Hardening the Autonomous Action Stack
From 11-minute cyber-defense to deterministic code-as-action, the agentic web is shedding its experimental skin for industrial-grade reliability.
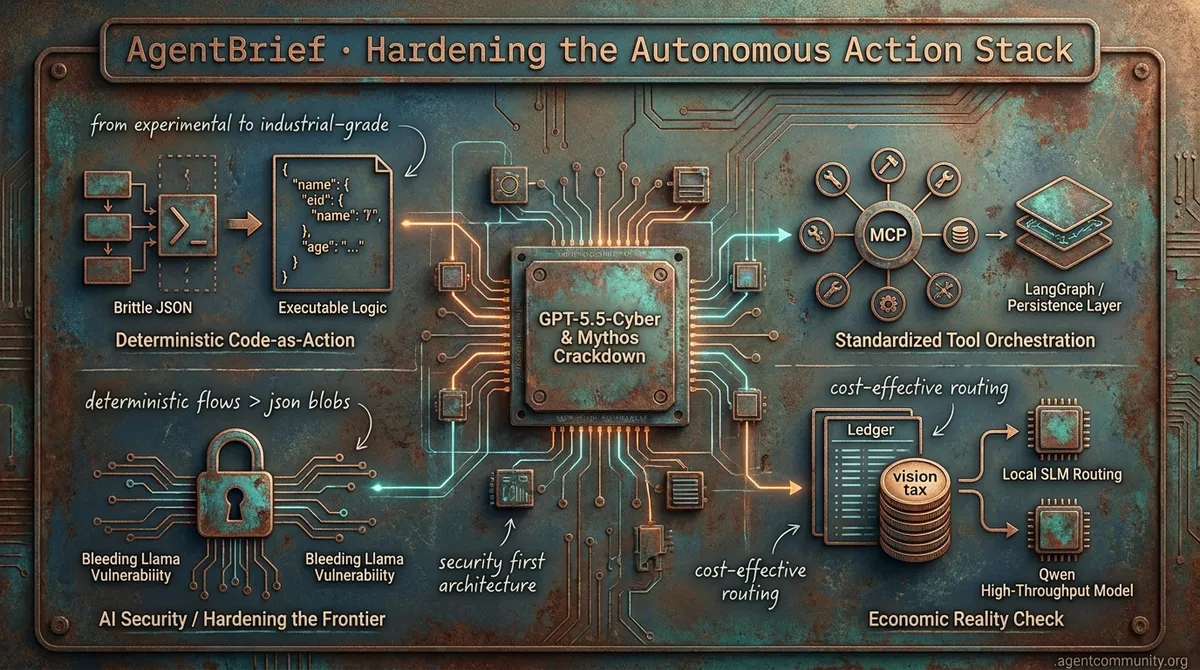
- Deterministic Code-as-Action Hugging Face's smolagents and NVIDIA's Cosmos are leading a shift away from brittle JSON toward executable logic, yielding significant performance gains in complex workflows.
- Hardening the Frontier The discovery of vulnerabilities like 'Bleeding Llama' and the emergence of GPT-5.5-Cyber are forcing developers to prioritize security and isolation as agents move into high-stakes environments.
- Standardized Tool Orchestration The Model Context Protocol (MCP) is rapidly becoming the universal interface for agentic tools, while persistence layers like LangGraph replace stateless RAG patterns to survive messy web-based tasks.
- Economic Reality Check Builders are grappling with the 'vision tax' and context bloat, pivoting toward local SLM routing and high-throughput models like Qwen for sustainable production.
The Cyber Frontier
When agents solve 12-hour security tasks in 11 minutes for under $2, the infrastructure of trust becomes the only bottleneck.
The agentic web is transitioning from a playground for experimental scripts to a high-stakes industrial complex. This week’s developments signal a massive shift: the commoditization of superhuman capability paired with the hardening of its boundaries. We are seeing OpenAI’s Symphony turn project management into an autonomous assembly line, while GPT-5.5-Cyber forces the White House to treat model weights like munitions. For those of us building, the message is clear: the bottleneck is no longer just the model's reasoning—it is the orchestration (Symphony), the latency of the sandbox (E2B), and the protocol for the payout (MPP).
We are moving beyond single-turn prompts into the era of the 'agent fleet.' When you can spin up thousands of hardware-isolated agents in 60ms and give them scoped wallets to buy their own data mid-task, the developer's role shifts from 'writer' to 'architect.' We aren't just shipping code anymore; we are managing autonomous workforces that operate at speeds humans cannot audit in real-time. This issue of AgentBrief explores the tools that make this possible and the gatekeeping that attempts to keep it safe.
