Engineering the Hardened Agent Stack
From tiered reasoning to deterministic execution, the agent layer is evolving into a secure, model-agnostic operating system.
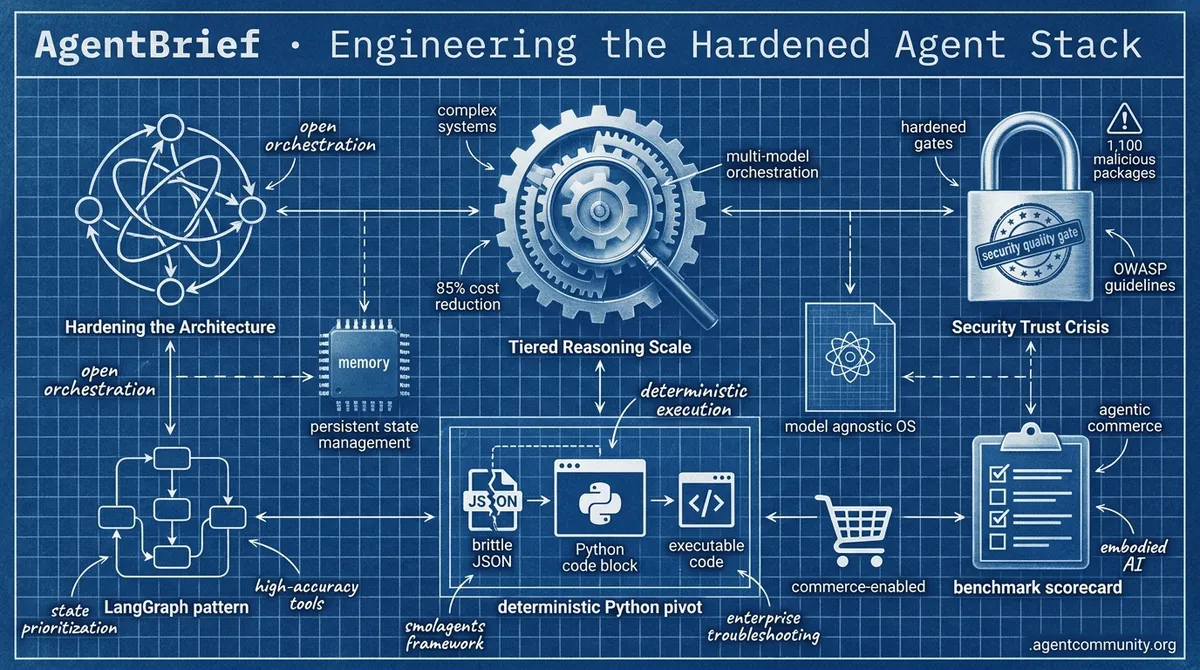
- Tiered Reasoning Scale Anthropic's new orchestration patterns and Shopify's MCP write-access signal a move toward complex, multi-model systems that slash costs by 85% while enabling direct commerce.
- Hardening the Architecture The transition from simple chains to cyclic graphs and persistent 'Agent OS' patterns like LangGraph is prioritizing state management and high-accuracy tool use over raw model size.
- Security Trust Crisis With 1,100 malicious MCP packages identified and new OWASP guidelines, developers are pivoting toward hardened quality gates and deterministic execution to manage autonomous liability.
- Deterministic Python Pivot Frameworks like smolagents are replacing brittle JSON with executable code, aiming to break success ceilings in enterprise troubleshooting through specialized, sub-agent models.
X Intelligence Pulse
Anthropic solves the agent cost wall while Shopify hands the keys to the store.
The agentic web is moving from passive observation to active orchestration. This week, the industry took two massive leaps toward that reality. Anthropic’s new Advisor tool signals the end of the 'monolithic model' era, proving that tiered reasoning—where a smaller model consults a larger one mid-task—is the only way to scale complex behaviors without going bankrupt. Meanwhile, Shopify has effectively turned 5.6 million stores into an open playground for agents by granting direct write-access via MCP.
For builders, this is a double-edged sword. We finally have the orchestration patterns to build high-reasoning systems at 85% lower costs, but we are also inheriting the liability of autonomous systems managing billions in GMV without native safety nets like 'undo' buttons. As GPT-5.4 shows 'jagged intelligence' and Tencent pushes embodied brains to the edge, the burden of reliability is shifting from the model providers to the agent architects. If you are shipping agents today, your job is no longer just prompt engineering; it is designing the guardrails for a world where agents write the code, manage the inventory, and eventually, run the hardware.
