The Shift to Learned Orchestration
From hand-coded logic to learned coordination, the agentic web is moving toward production-grade reliability and code-centric execution.
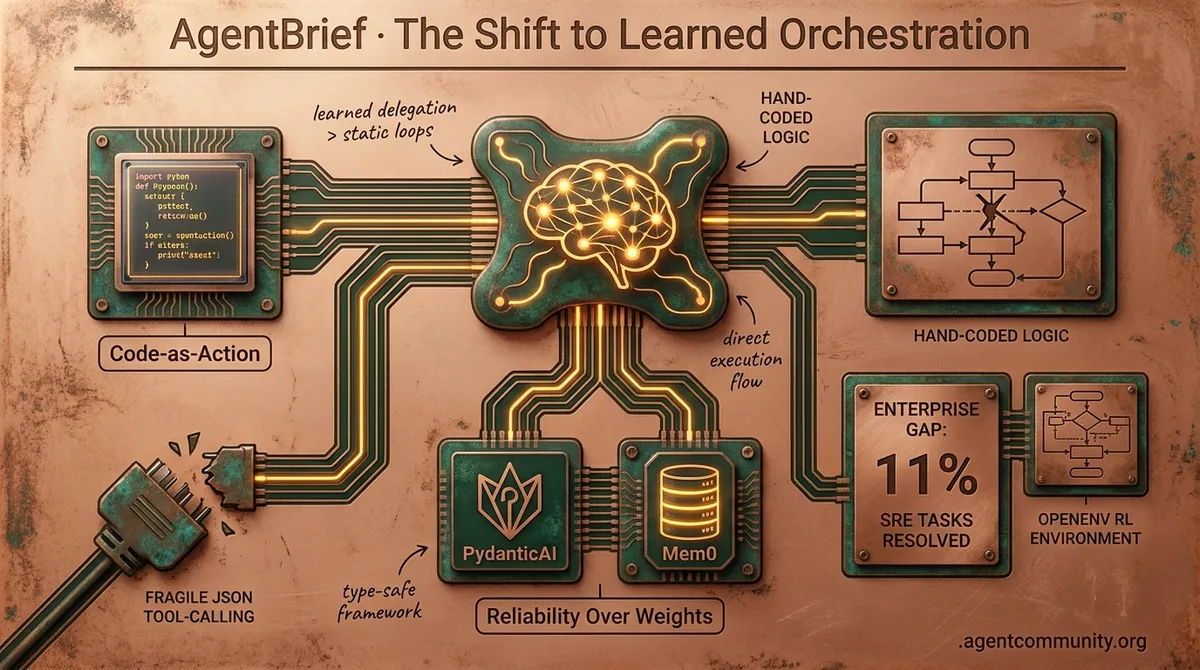
- Learned Orchestration Ascends Sakana AI’s Fugu signals a shift from hand-coded LangGraph state machines to learned coordination, where agents reason about delegation rather than following static logic trees.
- Code-as-Action Dominance Hugging Face’s smolagents and the 'Code-as-Action' paradigm are replacing fragile JSON tool-calling with direct Python execution to improve reliability in complex environments.
- Reliability Over Weights Production success is increasingly a property of the orchestration layer—using type-safe frameworks like PydanticAI and persistent memory like Mem0—rather than just raw model weights.
- The Enterprise Gap While GPT-4o’s sub-300ms latency enables fluid reasoning, recent benchmarks show enterprise agents still only resolve 11% of real-world SRE tasks, highlighting the need for better RL environments like OpenEnv.
// From the blog
• 7,000 organizations. So we built them a planet. — Crossing a dream line called for more than a counter going up. The new member globe shows who is actually building the agentic web, everywhere.
• AID v2 is live — Agent Identity & Discovery v2 makes AID the 0-th hop for agent discovery: a DNS-first endpoint and key anchor with sharper PKA, updated SDKs, and a cleaner migration path.
X Intel
Stop wiring your agent loops by hand—Sakana just made orchestration a learned skill.
