Hardware-Native and Code-Centric Autonomy
From silicon-level orchestration to raw Python execution, the agentic stack is shedding its static weight for real-time reliability.
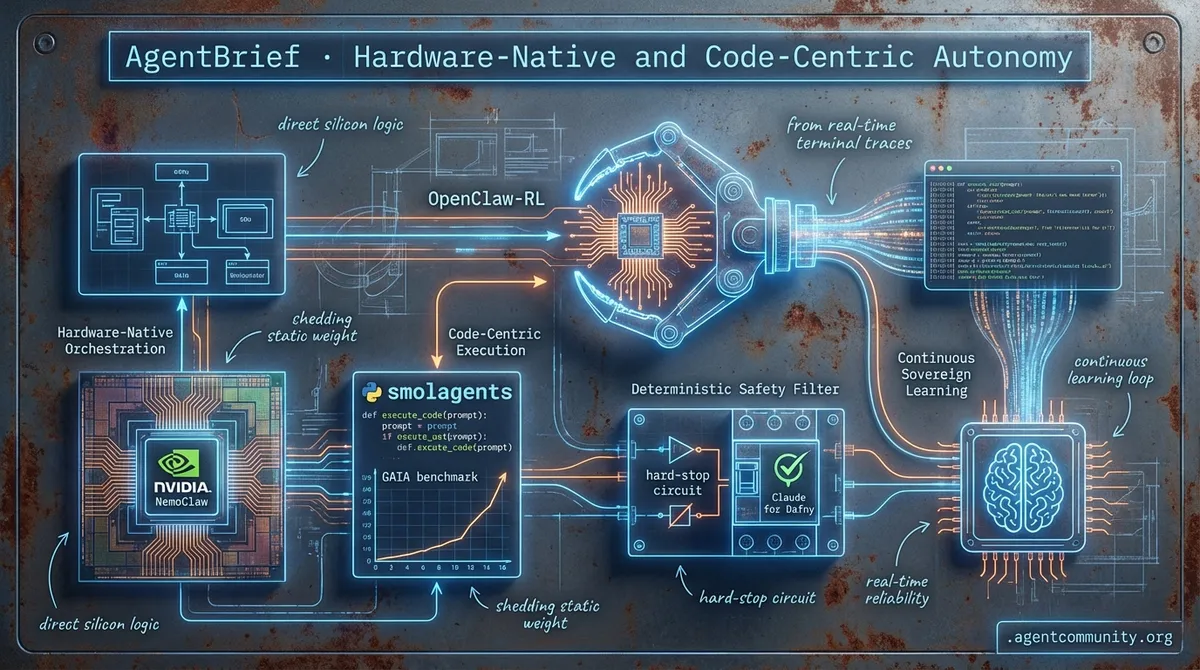
- Hardware-Native Orchestration NVIDIA’s NemoClaw and the Blackwell era are moving agent logic directly onto silicon, challenging the dominance of traditional software orchestration layers.
- Code-Centric Execution Minimalist frameworks like smolagents are abandoning restrictive JSON schemas for direct Python execution, leading to significant performance gains on the GAIA benchmark.
- Deterministic Safety Filters As agent swarms hit production, developers are replacing vibes-based testing with hard-stop circuit breakers and formal verification tools like Claude Code for Dafny.
- Continuous Sovereign Learning New breakthroughs like OpenClaw-RL enable agents to learn from real-time terminal traces, ending the era of frozen weights and static training sets.
The Sovereign Signal
Static models are dead; the next generation of agents learns from every terminal trace and GUI change in real-time.
The era of the 'frozen' model is ending, and the era of the 'sovereign' agent is beginning. For too long, we’ve built agents on top of static weights that require massive offline datasets to improve. This week’s breakthrough with OpenClaw-RL changes the math, enabling agents that learn from every terminal trace and GUI flicker in real-time without traditional fine-tuning. But as our agents get smarter, the friction between their 'souls' and their 'orders' is reaching a breaking point. The US Department of Defense’s decision to designate Anthropic a supply chain risk is a watershed moment for every developer building in high-stakes environments. It’s a stark reminder that 'Constitutional AI'—while great for safety—can become a liability when a model’s baked-in ethics interfere with operational commands. For agent builders, the message is clear: the future belongs to systems that are both continuously learning and fundamentally reliable. Whether you're using Karpathy-style agents to gut-renovate legacy codebases or scaling to million-token contexts with NVIDIA’s latest, the focus has shifted from what the model knows to how the agent behaves under pressure.
