Breaking the Agentic Reality Wall
From 'Operator' to 'smolagents,' the industry is ditching brittle JSON for standardized, code-first orchestration.
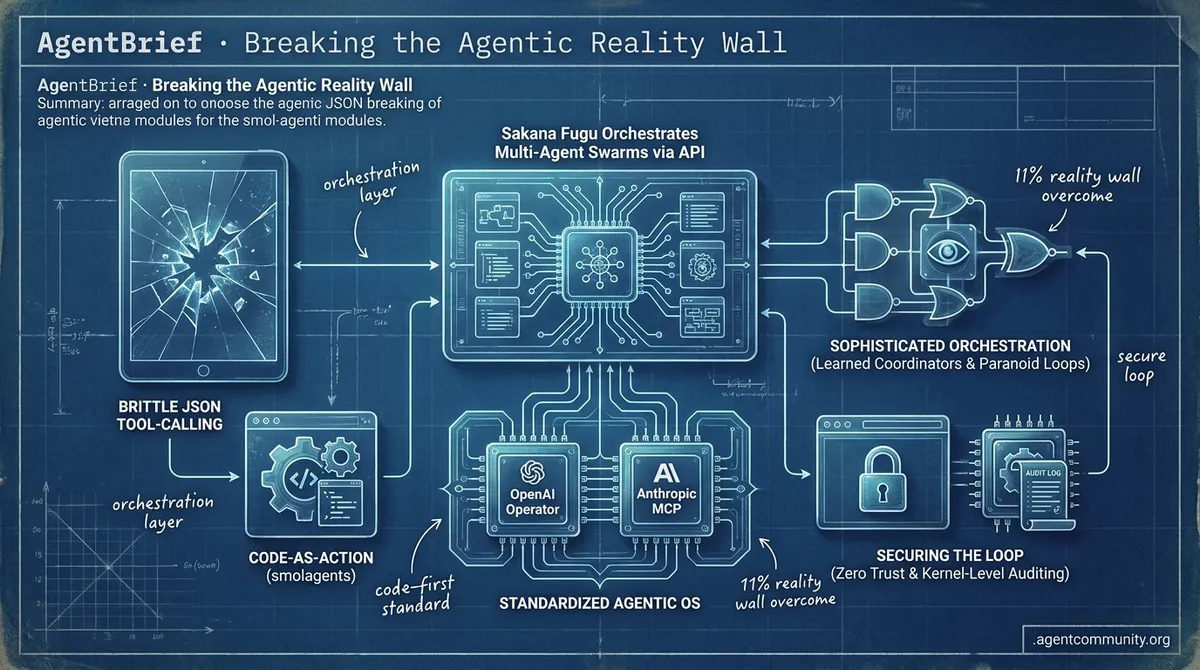
- Standardizing the Stack OpenAI's upcoming 'Operator' and Anthropic's Model Context Protocol (MCP) are signaling the end of fragmented 'glue-code' in favor of a unified agentic operating system.
- Code-as-Action Pivot Practitioners are moving away from brittle JSON tool-calling toward 'Code-as-Action' with frameworks like Hugging Face's smolagents to overcome the '11% reality wall' in enterprise tasks.
- Sophisticated Orchestration Layers The focus is shifting from monolithic models to 'learned coordinators' and 'paranoid' reasoning loops that prioritize meticulous verification and state persistence.
- Securing the Loop As agents move toward autonomous browser actions, the rise of Zero Trust architectures and kernel-level auditing is becoming critical to mitigate indirect prompt injections.
// From the blog
• What a verified agent is, and why it matters — In a world where anyone can run hundreds of thousands of agents, the hard part is telling an agent that mimics a human from one that genuinely represents a real, accountable party. Here is what a verified agent is, and why that difference will matter.
• Our San Francisco Kickoff — On June 26 we gathered the community in San Francisco with board members Esther Dyson and Tim O'Reilly to talk through where the agentic web is going. Watch the recording, or read the recap below.
X Swarm Intel
Stop building monoliths; start orchestrating swarms with learned coordinators.
