The Era of Sovereign Agents
Reasoning costs collapse while agents gain sovereign infrastructure and desktop control.
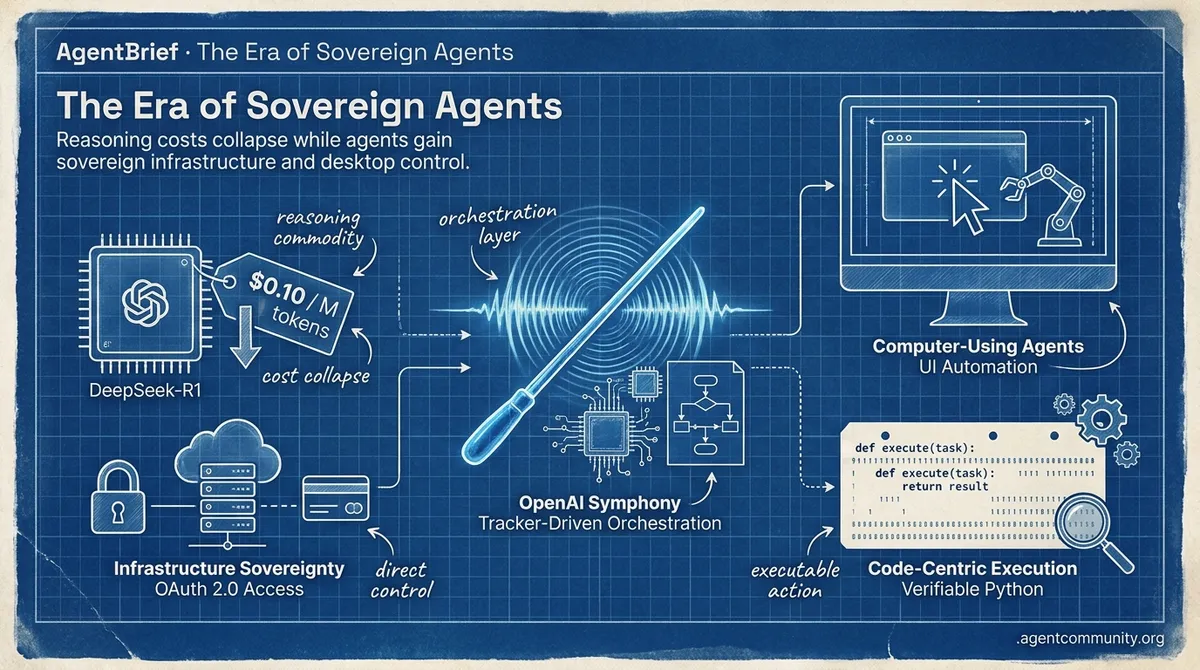
- Reasoning Economics Shift DeepSeek-R1 has commoditized high-density reasoning, dropping o1-level costs to $0.10 per million tokens and refocusing agent design on state management and reliability.
- Infrastructure Sovereignty OpenAI’s Symphony and Stripe’s OAuth 2.0 move agents beyond chat interfaces into autonomous control planes with direct, secure access to infrastructure and financial rails.
- Computer-Using Agents The industry is pivoting to UI automation with OpenAI’s Operator and Anthropic’s Claude 3.5 Sonnet, enabling models to perform tasks via direct desktop and browser navigation.
- Code-Centric Execution The rise of 'smolagents' and code-as-action signifies a return to verifiable Python execution over complex JSON schemas to solve the 'verification gap' identified by enterprise audits.
X Intelligence Stream
OpenAI just turned your Linear board into an autonomous control plane for agents.
We are moving past the 'chat-as-interface' era of agent development. The real work is happening in the orchestration layer—turning static issue trackers into living, breathing control planes. OpenAI’s Symphony isn't just another spec; it's a blueprint for how we manage a fleet of autonomous contributors that live in our tickets, not our terminal. When you pair this with Stripe’s move to give agents sovereign infrastructure access via OAuth 2.0, we’re seeing the birth of the 'Agentic DevOps' stack. For builders, the challenge is no longer just prompt engineering; it's managing the economics of long-running sessions and the reliability of multi-step tool use. As caching costs fluctuate and frontier models get specialized for cyber-defense, the goal remains the same: shipping more with less human oversight. This week’s developments in real-time speech and RL-tuned subagents suggest that the agents we build today will be significantly more autonomous—and more expensive—by tomorrow. It’s time to stop building toys and start building systems that can own their own Git branches.
