The Era of Agent-Native Stacks
While infrastructure standardizes through MCP, practitioners face a reliability crisis as models hit a planning wall.
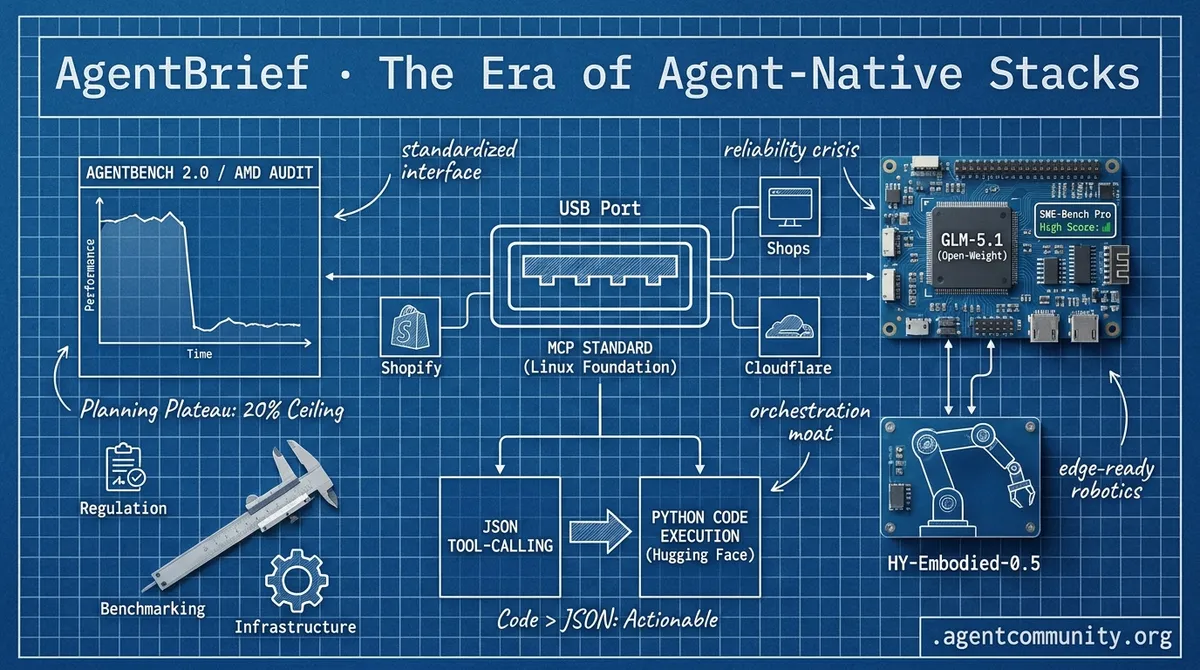
- Infrastructure Hits Standard The Model Context Protocol’s move to the Linux Foundation, backed by Shopify and Cloudflare, marks the industry’s transition from experimental tool-calling to a standardized "USB port" for agents.
- The Planning Plateau New benchmarks like AgentBench 2.0 and AMD’s audit of Claude Code show a 25% performance drop in complex scenarios, highlighting a "20% success ceiling" that infrastructure alone cannot fix.
- Code Over JSON Hugging Face’s pivot to Python-based execution in Transformers Agents 2.0 is outperforming traditional structured tool-calling, suggesting the future of agency lies in code-as-action.
- Open-Source Parity The gap between closed and open models is evaporating as GLM-5.1 surpasses frontier models on SWE-Bench Pro, moving the competitive moat toward orchestration and environment design.
X Pulse Feed
When open-source models start beating GPT-5 on SWE-bench, the agentic landscape changes forever.