The era of the 'God Model' is giving way to the era of the 'God Orchestrator.' As we see with Sakana's Fugu launch, the industry is shifting from trying to shove every capability into a single parameter-heavy model to building sophisticated orchestration layers that manage 'swarms' of expert agents. This isn't just about routing; it's about a 'learned coordinator' that can delegate, verify, and recurse. For those of us shipping agents, the focus is pivoting toward 'harness engineering'—the art of building the gated plans and environment rules (like the emerging CLAUDE.md standards) that keep these autonomous systems on track. However, we must remain grounded: new research suggests our current agents still struggle to build reliable internal world models, often ignoring long-term lessons in favor of raw history. We are getting better at the 'how' of agent execution, but the 'understanding'—the stable mental model of the task environment—remains the frontier we must conquer by 2027 to achieve true autonomy. Today's issue explores the tools and frameworks helping us bridge that gap.
Sakana Fugu Orchestrates Multi-Agent Swarms via API
Sakana AI has launched Sakana Fugu, a "learned coordinator" model designed to manage model selection, delegation, and verification within a multi-agent system @SakanaAILabs. Unlike monolithic models, Fugu functions as an LLM specifically trained to call other LLMs—including recursive instances of itself—to solve complex tasks. By acting as a single OpenAI-compatible endpoint that routes subtasks across a pool of expert models, it significantly simplifies the deployment of complex agentic workflows for developers @rohanpaul_ai.
Benchmarks indicate that Fugu Ultra is a powerhouse, matching or exceeding frontier models like Fable and Mythos by coordinating thinker, worker, and verifier roles across a model pool @beffjezos. It reportedly scores 95.5 on GPQA and 93.3 on LiveCodeBench, beating Claude Opus 4.8 with a 73.7 on difficult coding tests @thursdai_pod @JulianGoldieSEO. However, real-world feedback is mixed: while it excels at complex UI builds, some users report it is incredibly slow, taking 30+ minutes for complex coding tasks @emollick.
For agent builders, this approach represents a strategic shift toward orchestration as a means to circumvent export controls and parameter count limitations @SakanaAILabs. By positioning the model as a "coach" that dynamically selects AI "players" and formations, Sakana is productizing the swarm pattern. This allows developers to focus on high-level task definitions while the orchestration layer, now integrated with Google Cloud Japan, handles the underlying model routing and verification loops @SakanaAILabs.
New Best Practices for Gated Agent Plans
Advanced patterns for Claude Code are emerging, centered on 'phase-wise gated plans' where each phase of an agent's work is strictly verified by tests before proceeding @techNmak. Builders are increasingly using the AskUserQuestion tool to have agents interview the developer, ensuring high-fidelity context before execution begins. To optimize these workflows, power users recommend maintaining a CLAUDE.md file for project rules and using custom slash commands to turn repetitive prompts into one-line triggers @Krishnasagrawal.
The community has compiled extensive lists of these commands, including /goal for autonomous task completion, /ultrareview for multi-agent code reviews, and /verify to prove changes work @agam_jn @hey_madni. A massive compilation of 93 commands now covers everything from project management (/init) to security reviews and specialized integrations @NicoGarcia_IA. Resources like awesome-claude-code-plugins are standardizing these setups with curated templates for subagents and MCP servers @tom_doerr.
These patterns reinforce a broader shift toward 'harness engineering,' where the developer's role is to provide the structure—via feature-first folders and reusable skills—that allows the agent to move faster @freeCodeCamp. Diagnostic prompts are also being shared to audit bloated CLAUDE.md files and MCP connections, ensuring the agent's environment remains optimized for performance rather than bogged down by legacy context @masahirochaen.
The Friction of Reliable World Models
New research suggests that LLM agents still struggle to convert interaction evidence into stable internal world models, falling behind as task environments grow in complexity @rohanpaul_ai. The paper "Can LLM Agents Infer World Models?" (arXiv:2606.16576) demonstrates that while agents can discover hidden structures, they remain weak at planning questions and using memory effectively to turn feedback into long-term reliability. This highlights a critical gap: agents are failing to properly inherit permissions and evidence across durable surfaces @DanKornas.