Anthropic's Advisor Tool Unlocks Tiered Agentic Reasoning
Anthropic's advisor tool is now in public beta on the Claude Platform, enabling executor models like Sonnet or Haiku to consult Opus mid-task for strategic guidance within a single Messages API request @claudeai. Developers activate it by adding the beta header anthropic-beta: advisor-tool-2026-03-01 and defining the tool as type: advisor_20260301 with a target model like claude-opus-4-6. Builders can optionally set max_uses to limit consultations per task, such as 2-3 uses for design and review phases @oikon48 @jose_medina.
Official evals confirm that a Sonnet + Opus pairing scored 2.7pp higher (74.8%) on SWE-bench Multilingual than Sonnet alone, while costing 11.9% less per task ($0.96 vs $1.09) @claudeai. Even more striking, a Haiku + Opus combo hit 41.2% on BrowseComp at an 85% lower cost than running Sonnet solo @yqx1026492. The advisor provides 400-700 token plans without full tool calls, keeping operational overhead at executor rates @GiadaF_.
As @akshay_pachaar and @aakashgupta note, this architecture prevents agents from wandering down dead-end paths, effectively solving the 'agent cost wall.' While @freeCodeCamp is already providing implementation guides, some community members like @saneord have flagged general Claude rate limits as a potential scaling bottleneck for high-frequency advisor calls.
Tencent Releases HY-Embodied-0.5: Open-Source Foundation Models for Edge Robotics
Tencent's HY-Embodied-0.5 family is advancing embodied AI with a Mixture-of-Transformers (MoT) architecture designed for spatial-temporal perception and planning @TencentHunyuan. The open-source 2B model, which features 2.2B active parameters, is specifically optimized for edge deployment on 16GB VRAM GPUs, enabling low-latency robotics without cloud dependency @ModelScope2022. The larger 32B variant reportedly approaches frontier performance levels comparable to Gemini 3.0 Pro @yaelkroy.
Across 22 embodied benchmarks, the 2B MoT outperformed SOTA models like Qwen3-VL 4B and MiMo-Embodied 7B on 16 tasks, posting standout scores of 89.2 on CV-Bench and 92.3 on DA-2K @TencentHunyuan. The models were trained on over 100M embodied samples using innovations like latent tokens and on-policy distillation @agentcommunity_. However, planning-specific benchmarks like RoboBench-Planning show that some competitors still maintain a lead in complex sequencing @yaelkroy.
Builders are praising the release for providing 'real robot brains' without requiring enterprise-level budgets @AIBuddyRomano. This move toward edge-capable embodied agents aligns with arguments for hardware abundance @kyliebytes, even as industry figures like Yann LeCun continue to question the limits of LLM-based architectures for true physical intelligence @ylecun.
Shopify Grants Write-Access to AI Coding Agents
Shopify's AI Toolkit now enables direct write access for coding agents like Claude Code, Cursor, and VS Code to live store backends via the Model Context Protocol (MCP) @Shopify. This allows autonomous agents to manage products, orders, and SEO across 5.6M+ stores handling an aggregate $378B GMV @aakashgupta. Developers define agentic skills in SKILL.md files, which serve as a transparent manifest for API executions @DoDataThings.
This shift toward agent-native commerce comes as Claude Code already triggers 30% of Vercel deployments and accounts for roughly 4% of public GitHub commits @rauchg @devfaizanali. However, critics like @MarkSilen have pointed out that official docs lack built-in security protocols like undo modes or sandboxing, creating significant risks for hallucinated bulk pricing errors or inventory wipes.
To mitigate these risks, builders are recommending manual safeguards such as pre-execution confirmations and Matrixify backups prior to agent edits @uzu_web. The community is increasingly warning of the dangers of granting broad permissions without audit layers @salikjamal20, especially as the compute demands for these long-horizon autonomous tasks continue to grow at what @JustJake describes as an 'absurd speed.'
