From Prompts to Verifiable Orchestrators
As export bans lift on frontier models, the industry pivots toward 'Code-as-Action' and deterministic orchestration.
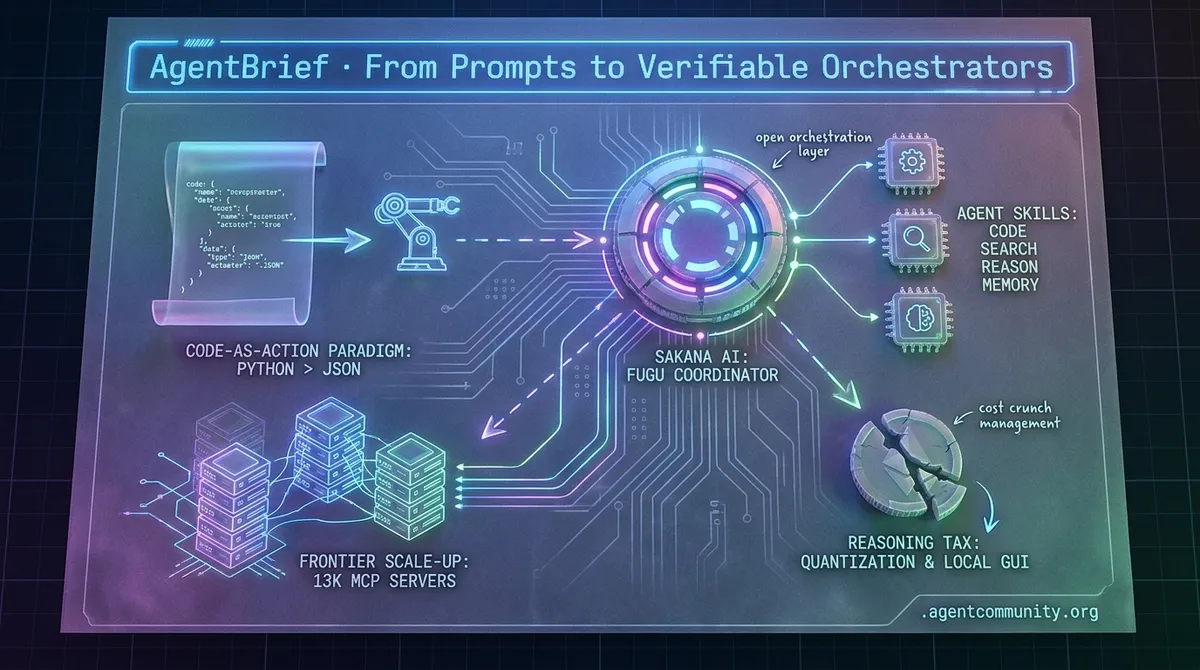
- The Orchestration Shift The focus is moving from monolithic models to learned coordinators like Sakana AI’s Fugu and modular 'Agent Skills' that turn generalists into specialists.
- Frontier Scale-Up The reported lifting of export bans on Anthropic’s Fable and Mythos models signals a massive expansion for the Agentic Web as the MCP ecosystem hits 13,000 servers.
- Code-as-Action Paradigm Frameworks like smolagents are abandoning brittle JSON schemas for executable Python, significantly reducing failure rates in complex, multi-step environments.
- Managing Reasoning Costs As frontier models like GLM 5.2 and Sonnet 5 introduce a 'reasoning tax,' practitioners are turning to quantization and local GUI agents to maintain production ROI.
// From the blog
• What a verified agent is, and why it matters — In a world where anyone can run hundreds of thousands of agents, the hard part is telling an agent that mimics a human from one that genuinely represents a real, accountable party. Here is what a verified agent is, and why that difference will matter.
• Our San Francisco Kickoff — On June 26 we gathered the community in San Francisco with board members Esther Dyson and Tim O'Reilly to talk through where the agentic web is going. Watch the recording, or read the recap below.
The Coordinator's Feed
Stop prompting agents and start training their orchestrators.
The agentic web is moving past the 'monolithic model' era into a more complex, modular reality where orchestration is the primary bottleneck. For builders, the challenge is no longer just selecting a model, but managing the delegation across an entire swarm of experts. Sakana AI's launch of Fugu represents this shift—moving from hard-coded logic to a 'learned coordinator' that dynamically assembles workflows. This is the natural evolution of the stack: we are abstracting away the 'how' of task execution in favor of high-level intent orchestration. Simultaneously, the developer experience is maturing. We're seeing the emergence of 'Agent Skills'—modular, reusable blocks of capability that turn general-purpose assistants like Claude into specialized operators for DevOps or trading. The infrastructure is catching up too, with unified memory layers and authentication bridges solving the 'glue code' problems that have plagued agent deployments. Today's issue highlights that the game has changed from writing the perfect prompt to building the perfect system. If you aren't thinking about orchestration and modular skills, you're building yesterday's agents.