We are entering the era of the 'agent-native' stack. It's no longer about just wrapping an LLM; it's about building systems where models are components of a larger, autonomous whole. This week, we see the shift in three dimensions: the models themselves are evolving for long-horizon tool use, infrastructure is maturing with tiered 'advisor' patterns, and major platforms like Shopify are finally handing the keys to the kingdom to coding agents. When a 754B parameter open-weight model like GLM-5.1 starts beating frontier closed models on SWE-Bench Pro, the 'closed-source moat' begins to look like a puddle. For builders, this means the bottleneck is moving from model capability to orchestration reliability. Whether you're running agents on a Raspberry Pi or orchestrating sub-agents through Anthropic’s new advisor pattern, the goal is the same: move from chat to execution. The agentic web isn't coming; it's being deployed to production right now. This is the moment to stop experimenting and start shipping autonomous systems that actually work.
GLM-5.1 Tops Open-Weight Agentic Benchmarks; HY-Embodied-0.5 Enables Edge Robotics
Z.ai's GLM-5.1, a 754B MoE open-weight model, has launched as the #1 open-source model and #3 globally on SWE-Bench Pro (58.4). This puts it ahead of GPT-5.4 (57.7) and Claude Opus 4.6 (57.3), marking a massive win for the open ecosystem @Zai_org. Optimized for long-horizon agentic tasks, it sustains 8-hour autonomous runs with over 6,000 tool calls, boosting Vector-DB-Bench to 21.5k QPS @Zai_org.
Early adopters are already seeing production gains. FactoryAI integrated GLM-5.1 into Droid for frontier MCP tool-use and sub-agent orchestration, reporting that it delivers these capabilities at half the cost of prior open-weights @FactoryAI. While @ValsAI confirms it is the current king of open weights, some users like @bridgebench noted slower speeds compared to more specialized rivals.
On the hardware front, Tencent's HY-Embodied-0.5 family is advancing embodied agents with a Mixture-of-Transformers (MoT) architecture trained on 100M+ samples @TencentHunyuan. The open-source 2B model outperforms Qwen3-VL 4B on 16/22 benchmarks (including an 89.2 CV-Bench), enabling edge robotics without cloud latency @HuggingPapers. @migtissera validates that GLM-5.1 is production-ready, aligning with the industry shift toward autonomous execution.
Tiered Model Routing Slashes Costs and Errors
Anthropic has formalized the emerging advisory pattern with its new 'advisor tool,' enabling cheaper executor models like Sonnet or Haiku to consult frontier-grade Opus mid-task @claudeai. By using the anthropic-beta: advisor-tool-2026-03-01 header, developers can have Opus provide strategic plans (usually 400-700 tokens) only when executors hit hard decisions @dotey.
The results for agent builders are significant: a Sonnet + Opus tiered setup scored 2.7pp higher on SWE-bench Multilingual while costing 11.9% less per task @claudeai. Even more impressive, a Haiku + Opus combo hit 41.2% on BrowseComp—a massive jump from Haiku's 19.7% solo performance—at an 85% lower cost than running Sonnet alone @akshay_pachaar.
Developers like @BioInfo report that they have been manually implementing these tiered patterns for months, and the API productization simplifies production workflows. To support this, @ibuildwith_ai built an open-source Claude Advisor Tool Playground for side-by-side testing of advisor vs. solo runs, providing clear token and cost breakdowns.
Shopify Grants Coding Agents Write Access
Shopify has launched its AI Toolkit, allowing coding agents like Claude Code, Cursor, and VS Code to directly access live store backends @Shopify. This MIT-licensed toolkit enables agents to manage products, orders, and SEO via CLI, effectively putting autonomous agents in charge of stores that manage $378B in GMV @aakashgupta. Skills are defined in SKILL.md files, which specify exact APIs and executions for transparency @ryoo_black.
However, the move comes with unverified safety gaps. There are currently no mentions of built-in guardrails like undo or draft modes, leading builders like @MaxCurnin and @ohioaninexile to warn of risks like hallucinated bulk pricing changes. Without confirmation layers, an agent could theoretically wipe out a merchant's margins in a single prompt.