The dream of the agentic web is moving from brittle, hand-coded state machines to fluid, learned behaviors. For too long, we have been stuck in the 'if-then' loop of LangGraph and CrewAI, manually wiring every possible edge case. This week, Sakana AI signaled the beginning of the end for that era with Sakana Fugu. By treating orchestration as a learned coordination problem rather than a hard-coded logic tree, we are seeing the emergence of agents that do not just execute—they delegate, verify, and reason about their own tool usage. But it is not just about the brains; it is about the environment. From Claude Code expanding its 'Agent Skills' ecosystem to the maturation of self-hosted memory layers like Mem0, the infrastructure for production-grade agents is hardening. We are shifting from demo-ware that lives in a notebook to enterprise-ready systems that can handle persistent memory, complex Microsoft 365 integrations, and sovereign compute clusters. If you are not building with learned orchestration and persistent context today, you are building for the past.
Sakana Fugu Replaces Brittle Loops with Learned Orchestration
Sakana AI has launched Sakana Fugu, a multi-agent orchestration system that abstracts complex coordination into a single OpenAI-compatible API. Unlike the static logic flows developers typically build, Fugu operates as a learned coordinator trained specifically to delegate tasks, verify results, and synthesize outputs from a pool of expert models @SakanaAILabs. The system functions as a recursive LLM that dynamically assigns roles—Thinker, Worker, or Verifier—internally deciding when to solve a problem directly or route it to specialized agents @SakanaAILabs. Early performance metrics for the 'Fugu Ultra' variant are striking, hitting GPQA-D 95.5 and SWE-Bench Pro 73.7, placing it squarely alongside or ahead of frontier models like Fable and Mythos @TheRundownAI @Ananth7e.
The community reaction highlights a fundamental shift toward 'collaborative ecosystems.' Aaron Levie noted that this architecture moves away from manual wiring toward an orchestrator that manages model selection and recursive task handling internally @levie. Based on ICLR 2026 research papers TRINITY and Conductor, the system leverages test-time compute scaling to evolve a small coordinator into a dynamic manager @hardmaru. While some users point to higher token usage as a necessary trade-off for this depth of orchestration, the consensus is that the ability to route around frontier model restrictions via a single API simplifies the stack significantly compared to hand-coded frameworks like LangGraph or CrewAI @karmakarthik @NeuralByte01.
For agent builders, Fugu represents the 'no-code' moment for orchestration logic. Instead of manually architecting planner-executor-verifier pipelines, developers can now rely on a model that has learned these patterns from data. This reduces the surface area for logic errors and allows builders to focus on the 'expert' models in their pool rather than the glue code connecting them @takepon_7. As we move toward more autonomous systems, the ability to scale reasoning at test-time without monolithic model growth will be the primary lever for performance.
Claude Code Ecosystem Hardens with Verified Skills and Custom Rules
Anthropic has formalized a set of best practices for Claude Code, emphasizing a 'plan mode' and gated verification phases to boost agent reliability in production @techNmak. Builders are increasingly adopting CLAUDE.md files for persistent project rules and implementing custom slash commands to trigger subagent tasks like parallel code reviews and automated testing @Krishnasagrawal. This move toward structured 'Agent Skills' allows Claude to act as a specialized agent for roles ranging from quantitative trading to legal analysis @tom_doerr.
The adoption of these Skills is accelerating, with developers publishing massive domain-specific libraries, such as a set of 754 cybersecurity skills mapped to frameworks like MITRE ATT&CK and NIST AI RMF @clxymox. In the community, this is manifesting as highly automated PR workflows that handle everything from CI checks and README updates to component validation @fujitech_ai. The mainstreaming of this ecosystem is perhaps best illustrated by the entry of 'Claude Code Agent Skills' manuals into Japanese IT bestseller lists @ComputerBookNew.
The implication for developers is clear: the most effective agents are not just the smartest models; they are the ones with the best 'operating manuals.' By combining Skills with Hooks, Subagents, and Rules, builders are creating project-specific tailoring that goes far beyond generic prompting @yoheitakanashi. This specialized integration is the key to moving agents from chatbots that code to autonomous members of the engineering team.