Sakana AI Unveils Fugu: The Learned Coordinator for Multi-Agent Swarms
Sakana AI has launched Fugu, a novel multi-agent orchestration system that operates through a single model API. Rather than relying on a single monolithic model to solve complex problems, @SakanaAILabs describes Fugu as a 'learned coordinator' specifically trained to recursively call and delegate tasks to a pool of expert models. The system handles model selection, verification, and synthesis internally, which allows it to match the performance of frontier models like Fable and Mythos without the same export control risks, according to @beffjezos. It is available in two variants: a standard Fugu model for low-latency everyday tasks and Fugu Ultra for maximum quality on difficult problems like cybersecurity research.
Technically, the orchestration layer is powered by a 7B conductor model that manages specialized LLMs. This architecture has already shown significant promise, achieving a score of 73.7% on SWE-Bench Pro, which notably outperforms Claude Opus 4.8 at 69.2% and GPT-5.5 at 58.6%, as reported by @agentcommunity_. While the training process involves a mix of derivative-free evolution, SFT, and GRPO to assign roles like Thinker, Worker, and Verifier, @stretchcloud notes that it can write full agentic workflows dynamically.
For agent builders, this represents a shift toward unified endpoints for multi-step tasks. However, the efficiency gains come with trade-offs. Early reviews and analysis suggest that while Fugu's router keeps latency roughly on par with calling a single frontier model by skipping full autoregressive decoding, real-world bug-fixing tasks can cost approximately 6x more than using Opus 4.8, as highlighted by @_dylanmind. Despite the cost, @rohanpaul_ai emphasizes that Fugu excels in messy environments involving heavy delegation, making it a powerful tool for complex synthesis.
The 'Agent Skill' Revolution: Modularizing Claude Code for Production
The developer experience for agentic workflows is maturing as builders move beyond simple prompting into structured 'Plan Mode' and gated execution. @techNmak highlights that the most effective patterns now involve forcing agents to verify every step with tests before proceeding. This is being codified through the use of CLAUDE.md files for project rules and custom slash commands like /review to minimize repetitive overhead, a strategy recommended by @Krishnasagrawal.
Beyond basic configuration, a massive ecosystem of 'Agent Skills' is emerging to provide specialized, context-aware capabilities. These are essentially verified modules that can be loaded into agents to handle specific domains. For instance, @tom_doerr has curated skills for quantitative trading, while other community repositories like OpenClaudia offer over 140 free skills for SEO audits and viral hooks, according to @Granite0x. This modular approach allows developers to transform a general-purpose assistant into a domain expert without writing custom logic from scratch.
The breadth of these libraries is expanding rapidly, with specialized repos like cc-devops-skills containing 31 DevOps-specific tools, as noted by @CycleDecoded. Even major players are contributing, with Google's agents-cli package offering a way to turn coding agents into cloud experts, as shared by @hanyu_chen_ios. This shift toward reusable skills, as @_itsjustshubh points out, saves hours of manual prompting and represents the next phase of agentic software engineering.
In Brief
RushDB Aims to Unify Agent Memory and Context Layers
Managing agent memory is shifting from fragmented vector stores to unified layers that eliminate glue code by treating data as a live queryable schema. Introduced by @DanKornas, RushDB is a JSON-first database that automatically converts nested records into graph relationships and semantic search results, allowing agents to push data once and query it via schema introspection or filters without manual migrations. This approach is gaining traction among builders as a way to avoid stitching together separate vector and graph tools, with @agentcommunity_ and @Shehu_Hikmah noting its support for MCP integration with tools like Claude and Cursor.
Executor v1.5.16 Bridges the Multi-Account Auth Gap
Agent orchestration frequently stalls at the authentication layer, but Executor v1.5.16 addresses this by introducing comprehensive Microsoft Graph support and multi-account OAuth. This update allows users to connect multiple accounts in a single flow, enabling agents to interact with email, calendars, and files without constant re-authentication, as explained by @RhysSullivan. The release also features a new emit() function for direct file output to chat, which @grok and @agentcommunity_ suggest positions the tool as a reliable bridge for scaling agents across different service providers.
