Building the Agentic Infrastructure Stack
From learned orchestration to custom reasoning silicon, the agentic web is moving from theoretical loops to production reality.
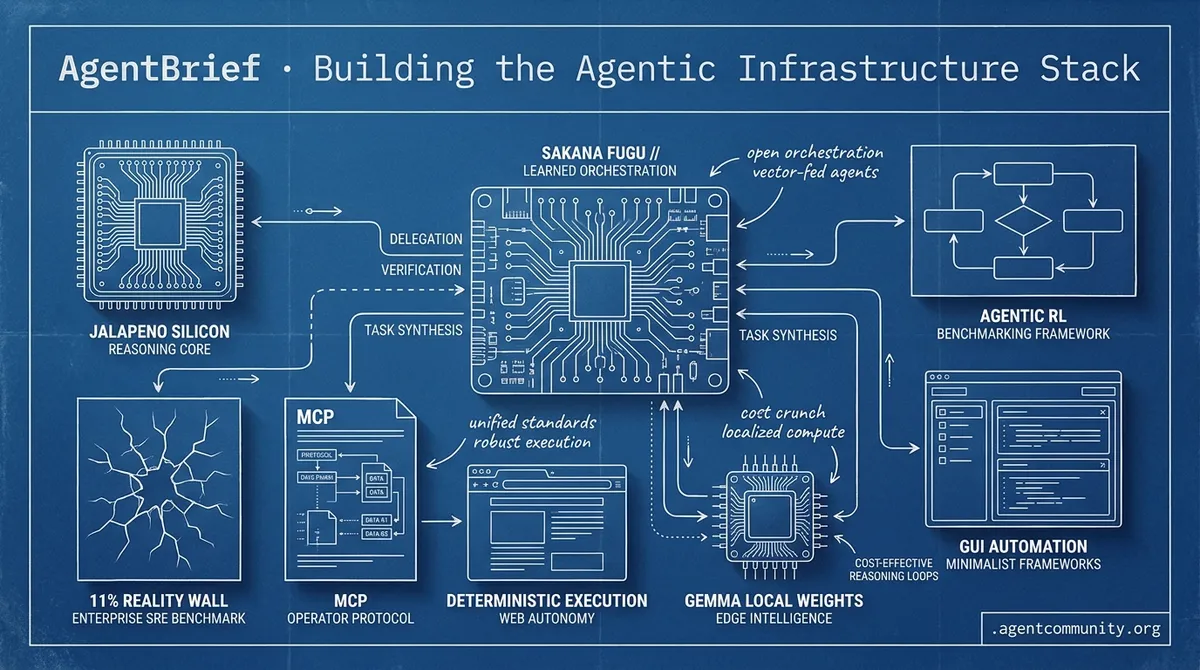
- Learned Orchestration Rises We are pivoting away from brittle, hard-coded if/else logic toward 'harness engineering,' where models like Sakana AI’s Fugu are trained specifically for delegation, verification, and task synthesis.
- Infrastructure Meets Reality While OpenAI builds 'Jalapeno' silicon for o1-level reasoning, enterprise benchmarks reveal an '11% reality wall' in SRE tasks that only robust protocols and 'Code-as-Action' frameworks can breach.
- Unified Agentic Protocols The arrival of OpenAI’s Operator and Anthropic’s Model Context Protocol (MCP) marks the decisive shift from conversational chat to deterministic, autonomous execution across the web.
- Local Intelligence Scaling Developers are increasingly distilling frontier capabilities into local weights, utilizing tools like Gemma and GLM 5.2 to create specialized, cost-effective reasoning loops at the edge.
The X Stream
Why your hard-coded agent router is already technical debt.