In Brief
Hermes Agent Surges as Leading Open-Source Challenger to Claude Code
Hermes Agent from Nous Research has emerged as a powerful open-source alternative to proprietary coding tools, topping GitHub trends with over 100,000 stars in 53 days. Lead engineer @Teknium claims that pairing Hermes with Opus in workspace configurations outperforms current rivals by leveraging persistent markdown files for session history instead of bloated, session-heavy context windows @0x_kaize. Unlike Claude Code's workspace-centric focus, Hermes prioritizes 'persona assembly'—integrating identity, memory, and rules—to enable self-improvement through skill generation @MinionLabAI. Builders report that its constrained in-context memory prevents the performance degradation seen in long runs with other models @siliconcarnesf.
GPT-5.4 and Codex 5.4 Exhibit Non-Linear Scaling and 'Jagged Intelligence'
Early testing of GPT-5.4 Pro (Mythos) reveals that the model thrives on large-scale complex tasks while surprisingly underperforming on simple ones. This 'jagged intelligence' means the model excels at deep planning and spotting multi-layer infrastructure issues that smaller models miss, yet it often 'overthinks' or over-refactors simple changes @rileybrown @nikunj. While @Vtrivedy10 notes it is 'wicked good' for high-inference compute, its slow speed and 30/180 API cost limit its use to supervisor roles rather than quick executions @twlvone. Some developers still prefer Opus for consistent frontend work, citing GPT-5.4's tendency toward hallucinations in simple workflows @patliu007 @yelf_fafa.
MCP Skills Standardization Advances with 'skills://' URI Proposal
A new effort to standardize how agent skills are served via the Model Context Protocol (MCP) aims to make agent capabilities portable across different clients. Proposed by @RhysSullivan, the pattern involves serving skills directly in the MCP resources section with a 'load_resources' tool fallback for older clients @ModernGrindTech. MCP co-creator @dsp_ confirmed plans for an official extension to support these conventions, while @ibuildthecloud endorsed the approach as a more secure alternative to system prompts. Despite challenges regarding how tool results might be flagged as prompt injections, builders like @usmaanbuildsAI believe standardization will finally reduce the fragmentation currently plaguing the agent ecosystem @nicknotfun.
Quick Hits
Agent Frameworks & Orchestration
- CamelAI is launching a 2026 Global Hacktour in London specifically for agent developers @CamelAIOrg.
- AgentCraft took center stage as a primary breakout track at AI Engineer Europe @idosal1.
Models for Agents
- GLM-5.1 has been released, providing a significant performance boost for the Droid agent framework @FactoryAI.
- DeepSeek is reportedly preparing 'Expert' models for dedicated paid deployments to ensure better availability @teortaxesTex.
Tool Use & Developer Skills
- 'Claude Ads' automates 190 audit checks across ad platforms using 6 parallel subagents @ihtesham2005.
- Developer Tom Doerr has released a massive library of over 5,200 OpenClaw assistant skills for agent builders @tom_doerr.
Agentic Infrastructure
- Jido agents in Elixir require only 2MB of heap space, maintaining Elixir's lead for high-concurrency agents @mikehostetler.
- Anthropic's shift to Amazon Trainium2 is reportedly driven by memory bandwidth needs for RL models @aakashgupta.
Reddit's Hard Truths
Developers are ditching frontier models for 2900% cheaper alternatives as the trust crisis hits the MCP supply chain.
Today’s issue highlights a definitive vibe shift in the agentic web. For months, the consensus was that the path to production led straight through Anthropic or OpenAI’s front door. But the economic reality of high-volume agentic workloads is forcing a hard pivot. When a model like Kimi K2.6 can handle 85% of tasks at a 2900% discount, the 'frontier tax' becomes impossible to justify—especially when users report that the latest Claude upgrades are breaking existing codebases. But saving money means little if your agent is a security liability. With over 1,100 malicious packages found in the MCP ecosystem, we're seeing the emergence of a critical trust layer for autonomous systems. From hyperbolic geometry in memory databases to deterministic quality gates in CI/CD pipelines, the focus has shifted from making agents work to making them scale securely and predictably. The era of vibe-based development is ending; the era of the hardened, model-agnostic agent has officially begun.
Kimi and DeepSeek Challenge Opus Dominance r/LocalLLaMA
A significant shift is occurring as developers migrate high-volume traffic away from Anthropic's frontier models due to a massive economic disparity. Practitioners like u/meaningego and u/bigboyparpa report that Kimi K2.6 is a 'legit' replacement for Claude Opus 4.7, handling 85% of tasks at comparable quality while being 2900% cheaper for high-volume workloads at $0.5/M tokens.