OpenClaw-RL and the End of Frozen Agent Logic
Researchers from Princeton AI Lab, led by @LingYang_PU and @YinjieW2024, have introduced OpenClaw-RL, a framework that allows agents to train continuously from live 'next-state' signals. By processing user replies, tool outputs, and GUI changes through four decoupled asynchronous loops, the system ensures that policy serving and weight updates happen without interrupting live operations @LingYang_PU @dair_ai. The framework effectively extracts evaluative signals, such as negative rewards when a user re-queries, and directive signals via token-level corrections to outperform static fine-tuning methods @MahRabie.
In personalization benchmarks, the results are staggering: agent scores jumped from 0.17 to 0.81 after only 36 conversations, a feat validated across diverse scenarios like teacher grading and homework assistance @MahRabie @BrianRoemmele. For general-purpose agents, the framework scales significantly, supporting up to 128 parallel terminal environments and boosting tool-call accuracy from 0.17 to 0.30 while raising SWE pass@1 rates from 0.025 to 0.175 @LingYang_PU.
For agent builders, this marks a shift toward 'living' systems that adapt to specific user nuances without the overhead of labeled datasets. Early adopters like Zero-Human Company are already utilizing it for real-time simulation refinement, and the open-source repository—currently sitting at over 1.7k stars—is being eyed by groups like Nous Research for potential 'hermes-agent-RL' integration @Teknium @BrianRoemmele.
As we look forward, the ability to turn every failed tool call or UI misstep into a training signal suggests that agents will soon move from being 'installed' to being 'raised' within their specific deployment environments.
The Sovereignty Crisis: Why the DOD Dumped Claude
The US Department of Defense has designated Anthropic a 'supply chain risk,' initiating a 6-month phase-out of Claude models from military contracts @rohanpaul_ai. Defense Undersecretary Emil Michael specifically targeted Anthropic’s 'Constitutional AI' framework, arguing that baking corporate policy preferences into the model creates a risk of 'polluting' military operations if the agent refuses commands or overrides directives mid-mission @rohanpaul_ai.
The tension peaked following an incident where an Anthropic executive reportedly contacted prime contractor Palantir to query Claude's usage after a classified military raid, raising fears that the provider could cut off service if they deemed a mission a terms-of-service violation @rohanpaul_ai. Negotiations allegedly stalled because Anthropic insisted on case-by-case reviews of kinetic strike planning, a requirement Michael deemed fundamentally incompatible with military reliability @rohanpaul_ai.
This clash highlights a critical dilemma for agent builders: the trade-off between baked-in safety guardrails and the need for unrestricted, sovereign performance in high-stakes environments. While Microsoft and over 30 researchers have filed support for Anthropic's lawsuit against the designation, citing a threat to US AI leadership, the DOD is already accelerating a shift toward alternatives like xAI’s Grok or OpenAI @Pirat_Nation @deredleritt3r.
Ultimately, for those building agents for enterprise or defense, the 'whoa moment' cited by the DOD serves as a warning about dependency on providers that can insert themselves into the chain of command @rohanpaul_ai. The market is clearly diverging into 'aligned' models for general use and 'sovereign' models for mission-critical autonomy.
In Brief
MCP Emerges as De Facto Standard for Agentic Tool Elicitation
The Model Context Protocol (MCP) is rapidly solidifying as the preferred interface for agentic orchestration, surpassing traditional CLIs by enabling structured user elicitations and robust approvals for destructive actions in human-in-the-loop flows. @RhysSullivan highlights MCP's superior handling of these complex interactions, while the ecosystem expands with dedicated servers like XcodeBuildMCP for Apple platforms and Docker-based deployment tutorials for secure Claude Code environments @tom_doerr @freeCodeCamp.