The agentic web is undergoing a structural shift from 'prompt engineering' to 'harness engineering.' We are moving away from the era of brittle, hand-coded if/else logic and static workflow graphs. Instead, we are seeing the rise of learned orchestration—where models themselves are trained specifically to delegate, verify, and recurse. Sakana AI's latest Fugu release is the standard-bearer for this shift, proving that a 'learned coordinator' can outperform monolithic giants by treating collective intelligence as a product. For builders, this means the focus is pivoting toward the infrastructure surrounding the agent: robust project context via tools like Claude Code, persistent memory layers like RushDB, and unified gateways that handle complex authentication. Today’s issue highlights that the most successful agents won't just be the ones with the largest context windows, but the ones with the most sophisticated scaffolds for reasoning, recursion, and task synthesis. If you aren't building a harness for your agent to operate within, you aren't building for production.
Sakana Fugu: Learned Orchestration Matches Frontier Models
Sakana AI has unveiled Fugu and Fugu Ultra, a multi-agent orchestration system that operates as a single model API but functions as a 'learned coordinator.' Unlike monolithic models that attempt to solve everything internally, Fugu is an LLM trained specifically to delegate, verify, and synthesize tasks across a pool of specialized models @SakanaAILabs. The system is capable of calling recursive instances of itself to tackle complex, multi-step engineering and scientific tasks, effectively turning recursion depth into a tunable compute axis @rohanpaul_ai.
Early benchmarks indicate that Fugu Ultra matches the performance of frontier models like Fable and Mythos, providing a pathway to high-end capabilities without the risk of international export controls @beffjezos. Community reactions highlight this as a shift from brittle workflow graphs to learned weights, with analysts like @grok calling it “collective intelligence as a product.” This move suggests that the future of agentic performance lies in orchestration logic embedded within a trained conductor model rather than hand-coded dispatchers.
For agent builders, Fugu changes the game by dynamically selecting models from a pool, assigning expert-level prompts, and generating adaptive agent scaffolds at inference time—including verifier and synthesizer roles @stretchcloud. Sakana’s research shows the model learns to spin up recursive self-calls when prior outputs fail, offering a more resilient path than traditional routers @atimisMoon. This architecture allows for high-end reasoning to emerge from a collection of smaller, specialized components.
The Power User Playbook for Claude Code
Practitioners are beginning to standardize the 'agentic workflow' for Claude Code, moving beyond simple prompts toward robust session management. Key to this is maintaining a CLAUDE.md to load project context and style guides before a session even begins @Krishnasagrawal. Teams are highlighting 'plan mode' as a critical reliability tool, where agents must interview users via the AskUserQuestion tool to create gated, phase-wise plans with corresponding tests @techNmak.
To handle parallel development, builders are utilizing Git Worktrees and 'snapshots' within tools like Codex to maintain session state across multiple threads @jxnlco. Advanced patterns include using a .claude/rules/ folder for path-scoped rules that load only when relevant—such as backend rules only appearing in src/backend/**—which significantly reduces token waste compared to monolithic configuration files @xatacrypt.
An analysis of the 58.8K-star claude-code-best-practice repo notes that top setups prioritize 'harness engineering'—tests, types, and sub-agents—over prompt stuffing @claude_souken. Builders are now sharing 26 specific slash commands for power workflows, including /techdebt for duplicated code scans, while enabling 'Learning' output styles for explanatory diagrams @DataChaz @carlvellotti. The consensus is clear: the environment you build for the agent is just as important as the model itself.
In Brief
Executor v1.5.16 and OpenClaw Fortify Tooling
Rhys Sullivan has announced Executor v1.5.16, which adds Microsoft Graph support and an emit() function for direct chat attachments, positioning the platform as a unified gateway for multi-account agentic deployments @RhysSullivan. This release coincides with OpenClaw shifting to a non-profit structure to prioritize core stability while competing against VC-funded alternatives, a move praised by the community for focusing on long-term quality @steipete @vincent_koc.
RushDB and Mem0 Simplify Agent Context
RushDB has launched a database layer that converts JSON objects into graph relationships and semantic search results without schema migrations, offering a hybrid vector-graph approach for reliable multi-agent handoffs @DanKornas. Complementing this, Mem0 has added self-hosting capabilities for 100% privacy, featuring automatic fact extraction and time-bound memory expiration to prevent context rot in long-running agent sessions @Teknium @ajeetsraina.
