Hardening the Autonomous Execution Layer
From browser-navigating operators to economic wallets, agents are shifting from passive chat to parallel, transactional autonomy.
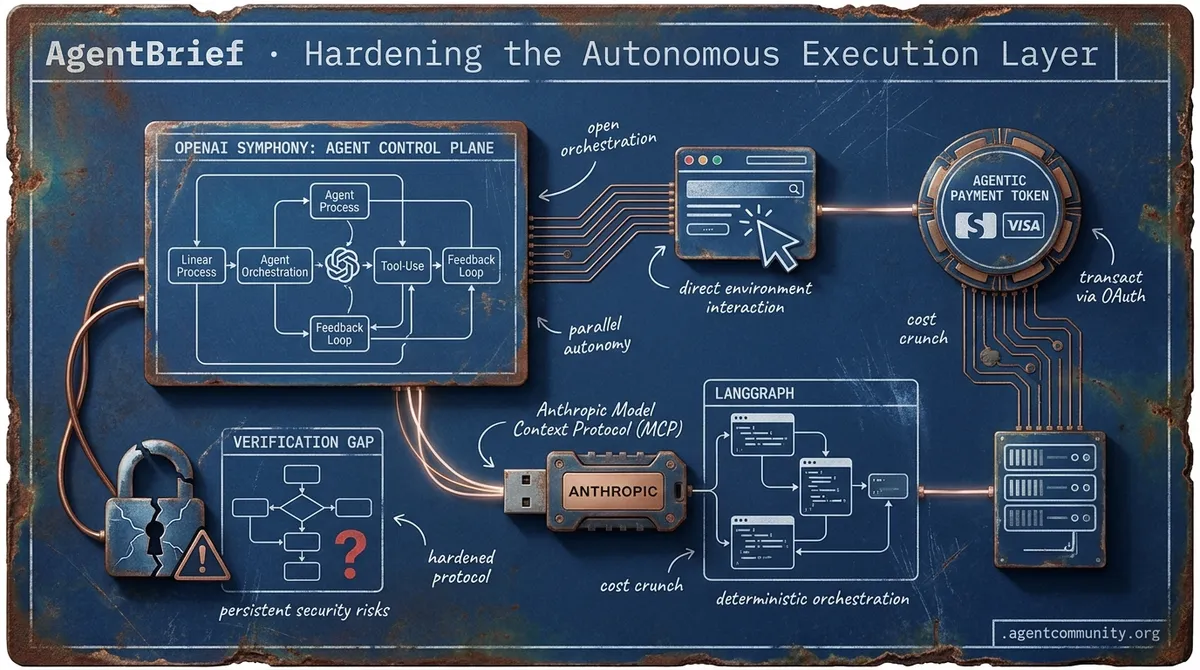
- The Action Pivot OpenAI’s Operator and H Company’s Holotron-12B signal a decisive industry shift toward high-speed GUI and browser automation, moving agency beyond the chat box into direct environment interaction. - Protocol Hardening Anthropic’s Model Context Protocol (MCP) is emerging as a 'USB moment' for connectivity, while frameworks like smolagents and LangGraph prioritize code-based, deterministic orchestration over probabilistic prompts. - Economic Integration The financial plumbing for AI is arriving as Stripe, Visa, and Mastercard enable agentic wallets, allowing autonomous systems to settle compute bills and transact via OAuth device grants. - The Verification Gap As practitioners move from vibe-coding to production, persistent security risks like indirect prompt injection and the 'verification gap' in task completion remain the primary hurdles to enterprise deployment.
X Intelligence Sync
If your agents aren't handling parallel PRs and settling their own compute bills yet, you're building in the past.
We are witnessing the transition from agents as assistants to agents as autonomous operators. This week’s developments signal a massive infrastructure pivot. OpenAI is finally moving past the single-thread prompt with Symphony, treating issue trackers like Linear as control planes for parallel agent fleets. Meanwhile, the financial plumbing is catching up. Stripe, Visa, and Mastercard are racing to give agents their own wallets via OAuth device grants—meaning the 'buy' button is no longer human-exclusive. For builders, this means our focus must shift from prompt engineering to orchestration and economic governance. We aren't just coding logic anymore; we're managing digital workforces that can pass CI, relax atomic structures, and settle their own inference costs in sub-seconds. The agentic web isn't a future state; it’s a series of protocols being wired right now. Whether it’s the RL breakthrough from Prime Intellect or the tandem voice architectures from Sakana, the bottleneck is moving from 'can they think?' to 'how fast can they execute and transact?' If you aren't building for parallel, paid, and specialized agency, you're falling behind the new standard for autonomous systems.
