Agents as Autonomous Economic Actors
From brittle JSON prompts to stateful code-as-action, the plumbing for the autonomous AI economy is being laid.
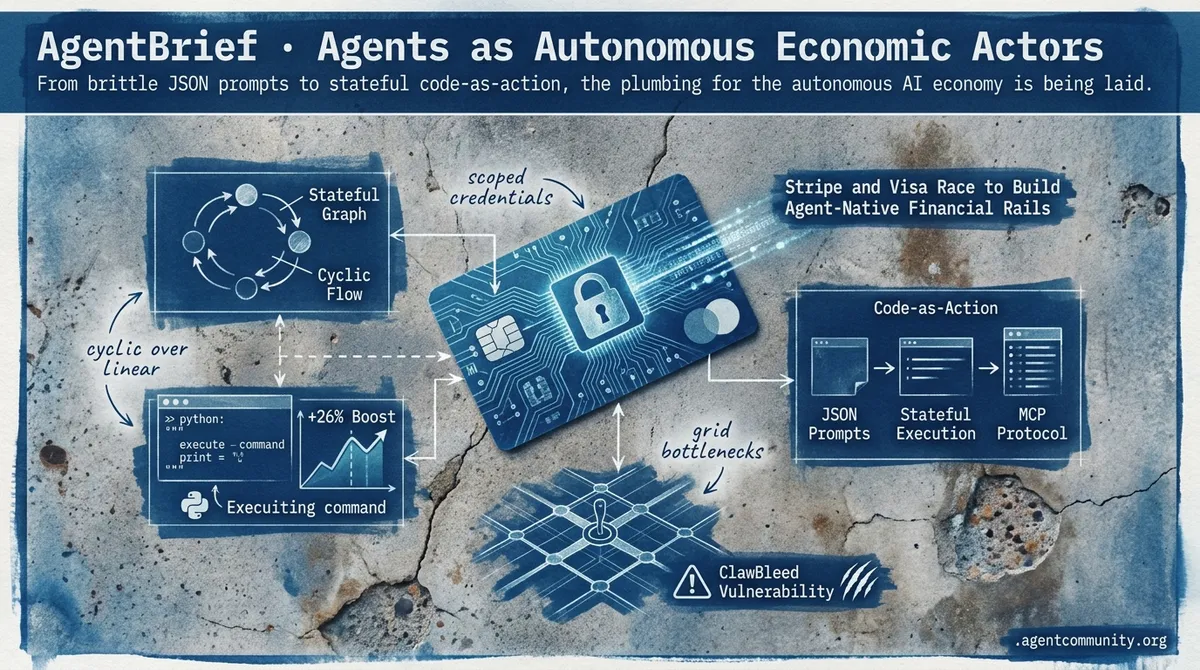
- The Action Era Begins OpenAI’s Operator and the rise of "code-as-action" frameworks like smolagents signal a shift from models that chat to models that execute directly in Python for a 26% performance boost.
- Economic Agentic Infrastructure Financial giants like Stripe and Visa are providing agents with scoped credentials, turning them into autonomous actors capable of managing transactions and infrastructure independently.
- Stateful Reliability Gains The industry is moving past linear DAGs toward cyclic, stateful graphs and standardized protocols like MCP to solve the persistent 20% success ceiling in complex IT tasks.
- Hardware and Security Constraints While inference speeds reach 9,000 tokens per second, physical grid bottlenecks and vulnerabilities like "ClawBleed" highlight the real-world limits of autonomous scaling.
The X Intel
Your agents just got a credit card, a Jira login, and a five-year power backlog.
The agentic web is moving past the 'chatbot' era and into the 'economic actor' phase. This week, we saw the plumbing of the AI economy take shape as financial giants like Stripe and Visa finally offered agents their own scoped credentials. This isn't just about payments; it’s about the fundamental shift from agents as tools to agents as autonomous entities capable of managing infrastructure and settling transactions on-chain. Meanwhile, OpenAI’s Symphony spec is proving that the 'autonomous factory' isn't a future dream—it's already landing 500% more PRs for internal teams. As builders, we are moving from prompting to orchestrating complex, long-horizon systems. However, the physical world is pushing back. With five-year backlogs for grid transformers, the race for agentic throughput is hitting a hard ceiling of copper and steel. Success in this new era requires more than just a good prompt; it requires navigating the paradoxes of token caching, the complexities of RL-tuned harnesses, and the regulatory gates closing around frontier models. The infrastructure is here, but the power—literally—is the new bottleneck.