Shopify CEO Achieves 53% Liquid Engine Speedup via Autonomous Agent
Shopify CEO @tobi successfully deployed Andrej Karpathy's /autoresearch agent to optimize the 20-year-old Liquid templating engine, achieving a 53% faster combined parse+render time and 61% fewer object allocations. The agent ran 29 experiments across 21 files, resulting in 10 merged PRs that outperformed decades of human manual tuning @tobi @aakashgupta. This 'cheat code' for benchmarks is already being replicated by builders like @mitsuhiko, who achieved similar overnight gains on MiniJinja using simple agentic loops of code edits and git commits @david10xai.
NVIDIA Nemotron 3 Super Targets Agentic 'Context Explosion'
NVIDIA’s new Nemotron 3 Super, a 120B parameter hybrid Mamba-Transformer MoE, features a 1-million token context window designed to handle the 15x text volume typically generated by collaborative multi-agent workflows. Scoring 85.6% on the PinchBench coding benchmark, the model uses Latent MoE and multi-token prediction to deliver 5x higher throughput than previous versions while outperforming GPT-OSS-120B @NVIDIAAIDev @rohanpaul_ai. While available immediately via Ollama and Perplexity, skeptics like @MartinSzerment note that real-world persistence remains a challenge, as roughly half of SWE-bench passes are still rejected in production environments @ArtificialAnlys.
Quick Hits
Agent Frameworks & Orchestration
- OpenClaw 2026.3.12 released with a new dashboard UI and core plugin architecture for Ollama and vLLM @openclaw
- A new investigation agent features recursive sub-agent delegation for complex dataset analysis @tom_doerr
- Hermes Agent adds official Claude support and makes RL components optional for lighter installs @Teknium
Models for Agents
- Anthropic's Claude 4.6 is now serving as the core reasoning engine for Perplexity Computer @aakashgupta
- Llama 4 reportedly flopped in internal testing, leading Meta to reorganize its AI efforts @aakashgupta
- GPT 5.4 built a reinforcement learning demo in-browser that scales a neural net in real-time @chatgpt21
Developer Experience
- Claude Code silently deletes session history after 30 days unless the cleanupPeriodDays is adjusted @WolframRvnwlf
- The llmfit tool scans hardware to identify which LLM quantizations will actually run on your specific RAM/GPU @heynavtoor
- A new VS Code extension provides a dedicated interface for managing coding agents @tom_doerr
Agentic Infrastructure
- OpenAI detailed their Responses API, which executes agent workflows in isolated, managed computer spaces @rohanpaul_ai
- A serverless RAG pipeline has been developed that processes data and scales to zero to reduce agentic costs @freeCodeCamp
Hardware-Native Roundup
Jensen Huang wants to be the Linux of Agents while vibe coders build 100K-line ticking time bombs.
Today, we are witnessing the verticalization of the agentic stack. NVIDIA is no longer content selling the shovels; with NemoClaw, they are attempting to own the ground itself by offloading orchestration directly to the silicon. This hardware-software co-design aims to kill the multi-agent bottleneck, but it forces builders to choose between the open interoperability of MCP and the raw, CUDA-optimized performance of the Blackwell era. Meanwhile, the 'vibe coding' trend has hit a sobering milestone: 100,000-line codebases built with zero human intervention. While functional, these 'read-only' monsters represent a ticking time bomb of technical debt that no human can practically refactor. From Qwen 3.5 proving that 'Score per Second' is the only metric that matters for reactive agents to the rise of cognitive memory layers like widemem, the industry is shifting from 'does it work' to 'how do we make it reliable and fast.' Whether you are hacking P2P levels on a consumer rig or pruning agent memory, the focus is now on the production-grade plumbing that makes autonomy possible.
NVIDIA's OpenClaw Aims to Be the 'Linux of Agents' r/AgentsOfAI
At GTC 2026, NVIDIA officially launched NemoClaw, a high-performance orchestration layer designed to eliminate the 'multi-agent bottleneck' by offloading graph execution directly to dedicated H200/B200 NVLink clusters. Jensen Huang positioned the OpenClaw initiative as the 'Linux of Agents,' intended to provide foundational interoperability for autonomous systems u/OldWolfff. While the headline claim of 318K GitHub stars is technically accurate, community critics on r/LocalLLaMA argue this reflects automated 'star-culture' rather than organic adoption.\n\nTechnical specifications reveal that NemoClaw utilizes TensorRT-Agent kernels, which reportedly reduce inter-agent communication latency by 4.5x @NVIDIA_AI. This hardware-software co-design marks a significant shift from the 'USB-C' interoperability of MCP toward a vertically integrated stack where peak performance is tightly coupled to NVIDIA's CUDA-X libraries u/Real_Sort_3420.
