, reportedly slashing token usage by 80%. u/Ok-Motor-9812 demonstrated a method to force the tool to use Language Server Protocol instead of standard Grep, allowing the model to bypass irrelevant context lines that typically inflate the 'thinking' budget. This optimization is gaining traction as part of a move toward structured agentic workflows, complemented by 'Semantic Diffs' that improve attention scores by filtering out unchanged boilerplate in massive, self-generated codebases.
The 'Agent Retry Storm' and the 40% Failure Rate r/LangChain
The rise of 'Retry Storms' is highlighting the technical fragility of autonomous loops, contributing to a 40% failure rate for multi-agent AI projects. u/Accomplished-Sun4223 warns that a single workflow can trigger dozens of API calls that cascade into system failures when scaled to concurrent agents. To stabilize these systems, practitioners like u/Illustrious_Yak_9488 are advocating for 'deterministic extraction' and specialized wrappers to handle 429 errors without triggering a 'thundering herd' effect on rate-limited endpoints.
Dynamic Caching and 'ClawOS' Propel Local MoE Performance r/LocalLLaMA
A breakthrough dynamic caching system called 'Hot Experts' has integrated into llama.cpp, delivering a 27% speedup for hybrid CPU+GPU inference. According to u/TriWrite, this optimization prioritizes keeping the most active weights in VRAM, making massive models like Qwen3.5-122B more viable on consumer hardware. This is complemented by 'ClawOS,' which offers one-command deployment for local agents with 29 built-in automations and native voice interaction, targeting the 'private Jarvis' market.
WebMCP Standardizes Browser-Based Tooling r/mcp
The Model Context Protocol is evolving toward a browser-native standard with 'WebMCP,' a proposed W3C standard co-authored by Microsoft and Google. This shift replaces brittle screen-scraping with structured tool discovery via a navigator.modelContext API, allowing agents to interact with DOM elements through a standardized interface. As agents gain autonomy, the ecosystem is industrializing with tools like the 'Coyns' payment system for agent-to-agent commerce and specialized servers with 175 tools for enterprise operations.
Meta Unveils Muse Spark as NEO-unify Challenges Vision Orthodoxy r/learnmachinelearning
Meta's new 'Muse Spark' natively multimodal model reportedly reduces compute requirements by 10x while trailing slightly behind GPT-5.4, as researchers introduce NEO-unify to eliminate traditional Vision Encoders.
LongParser and 'Logic Gates': The New HITL Standard r/LangChain
u/UnluckyOpposition has open-sourced LongParser to enable human review steps in RAG pipelines, solving issues with scrambled document layouts through explicit LangGraph 'Logic Gate' interruptions.
BeamEval and the Execution-Metric Crisis r/LLMDevs
BeamEval has launched to provide adversarial testing for agentic prompts, as the community highlights a 20% false positive rate in Text-to-SQL benchmarks that fail to use execution-first validation.
Discord Dev Digest
OpenAI's "Operator" doubles Claude's performance in browser automation as the industry pivots toward visual grounding and standardized orchestration.
The transition from experimental agent wrappers to production-grade autonomous systems is happening faster than many anticipated. Today’s issue highlights a critical shift in the browser automation landscape, where OpenAI’s 'Operator' has effectively doubled the performance of previous state-of-the-art models on the OSWorld benchmark. This isn't merely a contest of numbers; it marks a departure from brittle DOM-parsing toward robust visual grounding.
Simultaneously, the industry is standardizing the plumbing that makes these agents useful. The Model Context Protocol (MCP) moving to the Linux Foundation is a 'USB moment' for AI, promising to slash integration overhead by up to 40%. When you combine this standardization with the democratization of reasoning via DeepSeek-R1 and the developer-first rigor of PydanticAI, the 'Agentic Web' starts to look less like a series of demos and more like a viable software architecture.
For practitioners, the message is clear: the focus is shifting toward reliability, type safety, and cyclic orchestration. Whether it’s managing persistent memory or handling human-in-the-loop interrupts, the tools are maturing to meet the messy realities of the real world. We are moving beyond simple prompts into the era of typed, reasoned, and standardized agentic execution.
