The Rise of Deterministic Orchestration
Stop guessing with black-box prompts and start building deterministic, code-first agents.
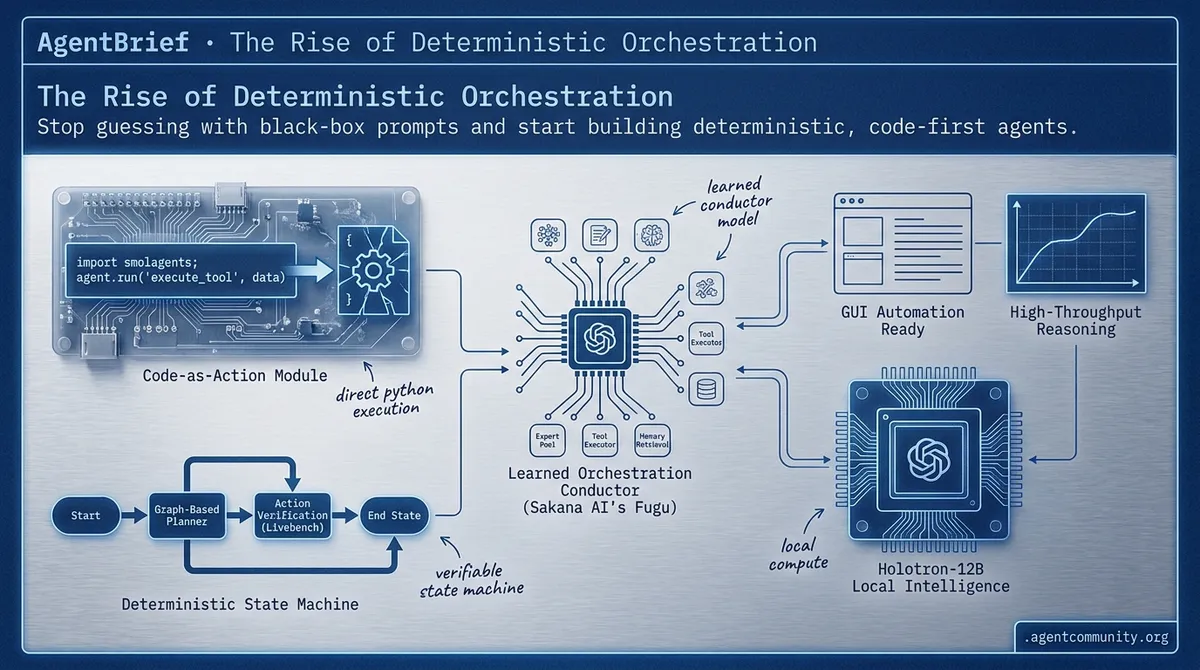
- Learned Coordination The transition from hand-coded logic to learned conductor models like Sakana AI's Fugu is redefining how we orchestrate expert pools at inference time.
- Code-as-Action Hugging Face's smolagents and the shift to direct Python execution are replacing brittle JSON parsing, yielding 30% better reliability on complex benchmarks.
- Deterministic Reliability Practitioners are reclaiming control from autonomous planners by adopting graph-based state machines and verifiable evaluation stacks like Livebench.
- Local Intelligence High-throughput models like Holotron-12B and GLM 5.2 are enabling production-ready GUI automation and reasoning on local hardware.
The Inference Layer
Stop coding static routers and start training conductors for the agentic web.
The era of the 'single-prompt agent' is ending. We are moving into a phase where the core challenge isn't just the model, but the orchestration of expert pools. Sakana AI's launch of Fugu signals a massive shift: moving from hand-coded logic to 'learned coordination' where a conductor model manages thinkers, workers, and verifiers at inference time. This is the infrastructure the agentic web actually needs to scale. Meanwhile, on the developer experience front, we are seeing the emergence of 'agentic standards' like the CLAUDE.md persistent memory file. These aren't just tips; they are the protocol for how agents interact with complex codebases. As Aaron Levie and Michael Grinich have pointed out, agents are the next class of enterprise users, expected to consume software at 100x the rate of humans. For builders, this means our workloads are shifting from simple task completion to building durable, memory-persistent systems that can handle recursive synthesis without leaking data or losing their way in complex world models. Today's issue breaks down the tools and patterns making this autonomous future a production reality.