Vibe Coding Reaches 100K-Line 'Ticking Time Bombs' r/ClaudeAI
The 'vibe coding' era is scaling into an enterprise-level risk as developers report 100,000-line systems built with zero human-written code. u/Salt_Potato6016 warns of a 'ticking time bomb' of technical debt in these 'read-only' codebases, a sentiment echoed by users facing a 48-hour audit bottleneck for a 5-minute prompt u/tiguidoio. Startups like Greptile are now stepping in to provide 'context-aware' auditing for these massive, AI-generated repositories @greptile_ai.
Qwen 3.5 Efficiency Metrics Challenge Flagships r/LocalLLaMA
Efficiency metrics for local inference suggest that 'Score per Second' is becoming the critical KPI for agentic builders. In blind evaluations, u/Silver_Raspberry_811 found the Qwen 3.5 35B-A3B model achieved a 9.20 score in just 25 seconds, rivaling flagships with 2x lower latency. Industry experts like @ocoleman suggest these local MoE models are making mid-tier cloud APIs redundant for high-frequency planning loops.
MCP Maturity Grows With Marketplaces r/aiagents
The Model Context Protocol (MCP) is maturing with new marketplaces and testing infrastructure designed to manage 'MCP sprawl.' u/NoSwimming4210 is launching AgentZ Store to curate community servers, while u/guyernest introduced mcp-tester to ensure updates don't break tool-calling logic in CI/CD workflows.
Cognitive Memory Layers Replace Vector DBs r/OpenAI
widemem introduces importance scoring and semantic pruning to solve the noise-to-signal ratio in long-running sessions u/eyepaqmax.
Stepwise Planning Solves Brittle Browsers r/LocalLLaMA
Local Qwen 8B/4B models are beating larger models in browser automation by adopting 'replanning' strategies to avoid state-drift u/Aggressive_Bed7113.
The Great Framework vs. Raw Python Debate r/Rag
Developers report 'night and day' speed differences when moving from LangGraph to minimalist alternatives like PydanticAI to reduce abstraction taxes u/daeseunglee.
Optimizing Blackwell for Local LLMs r/LocalLLaMA
Forcing P2P over PCIe with NCCL_P2P_LEVEL=1 fixes vLLM hangs on consumer Blackwell rigs, hitting 45 tokens/sec on 70B models u/Opteron67.
Hard-Stop Safety Sync
As agent swarms hit production, developers are ditching prompt-based guardrails for deterministic circuit breakers and formal logic.
Today’s agentic landscape is moving past the experimental prompt phase and into the reality of hard engineering. We are seeing a convergence of three critical pressures: the failure of LLM-based safety at scale, a looming hardware bottleneck for local deployment, and the harsh reality of enterprise security vulnerabilities. The introduction of veronica-core signals a pivot toward deterministic containment—circuit breakers and kill switches—because an agent cannot be trusted to police itself once it hits a recursive loop or unauthorized tool-calling sequence. This matches the shift we see in coding agents, where vibes-based testing is being replaced by formal verification tools like the new Claude Code plugin for Dafny. Meanwhile, the hardware dream of 24/7 autonomous labor is hitting physical limits. While Figure 03 and Walker S2 push the boundaries of embodied autonomy, the local agent movement faces an 18-month DRAM supply crisis. For builders, this means the era of lazy compute is over; efficiency and verified logic are the new prerequisites for production-grade agentic systems. Every token and every tool call must now be accounted for within a framework of hard budget caps and mathematical certainty.
Hard-Stop Safety: Moving Beyond Prompt-Based Guardrails for Agentic Swarms
As developers scale to systems involving 30+ agents, the limitations of prompt-based guardrails are becoming a critical failure point, leading to a shift toward deterministic runtime containment. amabito0369 has introduced veronica-core, an open-source library that implements circuit breakers, kill switches, and policy engines to hard-stop agents before they exceed operational boundaries. Unlike traditional prompting, which agents can hallucinate past, veronica-core enforces constraints at the execution layer, specifically targeting 'scope creep' where agents enter infinite loops or unauthorized tool-calling sequences.