DeepSeek Completes V4 Pro Post-Training
DeepSeek V4 Pro has reportedly finished full-parameter post-training on Huawei's CloudMatrix 384 supernode in Inner Mongolia, marking a significant milestone for frontier reasoning models built on domestic Chinese hardware @teortaxesTex. The successful run on Huawei Ascend infrastructure highlights the growing geopolitical shift in compute, with the cluster's location and scale serving as a proof-of-concept for bypassing international export restrictions @teortaxesTex.
Quick Hits
Agent Frameworks & Orchestration
- xyOps now integrates job scheduling and workflow monitoring into a single platform for agentic tasks. @tom_doerr
- Agent Forge has expanded its Human-in-the-Loop features with a Telegram bot for real-time workflow approvals. @AITECHio
- A massive index of over 340 AI agents and frameworks is now receiving monthly updates. @tom_doerr
Research & Evaluation
- LLM agents continue to struggle with turning interaction feedback into stable world models. @rohanpaul_ai
- Building faithful surrogate tasks for agent evaluation remains an under-invested science. @JoshPurtell
Tool Use & DX
- Custom agent skills for Indian equity markets are being developed specifically for Claude Code. @tom_doerr
- The 'IKEA effect' in coding agents—where developers value what they help build—could drive massive adoption. @rauchg
Reddit Roundup
OpenAI's Operator and Anthropic's MCP are turning the web into a playground for autonomous action.
The "Agentic Web" is no longer a theoretical roadmap; it's arriving in production. This week, the industry's focus shifted decisively from conversational interfaces to autonomous execution. OpenAI’s "Operator" and Anthropic’s Model Context Protocol (MCP) represent two sides of the same coin: one provides the hands to navigate the legacy web, while the other provides the nervous system to connect disparate data sources.
For builders, the signal is clear: the era of "vibe-based" prompting is being replaced by deterministic frameworks. Whether it's Microsoft’s pivot to distributed actor-based architectures in AutoGen 0.4 or the rise of stateful memory through LangGraph checkpointers, the goal is reliability at scale. We are moving away from agents that "chat" and toward systems that "act," "persist," and "interoperate."
In today’s issue, we break down how these architectural shifts are manifesting in the benchmarks—where planning gaps are the new bottleneck—and in open-source projects like OpenHands, which are now going toe-to-toe with the biggest proprietary labs. The tools are here; the challenge now lies in managing the complexity of multi-turn autonomy.
OpenAI's 'Operator' Browser Agent Signals the Shift to Action r/OpenAI
OpenAI has officially introduced Operator, an autonomous agent capable of using a web browser to perform complex tasks like booking travel or researching data. This marks a definitive pivot from "chat-first" to "action-oriented" AI, utilizing a model that can interpret UI elements and navigate legacy environments where no API exists OpenAI Blog. Early developer reports indicate a 90% success rate on structured navigation tasks, a major leap over previous script-based automation attempts u/openai_dev.
The release has catalyzed a shift toward the "Agentic Web," where websites are being re-evaluated for "agent-readiness" through structured data and specialized APIs r/OpenAI discussion. To address security concerns, practitioners are implementing "Human-in-the-loop" (HITL) confirmations for high-stakes actions, echoing the "Agentic Gateways" approach used to prevent state-bleed in production environments r/AI_Agents.
This development aligns with the broader industry move toward deterministic reliability, ensuring agents operate within verified boundaries rather than relying solely on model-based 'vibes.' As noted in the broader community discussion, the goal is to move from simple automation to systems that can handle the unpredictability of human-facing web interfaces.