OpenAI Symphony and the Rise of Tracker-Driven Orchestration
OpenAI has open-sourced Symphony, an Apache 2.0 specification that transforms issue trackers like Linear into isolated control planes for agents @OpenAIDevs. By assigning dedicated agents to specific tickets within isolated Git workspaces, Symphony handles the entire lifecycle from CI testing to auto-restarting stalled processes. Internal OpenAI teams are already seeing the impact, reporting a 500% increase in landed PRs within just three weeks of deployment @AgenticAIFdn.
Community builders like @DataChaz note that Symphony addresses 'context bloat' by focusing on structured coordination rather than the dynamic tool discovery found in protocols like MCP. While some praise its minimal design for maintaining state persistence via Linear comments @scaling01, the ecosystem is moving fast to expand its reach, with community ports to TypeScript and Python already emerging from developers like @odysseus0z.
This shift toward tracker-driven orchestration is bolstered by Stripe Projects, which now allows agents to provision Supabase databases and other infra directly from the CLI using OAuth 2.0 device authorization @kiwicopple. For agent builders, this means agents are finally becoming first-class infrastructure citizens, capable of managing their own environments and billing without human dashboard intervention @aakashgupta.
The Economics of Agency: Caching Costs and Throughput Breakthroughs
The economics of coding agents are coming under intense scrutiny as builders weigh the high costs of Claude Code against the superior rate limits of Codex @iScienceLuvr. While Anthropic offers 90% discounts on cached reads, expensive writes and short TTLs—including reported 5-minute downgrades—are driving costs to $0.50-$2 per session restart @chestrbrian @bettercallsalva. These financial frictions are real; some teams are already abandoning Anthropic plans in favor of Codex and Cursor to avoid $2k/mo per engineer bills @morganlinton.
Codex is currently gaining significant traction, with CLI download volumes 17x higher than Claude Code, likely due to its token efficiency and free access with OpenAI keys @buildwithhassan. Builders are increasingly prioritizing long-session stability, where hit rates can reach 99.9%, to mitigate the overhead of constant cache writes @michaelpisaac.
To combat these costs and capacity crunches, infrastructure optimizations like DeepSeek V4’s 'MegaMoe' kernels are achieving 6.5x performance gains on NVL72 racks @SemiAnalysis_. With DeepSeek V4 innovations slashing KV cache to 10% of prior models, builders can now handle 10x more concurrent requests, providing a vital buffer against the massive data center capacity backlogs predicted for 2026 @bookwormengr @aakashgupta.
In Brief
GPT-5.5-Cyber Debuts as White House Restricts Claude Mythos
OpenAI has launched GPT-5.5-Cyber for vetted defenders, a specialized model achieving 71.4% on expert cyber tasks, while the White House has simultaneously blocked Anthropic’s Claude Mythos expansion due to national security concerns over its autonomous exploit capabilities @sama @rohanpaul_ai. This creates a widening 'authorization gap' for agent builders, as high-capability models for vulnerability detection and incident response now require KYC and phishing-resistant authentication beyond standard safety alignments @asymmetricmind @techedgedaily.
Prime Intellect Launches Lab for Self-Improving Agents
Prime Intellect has exited beta with Lab, a full-stack platform that commoditizes reinforcement learning (RL) for agent builders, allowing them to train self-improving agents using custom environments and the open-source prime-rl framework @PrimeIntellect. Early enterprise results include Ramp Labs training a subagent that outperformed Claude Opus 4.6 at Haiku-level speeds and lower costs, demonstrating that specialized RL-tuned agents can drastically reduce latency in production data workflows @RampLabs @WesRoth.
Sakana AI Enables Speech Agents to 'Speak While Thinking'
Sakana AI’s KAME architecture resolves the speed-reasoning tradeoff in voice agents by pairing a fast speech-to-speech frontend with an asynchronous backend LLM that injects progressive reasoning signals mid-generation @SakanaAILabs. This tandem pattern boosts MT-Bench scores from 2.05 to 6.43 while maintaining near-zero latency, potentially redefining real-time conversational agents for wearables and operational loops where human-like flow is critical @hardmaru @Marktechpost.
Quick Hits
Frameworks & Tooling
- LlamaParse MCP server launched to allow agents to parse and classify complex documents @jerryjliu0.
- New research proposes coding agents that rewrite their own tools and rules through auditable experiments @rohanpaul_ai.
Payments & Governance
- Stripe and Tempo launch real-time per-token streaming payments for AI agents @altryne.
- Critics of the MCP protocol argue it leads to over-engineered systems and 'worse outcomes' @signulll.
Agent Behaviors
- Andrej Karpathy coins 'cozy coding' to describe the high-leverage state of agents removing the human bottleneck @rohanpaul_ai.