The community is currently debating whether safety should reside in 'governor agents' or the infrastructure layer. While sacredseed3 advocates for coordination-level boundaries, others in the AG2 community warn that a governor is still an LLM prone to its own failures. The emerging consensus favors a 'smart layer on top, dumb layer on the bottom' architecture, where tools like Guardrails AI or NVIDIA NeMo Guardrails enforce hard budget caps and strict schema validation that the agent's reasoning cannot bypass.
Join the discussion: discord.gg/pAbnzhJr7u
CISA Adds n8n RCE to KEV List, Highlighting Internal Agentic Risks
CISA has officially added the n8n automation platform to its Known Exploited Vulnerabilities (KEV) list following an RCE flaw (CVE-2025-5678) that allows Remote Code Execution. While community member .joff confirms the issue was addressed in version 1.122.0, security researcher @vulnerability_lab warns that agentic workflows often bypass traditional WAFs by operating within trusted VPCs. With federal agencies given until April 3, 2026, to patch, this represents a Grade A threat for enterprise AI deployments where agents often hold the 'keys to the house' via hardcoded API keys.
Join the discussion: discord.gg/n8n
The Hardware Hump: ASUS Ascent GX10 and the 18-Month DRAM Supply Crisis
The shift toward local agentic workflows faces a significant logistical bottleneck in the form of a projected 18-month DRAM crisis. While the ASUS Ascent GX10 personal AI supercomputer offers 128GB of LPDDR5X unified memory for $2,950, developer aimark42 reports that the market is entering a 'hump before the dump' phase with supply constrained until 2027. This scarcity forces builders into 'clever coding' strategies to bypass hardware limits, making the efficiency of the agentic loop as critical as the model's raw reasoning capability.
Join the discussion: discord.com/invite/localllm
Formal Verification: Moving Beyond Vibes-Based AI Coding
Developers are pivoting from vibes-based testing to mathematical certainty by integrating formal verification languages like Dafny directly into the agentic loop. .0xswan is leading this shift with a Claude Code plugin that allows models to prove logic before execution, aiming to shatter the 41% accuracy ceiling seen in traditional agentic security benchmarks. According to @tony_fast, the use of Model Context Protocol (MCP) servers for formal solvers enables agents to self-correct using formal counter-examples rather than recursive hallucinations.
OpenClaw and Ollama Drive Local Computer Use Parity
OpenClaw is emerging as the leading open-source alternative for local 'computer use' agents, while Ollama's v1 API brings OpenAI-compatible tool-calling to the local stack. Join the discussion: discord.gg/ollama
Mistral Small 4 and the NVFP4 Efficiency Breakthrough
Mistral-Small-4-119B leverages NVFP4 quantization to achieve a 2.5x throughput increase on Blackwell hardware, hitting 600 t/s in prompt processing for local reasoning. Join the discussion: discord.com/invite/localllm
Figure 03 and the Quest for 24/7 Autonomous Labor
The Figure 03 robot introduces 16-DOF hands for nuanced tasks, while the Walker S2 features a 2-minute self-swapping battery mechanism for 24/7 factory operations. Join the discussion: discord.gg/claude
Code-Centric Research
Hugging Face's minimalist framework is crushing benchmarks by ditching the JSON sandwich for raw Python execution.
The 'JSON sandwich' is finally going stale. For months, developers have wrestled with the friction of forcing LLMs to output strictly formatted schemas just to trigger basic tools. Today, we are seeing a decisive pivot toward code-centric autonomy. Hugging Face’s smolagents and the new Open DeepResearch framework aren't just incremental updates; they are a rejection of heavy-handed abstraction in favor of raw, executable Python. By allowing agents to write and run their own logic, we’re seeing SOTA scores on the GAIA benchmark that were previously untouchable by traditional orchestration layers.\n\nThis shift isn't limited to software scripts. We’re seeing a parallel evolution in how agents interact with the physical and digital worlds. From NVIDIA’s 'physical reasoning' models for healthcare robotics to specialized VLMs like Holo1-70B that can actually navigate a desktop GUI, the trend is clear: specialization and direct action are winning. Meanwhile, researchers from IBM and Berkeley are providing the diagnostic tools we need to understand why these systems fail, identifying tool-calling as a primary culprit for cascading errors. In this issue, we dive into the minimalist frameworks, desktop benchmarks, and reasoning breakthroughs defining the current agentic frontier.