Sakana AI Shifts Agent Logic to Learned Orchestration
Sakana AI has introduced Fugu and Fugu Ultra, a novel orchestration layer designed to coordinate model pools via a single OpenAI-compatible endpoint @SakanaAILabs. Unlike traditional hard-coded routers, Fugu utilizes a ~7B 'Conductor' model trained through reinforcement learning to dynamically manage model selection, delegation, and recursive synthesis across expert models @SakanaAILabs. On critical reasoning benchmarks, Fugu Ultra reportedly matches frontier models like Fable and Mythos, offering a high-capability path that circumvents current export control risks @rohanpaul_ai.
Early performance data suggests that this learned coordination significantly improves efficiency in complex tasks. In a Rubik’s Cube solver demonstration, Fugu Ultra generated a solver averaging 19.72 moves with a 100% success rate across 300 test cubes, outperforming single frontier models that either crashed or required significantly more moves @SakanaAILabs. The architecture allows for a swappable model pool, which @KURAOpenclaw notes is a key strategy for avoiding single-vendor lock-in or regulatory bottlenecks.
For agent builders, this represents a fundamental shift toward inference-time scaling. By treating recursion depth as an adjustable 'knob,' developers can scale compute based on task difficulty rather than relying on a static model response @stretchcloud. While exact token-consumption metrics for these recursive loops are still being verified, the move toward a 'learned coordinator' suggests we are nearing the end of manual, brittle agentic workflows.
The Rise of CLAUDE.md and Agentic Power User Patterns
As the Claude Code CLI gains traction, developers are standardizing a new set of 'agentic hygiene' patterns to manage context and persistence. Central to this is the CLAUDE.md file, which serves as a persistent guide for project rules and style @Krishnasagrawal. To prevent context bloat, power users recommend keeping this file under 200 lines while enforcing core rules like 'think before coding' and surgical changes @HeyAnjula.
Beyond basic configuration, a suite of new slash commands is emerging to provide agents with autonomous goal-seeking capabilities. Commands like /goal allow for autonomous completion until specific success criteria are met, while /loop manages recurring seven-day tasks @AlfieJCarter @techNmak. Developers are also adopting 'plan mode,' where the agent generates a gated, phase-wise roadmap with verification steps before executing any code @techNmak.
These patterns are quickly moving from manual tricks to reusable infrastructure. Builders are already packaging these 'skills' into GitHub repositories for team-wide installation, focusing on language-specific rules and disabling unhelpful LLM behaviors like unsolicited code comments @amecha_ai @sirstripy. This standardization is the first step toward a consistent 'OS' for agentic development.
In Brief
Unified Memory Layers Tackle Agent State Persistence
Builders are increasingly moving away from manual 'glue code' for agent memory, as new tools like RushDB provide API layers that automatically convert JSON input into graph relationships and semantic search @DanKornas. This shift is complemented by Mem0's new self-hosting capabilities, which allow developers to manage long-term agent memory within VPCs, utilizing automatic fact extraction and history compression to avoid replaying full transcripts @Teknium @agentcommunity_.
Enterprise Platforms Redesign for Agent-First Users
Industry leaders are calling for a radical redesign of enterprise architecture to accommodate agents as a primary user class that could consume software 100x more than humans, necessitating new layers for auditing and data leak prevention @grinich @levie. Early solutions are appearing in the form of 'Coinbase for Agents,' which uses crypto infrastructure and x402 to enable autonomous trading and payments under strict permission boundaries, addressing the fact that 78% of organizations currently lack formal entities for agents @coinbase @johniosifov.