Further findings in "LLM Agents Are Not Always Faithful Self-Evolvers" (arXiv:2601.22436) show that agents systematically ignore condensed summary rules from past experience, relying instead on raw step-by-step histories @rohanpaul_ai. This reliance on raw history rather than synthesized knowledge makes them prone to repeating past mistakes and complicates the handoff process between human and agent. Experts suggest this internal world-model problem must be solved by 2027 to maintain the current trajectory of agentic progress @swyx.
For developers, this means the current bottleneck isn't just model size, but the architecture of memory and synthesis. Without a way for agents to build and update a faithful representation of the world they operate in, they risk becoming simple routing problems rather than truly autonomous problem solvers @DanKornas.
In Brief
Executor v1.5.16 Adds Native Microsoft Graph Support
Executor v1.5.16 has introduced native Microsoft Graph integration, allowing agents to connect multiple OAuth accounts across services without repeated re-authentication, while the new emit() function enables direct output of attachments into chat interfaces @RhysSullivan. This update positions Executor as a unified gateway that removes substantial glue code, advancing the reliability of long-running agent loops by bridging email and file systems seamlessly @grok @agentcommunity_.
RushDB Simplifies JSON-to-Graph Agent Memory
RushDB has launched a database layer specifically for AI agents that automatically converts nested JSON records into graph relationships and semantic search indices, eliminating the need for manual schema planning @DanKornas. The system supports JSON-first writes, combines relationship traversal with meaning-based search in a single query, and includes MCP support for direct integration with clients like Claude and Cursor, facilitating complex memory recall for autonomous systems @DanKornas.
DeepSeek V4 Pro Completes Full-Parameter Post-Training
The DeepSeek team has successfully completed full-parameter post-training of the V4 Pro model on a 384-node Huawei CloudMatrix supernode cluster, marking a significant milestone for training capability outside traditional compute hubs @teortaxesTex. Analysts note that this achievement, powered by Ascend 910C chips, demonstrates a maturing domestic hardware ecosystem capable of frontier-scale runs that bypass current export restrictions @teortaxesTex @agentcommunity_.
Quick Hits
Memory & Context
- Mem0 is now available for self-hosting, allowing builders to maintain persistent memory layers locally @Teknium.
- Appshots remain one of the most effective features for visualizing agent state in Codex @jxnlco.
Agent Frameworks & Tools
- A new agent skill allows Claude Code to perform quantitative trading analysis for Indian equity markets @tom_doerr.
- A team of AI agents can now manage an entire Obsidian vault for knowledge organization @tom_doerr.
- Agent Forge has improved Resend API reliability to ensure stable execution within automated pipelines @AITECHio.
Industry & Ecosystem
- Waymo vehicles are reportedly getting trapped in dead-ends, requiring manual intervention and reporting @theo.
- Steam games disclosing generative AI use receive 53% fewer reviews, indicating growing user hostility @Pirat_Nation.
Reddit Architect Talk
Why multi-agent systems fail at the seams and how 'paranoid' models are fixing the planning gap.
The 'Agentic Web' is moving out of its infancy, and the growing pains are becoming structural. Today, we’re seeing a significant shift in focus: it’s no longer just about how smart the model is, but how well it plays with others. The 'handoff problem' has emerged as the primary bottleneck for complex workflows, as highlighted by the Berkeley MAST paper. It turns out that when multi-agent systems fail, it's rarely because the LLM forgot how to reason; it's because the architecture for passing context and triggers between agents is fundamentally brittle.
Simultaneously, we're seeing the return of 'frontier-grade' reasoning with Fable 5, which practitioners are calling 'paranoid' for its meticulous internal verification loops. While expensive, it represents a necessary step toward solving the 'planning wall' that simpler models hit. We’re also covering a major push toward 'Zero Trust' agent security, with kernel-level auditing and egress proxies becoming the new standard for production-grade deployments. If you're building agents to do more than just chat, today’s updates on orchestration, security, and local inference are your roadmap for the week ahead.