In Brief
Self-Hosted Memory Layers and Graph DBs Mature
Persistent memory for agents is moving in-house with the release of self-hosted Mem0 and RushDB, prioritizing privacy and relationship-aware context. Developers can now run Mem0 on their own hardware via MEM0_HOST, enabling 100% data privacy while maintaining automated fact extraction, semantic search, and history compression across user, session, and agent layers @Teknium @shesaidmewakeup. Parallel to this, RushDB has simplified the agentic backend by allowing JSON-to-graph translation, which eliminates the glue code usually required for relationship traversal and semantic search through a single API @DanKornas. This shift signals that memory is becoming essential VPC-kept infrastructure rather than a rented cloud service, complete with per-user API keys and audit logs @stretchcloud @witcheer.
DeepSeek V4 Pro Lands on Sovereign Supernode
DeepSeek has reportedly finished full-parameter post-training for its V4 Pro model on a 384-node Huawei Ascend cluster, sparking fresh debate on the origins of agentic reasoning. Analysts point to this milestone as evidence that advanced reasoning can emerge naturally from datasets and reinforcement learning rather than being purely distilled from frontier models like OpenAI's o1 @teortaxesTex @bookwormengr. Agent builders are already integrating V4 Pro into planning workflows as a low-cost, high-performance alternative for complex coding tasks, despite concerns that long reasoning traces could potentially lead to hallucinations if not properly managed @FloRyRy410 @sakurayukiai.
Executor v1.5.16 Unifies Microsoft 365 Connectivity
The new Executor v1.5.16 release streamlines cross-platform agent actions by adding native Microsoft Graph support and improved attachment handling. The platform now acts as a central hub for OAuth, allowing agents to access Google and Microsoft 365 services via a single interface that manages permissions, approvals, and multi-account handling @RhysSullivan. With the addition of a new emit() function for direct chat attachments and support for protocols like MCP and OpenAPI, developers can now build agents that interact more fluidly with enterprise productivity suites without managing fragmented auth flows @RhysSullivan @grok.
Quick Hits
Agent Frameworks & Orchestration
- OpenClaw transitions to a non-profit model to prioritize agent quality over commercial interests @steipete.
- A curated index of 340+ AI agents and frameworks is now receiving monthly updates for active builders @tom_doerr.
Research & Benchmarks
- New research suggests LLM agents struggle with environmental complexity, failing to turn feedback into reliable world models @rohanpaul_ai.
- A Nature study warns that AI automation might erode professional judgment by removing necessary friction in the workflow @rohanpaul_ai.
Agentic Infrastructure
- Agent Forge improves human-in-the-loop flows with a new Telegram bot and stabilized APIs @AITECHio.
- xyOps launches a unified backend for agentic job scheduling, workflow automation, and system monitoring @tom_doerr.
Reddit Roundup
Low latency and type-safe architectures are transforming "vibe-based" prompts into production-grade autonomous systems.
We are witnessing a fundamental shift in the "unit of intelligence" for autonomous agents. It is no longer just about the raw reasoning power of a model; it is about the friction between the model and the world. Today’s developments showcase this transition from two critical angles: the speed of thought and the rigor of execution. OpenAI’s GPT-4o is slashing latency to human-like levels, delivering response times as low as 232ms. This effectively removes the performance tax on multi-step reasoning, allowing agents to maintain fluid state across complex tool-calling sequences.
Meanwhile, the frameworks supporting these models are maturing. The rise of LangGraph and PydanticAI signals a move toward a structured 'Agentic SDLC,' where type safety and cyclic state management replace the fragile 'prompt-and-forget' patterns of the past year. For builders, the signal is clear: the barrier to entry for real-time agents is collapsing, but the bar for reliability is rising. Whether you are deploying Phi-3-mini on the edge to protect privacy or orchestrating autonomous web navigation via MultiOn, the focus has shifted to state persistence and deterministic execution. We are moving past the chat-box era into a world where agents are defined by their ability to handle errors gracefully and interact with the web as a first-class citizen.
GPT-4o Redefines Agentic Latency and Multi-Step Tool Reliability r/OpenAI
OpenAI's GPT-4o is fundamentally shifting the unit economics and performance of real-time agents, delivering an average response latency of 320ms with a floor as low as 232ms @OpenAI. This native multimodality eliminates the 'reasoning gap' found in previous vision-text pipelines, resulting in a 25% performance boost in complex navigation tasks that require visual grounding @OpenAI.