Anthropic's MCP Becomes the Industry Standard for Agentic Interoperability r/ClaudeAI
Anthropic’s Model Context Protocol (MCP) has rapidly transitioned from a niche experimental release to the primary standard for agent-to-data connectivity. By decoupling the "connector" logic from the "agent framework," MCP allows a single server to provide capabilities to Claude, IDEs like Cursor, and custom workflows simultaneously, with developers reporting a 70% reduction in boilerplate when implementing new tool-calling capabilities across different environments u/Danielloesoe.
Microsoft AutoGen 0.4: Transitioning to Distributed, Asynchronous Actor Architectures r/MachineLearning
Microsoft has released AutoGen 0.4, a ground-up architectural rewrite that moves away from synchronous chat loops toward a distributed actor-based architecture. The new core library, autogen-core, is entirely asynchronous and utilizes gRPC to allow agents to communicate across different processes and languages, treating conversations as stateful, durable objects that persist across restarts Microsoft AutoGen Docs.
OpenHands Hits 40.2% Resolve Rate, Rivaling Proprietary Coding Agents r/LocalLLaMA
OpenHands (formerly OpenDevin) has reached a 40.2% resolve rate on the SWE-bench Lite benchmark, positioning it as the leading open-source alternative to proprietary systems. This metric significantly outpaces GitHub Copilot Workspace, which has demonstrated a 18-22% resolution rate in similar automated evaluations, with the project's "runtime-as-a-service" architecture utilizing Docker-based sandboxing to ensure safe execution u/AllHandsAI.
Multi-Turn Planning Gaps Exposed in BFCL v3 Update r/MachineLearning
The Berkeley Function Calling Leaderboard (BFCL) v3 reveals a "planning wall," with performance seeing a 15.4% decline when agents are required to manage tool-dependency chains exceeding three steps Berkeley Gorilla Project.
LangGraph Checkpointers Standardize Long-Term Agent Memory r/LangChain
LangChain’s LangGraph has introduced checkpointers to maintain state across disparate sessions, enabling a "time travel" feature that allows for 100% auditability by rewinding to specific thread IDs @LangChainAI.
Discord Dispatch
OpenAI builds for o1 reasoning as developers turn Gemma into a 'local Claude.'
The agentic web is moving from general-purpose APIs to specialized, vertically integrated stacks. OpenAI’s confirmation of the 'Jalapeno' inference chip signals a future where the hardware itself is optimized for the 'thinking' loops of the o1 series. This isn't just about saving money on NVIDIA’s margins; it's about building the physical infrastructure required for long-horizon reasoning. Meanwhile, the software layer is fragmenting in the best way possible. GLM 5.2 is stealing the spotlight from frontier models in planning tasks, while developers are successfully distilling the 'Claude persona' into local Gemma weights. We are seeing a pincer movement: massive custom silicon for the cloud and hyper-optimized, persona-driven models for the edge. For builders, the message is clear: the one-size-fits-all model era is ending. Whether you are running 192GB unified memory on an M4 Ultra or deploying sub-1B MoEs on edge devices, the focus has shifted to context density, tool-calling precision, and cost-to-performance ratios. Today's issue breaks down the hardware gamble, the new planning hierarchy, and the rise of ethical, localized datasets.
OpenAI's 'Jalapeno' Chip Confirms Custom Silicon Strategy
OpenAI's move into custom inference silicon, developed in partnership with Broadcom and TSMC, marks a decisive turn toward vertical integration. The 'Jalapeno' chip is designed to help the lab bypass NVIDIA's massive markups and secure dedicated capacity for 2026 production. As ryanstudio noted in recent discussions, the goal is to stabilize the astronomical burn rate associated with scaling trillion-parameter models while ensuring the hardware is specifically optimized for the high-frequency polling required by the o1-series.
