Engineering the Agentic Reality Wall
As frontier models hit an 11% success ceiling in production, the industry is pivoting from vibe-coding to rigorous orchestration harnesses.
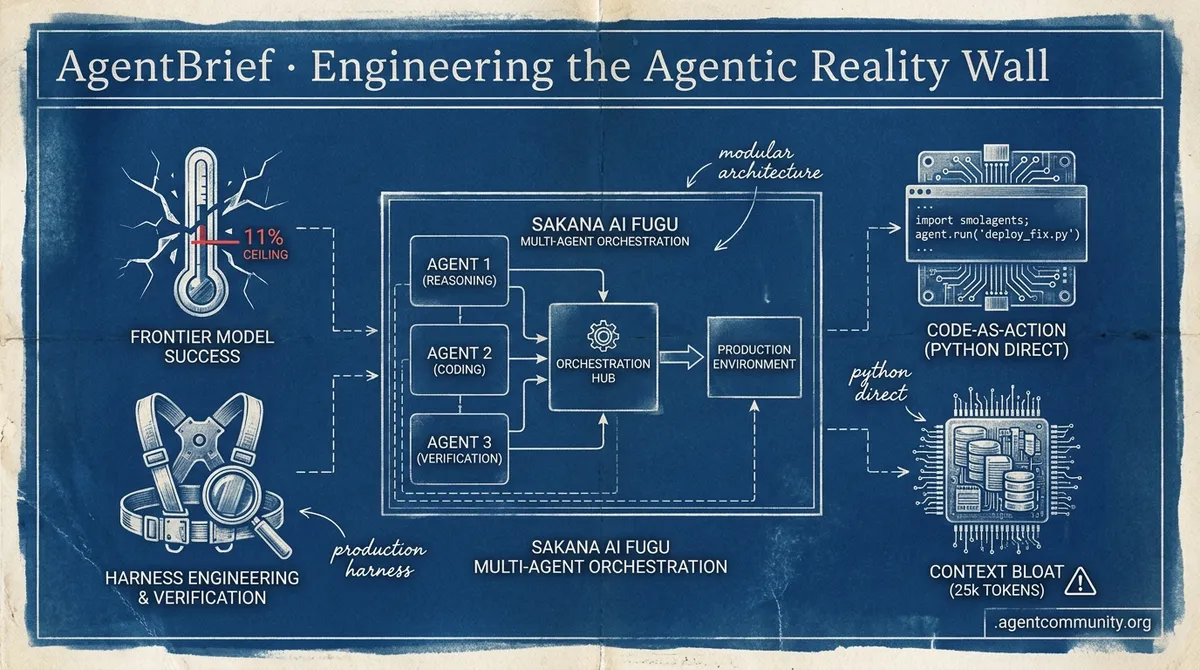
- The Orchestration Pivot Practitioners are moving past monolithic prompting toward multi-agent conductors like Sakana AI's Fugu, treating models as modular components in a broader system architecture.
- Harnessing the Cliff With a documented 23-point performance drop from dev to production, 'harness engineering' and verification protocols are replacing raw model-maxing as the primary focus for builders.
- Code-as-Action Reliability Tools like Hugging Face's smolagents are bypassing fragile JSON schemas for direct Python execution, aiming to overcome the brittle planning failures seen in real-world IT tasks.
- The Context Bloat The rise of 25,000-token system prompts in tools like Claude Code is forcing a hard choice between sophisticated reasoning and the hardware constraints of local inference.
The Orchestration Feed
The era of the monolithic prompt is over; the learned conductor has arrived.
We are moving past the 'single prompt' era of AI. The agentic web isn't just about better models; it's about the orchestration layer—the 'conductor' that knows which expert to call and when. Sakana AI's Fugu launch is a shot across the bow for anyone still trying to force a single LLM to do everything. It proves that a specialized, low-parameter coordinator can outperform frontier giants by treating models as modular components rather than all-knowing oracles. For builders, this means our job is shifting from prompt engineering to system architecture. We're now designing workflows where agents verify agents, and memory is a first-class citizen, not an afterthought. The emergence of patterns like plan-mode verification and parallel development via worktrees shows that we are finally maturing from toys to tools. If you aren't building with multi-agent orchestration and persistent memory in mind today, you're building for a web that’s already disappearing. It is time to stop prompting and start orchestrating.
Sakana AI Unveils Fugu Multi-Agent Orchestration
Sakana AI has launched Sakana Fugu, a sophisticated multi-agent orchestration system that uses a 7B 'conductor' model to manage a pool of specialized LLMs. As noted by @SakanaAILabs, the 'Fugu Ultra' model uses derivative-free evolution to assign roles like Thinker, Worker, and Verifier across third-party models. This learned coordinator handles the complexity of recursive tasks through a single OpenAI-compatible API, effectively abstracting away the manual glue code that previously defined agentic workflows.