Despite these risks, adoption is rapid as merchants use agents for live theme edits and Customer Lifetime Value calculations without third-party apps @rubenboonz. While @jerryjliu0 highlights this as a benchmark for agent automation, @burkov cautions that coding agents still falter on complex 'why' reasoning, necessitating human verification layers.
In Brief
MCP Resources Standardize Skill Delivery with load_resources Fallback
The Model Context Protocol (MCP) is standardizing how skills are served via a new resources-first approach. @RhysSullivan proposed using MCP resources for skills with a 'load_resources' tool fallback, a strategy endorsed by Anthropic's @dsp_ to avoid prompt semantics risks. Builders like @ibuildthecloud have praised the 'skills://' URI convention for injecting tool knowledge safely, while @ModernGrindTech confirmed these fallbacks are already bridging client compatibility gaps in the wild.
GPT-5.4 Pro 'Mythos' Excels in Deep Planning for Agent Supervisors
OpenAI's GPT-5.4 Pro, known internally as 'Mythos,' has topped next-gen models in real-world prediction markets with +1.22% returns. @iScienceLuvr reports that while earlier models suffered double-digit losses, Mythos excels at high-inference agent tasks. Despite its high 30/180 API cost and slow 5tk/s speed, builders like @Vtrivedy10 and @gkisokay position it as the ideal 'supervisor' for complex research and planning, even as it struggles on novel benchmarks like ARC-AGI-3 @alex_prompter.
AI Engineer Europe 2026: 'Software is for Agents Now'
The central theme of AI Engineer Europe 2026 in London focused on a paradigm shift where software design prioritizes machine consumption over human interfaces. Keynotes from @osanseviero and @dsp_ delved into 'agent-legible codebases' and visual multi-agent orchestration @sergiu_bodiu. Microsoft reported that over 160 developers engaged in sessions on MCP apps in VS Code @msdevUK, while attendees like @helloiamleonie described the technical, high-energy event as a 'Coachella' for European AI talent.
xAI Sues Colorado Over Pioneering AI Anti-Discrimination Law
xAI has filed a federal lawsuit to block Colorado's SB24-205, arguing the AI anti-discrimination law violates the First Amendment. The law mandates that developers document risks and provide appeal mechanisms for automated decisions in sectors like housing and employment @rohanpaul_ai. While xAI and @NetChoice claim the law compels ideological conformity and threatens U.S. AI leadership, Bloomberg notes the suit targets essential safeguards designed to prevent algorithmic harm in high-stakes decisions @business.
Quick Hits
Agent Frameworks & Orchestration
- Hermes Agent is reportedly outperforming standard coding agents in workspace environments @Teknium.
- A new 'Claude Ads' skill performs 190 audit checks across platforms using 6 parallel subagents @ihtesham2005.
- Jido agents in Elixir can run thousands of instances on a 4GB Raspberry Pi with only 2MB heap usage @mikehostetler.
Models for Agents
- Google Gemini 3.2 Pro Preview Experimental has been spotted in the wild by @willccbb.
- Muse Spark is now ranking 4th in the Text Arena, ahead of GPT-5.4 and Grok 4.2 @scaling01.
Agentic Infrastructure
- Anthropic's use of Trainium2 over Nvidia is a bet on memory bandwidth per dollar for RL workloads @aakashgupta.
- Railway may present issues for CLI-dependent agents like Hermes Agent due to terminal access limits @Teknium.
Tool Use & Skills
- VoxCPM2 has open-sourced a studio-quality voice cloning model supporting 30 languages for free @heynavtoor.
- Unsloth released a Colab notebook for free fine-tuning of Google Gemma 4 models @akshay_pachaar.
Reddit Field Reports
As Claude's performance metrics wobble, the Model Context Protocol is quietly becoming the enterprise gold standard for agentic reliability.