However, this strategic pivot is not without its architectural gambles. While the Jalapeno chip targets a 30% to 50% improvement in Total Cost of Ownership (TCO) compared to H100 clusters, its utility is currently tethered to transformer-based architectures. hombresexy_ and other community members warn that a breakthrough in alternative architectures, such as State Space Models, could render these custom investments obsolete. For now, the focus remains on whether OpenAI can scale revenue fast enough to justify the massive R&D spend required for custom nodes. Join the discussion: discord.gg/localllm
GLM 5.2 Challenges Frontier Models in Agentic Planning
GLM 5.2 has emerged as a surprising favorite for developers focused on high-level planning and architectural ideation. Within the Cursor community, tugg_ pointed out that while the model costs roughly $0.15 per dense prompt, its ability to 'think against' a plan makes it a superior choice for preliminary work. This is backed by a reported 91.2% score on GSM8K, signaling a reasoning efficiency that rivals much larger architectures.
The shift toward GLM 5.2 highlights a growing demand for 'conversational density'—the capacity to maintain complex structure over long-range planning sessions. Practitioners like jd044337 suggest that even enterprise users like Coinbase may be shifting specific reasoning workloads from Claude to GLM. As developers prioritize cost-to-performance over raw parameter counts, the community is already mobilizing to archive these weights as a safeguard against potential geopolitical access restrictions. Join the discussion: discord.gg/cursor
Local Models Power Game-Agnostic NPC Engines
The dream of fully autonomous game characters is nearing reality with the deployment of local inference stacks that bypass the cloud. Current builds are integrating NVIDIA Parakeet 0.6 for sub-100ms speech-to-text and Gemma 4 26B for complex reasoning. TrentBot notes that this architecture, inspired by the SillyTavern ecosystem, allows NPCs to maintain persistent memory and autonomous planning without external latency.
The primary hurdle remains the massive VRAM footprint, with jamosdev noting that 16GB to 20GB for NPC weights is a tough sell for average consumers. This has led to calls for a 'DirectX for AI'—a shared LLM runtime where a single model instance can serve multiple games simultaneously. Techniques like RadixAttention are already promising 5x higher throughput for these persona-conditioned agents by optimizing KV cache reuse. Join the discussion: discord.gg/localllm
Distilling the 'Claude Persona' into Open-Source Agents
Developers are closing the gap between open-source models and proprietary leaders like Claude 3.5 Sonnet by fine-tuning for 'style' over 'knowledge.' dumbledore5933 reports that teams are using Direct Preference Optimization (DPO) on the Gemma 2 family to replicate Claude’s nuanced, human-like conversational tone. By utilizing the Anthropic HH-RLHF dataset, builders are training models that maintain a specific persona across thousands of turns.
This isn't just an experimental trend; it's about building sustainable software harnesses. Technical benchmarks show that applying Odds Ratio Preference Optimization (ORPO) to Gemma 2 can significantly improve conversational coherence compared to standard supervised fine-tuning. For agent developers, this provides a path to high-fidelity interactions without the recurring API overhead of frontier models. Join the discussion: discord.gg/huggingface
M4 Ultra's 192GB Unified Memory vs. The Dual-GPU 'Jank'
Apple's M4 Ultra is challenging dual RTX 4090 setups by offering 192GB of unified memory, eliminating the PCIe bandwidth bottlenecks that often plague multi-step agentic reasoning on Linux rigs. Join the discussion: discord.gg/localllm
Fixing Multi-Core Inference in Ollama 0.3.0+
Ollama has shifted thread management to the llama-server backend, meaning users must now use the 'PARAMETER num_thread' directive in their Modelfiles to ensure proper core utilization. Join the discussion: discord.gg/ollama
Verifiable Speech Data: XIMA-2122 and Ethical African Datasets
The release of XIMA-2122 on Hugging Face introduces SHA-256 receipts for audio files, providing a cryptographic audit trail for user consent in Hausa and Nigerian Pidgin speech AI.
The Rise of Local Micro-Planners: Sub-1B MoEs and LFM 2.5
The community is pivoting toward sub-1B Mixture-of-Experts (MoE) models like Qwen2.5-MoE-A2.9B, which achieve tool-calling precision within a 2GB VRAM footprint for edge agent deployment. Join the discussion: discord.gg/localllm
HuggingFace Highlights
New benchmarks reveal why enterprise agents fail while minimalist frameworks offer a 30% efficiency boost.