Cyber-Offense at Scale: GPT-5.5-Cyber and the Mythos Crackdown
OpenAI has officially begun the rollout of GPT-5.5-Cyber, a frontier model specifically tuned for elite cybersecurity tasks, to a select group of critical defenders. According to @sama, this process involves deep collaboration with government entities to establish 'trusted access' protocols. The performance metrics are staggering: evaluations by the AI Security Institute (AISI) show the model achieving 71.4% on multi-step cyber-attack simulations, effectively solving a human-expert 12-hour reverse-engineering task in just 11 minutes for a total cost of $1.73 @rohanpaul_ai @AISecurityInst.
While OpenAI pushes forward with gated access, Anthropic has hit a regulatory wall with its 'Mythos' model. Reports indicate the White House has opposed Anthropic’s plan to expand access from 50 organizations to 120, citing the national security risks of wider proliferation @rohanpaul_ai. This tension highlights a growing divide in the ecosystem: as models gain the ability to autonomously identify and exploit software vulnerabilities, their commercial distribution is increasingly being treated with the same gravity as weapons technology.
For agent builders, this heralds a new era of 'gated reasoning.' David Sacks has noted that because these models discover existing bugs, defenders must be given priority access to patch them before attackers can weaponize the same intelligence @DavidSacks. As @emollick points out, we are entering a phase where general-purpose reasoning enables autonomous cyber offense and defense at superhuman speeds, making robust agentic oversight a prerequisite for deployment.
OpenAI Symphony: Turning Linear Into an Agent Control Plane
OpenAI has open-sourced Symphony, a new agent orchestrator specification for Codex that fundamentally reimagines the software development lifecycle. By turning task trackers like Linear into 'always-on' control planes, Symphony assigns a dedicated Codex agent to every open issue within an isolated workspace @OpenAIDevs. These agents don't just write code; they poll for issues, dispatch tasks, auto-restart if they crash, and autonomously file follow-up tickets for refactors or dependencies @DataChaz.
Internal data from OpenAI suggests this isn't just a marginal gain; teams reported a 500% increase in landed PRs within just 3 weeks, effectively shipping 5x more code by shifting humans from supervision to high-level architectural review @koltregaskes. The agents provide verifiable 'proof of work,' including CI status, PR reviews, and even walkthrough videos of the changes they've implemented before the human ever sees the pull request @ainativedev.
While the reference implementation is in Elixir, the spec is language-agnostic, though builders are already flagging challenges such as high token costs and the complexities of multi-agent conflict resolution @daniel_mac8. As @aakashgupta observes, this level of automation is set to flood PR queues, potentially repricing engineering roles to favor those who can direct and audit agent fleets rather than those who simply draft code @swyx.
In Brief
Stripe and Tempo Launch Real-Time Streaming Payments for Agents
Stripe has partnered with Tempo to launch the Machine Payments Protocol (MPP), enabling agents to settle sub-cent transactions with sub-second finality. This infrastructure treats agents as distinct devices using OAuth 2.0 device authorization, allowing them to make programmatic purchases via scoped Link wallets without exposing primary credentials @stripe @tempo. Demos featured Claude Code purchasing datasets mid-task, a move @altryne hails as the commoditization of agentic commerce, though critics warn that governance is needed to prevent prompt injection attacks from draining agent-controlled wallets @ChainBountyX.
E2B and CubeSandbox Race to Sub-60ms Agent Spin-Ups
The bottleneck for agent fleets is shifting from reasoning to infrastructure, with E2B hitting 60ms sandbox spin-up times using local NVMe snapshots. By eliminating network storage latency, E2B allows for the parallel execution of thousands of agent instances with zero-network overhead @ivanburazin. Competition is heating up with Tencent’s open-source CubeSandbox, which offers under-60ms cold starts and KVM-based isolation for hardware-isolated agent execution @BeauJohnson89. Builders are pairing these low-latency environments with Cloudflare tunnels to facilitate secure, real-time 'computer use' and remote browser access for autonomous agents @ivanleomk.