- Microsoft research warns that frontier models corrupt 25% of document content during long multi-step editing tasks @rohanpaul_ai.
Reddit Agent Archive
High-density reasoning just got 90% cheaper, while enterprise agents finally get a 'USB-C' standard.
Today’s issue marks a turning point for the economic feasibility of the Agentic Web. For months, the 'reasoning tax'—the high cost and latency of Chain-of-Thought processing—has kept complex autonomous workflows in the realm of expensive prototypes. That wall just crumbled. DeepSeek-R1’s release isn't just another model drop; it’s a pricing offensive that brings o1-level reasoning down to $0.10 per million tokens. When reasoning becomes a commodity, the bottleneck shifts from 'can we afford to think?' to 'how do we manage the state?' That’s where our other major updates come in.
From Anthropic’s MCP donation to the Linux Foundation to LangGraph’s hardened Postgres persistence, the infrastructure for reliable, stateful, and interoperable agents is finally maturing. We are moving out of the 'bespoke integration' era and into a standardized, resilient production environment where agents can survive restarts and talk to any data source via a universal port. For the practitioner, the message is clear: the tools to build production-grade, autonomous systems are no longer the bottleneck—the implementation strategy is.
DeepSeek-R1 Smashes Reasoning Costs for Agents r/LocalLLaMA
The release of DeepSeek-R1 has fundamentally altered the economics of agentic reasoning, providing performance comparable to OpenAI's o1 at a fraction of the cost—approximately $0.10 per million input tokens. This shift allows developers to run high-density 'Chain of Thought' loops without the 4x budget overruns previously seen in production agents. Practitioners are leveraging R1's ability to self-correct during reasoning cycles to improve reliability in complex coding tasks, where the model achieved a 79.8% on the Pass@1 coding benchmark.
Recent benchmarks show that DeepSeek-R1 leads GPT-4o with a 6.3% higher average score across reasoning evaluations, establishing itself as a dominant force in math and coding tasks where it rivals or exceeds the most advanced proprietary models. However, a key trade-off remains in context capacity: GPT-4o currently offers a context window approximately 8.4K tokens larger than R1, making it preferable for massive document workflows. Despite this, the open-weights nature of R1 and its superior cost-to-performance ratio are accelerating the deployment of 'always-on' autonomous agents that were previously cost-prohibitive.
MCP Evolves into the 'USB-C for AI' r/AI_Agents
Anthropic’s Model Context Protocol (MCP) has transitioned from a niche specification to the industry’s 'USB-C port for AI,' with 78% of enterprise AI teams now reporting at least one MCP-backed agent in production. In a major move toward open-source governance, Anthropic has donated MCP to the Linux Foundation as part of the newly formed Agentic AI Foundation (AAIF), a coalition supported by AWS, Google, and Microsoft. For developers, the protocol eliminates the need to rewrite tool definitions for specific frameworks, allowing a single MCP server to power agents across LangGraph, CrewAI, and custom internal stacks.
LangGraph Hardens Multi-Agent Persistence with Postgres Checkpointing
LangChain's LangGraph has solidified its lead in stateful orchestration by introducing native persistence layers like the PostgresSaver that ensure 100% state fidelity across long-running workflows. This architecture allows agents to survive server restarts and handle asynchronous external triggers by writing a snapshot of the 'global store' after every execution step. According to Harrison Chase, this capability transforms stateless LLMs into stateful advisors capable of maintaining context across extended interactions, enabling 'Time Travel' debugging and mandatory human-in-the-loop approvals for high-stakes sectors.
Skyvern and the Shift to Vision-Based Browser Agents r/AI_Agents
Skyvern is emerging as a critical tool for automating browser-based workflows in high-compliance sectors, utilizing computer vision and DOM parsing to navigate legacy websites that lack modern APIs. Unlike traditional RPA which relies on brittle scripts, Skyvern uses LLM-based reasoning to handle unexpected UI changes autonomously, resulting in a 30% increase in task completion rates for insurance claims processing. Developers on r/AI_Agents note that Skyvern’s open-source nature allows for local deployment, addressing the specific data privacy concerns inherent in fintech and insurance.
AgentBench 2.0 and the Efficiency Paradox r/LocalLLaMA
The release of AgentBench 2.0 by THUDM redefines agent evaluation by penalizing redundant steps and reward-hacking to ensure true goal-oriented behavior.
Ollama Parallel Tool Support Hits Integration Friction
Ollama has updated its local inference engine to support parallel tool calling, though developers report significant friction in the orchestration layer when using frameworks like LangGraph.