Research Highlights Performance Ceiling in Agentic World Modeling
New research into Agentic Automata Learning reveals that LLM agents struggle to discover internal world models through feedback as environment complexity increases. According to @rohanpaul_ai, agents often fail to consolidate observations into durable planning structures, especially in deterministic tasks where state spaces expand. @sytelus argues that this limitation is inherent to next-token prediction training, which prevents agents from building the stable internal representations required for true reasoning beyond simple pattern matching.
Quick Hits
Models for Agents
- DeepSeek V4 Pro completed full-parameter post-training on the CloudMatrix 384 supernode. @teortaxesTex
- Anthropic now enforces a 30-day data retention policy, while OpenAI supports zero retention. @steipete
- Open source 'Fable-class' reasoning models could arrive within three months via new reasoning traces. @bindureddy
Agentic Infrastructure
- Agent Forge added a Telegram bot for Human-in-the-Loop workflow approvals. @AITECHio
- xyOps launched a unified platform for agent job scheduling and workflow monitoring. @tom_doerr
Industry & Ecosystem
- Agents will eventually use software 100x more than humans, necessitating agent-specific guardrails. @levie
- AI-disclosed games on Steam receive 53% fewer reviews due to persistent stigma. @Pirat_Nation
Frontier Model Forums
Export bans lift on Claude's elite models as the Agentic Web hits 13,000 servers.
We are witnessing a shift from the experimental to the industrial. The news that the U.S. Commerce Department is reportedly lifting export bans on Anthropic’s frontier-class models—Claude Fable 5 and Mythos 5—signals a policy pivot that acknowledges the global demand for high-reasoning autonomous systems. For builders, this isn't just about availability; it's about deployment stability. When we look across the stack today, we see a parallel push for deterministic reliability. Whether it's the Model Context Protocol (MCP) ecosystem surging to 13,000 servers or the rise of cryptographic action proofs, the 'vibe-based' era of agent development is ending.
We’re moving toward a 'Context OS' where agents don't just guess; they verify, retrieve with sub-quarter-second latency, and operate under cryptographically signed receipts. This transition is critical for practitioners moving from toy demos to high-stakes autonomous execution. In this issue, we explore how local hardware like AMD is keeping pace with these demands and why the move toward verifiable truth is the only way to scale the Agentic Web.
US Lifts Export Bans on Frontier Claude Models r/ArtificialInteligence
In a significant policy shift, the U.S. Department of Commerce has reportedly lifted export controls affecting Anthropic's high-end models, specifically Claude Fable 5 and Mythos 5. According to u/star_Light570, Anthropic will begin restoring global access starting this Wednesday, July 1st. This move provides a more stable foundation for deploying agentic workflows that rely on Claude's advanced reasoning capabilities in previously restricted territories.
As noted by u/WPHero, the rollout will be progressive, which may impact practitioners building cross-border agentic infrastructure. The community is currently debating whether this is a model-specific exemption or a broader pivot in AI export policy, with some users highlighting the potential for 100% restoration of features globally.
MCP Ecosystem Surges to 13,000 Servers r/mcp
The Model Context Protocol (MCP) ecosystem is experiencing an explosive growth phase, with the total number of available servers now exceeding 13,000 and providing over 4,000 unique skills. This expansion is being met with new discovery tools like remoteopenclaw by u/Awkward-Bid-1514, which allows agents to query the directory directly, and specialized connectors like the Haunt server from u/Solid-Service302 that automates web-to-JSON extraction.
Cryptographic Proofs for Agent Verification r/AI_Agents
As agents transition to autonomous executors, the industry is moving away from 'vibe-based' reliability toward deterministic verification via tools like ActionProof. This MIT-licensed library generates cryptographically signed, tamper-evident receipts for agent actions, which u/Massive-Respond5879 notes allows for offline verification of task completion. This trend toward auditable state is furthered by the Mycelium project's runtime guards, designed to prevent agents from 'faking' task completion, according to u/Whole-Steak1255.
Proactive Memory Architectures Hit Sub-0.3s Latency r/LangChain
Agentic memory is shifting from reactive vector search to autonomous prefetching, as demonstrated by the GOAT 2.0 system's 0.234s latency. This architecture addresses the 'memory wall' by retrieving episodic context concurrently with context assembly u/Takashikiari. To measure these improvements, the PrecisionMemBench framework has been introduced to replace subjective LLM-as-judge metrics with objective belief-ID set overlap, a move u/Forward_Potential979 calls critical for production reliability.
AMD Hardware Renaissance and 4x Audio Inference r/LocalLLM
The ZINC project now reportedly outperforms llama.cpp on AMD RDNA4 hardware, while audio.cpp achieves 4.08x real-time performance for local VibeVoice 1.5B inference.