Practitioners on r/OpenAI report that while GPT-4 Turbo remains competitive in pure text reasoning, GPT-4o's ability to maintain state across long-form tool-calling sequences is significantly more robust. Technical evaluations on the Berkeley Function Calling Leaderboard (BFCL) confirm this, placing GPT-4o at the top of the rankings with superior accuracy in identifying and executing multiple concurrent tool calls compared to GPT-4 Turbo r/MachineLearning.
Furthermore, the model's performance on the GAIA benchmark highlights its superiority in 'real-world' agentic tasks, particularly those involving multi-step planning and tool usage across diverse modalities. This combination of speed and reliability marks a significant milestone for developers building autonomous systems that require immediate, multimodal feedback loops.
Beyond DAGs: LangGraph Codifies the 'Agentic SDLC' r/LangChain
The shift from linear chains to cyclic graphs is accelerating with LangGraph, which allows agents to loop back and self-correct across long-running interactions. This architecture is central to the emerging Agentic SDLC, where systems move away from 'prompt-and-forget' patterns toward adversarial review loops that catch 5x more bugs than standard self-correction u/rawsan. By utilizing 'checkpoints' and Thread ID persistence, LangGraph enables agents to resume execution after human intervention—a feature credited with improving task completion rates by 40% in enterprise pilot programs u/langchain-ai. This stateful design is specifically engineered to combat the 'hidden token tax' and 'silent tool failures' that account for 40% of logic failures in production u/camerongreen95.
PydanticAI: Hardening Agent Reliability via Type-Safe Dependency Injection r/Python
PydanticAI has emerged as a production-grade framework designed to eliminate 'vibe-based' agent development by enforcing strict type safety. Built by the team behind Pydantic, the framework uses Python type hints to validate prompt inputs and tool arguments, significantly mitigating the risk of malformed JSON—a primary hurdle cited by developers on r/Python. A standout feature is its type-safe dependency injection system, which allows developers to pass complex state—such as database pools—directly into tools via a Deps generic, ensuring agents remain testable and decoupled from global state @samuelcolvin.
Local SLMs: Phi-3-Mini Outperforms 8B Models in Edge Agent Benchmarks r/LocalLLaMA
Microsoft's Phi-3-mini is proving that high-quality agentic reasoning doesn't require massive parameters, scoring 68.8% on MMLU and 82.5% on GSM8K to outperform larger models like Llama-3-8B. While early tests suggested 85% accuracy in simple tool-use loops, community testing on r/LocalLLaMA highlights its "surprisingly good" ability to follow complex system prompts for JSON extraction without hallucinated keys. Practitioners like u/WolframRavenwolf note that its instruction-following precision makes it a superior 'router' for deterministic hierarchical systems, especially when deployed locally via ONNX to ensure data privacy.
OpenHands Scales Autonomous Coding with Event-Based Architecture r/OpenHands
OpenHands (formerly OpenDevin) has jumped to a 32.7% score on the SWE-bench Lite leaderboard by utilizing an 'Event Stream' architecture to process asynchronous inputs from terminals and browsers simultaneously @SWE-bench.
MultiOn API: Bridging the Gap Between Scraping and Autonomous Action r/AI_Agents
MultiOn's Web-LVM achieves a 60% reduction in navigation errors over traditional DOM-parsing, though developers warn of aggressive rate-limiting and the need for adversarial review loops to prevent unintended financial transactions u/Successful_Ad_9173.
Discord Discussions
Orchestration layers are proving more critical than raw model weights in the quest for autonomous reliability.
The 'intelligence' of an agent is increasingly becoming a property of its environment rather than its weights. Today’s landscape reveals a fundamental shift: the orchestration harness—the invisible layer of prompts, tool schemas, and error handlers—is now determining success more than the underlying model. While a raw Claude 3.5 Sonnet might stumble, the same model wrapped in a 'Cursor Doctrine' or a specialized system prompt is achieving SOTA performance in production.