OpenAI Operator Outpaces Claude in Browser-Native Task Execution
OpenAI’s "Operator" has fundamentally reset the performance ceiling for browser automation, achieving a 32.6% score on the OSWorld benchmark—more than double the 14.9% previously set by Anthropic’s Claude 3.5 Sonnet. While Claude’s "Computer Use" focuses on a generalized OS-level interface, Operator is purpose-built for browser-native tasks, with early access testers reporting 85% success rates on complex, multi-step travel bookings and research workflows.
The industry is now seeing a distinct bifurcation in agentic capabilities: Operator leads in web-based navigation and user experience, while Anthropic’s model maintains an edge in complex coding and software development tasks. This specialization is accelerating the adoption of frameworks like browser-use, which leverages vision-language models (VLMs) to interact with interfaces like a human. Despite these leaps, the "planning wall" remains a significant hurdle, as even top-tier agents currently score around 10.4% on broader computer-use benchmarks (CUB), still trailing human performance levels of 70-75%.
MCP Emerges as the 'REST for AI' Under Linux Foundation Governance
The Model Context Protocol (MCP) has transitioned to cross-industry governance under the Linux Foundation, emerging as a standardized 'USB port' that decouples tool implementation from model providers. Often described as the 'REST for AI,' MCP is already yielding significant efficiency gains, with enterprise developers reporting a 40% reduction in integration boilerplate code. The ecosystem is rapidly expanding with over 150 community-driven connectors for platforms like Slack and GitHub, while major frameworks like LangChain are introducing native adapters to treat MCP servers as standardized toolsets.
DeepSeek-R1 and the Democratization of Agentic Reasoning
DeepSeek-R1 has emerged as a formidable open-source alternative to OpenAI's o1, matching proprietary leaders with a 79.8% score on AIME 2024 and 97.3% on MATH-500. Its release has triggered an explosion in the ecosystem, with over 2.5 million downloads on Hugging Face, enabling developers to deploy 'thinking' models locally via Ollama and vLLM. This democratization allows for secure, low-latency multi-step planning, pivoting the industry toward Intelligent Router architectures where R1 serves as a high-efficiency engine for complex logical deduction.
PydanticAI Hardens Agent Logic with Type Safety
PydanticAI is rapidly becoming the standard for developers prioritizing production rigor by treating agents as typed Python functions to ensure tool outputs and model responses adhere to strict schemas. Practitioners are praising its dependency injection system, which simplifies unit testing and allows for seamless swapping of production and mock resources. While LangGraph remains the primary choice for complex, stateful multi-agent graphs, PydanticAI excels in high-performance 'agent-as-a-service' deployments, maintaining 100% type safety across diverse backends.
Beyond DAGs: The Era of Cyclic Multi-Agent Orchestration
The industry is moving toward cyclic graphs and persistent state management via frameworks like LangGraph to enable error correction and human-in-the-loop 'interrupts' in production.
The Battle for Agentic Memory: Mem0 vs. Zep AI
In the battle for agentic memory, Zep (utilizing Graphiti) achieved 63.8% retrieval accuracy on LongMemEval, outperforming Mem0's 49.0% while offering a more competitive price point for scaling teams.
HuggingFace Research Hub
Hugging Face is betting on 1,000 lines of Python to dismantle agentic bloat and crush the GAIA benchmark.
The pendulum of agentic architecture is swinging back toward minimalism. For the past year, developers have wrestled with the 'configuration bloat' of heavy frameworks and the fragility of JSON-based tool calling. Today, we are seeing a decisive pivot led by Hugging Face toward a 'code-as-action' paradigm. By allowing agents to write and execute Python directly, frameworks like smolagents are achieving SOTA results with a fraction of the complexity. This isn't just about cleaner code; it's about performance—shrinking the steps required for tasks by 30% and enabling 10x cost reductions in deep research.