Prime Intellect RL Residency Ships Verifiable Agent Environments
Prime Intellect has released a suite of open-source verifiable environments for reinforcement learning, covering everything from GPU programming to multi-agent systems like Hanabi. These environments allow for production-grade RL without heavy infrastructure, already powering nearly 10,000 training runs across specialized domains @PrimeIntellect @xeophon. This move toward verifiable RL coincides with 'Agentic Harness Engineering,' which has boosted Terminal-Bench 2 pass rates from 69.7% to 77.0% by allowing coding agents to evolve their own tools and prompts @rohanpaul_ai.
Quick Hits
Agent Frameworks & Orchestration
- Sakana AI's 'KAME' architecture allows speech agents to 'think while talking' by injecting reasoning into fast response loops @SakanaAILabs.
- LlamaParse released an MCP server to split complex documents directly within agentic workflows @jerryjliu0.
Tool Use & DX
- Meta has granted agents full write access to its Ads system, contrasting with Google's read-only Ads MCP @aakashgupta.
- The Codex CLI now includes an action review feature for monitoring autonomous work on sensitive projects @tom_doerr.
Agentic Infrastructure
- NVIDIA rack-scale systems deliver 6.5x better performance on DeepSeek V4 Pro workloads via disaggregated SGLang @SemiAnalysis_.
- OpenAI will scale agentic workloads on AWS Trainium through a new strategic partnership @theo.
Production Reality Check
From critical Ollama vulnerabilities to the 45x 'vision tax', the honeymoon phase of agentic prototyping is over.
The 'vibe-based' era of agentic development just hit a wall of reality. For months, we've focused on the magic of autonomy, but today’s developments signal a sharp pivot toward 'Boring' Infrastructure: hardening, security, and economic viability. The discovery of the 'Bleeding Llama' vulnerability (CVE-2026-5757) exposes the fragility of the 300,000 Ollama deployments currently powering local agentic experiments. It’s a stark reminder that as we grant agents more power over our file systems, the stakes for security move from theoretical to critical.
At the same time, we’re seeing a rebellion against the 'thinking mode' trend. While reasoning traces look impressive, practitioners are finding them to be a liability in production—bloating context windows and driving up latency without consistently improving tool-calling outcomes. From Qwen’s record-breaking local throughput to the 45x 'vision tax' associated with VLM-based automation, the message is clear: the next phase of the Agentic Web isn’t just about making agents smarter; it’s about making them reliable, secure, and economically sustainable. Today, we break down how builders are moving from fragile prototypes to hardened production systems.
The 'Bleeding Llama' Wake-Up Call r/LocalLLaMA
The 'Action Era' just encountered its first major security crisis. A critical unauthenticated remote information disclosure vulnerability, dubbed 'Bleeding Llama' (CVE-2026-5757), was flagged by u/exintrovert420 in Ollama’s quantization engine. This flaw allows attackers to exfiltrate server heap memory, potentially exposing sensitive session data and private files. With over 300,000 active deployments at risk, the industry is shifting from 'can we build it' to 'can we secure it.'
In response, developers are moving beyond simple prompts toward hardened infrastructure. u/Longjumping-End6278 has released a specialized scanner for LangChain and LangGraph that clones agents into sandboxes to test for tool-bypass exploits. This deterministic approach is being mirrored in the MCP ecosystem, where practitioners are implementing dedicated permission layers to serve as mandatory gatekeepers between autonomous agents and high-risk tools.
Infrastructure Hardening: Beyond the Vibe r/AI_Agents
As agents move from prototypes to production, 'boring' infrastructure is becoming the new frontier of reliability. u/Consistent-Arm-875 argues that idempotency keys are now non-negotiable for external tool calls, preventing catastrophic duplicate actions like double-billing when an LLM experiences high latency. Standardized error handling that distinguishes between model refusals and network timeouts is also becoming a core requirement to prevent recursive loop failures.
Meanwhile, the 'thinking mode' trend is facing a production reality check. u/Substantial_Step_351 notes that verbose reasoning traces are becoming a liability, often consuming 128k+ context windows and causing 'context drift' without significantly improving output. To solve this, developers are pivoting toward specialized agentic runtimes that move the burden of state management from the prompt to the execution layer.
MCP’s Silent Desync and the VRAM Tax r/mcp
The Model Context Protocol (MCP) is hitting early production hurdles as developers struggle with transport layer reliability. Technical audits by u/d3vilzwrld reveal that standard development practices, like using console.log for debugging, can silently corrupt JSON-RPC frames. Because the protocol relies on clean stdout, unexpected logs can cause the client to desync without the server crashing, necessitating the use of structured notifications defined in the official MCP Specification.