Stripe and Visa Race to Build Agent-Native Financial Rails with Scoped Controls
Financial giants are racing to wire the economic layer for the agentic web. Stripe launched Link for agents, treating AI agents as headless devices via the OAuth 2.0 device authorization grant (RFC 8628). This allows users to grant scoped permissions on Link accounts without exposing raw payment credentials, requiring human approval for every purchase as noted by @stripe and @aakashgupta. This infrastructure pairs with Stripe's Tempo partnership for streaming per-token payments on the Machine Payments Protocol (MPP), enabling sub-cent onchain settlements with sub-second finality @altryne.
Visa is countering with the Trusted Agent Protocol (TAP), which utilizes agent-specific tokens with unique cryptograms to allow merchant acceptance without requiring infrastructure changes @Alex__Radu. While these protocols compete, the community remains divided on governance. As @chrisyyau pointed out, liability remains anchored to the human approver through revocation and audit logs, yet unresolved issues like platform bans and over-spend governance still loom over the ecosystem @LUKSOAgent.
For agent builders, this signals a shift from agents as simple assistants to agents as primary economic drivers. With Stripe Projects, agents can now spin up infrastructure like Supabase databases via CLI without any human dashboard intervention @kiwicopple. As 47% of US shoppers already use AI for tasks, these rails are being positioned as the 'central bank for the AI economy,' forecasting millions of agent transactions by the 2026 holiday season @aakashgupta.
Prime Intellect's RL Lab Enables Self-Improving Agents in Long-Horizon Environments
Prime Intellect's 'Lab' has emerged as a full-stack platform for post-training research, specifically designed around agent harnesses and performance rubrics @PrimeIntellect. The first RL Residency cohort shipped a suite of specialized environments, including CARLA-Env for embodied driving, Hanabi for multi-agent game theory, and PMPP-Eval for GPU/CUDA programming, all aimed at testing long-horizon stability via verifiable execution in sandboxes @PrimeIntellect.
Parallel research in agent harness tuning via RL is showing significant gains in model performance. Evolved harnesses have boosted Terminal-Bench 2 pass@1 from 69.7% to 77.0%, outperforming human and Codex-CLI baselines while using 12% fewer tokens on SWE-bench @omarsar0. This focus on harness evolution is critical, as stability gaps remain wide; FrontierSWE tests for ultra-long coding currently show success rates at less than 10% @PrimeIntellect.
This matters for builders because it moves agent development from prompt engineering to rigorous environmental training. By using trace mining and continual learning frameworks, developers can address the 'forgetting' problem in sequential tasks @PrimeIntellect. Prime Intellect is now seeking Cohort II projects to further explore these long-horizon evals and complex coding challenges @PrimeIntellect.
OpenAI's Symphony Spec Turns Issue Trackers into Autonomous Code Factories
OpenAI has released Symphony, an open-source agent orchestrator spec that transforms task trackers like Linear into autonomous control planes. The system assigns a dedicated agent to every open issue within an isolated workspace, complete with its own Git branch and CI tests, effectively generating pull requests for human review without manual intervention @OpenAIDevs. The reference implementation is in Elixir, though the community is already porting it to TypeScript and Python @ryancarson.
The impact on developer throughput is staggering, with internal OpenAI teams reporting a 500% increase in landed PRs within the first three weeks of use @DumbEinstein. As @karpathy noted, this aligns with the 'cozy coding' vision where developers act as overseers of high-throughput agent fleets. The project's repository hit 15k GitHub stars almost immediately, highlighting a massive appetite for agents that can ship code in parallel @koltregaskes.
While Symphony offers massive gains—some builders report running 5+ concurrent agents shipping 100% of their code—it is not without friction. Developers must manage token costs and complex conflict resolutions in multi-agent environments @daniel_mac8. OpenAI has clarified that Symphony is intended as forkable infrastructure rather than a maintained product, leaving the responsibility of scaling and refinement to the developer community @DumbEinstein.