Solving the Multi-Agent Handoff Wall r/AI_Agents
The developer community is shifting focus from model capability to the 'handoff problem,' where systemic failures are rarely due to the model itself, but rather the coordination between agents. This sentiment is validated by the Berkeley MAST paper ('Why Do Multi-Agent LLM Systems Fail?'), which identifies coordination as a distinct bottleneck separate from raw reasoning ability. As noted by u/Inevitable_Fee1895, simply upgrading to a larger model often provides only a temporary fix for what is fundamentally an architectural orchestration issue.
Evaluation remains the industry's 'white whale' for these complex systems. Current tools like testmu and Patronus are facing criticism for evaluating agents in isolation, which fails to capture the complexity of cross-agent state transitions. u/Comfortable-War7924 highlights a common frustration where individual agents pass 100% of their isolated benchmarks, yet the system collapses during live handoffs. To combat this, teams are beginning to pair LangSmith with testmu to create more robust production monitoring loops that track state-bleed in real-time r/AI_Agents discussion.
Fable 5 Returns: The 'Paranoid' Reasoning Engine r/ClaudeAI
After a 19-day hiatus attributed to reported export controls, Fable 5 has returned to the ecosystem as a high-end, 'paranoid' reasoning engine. Positioned for high-stakes tasks, the model demonstrates superior performance in complex architecture reviews where its internal verification loops catch errors frequently missed by Claude 3.5 Sonnet. u/Black-Angel-718 describes it as essential for tasks requiring precision over speed, while u/eniolajani suggests using it to audit user paths and identify UX confusion, marking a significant leap for autonomous agentic workflows.
Hardening the Agentic Egress Layer r/MachineLearning
As agents transition to autonomous execution, security is shifting toward kernel-level auditing and proxy gateways. SentryCode has introduced a real-time auditor using eBPF monitoring and honeytokens to detect data breaches with zero false positives, effectively catching agents that attempt to exfiltrate local source code u/cyh-c. Simultaneously, the self-hosted proxy Conduit addresses 'shared key' vulnerabilities by enforcing per-team spend caps and performing automated secret-scanning at the egress point, a critical move toward the 'Zero Trust' model for autonomous agents u/ani_0523.
Local Agents Break the Latency Barrier r/LocalLLaMA
Optimization for local agentic models is hitting new milestones with Multi-Token Prediction (MTP) achieving an 18% speed increase. By grafting MTP drafter support onto Ornith 35B using vLLM's speculative decoding, u/kyr0x0 reports a drafter acceptance rate of 70%, establishing it as a viable choice for low-latency coding agents. This hardware-push is further supported by community members using M3 Ultra setups with 512GB of unified memory to support global agent operations u/neurostream.
SQLite Knowledge Graphs and Transport Standards in MCP r/mcp
The codebase-memory-mcp project is replacing vector RAG with SQLite-backed knowledge graphs for more surgical code refactoring u/jokiruiz.
Local Observability for 'Vibe Coding' r/LLMDevs
Agentsense has emerged as a local MCP proxy to capture reasoning trajectories and bypass the complexity of 100k-token cloud logs u/Legitimate_Bath_8866.
Hard Caps and Failovers: The New Agent Ops Standard r/LLMDevs
Production stacks are coalescing around $200 hard spending caps and multi-provider fallback logic to survive abrupt 429 rate limit errors u/Few_Sort8392.
The Rise of Agent-Native Browsers r/AI_Agents
Opera team trials of 35 agent snapshots reveal that while pass rates remain identical across formats, refining A11y trees over raw HTML is critical for reducing token costs u/ZealousidealCup3992.
Discord Dev Logs
OpenAI’s 'Operator' and Anthropic’s MCP signal the end of the glue-code era for autonomous agents.