On the hardware front, resource management is becoming less of a barrier. The new mcprt supervisor tool has successfully reduced idle MCP server memory from 1.5 GB down to just 16 MB by implementing an on-demand revival system. According to u/winwinwinguyen, this optimization allows complex agentic stacks to run efficiently even on limited 16GB Mac hardware, opening the door for more robust local agent adoption.
Qwen 3.6 and the Local Speed Record r/LocalLLaMA
Local inference is hitting new performance milestones, with Qwen 3.6 27B redefining what is possible on consumer-grade hardware. Using the llama.cpp Multi-Token Prediction (MTP) branch, u/m94301 reported achieving 54 t/s on a V100—a 1.86x increase over standard performance. This breakthrough suggests a cross-platform shift toward hardware-accelerated parallel token generation for real-time agentic loops.
However, the benchmark wars continue as practitioners weigh raw speed against production reliability. While Qwen dominates synthetic tests, contributors on r/LocalLLaMA note that Gemma 4 31B is often cited as more reliable for complex tool-calling. To bridge this gap, specialized fine-tunes like Hermes Agent Qwen 3.6 are being deployed to mitigate the parameterization errors that reportedly plague 85% of production agents.
The 45x Vision Tax r/LocalLLM
The economic feasibility of vision-based agents is under intense scrutiny. A detailed analysis by u/TroyNoah6677 reveals that Anthropic’s 'Computer Use' navigation is 45x more expensive than using structured APIs for identical tasks. This 'vision tax' stems from quadratic token growth, where re-sending full conversation history and high-resolution screenshots drives costs toward $5–8 per complex task.
To maintain margins, developers are pivoting toward 'token-saving' proxies like RTK and Caveman, which can reduce consumption by 60-90%. The prevailing sentiment in r/automation is that the industry is moving toward a hybrid model: vision is reserved for initial discovery, while repetitive execution is offloaded to deterministic, DOM-based automation to avoid unsustainable costs.
The Multi-Agent Dependency Spiral r/AI_Agents
Managing a single agent is a solved problem, but managing dependencies in a multi-agent system (MAS) is where the complexity explodes. Organizations now deploy an average of 12 agents, a number projected to climb 67% within two years according to Beam AI. u/Kitchen_West_3482 highlights that handoffs often create hidden dependencies where minor formatting shifts cause system-wide failures.
This reliability gap is forcing a transition from 'vibe-based' handoffs to formal orchestration patterns. Practitioners on r/automation confirm that managing these data flows now requires significantly more engineering hours than the initial agent development. This has spurred the adoption of foundational design patterns that treat agents as integrated enterprise components rather than isolated tools.
Verticalization: When Small Models Win r/LocalLLaMA
General-purpose models are losing ground to 'skill-based' agents fine-tuned for high-stakes domains. A prominent example is the Solidity-tuned version of Qwen 3.6 27B, which u/swingbear reports has surpassed Claude 3 Opus in smart contract auditing. In these specialized fields, the frontier of reliability isn't the model itself, but the validation loops that wrap it.
Developer tools are seeing similar verticalization through agents like Ghostpatch, which automates open-source contributions. According to u/One_Drink_2075, these agents succeed not by being better 'coders' in the abstract, but by mastering repository-specific rules. This trend is supported by the rise of specialized tool-calling models like Gorilla LLM, which prioritize deterministic execution over natural language fluency.
The Orchestration Layer
OpenAI and Anthropic race to automate the desktop as orchestration layers get a persistence makeover.
The transition from text-based assistants to autonomous action agents has officially entered the production reality phase. With the launch of OpenAI's Operator and Anthropic's hardened Computer Use API, the browser is no longer just a window for information retrieval—it is the interface for agency. But as we move toward visual-spatial reasoning and direct computer interaction, the technical debt of traditional orchestration is coming due. We are seeing a decisive move away from stateless, forgetful RAG implementations toward persistent, graph-based memory systems like LangGraph that can actually survive the messy reality of web-based workflows.
Simultaneously, the integration tax that has long hindered agent deployment is being aggressively tackled by the Model Context Protocol (MCP). With a staggering 7.8x growth in public servers, MCP is positioning itself as the universal standard for tool interaction. For developers, the focus has shifted from model size to system reliability: optimizing for sub-100ms local routing with Small Language Models (SLMs) and implementing human-in-the-loop patterns that treat safety as an architectural requirement rather than a side effect. Today's issue explores how these disparate threads are weaving together into a coherent stack for the Agentic Web.