However, as we race toward autonomous action, the industry is hitting a diagnostic wall. New research from IBM and UC Berkeley highlights a '20% success ceiling' in complex environments like Kubernetes, largely due to agents' inability to verify their own success. We are also seeing a fascinating divergence in model utility: the reasoning models we prize for 'solving' problems (like o1) are actually worse at 'sampling' or simulating human behavior than their predecessors. For builders, the message is clear: the future of the agentic web is lean, code-centric, and highly specialized, but our ability to verify autonomous outcomes remains the ultimate bottleneck.
Hugging Face Doubles Down on Code-First Agents and Open Deep Research
Hugging Face is pivoting toward code-centric agent architectures with the release of smolagents and Transformers Agents 2.0, prioritizing agents that write and execute Python code directly. This 'code-as-action' approach is significantly more robust than traditional JSON-based tool calling, enabling agents to achieve a 0.43 SOTA score on the GAIA benchmark Hugging Face. The smolagents library emphasizes extreme simplicity, comprising only ~1,000 lines of code, which drastically reduces debugging overhead compared to legacy frameworks and requires 30% fewer steps to complete tasks gitpicks.dev.
This shift extends into the search domain with the Open-source DeepResearch initiative. By leveraging the minimalist smolagents framework and the reasoning capabilities of DeepSeek-R1, this architecture achieves a 10x cost reduction compared to closed-source alternatives. The community has quickly adopted this stack, with implementations like MiroMind showcasing agents that synthesize complex information with 100% visibility into citations and reasoning loops.
To solve 'context bloat' in these long-horizon tasks, agents utilize a strategy where tool outputs are distilled into concise 'reflections' before the next reasoning step Tavily. The ecosystem is further expanding with native support for Vision-Language Models Hugging Face and integration with observability tools like Arize Phoenix Hugging Face, while specialized versions like Intel's DeepMath validate the framework's utility in complex reasoning Hugging Face.
High-Frequency Vision Models Bridge the GUI Latency Gap
The race for autonomous computer use is accelerating with the release of Holotron-12B, a specialized State Space Model (SSM) reaching a staggering 8.9k tokens/s. Developed by H Company, this high-throughput architecture addresses the latency bottlenecks found in earlier implementations, propelling performance on the WebVoyager benchmark to an 80% success rate, up from a 35% baseline. This system, paired with ScreenEnv for full-stack deployment, positions high-frequency visual feedback loops as a competitive alternative to reasoning-heavy models for real-time computer interaction.
The 'Solver-Sampler' Mismatch: Why Reasoning Models Struggle with Simulation
New research titled 'When Reasoning Models Hurt Behavioral Simulation' identifies a critical 'solver-sampler mismatch' where models like o1-preview fail to replicate human behavior. While these models are optimized for identifying mathematically optimal solutions, they struggle to model psychological nuances like reciprocity and social norms compared to 'sampler' models like GPT-4o huggingface. This research highlights a growing divergence in the agentic stack: one path optimized for autonomous task completion and another for accurate human behavioral simulation as tracked by benchmarks like OmniBehavior.
Diagnosing the 20% Success Ceiling in Enterprise AI
Diagnostic frameworks from ibm-research and UC Berkeley have exposed a stark 20% success ceiling for agents in complex IT environments. Using the Multi-Agent System Failure Taxonomy (MAST), researchers found that the strongest predictor of failure is Incorrect Verification, where agents declare victory without actually confirming the outcome ibm-research. To address this, the AssetOpsBench playground and ScreenSuite provide over 100 diagnostic tasks to stress-test UI interpretation and error-recovery logic.
MCP-Powered Agents: High-Performance Autonomy in Under 70 Lines
The Model Context Protocol (MCP) is enabling Tiny Agents that provide full autonomy in as few as 50 to 70 lines of Python huggingface, utilizing servers like Firecrawl Firecrawl and PatSnap for R&D PatSnap.
Specialized Agents Outperform Generalists in Medical and Crypto
The EHR Navigator powered by MedGemma maintains a 10-14% accuracy lead over GPT-4 in medical tasks google, while CrymadX-AI-Ext-32B offers native tool-calling for blockchain transactions.
Unified Tool Use and the Rise of JavaScript Agents
Hugging Face's Agents.js brings 'code-as-action' to the browser for privacy-focused, client-side applications Hugging Face, complemented by a Unified Tool Use standard across model providers.