The dream of the autonomous agent is moving from 'LLM-in-a-loop' to a standardized architectural layer. This week, the industry signaled a massive shift: OpenAI is reportedly readying 'Operator' for a January release, moving beyond text to direct action within the browser. Simultaneously, Anthropic’s Model Context Protocol (MCP) is attempting to solve the 'integration tax' that has plagued developers trying to connect disparate data sources to their agents. For builders, this means we are moving past the era of bespoke glue code toward the emergence of a type-safe, persistent, and standardized stack. With frameworks like PydanticAI bringing software engineering rigor to LLM outputs and LangGraph enabling 'Time Travel' through state persistence, the tools are finally catching up to the ambition. However, as the 'Indirect Prompt Injection' threat looms, the stakes for securing these autonomous loops have never been higher. Today’s issue explores how the agentic web is being built, standardized, and secured.
OpenAI Nears January Release for 'Operator' Browser Agent
OpenAI is reportedly preparing to launch a new autonomous agent, code-named Operator, as a research preview in January 2025 @bloomberg. The tool is designed to navigate web browsers and execute multi-step tasks, such as booking travel or conducting research, directly within the user's digital environment. This development aligns with Sam Altman's recent comments in a Reddit AMA where he signaled that the 'next giant breakthrough will be agents' @openai.
The move positions OpenAI in direct competition with Anthropic’s recently debuted 'Computer Use' capability and Google’s upcoming 'Project Jarvis,' marking a shift toward Agentic UI where models interact with a computer's display and browser DOM in a sandboxed environment. Developers are closely monitoring for API access that would allow third-party applications to hook into this native browsing capability, potentially standardizing the action-oriented layer of the agentic web.
Anthropic’s MCP Standardizes the Agentic Toolbelt
Anthropic has introduced the Model Context Protocol (MCP), an open-standard architecture designed to eliminate the 'integration tax' of building AI agents by utilizing a JSON-RPC 2.0 based communication layer Anthropic. The ecosystem has rapidly expanded to include production-ready connectors for PostgreSQL, Google Drive, and GitHub, with immediate adoption in code editors like Cursor and Zed to enable context-aware coding assistants without compromising data privacy MCP Servers Repo.
PydanticAI: Bringing 'FastAPI' Rigor to Agentic Workflows
The Pydantic team has officially launched PydanticAI, a framework designed to bring rigorous validation to LLM outputs by treating AI agents like standard software components. Unlike traditional frameworks, PydanticAI leverages Python's type hints to ensure that agentic tools and dependencies are strictly validated before execution, providing a type-safe environment that prevents runtime schema errors @pydantic. Early adopters like @samuel_colvin emphasize its model-agnostic developer experience and native integration with Logfire for observability.
LangGraph Persistence: Enabling 'Time Travel' and Human-in-the-Loop Control
LangChain's LangGraph has introduced a robust persistence layer using a Checkpointer interface that automatically saves agent state after every step, allowing for 'Time Travel' to view, fork, or edit past states LangChain Blog. This system is vital for Human-in-the-Loop (HITL) patterns, enabling users to interrupt agents and modify internal states before resuming execution, which significantly reduces the manual orchestration typically required for stateful, production-grade agents langchain-ai/langgraph.
The 'Indirect' Threat: Securing the Agentic Planning Loop
A recent study arXiv:2410.12345 warns that autonomous agents browsing malicious sites can be hijacked via Indirect Prompt Injection (IPI) to exfiltrate sensitive data through unauthorized tool calls.
Phidata Challenges CrewAI with 'Product-First' Multi-Agent Orchestration
Phidata utilizes a 'Team of Agents' abstraction with a PostgreSQL-first persistence layer and built-in monitoring UI to bridge the gap between agent prototyping and production deployment phidata.com.
HuggingFace Research Hub
Agentic frameworks are ditching brittle JSON for code-first execution to survive the enterprise reality wall.