Research Exposes Agent Struggle with Internal World Models
New research into agentic automata learning (arXiv:2606.16576) reveals that while LLM agents can discover hidden structures through queries, they struggle to build reliable internal world models as environmental complexity increases @rohanpaul_ai. This suggests a core limitation where agents rely on pattern matching rather than durable model construction, leading observers like @swyx to argue that true agency may eventually require architectures that move beyond simple next-token prediction.
Quick Hits
Agent Frameworks & Orchestration
- Executor v1.5.16 introduces Microsoft Graph support and an
emit()tool for better attachment handling @RhysSullivan. - xyOps launches as a unified platform for agent-friendly job scheduling and workflow automation @tom_doerr.
- Agent Forge adds a Telegram bot integration for human-in-the-loop workflow approvals @AITECHio.
Tool Use & Models
- GPT-5.5 has shown zero-shot 'guessing' capabilities by attempting to use tools for unsupported file formats @QuixiAI.
- Claude Code now features specialized quantitative trading skills tailored for Indian markets @tom_doerr.
- DeepSeek V4 Pro has completed full-parameter post-training on the CloudMatrix 384 supernode @teortaxesTex.
- Architectural analysis of GLM-5.2 is underway for local training using dolphin-summarize @QuixiAI.
Deterministic Dispatch
As OpenAI moves toward government-first gating, developers are pivoting from autonomous planning to deterministic state machines.
Today’s issue highlights a fundamental shift in the agentic stack: we are moving from the 'magic' of autonomous planning to the rigor of deterministic orchestration. For months, the industry has chased the 'open loop'—the idea that a model could autonomously manage its own success—only to find that 73% of these agents fail due to cognitive overload. The remedy? Practitioners are reclaiming control via graph-based orchestration and structured state machines, treating LLMs as natural-language shells rather than the primary driver.
Simultaneously, the 'frontier' is becoming increasingly gated. Reports of OpenAI's 'government-first' launch for GPT-5.6 suggest a future where the most capable models are sequestered behind national security vetting and 'Certificates of Purpose.' This creates a massive operational incentive for the local and open-weight ecosystems. We're seeing this play out in the rapid evolution of the Model Context Protocol (MCP) and hardware-level optimizations for local swarms. As we move toward 2025, the successful agentic developer isn't the one with the most autonomous model, but the one with the most robust evaluation pipeline and deterministic guardrails. The 'vibe check' is dead; long live the 800k-judgment-per-week eval stack.
Closing the Open Loop: The Move to Deterministic State Machines r/AgentsOfAI
The 'open loop' pattern—where a model plans, acts, and judges its own success—is being identified as the primary source of agent unreliability. u/CodedBeforeTheVibe argues that developers are leaning on the three things models do worst: holding massive context, deciding execution flow, and self-judging quality. To combat this, practitioners are moving toward structured state machines where the model is a component, not the driver. This sentiment is echoed by u/Worldly-Self-6270, who found that 73% of their failed agents (22 out of 30) died because they were given too many responsibilities in a single loop, suggesting that 'micro-agents' with narrow scopes are the only path to production stability.
This architectural pivot is manifesting as a shift from "Autonomous Planning" to "Graph-based Orchestration." Developers are increasingly adopting frameworks like Burr and LangGraph to enforce deterministic state transitions, effectively treating the LLM as a "natural-language shell" for a 90% deterministic code core u/anilkr84. Recent field reports indicate that explicit handoffs and type-safe trails are winning out over shared memory to prevent "state-bleed," where internal memory might otherwise bypass standard IAM checks u/GlitteringAngle8601. By constraining agents to specific "postures" or SKILL.md frameworks, builders are achieving an 88% success rate in specialized tasks like bug detection u/ClaudeAI discussion.
OpenAI to Prioritize Government Tiers for GPT-5.6 Rollout r/OpenAI
OpenAI is reportedly coordinating a restricted launch for its upcoming GPT-5.6 model, establishing a "government-first" tier that prioritizes federal agencies and national security partners. This strategy is allegedly tied to a new National Security Partnership requiring models to pass safety criteria monitored by the U.S. AI Safety Institute (US AISI), specifically targeting "dual-use" capabilities in cyber-defense and biological risk mitigation u/Historical-Habit7334. Community members like u/icompletetasks note that this shift creates a "cleared access" bottleneck, where enterprise agents may require a "Certificate of Purpose" for full model utilization, a move that has intensified debates over "AI Sovereignty" and the necessity of open-weight alternatives u/Crescitaly.