OpenAI Operator Signals Shift to Browser-Native Agency
The launch of OpenAI's Operator in research preview for U.S. Pro users marks a definitive pivot from text-based chat to functional, browser-native action. OpenAI highlights an 87% success rate on specialized browser benchmarks, utilizing a Computer-Using Agent (CUA) architecture that interprets visual interfaces directly. This move is intended to bypass the brittleness of traditional DOM-scraping, though developers on Discord (openai_dev) are already debating whether these results hold up against the volatility of dynamic web applications where 'static' success often fails.
This transition introduces a new hierarchy of technical challenges centered on latency and reliability. Early testers report a significant performance gap between vision-based planning and direct DOM manipulation, noting that recursive error loops remain a primary bottleneck for production-grade reliability. As builders move toward stateful orchestration frameworks like LangGraph and PydanticAI to manage these loops, the focus has shifted toward providing developers with more granular control over the agent's 'thinking' process to prevent autonomous failures in high-stakes environments.
Join the discussion: discord.gg/openai
Anthropic Hardens Computer Use with Visual-Spatial Reasoning
Anthropic has rolled out major updates to the Claude 3.5 Sonnet 'Computer Use' capability, introducing a refined 'visual-spatial' reasoning layer that has reportedly led to a 15% reduction in mis-clicks. These updates focus on coordinate mapping and screen parsing, enabling agents to handle legacy software automation where traditional APIs are unavailable. Beyond precision, the platform now supports advanced tool discovery, allowing agents to learn and execute tools dynamically within the developer platform.
While reliability is climbing, the economic friction of high token overhead for frequent task loops remains a primary concern for enterprise scaling. Developers on Discord (anthropic-dev) note that 'hybrid execution' models—combining vision with local OCR—remain necessary to verify high-stakes actions in production environments. Despite these hurdles, the latest Claude Code releases have improved the developer experience with smarter model picking and better Windows compatibility.
Join the discussion: discord.gg/anthropic
LangGraph Persistence Layer Redefines Agentic Memory
LangGraph has solidified its role as a low-level orchestration runtime by shifting the focus from stateless vector-store memory to persistent, graph-based state management. Unlike traditional RAG-based systems, LangGraph's persistence layer allows for checkpointing the entire agent state at every node, enabling 'time-travel' debugging and 100% state recovery. This architecture supports multiple storage backends, providing the flexibility needed for enterprise-grade, long-running agents that must survive process restarts.
A key innovation is 'managed memory,' which allows agents to retain structural context across sessions without re-injecting exhaustive message histories. This optimization is reported by developers to yield up to 30% savings in token usage for complex, multi-step autonomous tasks. By moving toward this graph-based approach, practitioners are effectively building tiered memory systems that prioritize plan optimality over raw data volume.
Join the discussion: discord.gg/langchain
Model Context Protocol (MCP) Gains Ecosystem Traction
The Model Context Protocol (MCP) has solidified its position as the "USB-C for AI agents," solving the complex N×M integration problem by standardizing how models interact with external tools. Recent data reveals that 78% of AI teams now have at least one MCP-backed agent in production, with the public server registry experiencing a massive 7.8x growth over the past year. Major providers including OpenAI, Google, and Anthropic have moved toward native support, significantly reducing the "integration tax."
Community contributors highlight that this shift toward a "plug-and-play" architecture is essential for scaling AgentOps, though adoption is currently most aggressive in marketing teams where 22% already manage three or more active MCP servers. By standardizing the interface between models and data sources, MCP is enabling a more modular ecosystem where agents can be swapped out without rebuilding tool integrations from scratch.
Join the discussion: discord.gg/mcp
Local SLMs Optimized for Agentic Tool Calling
Small Language Models (SLMs) are hitting sub-100ms latency for local tool-calling loops, with Llama 3.2 3B proving to be 8.0x cheaper per token than cloud-based alternatives for high-volume micro-agent roles. Current architectural trends favor a 'router' model where these local SLMs handle immediate tool execution and delegation, reserving complex multi-step planning for larger models.
Join the discussion: discord.gg/local-llm
Human-in-the-loop Patterns for Autonomous Systems
Human-in-the-loop (HITL) design is evolving into a core architectural requirement, utilizing 'Confidence Thresholds' and 'Draft Mode' patterns to increase oversight efficiency by 40%. Systems are increasingly adopting 'Asynchronous Approval Queues' and tools like LangChain MCP Adapters to bridge agentic workflows with external authorization platforms like Permit.io for secure, auditable intervention.