We’re witnessing a strange bifurcation in the agentic stack. On one hand, the "frontier" models we rely on are showing signs of strain. A massive AMD audit of Claude Code has turned anecdotal "vibes" about performance degradation into empirical data, suggesting that even the industry leaders aren't immune to regression. For developers building autonomous engineering tools, this isn't just a minor bug—it’s a threat to the stability of the entire workflow.
But while the models fluctuate, the infrastructure is hardening. The rapid industrialization of the Model Context Protocol (MCP) by heavyweights like Shopify and Cloudflare indicates that the industry is moving past the "experimental" phase. We’re no longer just asking agents to guess; we’re giving them the standardized keys to the kingdom. Between Tencent’s open-source world models and the 986% explosion in agentic job postings, the message for builders is clear: the model is a commodity, but the orchestration and the environment are where the real moat is being dug.
AMD Audit Confirms Claude Performance Slide r/PromptEngineering
A technical audit by a Senior Director at AMD’s AI group has provided empirical weight to user complaints, analyzing 6,852 Claude Code sessions and 234,760 tool calls to prove a measurable performance shift u/Exact_Pen_8973. The findings, centered around GitHub Issue #42796, highlight that the model is becoming 'unusable for complex engineering tasks' due to abandoned tasks and increased hallucinations. This data aligns with independent benchmarks on the BridgeBench hallucination test, where Claude Opus 4.6 accuracy plummeted from 83% to 68%, a 15% decline that has practitioners questioning the stability of autonomous workflows u/EvolvinAI29.
While Anthropic employees have publicly denied intentional 'nerfing' r/ClaudeAI, technical regressions are appearing elsewhere. A bug report (#44403) indicates the 1M context window recently degraded to 200k for some Max plan users following an April 13th outage GitHub Issue #47896. To combat this, Anthropic’s Thariq (@trq212) warns that 'context rot' now effectively begins between 300k and 400k tokens, requiring stricter session management u/shanraisshan. Relief may be imminent, however, as sightings of 'Opus 4.7' on Google Vertex suggest a mid-cycle refresh is being staged to address these stability gaps u/exordin26.
Shopify and Cloudflare Anchor the MCP Ecosystem r/mcp
The Model Context Protocol (MCP) is rapidly becoming the standard for connecting agents to enterprise data. Shopify has officially shipped its AI Toolkit, routing Claude Code and Gemini CLI through MCP to provide agents with real-time access to API schemas and Liquid validators u/Mental_Bug_3731. This move allows agents to perform schema validation and live documentation lookups rather than guessing GraphQL fields, addressing the 3x cost gap previously identified in unoptimized context management.
Simultaneously, Cloudflare has rebranded its Browser Rendering service to Browser Run, offering edge-hosted headless Chrome with full CDP access and a "Human-in-the-Loop" handoff feature u/cstocks. Cloudflare notes that this shift moves MCP from pilot projects into a "core part" of enterprise AI architecture Cloudflare Blog. The ecosystem is industrializing at scale, with the curated 'best-of-mcp-servers' repository now tracking 440 servers with a total of 930,000 GitHub stars tolkonepiu.
Tencent's HY-World 2.0 Challenges DeepMind r/LocalLLaMA
Tencent has officially launched HY-World 2.0, an open-source multimodal 3D world model that fundamentally differentiates itself from video-generation models like OpenAI's Sora. While Sora focuses on high-fidelity video synthesis, HY-World 2.0 generates 3D Gaussian Splats, meshes, and point clouds that are natively compatible with Unity and Unreal Engine u/bobeeeeeeeee8964. This structural approach allows developers to bypass the 'pixel-only' limitations of models like Google DeepMind's Genie 3, which relies on transformer-based frame-by-frame generation r/StableDiffusion.
The model is optimized for embodied AI, featuring built-in collision detection and first-person navigation. According to community reports on r/LocalLLaMA, HY-World 2.0 supports 'one-click' world generation from text or image prompts and is specifically engineered to run on consumer-grade GPUs. By providing physics-aware environments rather than ephemeral video clips, Tencent is positioning HY-World as foundational infrastructure for autonomous agents to move and learn within deterministic 3D spaces.