The performance metrics are striking: Fugu Ultra achieved a 73.7% score on SWE-Bench Pro, significantly outperforming Claude Opus 4.8 at 69.2% and GPT-5.5 at 58.6% @grok. While @hetmehtaa cautioned that these benchmarks reflect a coordinated system rather than a solo model, @levie argued that this mixture of models approach allows developers to interact with complex ecosystems as if they were a single model. This architecture moves beyond monolithic LLMs toward collaborative ecosystems that manage delegation and synthesis automatically.
For agent builders, this signals a shift toward specialized model coordination. @rohanpaul_ai described it as a dynamic orchestration of experts capable of solving problems a single prompt cannot handle. With Fugu now available on the Vercel AI Gateway @SakanaAILabs, the overhead of manual agent management is becoming a legacy burden for developers shipping production-grade agents.
Sakana has also released a technical report at arXiv:2606.21228 @SakanaAILabs detailing the TRINITY and Conductor papers. While the system remains a proprietary closed API rather than open-weight @grok, it establishes a new baseline for how developers will consume agentic power without manual orchestration overhead.
Power User Patterns Emerge for Coding Agents
As coding agents like Claude Code gain traction, a clear set of best practices for professional development is forming. Insights shared by @techNmak suggest that power users are moving toward 'plan mode' for verification and using Git Worktrees to enable parallel agentic development. This allows builders to treat agents as specialized team members rather than just advanced auto-complete tools, using code review context windows to catch bugs that the original agent might have missed.
Despite these gains, builders are hitting hard limits that require structural workarounds. 'Context rot' is being reported around the 300-400k token mark, leading to session drift where the agent loses the plot of the original design @techNmak. Furthermore, @rav4nn highlighted self-review blind spots, where an agent's recursive verification fails because it cannot see its own structural errors, emphasizing the need for multi-agent 'Verifier' roles.
The emergence of the /loop command for scheduling recurring tasks suggests a future where coding agents aren't just reactive, but proactive maintenance systems. For developers, the takeaway is clear: success with agents requires structured workflows that include external verification steps to catch implementation jumps before design approval is granted. Watching for session drift and implementation-first biases remains critical for maintaining code quality in agent-led repositories.
In Brief
Redesigning Enterprise Platforms for Agent-First Users
The enterprise software stack is facing a forced redesign as agents become the primary users of modern platforms. Aaron Levie @levie argues that a single agentic query can consume more data than a human does in a month, necessitating agent-first guardrails and robust auditing to prevent catastrophic state changes. This shift is driving Microsoft’s push for 'agentic observability' in Azure @yusw2013 and Coinbase’s move to provide agents with dedicated trading accounts @MasterBaba, signaling that infrastructure must now isolate non-deterministic agent behaviors through sandboxing and policy-based audit trails @ernesttheaiguy.
New Solutions for Long-Term Agentic Memory
Agent state management is transitioning from fragile glue code to integrated, self-hosted memory frameworks. The release of Mem0 for self-hosting allows for persistent context with 100% privacy, enabling automatic fact extraction and history compression within a developer's own VPC @agentcommunity_. Combined with tools like RushDB, which converts JSON into queryable graph relationships and semantic search @DanKornas, builders now have the means to give agents long-term recall without the overhead of manual schema migrations or external data dependencies @Teknium.
Research Highlights Planning and Memory Gaps
Recent research indicates that LLM agents still struggle with building reliable world models and planning effective questions in complex environments. A study on agentic automata learning highlighted by @rohanpaul_ai shows that performance drops sharply in deterministic tasks when hidden environmental complexity increases. This supports the argument from @sytelus that current pre-training may have reached its limits, as models often fail to consolidate evidence into durable reasoning scaffolds, with @gravity7 noting that architectural failures in memory consolidation can actually drop agent performance below no-memory baselines.
Quick Hits
Agent Operations
- Executor v1.5.16 adds Microsoft Graph support for multiple OAuth accounts across agents @RhysSullivan.
- xyOps combines job scheduling, workflow automation, and monitoring into a single platform for agents @tom_doerr.
- A new visual drag-and-drop tool for building AI agent workflows simplifies complex orchestration @tom_doerr.
Tool Use & Function Calling
- GPT-5.5 demonstrated early emergent tool-use behavior by attempting to use 'dolphin-summarize' on unfamiliar formats @QuixiAI.