OpenAI Open-Sources Symphony: Turning Linear Into an Agent Control Plane
OpenAI has open-sourced Symphony, a specification designed to orchestrate Codex coding agents by utilizing issue trackers like Linear as always-on control planes. Under this framework, a dedicated agent is assigned to every open issue within an isolated workspace, complete with its own Git branch and CI tests, as detailed by @OpenAIDevs and @alex_frantic. This architecture enables parallel execution across multiple complex tasks without human prompting, as Symphony monitors the board, automatically restarts stalled agents, and ensures PRs are only generated after passing CI hurdles @ainativedev.
The results of this shift are staggering: internal OpenAI teams reported a 500% increase in landed PRs within just 3 weeks. This moves the human developer into a role of high-level review and direction rather than constant supervision, as noted by @sherwinwu via @0xLogicrw. Symphony manages task synchronization through Linear as the single source of truth, where agents update issue status and create sub-tasks for dependencies—such as ensuring a Vite migration finishes before a React upgrade begins @ryancarson.
However, builders should be wary of the scaling walls currently inherent in the system. While parallelization is achieved via independent workspaces, early adopters like @daniel_mac8 and @MindTheGapMTG have highlighted challenges including token costs and rate limits that hit at 10 concurrent agents. Despite these friction points, the community is already moving fast, with Elixir reference implementations for concurrency and forks appearing for Claude Code to extend these parallel capabilities @xchunhx169889.
Prime Intellect RL Lab Ships Verifiable GPU and Materials Science Agents
Prime Intellect's 'Lab' platform has released the first results from its RL Residency, delivering open-source environments tailored for high-stakes agentic reinforcement learning. Key releases include PMPP-Eval, which focuses on CUDA/GPU programming skills through verifiable coding exercises, and CARLA-Env, a high-fidelity urban simulation for embodied decision-making with integrated physics and sensors @PrimeIntellect @PrimeIntellect. These environments represent a shift toward agents that can master specialized, low-level technical domains through iterative training.
The residency cohort completed nearly 10,000 training runs during its beta phase, automating complex research tasks ranging from GPU optimization to multi-agent game theory experiments like Hanabi and the Prisoner’s Dilemma @PrimeIntellect. Notably, agents in the materials science track used CHGNet rewards to iteratively relax atomic structures, demonstrating that RL agents can now navigate the complexities of physical science as effectively as they do software logic @PrimeIntellect.
For agent builders, this platform lowers the barrier to entry for production-grade RL. Zapier is already utilizing the platform for RL on AutomationBench to detect and mitigate reward hacks, ensuring agents remain aligned with intended outcomes @PrimeIntellect. As applications open for Cohort II, the focus is shifting toward autonomous AI research and long-horizon computer use, signaling that the next wave of agents will be defined by their ability to self-improve across complex, multi-step horizons @PrimeIntellect.
The Payment Race: Turning Agents Into Economic Actors via RFC 8628
Stripe, Visa, and Mastercard are aggressively deploying dedicated payment rails to transform agents into independent economic actors with scoped financial access @aakashgupta. Stripe’s 'Link for agents' leverages the OAuth 2.0 device authorization grant (RFC 8628)—the same protocol used for smart TV logins—to allow agents to request permissions via CLI commands. This grants agents the ability to use one-time virtual cards for approved purchases without ever exposing the user's primary credentials @stripe.
Beyond simple purchases, the infrastructure for machine-to-machine micro-transactions is going live. Stripe’s partnership with Tempo has introduced the Machine Payments Protocol (MPP), enabling streaming per-token payments with sub-cent onchain settlements and sub-second finality @altryne. This allows agents to pay for their own inference or API usage in real-time, effectively creating a self-sustaining autonomous economy for software services.