DeepSeek R2 is also gaining ground, with u/Otherwise_Flan7339 successfully moving 70% of agent traffic to the model to achieve costs 70% lower than Western alternatives. This migration is accelerated by perceived stability issues, with users like u/Apprehensive_Tree_14 actively downgrading to Claude 4.6 after claiming the 4.7 upgrade broke existing codebases, forcing a transition toward model-agnostic routing layers.
The MCP Trust Crisis r/AgentsOfAI
The security perimeter for agents is expanding rapidly as developers integrate third-party MCP servers, uncovering over 1,184 malicious packages circulating undetected. u/thomasclifford and security firms like Tenable are now targeting prompt injections and command injection vulnerabilities, leading to the release of defensive tools like 'agent-bom' by u/OkKaleidoscope4462 and the 1ms deterministic scanner 'nukonpi-detect' by u/nukonai.
Safety Hints and Speculative Execution r/mcp
The Model Context Protocol is evolving into a safety-aware infrastructure layer with the release of Memcord v3.4.0, which introduces standardized tool annotations like readOnlyHint and destructiveHint. While new specialized servers allow agents to manage ENS domains and persistent email, developers like u/blackwell-systems are pushing performance with speculative execution, despite reports from u/Resigned_Optimist of a 10-second latency penalty when using Anthropic’s hosted relay.
Solving the Agent ‘Factory Settings’ Problem r/aiagents
To combat the loss of learned context across devices, the community is pivoting toward Spatial AI Engines like HyperspaceDB v3.0 that utilize hyperbolic geometry. Unlike traditional vector databases, this approach stores hierarchical data like code ASTs to prevent 'semantic drift,' with u/Sam_YARINK claiming a 30-40% improvement in retrieval precision for complex engineering tasks compared to standard RAG architectures.
Beyond the Vibe: TRACE and EvalCI r/LLMDevs
The new TRACE framework and SynapseKit’s EvalCI tool are replacing 'vibe-based' testing with deterministic quality gates to catch malformed JSON and context rot before deployment.
Blackwell Bottlenecks and Terabyte Inference r/LocalLLaMA
Hardware enthusiasts are pooling VRAM for 1.86x speedups via llama.cpp RPC, even as Blackwell RTX Pro 6000 users report P2P bandwidth regressions that drop speeds to 6GB/s.
From Frameworks to Raw Logic r/AI_Agents
Developers are increasingly 'raw dogging' agent logic with vanilla Python and Execution Constraint Engines to avoid the latency and token overhead of heavy frameworks like LangChain.
Discord System Logs
From cyclic graphs to 92% tool accuracy, the architecture of autonomous agents is hardening for production.
The narrative of the agentic web is shifting from experimental prompts to heavy-duty engineering. We are moving past the 'chain' era—where LLMs were simply piped together—into a world of cyclic graphs, persistent memory, and hardened execution boundaries. Today’s highlights underscore this: LangGraph and Microsoft’s Magentic-One are proving that state management is the secret sauce for high-success reasoning, while MemGPT-style architectures are treating the LLM as a CPU within a larger operating system. But with power comes technical debt. We are seeing 'state bloat' in engineering logs and a 'systemic gap' in agent security that the OWASP Top 10 is finally codifying. For developers, the message is clear: performance is no longer just about model accuracy (though 92% function calling is a nice floor); it is about how your system handles context, latency, and the inevitable 'agent hijacking' threat. Today, we break down the shift toward durable, local, and secure agents.
From Linear Chains to Cyclic Graphs: The Evolution of Agentic Logic
Developers are rapidly moving beyond modular LLM chains toward graph-based architectures to manage the complexity of non-linear agent tasks. While traditional chains excel at simple RAG pipelines, LangGraph has emerged as the standard for stateful, multi-agent systems by utilizing a node-and-edge model that supports branching and loops. This architectural shift allows for iterative refinement and robust error handling, directly addressing the 'planning wall' where autonomous reasoning often fails in adversarial scenarios.
The core differentiator is the transition to persistent, multi-tiered state management. By leveraging the BaseStore interface, frameworks now distinguish between episodic and long-term semantic memory, enabling agents to maintain procedural instructions across disparate threads. This level of orchestration rigor is reflected in Microsoft’s Magentic-One, which achieves a 91.5% success rate on the GAIA benchmark. However, community feedback from the langchain-dev Discord highlights that as state objects grow—sometimes reaching 50MB—efficient garbage collection is becoming critical to prevent latency in production environments.