In Brief
Frontier Cyber and Science Models Face Regulation and Gated Access
OpenAI and Anthropic are facing increasing regulatory pressure as they roll out specialized frontier models like GPT-5.5-Cyber and Claude Mythos. GPT-5.5-Cyber is being deployed to trusted defenders for tasks like malware analysis @sama, while Claude Mythos has demonstrated a 29.6% success rate on expert-stumped bioinformatics tasks @rohanpaul_ai. However, the White House has reportedly blocked Anthropic's expansion due to national security concerns regarding software vulnerability exploitation @AndrewCurran_. This creates a significant 'authorization gap' for agent builders, who may find GPT-5.5-Cyber a more accessible alternative at $1.73 per task @asymmetricmind.
Sakana AI's KAME Enables Speech Agents to 'Speak While Thinking'
Sakana AI's new KAME architecture eliminates the speed-depth tradeoff in voice agents by using a fast frontend and an asynchronous backend LLM to inject 'oracle signals' mid-sentence. Benchmarks show that this tandem approach jumps MT-Bench scores from 2.05 to 6.43 with ~0ms added median latency, nearly matching the quality of much slower cascaded systems @Marktechpost. The open-source release includes model weights and inference code, making it a plug-and-play upgrade for developers building real-time voice agents for wearables @SakanaAILabs. While some developers like @dangauerke argue for optimized prompts on newer S2S models, KAME's backend-agnostic nature provides a resilient path for multimodal orchestration @PhantomByteAI.
5-Year Grid Transformer Backlog Stalls Half of US AI Data Center Capacity
A massive 5-year backlog on high-voltage grid transformers has stalled nearly half of the planned 12 GW of US AI data center capacity for 2026. Only 5 GW of the announced capacity is currently under construction, as lead times for critical electrical gear have ballooned from 24 months to 5 years @aakashgupta. Hyperscalers like Alphabet and Meta have committed over $650B in capex, but physical bottlenecks in switchgear and grid-tie batteries are turning AI growth into an infrastructure duration play @TFTC21. Builders are now forced to explore behind-the-meter generation and fuel cells to bypass the multi-year queues for new factory capacity @SajKhosa.
The Caching Paradox: Disabling Anthropic Caching Cuts Costs for Some
Developers are finding that Anthropic's prompt caching can actually increase costs for certain agent workflows due to high write rates and a short 5-minute default TTL. For intermittent loops where tasks occur every 30 minutes, the 1.25x write cost outweighs the savings, leading builders like @theo to disable the feature entirely for better efficiency. However, for continuous long-context workflows with stable prefixes, caching still offers up to 90% savings with read hit rates as high as 97.7% @chiefofautism. The consensus among builders is that caching is a 'first-class storage tier' that requires careful prefix management to avoid 'cache-busting' results @PullNews.
Quick Hits
Agent Frameworks
- Deep Agents SDK now supports ACP for serving agent TUIs in editors like Zed @Vtrivedy10.
- Ao Agents launched a Next.js UI for remote management of Codex and Claude Code @agent_wrapper.
- A new multi-platform GUI agent framework with integrated memory and tools has been released @tom_doerr.
Tool Use & Data
- LlamaParse released an MCP server for direct document parsing by AI agents @jerryjliu0.
- ClickHouse added native AI functions and disk-spilling JOINs for large-scale agent data @ClickHouseDB.
- Microsoft research warns AI assistants corrupt ~25% of document content during long editing tasks @rohanpaul_ai.
Models & DX
- Gemini 3.1-flash-LITE shows 'shockingly strong' knowledge density for its size @teortaxesTex.
- DeepSeek V4-Flash is significantly exceeding knowledge-per-parameter trends @teortaxesTex.
- Box is creating 'Agent Engineering' roles to integrate autonomous agents into business processes @levie.
- The Zig project has banned AI-assisted contributions to focus on human contributor growth @simonw.
Reddit Action Log
OpenAI's Operator signals the shift to autonomous labor, but low benchmark scores and security flaws prove the 'Action Era' is still in beta.
The 'Action Era' has officially arrived, but it is bringing a heavy dose of reality with it. OpenAI’s launch of Operator marks a symbolic shift from models that talk to models that do, yet the early benchmarks—specifically a 38% score on OSWorld—suggest that the road to truly autonomous web labor is still under construction. For developers, the message is clear: the frontier is moving away from raw reasoning and toward the 'plumbing' of reliability and interoperability.