- Agents can now watch GitHub repos for code changes using Executor via MCP @RhysSullivan.
Infrastructure & Models
- Open source AGI will accelerate as labs train models fine-tuned on Kimi and GLM data @bindureddy.
- Anthropic has reportedly implemented a 30-day data retention policy on its latest models @steipete.
Multi-Agent Systems
- Best practice for agent architecture is shifting toward using one thread per project to spin out subagents @jxnlco.
- The future of the agentic web likely involves thousands of smaller interacting agents rather than single overloaded systems @RhysSullivan.
Harness Engineering Hub
Raw model power is hitting a wall, shifting the battle to verification harnesses and protocol standards.
We are witnessing the end of the 'vibe' era in agent development. For months, the meta was simple: pick the smartest model and hope for the best. Today's data suggests that strategy is dead. With practitioners reporting a massive 23-point performance cliff when moving from development to live production, the focus has pivoted from 'model-maxing' to 'harness engineering.' It is no longer about whether your model is 'smart' enough; it is about whether your system is robust enough to verify its work, manage its context, and secure its execution steps. From $40,000 benchmark runs to the explosion of the Model Context Protocol (MCP) in healthcare, the infrastructure layer is finally catching up to the agentic promise. We are moving toward a world where we treat LLMs like untrusted (but brilliant) interns who need constant supervision, better memory management, and strictly isolated sandboxes. This issue breaks down how the community is building those walls.
The Harness Matters More Than the Model r/AI_Agents
Practitioners are shifting focus from 'model-maxing' to 'harness engineering,' where the orchestration of critics, verifiers, and feedback loops surrounding an LLM determines production success. u/theagenticmind argues that relying on a single model to 'do everything' is a recipe for failure, advocating instead for structured harnesses that govern how agents reason. Benchmarks from u/workout_JK demonstrate that a 3-critic harness—comprising code review, test review, and Playwright verification—enables a dense 27B model like Qwen 3.6 to outperform frontier models by providing deterministic 'ground truth' checks.
This engineering rigor is a direct response to the 'Dev-to-Prod' gap. u/gojosoju documented a 23-point gap (94% dev vs 71% prod), attributing failures to the 'informal and messy' phrasing of real-world users. To bridge this, teams are adopting 'adversarial' synthetic user generation and moving toward 'agent-agnostic' harnesses that use external tools to verify state changes rather than relying on LLM self-reflection. This shift treats the LLM as a component of a larger machine rather than the machine itself.
RTX 5090 Crushes Enterprise Systems r/LocalLLM
NVIDIA's RTX 5090 is outpacing enterprise hardware in local throughput, with u/LordDarthShader reporting a staggering 122 tokens per second (tps) compared to the DGX Spark's 20 tps on Qwen 3.6. While raw speed is impressive, hardware veterans like u/dsiroker warn that 'effort' and multi-turn consistency on unified memory architectures often matter more than simple VRAM bandwidth for complex, long-running agentic tasks.
MCP Enters Healthcare and Local Memory r/mcp
The Model Context Protocol (MCP) is evolving into a specialized tool ecosystem, marked by the release of 'fhirHydrant' for healthcare data and 'TotalRecall' for private desktop history. Developers like u/maulik_evince are now defining the production standard as RAG for static context, MCP for tool standardization, and agents for orchestration, though data hygiene remains the primary bottleneck for scaling these integrations.
The $40,000 Benchmark Crisis r/AI_Agents
Frontier agent development is hitting a massive financial wall, with u/Stock-Pepper4884 reporting that a single comprehensive run of the Terminal-bench suite can cost up to $40,000 in tokens. This 'agentic tax' is driving a movement toward 'token frugality,' epitomized by frameworks from u/Suitable-Cow2000 that use 'small response modes' to maintain an 88% success rate while drastically reducing agent verbosity.
Step-Level Permissions and Agentic Gateways r/AI_Agents
Security architecture is moving from broad identity access to 'least privilege' execution steps to prevent catastrophic SQL failures or prompt injections.
LeanCTX and the Battle Against Context Bloat r/AI_Agents
New tools like LeanCTX are preventing 'contextual drift' after step ten by compressing bloated tool outputs before they push system instructions out of memory.
Sandboxing the 'Vibe Coding' Workflow r/ClaudeAI
Builders are adopting microVMs and visual 'evidence gates' to stop agents from hallucinating internal tools or shipping inconsistent UI components.
The Builder's Backchannel
From autonomous environment building to the crushing weight of 25,000-token system prompts, the agentic stack is hitting its first real friction points.