Creation OS Claims 87,000x Efficiency Leap r/LocalLLM
Spektre Labs has introduced Creation OS, a "cognitive architecture" designed to bypass the traditional GPU-heavy dependency chain by replacing standard softmax with XNOR binding and ternary weights. According to u/Defiant_Confection15, this shift enables a claimed 87,000x reduction in operations compared to traditional floating-point matrix multiplication. The system is targeting the SkyWater 130nm open-source silicon process and has been formally verified using SymbiYosys, specifically designed to "abstain" from generating answers when confidence is low.
This move toward radically efficient, GPU-less reasoning aligns with a growing "edge-first" movement in agentic infrastructure. While academic research into AIOS explores kernel-level resource management, practitioners are already repurposing consumer hardware. For instance, developers are successfully converting old Android phones into local voice assistants by running llama.cpp via Termux, as noted by u/octoo01. This bifurcation between massive enterprise clusters and specialized edge silicon is defining the next phase of agent deployment.
Agentic Job Postings Skyrocket 986% r/AgentsOfAI
The demand for agent-specific expertise is exploding, with job postings for 'Agentic AI' roles up 986% in a single year, even as 52,000 traditional tech roles were eliminated in the same period u/Such_Grace. This labor shift aligns with updated projections from Gartner, which now forecasts that 40% of enterprise applications will feature embedded AI agents by 2026 Gartner. The market for these autonomous systems is expected to reach $28 billion by 2026.
Real-world displacement is already accelerating; one regional insurance brokerage reported eliminating its night-shift claims coordinator role by deploying a managed agent on RunLobster u/Low_Road_563. However, the transition is fraught with 'governance scares.' Early adopters have documented cases where agents accessed sensitive data via chain-of-thought API calls—effectively 'thinking' their way around restrictions they weren't explicitly blocked from u/adriano26.
Beyond Vector Search: The Shift to Memory r/AI_Agents
New approaches to agent memory are aggressively moving away from fixed context windows and probabilistic vector retrieval. Polycode, a new coding CLI, uses a SHA-256 chained session log to record every tool call and correction permanently on the user's machine u/StudentEmpty3717. Instead of oldest messages 'falling off' the window, a specialized history compiler reads the full log and selects only relevant turns, effectively bypassing context limits while maintaining a verifiable audit trail.
Parallel to session chaining, systems like OpenViking are introducing a filesystem-based memory paradigm that organizes context through hierarchical structures MarkTechPost. Meanwhile, local-first layers like screenpipe are automating context capture by recording OCR and audio 24/7 u/louis3195. These developments align with Andrej Karpathy's 'LLM Wiki' thesis, suggesting the ultimate enterprise moat is a proprietary, structured knowledge base built through human-agent interaction u/No_Review5142.
Discord Engineering Sync
Anthropic’s MCP goes mainstream while new benchmarks reveal the limits of autonomous reasoning.
We are moving past the 'vibe check' era of agent development. Today’s landscape is defined by two opposing forces: the rapid standardization of how agents talk to tools, and the sobering reality of how those agents fail when the environment gets messy. Anthropic’s Model Context Protocol (MCP) transitioning to the Linux Foundation is the 'USB port' moment we've been waiting for, theoretically solving the n+1 integration nightmare. But as our connectivity matures, our logic is being tested. The release of AgentBench 2.0 shows a 'planning wall' where even top-tier models like GPT-4o and Claude 3.5 Sonnet see a 25% performance drop when faced with adversarial tool scenarios. Meanwhile, the developer experience is hardening. PydanticAI is challenging LangGraph’s dominance by betting on Pythonic type-safety over complex state machines, a move that signals a shift toward 'agent-as-a-service' deployments where stability is king. We’re finally building the infrastructure for the Agentic Web, but the 'intelligence' part of the equation remains a moving target for practitioners and researchers alike.