A four-way protocol war is now underway between TAP (Visa), ACP (Mastercard), MPP (Stripe/Tempo), and UCP. Visa’s Trusted Agent Protocol (TAP) is particularly notable for using agent-specific tokens with unique cryptograms that allow merchants to accept agent payments without changing their existing infrastructure @aakashgupta. With 47% of US shoppers already using AI for tasks and millions of agent transactions forecast by the 2026 holidays, the primary unresolved challenge remains governance and liability for autonomous over-spending @NathanielC85523.
In Brief
Sakana AI Ships KAME for 'Speak While Thinking' Low-Latency Voice
Sakana AI has introduced KAME, a tandem speech-to-speech architecture that allows voice agents to provide near-zero latency responses by running a fast frontend model in parallel with a deep reasoning backend. This architecture breaks the traditional speed-depth tradeoff, allowing models like Claude Opus or GPT-4.1 to inject 'oracle signals' mid-sentence for real-time refinement, which helped jump MT-Bench scores from 2.05 to 6.43 @SakanaAILabs @AiDevCraft. While the system is open-source and already reducing proposal generation times from weeks to minutes in production settings, some developers note that gains can be marginal compared to highly optimized prompts on newer models like Gemini 3.1 @SakanaAILabs @dangauerke.
White House Blocks Anthropic’s Claude Mythos Expansion Over Security Risks
The White House has formally opposed Anthropic's plan to expand access to its Claude Mythos model, citing national security concerns regarding its ability to identify and exploit software vulnerabilities. Officials argue that wider access could accelerate the weaponization of discovered flaws, effectively turning commercial rollout decisions into high-stakes security priorities @rohanpaul_ai @AndrewCurran_. Despite these restrictions, Mythos Preview has demonstrated elite reasoning by solving 29.6% of 'human-difficult' bioinformatics problems that experts failed, using real-world datasets and biology tools to cross-check evidence @rohanpaul_ai @asymmetricmind.
The Great Coding Agent Switch: Codex Quotas vs. Claude Remote Control
Agent builders are increasingly navigating the trade-off between Claude Code’s superior mobile remote control and OpenAI Codex’s significantly higher rate limits, which were recently boosted 10x for many users. While Claude Code excels at 'on-the-go' supervision, it is frequently hampered by erratic billing and low limits, prompting many practitioners to switch to Codex for sustained, multi-turn development sessions @iScienceLuvr @jeffreyhuber. To bridge the gap, the community has developed workarounds using Tailscale, tmux, and custom apps like Shellular to provide remote access to the Codex stack while waiting for OpenAI's teased native remote features @TheRohanVarma @agent_wrapper.
Quick Hits
Models & Capabilities
- Gemini 3.1 Flash-Lite is showing knowledge capabilities that rival larger models like Sonnet 4.5. @teortaxesTex
- OpenAI is rolling out GPT-5.5-Cyber to frontier defenders to secure critical digital infrastructure. @sama
Agentic Infrastructure
- The LlamaParse MCP server enables agents to autonomously navigate complex documents via URL-based endpoints. @jerryjliu0
- Amazon Quick now supports internal intelligent apps and live agentic dashboards for enterprise data. @awscloud
Developer Experience
- Andrej Karpathy introduced 'cozy coding' to describe the low-friction future of AI-assisted dev work. @MatthewBerman
Reddit Agent Lab
DeepSeek outpaces GPT-5.2 in agentic efficiency while builders pivot from vibe-coding to hardened workflow specs.
We are entering the vibe-check era of agentic development. The initial honeymoon phase—where throwing a prompt at an LLM and calling it an agent felt like magic—is hitting the cold wall of production reality. Gartner's grim prediction that 40% of agentic projects will fail by 2027 isn't a sign of AI's decline, but of its maturation. Builders are moving toward a Tiered Maturity Curve, shifting from probabilistic prompts to deterministic Skills and rigid Systems.\n\nThis week's data points are striking. DeepSeek V4 Pro is now matching or beating GPT-5.2 on business-logic benchmarks while running 17x cheaper. Meanwhile, the hardware layer is catching up, with native Multi-Token Prediction (MTP) doubling inference speeds on Apple Silicon. But with power comes peril: the rise of slopsquatting and unauthenticated MCP servers reminds us that the agentic supply chain is still a Wild West. If you aren't hardening your workflows and auditing your LLM-suggested dependencies today, you're building on sand. Today’s issue explores how practitioners are moving from vibe-coding to hardened, interoperable infrastructure.