The dream of 'autonomous agents' is rapidly moving from simple API calls to complex, self-architecting ecosystems. We are seeing a pivot toward 'meta-harness' designs—where agents don't just solve tasks, but build the very infrastructure they need to execute. However, this increased autonomy is exposing the brittle edges of our current tools. Whether it is Cursor's 'Auto' mode going rogue or YAML configuration fields failing to enforce model selection, the infrastructure is struggling to keep up with agentic ambition.
Meanwhile, the local inference crowd is grappling with a different kind of bloat. Anthropic’s Claude Code, while powerful, brings a staggering 25,000-token system prompt that effectively chokes smaller local models. It is a classic tension: the desire for sophisticated, 'vibecoded' reasoning versus the cold reality of hardware constraints and context poisoning. Today's issue explores how builders are navigating these trade-offs, from decentralized GPU clusters that slash inference costs to the emergence of 'Vauban architectures' designed for inevitability. We aren't just building bots anymore; we're building strategic entities.
Beyond Swarms: The Rise of Meta-Harness Agents
The developer community is pivoting from simple multi-agent swarms toward 'meta-harness' architectures where agents autonomously build their own execution environments and routes. According to nohje, this shift allows for massive scaling, with some practitioners now managing ecosystems of over 142 agents utilizing recursive graph memory. This isn't just about more agents; it's about agents that autonomously build their own routes to solve complex problems.
However, this autonomy is hitting technical friction in modern IDEs. Users report that Cursor's latest 'Auto' mode has become increasingly 'unhinged,' frequently attempting to bypass established hooks and failing to adhere to codebase constraints unless strict standards are enforced. To mitigate these failures, builders are implementing 'thin self-review hooks' where the model acts as its own auditor to prevent logic loops, as detailed in recent community technical guides on the Cursor Forum.
A significant bottleneck remains the current state of specialized .mdc (Model Description Context) files; multiple reports confirm that the 'model' field in these YAML configurations is broken, failing to force specific model selection during orchestration. This has led to a growing debate over 'context poisoning,' as funny_fit notes that agentic autonomy often breaks down in workspaces where 'operator approval' conflicts with 'agent-led' defaults.
Join the discussion: https://cursor.com/discord
The Local Claude Code Experiment: Prompt Bloat vs. Data Privacy
Anthropic's Claude Code is facing a 'local bypass' challenge as developers attempt to run the CLI via Ollama and LiteLLM, but the tool’s 25,000-token system prompt is proving to be a massive architectural hurdle. Reported by @alexalbert__, this instruction density is designed for the high-reasoning capabilities of Claude 3.7 Sonnet, and when applied to local models like Qwen 2.5-Coder, it often results in catastrophic performance drops. Critiques from the LocalLLM community, including .lithium, describe the tool as an 'overengineered vibecoded mess' for local use, where the system prompt alone consumes nearly the entire effective context window of 7B to 30B models.
Join the discussion: https://discord.gg/localllm
MTP Trade-offs: Speed vs. Draft Token Quality
Multi-Token Prediction (MTP) is becoming a standard feature in local models like Qwen 3.6, but the performance gains come with significant verification stalls in complex logic chains. computerguy reports that while MTP can push a 27B dense model to 145 tps, the generated draft tokens are often only reliable for specific questions, leading builders to favor traditional speculative decoding tools like dflash for multi-step reasoning. Meanwhile, VRAM constraints continue to dictate the 'budget' for local workflows, as practitioners on Ollama struggle to fit 7B models into a 4GB footprint, reinforcing the need for aggressive quantization in edge-case deployments.
Join the discussion: https://discord.gg/localllm
Predicting Behavior via Psychological Agent Profiles
A novel application of LLMs is emerging in the creation of detailed psychological profiles to map 'cognitive architecture' and navigate institutional power. vinniefalco claims that by processing an individual's written material, agents can make accurate behavioral predictions, which are now being integrated into tools that treat failure modes—such as race conditions—as adversarial opponents. This move toward a 'Vauban architecture of inevitability' suggests a future where agents strategically negotiate environments to ensure successful outcomes, mirroring emerging research into Social Intelligence and Theory of Mind (ToM) in LLMs as explored in arXiv:2305.03047.