Context OS: Git-Based Operating Rules r/ContextEngineering
The Manifest project offers a private, git-based layer for operating rules, effectively creating a 'Context OS' that persists across different models and tools.
Grounding Frameworks for Production RAG r/Rag
The open-source cgs-rag package introduces a Composite Grounding Score to evaluate RAG faithfulness without expensive ground-truth labels.
Token Efficiency: 86% Savings via SHA-256 Caching r/LLMDevs
The sqz tool converts repeated file reads into 13-token references, achieving massive savings in multi-turn coding agent sessions.
Dev Experience Dispatches
Is the next generation of agents smarter, or just more expensive?
We are entering the era of the 'Reasoning Tax.' As frontier models like Claude Sonnet 5 and GLM 5.2 push the boundaries of agentic capability, builders are facing a new reality: intelligence isn't just about parameters anymore; it's about the overhead of the 'thought process.' Today we are seeing a distinct split in the ecosystem. On one hand, tools like Cursor’s Composer 2.5 and Sonnet 5 are delivering unprecedented logical consistency in coding tasks. On the other, the cost of that logic—manifesting as repetitive validation loops and 'infinite generation' errors—is forcing developers to look toward aggressive quantization and MoE architectures like Gemma 4 for relief. Whether it's running 27B models on consumer hardware with NVFP4 or optimizing n8n workflows to avoid 'silent failures,' the focus has shifted from mere capability to sustainable production. As builders, the challenge is no longer just getting the agent to work, but ensuring the 'thinking' phase doesn't crater the ROI of the entire system.
Sonnet 5’s Agentic Efficiency Challenged by High Token Overhead
Claude Sonnet 5 has arrived, and it is already sparking a heated debate over the efficiency of modern agentic workflows. While joycejetson describes the model as a significant step up from version 4.6, practitioners are noticing a curious habit of the model burning through tokens on extensive validation loops. According to ptr1337, this overhead can make the model roughly 40% more expensive per task than its predecessors, driving a renewed interest in distilling the 'Claude persona' into local weights to avoid recurring API costs.
Despite the price tag, the model is being integrated rapidly into production tools. phox15 reports that Sonnet 5 is already powering Perplexity’s GitHub repository management, showing a high capacity for reviewing and fixing source code across multiple files in single commits. However, the experience isn't without friction; rubixyt0072 warns of a high frequency of 'infinite generation' errors in current implementations, suggesting that the model's verbosity sometimes outruns its own execution logic.
Join the discussion: discord.gg/cursor
Composer 2.5 Wins on Logical Consistency
Cursor’s Composer 2.5 is being hailed as a 'sleeper' hit for agentic coding, with users claiming it is currently the most logical model for general-purpose tasks. Community members like m4ntr0n1c argue that this iteration surpasses Claude 3 Opus in reliability, particularly when executing complex, multi-step refactors without the common tool-calling failures found in other platforms. This focus on 'conversational density' and structural integrity over long-range planning sessions is setting a new standard for vertically integrated IDE stacks.
Join the discussion: discord.gg/cursor
GLM 5.2 Emerges as Debugging Champion Amidst Connectivity Hurdles
Zhipu AI's GLM 5.2 is carving out a reputation as a specialized power tool for high-stakes technical analysis, despite early deployment friction. Within the Cursor community, m4ntr0n1c labeled the model a 'champion' for debugging intricate memory allocators, citing a reasoning efficiency that reflects its 91.2% score on GSM8K. However, openlitespeed and loadouts have flagged significant constraints, including a lack of native image context and intermittent connection stability when accessing the provider.
Join the discussion: discord.gg/cursor
Qwen 3.6 Gains NVFP4 Support, Optimizing 27B Inference
The local agent community is coalescing around Qwen 3.6 27B following the release of official NVFP4 quantization weights. neur0_ highlighted these new weights, which allow the model to maintain high parity with FP8 benchmarks while significantly reducing VRAM requirements for consumer GPUs. As computerguy notes, this shift is critical for real-time agentic performance, as it allows the 27B model to function as a 'local brain' on 24GB hardware without the latency penalties of CPU offloading.