This move toward system-level optimization is manifesting everywhere. The LMSYS Agent Arena is stripping away brand names to test pure functional success, while local developers are leveraging Ollama’s new backend to rival native performance. Even the hardware is shifting, with AMD’s high-memory MI300X droplets becoming the go-to for those looking to escape the performance degradation of shared cloud clusters. For builders, the message is clear: stop waiting for the next model to solve your problems and start perfecting the harness that houses it.
The Harness Outperforms the Raw Model
A growing consensus among developers in the Cursor and LMArena communities suggests that the orchestration 'harness'—the layer of system prompts, tool definitions, and error-handling logic—is becoming more critical than the underlying model itself. Technical evaluations by Endor Labs demonstrate that the Claude 3.5 Sonnet yields drastically different success rates depending on the harness used, proving that a refined environment can fix errors that a raw model fails to address.
This shift emphasizes that for autonomous workflows, the surrounding logic—specifically community-vetted rulesets like 'Cursor Doctrine'—acts as a critical deterministic feedback loop. According to @tugg_, these rulesets allow 'good enough' models to achieve high-tier performance by enforcing strict context management and tool-calling boundaries. Developers like vishiri.rilgatan have observed that Cursor’s custom implementation significantly outperforms Anthropic’s native Workbench in multi-turn coding tasks.
Join the discussion: discord.gg/cursor
Agent Arena Enforces Orchestrator Anonymity to Combat Brand Bias
The LMSYS Agent Arena is formalizing its benchmarking methodology by masking orchestrator identities to ensure evaluations focus strictly on functional success. According to lm_mod_16, the leaderboard now prioritizes Task Success Rate (TSR) and Average Tool Calls per Task as primary metrics to differentiate between efficient reasoning and brute-force token consumption, a shift that comes as models like GLM-5.2 were recently pulled from rankings following performance regressions and 'hallucinatory loops' during multi-turn autonomous tasks lm_mod_4.
Join the discussion: discord.gg/lmsys
GLM 5.2: The Logic Specialist Challenging the Frontier
Zhipu AI's GLM 5.2 is emerging as a formidable logic contender, with users describing the model as 'goated' for solving reasoning puzzles that stumped Claude Opus. While the model reportedly achieves 91.2% on GSM8K, practitioners like 123sora2 suggest it is better suited as a high-level architectural planner rather than a primary code generator, especially given its recent struggle with stability and high resource footprint in local multi-agent architectures goodlife0416.
Join the discussion: discord.gg/lmsys
Ollama 0.30 Update Rivals Native Llama.cpp Speed
The performance gap between user-friendly local runners and raw implementations is closing as the Ollama 0.30 update transitions its backend to llama-server. Developers in the community report throughput nearly equivalent to native llama.cpp builds, while new optimization guides by TrentBot highlight that even an affordable $200 RTX 3060 can reliably run 35b MoE models by leveraging strategic VRAM fitting and 4-bit quantization colorado.rob1459.
Join the discussion: discord.gg/ollama
Fixing Qwen 3.6 Tool Calling with Native Mode
Switching Qwen 3.6 to 'native' tool-calling mode leverages internal tokens to significantly reduce the 'quantization tax' on reasoning logic mister_spoogles.
Join the discussion: discord.gg/localllm
AMD MI300X Droplets Enter the Commodity Market
AMD's MI300X droplets are now available for as low as $2.50/hr, offering 192GB of HBM3 memory to bypass the 'intelligence tax' of shared cloud infrastructure electroglyph.
Join the discussion: discord.gg/localllm
The HF Hub
Hugging Face standardizes on Python execution while enterprise agents hit an 11% reality wall.
The Agentic Web is moving out of its awkward teenage phase of calling JSON tools and hoping for the best. Today’s big theme is execution-first architecture. Hugging Face is leading the charge with smolagents, effectively declaring that if an agent can't write and run its own code, it’s just a glorified chatbot. This 'Code-as-Action' paradigm isn't just a preference; it’s a performance necessity, as shown by the Transformers Code Agent topping the GAIA leaderboard. But there’s a sobering counter-narrative: while we’re winning academic benchmarks, IBM and Berkeley just dropped a reality check showing that enterprise agents only resolve 11% of real-world SRE tasks. The gap between 'passing a test' and 'running a data center' is where the real work begins. We’re seeing a convergence of high-speed local models like Holotron-12B and standardized RL environments like OpenEnv to close that gap. The message for builders is clear: stop prompting for output and start building for execution.