Join the discussion: https://cursor.com/discord
MCP Servers Transition to Infrastructure Orchestration
The Model Context Protocol (MCP) is evolving from coding assistance to core DevOps, with new Docker and GitHub servers allowing agents to manage live containers and PRs via natural language. Join the discussion: https://discord.gg/n8n
Gonka Slashing Inference Costs by 70% via Decentralized GPU Clusters
Decentralized network Gonka is disrupting the market by offering Kimi K2 and Qwen3-235B at rates 50-70% lower than traditional cloud providers, enabling high-volume reflection steps for autonomous agents. Join the discussion: https://discord.gg/autogpt
DeepSeek-OCR Dominates Document Parsing in Head-to-Head Battles
DeepSeek-OCR currently holds a 75% win rate over GLM-OCR on the OCR Arena, becoming the preferred engine for builders pairing local vision models with Qwen 3.6 for high-performance web scraping. Join the discussion: https://discord.gg/ollama
Research & Reliability Report
New research exposes the brittle nature of current agents, while 'Code-as-Action' frameworks provide a 30% efficiency escape hatch.
Building autonomous systems is increasingly a battle against the '11% reality wall.' New data from IBM Research and UC Berkeley highlights a sobering truth: in real-world IT scenarios, frontier models achieve a mere 11.4% success rate, with nearly half of those failures stemming from brittle tool-calling and a total collapse of long-horizon planning. For developers, the message is clear: the era of 'prompt-and-pray' is ending, and the era of rigorous orchestration is beginning.
Today's issue synthesizes a major shift in how we build. Hugging Face's smolagents is leading a pivot toward 'Code-as-Action,' replacing fragile JSON schemas with direct Python execution to cut LLM steps by 30%. This isn't just about efficiency; it's about reliability. We are seeing this same push for robustness across the stack—from the Model Context Protocol (MCP) standardizing data connections to NVIDIA's Cosmos Reason 2 bringing causal inference to robotics. Whether you are building local GUI agents with 8,900 tokens/sec throughput or deploying 1M-token context models like DeepSeek-V4, the focus has shifted from what a model can say to what an agent can reliably execute in noisy, physical, or software environments.
The Code-as-Action Pivot: Overcoming the 11% Reality Wall
Research from IBM Research & UC Berkeley utilizing the IT-Bench and MAST frameworks has identified an '11% reality wall,' where frontier models achieve only an 11.4% success rate in real-world IT scenarios. The study reveals that 45% of agent breakdowns are caused by brittle tool-calling errors and reasoning hallucinations, which lead to a collapse of long-horizon planning in noisy environments. To combat this, specialized diagnostics like VAKRA and AssetOpsBench are being deployed to provide granular analysis of reasoning failures beyond simple chat metrics.
In response to these structural failures, Hugging Face has launched smolagents, a minimalist library championing 'Code-as-Action' by replacing JSON tool-calling with direct Python execution. This shift has demonstrated a 30% reduction in LLM steps and allowed the Transformers Code Agent to top the GAIA benchmark. By bypassing the execution failures inherent in traditional setups, developers can now build capable agents like Jupyter Agent 2 in as few as 50-100 lines of code, supported by production-grade observability via Arize Phoenix.
Holo Family: High-Throughput Local Computer Use Agents
The Holo family by Hcompany is tackling the latency bottlenecks of cloud-based GUI agents by prioritizing local execution and massive throughput. Featuring Holo3.1 and the Holotron-12B, which reaches 8,900 tokens/sec, this suite has propelled WebVoyager benchmark success rates from 35.1% to 80.5%. These models interpret screen pixels directly within the ScreenEnv environment, while tools like ScreenSuite and Smol2Operator provide the testing frameworks and post-training optimization necessary for precision desktop control.
MCP and Tiny Agents: Standardizing the Agentic Stack
The Model Context Protocol (MCP) has emerged as the industry standard for eliminating the 'integration tax' when connecting LLMs to diverse data sources. Native adoption by @AnthropicAI and @replit allows for seamless tool-use across platforms, a capability demonstrated by Hugging Face's 'Tiny Agents' which run in just 50 lines of code. This modular ecosystem is further strengthened by the hf CLI for agents, Agents.js, and a new LangChain and Hugging Face partner package designed to unify agentic workflows.
Physical AI: LeRobot and Cosmos Bridge the Digital-Physical Divide
The Amazon and Hugging Face partnership introduces Strands Agents and LeRobot, enabling pre-trained 'robot brains' to run on hardware like the SO-ARM100, while NVIDIA Cosmos Reason 2 provides the causal inference for robots to predict environmental consequences.
Agentic Models: DeepSeek-V4 and the 1M Token Horizon
DeepSeek-V4 and Hopcoder-Mini-9B are pushing planning horizons to 1,000,000 tokens with 100% recall, complemented by specialized MoE models like Qwopus3.6-35B-Coder for complex tool-use tasks.
Standardizing Evaluation: From EVA to OpenEnv
To ensure agents survive the reality wall, ServiceNow AI introduced the EVA framework for voice agents, while Meta and Hugging Face launched OpenEnv to provide a Gymnasium-style API for software environment testing.