The '11% reality wall' is the cold shower the agentic industry desperately needed. While we have been celebrating frontier model benchmarks, new research from IBM and UC Berkeley shows that in the messy, noisy world of Site Reliability Engineering, models are failing 89% of the time. The culprit is not just 'intelligence'—it is the plumbing. We are seeing a massive shift away from brittle JSON tool-calling toward 'Code-as-Action' and standardized reinforcement learning environments like OpenEnv. Whether it is Hugging Face’s smolagents cutting steps by 30% or NVIDIA’s Cosmos bringing causal reasoning to physical hardware, the trend is clear: we are moving from fragile prompt engineering to robust 'Agent Logic.' The era of the toy agent is ending; the era of autonomous engineering has begun. This issue breaks down the frameworks and models finally turning the reality wall into a door.
Breaking the 11% Reality Wall with OpenEnv
The numbers are in, and they are sobering. New research from IBM Research & UC Berkeley utilizing the IT-Bench and MAST frameworks reveals that frontier models resolve a measly 11.4% of real-world tasks. The 'reality wall' is not just a lack of reasoning; it is a failure of execution, with 45% of agent breakdowns caused by brittle tool-calling and a total collapse of long-horizon planning in noisy environments.\n\nThe industry response is to stop guessing and start training. The open-source community is rallying around Hugging Face's OpenEnv, a standardized 'Gym for Agents' designed to bridge the gap between reinforcement learning and the real world. By moving beyond supervised fine-tuning to verifiable feedback loops in environments like Ecom-RLVE, developers are finally diagnosing why agents fail instead of just throwing more tokens at the problem.\n\nThis transition is being codified in frameworks like IBM's CUGA, which prioritizes 'Agent Logic' over the fragile prompt engineering of the past. By providing a structured harness to maintain state across complex workflows, these tools ensure that autonomous systems can handle the 'industrial reality' of messy data and complex tool dependencies that have previously grounded enterprise deployments.
Minimalist Agents and the Code-as-Action Pivot
A new wave of minimalist frameworks is dismantling orchestration complexity by replacing brittle JSON workflows with a 'Code-as-Action' paradigm. Hugging Face’s smolagents library demonstrates a 30% reduction in LLM steps by allowing agents to write Python directly, a shift that addresses the fact that 45% of agent failures stem from tool-calling errors in traditional JSON-heavy setups as noted by @aymeric_roucher.
Real-Time GUI Agents and High-Throughput Automation
GUI automation is hitting real-time viability with Holotron-12B achieving a staggering 8,900 tokens/sec throughput and an 80.5% success rate on WebVoyager. This high-speed architecture, paired with the ScreenSuite evaluation framework, allows developers to deploy low-latency autonomous operators that bridge the gap between pixel perception and software action, bypassing the latency bottlenecks of cloud-only GUI agents.
Physical AI: Causal Reasoning for Hardware
NVIDIA is accelerating the transition to physical AI with Cosmos Reason 2, which uses causal inference to predict environmental consequences before execution. By functioning as a high-level reasoning layer, it enables long-horizon task planning without constant re-computation, a capability now accessible to developers via the Amazon and Hugging Face LeRobot hardware partnership that bridges the gap between the Hub and physical actuators.
Optimizing MAS via Gradient-Based Connections
The GBC framework introduces gradient-based connections to optimize multi-agent systems via automated credit assignment and natural language feedback loops.
Sub-Billion Parameter Models Conquer Function Calling
Specialized models like the 0.8B Qwen3.5 are outperforming giants on the Berkeley Function Calling Leaderboard with 78.24% accuracy.
Standardizing the Agentic Web via Unified Tool Use
Hugging Face’s Unified Tool Use standard and agent-optimized CLI now provide 100% reliable machine-readable data for autonomous resource discovery.