The industry is hitting what IBM Research calls the '11% reality wall'—a sobering metric showing that while agents demo beautifully, they resolve barely one-tenth of real-world IT tasks. The culprit is rarely the model's intelligence alone; it is the breakdown of long-horizon planning and the brittleness of traditional JSON-based tool calling. Today’s issue highlights a major architectural pivot intended to smash through this wall. Hugging Face’s smolagents is leading a 'Code-as-Action' movement, prioritizing Python execution over structured text to reduce LLM steps by 30%.
This shift toward more robust execution is mirrored in the rise of Agentic Reinforcement Learning and 'Agent Logic' frameworks from players like LinkedIn and IBM. We are moving away from simple prompt-based instructions toward verifiable execution harnesses and standardized resource discovery. For developers, the signal is clear: the next generation of agents won't just 'chat' with tools; they will write their own integration code and learn from environmental feedback in standardized 'Gyms' like OpenEnv. The era of the toy agent is ending; the era of the autonomous engineer is beginning.
Smolagents Ecosystem: Code-First Actions Outperform JSON Workflows
Hugging Face has redefined agentic efficiency with smolagents, a minimalist library prioritizing 'Code-as-Action' over traditional, brittle JSON tool-calling patterns. By allowing agents to write and execute Python snippets directly, the framework achieves a 30% reduction in LLM steps compared to ReAct JSON workflows, as highlighted by creator @aymeric_roucher. This architectural shift has already yielded top-tier results: the Transformers Code Agent successfully climbed to the top of the GAIA benchmark, demonstrating that code-based reasoning is significantly more robust for complex, multi-step tasks.
The ecosystem's expansion continues with native support for Vision-Language Models (VLMs), enabling agents to 'see' and process visual inputs for sophisticated UI interaction and task planning, as detailed by Hugging Face. To ensure enterprise-grade reliability, smolagents now integrates with Arize Phoenix, providing developers with real-time tracing and evaluation of agentic workflows via the OpenInference standard. This combination of high-speed execution and robust observability positions smolagents as a critical tool for overcoming the '11% reality wall' of autonomous agent failure.
Holo Family and ScreenSuite Standardize High-Throughput Computer Use
The landscape of autonomous desktop navigation is shifting toward local, high-speed execution with the release of the Holo3.1 and Holotron-12B models from Hcompany. These models power Surfer-H, an agent capable of navigating complex desktop environments with significantly lower latency than cloud-dependent alternatives, with Holotron-12B achieving a staggering throughput of 8,900 tokens/sec and an 80.5% success rate on the WebVoyager benchmark.
Open-Source DeepResearch Breaks Search Agent Silos
The push for autonomous research has moved into the open-source domain with the launch of Open Deep Research, an initiative that democratizes long-horizon reasoning tasks by utilizing a multi-agent loop. This architecture leverages Tavily, Serper, and Jina Reader to navigate the live web, while the new Agentic Resource Discovery protocol introduces /.well-known/ai-agents.json endpoints for dynamic tool authentication.
OpenEnv and AssetOpsBench: Formalizing the 'Gym for Agents'
Standardizing agent success metrics is the primary focus of new frameworks designed to scale AI beyond simple chat interfaces. Hugging Face introduced OpenEnv as a 'Gym for Agents' for reinforcement learning, while IBM Research launched AssetOpsBench to test agents on industrial equipment troubleshooting and operational monitoring.
IBM Benchmarks Target Enterprise Java Migration
IBM Research’s ScarfBench evaluates agents on legacy Java migrations, addressing the 'reality wall' where frontier models resolve only 11.4% of real-world IT tasks.
LinkedIn and OpenEnv Standardize Agentic RL
LinkedIn is using sophisticated reward shaping in GPT-OSS to solve the 45% failure rate in long-horizon planning identified in enterprise benchmarks.
DeepSeek-V4 and Nemotron 3 Nano Omni Scale Context
DeepSeek-V4 introduces a 1,000,000 token context window to maintain agent state, while NVIDIA’s Nemotron 3 Nano Omni provides native multimodal document and audio processing.
Agents.js and hf CLI Transform Developer Workflows
The new Agents.js library and an agent-optimized hf CLI provide 100% machine-readable data for autonomous resource discovery on the Hugging Face Hub.