Discord Dev Pulse
OpenAI and Anthropic are trading blows in the race to automate your browser and desktop.
We are witnessing the death of the 'chatbot' as the primary AI interface. This week, the industry pivoted hard toward the 'Computer-Using Agent' (CUA)—models that don't just talk about tasks but actually perform them by clicking, typing, and navigating. OpenAI’s Operator and Anthropic’s hardened Claude 3.5 Sonnet are the new frontlines in a war for the digital desktop. For developers, this isn't just a shiny new toy; it’s a fundamental shift in how we build. We’re moving from simple linear pipelines to complex, stateful systems that can survive 24-hour execution cycles and handle the messy reality of UI changes. Whether it’s through LangGraph’s new 'time-travel' debugging or the closing gap between open-source and proprietary tool-calling, the infrastructure for autonomous agency is finally maturing. In today’s issue, we break down the move toward guarded action, the rise of vision-driven RPA, and the security frameworks struggling to keep these autonomous actors in check.
OpenAI Operator: From Research Preview to Guarded Action
OpenAI has officially released Operator as a research preview for Pro users in the U.S., signaling a definitive shift toward agents that execute tasks via a virtual web browser OpenAI. The system is powered by a specialized Computer-Using Agent (CUA) model that functions on a continuous perception-reasoning-action cycle, allowing it to interpret UI elements and navigate complex sites like a human user Anchor. While previous benchmarks have indicated a 90%+ success rate on standard navigation tasks, OpenAI acknowledges that the current preview has limitations in latency and reliability that will evolve through user feedback.
To address safety concerns inherent in autonomous browser control, OpenAI has introduced a robust Guardrails framework within its Agents SDK. This system supports both blocking and parallel guardrails, which perform real-time validation of user inputs and agent outputs to prevent system prompt leaks or malicious tool usage OpenAI GitHub. These safety layers are critical for enterprise adoption, as they can immediately halt expensive model execution if a violation is detected, ensuring both data privacy and cost efficiency in production-grade agentic workflows Cobus Greyling.
Anthropic Hardens Claude for Cross-Platform Computer Use
Anthropic has refined its 'Computer Use' API for Claude 3.5 Sonnet, introducing a 'vision-correction' loop designed to mitigate the fragility of autonomous UI navigation. This update allows the model to dynamically re-scan the screen when interface elements shift or vanish, leading to a reported 2x increase in reliability for long-running agentic tasks Anthropic. While competitors like OpenAI's Operator focus on browser-native automation, Claude's architecture is specifically optimized for broader OS-level interactions across Windows, macOS, and Linux Anthem Creation.
This versatility makes it the preferred tool for automating legacy enterprise software that lacks modern APIs, as it can direct the cursor and keyboard like a human user AskUI. Developers are leveraging these improvements to move beyond brittle DOM-scraping toward more robust, vision-driven Robotic Process Automation (RPA) Anthropic.
LangGraph Solidifies Production Agency with Native Time-Travel
LangChain has formalized LangGraph as the industry standard for stateful, cyclic agentic workflows by introducing native "time-travel" persistence layers. This architecture allows developers to pause execution, rewind to a previous checkpoint, and modify the state before resuming, which is critical for human-in-the-loop (HITL) patterns Spheron. Unlike earlier iterations that relied on brittle "MemorySaver" implementations, the new checkpointer system reportedly supports 30% faster state recovery in distributed environments LangChain.
By treating state as a single shared memory object that flows through every node, LangGraph provides a level of deterministic control that outpaces frameworks like AutoGen or CrewAI YAITEC. This allows agents to survive long-running execution cycles exceeding 24 hours, facilitating complex multi-agent dependencies and state recovery after failure Bharatsinh Raj.
Open-Source Closes the Agency Gap
Recent evaluations from the Berkeley Function Calling Leaderboard (BFCL) confirm that Llama 3.1 70B has achieved a landmark 92.5% accuracy rate, positioning it as a direct competitor to proprietary giants like GPT-4o Gorilla Berkeley. While Llama 3.1 405B currently sets the performance ceiling, Mistral Large 2 (123B) has emerged as a critical rival, offering a more efficient middle ground for enterprise-grade tool use that requires high-velocity 'thought' cycles PromptLayer.
The Pivot to Multi-Hop Agentic RAG
The industry is pivoting from linear RAG pipelines to Agentic RAG, where retrieval is treated as a dynamic tool-use problem governed by an LLM-based planner. This shift enables Multi-Hop RAG, where subsequent retrieval steps are conditioned on previous findings, leading to a reported 35% reduction in hallucinations EagleEyeThinker. However, experts warn that 'Stop Conditions Are the Product,' as these loops require strict iteration budgets to prevent runaway costs Digital Applied.