MCP Becomes the Universal Agent Connector r/mcp
The Model Context Protocol (MCP) is rapidly expanding from a simple tool interface to a full ecosystem for enterprise data access with new SFTP and Gitea integrations. Recent community contributions include an SFTP Orchestrator for remote server management and a Gitea MCP tool featuring over 200 CLI commands for repository management. Beyond connectivity, practitioners like u/petburiraja are optimizing inference costs by splitting models like GLM-5.2 into separate 'run' and 'advise' MCP tools, allowing agents to perform simple JSON reshaping tasks without burning tokens on expensive reasoning cycles.
Memory Bandwidth: The Hidden Inference Bottleneck r/LocalLLaMA
While raw TFLOPS dominate marketing, transformer inference remains fundamentally memory-bandwidth-bound during the autoregressive decoding phase. For local agent workstations, the bottleneck often shifts to the hardware interconnect; u/PhantomWolf83 reports that switching from PCIe x16 to x4 in multi-GPU setups can lead to a 15-25% performance degradation during Tensor Parallelism tasks. Developers building local swarms for Qwen 3.6-27B are now prioritizing motherboards that support PCIe 5.0 x8/x8 configurations to maintain throughput during complex, multi-step reasoning trajectories u/ArchitectingAI.
Claude-Style Artifacts Arrive for Local Models r/LocalLLM
TurboLLM v1.5.0 and JoeBro are bringing Claude-style artifact rendering and native macOS Python interpreters to local agents to mitigate the "agentic tax" of unverified code execution u/Bramha_dev.
Sentinel Gateway Enforces Instruction/Data Separation r/AI_Agents
Sentinel Gateway addresses prompt injection by implementing a strict separation between instruction and data channels via signed, cryptographic tokens for every tool execution u/vagobond45.
Beyond the Vibe Check: The Rise of High-Volume Agent Evals r/LLMDevs
Modern evaluation stacks are scaling to 800,000 judgments per week, driving the adoption of ultra-low-cost models like DeepSeek V4 Flash to handle regression testing u/GrayZetsu.
Visual Compilers: Solving the 'Spatial Idiot' Problem r/AI_Agents
A new 2.5D visual compiler decouples logical topology from physical geometry, preventing layout collapse in complex multi-agent systems exceeding 15 nodes u/Creative_Factor8633.
Local Reasoner Roundup
Open-source reasoning hits Opus-level benchmarks as developers ditch vibe-based rankings for hard coding metrics.
The shift from proprietary 'black box' models to verifiable, open-weight reasoning is accelerating. Today's landscape is defined by a rejection of the status quo. On one side, we see ZhipuAI's GLM 5.2 delivering what community members describe as 'Opus-level' intelligence for local deployment, effectively democratizing the reasoning capabilities previously gated by frontier labs. On the other, the community is moving away from the subjective 'vibes' of human-preference benchmarks in favor of 'uncontaminable' metrics like Livebench and DeepSWE. This isn't just about higher scores; it's about reliability in production. For practitioners, the focus is shifting toward 'agentic infrastructure'—from Ollama's strict context management to Unsloth's tool-healing layers. We are moving from a world where we hope an agent works to one where we engineer it to succeed, even when the hardware is a DIY 4x GPU rig. Today's issue breaks down the tools and models turning these autonomous ambitions into reality.
GLM 5.2 Emerges as Opus-Level Open Competitor
The open-source community is rallying around GLM 5.2, with neuralnetworks describing it as "borderline Opus level intelligence." Technical benchmarks support this claim, showing GLM 5.2 achieving a 91.2% score on GSM8K, rivaling the reasoning capabilities of 1T architectures despite its rumored 700B parameter size lm_mod_16. In coding-specific benchmarks, the model has demonstrated a 94.5% success rate in multi-turn tool orchestration, matching the precision of Claude 3.5 Opus while remaining free for local deployment @ZhipuAI.