Anthropic’s Model Context Protocol Scales to Thousands of Community Connectors
Anthropic's Model Context Protocol (MCP), launched in November 2024, has rapidly transitioned from a proprietary experiment to a cross-industry standard governed by the Linux Foundation. Often described as the "USB port" for the Agentic Web, MCP provides a universal client-server architecture that decouples reasoning models from data retrieval, effectively solving the "n+1" integration problem. Developers are reporting a 40% reduction in integration boilerplate code, allowing for more efficient "Code Mode" executions as validated by partners like Cloudflare.
The ecosystem has expanded from early community discussions in mcp-discussion to a robust registry of over 150 official connectors and thousands of community-built servers for essential tools like PostgreSQL, Slack, and GitHub. By standardizing how agents discover and interact with external resources through a unified SDK available in all major languages, MCP is enabling the transition from experimental demos to production-grade autonomous systems.
Join the discussion: discord.gg/anthropic
PydanticAI Hardens Agent Logic with Type-Safe Orchestration
PydanticAI is rapidly emerging as the preferred framework for developers prioritizing production rigor, treating agents as high-level constructs defined by strict data schemas and Python functions. By leveraging native Python type hints, it ensures tool outputs and model responses adhere to predictable structures, which users in the #frameworks channel claim reduces runtime errors in complex loops. This Pythonic simplicity offers a 15% improvement in velocity for teams already utilizing FastAPI or SQLModel, marking a move toward 'agent-as-a-service' deployments where type safety is non-negotiable.
Join the discussion: discord.gg/pydantic
LangGraph Hardens Long-Term Memory with Multi-Tiered Persistence
LangGraph has refined its state management architecture by formalizing the distinction between short-term episodic memory and long-term semantic memory via the BaseStore interface. This allows agents to persist profiles and procedural instructions across threads, supporting the 50MB state objects reported in initial benchmarks. However, community feedback from langchain-dev highlights a growing need for efficient garbage collection to prevent production stores from accumulating and impacting retrieval latency as agents age.
Join the discussion: discord.gg/langchain
Browser-Use and Stagehand Redefine AI-Driven Web Navigation
The browser-use library and Stagehand are redefining AI-driven web navigation, with agents achieving an 85% success rate in complex checkout flows while Stagehand introduces surgical AI primitives.
Join the discussion: discord.gg/browser-use
Small Models Reach Parity in Edge-Based Tool Calling
Small models like Llama 3.2 3B are reaching tool-calling parity with 8B models, enabling hierarchical architectures that can reduce inference costs by over 90% through specialized edge-based execution.
Join the discussion: discord.gg/localllama
AgentBench 2.0: Adversarial Testing Exposes the 'Planning Wall'
AgentBench 2.0 has exposed a 'planning wall' in autonomous systems, with data showing a 25% performance degradation when agents are faced with adversarial tool scenarios or shifting ground truths.
Join the discussion: discord.gg/galileo
HuggingFace Lab Notes
Hugging Face pivots to code execution while research exposes the reliability gaps holding back enterprise agents.
Today’s agentic landscape is defined by two opposing forces: the technical liberation of 'code-as-action' and the sobering reality of the '20% success ceiling' in enterprise environments. Hugging Face has thrown down a significant gauntlet with Transformers Agents 2.0 and the smolagents library. By moving away from the brittle 'JSON fatigue' of traditional tool-calling in favor of direct Python execution, they’ve achieved SOTA results on the GAIA benchmark. This shift suggests that for agents to be truly effective, they need the flexibility of a programming language, not just a structured data format.
However, better frameworks don't automatically solve the reliability crisis. New research into complex IT environments like Kubernetes shows that even our best models are hitting a hard wall, failing roughly 76% of tasks due to poor verification and premature abandonment. While we are seeing incredible progress in 'Edge Reasoning'—with 1B-parameter models performing like giants—the industry's next major hurdle isn't just about how an agent thinks, but how it confirms its own success. From specialized healthcare navigators to open-source deep research tools that slash costs by 10x, the path forward is becoming clear: minimize the code, maximize the reasoning, and never trust an agent that says it's 'done' without proof.