Join the discussion: discord.gg/safety
Deterministic Logic Labs
Hugging Face's smolagents and NVIDIA's Cosmos lead a shift toward deterministic, code-driven agent execution.
Today marks a definitive pivot in the agentic stack. We are moving away from the era of 'probabilistic guessing'—where agents struggle with brittle JSON schemas and text-based tool calls—and toward an era of deterministic execution. Hugging Face's smolagents is the catalyst here, proving that a minimalist 'code-as-action' approach isn't just simpler; it is objectively more effective, yielding a 26% performance boost on benchmarks like GAIA. This isn't just about software workflows; we are seeing this rigor extend into the physical world.
NVIDIA's Cosmos Reason 2 is bringing advanced planning to robotics, allowing models to 'imagine' spatial outcomes before they move. Meanwhile, the standardization of tool use through the Model Context Protocol (MCP) and the rise of industrial-grade benchmarks like AssetOpsBench show a community maturing beyond academic chat interfaces. For builders, the message is clear: the industry is consolidating around verifiable environments and executable logic. If your agent isn't writing code or being tested in a grounded, state-dependent setting, it is already legacy. We are moving from agents that talk to agents that do.
Smolagents Redefines Agentic Workflows with Code-as-Action
Hugging Face is leading a fundamental shift in the agentic web with smolagents, a minimalist library of approximately 1,000 lines that prioritizes a 'code-as-action' paradigm over traditional, brittle JSON tool-calling. By allowing agents to write and execute Python snippets directly, the framework achieves a 26% performance improvement and a 30% reduction in logic steps. This approach was validated by the Transformers Code Agent, which topped the GAIA benchmark, demonstrating that code-writing agents are far more effective at complex reasoning than those limited to probabilistic text tool-selection.
To address the 'verification gap' where agents fail to confirm task completion, the ecosystem now integrates Arize Phoenix for granular tracing and evaluation. Multimodal capabilities are also expanding through smolagents-can-see, which enables Vision-Language Models (VLMs) to interact with visual GUI elements natively. For rapid deployment, the library utilizes the Model Context Protocol (MCP), enabling developers to build functional agents in as few as 50-70 lines of code Hugging Face.
High-Throughput SSMs and Evaluation Suites Redefine Desktop Automation
The landscape of autonomous desktop interaction is shifting toward high-velocity execution with the release of Holotron-12B by H Company. Post-trained from NVIDIA’s Nemotron-Nano-2 VL, this 12B-parameter model utilizes a hybrid State-Space Model (SSM) architecture to achieve a throughput of 8.9k tokens/s on a single H100, powering the Surfer-H agent to a 62.3% success rate on the ScreenSuite benchmark—nearly doubling the 36.1% baseline established by GPT-4o.
NVIDIA Cosmos and UAVs Bring Spatial Reasoning to Physical AI
NVIDIA is accelerating the transition from chatbots to autonomous operators with Cosmos Reason 2, an open reasoning Vision-Language Model (VLM) built for robotics. By integrating spatial-temporal scene understanding and common-sense physics, the model enables robots to reason about space and time before executing actions, while the new ESARBench framework provides a specialized evaluation for UAVs in high-stakes search-and-rescue scenarios to mitigate 'Incorrect Verification' failures NVIDIA AI.
The 'USB Moment' for AI: Unified Tool Use and Transformers Agents 2.0
Standardization is arriving for agentic tool use as Hugging Face launches a Unified Tool Use specification to harmonize LLM interactions across OpenAI, Anthropic, and Google. This 'single interface' approach is paired with Transformers Agents 2.0 and the 'License to Call' framework, which grants agents granular tool permissions and a robust execution loop, while the Hugging Face x LangChain Partner Package ensures seamless interoperability across orchestration layers.
Open-Source Deep Research Agents Challenge Proprietary Giants
Open-source DeepResearch achieves 67% on GAIA by using a CodeAgent architecture to execute Python for data processing.
From Academic Chat to Industrial Action: The Rise of Execution-Centric Benchmarking
IBM Research has introduced AssetOpsBench, a multimodal IoT environment that tests agents against real-world industrial constraints.
Specialized Agents for Healthcare and Academia
Google's EHR Navigator Agent demonstrates intelligent clinical data retrieval using MedGemma, though it is currently for illustrative purposes only.
Tiny Agents and Math Reasoning for Edge Devices
Google's FunctionGemma-270M requires only 0.5 GB of RAM to perform local tool-calling on smartphones with sub-second latency.