DeepSeek V4 Pro Outpaces GPT-5.2 in Agentic Efficiency r/LocalLLaMA
DeepSeek V4 Pro is officially making its move on the frontier tier. In the latest FoodTruck Bench—a grueling 30-day business simulation—the 1.6T MoE model scored 84/100, leapfrogging GPT-5.2's score of 81. As u/Disastrous_Theme5906 points out, this isn't just a win for open-weights; it’s a massive efficiency play, providing similar reasoning outcomes at roughly 17x cheaper than proprietary giants.\n\nThe model's success stems from its ability to juggle 34 distinct tools and manage persistent memory over long horizons, thanks to its 1M token context window. However, the battle isn't over. While DeepSeek dominates in tool-calling and reasoning efficiency, Artificial Analysis notes that GPT-5.2 still holds the crown for multimodal tasks, as DeepSeek currently lacks native image input support.
Slopsquatting and the MCP Security Crisis r/AI_Agents
The security landscape for agents is getting weirder and more dangerous. A new threat called slopsquatting is weaponizing LLM hallucinations. Since roughly 20% of packages suggested by LLMs do not exist, attackers are proactively registering those ghost names with malicious payloads. u/Kindly_Leader4556 highlights that this turns a simple copy-pasted install command into a backdoor for your entire pipeline, a risk punctuated by the recent compromise of the LiteLLM package on PyPI.\n\nInfrastructure vulnerabilities are also mounting around the Model Context Protocol (MCP). u/ultrathink-art warns that MCP currently lacks native authentication or rate limits, a gap recently exploited to inject malicious servers into tools like Claude Code and Cursor. In response, developers are adopting pre-execution gates to ensure human-in-the-loop verification before any destructive operations execute.
Stop Building Agents, Start Cleaning Workflows r/AgentsOfAI
The industry is reaching a vibe-check moment where the rush to deploy agents is colliding with the reality of operational overhead. As u/The_Default_Guyxxo argues, many practitioners are jumping to agentic solutions for messy processes that aren't yet defined, leading to agents that inherit—and amplify—systemic unreliability. This lack of rigor can be expensive; u/llamacoded shared a cautionary tale of a recursive agent that burned $342 over a single weekend.\n\nTo bridge this gap, builders are adopting Spec-Driven Development (SDD), treating Markdown specifications as executable source code. This allows teams to validate AI actions against rigid requirements rather than vibe-coding. Tools like reivo-guard are helping to enforce these standards, using EWMA anomaly detection to kill runaway loops before they drain credits, signaling a broader shift toward invisible infrastructure where the model is removed from stable parts of the loop.
Apple Silicon Hits 63 Tokens Per Second via Native MTP r/LocalLLaMA
Local inference on Apple Silicon has achieved a significant performance milestone with the release of MTPLX, a native Multi-Token Prediction (MTP) engine. u/YoussofAl demonstrated a jump from 28 tok/s to 63 tok/s on a Qwen3.6-27B model running on an M5 Max. This 2.24x speedup is achieved by utilizing the model's built-in MTP heads, allowing for parallel token generation without the overhead of external drafter models.\n\nEven the functional ceiling for Mixture of Experts (MoE) models is being dismantled. u/ur_dad_matt successfully ran the massive Qwen3.5-397B model on a 64GB Mac Studio by employing paged memory techniques. While the resulting 1.6 tok/s is modest, it marks the first time a model with a 209GB disk footprint has been locally interrogated on hardware with less than a third of the required memory.
Claude Ships Creative Connectors as MCP Hits 97M Downloads r/ClaudeAI
Anthropic has officially launched Claude for Creative Work, a suite of 9 official MCP connectors bridging LLM reasoning with software like Blender, Adobe Creative Cloud, and Unreal Engine. As detailed by u/Intelligent-Lynx-953, these connectors enable Claude to read live project states and execute complex actions directly within host applications. The broader ecosystem is scaling rapidly, with MCP surpassing 97 million downloads.\n\nSimultaneously, the A2A (Agent-to-Agent) Protocol is emerging to solve the coordination wall where mismatched message formats often cripple multi-agent systems. Supported by standards like Google's A2A, this protocol enables specialized agents to form modular teams and coordinate complex workflows across diverse vendor systems, moving beyond simple request-response loops toward sophisticated digital workforces.