Discussions in LocalLLM general suggest that GLM's architecture is particularly effective at distilling high-tier reasoning into smaller, edge-ready variants. venexificus predicts that because GLM 5.2 maintains an open-weight license for research and low-scale commercial use, it will become the primary "distillation backbone" for the next generation of autonomous agents. This release addresses a critical gap in the market, providing high-tier reasoning for $0 inference cost and positioning GLM as a vital asset for the agentic web as users seek alternatives to proprietary APIs.
Join the discussion: discord.gg/localllm
Rigorous Evaluations Overthrow 'Vibe-Based' Rankings
The developer community is increasingly pivoting away from 'vibe-based' evaluations like LM Arena in favor of 'uncontaminable' metrics that better predict agentic performance. ryanstudio argues that many frontier models are now 'benchmark maxxing,' leading to inflated scores that fail to translate to real-world utility. To combat this, Livebench has emerged as a primary filter, with o1-preview and Claude 3.5 Sonnet consistently leading the pack by focusing on reasoning tasks that are difficult to find in training data @abacusai. Notably, while human-preference rankings often favor conversational 'vibes,' Livebench reveals significant discrepancies; for instance, DeepSeek-V3 and o1-mini often outperform larger models like Llama 3.1 405B in objective coding and math categories, despite lower 'preference' scores @maximelabonne.
Join the discussion: discord.gg/localllm
Debugging Subagent Failures in Cursor Composer 2.5
Developers utilizing Cursor's Composer 2.5 are encountering intermittent failures where subagents fail to spawn, a bottleneck in the platform's transition toward an 'Agentic OS.' While the UI often triggers a 'Couldn't start' error, tomtowo and community practitioners report that these are frequently visual quirks rather than functional blocks, meaning the background processes often continue to execute despite the error message. In instances of genuine failure, the primary agent has been observed manually delegating tasks to approximate subagent directives, which can lead to redundant logic loops or silent degradation of the workflow digilog2501. Technical gaps in the current implementation also prevent developers from forcing specific models for subagents; nohje confirmed that defining a model field in agent rule files currently fails.
Join the discussion: https://discord.com/invite/cursor
Mastering Context Management with Ollama 0.30
Setting truncate=false and shift=false in Ollama 0.30 forces hard errors on context overflow, preventing the silent hallucinations that plague long-running agent sessions frob_08089.
Join the discussion: https://discord.com/invite/ollama
Hermes and Unsloth Enable Robust Computer Use
Hermes 3 is becoming the go-to for edge-based "computer use," supported by Unsloth Studio’s tool healing layer which intercepts and corrects malformed JSON before execution @unslothai.
Join the discussion: discord.gg/localllm
Building High-VRAM Agent Rigs for Cheap
Hardware hackers are achieving 64GB VRAM via 4x 5060 Ti consumer setups, providing a cost-to-VRAM ratio 10x lower than A6000 rigs for local long-context orchestration mister_spoogles.
Join the discussion: discord.gg/localllm
The Open-Source Forge
Hugging Face’s smolagents and 8,900 t/s GUI models are redefining autonomous reliability.
The agentic landscape is currently undergoing a violent correction away from the 'black box' architectures of 2024. Today's release of smolagents by Hugging Face signals a definitive pivot toward 'Code-as-Action'—a philosophy that swaps brittle JSON parsing for direct Python execution. For developers, this isn't just a stylistic choice; it's a performance necessity, yielding a 30% reduction in LLM steps and higher reliability on benchmarks like GAIA. We are moving from agents that 'suggest' actions to agents that 'author' and 'execute' them in real-time.