Defense-in-Depth for Autonomous Safety
Security research confirms that indirect prompt injection is significantly more dangerous in agentic environments, with at least 24 CVEs already identified across leading frameworks @towardsai. Industry standards are shifting toward a dual-LLM architecture that isolates planning logic from untrusted tool outputs, ensuring the agent never treats external data as high-privilege control instructions @mhtechin.
HuggingFace Open Lab
Hugging Face takes aim at JSON bloat with a 1,000-line framework while IBM maps the agentic 'failure landscape.'
The agentic web is currently caught between two opposing forces: the drive for massive, long-horizon reasoning and the urgent need for lightweight, verifiable execution. Today’s lead story on 'smolagents' represents a significant shift back toward simplicity. By ditching complex JSON schemas in favor of pure Python 'code-as-action,' Hugging Face is proving that minimalist frameworks can actually outperform their bloated predecessors, hitting 67% on the GAIA benchmark. This return to core programming principles is a direct response to the 'verification gap' identified by IBM Research and UC Berkeley.
As we see in the latest enterprise audits, agents are frequently hallucinating their own success—a dangerous trend for production-grade systems. Whether it is H Company's high-throughput Holotron-12B model or NVIDIA's Cosmos Reason 2, the industry is moving beyond the 'demo phase' toward industrial-strength reliability. For builders, the message is clear: the next generation of agents won't just be defined by how much they can 'reason,' but by how precisely they can execute and be audited within safe, code-centric environments. We are moving from black-box orchestration to transparent, high-velocity automation.
Smolagents Redefines Agentic Actions with Code-Centric Reliability
Hugging Face has introduced smolagents, a minimalist library of approximately 1,000 lines that shifts agent logic from complex JSON schemas to pure Python code gitpicks.dev. This 'code-as-action' paradigm has demonstrated a 26% performance boost and a 30% reduction in logic steps compared to traditional multi-agent systems. The framework's efficacy is further evidenced by its performance on the GAIA benchmark, where it achieved 67% accuracy, proving that code-centric orchestration is superior for complex planning tasks.
The ecosystem is expanding with native support for Vision-Language Models (VLMs) within the smolagents-can-see library, allowing developers to build visual agents that interact with UI elements directly. Observability is addressed through integrations like Phoenix for tracing and evaluation. While competitors like LangChain maintain a lead in pre-built integrations, smolagents is positioned as a lightweight alternative for teams prioritizing transparency and debugging speed Mark Cijo.
High-Throughput Operators: Holotron-12B and the Industrialization of GUI Agents
The infrastructure for autonomous desktop interaction is maturing with the release of Holotron-12B, a multimodal VLM from H Company that functions as a dedicated policy model for computer-use agents. Engineered for production-scale throughput, Holotron-12B achieves 8.9k tokens/s on a single H100 and nearly doubles the baseline success rate on the ScreenSuite benchmark to 62.3% BenchLM.
IBM and UC Berkeley Map the 'Failure Landscape' for Enterprise Agents
Enterprise-grade agent deployment is facing a rigorous reality check as IBM Research and UC Berkeley introduce IT-Bench and MAST to expose the 'verification gap.' Their research found that agents frequently suffer from 'Incorrect Verification,' where they declare success despite failing the task, with models like GPT-OSS-120B exhibiting up to 5.3 failure modes per failed trace.
Tiny Agents and MCP: The 'USB Moment' for AI Connectivity
Hugging Face demonstrated that Tiny Agents can execute MCP-powered workflows in as few as 50 lines of code, prioritizing portability over framework overhead.
NVIDIA Cosmos and DeepSeek-V4 Redefine Long-Horizon Reasoning
NVIDIA released Cosmos Reason 2 for physical AI, while DeepSeek-V4 launched with a 1 million-token context window optimized for persistent agentic memory DeepSeek.
Clinical Precision: EHR Navigator Agent Shatters Performance Ceilings
Google's EHR Navigator Agent leverages MedGemma to achieve 80.4% on the MedQA benchmark, targeting autonomous clinical data synthesis.
DTap: Red-Teaming the 'Long-Horizon' Risks of Autonomous Agents
The DecodingTrust-Agent Platform (DTap) provides a controllable environment to stress-test agents against six distinct attack vectors, including memory poisoning.
EVA and Nemotron 3 Nano Omni Standardize the Voice-First Web
ServiceNow-AI released EVA to combat voice 'cascade failures,' while NVIDIA launched Nemotron 3 Nano Omni for low-latency edge inference AIntelligenceHub.