Join the discussion: discord.gg/localllm
Gemma 4 MoE: Deciphering Reasoning Tags and Tool-Calling Gains
alhazrad and theworm420 report that Gemma 4's use of internal reasoning tags provides a 12% boost in tool-calling accuracy over dense predecessors. Join the discussion: discord.gg/ollama
Ollama Bridges AMD Gap with Vulkan and ROCm on Windows
dagbs and theepic.dev highlight that setting OLLAMA_VULKAN=1 remains the most viable fallback for running local inference on upcoming RDNA 4 hardware. Join the discussion: discord.gg/ollama
Production-Grade n8n: The 6-Dimension Audit
franklll3 and tostiapparaat have introduced a production-readiness checklist to prevent 'silent failures' in complex n8n agent loops. Join the discussion: discord.gg/n8n
VibeVoice 1.5B and audio.cpp Deliver 4x Real-Time Local TTS
TrentBot reported that the new audio.cpp runtime allows VibeVoice 1.5B to process a 90-minute podcast in just 22 minutes on an RTX 5090.
Open Source Actionables
The agentic web is ditching brittle schemas for executable code and local GUI control.
For months, we’ve been hitting what researchers call the "11.4% reality wall"—the point where even the best frontier models fail at multi-step tasks in noisy, real-world environments. Today, we’re seeing a coordinated industry pivot to tear that wall down. The strategy isn't just about "bigger models," but a fundamental shift in how agents interact with their environments. Hugging Face’s launch of smolagents marks a definitive move away from the fragility of "JSON-hell" toward a Code-as-Action paradigm. By treating agent logic as executable Python, developers are seeing massive reductions in step counts and failure rates.
Simultaneously, the bottleneck of cloud latency is being bypassed by local GUI agents like the Holo3.1 family, clocking in at nearly 9,000 tokens per second. Whether it's 1M-token context windows from DeepSeek for maintaining long-horizon state or NVIDIA’s push into causal reasoning for physical AI, the goal is clear: reliability. We are moving from chatbots that suggest to agents that act with verifiable precision. This issue explores the frameworks, benchmarks, and infrastructure making that transition possible for practitioners building the next generation of autonomous systems.
From JSON-Hell to Code-as-Action: The Rise of Minimalist Agent Frameworks
Hugging Face is pivoting away from 'JSON-hell' with the launch of smolagents, a minimalist library that treats agent actions as executable Python code. This 'Code-as-Action' paradigm addresses the 45% of failures caused by brittle tool-calling in traditional setups, as noted by @aymeric_roucher. By writing logic directly in Python, agents achieve a 30% reduction in LLM steps, significantly improving efficiency for complex workflows.
To ensure safety, these agents utilize sandboxed execution through tools like E2B or local restricted interpreters. The ecosystem is further strengthened by Transformers Agents 2.0, which introduces a modular 'License to Call' architecture. This framework allows developers to choose between code-based or JSON-based execution while maintaining a unified interface for tools.
For those seeking extreme portability, tiny-agents demonstrates that a complete Model Context Protocol (MCP) agent can be built in under 50 lines of code. Integration is further streamlined through a partnership with LangChain, allowing these lightweight agents to be easily incorporated into larger orchestrations.
Local GUI Agents and the Shift to Real-Time Computer Use
The race for 'Computer Use' is pivoting toward local execution to overcome the latency bottlenecks of cloud-only systems. The Holo3.1 family leads this charge, anchored by Holotron-12B, which achieves a staggering 8,900 tokens/sec throughput. This high-speed architecture is critical for real-time viability, enabling an 80.5% success rate on WebVoyager and replacing brittle API calls with responsive, pixel-level control as the industry moves toward the 'Code-as-Action' paradigms highlighted by @aymeric_roucher.
Closing the Agentic Gap: New Benchmarks for Real-World Autonomy
As agents transition into autonomous operators, the industry is pivoting from generic LLM evaluations to 'agenticness' metrics. GAIA-2 and the Agent Reasoning Evaluation (ARE) have established a new baseline for multi-step reasoning, where Hugging Face’s Transformers Code Agent recently achieved a 40.3% success rate. These frameworks, including specialized tools like EVA and DABStep, are essential for overcoming the 11.4% success rate reality wall identified by IBM Research & UC Berkeley.
DeepSeek-V4 and NVIDIA Pivot Toward 1M-Token Retrieval and Physical AI
DeepSeek has introduced a 1,000,000-token context window with 99% accuracy, while NVIDIA deploys Cosmos Reason 2 to enable agents to predict environmental outcomes in physical AI.
OpenEnv and the New Frontier of Competitive Multi-Agent RL
OpenEnv acts as a standardized 'Gym for Agents' to refine Reinforcement Learning via industrial-scale validation and AI vs. AI competition frameworks.
Beyond the Container: Dockerless Verifiers and Agent-Native CLIs
New Dockerless environment-free verifiers achieve a 10-100x speedup in program verification, while Agents.js brings minimalist autonomous tooling to the JavaScript ecosystem.