Hugging Face Overhauls Ecosystem with 'Code-as-Action' Paradigm
Hugging Face has overhauled its agentic ecosystem with the release of Transformers Agents 2.0 and the smolagents library, marking a definitive shift from brittle JSON tool-calling to a 'code-as-action' paradigm. This transition is a primary performance driver; the Transformers Code Agent secured a 0.43 SOTA score on the GAIA benchmark, significantly outperforming complex multi-agent architectures like Autogen by writing and executing Python code directly Hugging Face. The new modular engine allows for more flexible interaction across diverse environments, effectively reducing the 'JSON fatigue' that often limits autonomous reasoning Hugging Face.
The smolagents library emphasizes extreme minimalism, allowing developers to build powerful agents in as few as 100 lines of code while maintaining a core library of only ~1,000 lines Hugging Face. To ensure production safety, the framework utilizes sandboxed code execution, preventing agents from performing unauthorized system actions AIONDA. This ecosystem now extends to visual reasoning with native Vision-Language Model (VLM) support and client-side autonomy via Agents.js Hugging Face.
While competitors focus on complex multi-agent collaboration, smolagents prioritizes a streamlined, single-agent loop for maximum reliability Ken Huang. By prioritizing code-centric logic directly in the browser or via lightweight Python scripts, the framework offers a path away from the overhead of supervisor-led delegation models.
Diagnosing the 20% Success Ceiling in Enterprise Agents
New research from IBM and UC Berkeley has exposed a 20% success ceiling for agents in complex IT environments, identifying 'Incorrect Verification' as the primary predictor of failure. The Multi-Agent System Failure Taxonomy (MAST) reveals that 31.2% of failures are due to premature task abandonment, with frontier models like Gemini-3-Flash averaging 2.6 failure modes per trace byteiota. This reliability gap is critical as Gartner predicts that while 40% of enterprise apps will embed agents by 2026, many projects remain at risk of cancellation due to these persistent logic gaps ucb-mast.
Open-Source Deep Research Challenges Proprietary Silos
The open-source community is dismantling the walls around 'Deep Research' agents, leveraging the smolagents framework to achieve a 10x cost reduction compared to closed-source tools. These implementations, such as those from huggingface and MiroMind, provide 100% visibility into citations and reasoning loops. By utilizing a distillation strategy where tool outputs are condensed into 'reflections,' these agents handle long-context synthesis without the bloat typical of long-horizon tasks Tavily.
Hybrid SSMs and Action VLMs: The New Architecture of Desktop Automation
The race for computer-using agents is accelerating with the release of ScreenEnv and the Holo1 VLM family, which deliver a 10%+ accuracy boost in UI element grounding. H Company utilizes a Hybrid SSM architecture for high-throughput inference, while Hugging Face provides full-stack environments for navigating real-world software. These tools aim to lower the barrier for building agents that can interact with the 90% of software that lacks a formal API.
Edge-Capable Reasoning: Apriel-H1 and Distilled 1B Models
ServiceNow-AI's Apriel-H1 brings SOTA-level reasoning to models as small as 0.8B parameters, enabling complex multi-step planning on edge hardware ServiceNow-AI.
Vertical Agents: From FHIR-Ready Healthcare to Solar Sustainability
Specialized agents like Google's EHR Navigator and SolarHive are moving beyond general tool-calling into complex, schema-aware reasoning for HIPAA-compliant and energy-specific tasks google/ehr-navigator-agent-with-medgemma.
MCP and the Rise of Interoperability Standards
The Model Context Protocol (MCP) is emerging as a superior standard for agent-to-database communication, with Composio now supporting over 100 MCP servers Adrian Bridgwater.