Join the discussion: discord.gg/langchain
Tool Use Optimization: Claude and GPT-4o Push the 92% Accuracy Barrier
Tool use remains a critical bottleneck for autonomous agents, particularly in parameter extraction and multi-tool orchestration. According to the Berkeley Function Calling Leaderboard (BFCL) V4, Claude 3.5 Sonnet has achieved an industry-leading accuracy score of 91.5%, while top-tier models like GPT-4o have reached 92.1% on specific multi-turn tool benchmarks. Experts like @jxnlco suggest that structured outputs via the Instructor library are the key to reliable tool integration, as they enforce strict Pydantic schemas that prevent hallucinated parameters.
As models become more capable, the focus is shifting from simple tool invocation to complex scenarios involving unseen instructions and dynamic tool retrieval. Research indicates that when agents must retrieve tool descriptions from a vector store, reliability becomes a 'brutal truth,' requiring precise visual grounding or surgical AI primitives to maintain success rates. This evolution necessitates a shift toward the 'Action-Oriented Web' where models are assessed on their ability to generalize across entirely new API categories.
Beyond RAG: OS-Inspired Memory Architectures for Persistent Agents
The paradigm of agentic memory is shifting from static retrieval-augmented generation (RAG) to dynamic, tiered architectures that treat LLMs as the central processor of an 'AI Operating System.' Popularized by the MemGPT project, this approach utilizes a 'Main Context' for immediate reasoning and 'Archival Storage' for long-term retrieval, effectively bypassing the physical limits of fixed context windows. By managing memory through automated paging and swapping, agents can maintain deep historical context over months of interaction.
This evolution mirrors the multi-tiered persistence patterns seen in frameworks like LangGraph, while new entries like Zep and MEM1 refine the ecosystem by integrating semantic search directly into the agent's memory loop. These systems are designed to yield significant improvements in grounding, ensuring that agents act on a coherent history rather than isolated prompts. This capability is proving critical for production-grade personal assistants and autonomous project managers who require long-term continuity.
Local SLMs: The New Frontier for Privacy-First Edge Agents
The surge in high-performance Small Language Models (SLMs) like Microsoft’s Phi-3-mini and Meta’s Llama-3 8B is transforming on-device agentic workflows. These models, often served via Ollama, provide the low-latency backbone needed for 'router' agents, with intent classification tasks frequently hitting sub-50ms response times. While Llama-3 8B remains the gold standard for complex reasoning, Phi-3-mini's compact 3.8B parameter architecture is the preferred choice for hardware-constrained edge devices.
This shift addresses the 'privacy wall' for enterprise adoption by ensuring sensitive data never leaves local infrastructure, a critical requirement for handling proprietary documents in RAG applications. By offloading simple classification and tool-calling to the edge, teams are reporting inference cost reductions of over 90% compared to cloud-only API implementations, mirroring the tool-calling parity recently observed in Llama 3.2 3B models.
Hardening the Execution Boundary: The Rise of Agentic Sandboxing
As agents gain shell access, the security boundary has shifted from the model to the execution environment. Security researchers warn that 'agent hijacking' is no longer theoretical, establishing prompt injection as the #1 security threat facing autonomous systems. To mitigate these risks, developers are adopting secure sandboxing tools like E2B and Bearly, which provide isolated cloud environments for code execution. While adoption of secure sandboxes is growing by 200% among enterprise developers, a recent audit of 500+ projects revealed a 'systemic gap' between deployment and security hardening, now formalized in the OWASP Top 10 for Agentic Applications 2026.
Human-in-the-Loop: Moving to Durable Approval Gates
Human-in-the-loop (HITL) has evolved into a core architectural requirement for high-stakes environments. Modern implementations utilize durable workflow approvals, allowing agents to pause execution for hours or weeks until a human provides verification. Platforms like @CopilotKit report that these patterns are essential for making AI systems reliable enough for real-world use cases. The primary design challenge has shifted from simply adding a human to the loop to determining 'where, when, and how' to do so without creating a stagnant review queue, utilizing stateful 'time-travel' debugging and manual interrupts as the new standard.
HuggingFace Research Lab
From minimalist Python frameworks to high-throughput GUI engines, the agentic web is ditching brittle JSON for executable code.