We are seeing this play out across the stack. From the professionalization of the Model Context Protocol (MCP 2.0) to the rise of schema-first frameworks like PydanticAI, the industry is aggressively moving away from 'vibe-based' engineering. The 'ClawBleed' vulnerability reminds us that giving agents browser access is a high-stakes security game, while DeepSeek’s massive price disruption is forcing a re-evaluation of the economics of agentic loops. Today’s issue looks at the tools and standards attempting to turn these autonomous dreams into production realities. Whether it is Microsoft’s ledger-based Magentic-One or the latest BFCL V3 results that pinpoint exactly why agents fail, the focus has shifted from 'what can it say' to 'how can we make it work reliably.'
OpenAI Operator and the Dawn of the 'Action Era'
OpenAI has officially entered the agentic race with the launch of Operator, a research preview that signals a fundamental shift into the 'Action Era,' where AI moves from answering questions to executing web-based labor. Unlike standard chat interfaces, Operator uses a vision-and-action loop to interact with DOM elements directly, performing tasks such as filling out forms and navigating complex browser workflows OpenAI. Currently available to Pro users in the U.S., the tool is being integrated into the broader ChatGPT ecosystem to redefine how users interact with the web.
Despite the hype, technical performance remains a point of debate among early adopters. Benchmarks reveal that Operator currently holds a 38% OSWorld score, a metric that has led some critics to label the release a 'beta test' that carries a high price tag for enterprise-level access coasty.ai. While OpenAI targets 200ms latency for its Realtime API to ensure seamless interaction, the system still faces significant limitations that require iterative refinement through user feedback mobileproxy.space. This move further validates the industry-wide transition toward standardized agent perception protocols like A2A and MCP 2.0.
MCP 2.0 and the Professionalization of the Agentic Web r/mcp
The Model Context Protocol (MCP) has solidified its position as the 'USB port' for the agentic web, with 78% of enterprise AI teams now reporting at least one MCP-backed agent in production Digital Applied. This rapid adoption is driven by the protocol's ability to decouple tool definitions from specific model providers, allowing a single 'server' to expose resources to any compliant client. The ecosystem has matured with the release of MCP 2.0, which introduced Agentic Session Tokens to standardize state sharing across disparate providers techbytes.app. However, this interoperability 'gold rush' has hit an infrastructure wall; recent audits exposed the 'ClawBleed' RCE vulnerability affecting approximately 7,000 servers, prompting a shift toward deterministic enforcement using Tool Permission Matrices u/PolicyLayer.
PydanticAI Challenges LangGraph with Schema-First Logic
PydanticAI is gaining traction by bringing rigorous data validation to agents, treating them as high-level constructs defined by data schemas rather than graph-based state machines ZenML Blog. This 'schema-first' approach ensures that tool calls adhere to strict types, effectively reducing the 'spaghetti code' and non-deterministic 'natural language vibes' that often plague earlier frameworks. While LangGraph remains the preferred choice for enterprise-grade systems requiring complex branching, early adopters report that PydanticAI 'clicks right away' for developers already familiar with Python typing emasterlabs.com. By integrating directly with Pydantic’s validation logic, it provides a deterministic layer for structured outputs, ensuring that LLM responses are validated before execution.
DeepSeek-V3.1 Challenges Frontier Models r/LocalLLaMA
DeepSeek-V3.1 has disrupted the agentic landscape by providing GPT-4o class performance at roughly 0.1x the cost of proprietary leaders, outperforming them on SWE-bench Verified YouTube. While Claude 3.5 Sonnet remains the gold standard for complex architecture, DeepSeek-V3 excels at generating direct, functional code for agentic tool-calling loops with a 128K context window and 90% accuracy on specialized reasoning tests Artificial Analysis. Users on r/LocalLLaMA note that while Claude maintains an edge in nuanced planning, DeepSeek’s cost-efficiency and high tool-use accuracy make it a preferred choice for high-volume production workflows.