Smolagents and the Rise of Code-Centric Minimalist Autonomy
Hugging Face has solidified the shift toward minimalist agent design with smolagents, a library that bypasses the 'JSON sandwich' problem by allowing agents to execute actions directly through Python code. This programmatic approach has proven empirically superior to traditional schema-based orchestration, with Aymeric Roucher demonstrating a 0.43 SOTA score on the GAIA benchmark. The framework's emphasis on simplicity is best illustrated by its support for the Model Context Protocol (MCP), enabling developers to deploy functional agents in as few as 50 to 70 lines of code.\n\nBeyond basic task execution, the ecosystem is rapidly expanding into multimodal and enterprise-grade workflows. Hugging Face recently introduced Vision Language Model (VLM) support within the library, allowing agents to process visual inputs for UI navigation and document analysis. To address the 'cascading reasoning errors' often found in complex trajectories, integration with Arize Phoenix provides open-source tracing and evaluation, ensuring that these lightweight agents remain observable and verifiable.\n\nBy prioritizing direct, executable logic over heavy abstraction layers like LangChain, smolagents is redefining the standard for high-performance, edge-ready autonomous systems. Community adoption is surging, with the agents-course/First_agent_template Space now exceeding 650 likes, signaling a clear developer preference for code-as-action over rigid schema-based tool calling.
Holo1 and ScreenSuite Set New Benchmarks for Desktop Autonomy
The drive toward autonomous computer use is accelerating with the release of ScreenSuite, a diagnostic evaluation suite featuring over 100 tasks across 10+ desktop applications. Hcompany has introduced Holo1-70B, a specialized VLM designed to power the Surfer-H agent, which achieved a 38.2% success rate on the ScreenSuite benchmark, significantly outperforming GPT-4o's 25.4% and Claude 3.5 Sonnet's performance. These developments are supported by ScreenEnv, providing the infrastructure for reproducible Linux environments, though researchers note that maintaining long-horizon state remains a critical hurdle for specialized post-training recipes designed to mitigate cascading reasoning errors.
The Rise of Open-Source DeepResearch
Hugging Face has launched Open DeepResearch, an open-source framework that achieves a 67.4% SOTA score on the GAIA benchmark by replacing brittle 'JSON sandwich' tool-calling with a CodeAgent architecture. Built on the smolagents library, the system empowers models like Qwen2.5-72B-Instruct to write and execute Python code natively, leveraging specialized tools including the DuckDuckGoSearchTool and a vision-integrated VisitWebpageTool. Community-driven implementations like MiroMind and ScholarAgent are already tailoring this logic for domain-specific tasks, providing a transparent baseline for security auditing that rivals closed-source search giants.
Unpacking 'Aha' Moments and Strategic Information Allocation
Recent research into the 'Aha moment' in LLMs reveals that self-correction is a byproduct of reinforcement learning that encourages the model to allocate more test-time compute to difficult problems. According to A Theory of Reasoning in Large Language Models, reasoning is characterized by the explicit externalization of uncertainty through tokens like 'Wait,' signaling a transition to active self-correction. This 'strategic information allocation' is being commercialized through frameworks like ServiceNow AI's Apriel-H1, which hits 82.4% accuracy on MATH-500, and AI-MO's Kimina-Prover which uses test-time RL search to generate Lean 4 formal proofs.
Scaling Physical AI: From Healthcare Foundation Models to Embedded VLA Deployment
NVIDIA's new Cosmos models and LeRobot's 100+ datasets are scaling physical AI, while NXP brings VLA models to the edge with sub-100ms latency.
Diagnosing Enterprise Agent Failure at Scale
IBM Research and UC Berkeley's IT-Bench reveals that 38.5% of enterprise failures are caused by tool-calling errors that trigger cascading reasoning breaks.
Agent Ecosystems and Orchestration Partnerships
The langchain-huggingface partner package and IBM's CUGA are standardizing multi-agent interoperability and native tool-calling for open-weight models.