Hugging Face Standardizes on Code-First Agent Architectures
Hugging Face has officially moved to standardize the 'Code-as-Action' paradigm, launching smolagents to replace the brittle nature of JSON tool-calling with direct Python execution. By allowing agents to handle complex logic like loops and data manipulation within a single block, this architectural pivot has reportedly achieved a 30% reduction in LLM steps and operational costs. The results speak for themselves: the Transformers Code Agent reached the top of the GAIA benchmark by bypassing the structural parsing errors that frequently derail traditional orchestration.
This transition marks a broader ecosystem shift away from 'black-box' autonomy toward 'harness' architectures that prioritize transparency. With the release of Transformers Agents 2.0 and Agents.js, developers can now deploy agents in as few as 50-100 lines of code across both Python and JavaScript environments. To streamline this, a new agent-optimized CLI has been introduced, allowing for rapid deployment directly from the Hugging Face Hub.
IBM and Berkeley Expose the 11% Reality of Enterprise Agent Performance
A sobering reality check from IBM Research and UC Berkeley reveals that frontier models resolve a mere 11.4% of real-world Site Reliability Engineering (SRE) scenarios. Through their new IT-Bench and MAST frameworks, researchers identified that tool-calling errors (45%) and reasoning hallucinations (38%) remain the primary roadblocks to industrial grounding. To combat this, the VAKRA benchmark and AssetOpsBench have been released to provide a diagnostic lens into multi-step reasoning and safety, shifting the focus from academic text generation toward standardized, execution-heavy industrial metrics.
Local GUI Agents Achieve 8,900 Tokens/Sec with Holotron-12B
Local 'Computer Use' has hit a new performance ceiling with the Holotron-12B model, which achieves a massive 8,900 tokens/sec throughput. By utilizing a hybrid SSM-Attention architecture, Hcompany has effectively eliminated the KV Cache bottleneck, enabling real-time GUI interactions that were previously limited by cloud latency. This jump in speed has propelled WebVoyager success rates from 35.1% to 80.5%, supported by the Holo1 family of VLMs and ScreenEnv, a new gymnasium-style environment designed to bridge the gap between pixels and actions in real-world software stacks.
NVIDIA and LeRobot: Bridging the Reasoning-to-Action Gap in Physical AI
NVIDIA is bridging the reasoning-to-action gap in physical AI with the launch of Cosmos Reason 2, a model engineered for visual-spatial reasoning and long-horizon task planning. This 'brain' for embodied agents enables causal inference, allowing robots to predict physical consequences before execution, while the Nemotron 3 Nano Omni provides a 30B parameter multimodal core for low-latency edge performance. The ecosystem is further bolstered by the Strands Agents and LeRobot collaboration, which standardizes 'Code-as-Policy' frameworks for deploying models directly to hardware like the SO-1 arm.
Open Source Community Standardizes Agentic RL with OpenEnv
Meta’s PyTorch team and Hugging Face have launched OpenEnv, the first standardized Gymnasium-style API for training tool-using agents via Reinforcement Learning. Moving beyond simple few-shot prompting, OpenEnv treats agents as RL entities that learn from direct environmental feedback within actual software stacks. This shift toward 'doing' agents is echoed by LinkedIn's GPT-OSS, which fine-tunes models based on execution success rather than text similarity, using reward functions like OpenEnv-Turing to optimize for successful tool outcomes.
Deep Research Evolves into Autonomous Agentic Loops
The Open-source DeepResearch initiative is replacing static RAG with autonomous search loops that use the smolagents framework to reduce overhead by 30%.
Tiny Agents Harness MCP for Dynamic Tool Discovery
Tiny agents are now harnessing the Model Context Protocol (MCP) to achieve dynamic tool discovery in as few as 50 lines of Python code.
Specialized Coding Agents Surpass GPT-4o
Specialized models like Qwen2.5-Coder are officially outperforming GPT-4o on SWE-bench Verified, achieving a 49.1% success rate for autonomous repository-level reasoning.