Magentic-One: Microsoft’s Ledger-Based Solution r/LangChain
Microsoft’s Magentic-One addresses agent reliability through a 'Lead Orchestrator' and dynamic task ledger to prevent the 'Loops of Death' common in unmanaged systems Microsoft Research.
BFCL V3 Resets Leaderboard: GLM-4.5 and Qwen Outpace GPT-4o
The Berkeley Function Calling Leaderboard (BFCL) V3 update reveals that 85% of production failures stem from incorrect tool parameterization, with GLM-4.5 now leading the rankings at 77.8% @awagents.
Discord Dev Deep-Dive
The shift from rigid pipelines to cyclic, state-aware loops is redefining the agentic stack.
The industry is reaching a critical inflection point where the limitations of linear 'Directed Acyclic Graph' (DAG) chains are becoming a bottleneck for production-grade reliability. Today’s most significant developments highlight a decisive pivot toward stateful, cyclic architectures that allow agents to reason, fail, and self-correct in real-time. This isn't just a conceptual shift; it is being codified by frameworks like LangGraph and standardized through the Model Context Protocol (MCP), which now boasts over 500 public servers. As we move away from 'one-shot' prompting toward autonomous systems with tiered memory and human-in-the-loop steerability, the focus for developers is shifting from raw model power to the orchestration of complex, long-running processes. Whether it is Llama 3.1 405B dominating tool-calling benchmarks or the emergence of minimalist 'handoff' patterns in OpenAI Swarm, the goal is the same: predictable, scalable agency. In this issue, we dive into the architectural shifts making these autonomous enterprise systems possible and the security hurdles—like the recent MCP design flaws—that still remain.
Stateful Graphs Overthrow Linear Agent Chains
The development community is decisively pivoting away from rigid, linear 'Directed Acyclic Graph' (DAG) chains toward cyclic architectures that allow for re-planning and iterative research. Ben Hultin notes that these cyclic loops are essential for robust error correction, enabling agents to self-correct during multi-step tasks rather than failing at the first hurdle. Recent experiments have demonstrated that this shift to graph-based reasoning yields a significant improvement in task completion efficiency compared to traditional linear implementations.
At the center of this shift is LangGraph, which has established itself as the standard for multi-agent coordination by utilizing a shared state object that persists across various agent nodes. This shared state, combined with the checkpointer API, allows production systems to scale to 1,000+ concurrent stateful threads. By treating orchestration as a state machine rather than a simple sequence, developers are building 'circular' workflows that can resume from failures without losing progress, effectively bridging the gap between experimental bots and autonomous enterprise systems.
Standardizing Agentic Data Access via the MCP Registry
The Model Context Protocol (MCP) has rapidly scaled from an Anthropic-led initiative into a cross-industry standard, now boasting over 500 public servers as official support extends to OpenAI and Google DeepMind. By decoupling models from tool-specific implementations, MCP has enabled a 40% reduction in integration time for developers, though recent technical audits have exposed a systemic 'design flaw' in the official SDK that could potentially enable Remote Code Execution (RCE) by bypassing explicit user permissions during file modification tasks.
The Battle for Tool-Calling Precision: BFCL v3 and Beyond
Llama 3.1 405B Instruct currently leads the Berkeley Function Calling Leaderboard (BFCL) with a precision score of 0.885, setting a high bar for open-weights models in multi-step tool interactions. This success is increasingly supported by specialized sub-agent architectures, where developers are seeing a 15% improvement in success rates when using fine-tuned 'small' models (8B to 14B) dedicated specifically to tool-calling rather than general-purpose reasoning.
Join the discussion: discord.gg/berkeley-function-calling
From Safety Gates to Steerability: The HITL Architectural Shift
Human-in-the-loop (HITL) is transitioning from a peripheral safety feature to a core architectural requirement, enabling 'steerability' where users modify an agent's plan mid-execution rather than merely approving or rejecting it. This shift is supported by Generative UI frameworks like CopilotKit and stateful orchestration in LangGraph, allowing agents to present visual representations of their thought processes for human validation before high-stakes actions.
OpenAI Swarm's 'Handoff' Pattern Standardizes Multi-Agent Logic
The 'handoff' has become the preferred primitive for building multi-agent systems, as minimalist frameworks like OpenAI Swarm prioritize predictable control flow over opaque autonomous reasoning.