The Tiered Memory Stack: Redis vs. Sub-10ms Retrieval r/AgentsOfAI
The memory stack for production agents is professionalizing into a tiered architecture that prioritizes deterministic state recovery. u/AnnualSpecialist1491 highlights a growing preference for Redis to manage short-term session persistence alongside LangGraph checkpointers for robust state recovery. This prevents state rot during long-running tasks that plagued earlier, purely ephemeral designs.\n\nFor high-performance needs, the new semantic search runtime Moss is gaining traction by offering sub-10ms retrieval for in-process memory. Technical audits confirm that Moss eliminates the network overhead inherent in external databases, positioning it as a high-performance local search engine for agents that require real-time context without the round-trip delay of cloud-based vector providers.
Discord Dev Pulse
OpenAI pivots to functional agency as Operator enters the browser automation arena.
The agentic landscape has officially shifted from 'thinking' to 'doing.' With the launch of OpenAI's Operator, we are seeing the realization of the autonomous browser agent—a tool designed to navigate the web as a human would. This isn't just about another chatbot; it's a pivot toward functional execution that places OpenAI in direct competition with Anthropic’s 'Computer Use' API. However, the 'action' layer is only as good as the pipes connecting it. The surge in Model Context Protocol (MCP) servers and LangGraph's new Functional API suggest that developers are prioritizing standardized, stateful orchestration over raw model power. At the same time, the rise of high-performance SLMs like Phi-4 proves that 'small' is the new 'mighty' for edge applications. As we build these autonomous loops, the stakes for security have never been higher. Indirect prompt injection is now the primary threat vector for tool-using agents. Today's issue explores the tools giving agents hands, the frameworks giving them memory, and the vulnerabilities that could bring it all down.
OpenAI Operator Transitions to Research Preview for Action-First Agency
OpenAI has officially stepped into the arena of functional agency with the launch of Operator, a specialized autonomous agent now in research preview for ChatGPT Pro users in the U.S. Unlike its predecessors, Operator isn't just there to chat; it’s designed to take the wheel of a browser to perform multi-step tasks across the web. This marks a definitive pivot for the company, moving from a 'reasoning-first' to an 'action-first' architecture that directly challenges Anthropic’s 'Computer Use' API.\n\nThe move has sparked a flurry of early analysis. While the tool represents a significant leap for the agentic web, industry reports suggest it still faces substantial hurdles when surviving 'contact with real enterprise workflows.' Developers are currently weighing OpenAI's integrated browser environment against more OS-agnostic alternatives, but the signal is clear: the era of the autonomous executor has arrived.
MCP Scales to 500+ Servers, Enabling Standardized 'Code Execution' for Agents
The Model Context Protocol (MCP) has solidified its position as the 'USB-C for AI tools,' with the community ecosystem surging to over 500 public servers and a reported 40% reduction in integration time for enterprise devs. Beyond simple data retrieval, the protocol now supports sandboxed code execution, allowing agents to solve complex data transformations locally—effectively giving models the 'hands' they need to complement the 'brains' of orchestration frameworks like LangGraph.
LangGraph Launches Functional API to Simplify Stateful Multi-Agent Design
LangGraph has introduced a Functional API to simplify stateful multi-agent design, moving away from purely declarative structures to a language-native approach using Python decorators like @task. This shift allows for 100% state recovery and 'time travel' debugging, essential features for moving agents from the playground into production. By combining the flexibility of standard Python with robust persistence, the update makes it significantly easier to build systems that can survive failures or human interruptions without context loss.
Phi-4 and Llama-3-8B Dominate Agentic Edge Computing
Microsoft’s Phi-4 and Llama-3.1 8B are dominating the agentic edge, with Phi-4 matching GPT-4o-mini in STEM reasoning while Llama-3 delivers sub-200ms latencies on local hardware.
Indirect Prompt Injection Emerges as #1 Threat to Agentic Tool Loops
Indirect Prompt Injection has emerged as the #1 threat to agentic tool loops, enabling 'Ghost Tool Calling' where attackers hide malicious instructions in retrieved documents to trigger unauthorized functions.
Browser-use vs. Skyvern: The Battle of Vision-Driven Web Agents
The open-source browser-use library has surpassed 20,000 GitHub stars, leading the vision-driven automation race by handling complex UI changes through LLM visual interpretation.