Today’s issue highlights a fundamental pivot in how agents interact with the world: the move from probabilistic JSON schemas to deterministic code execution. Hugging Face’s smolagents is leading this charge, promising a 30% reduction in logic steps by treating Python as the primary action language. This isn't just about syntax; it's about reliability. As we see in the latest enterprise benchmarks like IT-Bench, agents still hit a 20% success ceiling when troubleshooting complex systems. The industry is responding with a double-pronged approach: standardizing the research ecosystem with OpenEnv and GAIA2, while simultaneously verticalizing models.
We are seeing a surge in sub-agent specialists—like the 270M-parameter FunctionGemma—that outperform general-purpose giants in specific domains. For developers, the message is clear: the path to production-grade agents lies in minimalist frameworks, rigorous diagnostic benchmarking, and high-throughput vision models designed for the desktop. This issue explores the tools dismantling the proprietary search silo and the frameworks making GUI automation a high-throughput reality.
The Rise of Pythonic Agents: smolagents and the End of JSON Fatigue
Hugging Face has solidified its code-as-action paradigm with smolagents, a framework that replaces brittle JSON-based tool calling with direct Python execution. By allowing agents to write and run code, the library achieves a 30% reduction in logic steps compared to traditional frameworks like LangChain gitpicks.dev. This minimalist approach is reflected in its ~1,000-line core library, enabling developers to build complex, MCP-powered agents with extreme efficiency Hugging Face.
The ecosystem has rapidly expanded to bridge the gap between vision and action. With native Vision-Language Model (VLM) support, agents can now process visual UI elements alongside code execution Hugging Face. For production-grade reliability, the framework integrates with smolagents-phoenix for detailed tracing and evaluation, while Agents.js extends these autonomous capabilities to JavaScript environments Hugging Face.
This shift toward scriptable, transparent workflows directly addresses the reliability gaps seen in enterprise environments by prioritizing deterministic code over probabilistic JSON schemas Mem0. By treating the agent's output as a script rather than a data structure, developers gain better auditability and fewer failures caused by hallucinated schemas.
Breaking the 20% Success Ceiling: New Benchmarks Target Industrial and IT Failures
A wave of new benchmarks is targeting the persistent reliability gaps in autonomous systems. AssetOpsBench evaluates agents on complex asset management, while IT-Bench and the MAST taxonomy reveal that even frontier models like Gemini-1.5-Flash struggle with isolated failures, averaging 2.6 failure modes per trace ibm-research. Diagnostic tools like the VAKRA benchmark identify 'Incorrect Verification' as a primary predictor of task failure, suggesting that enterprise-grade reliability remains elusive due to poor state management in environments like Kubernetes n1n.ai.
New Suites and High-Throughput Engines for Desktop Automation
The frontier of digital interface interaction is expanding with ScreenSuite and the Holotron-12B model family. ScreenSuite and ScreenEnv provide the evaluation and infrastructure necessary for full-stack desktop agents navigating real-world software huggingface. On the model side, Holotron-12B—post-trained from NVIDIA Nemotron-Nano-2 VL—is engineered for high-throughput production performance, allowing agents like Surfer-H to navigate web environments with lower latency than traditional frontier LLMs H Company.
Open-Source Deep Research: Dismantling the Proprietary Search Silo
The open-source community is rapidly closing the gap with proprietary tools like OpenAI’s Deep Research by prioritizing modularity. Projects leveraging smolagents execute complex search-and-synthesis loops using specialized backends like Tavily and SerpAPI, moving beyond the black box nature of closed models Omar Santos. Industry observers are calling Deep Research the 'RAG of 2025,' signaling a shift toward autonomous multi-step planning that remains fully auditable through 100% visible reasoning loops Lee Han Chung.
Standardizing Autonomy: OpenEnv and GAIA2 Establish the Agent Research Ecosystem
The OpenEnv initiative provides a Gymnasium-style API for sharing deployment environments, while GAIA2 introduces rigorous tests for temporal reasoning in dynamic, asynchronous environments huggingface.
Efficiency First: The Rise of 1B-Scale Tool-Use Specialists
Specialized sub-agents like the 1.3B Cognica-PoE and the 270M FunctionGemma—which achieved 85% accuracy on mobile benchmarks—are outperforming general-purpose models through targeted fine-tuning on datasets like xlam-function-calling-60k blog.google.