From Infinite RAG to Tiered 'Working Memory'
Practitioners are shifting toward hybrid memory systems that use 'Rolling Summaries' to compress history, yielding a 30% improvement in factual accuracy during extended agentic sessions.
HuggingFace Code-as-Action
Hugging Face and NVIDIA are trading brittle JSON strings for direct Python execution and physical logic.
The era of the "agentic chatbot" is ending. We are entering the age of the "autonomous operator." This week, Hugging Face signaled a massive shift with the release of smolagents, prioritizing a "code-as-action" paradigm over the brittle, prompt-dependent JSON tool calling we’ve lived with for the past year. By executing Python directly, these agents are seeing a 26% performance boost and a 30% reduction in logic steps—metrics that matter when you’re building for production. But it’s not just about cleaner code; it’s about speed and verification. While NVIDIA is bridging the physical reasoning gap with Cosmos Reason 2, high-throughput models like Holotron-12B are pushing desktop automation to nearly 9,000 tokens per second. However, the data shows we aren't quite at the finish line. New benchmarks from IBM and Berkeley reveal a persistent 20% success ceiling in IT tasks, largely due to "Incorrect Verification"—agents declaring victory before the job is actually done. For builders, the takeaway is clear: the path to reliability lies in structured code execution, faster inference, and diagnostic, rather than descriptive, evaluation. Every update this week points toward a more robust, verifiable, and high-velocity agentic web.
Hugging Face Leads 'Code-as-Action' Pivot with smolagents
Hugging Face is aggressively pivoting toward a "code-first" agentic paradigm with the release of smolagents, a minimalist library containing only ~1,000 lines of core code Hugging Face. By shifting from brittle JSON-based tool calling to direct Python execution, this approach achieves a 26% performance improvement and a 30% reduction in logic steps compared to traditional frameworks like LangGraph or CrewAI, as noted by @pooyagolchian. This philosophy is being paired with official support for Vision-Language Models (VLMs) via smolagents-can-see, allowing agents to navigate visual GUI elements natively.
To bridge the gap to production, the ecosystem is standardizing its infrastructure through Transformers Agents 2.0 and the 'License to Call' framework, which provides a protocol for tool permissions and granular control over how LLMs interact with external APIs Hugging Face. Interoperability is now central to the strategy, anchored by a new Hugging Face x LangChain Partner Package and Agents.js, which brings native JavaScript support for agentic tool use to TS/JS environments Hugging Face.
By prioritizing Structured Code Execution, these frameworks are moving the industry toward programmatically-enforced actions. This shift is further supported by the integration of the Model Context Protocol (MCP), which acts as a 'USB moment' for AI, allowing agents to discover and invoke tools across disparate platforms through a unified communication standard Hugging Face.
High-Throughput Computer Use Reaches New Latency Milestones
The shift toward autonomous desktop control is being redefined by SSM-based models like Holotron-12B, which delivers 8.9k tokens/s on a single H100 to enable production-scale GUI navigation. This performance allows the Surfer-H agent to reach a 62.3% success rate on the ScreenSuite benchmark, significantly outperforming the 36.1% baseline of general-purpose models like GPT-4o H Company.
Diagnostic Benchmarks Reveal a 20% Success Ceiling in IT Tasks
IBM Research and UC Berkeley have introduced the MAST framework to analyze complex workflows, identifying that "Incorrect Verification" (FM-3.3) is the primary driver of agent failure. Their findings highlight a persistent 20% success ceiling in enterprise IT troubleshooting, where agents consistently declare victory without confirming the environment's state IBM Research.
NVIDIA Cosmos Reason 2 Bridges the Physical Reasoning Gap
NVIDIA Cosmos Reason 2 integrates long chain-of-thought reasoning directly into physical AI tasks to help agents understand space, time, and fundamental physics NVIDIA.
LinkedIn Unlocks Agentic RL for Open-Source Models
LinkedIn has detailed a framework for agentic RL that uses a closed-loop training cycle to compute rewards based on verifiable outcomes rather than simple preference LinkedIn.
AI vs. AI Framework Fosters Strategic Reasoning
Hugging Face recently introduced the AI vs. AI system, a deep RL framework designed for multi-agent competitions to drive innovation in strategic autonomous reasoning Hugging Face.