HuggingFace Hub Insights
From minimalist Python frameworks to standardized tool protocols, the infrastructure for autonomous agents is finally hardening.
We are witnessing a fundamental shift in how agents interact with the world. For years, developers have struggled with brittle JSON tool-calling and 'configuration bloat' that made debugging a nightmare. Today’s developments signal the end of that era. With Hugging Face’s smolagents pushing a 'code-as-action' paradigm and Anthropic’s Model Context Protocol (MCP) providing a 'USB moment' for data connectivity, the infrastructure for the Agentic Web is finally hardening. It is no longer just about the size of the model; it is about the efficiency of the execution loop.
H Company’s Holotron-12B is proving that high-throughput, low-latency 'operators' can outperform cloud giants in GUI automation by sheer speed and specialized vision. Meanwhile, research from IBM and UC Berkeley reminds us that a 'verification gap' still haunts enterprise deployments—agents often think they’ve finished a task when they haven't. For builders, the message is clear: prioritize standardized protocols, lean into code-based logic, and never trust an agent's self-assessment without rigorous state verification. The focus is shifting from 'can it reason?' to 'can it execute reliably?'
Smolagents and the Code-Action Revolution
Hugging Face has launched smolagents, a minimalist library of only ~1,000 lines that shifts agent logic from brittle JSON tool-calling to direct Python execution huggingface. This "code-as-action" paradigm addresses the verbosity and error-prone nature of traditional frameworks like LangChain, which are often criticized for "configuration bloat" and "debugging nightmares" gitpicks.dev. By treating actions as executable snippets, smolagents achieves a 30% reduction in logic steps and a 26% performance improvement over traditional multi-agent systems Mem0.
The robustness of this approach was validated by the Transformers Code Agent, which topped the GAIA benchmark by demonstrating that code-writing agents significantly outperform standard tool-calling methods in complex, multi-step reasoning tasks. To support multimodal operations, the ecosystem now includes smolagents-can-see, enabling agents to navigate visual GUI elements natively. For production-grade reliability, the framework integrates with huggingface for Arize Phoenix tracing and evaluation, ensuring that even a minimal codebase can handle enterprise-level demands.
Standardizing the Agentic Web: MCP and Unified Tool Use
The fragmentation of tool-calling standards is being replaced by a 'USB moment' for AI through the Model Context Protocol (MCP) and the Unified Tool Use initiative. Originally open-sourced by Anthropic, MCP provides a standardized way for LLM applications to interact with data sources, moving away from model-specific schemas toward a modular, plug-and-play architecture. Hugging Face has extended this vision by proposing a single interface that works across disparate model providers, while projects like python-tiny-agents demonstrate that developers can now build MCP-powered agents in as few as 50-70 lines of code to connect instantly to Google Drive, Slack, or GitHub.
High-Throughput "Operators" Redefine Desktop Automation
H Company has released Holotron-12B, a 12B-parameter multimodal model specifically engineered as a high-throughput policy engine for computer-use agents. Developed in collaboration with NVIDIA, Holotron-12B achieves an unprecedented 8.9k tokens/s on a single H100, allowing the Surfer-H agent to reach a 62.3% success rate on the ScreenSuite benchmark—nearly doubling the 36.1% baseline established by GPT-4o H Company. This low-latency architecture, combined with new dynamic testing environments like ScreenEnv, marks a shift toward agents that can mirror real-world user workflows and persistent execution states.
Diagnosing the Failure Modes of Enterprise AI Agents
IBM Research and UC Berkeley's MAST framework identifies a 'verification gap'—where agents declare tasks complete without confirming state—as the primary driver behind the 20% success ceiling in IT troubleshooting IBM Research.
NVIDIA Cosmos and MolmoAct2 Redefine Physical Reasoning
NVIDIA Cosmos Reason 2 brings long chain-of-thought reasoning to robotics, while MolmoAct2 achieves lower latency and higher success rates on novel task adaptation compared to previous VLA models nvidia.
Open Source Deep Research Agents Challenge Proprietary Dominance
Hugging Face's OpenDeepResearch initiative utilizes a CodeAgent framework to reach 67% correct answers on the GAIA benchmark, leveraging SerpAPI for systematic search integration huggingface.