Simultaneously, the hardware-software barrier is collapsing. With the Holotron-12B model hitting 8,900 tokens per second, local GUI automation is finally fast enough for production desktop use. This issue covers how these two trends—lean code execution and high-throughput local models—are converging with the Model Context Protocol (MCP) to create a standardized, verifiable stack for autonomous systems. Whether you are building research loops with Open DeepResearch or deploying 1.5B-parameter reasoning to IoT devices, the message is clear: the future of agents is transparent, local, and code-first.
Smolagents: The 'Code-as-Action' Pivot for Reliable Autonomous Systems
Hugging Face is fundamentally shifting the agentic paradigm with smolagents, a minimalist library that replaces brittle JSON tool-calling with a 'Code-as-Action' philosophy. By allowing agents to write and execute Python snippets directly, the framework has demonstrated a 30% reduction in LLM steps and operational costs compared to traditional orchestration. This architectural pivot was validated on the GAIA benchmark, where code-based agents outperformed structural parsing methods by bypassing the errors common in JSON-heavy workflows.
The ecosystem's expansion into multi-modal capabilities is marked by the introduction of the VisionCodeAgent, which enables agents to process visual inputs directly within code-generation loops. To address the 'black box' problem in production, the library now integrates with Arize Phoenix for granular tracing and evaluation using OpenInference standards.
This shift toward lean, execution-first architectures is further evidenced by DeepMath, a lightweight math reasoning agent, and the Open-source DeepResearch initiative, which replaces static RAG with autonomous, multi-step search loops.
Local GUI Agents: High-Throughput Desktop Automation
The frontier of local 'Computer Use' has reached a new performance ceiling with the Holotron-12B model, which achieves an unprecedented 8,900 tokens/sec throughput. This speed enables real-time interaction, propelling WebVoyager success rates to 80.5% and reaching 54.2% on Mind2Web cross-task benchmarks. Complementing this is Holo3.1, which focuses on ultra-low latency local execution to ensure agents can react to GUI changes without cloud-induced delays, while the Smol2Operator agent leverages a 'pixel-to-code' philosophy to generate executable Python scripts for desktop control through standardized environments like ScreenSuite.
Open DeepResearch: Scaling Autonomous Information Foraging
Hugging Face has launched Open-source DeepResearch to dismantle the 'black box' monopoly held by proprietary research agents like OpenAI's Deep Research. Built on the minimalist smolagents library, these agents utilize a Code-as-Action philosophy to perform autonomous information foraging, replacing static RAG with dynamic, multi-step search loops and demonstrating a 30% reduction in LLM steps. To scale these capabilities, the Agentic Resource Discovery protocol enables agents to dynamically 'shop' for new tools and models on the Hugging Face Hub, prioritizing verifiable execution and transparency over hidden reasoning.
Standardizing Tool Access with Tiny Agents and MCP
The Model Context Protocol (MCP) is rapidly becoming the universal interface for agentic tool use, enabling developers to deploy tool-enabled agents in as few as 50 to 70 lines of code. By standardizing how LLMs interact with external data, MCP removes the 'integration tax,' allowing a single agent to swap between servers like Brave Search and GitHub without rewriting core logic. The release of the Gradio Agent Inspector further bolsters this ecosystem, providing a specialized UI to visualize and debug complex tool-calling sequences for production-grade autonomous systems.
Multi-Agent Economics and Industrial Benchmarking
CoffeeBench introduces a framework for evaluating LLM agents within heterogeneous multi-agent economies, testing long-horizon negotiation and transactions Hugging Face.
Agentic IoT and 1.5B-Parameter Edge Reasoning
The hardikchadda/hatch-agent-qwen2.5-1.5b model brings agentic reasoning to IoT, enabling sensors to trigger code-execution loops on Arduino hardware.
Transformers Agents 2.0 and Multi-Language Support
Transformers Agents 2.0 introduces a modular 'License to Call' mechanism and Agents.js enables production-grade reasoning directly in browser-based execution layers Hugging Face.
Agentic RL: Verifiable Environments for Alignment
LinkedIn's OpenEnv initiative provides standardized Gymnasium-style APIs for training agents to recover from tool-calling errors via Reinforcement Learning LinkedIn.